Googlebot抓取2MB限制:8步实战优化指南
本文目录
- 三层抓取限制体系:不是一个数字,而是一套分层架构
- Google 的爬虫系统不是铁板一块
- 2MB 限制的真实影响:恐慌还是淡定
- 真正受影响的场景
- Spotibo 的实测发现:静默截断的陷阱
- 为什么这些限制存在
- 8 个可直接执行的实战优化
- 审计:找出你的"胖页面"
- 内容前置:把最重要的东西放在最前面
- 外部化:把"重量"从 HTML 中搬出去
- 前端框架特别处理:__NEXT_DATA__、Nuxt state 等
- 拆分:将超长内容分页或分章节
- 压缩与精简:减少 HTML 冗余
- 监控:建立持续检测机制
- PDF 优化:64MB 够用但别浪费
- 真实案例:一个新闻站发现 22% 文章被截断
- John Mueller 的实用检测方法
- 国产 CMS 和国内站的 HTML 为什么特别容易撑爆 2MB
- 真实翻车:一个 Shopify 出海站被 2MB 悄悄截断的排查实录
- 常见问题解答
- 小结
- 权威参考资料
摘要:Googlebot的抓取不是一个数字而是分层的——通用15MB、HTML索引只取前2MB、PDF最大64MB,超过2MB的部分会被静默截断。本文基于Google官方播客披露的信息详解这套体系,给审计、内容前置、外部化、SSR裁剪等八步优化和Mueller的实用检测方法,附一个新闻站22%文章被截断的修复案例。
最近在 Google 官方播客 Search Off The Record 中听到了一段非常有价值的对话——Google 的 Gary Illyes 和 Martin Splitt 首次详细披露了 Googlebot 抓取限制背后的运作机制。这些信息对于做技术 SEO 的人来说堪称金矿,因为它揭开了我们过去对 Google 爬虫理解中的很多盲区。
这篇文章把这些新信息和 2026 年 2 月以来的抓取限制文档更新完整串起来,覆盖三层抓取限制体系、2MB 静默截断的实测案例、8 步实战优化清单、前端框架内联状态排查、PDF 64MB 限制、John Mueller 的检测技巧和 10 条 FAQ,给你一篇真正能用的技术 SEO 实操指南。
三层抓取限制体系:不是一个数字,而是一套分层架构
过去大多数 SEO 从业者只知道"Googlebot 有 15MB 的抓取限制"。但 2026 年 2 月 Google 更新了官方文档后,我们才发现这个认知远远不够准确。实际上,Google 的抓取限制是一套分层体系:
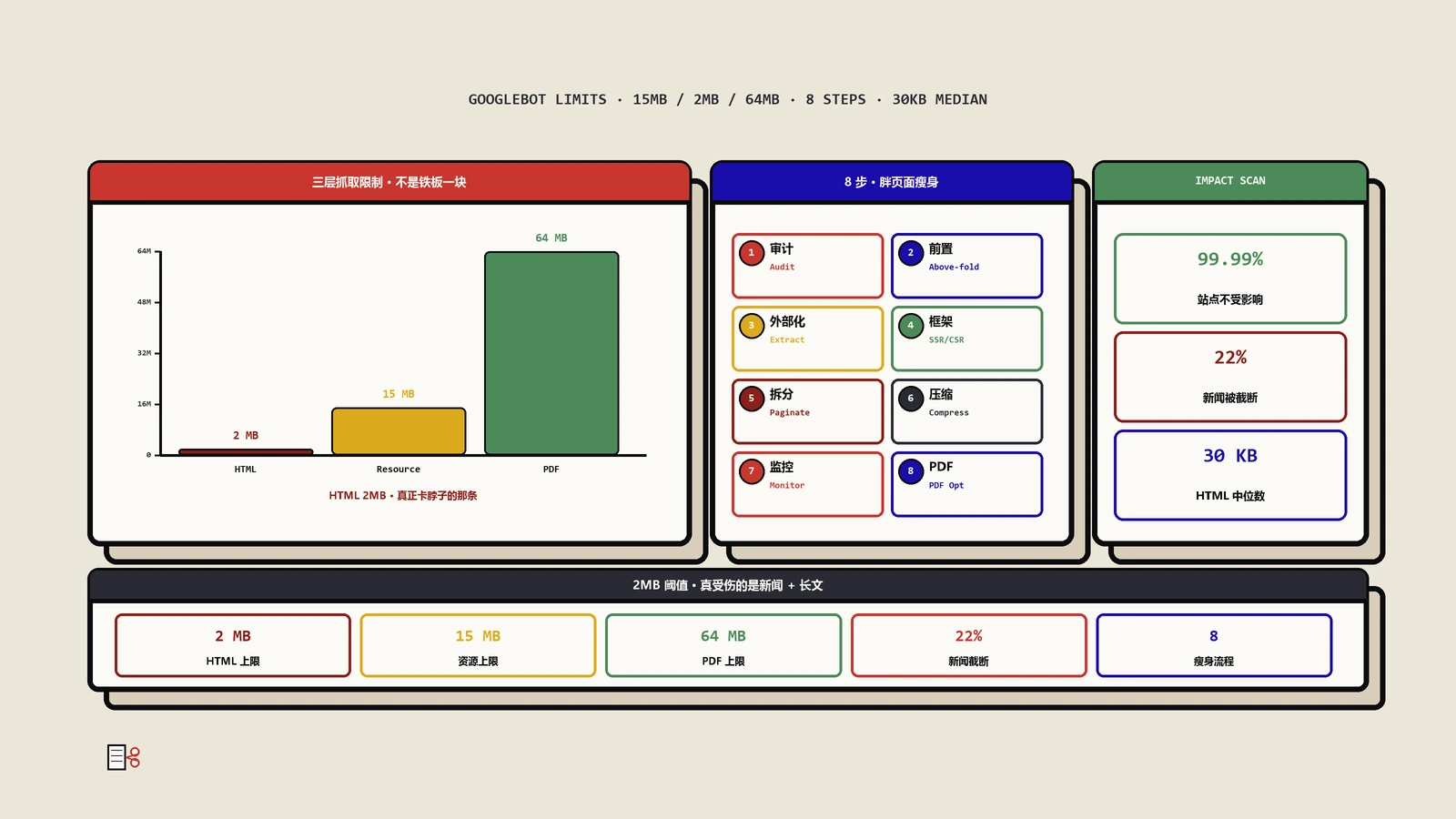
第一层:通用基础设施层——15MB 默认限制。这是 Google 整个爬虫基础设施的默认上限。任何没有主动覆盖这个设置的 Google 爬虫,都会受到 15MB 的约束。当爬虫从服务器获取字节流时,内部有一个计数器,一旦达到 15MB 就停止接收数据。
第二层:Google 搜索特定层——HTML 文件 2MB 限制。这是对 SEO 影响最直接的数字。Google 搜索团队主动将默认的 15MB 限制下调为 2MB,专门用于 Googlebot 处理 HTML 内容进行搜索索引。一旦 HTML 文件的未压缩大小超过 2MB,超出部分的内容将被静默截断。
第三层:特定文件类型例外——PDF 64MB 限制。考虑到 PDF 文件通常比 HTML 大得多(比如 HTTP 标准导出为 PDF 后可达 96MB),Google 为 PDF 单独设置了 64MB 的抓取上限。
Gary Illyes 在播客中的原话非常关键,他明确表示这些限制是可被覆盖的:Google 内部的各个团队会经常根据需要调整这些限制。某些场景下会调高(比如 PDF 从 15MB 调到 64MB),某些场景下会调低(比如搜索团队从 15MB 调到 2MB)。如果需要在几秒内快速推送内容通过索引管线,截断限制甚至可能被压到 1MB 以进一步加速处理。
