CMS装了SEO插件却冒出两个canonical、两套结构化数据怎么归一?
本文目录
- 为什么装了SEO插件,页面反而冒出两个canonical、两套结构化数据?
- CMS的head区,到底有多少个“主人”在抢着写SEO标签?
- 重复的title和meta description,Google到底听谁的?
- 一个页面出现两个canonical,会发生什么?
- 两套结构化数据同时存在,是加分还是互相拆台?
- 怎么把一个页面到底输出了哪些重复标签,查得明明白白?
- 排查清楚之后,标签的“输出权”该怎么分配归一?
- 把CMS标签冲突的排查归一,收成一张能照着走的清单
- 常见问题解答
- 我只装了一个SEO插件,怎么还会出现重复标签?
- 一个页面有两个canonical标签,Google会怎么处理?
- 两套结构化数据都保留着,是不是等于双保险、更容易拿到富媒体展示?
- 怎么快速判断我的站有没有标签冲突的问题?
- 查出来重复了,到底该关主题那套还是关插件那套?
- 标签归一之后,以后换主题、加插件还会再出问题吗?
- CMS标签冲突最容易踩的5个坑
- 权威参考资料
摘要:不少人做站有个朴素的安全感:装个口碑好的SEO插件,title、描述、canonical、结构化数据这些就都交给它,省心。可保哥在体检客户站时,最常掏出来的一类问题恰恰相反——装了SEO插件之后,页面的head区反而变得更乱了:一个页面冒出两个canonical指向不同地址,两套互相打架的Open Graph标签,甚至同一类结构化数据被重复输出了两遍。
根子在于,CMS的head区不是只有一个主人。主题自带一套SEO输出、SEO插件又来一套、某个功能插件顺手再塞点、CDN或优化插件还可能改写,几股力量各写各的,谁也不知道谁,最后在head里撞成一团。Google面对自相矛盾的信号,要么挑一个它认为对的、忽略你真正想要的,要么干脆都打折扣。
这篇专讲怎么把这摊看不见的乱账查清楚、理顺:从head区到底有几个主人、重复的title和canonical会怎样、两套schema是加分还是拆台,一路讲到怎么排查、怎么把标签的输出权重新分配归一。
为什么装了SEO插件,页面反而冒出两个canonical、两套结构化数据?
做站的人对SEO插件大多有种托管式的信任:装一个口碑好的,把title、描述、canonical、Open Graph、结构化数据这些都交给它,从此省心。这种信任不能说错,但它掩盖了一个被严重低估的风险——插件接管SEO标签,不等于别人就不再写这些标签了。
保哥给客户站做SEO体检,最高频挖出来的问题之一,恰恰是装了SEO插件之后head区反而更乱。打开源代码一看:一个页面里两个rel=canonical指向不同地址,两套互相打架的Open Graph,同一类结构化数据被输出了整整两遍。站长本人往往一脸错愕——我明明装了专业插件,怎么会这样?
答案是CMS的head区从来不是一个人说了算的地盘。主题模板可能自带一套SEO输出,SEO插件又来一套,某个功能插件顺手再塞几个标签,性能优化插件或CDN甚至会在传输层改写。这几股力量互不知情、各写各的,最后在head里撞成一团。你以为装了插件就一统江湖,实际上只是往本就拥挤的房间里又请进了一位强势的客人。
这类问题之所以危险,是因为它隐蔽。页面前端看着一切正常,排名却莫名其妙上不去或者掉了,你查了内容、查了外链,就是想不到问题出在head区那几行你从没正眼看过的标签上。它属于那种典型的隐性失分,跟保哥在独立站CMS第一年SEO隐性失分排查那篇里讲的那批坑是一个性质——不致命,但持续阴你。这篇就专门把标签冲突这一类查清、理顺。
CMS的head区,到底有多少个“主人”在抢着写SEO标签?
