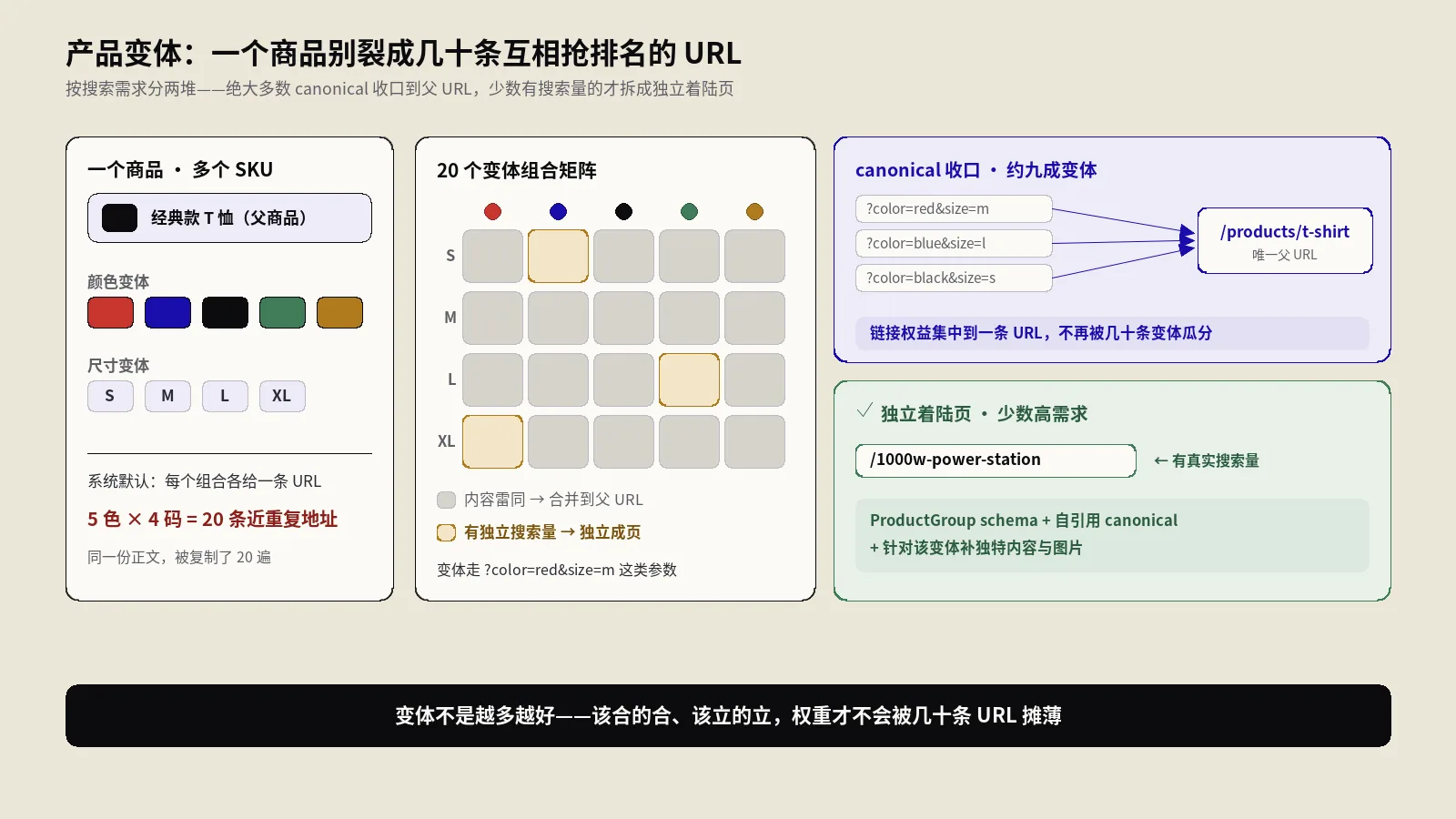
产品变体SEO怎么做?同一商品的几十个URL该合还是该拆
同一件商品的颜色、尺码、容量变体,常被电商系统拆成几十条近重复URL,互相稀释权重、吃抓取预算。本文讲清按搜索需求把变体分两堆:多数用canonical收口父URL,少数有搜索量的才独立成页,附ProductGroup结构化数据与三大平台落地。
标签
保哥笔记 canonical 标签下共 14 篇文章合集,含《产品变体SEO怎么做?同一商品的几十个URL该合还是》《电商重复内容怎么治?8类成因地图加诊断与canoni》《CMS装了SEO插件却冒出两个canonical、两》等,与 技术SEO、重复内容、noindex 主题密切相关,覆盖 SEO/GEO 实战角度的深度解析与可落地方案。
