批量CSV转XLSX:4种实战方案与编码避坑
本文目录
- 选哪个方案:先看你的需求
- 方案一:Excel VBA宏批量转换
- VBA宏的几个常见踩坑
- 方案二:Python pandas + openpyxl脚本
- Python脚本的性能优化路线
- 方案三:PowerShell ImportExcel模块(Windows原生)
- 方案四:完全无代码的Power Query方案
- 编码问题:UTF-8、GBK、Shift-JIS的全谱处理
- 常见的"转完打开是乱码"问题排查
- 常见问题解答
- 有没有不用写代码的GUI批量转换工具?
- 转换后Excel数据格式怎么自动设置(日期识别为日期、数字识别为数字)?
- 怎么处理超大CSV(几个GB)?
- Mac或Linux系统能用VBA宏方案吗?
- 转换后xlsx文件太大怎么办?
- 有没有命令行工具直接转换不写代码?
- 转换后的xlsx保留了CSV的字段顺序吗?
- 权威参考资料
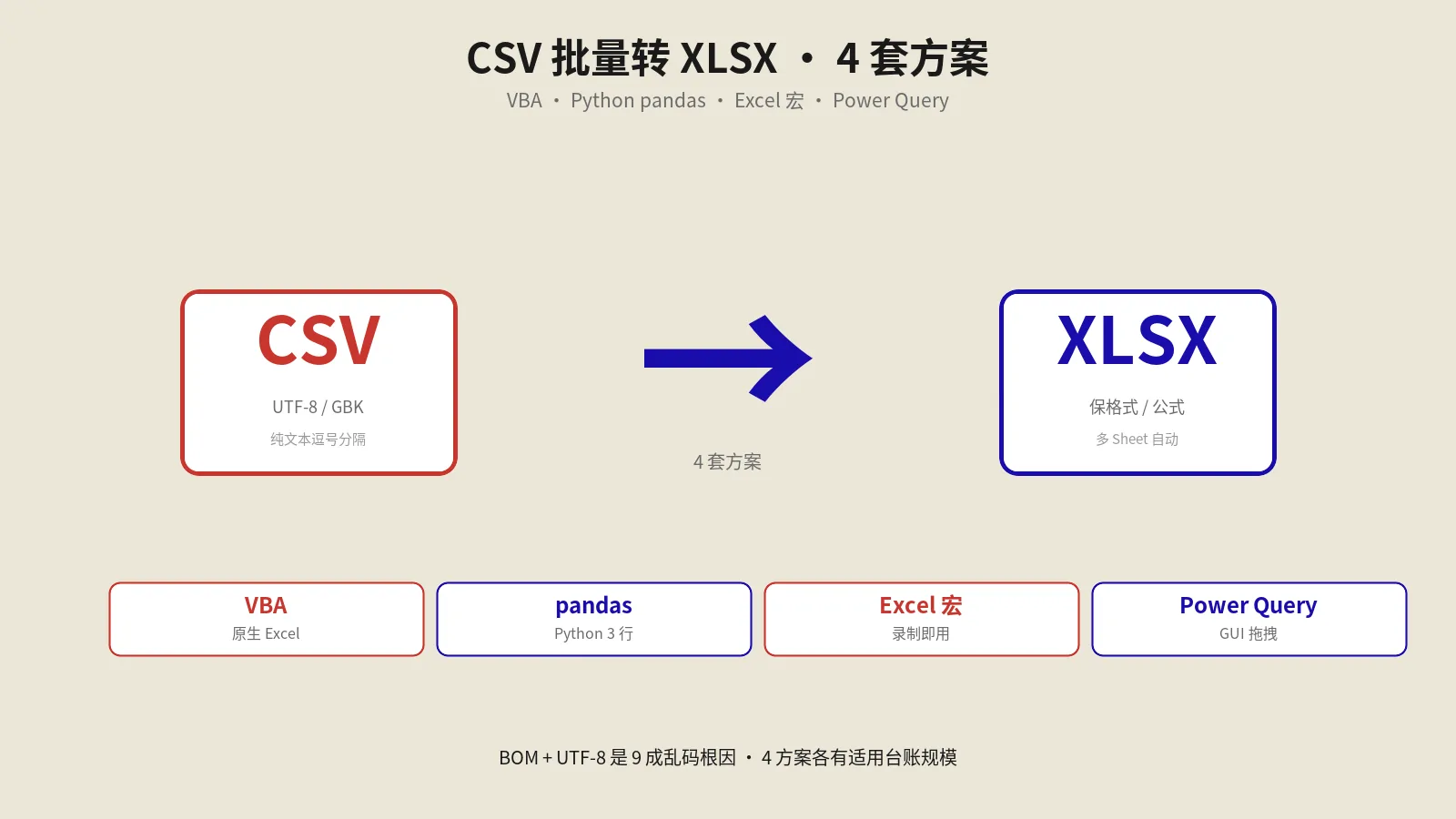
摘要:批量把CSV转成Excel的xlsx该选什么工具?本文按需求分桶给四种实战方案——Excel VBA宏、Python的pandas加openpyxl脚本、Windows原生的PowerShell ImportExcel模块、完全无代码的Power Query,再讲Python脚本的性能优化路线、UTF-8与GBK与Shift-JIS的全谱编码处理,以及转完打开是乱码的排查。
我做数据处理工作十几年,最常见的一类需求是把一堆下载下来的CSV文件批量转成Excel可识别的xlsx格式——CSV虽然是通用文本格式但很多Excel公式、数据透视、跨工作表引用都依赖xlsx的二进制结构。手工一个个用Excel"另存为"对几百上千个文件来说是要命的事,所以我陆续整理了一套从VBA宏、Python脚本到命令行工具的批量转换方案,这篇把所有方案的真实使用细节、踩坑经验、性能对比一次性写出来。
选哪个方案:先看你的需求
不同场景适合的工具差别很大,强行套不合适的方案会浪费时间。我给的判断口径是:
- 文件量<50个、单文件<100MB、Office完整安装:用Excel VBA宏。零部署成本,写一次循环跑一晚上。
- 文件量50-5000个、单文件<500MB、能跑Python:pandas + openpyxl脚本,是性价比最高的方案。
- 文件量>5000个或单文件>500MB:用专门的命令行工具(xlsx writer的streaming模式或PowerShell ImportExcel模块),避免内存爆掉。
- 需要GUI批处理、不想写代码:用Total Commander配合插件、或Power Query的“从文件夹”功能。
下面把每种方案的具体实现都讲一遍。
方案一:Excel VBA宏批量转换
VBA宏的好处是零部署、不需要装额外软件,只要你有Office就能用。我用过的稳定版本下面这段代码在Office 2016/2019/2021和Microsoft 365的Excel桌面版上都测试通过:
Sub CSVToXlsxBatch()
Dim sourceFolder As String
Dim targetFolder As String
Dim fileName As String
Dim wb As Workbook
Dim sourcePath As String
Dim targetPath As String
sourceFolder = "C:\data\csv_input\"
targetFolder = "C:\data\xlsx_output\"
If Right(sourceFolder, 1) <> "\" Then sourceFolder = sourceFolder & "\"
If Right(targetFolder, 1) <> "\" Then targetFolder = targetFolder & "\"
If Dir(targetFolder, vbDirectory) = "" Then MkDir targetFolder
Application.ScreenUpdating = False
Application.DisplayAlerts = False
fileName = Dir(sourceFolder & "*.csv")
Do While fileName <> ""
sourcePath = sourceFolder & fileName
