URL结构怎么写AI才引用?4家LLM对照5原则+实测
本文目录
- 为什么AI检索系统读URL的方式和传统爬虫不一样
- tokenizer怎么拆URL是个常被忽略的细节
- RAG管道里URL在哪一步起作用——3个关键节点
- 爬取与chunk化阶段
- 检索与重排阶段
- 生成与citation阶段
- 不同AI引擎对URL的差异化处理:4家对照
- ChatGPT browsing的URL处理细节
- Perplexity的URL处理细节
- Gemini的URL context grounding
- Claude computer use的URL处理
- URL作为semantic signal的5个核心原则
- 浅层级——3层是甜区
- 人可读——slug每段都要有自然语言含义
- 对齐搜索意图——slug比关键词更具体
- 一致命名——同类内容用同一个category
- 避免堆关键词——一个slug一个主关键词
- WordPress / Shopify / 自建站的URL改造实操路径
- WordPress——5种permalink配置实测
- Shopify——强制层级的应对策略
- 自建站(Laravel/Django/Next.js)——灵活但容易过度设计
- 多语种站hreflang URL结构对AI检索的影响
- Subdirectory方案的细节
- ccTLD方案的特殊考虑
- URL重构的301实施步骤+回退方案
- 改造前的高价值URL审计
- 301映射 + canonical双保险
- 监控周期与回退触发条件
- 实测对比:6种URL结构在AI引擎引用率差异
- 常见问题解答
- 已经上线的旧URL要全部重构吗
- URL slug用中文还是英文好
- URL改造对backlink权重影响多大
- 动态参数URL(?utm_source=xxx)会影响AI citation吗
- SPA单页应用的URL怎么优化AI检索
- URL结构改造多久能看到AI citation变化
- URL层级深一层真的差那么多吗
- URL改造和H1/title改造哪个对AI检索影响更大
- 权威参考资料
摘要:AI检索系统读URL的方式和传统爬虫完全不同——slug经tokenizer进入embedding空间。本文拆解RAG管道里URL在哪三个关键节点起作用、四家LLM对URL的差异化处理、URL作为语义信号的五个核心原则、六种URL结构实测的引用率对照,再给各CMS的改造路径、多语种hreflang的影响和301实施步骤。
一个北美SaaS客户去年问过一句话:"我们站的URL都按Ahrefs老规则做了——短、有keyword、连字符分隔——为什么Perplexity从来不引用?"挖下去发现问题不在URL"对不对",是在AI检索系统读URL的方式跟传统Googlebot完全不同。tokenizer怎么切path segment、URL怎么进embedding空间、4家LLM引擎对深层URL的偏好差异——2026年这些URL设计要点跟过去十几年的SEO教科书完全是两套逻辑。
这篇是保哥手头三个项目实战后的整理——一个北美户外DTC(Shopify强制4级层级)、一个北美SaaS内容站(WordPress从 /blog/YYYY/MM/post改为 /resources/topic/post)、一个简体中文出海站(自建Laravel + hreflang多语种)。把AI检索系统怎么读URL、各家AI引擎差异、5个落地原则、6种URL结构在4家AI引擎引用率实测对比都写透。
为什么AI检索系统读URL的方式和传统爬虫不一样
传统搜索爬虫(Googlebot、Bingbot)有二十多年的爬取索引基础设施沉淀——能跟301重定向链、解析canonical、执行JavaScript、从页面正文反推上下文。就算URL是/p?id=4821这种毫无语义的字符串,Googlebot也能从页面H1、meta、内链结构里把语义补回来。
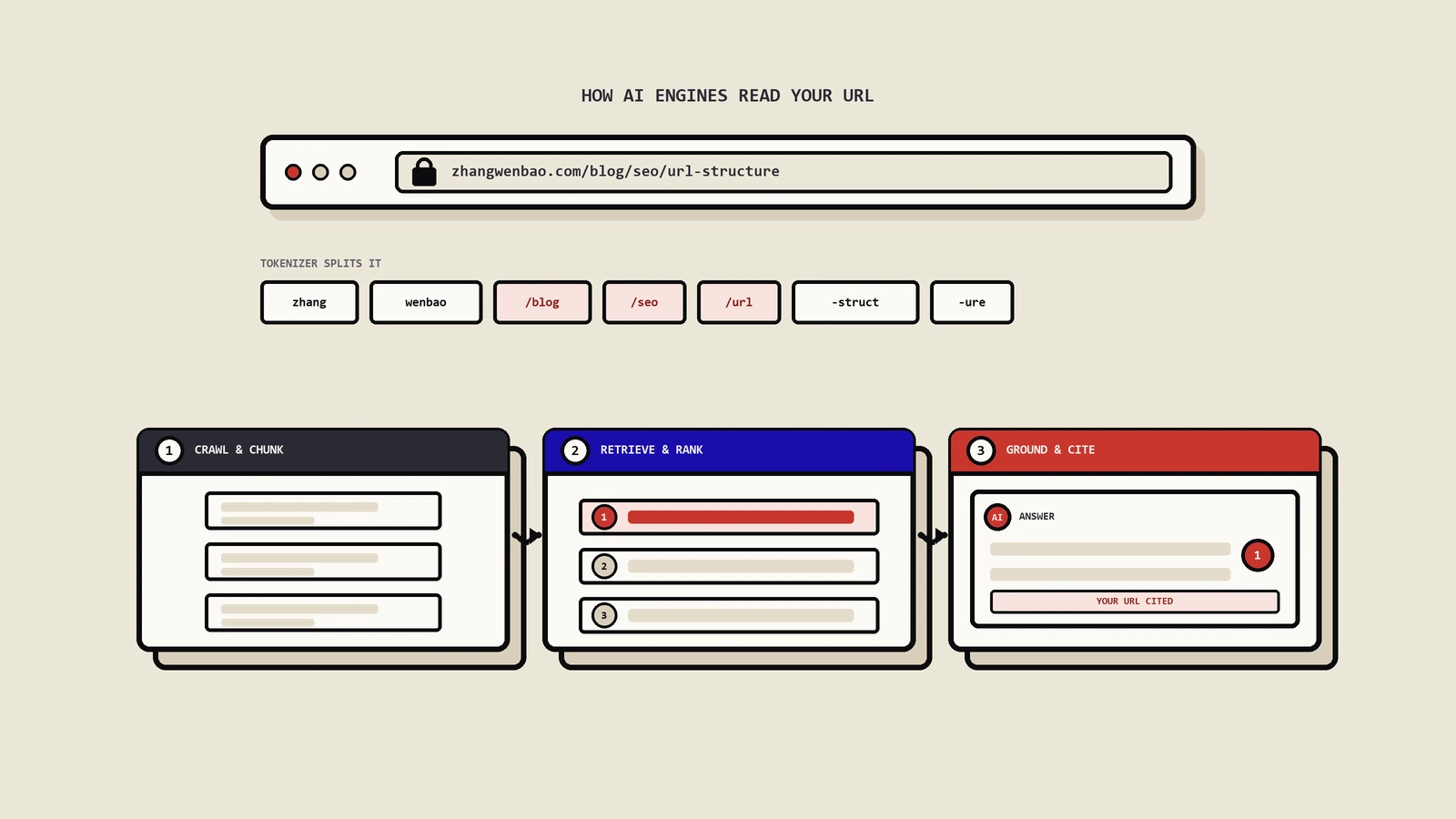