同一件商品的颜色、尺码、容量变体,常被电商系统拆成几十条近重复URL,互相稀释权重、吃抓取预算。本文讲清按搜索需求把变体分两堆:多数用canonical收口父URL,少数有搜索量的才独立成页,附ProductGroup结构化数据与三大平台落地。
电商站几乎天生重复内容成灾,但根子不是被Google罚,而是权重稀释和抓取浪费。本文把产品变体、分面、集合页、分页、参数、样板描述、缺货、跨站这8类电商特有成因画成地图,每类给诊断与治理手法,再配四步诊断工具箱和合并拆分拦截决策树。

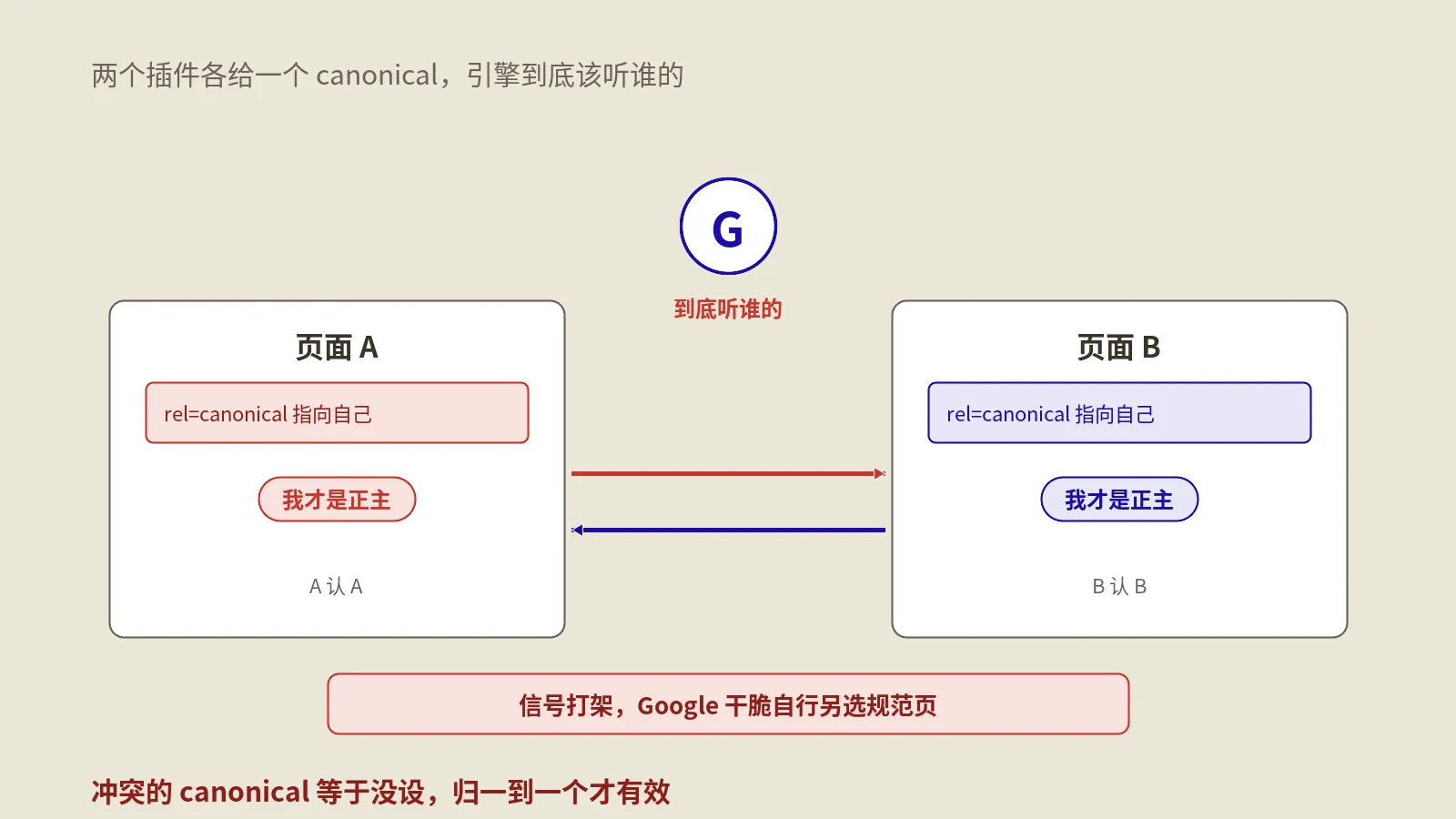
把网站的SEO标签全权交给一个好插件,是很多站长默认的省心做法,可这恰恰可能埋下一个看不见的隐患。