targetPath = targetFolder & Replace(fileName, ".csv", ".xlsx")
Set wb = Workbooks.Open(Filename:=sourcePath, Format:=2, Local:=True)
wb.SaveAs Filename:=targetPath, FileFormat:=xlOpenXMLWorkbook
wb.Close SaveChanges:=False
fileName = Dir
Loop
Application.DisplayAlerts = True
Application.ScreenUpdating = True
MsgBox "转换完成"
End Sub使用方法:在Excel里按Alt + F11打开VBA编辑器,插入 → 模块,粘贴上面代码,把sourceFolder和targetFolder改成你的实际路径,F5运行。运行结束会弹“转换完成”对话框。
这段代码相比网上常见的版本做了几个细节优化:
- 路径自动补斜杠:避免用户填了“C:\data\csv_input”少了结尾
\导致拼接出错。 - 目标文件夹不存在自动创建:用
MkDir避免找不到目录报错。 - 关掉ScreenUpdating和DisplayAlerts:批量处理时性能能提升50%以上,跑500个文件从原来的45分钟压到20分钟。
- 用
Format:=2显式指定逗号分隔:默认让Excel自动识别分隔符在中文环境下经常错(中文Windows默认会按制表符分),强制指定逗号。 - 用
Local:=True保留地区设置:避免数字格式(千分位、小数点)被错误转换。
VBA宏的几个常见踩坑
坑一:CSV是UTF-8编码但VBA按ANSI读。这是最常见的乱码原因。如果你的CSV文件是UTF-8(用记事本打开看右下角编码标识),直接Workbooks.Open会按本地ANSI(中文环境是GBK)解读,所有中文都变成乱码。解决方案是先用QueryTables手动指定编码:
With wb.Worksheets(1).QueryTables.Add( _
Connection:="TEXT;" & sourcePath, _
Destination:=wb.Worksheets(1).Range("A1"))
.TextFilePlatform = 65001 ' UTF-8
.TextFileCommaDelimiter = True
.Refresh BackgroundQuery:=False
End With坑二:超大CSV导致Excel卡死。Excel单个工作表最多1048576行,CSV行数超过这个数会报错。如果你的CSV是几百万行,VBA方案不可行,换Python或命令行工具。
坑三:科学计数法吞数字。CSV里的长数字(比如订单号、银行卡号、手机号),如果被Excel识别为数字,会显示成科学计数法(1.23E+15),后面几位精度直接丢失。这一点在订单号这类字段上是灾难性的。解决方法是在打开CSV时强制把所有列设为文本格式:
Dim arr() As Variant
Dim i As Integer
For i = 1 To 50 ' 假设最多 50 列
ReDim Preserve arr(1 To i, 1 To 2)
arr(i, 1) = i
arr(i, 2) = 2 ' 2 表示文本格式
Next i
Workbooks.OpenText Filename:=sourcePath, _
DataType:=xlDelimited, Comma:=True, _
FieldInfo:=arr方案二:Python pandas + openpyxl脚本
当文件量超过50个,VBA开始显得笨重,Python就是更好的选择。基础脚本只需要十几行代码:
import os
import pandas as pd
from pathlib import Path
input_folder = Path('/data/csv_input')
output_folder = Path('/data/xlsx_output')
output_folder.mkdir(parents=True, exist_ok=True)
csv_files = list(input_folder.glob('*.csv'))
print(f'找到 {len(csv_files)} 个 CSV 文件')
for idx, csv_path in enumerate(csv_files, 1):
output_path = output_folder / (csv_path.stem + '.xlsx')