要解决冲突,先得知道冲突从哪来。把CMS的head区想象成一块公告栏,问题是这块公告栏的钥匙,不止一个人手里有。保哥把常见的标签来源梳理一遍,你就明白为什么重复几乎是必然的。
第一个主人是主题。很多主题为了显得功能完整、卖相好,会内置一套自己的SEO输出:自动生成title、写meta description、输出Open Graph给社交分享用,讲究点的还自带一段结构化数据。这套输出在你没装任何插件时是有用的,可一旦你装了专门的SEO插件,它就成了重复的源头,而大多数主题默认不会自动让位。
第二个主人是SEO插件本身。这是你主动请来管SEO的,它会系统地输出title、canonical、各类meta、Open Graph、Twitter Card、结构化数据。它干得越全,和主题那套撞车的面积就越大。第三个主人是各种功能插件。社交分享插件可能自带Open Graph,电商、评分、食谱、活动类插件常常输出自己的结构化数据,多语言插件会插hreflang,它们各管一摊,却都往同一个head里写。
第四个主人藏得最深——性能优化插件和CDN。有些缓存、优化插件或CDN会在输出层对HTML做处理,可能改写、合并甚至重复某些标签。这类来源最难排查,因为它发生在你后台设置之外。不同CMS、不同生态,这几个主人的活跃程度不一样,这也是为什么平台选型会实实在在影响你的SEO维护成本,保哥在CMS选型与SEO差异那篇里横评过不同平台的差异。但无论哪个平台,只要head区有多个互不知情的写入者,重复和冲突就是迟早的事。
保哥真做过一次排查,一个看着很普通的博客站,文章页的head里居然能数出四个标签来源:主题输出了title和一套Open Graph,SEO插件输出了全套,一个分享插件又塞了自己的Open Graph,还有个相关文章插件偷偷加了段结构化数据。站长全然不知,只觉得站点收录一直不温不火。四个来源各写各的,光Open Graph就有两套在打架。这种情况绝不是个例,反而是疏于体检的站的常态。
重复的title和meta description,Google到底听谁的?
