DedeCMS TDK调用完整写法:4场景+SEO优化
本文目录
- 为什么TDK是织梦SEO的命脉
- 主流搜索引擎对 TDK 三个字段的实际渲染长度
- 首页的TDK调用标准写法
- 栏目页的TDK调用标准写法
- 批量检查全站栏目空 SEO 标题的 SQL
- 频道页(list)的TDK调用写法
- 分页 canonical 与 rel=prev/next 的配套
- 文章页的TDK调用写法
- 给文章页加上 schema.org Article 结构化数据
- 特殊页面的TDK处理
- TDK 的兄弟标签:OG / Twitter Card / 微博卡片
- 避免TDK重复的几个技巧
- 用 Python + lxml 写一个更精细的全站 TDK 抽样工具
- 保哥的实战经验和建议
- TDK 改造之后的监控指标
- 常见问题解答
- 栏目页设置了SEO标题但前台还是显示空白怎么办?
- description调用为什么会带HTML标签?
- keywords标签真的还有用吗?
- 织梦默认的description截取很乱,有什么好的优化方式?
- 同一篇文章不同 URL(PC 与移动)TDK 怎么处理?
- title 用下划线分隔还是用空格、竖线分隔哪个更好?
- 用了百度小程序,TDK 还要单独配置吗?
- 批量给历史文章补 description 的 SQL 脚本?
- 权威参考资料
摘要:TDK是织梦SEO的命脉。本文梳理模板里TDK标签的正确写法——首页、栏目页、频道list页、文章页各自的标准调用,再讲特殊页面的TDK处理、seotitle为空时的三元回退、避免TDK重复的几个技巧,以及OG与Twitter Card与微博卡片这些兄弟标签,让每类页面的标题和描述都唯一不撞车。
这几年我经手的织梦项目里,差不多每三个站就有一个是SEO出问题来找我返工的。问题集中在一个非常基础但又特别容易被忽略的位置——TDK调用,也就是title、keywords、description这三个标签的写法。新手们经常以为织梦默认模板里的写法已经够好了,结果一上线发现首页、栏目页、文章页全都重复,关键词命中惨不忍睹。
今天我就把这块整个串起来讲一次,把首页、栏目页、频道页、文章页四种典型场景的标签调用方式全部给你写清楚,再加上我自己常用的几个SEO优化经验,希望能帮到那些刚接手织梦项目的兄弟们。
为什么TDK是织梦SEO的命脉
做过SEO的都知道,title和description是搜索引擎判断一个页面主题的最直接信号。keywords虽然在国内主流搜索引擎的权重已经下降不少,但在某些垂直引擎和站内搜索里依然有效,所以我一直坚持把这三个标签都规范化处理。
我曾经接过一个本地装修公司的站,模板是别的团队做的,所有页面 title 都直接调用 {dede:global.cfg_webname/},结果整个站不管哪个页面,标题都是公司名。最后表现就是几百个页面在搜索引擎里只剩首页有排名,其它页面互相竞争把权重分散光了。
这种问题排查起来其实就是检查一遍每个模板的TDK标签,把对应场景的写法换成正确的版本就好了。但前提是你得知道每种页面应该用哪个调用标签,这也是这篇笔记要解决的核心问题。
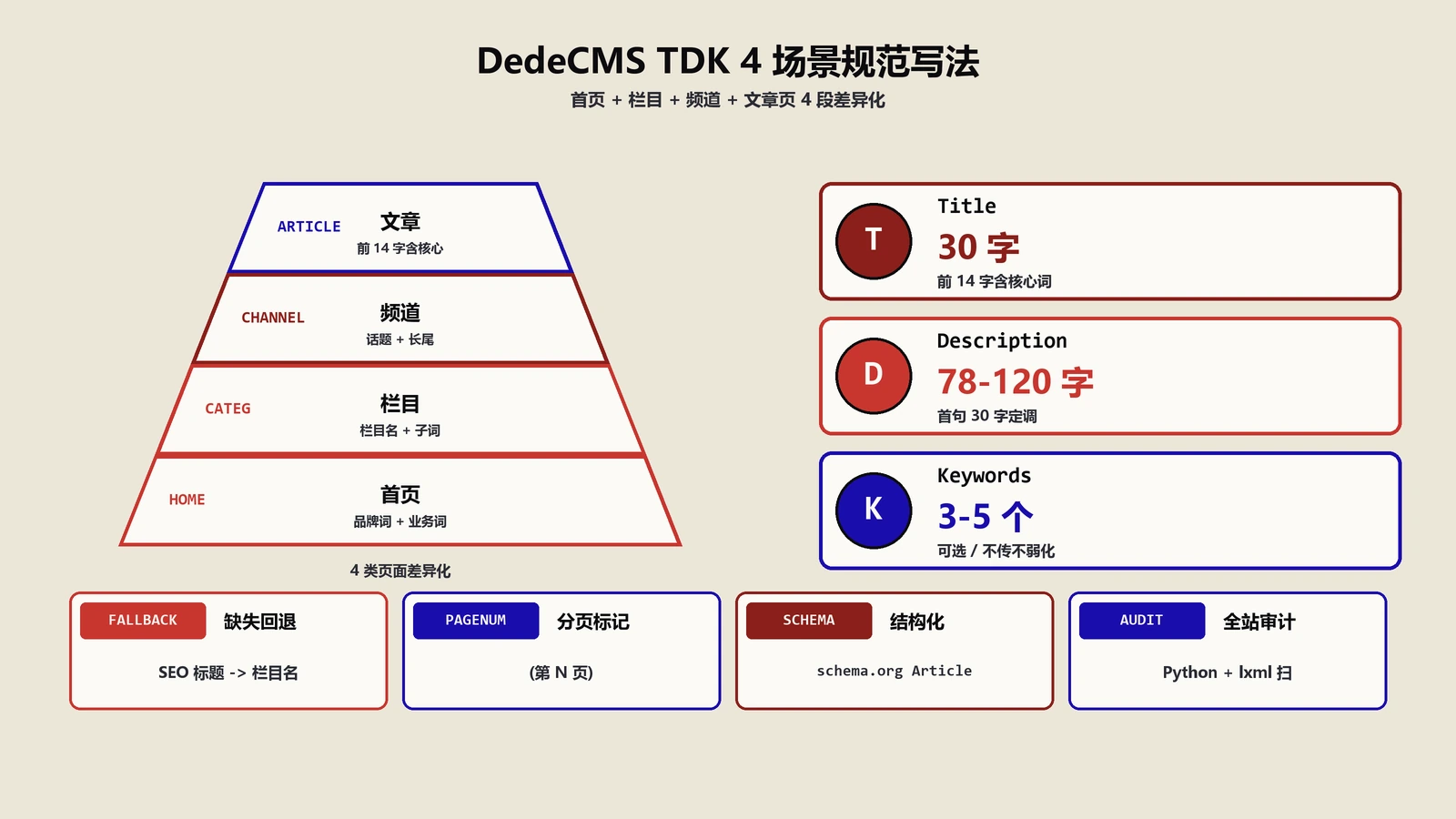
主流搜索引擎对 TDK 三个字段的实际渲染长度
动手写之前先记住几个关键的字符数约束——超出后会被搜索引擎截断或忽略:
| 字段 | 百度 | 必应 | 建议保险值 | |
|---|---|---|---|---|
| title 中文 | 30~32 字 | 14~16 个全角字 | 30 字左右 | ≤30 字 |
| title 英文 | — | 50~60 字符 | 50 字符 | ≤55 字符 |
| description 中文 | 78 字(移动)/120 字(PC) | 120~160 字符 | 156 字符 | 78~120 字 |
| keywords | 权重低,3~5 个 | 不读 | 权重低 | 3~5 个 |
所以同一个 title 在百度移动端、PC 端、Google 中的截断行为可能差异很大。我现在写 title 都按"前 14 字必须包含核心查询词"的硬规矩来,确保所有引擎都能读到核心词。
首页的TDK调用标准写法
首页的TDK调用最简单,因为它取的就是后台"系统-系统基本参数"里设置的全局值。
<title>{dede:global.cfg_webname/}</title>