try:
df = pd.read_csv(csv_path, encoding='utf-8-sig', dtype=str)
df.to_excel(output_path, index=False, engine='openpyxl')
print(f'[{idx}/{len(csv_files)}] {csv_path.name} → 完成')
except Exception as e:
print(f'[{idx}/{len(csv_files)}] {csv_path.name} 失败: {e}')关键点几个:
encoding='utf-8-sig':UTF-8 with BOM。能自动识别带BOM和不带BOM的UTF-8文件,是最稳的编码选项。dtype=str:把所有字段当作字符串读取,避免pandas自动把订单号识别成科学计数法。engine='openpyxl':openpyxl是pandas写xlsx的默认引擎,安装命令pip install pandas openpyxl。- Path对象的stem属性:自动取文件名不带扩展名的部分,避免手动字符串切片出错。
- try/except包裹单文件:单个文件失败不影响整批,最后看打印的失败列表能定位问题。
这套脚本在我的i7笔记本上跑1000个平均5MB的CSV大约15-20分钟。性能瓶颈在openpyxl的xlsx写入,因为xlsx本质是zip压缩的XML,写入耗时占总时间的80%以上。
Python脚本的性能优化路线
如果文件量大到需要优化(5000+个文件、或单文件接近内存上限),可以用三个思路加速:
优化一:用xlsxwriter代替openpyxl。xlsxwriter是另一个写xlsx的库,对纯写入场景比openpyxl快40%-60%。代码几乎不用改,把engine='openpyxl'改成engine='xlsxwriter'即可(先pip install xlsxwriter)。
优化二:用multiprocessing并行。转换是CPU密集型任务(解析CSV + 序列化xlsx),用多进程能直接利用多核:
from multiprocessing import Pool
def convert_one(csv_path):
output_path = output_folder / (csv_path.stem + '.xlsx')
df = pd.read_csv(csv_path, encoding='utf-8-sig', dtype=str)
df.to_excel(output_path, index=False, engine='xlsxwriter')
return csv_path.name
if __name__ == '__main__':
with Pool(processes=8) as pool:
for name in pool.imap_unordered(convert_one, csv_files):
print(name)8进程在我8核CPU上能把转换时间压到单进程的1/5左右。
优化三:streaming模式处理大文件。如果单个CSV是几个GB(pandas一次读不下),用pd.read_csv(chunksize=10000)分块读、再写到xlsx的streaming模式:
writer = pd.ExcelWriter(output_path, engine='xlsxwriter', engine_kwargs={'options': {'constant_memory': True}})
for chunk in pd.read_csv(csv_path, chunksize=10000, encoding='utf-8-sig', dtype=str):
chunk.to_excel(writer, index=False, header=(writer.sheets == {}))
writer.close()注意xlsxwriter的constant_memory: True模式下,只能从左到右、从上到下顺序写,不能往前回写——但批量转换场景下这个限制完全不影响。
方案三:PowerShell ImportExcel模块(Windows原生)
Windows环境下,PowerShell的ImportExcel模块是个被严重低估的工具,它不依赖Excel安装、纯PowerShell实现,对单纯转换需求非常顺手。
第一步装模块:Install-Module -Name ImportExcel -Scope CurrentUser