| 爬虫/场景 | 限制 | 影响 |
|---|---|---|
| 通用基础设施 | 15MB | 所有 Google 爬虫的默认上限 |
| Googlebot HTML 索引 | 2MB | 超出部分静默截断,索引不可见 |
| Googlebot PDF | 64MB | 大型规范文档/白皮书的特殊上限 |
| Googlebot Image / Video | 独立配置 | 不参与 HTML 2MB 计算 |
| Google-InspectionTool(URL 检查) | 15MB | 不等于真实 Googlebot 行为 |
| 快速索引管线 | ≤1MB | 新闻、突发、Discover 极限场景 |
Google 的爬虫系统不是铁板一块
Martin Splitt 在播客中用了一个很精准的描述:"Google 的爬虫基础设施不是 monolithic(铁板一块的)"。他将其描述为一种软件即服务(SaaS)架构——Google 搜索只是这个爬虫服务的众多客户端之一。这意味着什么?翻译成实操语言:
不同的 Google 爬虫有不同的限制配置。Googlebot Image(图片爬虫)允许的文件大小肯定比 2MB 大得多,因为图片本身就经常超过 2MB。Googlebot Video 同样有自己的独立限制。你在 Google 文档中看到的限制数字,并不是跨所有 Google 爬虫的硬性规定。
同一个爬虫在不同请求级别也可以有不同配置。Splitt 明确说了:"配置可以在请求级别改变,而不仅仅是在 Googlebot 层面固定不变。"这意味着同一个 Googlebot 在抓取不同页面时,可能会应用不同的参数配置。
快速索引场景可能有更严格的限制。Illyes 提到,如果需要在几秒内将内容推过索引管线,截断限制可能会被压缩到 1MB 甚至更低。这暗示了 Google 在处理突发新闻、实时内容等场景时,会牺牲完整性换取速度。
2MB 限制的真实影响:恐慌还是淡定
先给你一颗定心丸:对 99.99% 的网站来说,2MB 的 HTML 限制不是问题。
根据 HTTP Archive Web Almanac 的数据,网页 HTML 的中位数大小大约是 30KB(移动端约 33KB)。这意味着你需要一个比平均水平大 67 倍的页面才会触及 2MB 的门槛。一个纯文本文件要达到 2MB,需要超过 200 万个字符——这大约相当于一部中长篇小说的篇幅。
但不会让你就此放松警惕,因为有几类网站确实需要关注。
真正受影响的场景
内嵌大量 JavaScript 或 JSON 数据的页面。如果你的页面把巨大的 JavaScript 代码块、JSON-LD 数据对象、或者 base64 编码的图片直接内联在 HTML 中,这些都会计入 HTML 文件大小。一些前端框架生成的初始 HTML 可能因为包含服务端渲染的状态数据而膨胀到几 MB。
超长单页文档。技术文档、法律法规全文、产品规格大全等以单页形式呈现的超长内容,确实可能超过 2MB。比如 HTML Living Standard 导出为单页版本后达到 14MB。
内容型电商页面。产品页面如果同时包含大量详细参数表、用户评价(直接内嵌在 HTML 中而非异步加载)、以及内联的结构化数据,也可能逼近或超过限制。
评论密集型博客。开放评论的热门博客,单篇文章评论达数千条且全部在 HTML 中渲染(非异步加载),是被静默截断的高危群体。
论坛主帖页。一个被回复几千楼的主帖,HTML 体积轻松破 2MB。Discuz/Vanilla/Discourse 这类论坛要特别留意。
Spotibo 的实测发现:静默截断的陷阱
Spotibo 团队做了一个非常有价值的实测。他们创建了一个 3MB 的 HTML 测试文件并提交给 Google 索引。结果:
- Google Search Console 的 URL 检查工具显示一切正常——因为该工具使用的是"Google-InspectionTool"爬虫,它运行在 15MB 的通用限制下,而不是 Googlebot 搜索索引用的 2MB 限制。所以 URL 检查工具会显示完整内容,但这跟 Googlebot 实际索引的内容是两回事。
- 查看实际索引的源代码后发现:内容在 2MB 处被截断。源代码在第 15,210 行左右中断,文字在"Prevention is b"处戛然而止,后面直接跟了一个
</html>闭合标签。2MB 之后的所有内容被静默丢弃。 - 但 Google Search Console 的状态显示"URL 已在 Google 上"且"页面已编入索引"。没有任何错误提示或警告。
这是最危险的地方——截断是静默发生的,没有任何告警。你的页面看起来一切正常,实际上后半部分的内容从未被索引。强烈建议你使用 Googlebot 抓取大小检测器来检测你网站关键页面的实际 HTML 大小是否逼近或超过 2MB 阈值。这类工具可以模拟 Googlebot 在 2MB 截断点处停止抓取的行为,直观展示哪些内容会被丢弃。发现问题远比等到排名莫名下跌后再排查要划算得多。
为什么这些限制存在
很多 SEO 从业者把抓取限制理解为"Google 对网站的限制",但 Gary Illyes 的解释让我对此有了全新认识。他的原话是:这些限制主要是 "for our own protection or our infrastructure's protection"——为了保护 Google 自身的基础设施。
想想看,Google 每天要抓取数十亿个页面。如果没有任何大小限制,遇到一个动态生成的无限长页面(比如某些日历应用可以无限展开),Google 的抓取和处理系统就会被淹没。Illyes 专门用 HTTP Living Standard 的例子来说明:14MB 的单页 HTML 标准文档如果完整抓取、转换为 HTML、再进行处理,会 "overwhelm(压垮)"他们的基础设施。
这个视角很重要,因为它暗示了一个底层逻辑:Google 在效率和完整性之间做了明确的权衡取舍。对于搜索索引来说,2MB 的 HTML 已经足够覆盖绝大多数网页的全部有意义内容,而更高的限制带来的边际收益远不如对基础设施的额外负担。
8 个可直接执行的实战优化
审计:找出你的"胖页面"
第一步永远是摸清现状。使用以下方法检测你网站中 HTML 文件大小可能超标的页面:
- Chrome DevTools → Network 标签:过滤 HTML 请求,查看"Size"列(注意区分压缩前和压缩后的大小,Googlebot 的限制针对的是未压缩数据);
- Screaming Frog SEO Spider:抓取全站后按 HTML 大小排序,快速定位异常页面;
- Googlebot 抓取大小检测器:专门模拟 Googlebot 2MB 截断行为的工具;
- 命令行实测:
curl -A "Googlebot" https://your-site.com/page | wc -c,直接得出未压缩字节数; - Google Search Console → URL 检查 → 查看已抓取的页面:但请记住 Spotibo 的发现——这个工具使用的不是 Googlebot 搜索爬虫,结果可能具有误导性。
建议把阈值设在 1.5MB 而非 2MB。留出 500KB 的安全缓冲,因为页面内容可能会因为 A/B 测试、个性化注入、广告代码等原因动态变化。
内容前置:把最重要的东西放在最前面
既然 Googlebot 在 2MB 处截断,那最重要的内容就必须出现在 HTML 的前 2MB 之内。"关键内容前置"原则:
- 标题标签(title)、meta description、H1 标题应该出现在 HTML 的最前面;
- 核心正文内容应该在 HTML 结构中优先于侧边栏、页脚、评论区等辅助内容;