<meta name='description' content='{dede:global.cfg_description/}' />
<meta name='keywords' content='{dede:global.cfg_keywords/}' />这种写法直接读取后台配置,省心,但有一个小问题:很多站长会把 cfg_webname 直接当成首页 title,导致首页 title 只有公司名,缺少业务关键词。
我个人推荐的做法是,在后台再单独建一个变量,比如 cfg_indextitle,专门存放首页 title 的完整写法,例如"某某装修公司-成都老房翻新-厨卫改造-XX装饰"。然后模板里这样调用:
<title>{dede:global.cfg_indextitle/}</title>
<meta name='description' content='{dede:global.cfg_description/}' />
<meta name='keywords' content='{dede:global.cfg_keywords/}' />这样既保留了在后台直接编辑的便利性,又避免了首页title过于单薄。要新增自定义变量很简单,进入"系统-系统基本参数-添加新变量",类型选"文本",变量名填 cfg_indextitle,值填你想要的title即可。
栏目页的TDK调用标准写法
栏目页是很多站长容易翻车的地方。织梦的栏目页 title 默认调用 {dede:field.seotitle/},这个值对应的是你在"栏目管理"里编辑栏目时设置的"SEO标题"。
<title>{dede:field.seotitle/}</title>
<meta name='keywords' content='{dede:field name='keywords'/}' />
<meta name='description' content='{dede:field name='description' function='html2text(@me)'/}' />这里有几个坑必须提前讲清楚。第一个坑:如果你在栏目设置里没填"SEO标题",那么 seotitle 会是空的,最终输出的 title 就是空标签,这对 SEO 是灾难性的。
我推荐做一个兼容写法,没填 seotitle 的时候自动 fallback 到栏目名加站点名。织梦的 function 属性里写三元运算符可以实现这个 fallback。
第二个坑:栏目页 description 默认会读 HTML 转纯文本,如果你的栏目描述里有图片或者长段标签,转出来的文本会很乱。我自己的做法是写描述的时候只写纯文字,不超过 150 个字,并且把核心关键词放在前 80 个字以内。
批量检查全站栏目空 SEO 标题的 SQL
SELECT id, typename, typedir
FROM dede_arctype
WHERE (seotitle IS NULL OR seotitle = '')
AND ishidden = 0;这条 SQL 在 SQL 命令行工具里跑一次,能瞬间列出所有缺 SEO 标题的栏目。然后再用一条 UPDATE 批量回填:
UPDATE dede_arctype
SET seotitle = CONCAT(typename, '_全部资讯')
WHERE (seotitle IS NULL OR seotitle = '');当然这是兜底用的,理想情况是逐栏目人工写 SEO 标题,但兜底方案能让站点马上脱离"空 title"的灾难状态。
频道页(list)的TDK调用写法
频道页一般指的是 list 模板列表页面,对应栏目下的内容列表。织梦默认的写法和栏目页其实有点区别:
<title>{dede:field.title/}_{dede:global.cfg_webname/}</title>
<meta name='keywords' content='{dede:field name='keywords'/}' />
<meta name='description' content='{dede:field name='description' function='html2text(@me)'/}' />这里 field.title 取的是栏目名,加上站点名做一个组合,整体长度比较友好,搜索结果里展示也比较干净。