在CMS里,主题模板、功能插件、缓存与CDN都有能力往页面头部写入标题、规范链接、社交分享标签和结构化数据,它们彼此并不知道对方的存在,于是同一类标签被写了不止一份,甚至给出互相打架的值。搜索引擎读到这种自相矛盾的信号,常常是只认其中一个、把你真正想生效的那个丢掉,或者干脆都不太当真,你后台辛苦设好的优化就在页面头部被悄悄抵消了。这篇文章手…
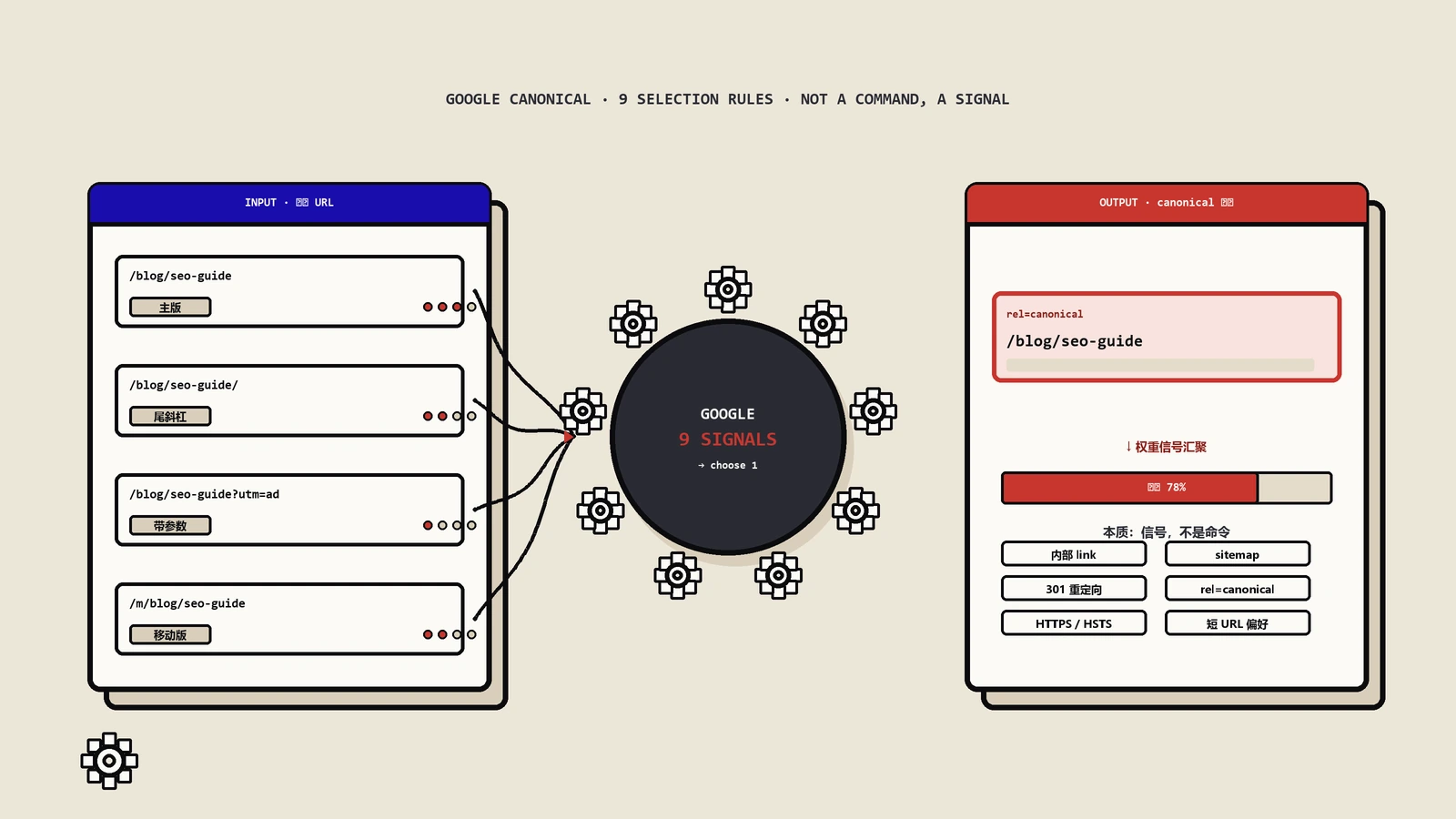
深度解析Google选择Canonical URL的9大核心逻辑,包括精确重复、部分匹配、URL参数推断、移动端版本、渲染失败等场景,附带系统化排查流程与实操修复策略,帮你彻底解决canonical被选错导致的收录和排名问题。
title写了、description也填了,页面SEO就稳了?canonical指错、robots误带noindex这些藏在head里的雷,得靠加权评分一次扫出来。这篇拆透10项权重与扣分逻辑。