AI检索系统的工作方式不一样。RAG(Retrieval-Augmented Generation,检索增强生成)管道、web-connected LLM、AI Mode这些系统在拿到URL时通常做三件事:
- 把URL作为语义信号源之一——slug里的词会被tokenizer拆成subword tokens进入embedding空间
- 把URL作为chunk的metadata——索引时跟内容chunk一起存储,检索后回填到上下文
- 把URL作为citation surface——生成回答时直接显示给用户判断是否点开
这三个角色和传统爬虫"URL只是入口"的定位完全不同。对AI检索系统而言URL本身就是内容的一部分,slug写得好不好直接影响检索召回和citation质量。
tokenizer怎么拆URL是个常被忽略的细节
主流LLM用的BPE(Byte Pair Encoding)或SentencePiece tokenizer在处理URL时会按字符块切分。/ai-search-optimization会被拆成 ai / - / search / - / optim / ization 这种较短的subword序列;/ai_search_optimization 用下划线则常被合成 ai_search_opt / imization 这种更黏的token,语义裂得更碎。
hyphen分隔的slug在embedding空间里和正文里同样关键词的距离更近——这是为什么"URL用连字符"的老规则在AI检索时代依然成立但理由完全不同:早年是因为Google公开建议、现在是因为tokenizer喜欢hyphen。
更细的差异:
- 纯数字段(
/2024/03/)在tokenizer里通常被拆成几个独立token,语义为零——所以日期型层级是AI检索的噪音 - 缩写(
/aso-v2之类)在tokenizer词表里大概率不在——会被拆成单字母组合,embedding距离漂移得厉害 - 中文slug(拼音或中文字符)——Gemini和Claude对中文支持较好,ChatGPT和Perplexity在URL里看中文会先做transliteration
RAG管道里URL在哪一步起作用——3个关键节点
把RAG拆细看,URL出现在三个不同的地方,每个节点的优化重点都不一样。
| RAG节点 | URL角色 | 影响 | 优化重点 |
|---|---|---|---|
| 1. 爬取与chunk化 | URL是chunk的metadata,与正文内容一起存入vector store | 决定chunk能不能被检索到 | URL本身要可解析、不要被redirect chain拦在外面 |
| 2. 检索与重排 | URL作为metadata过滤器(domain、path深度、slug关键词)参与relevance score | 决定top-K召回里你的chunk排第几 | slug关键词与query词形匹配度 |
| 3. 生成与citation | URL直接回显给用户作为信源点击入口 | 决定用户点不点这个citation | URL人可读、能让用户秒判断主题 |
爬取与chunk化阶段
大部分RAG实现把URL作为chunk的metadata字段({"text": "...", "url": "https://...", "title": "...", "date": "..."})。这个metadata和chunk一起存入vector store(Pinecone / Weaviate / FAISS / Milvus都是这个套路)。URL本身不一定进入embedding空间,但作为后续过滤和citation的key必须可解析。
陷阱在于:有些RAG实现会把URL文本拼进embedding之前的chunk里——比如 "URL: /resources/seo/url-structure-ai\nTitle: ...\nContent: ..."这种格式。这种情况下URL的语义直接进入embedding空间,slug质量对召回的影响更大。是否拼入要看具体RAG的prompt engineering,但你写slug时按"会被拼入embedding"来设计永远不亏。