先从最常见、后果相对温和的一类说起——重复的title和meta description。当主题和插件都输出一份title标签、一份description,head里就有了两份,问题是Google会怎么对待。
title标签理论上一个页面只该有一个。当出现两个时,Google一般会选择其中一个作为页面标题来理解和展示,通常是按它在HTML里出现的顺序或它判断的有效性来取舍,但它选哪个并不完全受你控制。如果两份title内容还不一样——比如主题生成的是文章标题加站名,插件生成的是你精心优化过的SEO标题——那么Google可能用了那个你没优化的版本,你在插件里下的功夫就白费了。
meta description的情况类似。两份描述同时存在,Google要么挑一个,要么干脆都不用、自己从正文里抓一段。无论哪种结果,你想通过description影响搜索结果摘要、提升点击率的意图都落了空。这不是会不会被惩罚的问题,而是你的优化指令因为有了竞争者而失效的问题。
这类冲突的后果虽然不像canonical那么致命,但它日复一日地让你的标题和摘要优化打折扣,是一种持续的隐性浪费。判断方法很简单:看源代码数一下title和meta description各有几个,超过一个就该归一。理顺它,等于把标题和摘要的控制权重新攥回自己手里,让你在插件里设的每一个字都真正生效。
保哥碰到过一个很典型的例子。一个客户在SEO插件里把文章标题精心改成了前置核心词的版本,上线后却发现搜索结果显示的还是老样子——标题后面硬拖着一长串站点名。查源代码才发现,主题在插件之前也输出了一个title,Google取了主题那个。客户在插件里下的所有功夫,被主题一个没人注意的默认输出整个盖掉了。把主题的title输出一关,插件版本立刻生效,搜索结果当天就开始变。这种白忙一场,根子全在那个被忽略的重复标签上。
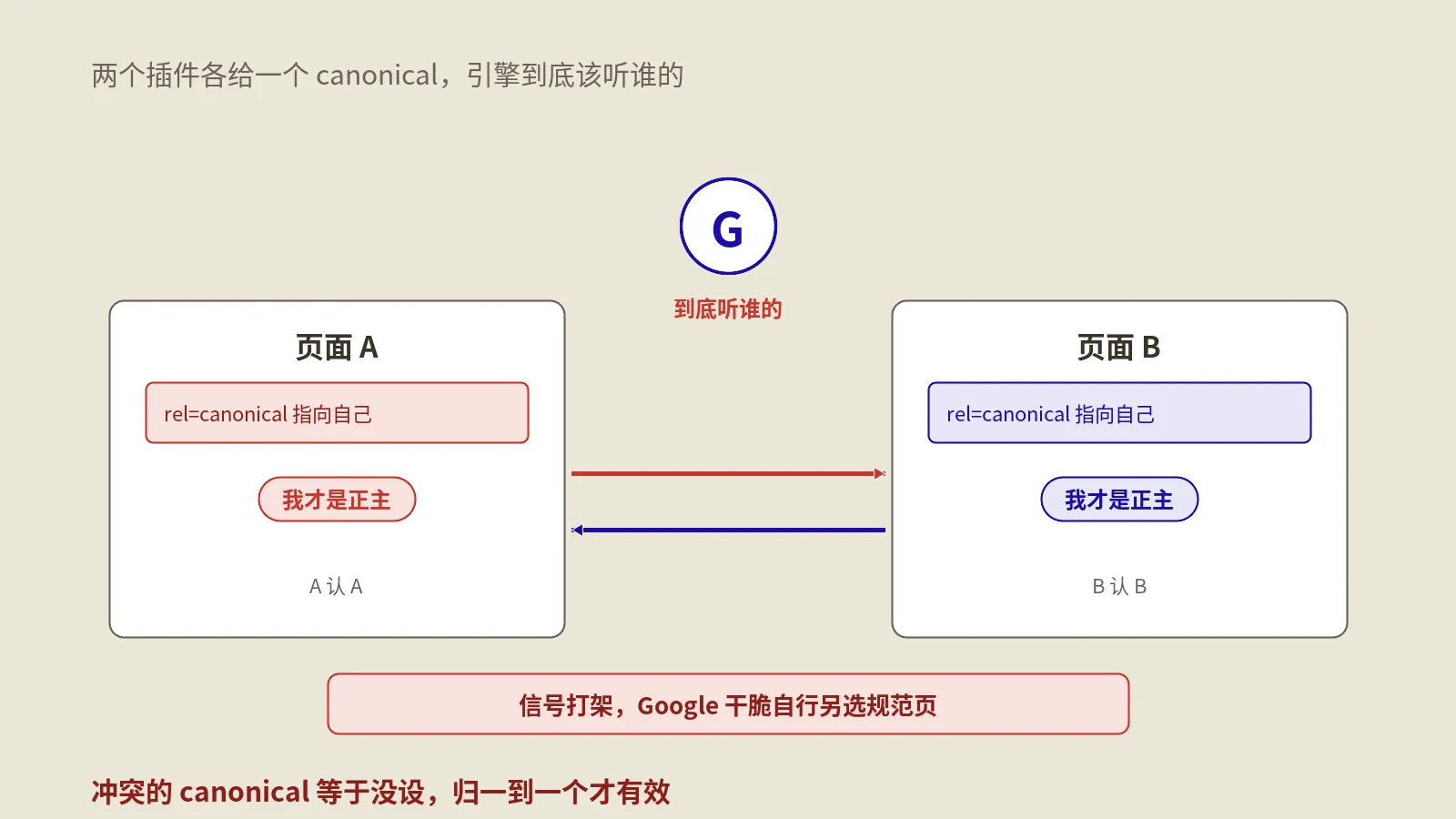
一个页面出现两个canonical,会发生什么?