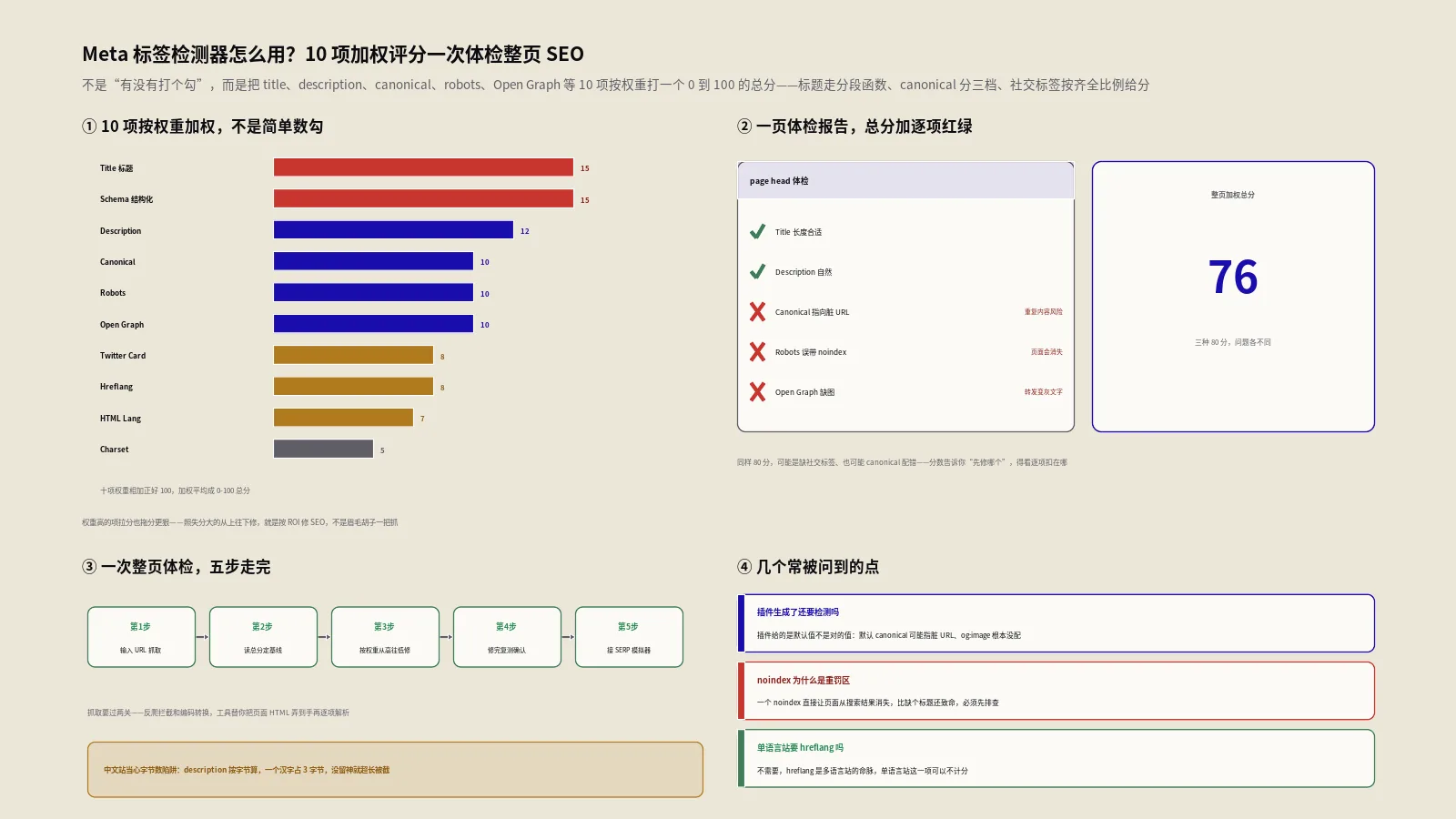
重复页面设了noindex还要不要加Canonical?答案不只是不需要这么简单。本文从Google算法的指令与信号机制出发,拆解两者本质区别、信号冲突的实际后果、John Mueller的最终立场,并按内部重复页、电商参数页、多语言站点、永久迁移等五种场景给出明确决策方案,附Search Console验证流程与8项实操检查清单。
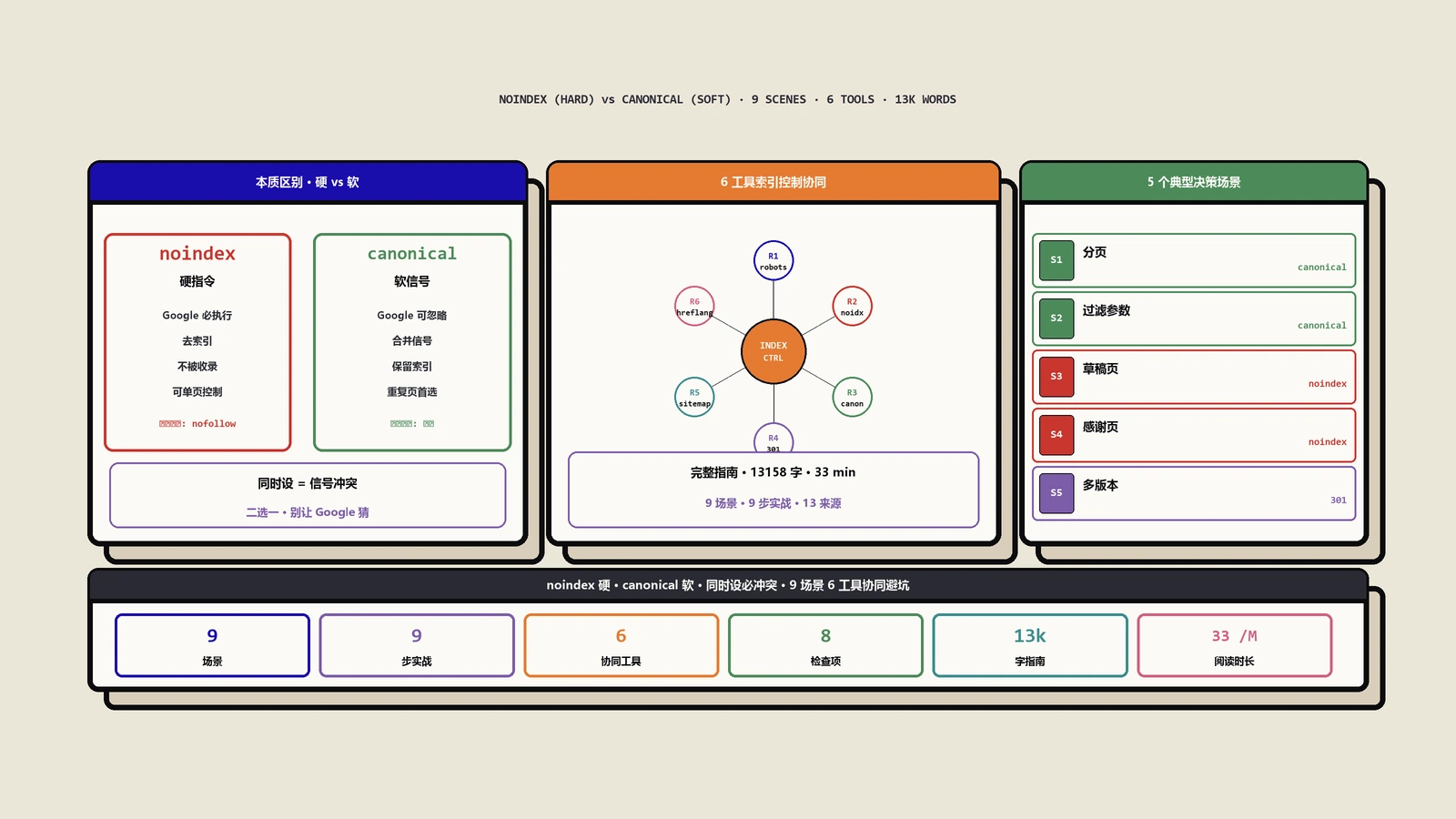
2024年8月谷歌把srsltid参数从Merchant Center扩展到自然搜索结果,导致着陆页URL混乱与GA4数据污染。