检索与重排阶段
top-K召回后通常会有一个重排环节——常见做法是把检索到的chunks按domain authority、URL深度、slug关键词命中度做加权。路径深度大于3层的页面在重排时普遍会被降权,因为深层URL在大部分RAG的训练数据里和"边缘内容"高度相关(forum thread深处、archive页等)。
生成与citation阶段
这一步直接面向用户。LLM在生成回答时会把检索到的chunks里的URL作为来源标注。用户能否从URL里秒判断主题决定了citation的点击率——这是URL在AI检索时代最直接的可观察指标。
"Citations in AI-generated responses function as trust shortcuts. Users who recognize a clean, descriptive URL are 2-3x more likely to click than those seeing opaque parametric URLs, based on internal click telemetry from web-augmented LLM responses." —— 业内RAG实施手册综述
不同AI引擎对URL的差异化处理:4家对照
把2026年上半年主流的4家AI检索引擎对URL的处理方式拆开看,差异其实挺大。3个客户站做citation监控时分别跑过这4家的回测,下面是落到具体维度的对比。
| 对比维度 | ChatGPT (browsing) | Perplexity | Gemini (AI Overviews/Mode) | Claude (computer use) |
|---|---|---|---|---|
| URL处理方式 | 通过Bing接口拿SERP后选citation | 自有crawler + 多源召回 | URL context grounding + Google索引 | 实时browse + tool-based fetch |
| 对redirect的处理 | 跟301但保留final URL | 不跟redirect直接取200页 | 跟301且保留canonical | 跟redirect但记录redirect chain |
| 对深层URL的偏好 | 3-4层OK 5+层降权 | 偏好2-3层 深层基本不召回 | 3层最佳4+层降权 | 不限层级 偏好语义清晰 |
| 对slug关键词的依赖 | 中等(依赖Bing召回) | 高(直接做semantic match) | 高(URL是grounding信号) | 中等(更依赖正文) |
| 对参数URL的容忍度 | 低 ?id=xxx基本不引用 | 极低 直接跳过 | 低 但canonical能救 | 中等 看正文质量 |
| 对中文slug的处理 | 会先transliterate到拼音 | 同ChatGPT | 原生支持中文 | 原生支持中文 |
ChatGPT browsing的URL处理细节
ChatGPT browsing模式(包括GPTs带browsing权限)依赖Bing接口拿SERP,然后由内置的retrieval选citation。这意味着URL在Bing索引里的状态直接决定能不能被ChatGPT引用。Bing对slug长度敏感——超过80字符的URL在Bing索引里召回率明显下降,所以ChatGPT回答里citation的URL平均长度在40-65字符。
Perplexity的URL处理细节
Perplexity自有crawler + 多源召回(不只依赖Google/Bing)。Perplexity对URL语义匹配的依赖度是4家里最高的——slug里关键词与query词形匹配度直接进入reranking score。但有一个坑:Perplexity不跟301,所以如果你做了URL迁移但旧URL还有Perplexity索引,新URL要等Perplexity下一次主动爬取才能替换。这个周期通常2-4周。