- 结构化数据(JSON-LD)如果体积较大,考虑只保留最关键的标记在页头,其余通过外部文件加载;
- 重要的内部链接确保出现在页面早期位置,不要全部堆在页面底部。
外部化:把"重量"从 HTML 中搬出去
减少 HTML 文件大小最有效的方法就是把不属于它的东西搬出去:
- CSS 外部化:将所有样式从内联
<style>标签移到外部.css文件。外部 CSS 是单独抓取的,不计入 HTML 的 2MB 限制; - JavaScript 外部化:将内联
<script>代码移到外部.js文件。特别注意一些前端框架(如 Next.js、Nuxt.js)可能在服务端渲染时将大量状态数据内联到 HTML 中; - Data URI 移除:如果你在 HTML 中使用了 base64 编码的图片(
data:image/...),将它们替换为普通的<img src="...">引用。图片会被 Googlebot Image 单独抓取,有独立的大小限制; - 大型 JSON 数据外部化:如果页面中嵌入了大型 JSON 数据块(比如产品目录、配置数据),将它们移到外部 API 端点或单独的 JSON 文件中。
前端框架特别处理:__NEXT_DATA__、Nuxt state 等
Next.js、Nuxt、Remix 等 SSR 框架默认会把页面初始状态序列化为 __NEXT_DATA__ 或 __NUXT__ 这类全局 JSON 嵌入 HTML 底部。一个商品详情页可能因此 inline 进去几百 KB 的 JSON。处理方法:
- Next.js:用
getStaticProps时只返回页面真正需要的数据,避免把整个 catalog 序列化进去; - Nuxt:在
useAsyncData里用pick选项裁剪字段; - Remix:检查
loader返回值的体积,避免返回 raw DB row; - 通用:把"页面初次渲染不需要"的数据改为客户端按需 fetch,HTML 体积能瘦身 30-60%。
拆分:将超长内容分页或分章节
对于确实需要包含大量文本内容的页面(如技术文档、法律全文等),考虑将单一超长页面拆分为多个逻辑章节页面,通过清晰的导航串联。这不仅解决了抓取截断问题,通常还能改善用户体验和页面加载速度。
Google 的 Gary Illyes 自己也举了这个例子:HTML Living Standard 有 14MB 的单页版本,但同时也有按功能特性拆分的独立页面版本。Google 会去抓取那些独立页面,而不是试图处理 14MB 的单页巨无霸。
压缩与精简:减少 HTML 冗余
- 清理冗余的 HTML 标签:很多 CMS 和可视化编辑器会生成大量不必要的嵌套
<div>、空标签、重复的 class 属性; - 移除 HTML 注释:开发环境的注释不需要出现在生产环境中;
- 精简内联 SVG:如果页面中包含大量内联 SVG 图标,考虑使用 SVG sprite 或外部 SVG 文件;
- 启用服务端 HTML 压缩(minification):这虽然不直接影响 Googlebot 的截断行为(因为限制针对的是未压缩数据),但可以减少传输时间,间接改善抓取效率。
监控:建立持续检测机制
建议在你的技术 SEO 监控体系中加入 HTML 大小指标:
- 在 DebugBear、ContentKing 等监控工具中设置 HTML 大小超过 1.5MB 的告警;
- 定期使用 Googlebot 抓取大小检测器抽查核心页面,确认关键内容是否在截断点之前;
- 在 CI/CD 流程中加入 HTML 大小检查,防止开发团队的代码变更意外导致页面膨胀;
- 每月审查 Google Search Console 中"已发现-当前未编入索引"页面的列表,排查是否有因截断导致的索引异常。
PDF 优化:64MB 够用但别浪费
虽然 PDF 的 64MB 限制足够宽松,但还是建议遵循以下原则:
- 确保 PDF 中的文本层可搜索(不要只是扫描图片);