本文拆解srsltid的工作原理、四类SEO负面影响(重复内容、抓取浪费、数据失真、缓存命中下降),给出canonical标签、Search Console、GA4参数处理、Cloudflare Cache四套应对方案与五个真实踩坑记录。
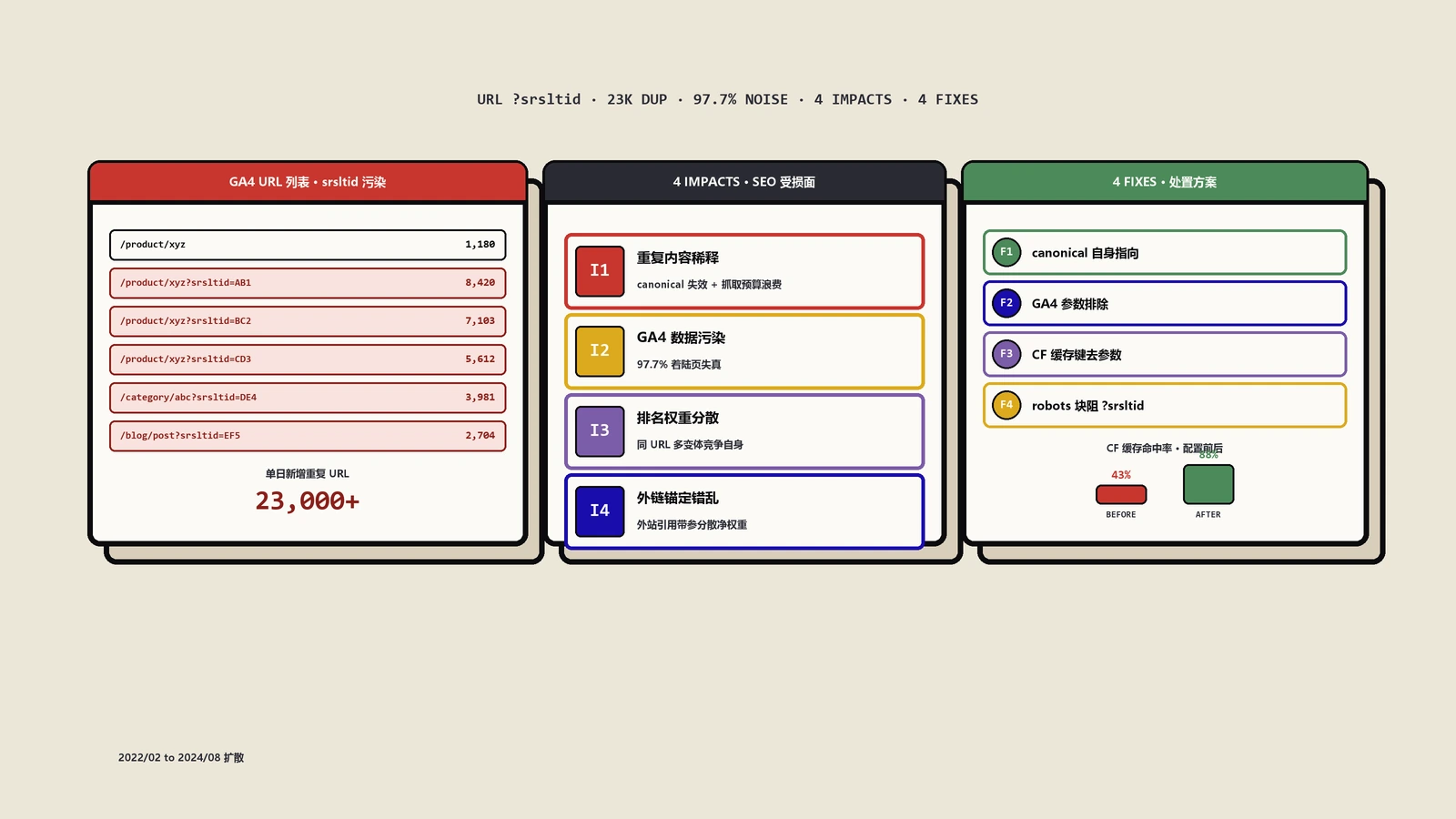
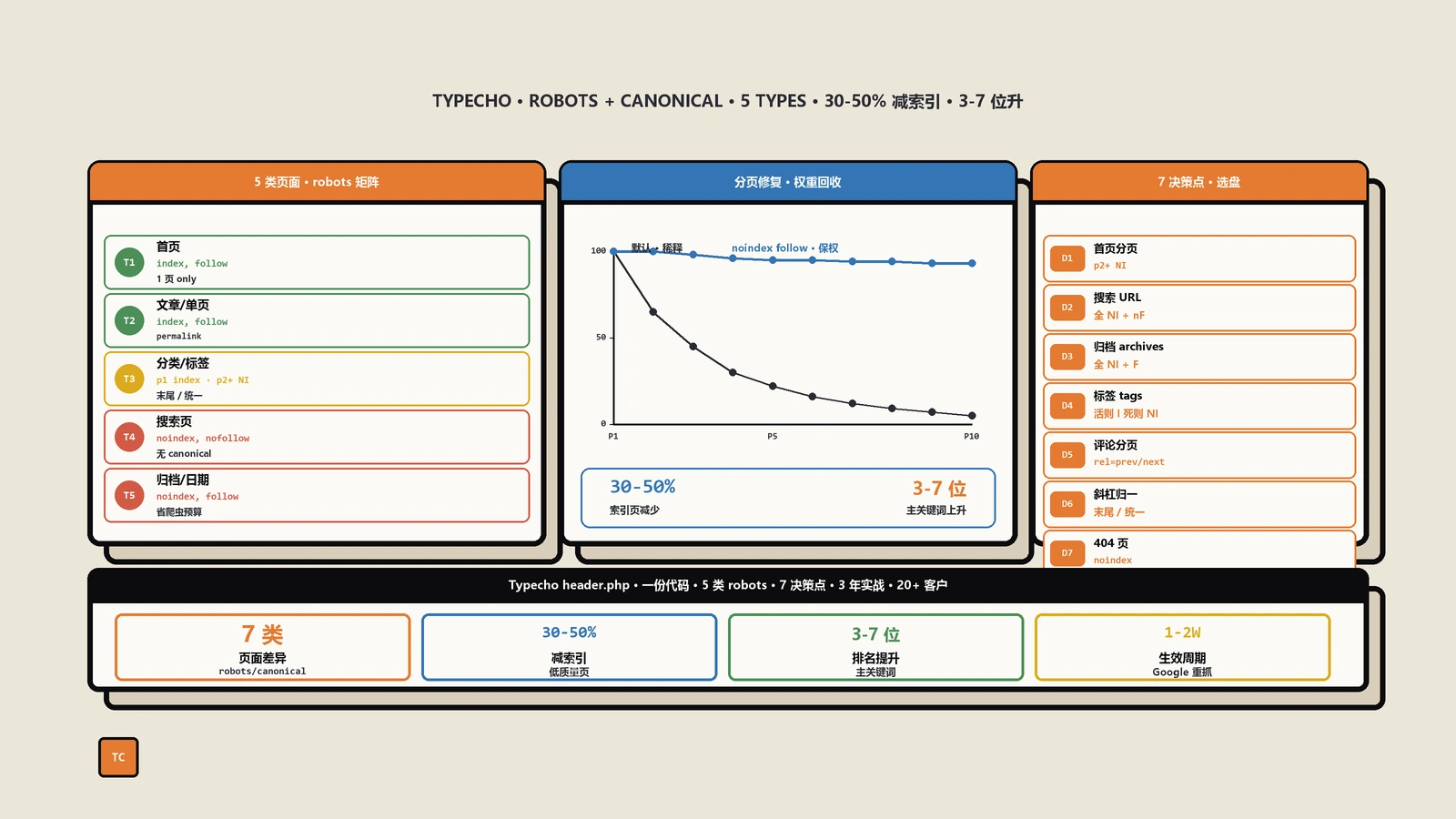
Typecho 默认主题对所有页面统一输出 follow,index 不够精细,导致分页权重稀释、搜索页低质量索引爆炸、归档页占用爬虫预算。本文按首页、文章页、单页、分类页、标签页、搜索页、归档页七种类型给出 meta robots 与 canonical 完整规则代码(基于 getCurrentPage 与 archiveUrl 末尾斜杠归一),可直接粘贴 header.php 立即生效。