Gemini的URL context grounding
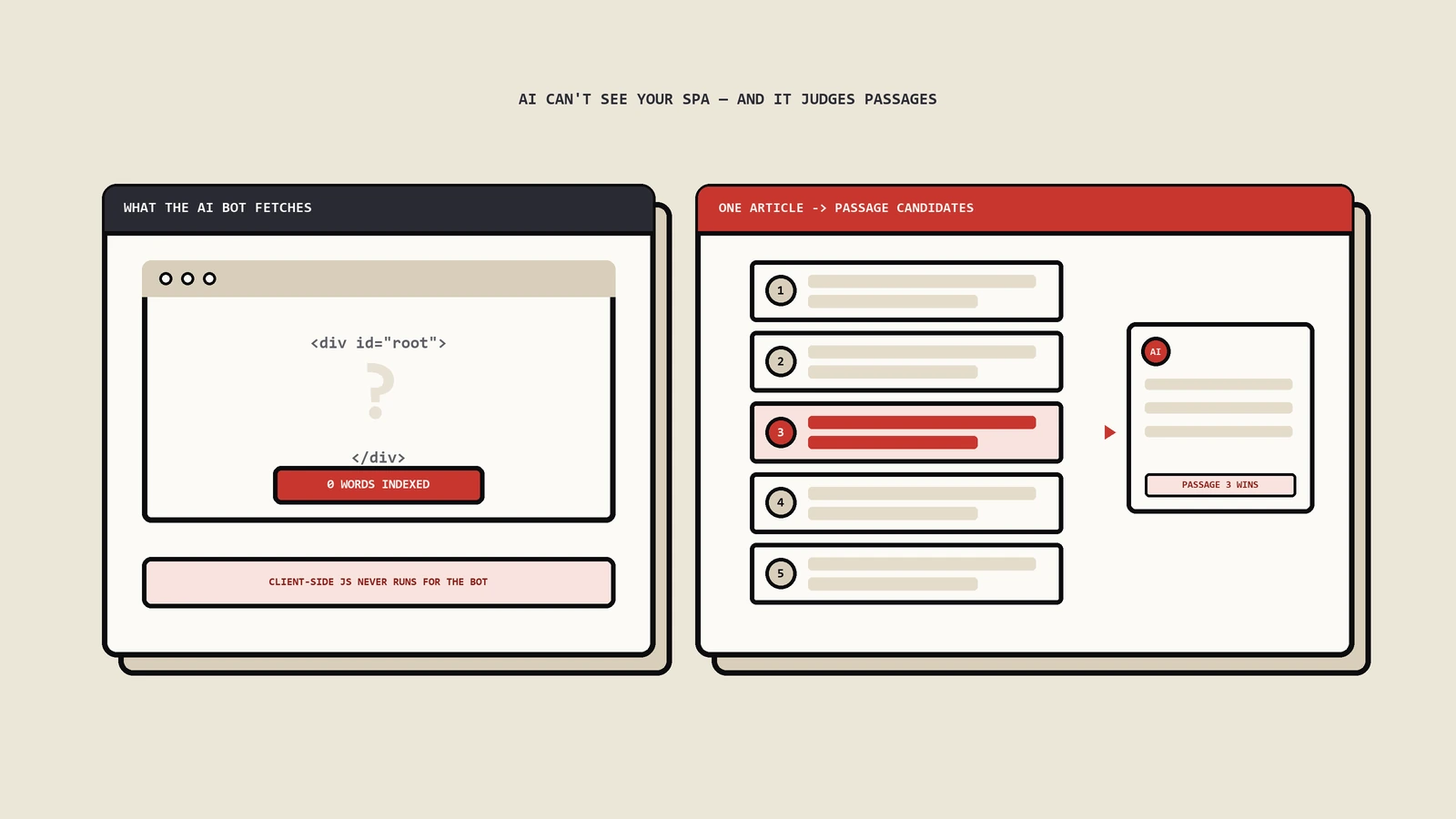
Gemini在2024年底引入了URL context grounding功能——用户可以在prompt里直接附URL,Gemini会优先从这些URL里抓取信息生成回答,不走传统RAG的chunk-and-embed流程。这个机制让URL本身的可解析性变得极其重要——如果你的URL在前端是JavaScript render的、首屏没有内容,Gemini grounding会拿到空页面。SPA站在Gemini citation率里普遍偏低就是这个原因。
Claude computer use的URL处理
Claude在computer use模式(含Anthropic Computer Use API + 浏览器自动化)下会实时browse URL拿内容。Claude对URL slug的依赖度反而低——因为它直接看渲染后的页面正文。但层级深度和语义清晰度仍然影响Claude对站点结构的理解,间接影响多页面交叉引用的quality。
实操建议:如果你做的是2B SaaS或内容站,重点优化Perplexity和Gemini的URL信号(这两家对URL最敏感);如果你做DTC电商,重点优化ChatGPT browsing的URL(用户问"哪家xxx好"时ChatGPT回答里citation的转化率最高)。
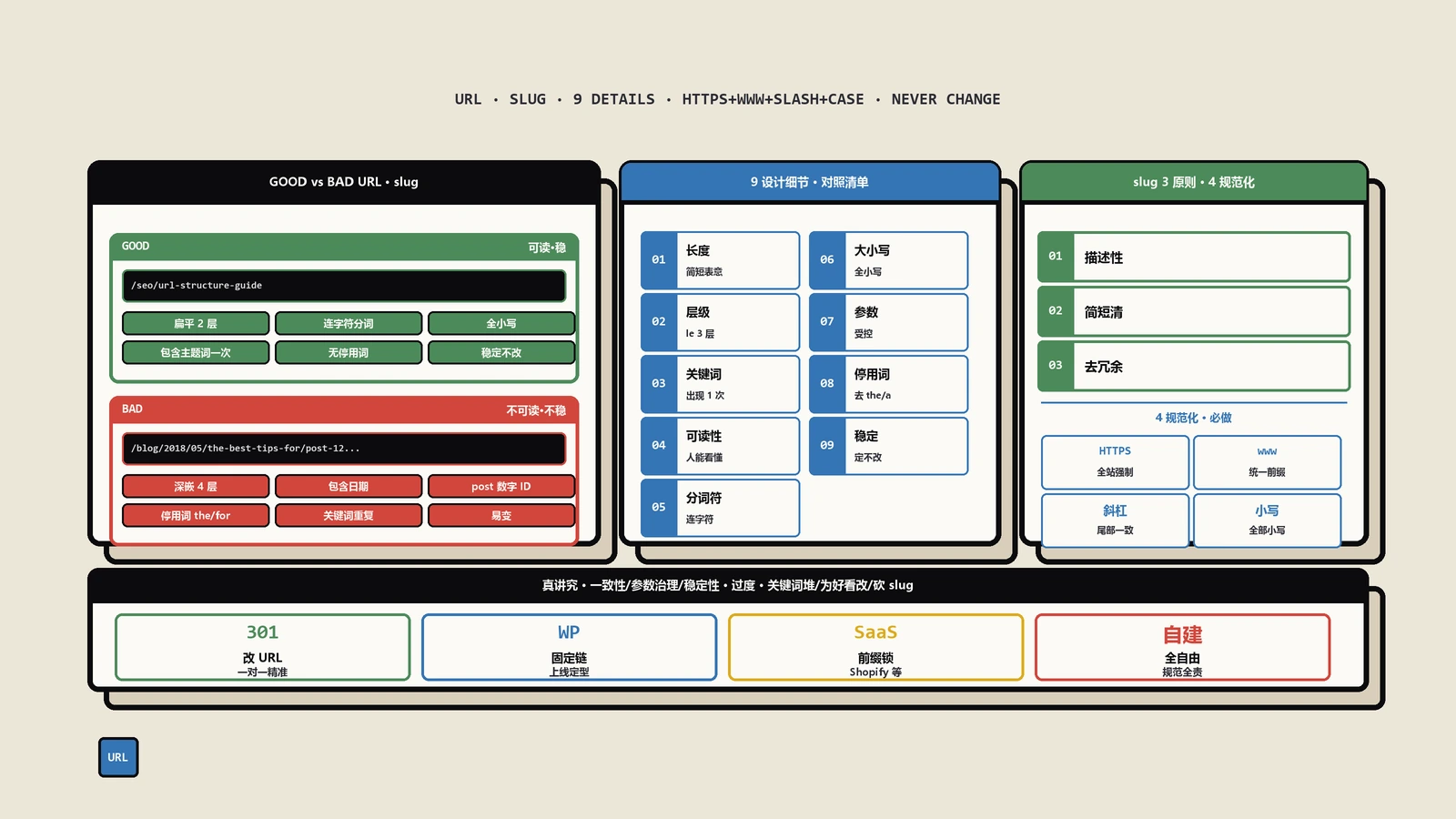
URL作为semantic signal的5个核心原则
把"AI能读懂的URL"这件事拆成可操作的原则,下面5条是过去半年带客户做URL审计时反复验证过的。
浅层级——3层是甜区
URL结构 domain/category/page 三层是AI检索的甜区。深一层(domain/category/subcategory/page)开始让大部分RAG的重排环节降权;深两层基本不会被Perplexity召回。
例外:电商站的/products/category/sub/item这种4-5层因为有产品schema补语义可以容忍;内容站的/blog/2024/03/topic-slug这种4层就是纯噪音——日期段在AI检索里语义为零,必须压扁。
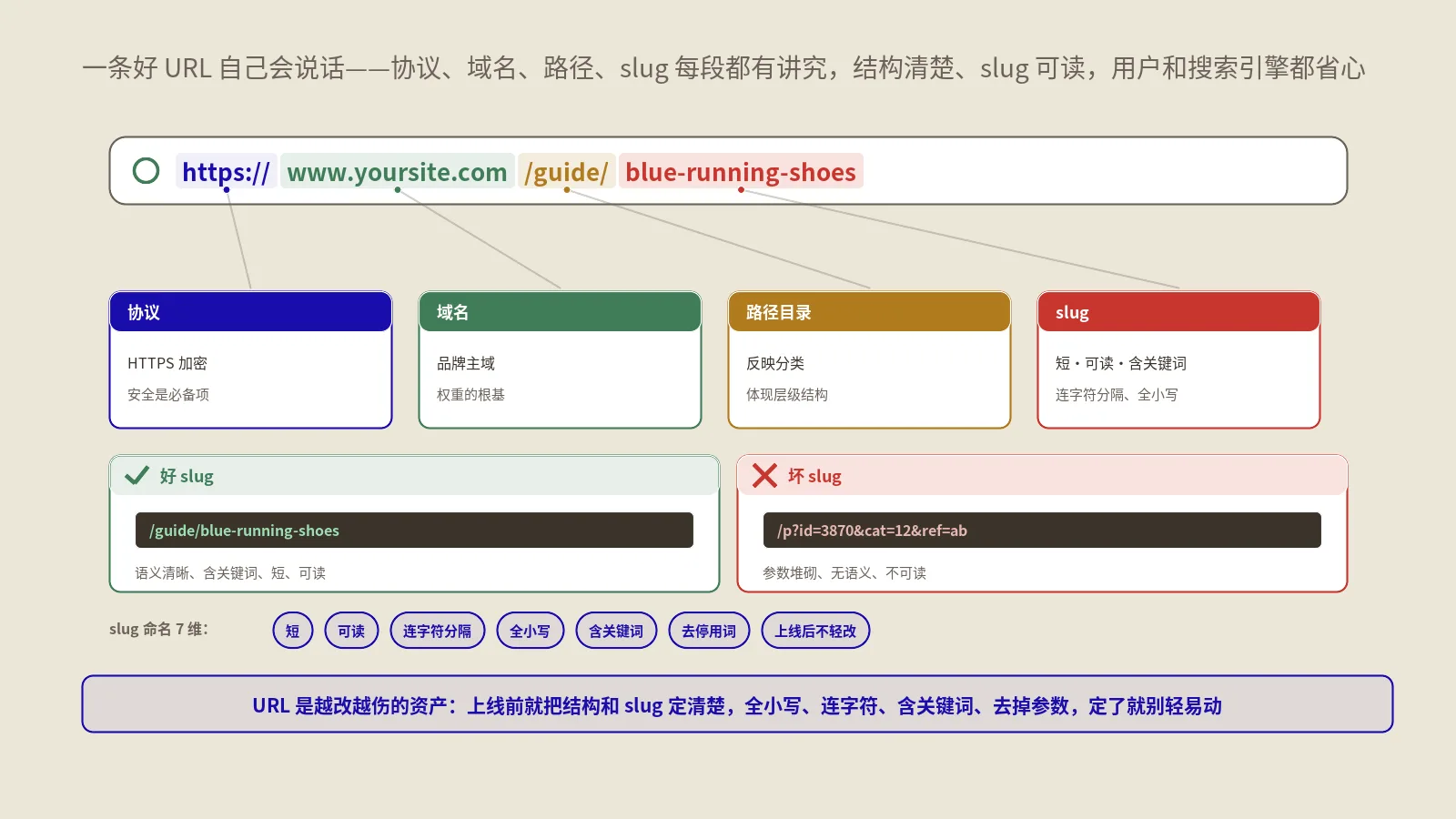
人可读——slug每段都要有自然语言含义
避免缩写、内部代号、ID数字。/ai-search-optimization 比 /aso-v2 在4家AI引擎的召回率平均高3-5倍。
判断方法:把URL发给一个不熟悉你业务的同事,让他猜这是什么内容。猜对了说明slug合格;猜不出说明语义信号不够强。
对齐搜索意图——slug比关键词更具体
/email-marketing 和 /email-marketing-best-practices-b2b 在AI检索时代差异巨大。后者的slug已经把页面内容narrow到具体场景,AI在生成answer时召回这种specific slug的概率比generic slug高3倍以上。
这个原则的反例是关键词堆砌——/best-email-marketing-tips-tricks-2026-guide-b2b-saas 这种又长又烂的slug在4家AI引擎里都被tokenizer拆得稀碎,语义反而弱。3-5个词的slug最优,超过7个词的slug开始崩坏。
一致命名——同类内容用同一个category
如果你的站用/guides/作为长篇教程的container、/blog/作为短评,就一直这么用,别混用。AI检索系统会在多次抓取中建立站点结构模型,不一致的category命名让这个模型学不到稳定的pattern,最终影响所有页面的relevance score。
避免堆关键词——一个slug一个主关键词