如果说重复title是温和的浪费,那重复canonical就是标签冲突里的头号杀手,必须最优先处理。因为canonical直接干预Google的索引和归并决策,它出错,伤的是收录和排名的根。
canonical的职责,是告诉Google这个页面的规范版本是哪个URL。一个页面正常只该有一个canonical,指向它自己(或它真正的规范地址)。当head里冒出两个canonical、还指向不同地址时,你等于同时给了Google两条互相矛盾的指令。Google面对这种自相矛盾,往往会判定这个canonical信号不可信。
它的处理可能有几种,没有一种是好结果。它可能忽略掉你的canonical、退回到自己的判断;可能两个里挑一个,而挑中的偏偏是错的那个;最坏的情况是那个错误的canonical指向了别的页面,导致你这个页面被归并、不再单独索引,排名和流量当场受损。更阴险的是,有些主题或插件会默认把canonical错误地指向首页或某个固定页,你不翻源代码永远发现不了,只觉得页面莫名不收录。
canonical和noindex这些索引控制标签之间的配合本身就有不少讲究,搭配不当同样会出乱子,保哥在noindex与canonical能同时设吗那篇里专门拆过它们的组合场景。回到重复问题上,结论很硬:每个页面必须有且只有一个canonical,且指向正确的自身规范地址。遇到canonical重复,这是整个标签归一里优先级最高、最不能拖的一项,查到了就要立刻收敛掉多余的那个。
两套结构化数据同时存在,是加分还是互相拆台?
结构化数据这块,藏着一个很普遍的误解:很多人觉得结构化数据是加分项,那主题一套、插件一套都留着,岂不是双保险、更容易拿富媒体展示?实际上恰恰相反,两套并存更可能互相拆台。
问题分几种。最常见的是字段冲突:主题输出的Article和插件输出的Article,发布时间、作者、标题、图片对不上,Google读到两份矛盾的描述,对这页的理解反而乱了。其次是类型冗余:同一个实体被描述两遍,模糊了页面真正的主类型,让Google拿不准这页到底以什么为主。还有的是其中一套标记本身不规范、字段缺失或填错,拖累整体可信度。
Google在Google搜索中心 — General Structured Data Guidelines(结构化数据须真实代表页面内容、标注页面主类型与一致性要求)里讲得很清楚:结构化数据必须真实代表页面内容,要清楚标出页面的主类型。自相矛盾或冗余的标记,不但拿不到富媒体加分,还可能因为不符合规范而被忽略,严重的会影响信任。结构化数据从来不是越多越保险,而是准确、一致、不矛盾才有价值。
正确做法不是都留着求心安,而是只保留一套准确、完整、和页面内容一致的结构化数据,把另一套干净地关掉。至于保留哪套,看哪套字段更全、更贴合页面真实内容,通常专门的SEO插件比主题顺手塞的那套更规范,但务必逐页用测试工具验证后再定。结构化数据本身怎么配合SEO系统地做,保哥在结构化数据完整指南那篇里有整套方法,这里强调的是先解决有没有打架,再谈做得好不好。
举个常见场景。一个用WordPress做的电商站,主题自带商品结构化数据,又装了个评分插件也输出一套带评分的Product标记,两套的价格、库存、评分字段还对不上。结果富媒体测试里一堆警告,商品的富媒体结果时有时无。保哥的处理是把主题那套关掉,只留插件那套并补全字段,验证通过后展示才稳定下来。两套看似都在帮忙,实际是在让Google反复犹豫到底信谁,远不如一套干净准确的来得管用。
怎么把一个页面到底输出了哪些重复标签,查得明明白白?