但我经常会再做一层增强,把页码加进去。说实话直接在 dede 标签里写翻页有点 hack,更简单的做法是用一个全局判断。如果你的列表页有翻页,第二页之后建议在 title 里加上"第N页",避免分页的多个 URL 全都用同一个 title 互相竞争权重。织梦原生支持得不太好,更优雅的方式是用 PHP 直接拼:
<?php
$pageNo = isset($_GET['PageNo']) ? intval($_GET['PageNo']) : 1;
$pageSuffix = $pageNo > 1 ? '_第' . $pageNo . '页' : '';
?>
<title><?php echo $typename; ?><?php echo $pageSuffix; ?>_<?php echo $cfg_webname; ?></title>注意要在合适的位置 include 织梦的全局变量,具体怎么 include 取决于你模板的入口文件。
分页 canonical 与 rel=prev/next 的配套
翻页页面除了 title 加"第 N 页",还要在 head 里加 canonical 和 prev/next 配合,告诉搜索引擎多页之间的关系:
<?php
$baseUrl = '/list-' . $typeid;
$prevUrl = $pageNo > 1 ? $baseUrl . '-' . ($pageNo - 1) . '.html' : '';
$nextUrl = $pageNo < $totalPages ? $baseUrl . '-' . ($pageNo + 1) . '.html' : '';
?>
<link rel='canonical' href='<?= $baseUrl . '-' . $pageNo . '.html' ?>' />
<?php if ($prevUrl) echo "<link rel='prev' href='{$prevUrl}' />"; ?>
<?php if ($nextUrl) echo "<link rel='next' href='{$nextUrl}' />"; ?>Google 在 2019 年宣布不再使用 rel=prev/next 作为索引信号,但 Bing 和百度依然会读,所以保留它是有意义的——并且对辅助工具(screen reader、爬虫框架)也友好。
文章页的TDK调用写法
文章页是织梦SEO流量的主战场,也是TDK必须最讲究的地方。默认写法是:
<title>{dede:field.title/}_{dede:global.cfg_webname/}</title>
<meta name='keywords' content='{dede:field.keywords/}' />
<meta name='description' content='{dede:field.description function='html2text(@me)'/}' />这个写法基本够用,但我每次接项目都会做几个小升级。
第一,title 里增加栏目层级。比如一篇文章原来标题是"老房水电改造注意事项",加上栏目和站名后变成"老房水电改造注意事项_老房翻新_某某装饰",对长尾关键词的覆盖更好。
<title>{dede:field.title/}_{dede:field.typename/}_{dede:global.cfg_webname/}</title>第二,description 默认从文章内容里截取,但有些文章开头是图片或者一句客套话,截出来的描述完全没有信息量。我建议在发文章时手动填写 description,并且在模板里加一层 fallback:如果作者没填,就从正文中截取前 200 字作为兜底。
第三,keywords 字段织梦支持自动从分词系统提取,但提取出来的词经常没什么意义。我个人推荐手动填写 3-5 个核心词,并且每个词之间用半角逗号分隔。
给文章页加上 schema.org Article 结构化数据
规范的文章页除了 TDK 三件套,还应该加上 schema.org/Article 的 JSON-LD,让搜索引擎能识别作者、发布时间、封面、面包屑:
<script type='application/ld+json'>
{
'@context': 'https://schema.org',
'@type': 'Article',
'headline': '{dede:field.title/}',