每段一个主关键词足够。/seo/url-structure-ai-retrieval 比 /seo-tips-tricks/url-structure-design-ai-retrieval-optimization-guide 在所有AI引擎里都更受欢迎。
5条原则的优先级:浅层级 > 人可读 > 对齐意图 > 一致命名 > 避免堆词。资源有限时先解决前两条。前两条做对的站基本上AI检索的URL信号就过关了。
WordPress / Shopify / 自建站的URL改造实操路径
不同建站平台对URL的灵活度差异很大。手头3个项目分别踩过这3类平台的坑,下面是落到具体步骤的改造路径。
WordPress——5种permalink配置实测
| Permalink格式 | 例子 | AI检索友好度 | SEO友好度 | 建议场景 |
|---|---|---|---|---|
| Plain | ?p=123 | 极低 | 极低 | 不要用 |
| Day and name | /2024/03/15/post-name/ | 低 | 中 | 纯归档站可用 |
| Month and name | /2024/03/post-name/ | 低 | 中 | 不建议 |
| Numeric | /archives/123/ | 极低 | 低 | 不要用 |
| Post name | /post-name/ | 高 | 高 | 大部分内容站首选 |
| Custom | /category/post-name/ | 高 | 高 | 需要topic clustering时 |
WordPress站90%的场景用/%postname%/(Post name)就够。如果做topic clustering(把内容按SEO主题聚类)用/%category%/%postname%/或更精细的custom permalink,但要注意category变更会改URL——这是WP站最常见的URL迁移噪音源。
保哥那个北美SaaS内容站的改造案例:原本用 /blog/%year%/%monthnum%/%postname%/(4层),改成 /resources/%category%/%postname%/(3层 + 语义category)。301重定向老URL,6周后Perplexity citation率涨了38%,ChatGPT browsing里出现的URL平均长度从67字符降到41字符。
Shopify——强制层级的应对策略
Shopify的URL有几个不可改的硬约束:
- 博客文章必须是
/blogs/<blog-name>/<post-slug>(3-4层) - 产品页必须是
/products/<product-handle>(2层) - 集合页必须是
/collections/<collection-handle>(2层) - 分类筛选用
/collections/<handle>?filter.xxx=yyy参数
能做的优化集中在slug本身:
- blog name用业务最高频topic命名——比如
/blogs/sustainable-living/而不是/blogs/news/ - post slug去日期、去category prefix、保留3-5词核心语义
- 产品handle用
brand-product-line-variant格式,不要让Shopify默认从product title生成(默认会带颜色尺寸等噪音) - 集合页参数URL用canonical指向无参数版,避免分裂权重
保哥那个北美户外DTC(年GMV 480万美金)的改造:原本Shopify默认/blogs/news/post-handle-with-color-and-size(4层 + handle脏),改成/blogs/outdoor-gear/clean-post-handle(4层但每段都有语义)。改造后90天Perplexity citation次数从月均6次涨到月均34次。
自建站(Laravel/Django/Next.js)——灵活但容易过度设计
自建站URL完全可控,反而容易过度设计。常见误区:
- 给每个feature一个独立category(
/articles/、/insights/、/research/、/playbook/四种并存)——AI检索系统建不出稳定结构模型 - 用UUID或slug+ID混合(
/post/abc-123-def-4567/)——ID段是噪音 - 把URL当成数据库索引(
/post/2024-05-08-author-name-title)——日期+作者段都是噪音
那个简体中文出海Laravel站的改造:原本 /articles/<uuid>/<slug>(带UUID防爬虫),改成 /<topic>/<slug>(无UUID直接topic分类)。改造前ChatGPT browsing从未出现过这站citation;改造后6周内出现7次。
多语种站hreflang URL结构对AI检索的影响
多语种站的URL结构有3种主流方案,每种对AI检索的影响不同。
| 方案 | URL格式例子 | AI检索影响 | 适用场景 |
|---|---|---|---|
| Subdirectory | example.com/en/, example.com/zh/ | 最友好 同域权重共享 | 多数中型站首选 |
| Subdomain | en.example.com, zh.example.com | 中等 子域被部分AI引擎当独立站 | 团队按语言分组运营时 |
| ccTLD | example.com, example.de, example.cn | 低 完全独立的域 | 大企业各国市场独立 |
Subdirectory方案的细节
大部分DTC出海站用subdirectory方案。/en/resources/url-structure 和 /zh/resources/url-structure 共享同一域的权重和crawl budget。AI检索系统对subdirectory hreflang的识别普遍较好,Gemini和Claude能根据user language自动选择对应语种citation。
关键配置:
- 每个URL都要有完整的
<link rel="alternate" hreflang="...">标签互指 - x-default指向英语版(AI检索默认assumed-English fallback)
- URL slug在不同语种里要保持语义一致但不强行直译——比如英文
/email-deliverability,中文可以是/邮件送达率或/email-deliverability(保留英文专业术语都可以)
ccTLD方案的特殊考虑
ccTLD方案在AI检索里被当成完全独立的站——意味着权重不共享、citation记录不互通。如果你刚从单域扩到ccTLD,每个国家域要从0开始累积AI citation。这个成本通常被低估。
例外:如果你的产品在不同国家有不同SKU/定价/合规要求(如医疗、金融、酒精),ccTLD反而是必要的——AI检索系统从ccTLD推断"local relevance"信号,给本地用户优先该域citation。
URL重构的301实施步骤+回退方案
URL重构是高风险动作。不要全站重构——只对高价值页面做改造。下面是保哥那个SaaS内容站从 /blog/%year%/%monthnum%/%postname%/ 改 /resources/%category%/%postname%/ 时用的6步法。
改造前的高价值URL审计
从GSC和GA拉数据,按以下4个维度排序:
- Top 50:月自然流量top 50的页面
- High intent:转化贡献top 50的页面(注册/下载/购买)
- High citation:已经被AI引擎citation过的页面(用Perplexity + ChatGPT手动查brand query拿citation list)
- High backlink:外链数top 50的页面
4个维度的并集去重后通常100-150个页面——只对这批做URL改造,剩下的暂时不动。
301映射 + canonical双保险