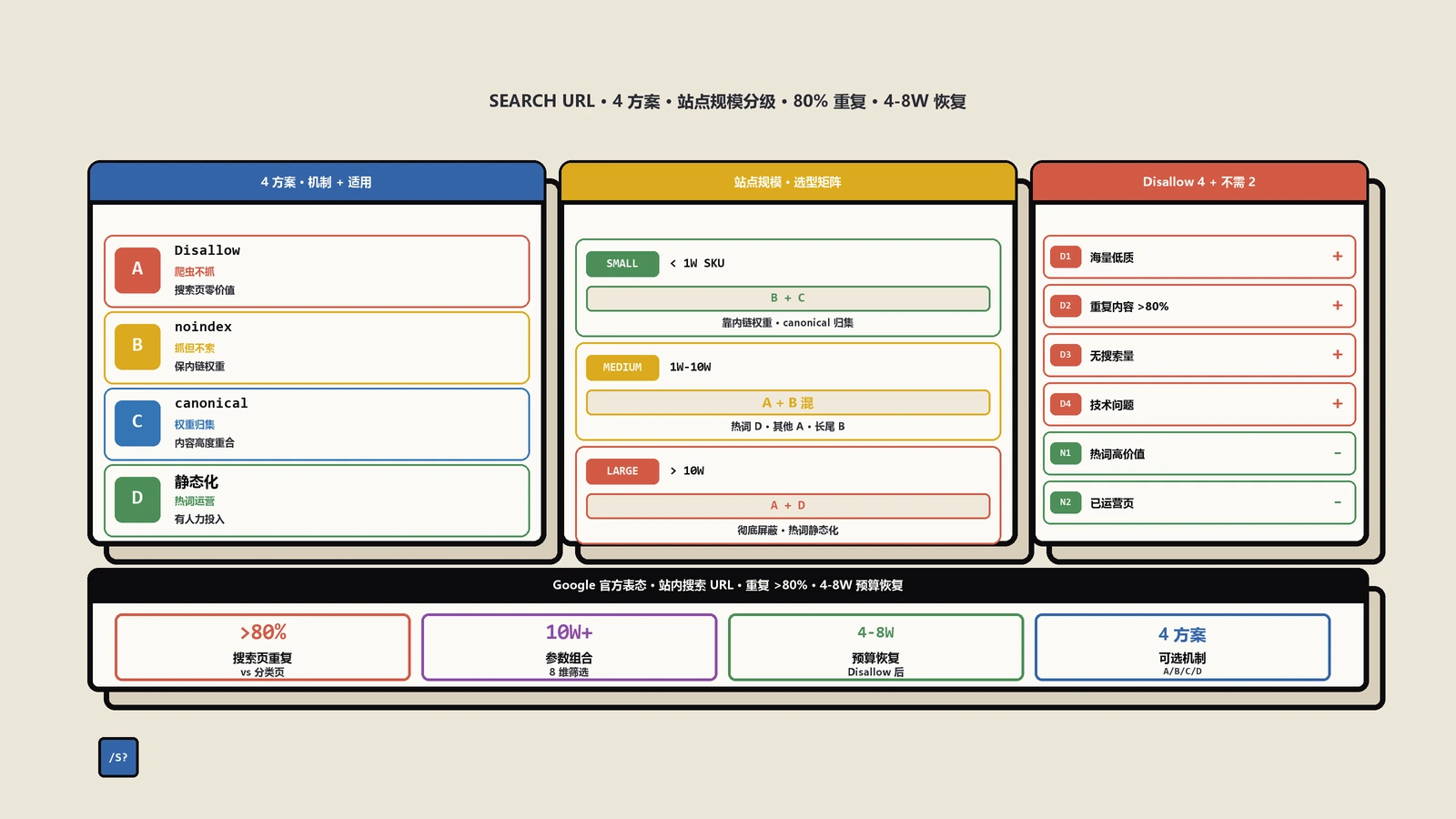
站内搜索页面会产生大量参数化低质 URL,要不要在 robots.txt 里 Disallow?保哥结合 Google 官方表态梳理 4 种处理方案:robots.txt Disallow、meta noindex follow、rel=canonical 归集、URL 静态化运营,并按站点规模给出三档实施清单与典型踩坑回顾。
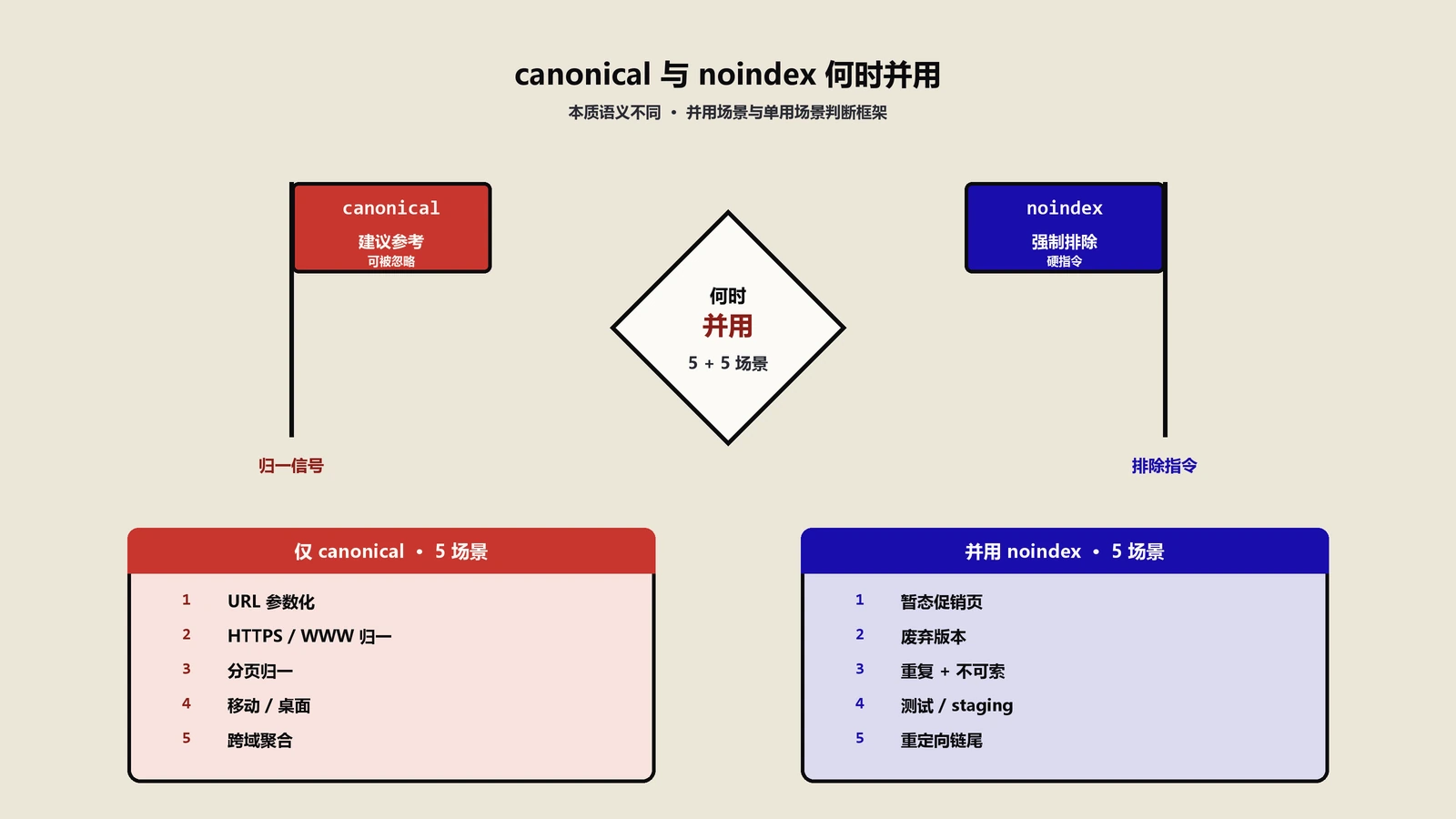
rel canonical 是建议告诉搜索引擎权重归属哪个 URL,meta robots noindex 是命令告诉搜索引擎别索引此页。