道理讲透了,落到操作上,排查其实不难,关键是养成去看页面真实输出的习惯,而不是只盯着后台设置想当然。保哥给一套零成本就能上手的排查流程。
第一步,看网页源代码。在浏览器里打开一个重要页面,右键选查看网页源代码,调出原始HTML。注意是看源代码,不是看开发者工具里被JS改造过的DOM,因为SEO标签大多在原始HTML的head区,看源代码最真实。
第二步,在head区逐项数标签。用页面内查找功能,依次搜这几个关键词:搜canonical,看rel=canonical出现几次、分别指向哪;搜og:title或og:,看Open Graph是不是成套重复;搜ld+json,看结构化数据有几块;再看title标签、meta name等于description各有几份。正常每一类都该只出现一次,出现两次及以上就是冲突。
第三步,用富媒体结果测试工具验证结构化数据。把页面丢进Google的富媒体结果测试,它会列出识别到的结构化数据类型,有没有重复、报错一目了然。第四步,多类页面分别查。首页、文章页、分类页、产品页的标签来源和冲突往往不一样,别只查一个页面就下结论,每种核心页型都抽一个查。走完这四步,哪些标签重复、各重复几次、大概来自主题还是插件,你心里就有一张清楚的账,归一才有依据。
如果站点页面很多,一个个手动看源代码不现实,可以借助全站爬虫类的审计工具批量抓取,让它统计每个页面canonical、title这些标签的数量,把出现多个的页面挑出来重点处理。但工具跑出来的结果,关键页面还是建议人工再看一眼源代码确认,因为有些动态注入的标签自动化工具未必抓得全。手动看懂一个页面的真实输出,是用任何工具前都该先具备的基本功。
排查清楚之后,标签的“输出权”该怎么分配归一?
查清了重复,最后一步是归一——把每一类标签的输出权,从混乱的多头收敛到唯一一个负责人。这一步的核心原则只有一句:每一类标签,只保留一个最专业、最可控的来源,其余全部关掉。
怎么分配,看哪个来源做得更规范、更好维护。一般来说,title、meta description、canonical、Open Graph、结构化数据这些核心SEO标签,专门的SEO插件通常比主题顺手塞的那套做得更完整、更可控,建议统一交给SEO插件,然后去主题的设置面板或模板代码里,把它自带的那套SEO输出关掉或移除。当然也有例外,某个主题的某类输出如果反而更合你的需求,那就反过来关插件那部分。
关的时候会遇到难处理的情况。有些主题没提供关闭SEO输出的选项,那可能得改主题模板代码、用子主题覆盖对应部分,或者用平台提供的过滤钩子把多余的标签移除。功能插件塞的结构化数据、社交插件塞的Open Graph,也要逐个找到它们的设置项关掉冗余。
这里还要留意一类特殊情况——robots、noindex这类索引指令万一也出现矛盾,Google的规则是以更严格的那条为准。Google在Google搜索中心 — Robots meta标签、data-nosnippet与X-Robots-Tag规范(冲突指令时以更严格的规则生效)里说明,冲突指令下更严格的规则生效,这意味着一个误加的noindex可能盖过你想要的收录,归一时这类指令尤其要查清。
归一做完,给自己定个验收标准:拿任意一个页面,每一类标签都能干脆地回答出它由谁负责、唯一来源是谁。
多个canonical怎么收敛到一个、Google怎么处理规范化信号,可以对照Google在Google搜索中心 — How to specify a canonical URL with rel="canonical"(规范化方法与多个canonical信号的处理)里的方法说明来确认你的处理是对的。当head区每一类标签都只有一个明确的主人,你的SEO优化指令才不会在内部互相抵消,真正传达到Google那里。
把CMS标签冲突的排查归一,收成一张能照着走的清单
讲了这么多,保哥把整套排查归一压成一张清单,你照着从上往下走一遍,基本就能把head区那摊乱账理清楚。
| 标签类型 | 正常应有数量 | 冲突后果 | 归一去向 |