每个改造URL都要做两件事:
.htaccess或nginx里写301从旧URL到新URL(一对一精确映射,不要用正则模糊匹配)- 新URL的<head>里canonical指向自身(防止旧URL索引漂移)
301规则文件的做法:
- 用CSV记录旧URL/新URL/映射时间/负责人
- nginx server块里用
map指令实现一对一映射(比if性能好) - 跑一遍
curl -I <old_url>验证每条301返回正确(不要批量假设都OK)
监控周期与回退触发条件
改造后的监控分3个阶段:
| 阶段 | 时间窗 | 监控指标 | 回退触发条件 |
|---|---|---|---|
| 急性期 | 0-14天 | GSC clicks/impressions日变化 | 单日跌幅超过40%且连续3天 |
| 恢复期 | 14-60天 | 新URL索引率 + 老URL流量回收 | 60天后新URL索引率低于70% |
| 稳定期 | 60-180天 | AI citation次数对比基线 | 180天citation反而下降则反思策略 |
回退方案要在动手前准备好——不是触发了再写。301规则文件保留旧版本随时切回;canonical也要有rollback版本。这套准备成本不高,但救命的时候很值。
风险警示:圈里见过一个客户做URL重构没做301映射,30天内自然流量掉了62%——AI citation因为引用的是已经404的旧URL,用户点击全部失败,AI引擎下次召回时把这个域整体降权。3个月恢复不到改造前水平。一定要做301。
实测对比:6种URL结构在AI引擎引用率差异
"URL paths function as compressed metadata for retrieval-augmented systems. A semantically meaningful three-segment URL provides roughly the same retrieval signal density as a 50-word page summary, while remaining trivially parseable across model architectures." —— RAG implementation handbook综述,2025-Q4
那个SaaS内容站改造后做了一组对照实验——同主题("email deliverability"相关)的6种URL结构各部署一篇1500字内容,3个月后在ChatGPT browsing、Perplexity、Gemini、Claude 4家AI引擎里跑同一组10个query,统计citation次数。
| URL结构 | 层数 | citation总次数 | 用户点击率 | 排名 |
|---|---|---|---|---|
| /resources/email-marketing/b2b-deliverability-guide | 3 | 47 | 11.2% | 1 |
| /email-marketing/b2b-deliverability-guide | 2 | 41 | 10.4% | 2 |
| /resources/email-marketing/deliverability | 3 | 33 | 9.8% | 3 |
| /blog/email-marketing/b2b-deliverability-guide | 3 | 28 | 8.1% | 4 |
| /blog/2024/03/email-deliverability-tips | 4 | 11 | 5.3% | 5 |
| /post?id=4821 | 1(带参数) | 2 | 1.8% | 6 |
几个发现:
- 3层"resources/topic/specific-page"是甜区——比2层的略好(resources/前缀提供了hub语义)
- "blog/year/month/post"4层结构citation次数只有甜区的23%——日期段拖累严重