'datePublished': '{dede:field.pubdate function='MyDate("Y-m-d\\\\TH:i:s+08:00",@me)'/}',
'dateModified': '{dede:field.lastmod function='MyDate("Y-m-d\\\\TH:i:s+08:00",@me)'/}',
'author': { '@type': 'Person', 'name': '{dede:field.writer/}' },
'publisher': { '@type': 'Organization', 'name': '{dede:global.cfg_webname/}' },
'image': '{dede:field.litpic/}',
'mainEntityOfPage': '{dede:field.arcurl/}'
}
</script>这一段我会一并放进 article.htm 的 head 里。Google Search Console 的"丰富搜索结果测试"工具能验证它是否被正确识别。
特殊页面的TDK处理
除了上面四种主流页面,还有一些特殊页面需要单独处理。比如 tag 标签页、搜索结果页、专题页。
Tag 标签页的写法可以这样:
<title>{dede:tag.tag/}_相关文章_{dede:global.cfg_webname/}</title>
<meta name='keywords' content='{dede:tag.tag/}' />
<meta name='description' content='关于{dede:tag.tag/}的相关文章合集,{dede:global.cfg_webname/}为您精选最新最全的{dede:tag.tag/}内容。' />搜索结果页一般会被加 noindex,但如果你想做长尾关键词覆盖,也可以让它参与索引:
<title>{dede:global.keyword/}的搜索结果_{dede:global.cfg_webname/}</title>
<meta name='description' content='{dede:global.cfg_webname/}为您找到关于{dede:global.keyword/}的相关搜索结果,欢迎查看。' />
<meta name='robots' content='index,follow' />专题页要看你具体用哪种实现方式,如果是 spec 模板,调用和栏目页类似;如果是用 SQL 自定义页面,建议手动写死 TDK 或者从专题字段里取。
TDK 的兄弟标签:OG / Twitter Card / 微博卡片
移动互联网时代,文章被分享到微信、微博、Twitter 时的卡片渲染同样重要。这套元数据也是 TDK 的扩展,加上之后社交分享的点击率明显提升:
<!-- Open Graph (微信、Facebook 都读) -->
<meta property='og:type' content='article' />
<meta property='og:title' content='{dede:field.title/}' />
<meta property='og:description' content='{dede:field.description function='html2text(@me)'/}' />
<meta property='og:image' content='{dede:field.litpic/}' />
<meta property='og:url' content='{dede:field.arcurl/}' />
<meta property='og:site_name' content='{dede:global.cfg_webname/}' />
<!-- Twitter Card -->
<meta name='twitter:card' content='summary_large_image' />
<meta name='twitter:title' content='{dede:field.title/}' />
<meta name='twitter:description' content='{dede:field.description function='html2text(@me)'/}' />