|---|---|---|---|
| title | 1个 | Google可能用了没优化的那份 | 统一交SEO插件,关主题输出 |
| meta description | 1份 | 摘要优化失效或被忽略 | 统一交SEO插件 |
| canonical | 1个(指向自身规范) | 最致命:归并错位、丢收录 | 最优先收敛到唯一正确来源 |
| Open Graph | 1套 | 社交分享卡片错乱 | 留一套,关社交/主题冗余 |
| 结构化数据 | 1套准确的 | 字段矛盾、主类型模糊、失资格 | 留最规范的一套,关其余 |
| robots/noindex | 无矛盾 | 更严格规则生效,可能误屏蔽 | 清查矛盾指令,确认无误加 |
这张表的逻辑就一条主线:head区的每一类标签,都该有且只有一个明确的负责人。查的时候按这张表逐项数数量,归一的时候按这张表逐项定去向,乱账就理清了。难的从来不是技术,而是你愿不愿意低下头去看那几行从没正眼瞧过的源代码。
最后提醒一句,标签归一不是一劳永逸的。CMS站的标签输出是动态的,你每换一次主题、每加一个插件、每做一次大版本升级,head区的格局都可能被重新洗牌,原本理顺的又被搅乱。所以把查看源代码、核对标签唯一性这件事,做成每次改动后的固定检查工序,像回归测试一样跑一遍。花不了几分钟,却能让你辛苦理顺的head区不会在某次不经意的改动后又悄悄变回一团乱麻。把它摁成习惯,这类隐性失分就能长期不再找上门。
常见问题解答
我只装了一个SEO插件,怎么还会出现重复标签?
因为SEO插件不是head区唯一的写入者,最常见的重复来源是它和你的主题撞了车。很多主题为了显得功能完整,自己就内置一套SEO输出——写title、输出Open Graph、甚至自带结构化数据。你再装一个SEO插件,插件也写这些,主题那套却没关,两套就同时挤在head里。除了主题,一些功能插件也会顺手注入,比如社交分享插件输出一套Open Graph,电商或评分插件输出自己的结构化数据。所以哪怕只装一个SEO插件,只要主题或其他插件没把各自的SEO输出关干净,重复就会发生。排查第一步永远是直接看页面源代码,数一数title、canonical、og:title、结构化数据各出现几次,先确认重复真实存在、来源是谁,再谈归一。
一个页面有两个canonical标签,Google会怎么处理?
这是标签冲突里后果最严重的一种,要优先排查。canonical的作用是告诉Google页面的规范版本是哪个URL,直接影响索引和归并决策。当一个页面出现两个canonical、指向不同地址,你等于给了Google两条矛盾指令。Google通常会把这种自相矛盾的信号判为不可信,要么忽略、退回自己判断,要么挑一个,而挑的那个未必是你要的。最坏的情况是错误的canonical指向了别的页面,导致你这页被归并、不再单独索引,排名流量直接受损。更隐蔽的是有些主题或插件会把canonical默认指向首页或固定页,你不查源代码根本发现不了。所以遇到canonical重复别犹豫,必须收敛到每页有且只有一个、指向正确自身规范地址,这是标签归一里优先级最高的一项。
两套结构化数据都保留着,是不是等于双保险、更容易拿到富媒体展示?
不是双保险,更可能是互相拆台。结构化数据不是越多越保险,关键是准确、一致、不矛盾。主题和插件各输出一套,常见问题有两种:一是字段冲突,两套Article的发布时间、作者、标题对不上,Google读到矛盾信息,对这页的理解就乱了;二是类型冗余,同一个实体被描述两遍,模糊了页面主类型。Google的结构化数据指南强调标记必须真实代表页面内容、清楚标出主类型,自相矛盾或冗余的标记不仅拿不到富媒体加分,还可能因不符规范被忽略。正确做法不是都留着求保险,而是只留一套准确、完整、与页面一致的,另一套关掉。保留哪套看哪套字段更全、更贴合内容,通常SEO插件比主题顺手塞的更规范,但也要逐页用测试工具验证后再定。
怎么快速判断我的站有没有标签冲突的问题?