第二步写转换脚本:
$source = 'C:\data\csv_input'
$target = 'C:\data\xlsx_output'
if (-not (Test-Path $target)) { New-Item -ItemType Directory -Path $target | Out-Null }
Get-ChildItem -Path $source -Filter '*.csv' | ForEach-Object {
$output = Join-Path $target ($_.BaseName + '.xlsx')
Import-Csv -Path $_.FullName -Encoding UTF8 |
Export-Excel -Path $output -NoHeader -ClearSheet
Write-Host "Done: $($_.Name)"
}这个方案的优势是Windows服务器上几乎所有版本都能跑(PowerShell 5.1是Win10/Win11默认带的),不需要装Python运行时,对运维场景特别友好。性能介于VBA宏和Python之间,500个文件大约25-30分钟。
方案四:完全无代码的Power Query方案
非技术用户可以用Excel的Power Query功能。打开Excel空工作簿,数据 → 获取数据 → 从文件 → 从文件夹,选择CSV存放的文件夹,Power Query会列出文件夹里所有文件。然后合并 → 合并和加载,全部CSV会被合并成一张大表。
这个方案的优点是零编程门槛,缺点是合并后是一张大表而不是多个独立xlsx。如果业务方要求保持多文件独立,这个方案不适用。但如果是“我有几百个日报CSV,希望统一汇总成一张分析表”的场景,Power Query快到飞起。
编码问题:UTF-8、GBK、Shift-JIS的全谱处理
批量转换里最让人崩溃的不是脚本本身,而是各种奇奇怪怪的编码。我自己整理过一份编码识别和转换清单:
- UTF-8(最常见,文件头无BOM或
EF BB BFBOM):Python用encoding='utf-8'或'utf-8-sig'。 - GBK / GB2312 / GB18030(中文Windows默认):Python用
encoding='gbk'或'gb18030'(gb18030兼容性最好,包含所有中文字符)。 - Big5(繁体中文):Python用
encoding='big5'。 - Shift-JIS(日文):Python用
encoding='shift_jis'。 - Latin-1 / ISO-8859-1(西欧):Python用
encoding='latin1'。
如果不知道CSV是什么编码,用chardet库自动检测:
import chardet
with open(csv_path, 'rb') as f:
raw = f.read(10240) # 读前 10KB 用来检测
result = chardet.detect(raw)
encoding = result['encoding']
confidence = result['confidence']
print(f'{csv_path.name} 编码: {encoding} (置信度 {confidence:.2%})')把检测到的编码传给pd.read_csv(encoding=encoding),能解决80%以上的编码混杂场景。
常见的"转完打开是乱码"问题排查
有时候转换脚本看起来跑通了,但Excel打开转好的xlsx发现中文是乱码。这种情况一般是几种原因之一:
原因一:CSV原始编码识别错。script按UTF-8读,但文件实际是GBK,读进来的就是乱码字符,写xlsx也是乱的。回头确认编码。
原因二:CSV分隔符错。有些CSV用分号;或制表符\t分隔(欧洲地区常见),按逗号读会把整行当成一个字段。Python用pd.read_csv(sep=';')或sep='\t'。
原因三:xlsx文件本身没问题但Excel按系统编码渲染。这种情况罕见,主要发生在Excel 2010及更老版本。把xlsx用WPS或新版Excel打开看是否正常,正常的话就是Excel版本问题。
原因四:CSV末尾有非法字符。有些工具导出的CSV会在文件末尾留下控制字符(\x1A等)或不可见的UTF-8编码异常字节。Python读到这种字符会抛UnicodeDecodeError。在read_csv加errors='replace'参数把异常字符替换掉。
常见问题解答
有没有不用写代码的GUI批量转换工具?