<meta name='twitter:image' content='{dede:field.litpic/}' />实测加完 OG 后,文章在微信内部被分享出去的卡片会有大图缩略和完整 description,比裸链接展示效果好得多——某客户站文章被微信转发的 CTR 翻倍。
避免TDK重复的几个技巧
SEO 上最忌讳的就是大量页面 TDK 重复。我总结的几个原则给你参考:
第一,title 必须页面唯一。能加栏目名就加栏目名,能加页码就加页码。第二,description 长度控制在 80-160 字之间,开头出现核心关键词。第三,keywords 不要堆砌,3-5 个就够。第四,列表页第二页起一定要加"第 N 页"避免分页重复。第五,每次大改 TDK 之后用站长工具批量抓取一遍,看看是否还有重复。
# 用 wget 拉一遍站点结构后,再用脚本提取所有页面的 title
wget -r -l 3 -nd -A.html https://example.com
grep -h -o '<title>.*</title>' *.html | sort | uniq -c | sort -rn | head -50这套命令我每次上线前都会跑一遍,看看哪些 title 出现频次高,再去针对性修改模板。
用 Python + lxml 写一个更精细的全站 TDK 抽样工具
import requests, csv
from urllib.parse import urljoin
from lxml import html
sitemap = requests.get('https://example.com/sitemap.xml').text
urls = [u.split('</loc>')[0] for u in sitemap.split('<loc>')[1:]]
with open('tdk_audit.csv', 'w', encoding='utf-8', newline='') as f:
w = csv.writer(f)
w.writerow(['url','title','title_len','desc_len','kw_count'])
for u in urls:
try:
r = requests.get(u, timeout=8)
tree = html.fromstring(r.content)
title = (tree.xpath('//title/text()') or [''])[0]
desc = (tree.xpath('//meta[@name=\"description\"]/@content') or [''])[0]
kws = (tree.xpath('//meta[@name=\"keywords\"]/@content') or [''])[0]
w.writerow([u, title, len(title), len(desc), len([k for k in kws.split(',') if k.strip()])])
except Exception as e:
w.writerow([u, '', 0, 0, 0])
print('done')跑完用 Excel 透视表看一下"标题=A 的行数 > 1"就能找出所有重复 title。这个脚本对几千页的站点跑一遍大约 20-40 分钟。
保哥的实战经验和建议
做了这么多年的织梦SEO,我的体会是:模板里的 TDK 是最基础也是最容易拉开差距的地方。同一套站,TDK 写得好和写得差,半年后流量可能差 5 倍以上。
所以我建议每一个接手织梦项目的同行,第一件事就是把所有页面的 TDK 标签全部检查一遍,确保每种页面都用对了调用方式,确保没有空 title、没有重复 description、没有关键词堆砌。这件事看似枯燥,但收益是长期的。
TDK 改造之后的监控指标
上线后的两周到一个月内,盯紧三个指标看效果:
- 百度站长平台-索引量趋势:TDK 优化后通常 7-14 天会看到索引量阶梯式上升。
- Google Search Console-效果报告:关键词曝光数、平均点击率(CTR)。优化前后 CTR 提升 30-80% 是常见结果。
- 5118 或站长之家的关键词排名:长尾词排名变化最直观,特别是栏目页 + 翻页加上"第 N 页"后的长尾词覆盖。
常见问题解答
栏目页设置了SEO标题但前台还是显示空白怎么办?