两者解决的是不同问题不能互相替代。本文给出 5 个仅用 canonical 的场景与 5 个需要叠加 noindex 的场景,配 X-Robots-Tag HTTP 头进阶用法、5 类常见错误避坑、9 项 FAQ。
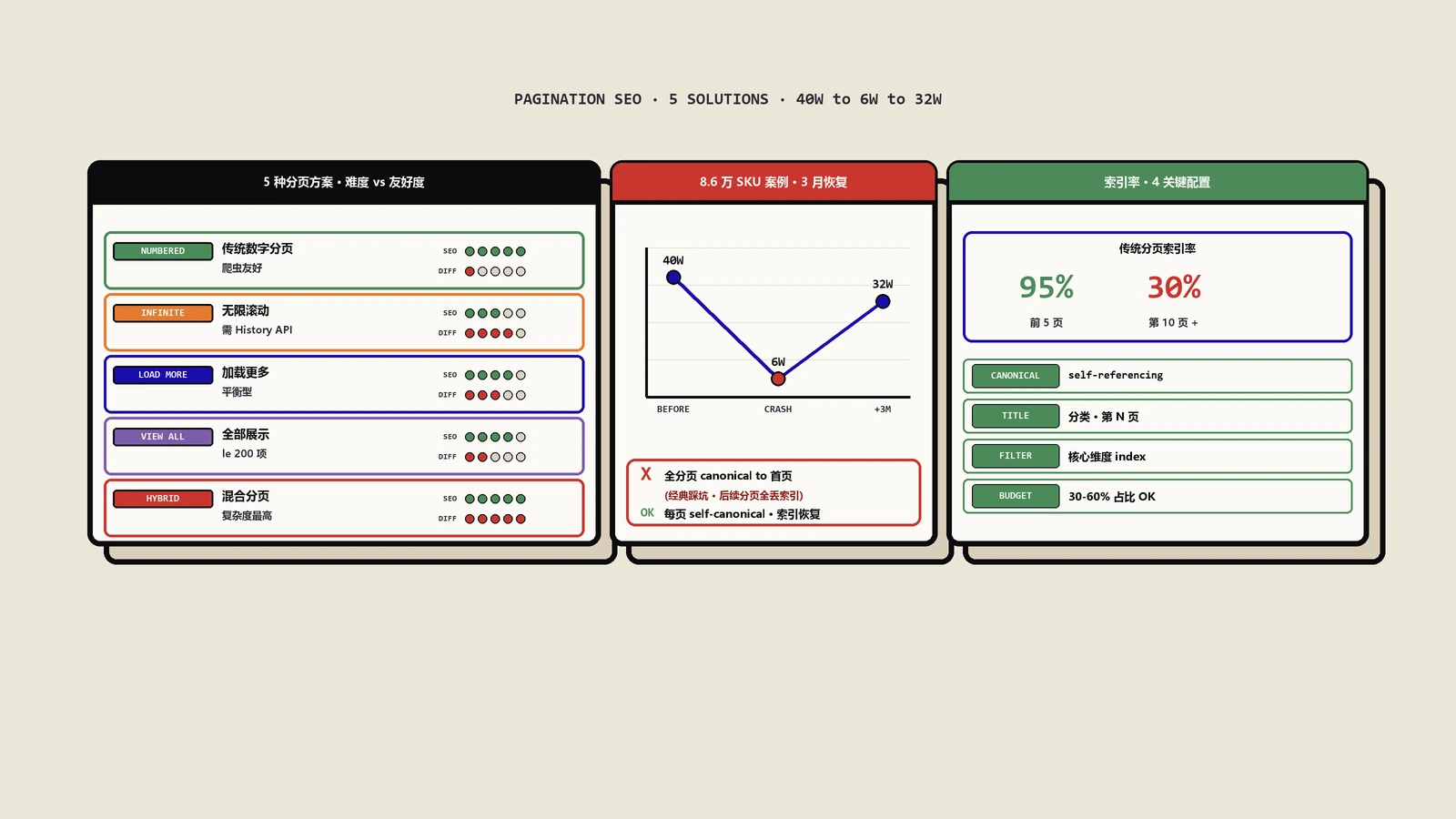
网站分页SEO完整指南:传统数字分页、无限滚动、Load More、View All、混合方案五种实战对比,rel=prev/next废弃后的Canonical配置和Crawl Budget管理,附三个真实修复案例。
A/B 测试用 301 替代 302 让原始 URL 被去索引、把 H1 主关键词换成另一个让排名分裂——这两个真实事故说明产品团队和 SEO 团队对边界认识不一致。