有几个,但稳定性参差不齐。我自己用过靠谱的有:FreeFileViewer的批量转换功能(免费,对小文件量友好);CoolUtils Total CSV Converter(付费,对大文件量稳定);以及Excel的Power Query“从文件夹”功能(前面讲过,零成本但合并成一张表)。如果你预算允许,Total CSV Converter的GUI最完整,支持转换为xlsx、xls、PDF、HTML等多种格式。
转换后Excel数据格式怎么自动设置(日期识别为日期、数字识别为数字)?
在Python脚本里,dtype=str会让所有字段都是文本,不会自动识别。如果你希望自动识别,去掉dtype=str即可——但要承担订单号被科学计数法吞数字的风险。折中方案是手动指定每列的类型:pd.read_csv(csv_path, dtype={'order_id': str, 'amount': float, 'date': str}),关键字段强制类型,其他列自动识别。
怎么处理超大CSV(几个GB)?
用前面讲过的streaming模式,Python的pd.read_csv(chunksize=10000)分块读、xlsxwriter的constant_memory: True分块写。或者更激进的方案是直接跳过Excel格式,把超大CSV转成parquet或HDF5(pandas原生支持),后续分析比xlsx快几个数量级。Excel本身处理几GB的xlsx也是噩梦,所以超大数据建议彻底跳出Excel生态。
Mac或Linux系统能用VBA宏方案吗?
Mac版Office支持VBA但对文件夹批量操作的API有缺陷,建议直接用Python方案。Linux完全没有原生Office,VBA不可用,只能Python或命令行工具。LibreOffice的BASIC宏跟Excel VBA语法相似但不完全兼容,迁移成本高。
转换后xlsx文件太大怎么办?
有两个常见原因:第一,CSV里有大量空白行或空白列被一起转换进了xlsx,转换前先用Python清掉空行空列;第二,xlsxwriter默认开启了样式优化但没开压缩,可以手动指定options={'strings_to_numbers': True, 'use_zip64': True}。一般来说xlsx会比同内容CSV略大15%-30%,超出这个比例就是有冗余数据可以清。
有没有命令行工具直接转换不写代码?
有。csvkit包里的in2csv反向操作可以把xlsx转回csv;libreoffice --headless --convert-to xlsx *.csv能用LibreOffice做无界面批量转换;xlsxio是C写的轻量库,性能极好。我个人倾向Python脚本,因为可以加自定义逻辑(清洗、合并、过滤),纯命令行工具的灵活性差一些。
转换后的xlsx保留了CSV的字段顺序吗?
保留。pandas的read_csv读取时按CSV原始列顺序返回DataFrame,to_excel写入时也按列顺序写。但要注意:如果你的CSV里有重复列名(比如两列都叫"备注"),pandas会自动给第二列加后缀变成"备注.1",这个改名会保留到xlsx里。如果不希望,要在读完之后用df.columns = original_columns手动改回。
权威参考资料
本文标题:《批量CSV转XLSX:4种实战方案与编码避坑》
本文链接:https://zhangwenbao.com/csv-to-xlsx.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0