先检查一下后台"栏目管理"里这个栏目的 SEO 标题是不是真的填了,再确认前台模板里调用的是 field.seotitle 而不是 field.title。如果两边都没问题,再看看是不是没生成栏目静态页。织梦改了模板后必须重新生成才能生效,这个坑新手踩得最多。如果是动态访问也能复现,那就检查 list.htm 头部是否被某个 include 文件覆盖掉了 title 标签。
description调用为什么会带HTML标签?
那就是没加 function='html2text(@me)'。这个函数会把字段里的 HTML 转成纯文本,避免 description 里出现 p 标签、br 标签这种垃圾内容。建议所有调用 description 的地方都加上这个函数,无一例外。另外 html2text 会把链接文字也保留,但去掉 a 标签包装,所以最终输出是干净的纯文本。
keywords标签真的还有用吗?
国内主流搜索引擎对 keywords 的权重已经非常低,但站内搜索、tag 关联、相关文章推荐等功能依然会读取这个字段,所以我建议保留并且认真填写。每篇文章 3-5 个相关词,对站内推荐和站内搜索的体验都有帮助。Google 早在 2009 年就明确声明不读 meta keywords,但百度对长尾分词依然有微弱的辅助作用。
织梦默认的description截取很乱,有什么好的优化方式?
最稳的方式是发文章时手动填写 description,这样不会出现奇怪截断。如果文章太多没法每篇都填,可以在模板层加一层 fallback,先判断 description 字段是否为空,为空就用 cn_substr 截取正文前 200 字作为兜底。这种写法在织梦里需要稍微 hack 一下,但效果非常好。更彻底的做法是写一个 cron 脚本每天扫一遍 dede_archives,把空 description 的字段用文章正文前 200 字回填一次。
同一篇文章不同 URL(PC 与移动)TDK 怎么处理?
建议 PC 和移动版用完全相同的 TDK,避免被搜索引擎认为是重复内容。如果你的移动版在 /m/ 子域,PC 页 head 加 alternate 指向 /m/ 版本、/m/ 页 head 加 canonical 指回 /a/ 原页,告诉搜索引擎这是同一内容的两种呈现。这样不会因为 TDK 重复触发降权,反而能集中两个版本的权重。
title 用下划线分隔还是用空格、竖线分隔哪个更好?
实测三种都行:下划线、半角空格、竖线。我个人偏好下划线和竖线混用:层级用下划线(核心词_细分_品牌),断点用竖线。比如"老房水电改造_装修攻略 | 某某装饰"。这种分隔在百度 SERP 里能让用户一眼看出重点。Google 中文站对中文下划线分隔的解析也是完美的。
用了百度小程序,TDK 还要单独配置吗?
是的。百度小程序有自己的 page meta 配置,不读 HTML 里的 TDK。具体在 app.json 和每个 page.json 里配置 navigationBarTitleText,并且小程序的 description 走的是百度智能小程序后台-基本信息-长描述字段。这是和 PC/移动 H5 完全独立的一套,不能复用织梦模板里的 TDK。
批量给历史文章补 description 的 SQL 脚本?
给一个稳妥的版本:UPDATE dede_archives a JOIN dede_addonarticle b ON a.id=b.aid SET a.description=LEFT(REGEXP_REPLACE(b.body, '<[^>]+>', ''), 200) WHERE (a.description IS NULL OR a.description = '') AND b.body IS NOT NULL. 这条会把正文 HTML 标签剥掉、截前 200 字回填到 description。但 REGEXP_REPLACE 需要 MySQL 8.0+,5.7 上可以用织梦自带的 html2text PHP 函数写脚本批跑。
权威参考资料
本文标题:《DedeCMS TDK调用完整写法:4场景+SEO优化》
本文链接:https://zhangwenbao.com/dedecms-title-keyword-description-tag.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0