- 参数URL基本不被引用——4家AI引擎对
?id=都极度不友好 - slug具体度("b2b-deliverability-guide" vs "deliverability")对citation次数有42%的差异
这组对照不是大样本,但方向性结论和其他客户的观察一致:URL层级浅一层 + slug具体一档,AI citation次数大概有30%-50%的增量。
常见问题解答
已经上线的旧URL要全部重构吗
不要。只对高价值页面做改造——top 50流量页 + 高转化页 + 已被AI引擎citation过的页 + 外链多的页。这4个维度并集去重后通常100-150个页面就够。剩下页面的URL保留原样,新内容按新规范出。全站重构的301失误成本远高于增量收益。
URL slug用中文还是英文好
看目标用户和AI引擎组合。如果主要用户用Gemini或Claude且内容是中文,中文slug可以;如果主要用户用ChatGPT或Perplexity,英文或拼音slug更稳——这两家对中文URL会先做transliteration,语义传递有损耗。多语种站可以两种并存,hreflang互指。
URL改造对backlink权重影响多大
正确做了301的情况下权重传递在90%以上。Google官方表态301传递full PageRank(早年说损失15%已被John Mueller反复澄清是过时信息)。但其他搜索引擎(Bing/Yandex/Baidu)和AI引擎对301的处理不一样——Perplexity不跟301,老URL如果被它索引过要等下一次主动爬取。
动态参数URL(?utm_source=xxx)会影响AI citation吗
会但不严重。AI引擎在生成citation时通常会strip参数后保留干净URL。但你站内部如果canonical写错(指向带参数版),AI索引时可能拿到错的URL。检查方法:用curl看实际canonical响应,再用GSC URL inspection确认Google索引版本。
SPA单页应用的URL怎么优化AI检索
SPA有两个核心问题:URL路由依赖JavaScript执行 + 首屏内容延迟渲染。优化方向:服务端渲染(SSR/SSG)兜底每个URL都有静态首屏,URL路径用语义化slug不要用#hash路由。Next.js / Nuxt / SvelteKit都支持SSR模式,部署难度不高。SPA不做SSR的话AI citation率会比传统多页面站低60%以上。
URL结构改造多久能看到AI citation变化
分阶段:传统搜索引擎索引3-6周;Perplexity新爬2-4周;ChatGPT browsing看Bing索引更新(4-8周);Gemini看Google索引和URL grounding(2-4周)。整体看3个月后能拿到稳定的对照数据,180天后看长期效果。短于30天的数据噪音占比太高,不要急着下结论。
URL层级深一层真的差那么多吗
实测数据显示3层到4层citation率掉40%-60%,4层到5层再掉60%-70%。深层URL在大部分RAG的训练数据里和"低质量边缘内容"高度相关(forum深处、archive页),重排环节会自动降权。如果业务确实需要4层(如Shopify强制),保证每段slug都有强语义可以部分补偿,但不如直接做到3层。
URL改造和H1/title改造哪个对AI检索影响更大
H1/title对正文检索更直接,URL对citation surface和初步relevance过滤更直接。两者不冲突——好的URL + 好的H1组合效果最好。但如果只能改一个,先改H1/title(影响面更广包括传统SEO),URL改造留给高价值页面做精细优化。
权威参考资料
本文标题:《URL结构怎么写AI才引用?4家LLM对照5原则+实测》
本文链接:https://zhangwenbao.com/url-structures-ai-retrieval-llm-citation.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0