本文按抓取一致性、页面速度、URL 结构、排名波动、测试结束清理五层拆解风险,给出 Google Search Central 官方 5 条规则与一份 12 项实操检查表。

HTTPS与HTTP并存、参数化URL、产品变体、分页、筛选器、移动版让Google把同一份内容数到好几份的6类同域场景;canonical/301/noindex/robots/hreflang的决策矩阵、Search Console七步排查清单、出海乐器配件DTC独立站14周治理实战复盘。

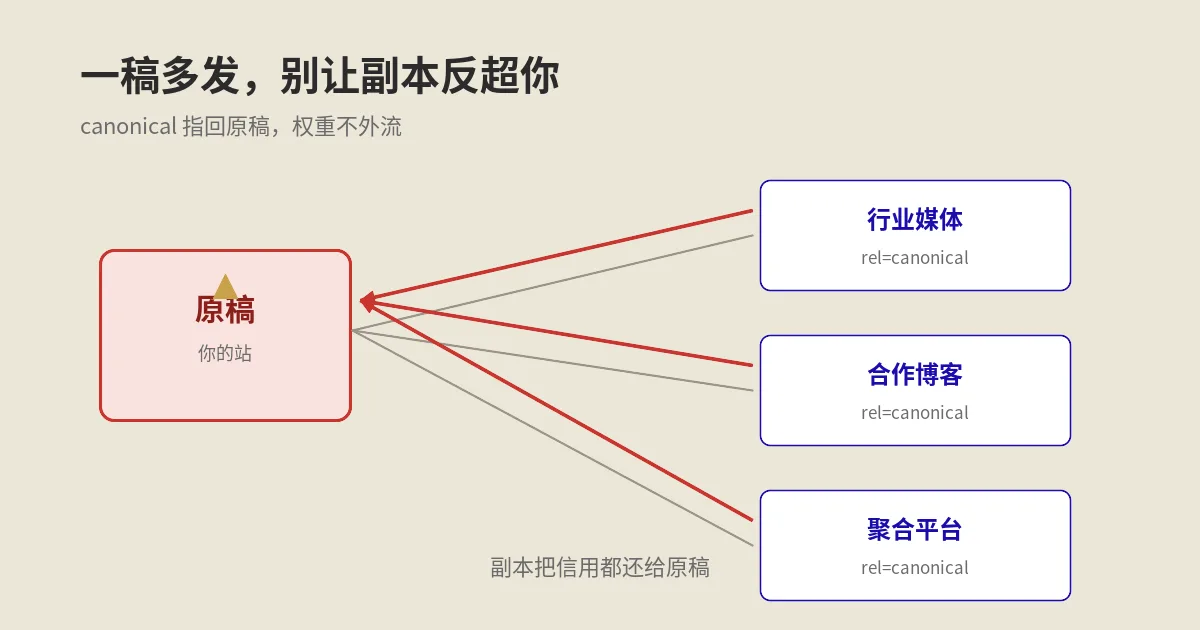
把同一篇内容发到Medium、LinkedIn、行业媒体上,怎么保证搜索流量还算你的?这篇拆解内容联合发布的归并机制、跨域canonical为何会失效、各大平台的不同处理,以及一份可复用的检查清单。