最直接、零成本的办法是看页面源代码。浏览器里打开一个重要页面,右键查看网页源代码,在head区用查找功能依次搜几个关键标签:搜canonical看出现几次、搜og:title看Open Graph是否成套重复、搜ld+json看结构化数据有几块、再看title和meta description是否只有一份。正常每一类只该出现一次,两次及以上就是冲突。结构化数据还可以用Google富媒体结果测试工具跑一遍,看识别出哪些类型、有没有重复报错。查的时候多选几种页型分别看——首页、文章页、分类页、产品页的来源和冲突可能不一样。这几步走完,哪些标签重复、各几次、大概来自主题还是插件,心里就有数了,接下来才谈得上对症归一。
查出来重复了,到底该关主题那套还是关插件那套?
原则是每一类标签只保留一个最专业、最可控的来源,其余全关掉,而不是一刀切地一律留插件或留主题。具体看哪个来源更规范、更好维护。一般来说title、description、canonical、Open Graph、结构化数据这些核心标签,专门的SEO插件通常比主题顺手塞的更完整可控,建议统一交给插件,再去主题设置或代码里把它自带那套关掉。也有例外,某主题的某类输出更贴合需求,就反过来关插件那部分。关键是做完决定后,每一类标签都能明确回答:现在由谁负责、唯一来源是谁。关不掉的情况也有,有些主题没给关闭选项,那得改主题代码、用子主题覆盖或用过滤钩子移除多余输出。归一的本质就是把每类标签的输出权,从多头收敛到唯一一个负责人。
标签归一之后,以后换主题、加插件还会再出问题吗?
很可能会,所以归一不是一锤子买卖,而要变成一道固定的检查工序。CMS站的标签输出是动态的,你每换一次主题、每加一个插件、每做一次大版本升级,head区的格局都可能被重新洗牌——新主题又自带一套SEO输出,新插件又塞进结构化数据或Open Graph,原本理顺的就被打破。所以正确心态是把查看源代码、核对标签唯一性,纳入每次换主题、装插件、升级后的标准检查,像回归测试一样做。改动之后挑首页和几类核心页面,重走一遍数标签的流程,确认canonical、title、结构化数据还是各自唯一、没被新成员搅乱。这套检查花不了几分钟,却能避免你理顺的head区在某次改动后又悄悄变回乱麻而毫不知情。做成习惯,标签冲突这类隐性失分就能长期被摁住。
CMS标签冲突最容易踩的5个坑
照例收尾,把保哥见过最高频的5个坑摆出来,对照自查,每一个都在悄悄抵消你的SEO努力。
坑一:以为装了SEO插件就一统江湖,从不看源代码。插件接管不等于别人不写了,主题和功能插件那几套往往还在。不亲眼数一遍head区的标签,你永远不知道它有多乱。
坑二:放任两个canonical共存。这是最致命的。canonical矛盾会让Google判信号不可信,轻则忽略、重则归并错位丢收录。每页必须有且只有一个、指向正确自身地址,这项优先级最高。
坑三:把两套结构化数据都留着当双保险。不是双保险是互相拆台,字段矛盾、主类型模糊反而失去富媒体资格。只留一套准确一致的,另一套干净关掉。
坑四:只查一个页面就以为全站没事。首页、文章页、分类页、产品页的标签来源和冲突往往不同。每种核心页型都要抽样查,别用一个页面的结论盖全站。
坑五:归一一次就再不管,换主题加插件后又乱了。标签输出是动态的,每次改动都可能重新洗牌。把核对标签唯一性做成改动后的固定检查,才能长期摁住。
这5个坑串起来其实是一个意识问题:你在后台设置里以为做好的优化,和页面head区真正输出给Google的东西,未必是一回事。SEO做到一定程度,拼的不只是你设了什么,更是你设的东西有没有干净、无矛盾地传达出去。把标签冲突这摊看不见的乱账查清理顺,让每一类标签都只有一个主人,你之前所有的SEO努力才不会在自家head区里被悄悄抵消掉。这活儿不起眼,却是把优化效果真正落地的最后一公里。
权威参考资料
本文标题:《CMS装了SEO插件却冒出两个canonical、两套结构化数据怎么归一?》
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0