- 对于超过 20MB 的 PDF,考虑是否可以拆分为多个较小的文件;
- 在 PDF 的元数据中正确设置标题、作者、关键词;
- 为 PDF 页面提供 HTML 摘要页,让 Googlebot 可以通过 HTML 页面了解 PDF 的核心内容;
- 给 PDF 设置正确的 Cache-Control 和 Last-Modified,让 Googlebot 知道是否需要重抓。
真实案例:一个新闻站发现 22% 文章被截断
2026 年 3 月我帮一家财经新闻站做技术审计。审计前他们流量莫名其妙在过去 6 个月跌了 18%,但他们的内容产量没变、技术架构没动。检查过 robots、sitemap、Core Web Vitals 都没问题。最后用 curl -A Googlebot 抽查发现:
- 22% 的文章 HTML 体积 > 2MB;
- 原因是评论区直接内联渲染(每篇 200-500 条),且文章底部"相关推荐"塞了 50 篇文章卡片;
- 核心新闻正文在前 100KB,但文章的"原始数据来源"、"延伸阅读"在 2MB 之后,被静默截断;
- 对应 Google 索引的内容缺少专业性来源,E-E-A-T 评分下滑,连带影响首页核心新闻的排名。
修复方案:
- 评论区改为异步加载,HTML 只 inline 前 20 条;
- "相关推荐"从 50 篇缩到 8 篇;
- "数据来源"和"延伸阅读"前置到正文末、评论前;
- JSON-LD 中冗余字段裁剪掉。
修复后 HTML 平均体积从 2.5MB 降到 380KB。3 个月后自然流量回升 24%,超过修复前水平。这个案例验证了:HTML 体积不是抽象问题,是真金白银的流量。
John Mueller 的实用检测方法
Google 的 John Mueller 在 Bluesky 上分享了一个非常简洁实用的检测技巧——这可能是全文最实用的一个 tip:
在页面靠后位置找到一句重要的文字,然后在 Google 中搜索这句话(加引号)。如果 Google 能找到这句话,说明你的页面在这个位置之前的内容都被成功索引了。如果找不到,就说明这部分内容可能被截断了。
Mueller 同时强调:"2MB 的 HTML 相当多了",大多数网站不需要为此担心。同意这个判断——但"大多数"不代表"所有",如果你管理的是内容密集型网站,定期检测总归是好习惯。
国产 CMS 和国内站的 HTML 为什么特别容易撑爆 2MB
前面说 2MB 限制对 99.99% 的网站不是问题,这个判断对欧美轻量站成立,但国内站和出海站有几个本土特色的膨胀源,让“踩线”的概率明显高于全球平均。保哥审计国内站时,HTML 体积异常的页面十有八九栽在下面几处。
第一是统计代码叠罗汉。国内站有个习惯,喜欢同时挂一堆统计:百度统计、友盟(CNZZ)、51.LA,再加一个 Google Analytics,讲究点的还要上热力图工具。每个统计脚本都要在页面里内联一段初始化代码,有些老牌统计甚至还用 document.write,加起来几十上百 KB 就这么堆进了 HTML。第二是在线客服和营销插件。商务通、53 客服、美洽这类悬浮客服在国内站几乎是标配,很多版本直接把一大段 JS 加 base64 编码的图标内联进页面,单个插件就能贡献可观的体积。
第三是国产建站工具生成的冗余代码。织梦、帝国这类老牌 CMS 的模板,以及部分自助建站平台,生成的 HTML 里满是不必要的 div 嵌套、空标签、重复的行内 style,结构臃肿。第四是出海站最常见的元凶——WordPress 加页面构建器。Elementor、WPBakery 这类可视化构建器为了实现拖拽效果,会生成层层包裹的容器和大段内联关键 CSS,一个看起来普通的落地页,HTML 轻松就几百 KB 起步。
所以国内站和出海站的审计顺序应该反过来:别先假设自己安全,先用 curl -A "Googlebot" 你的页面 | wc -c 抓一遍未压缩字节,重点盯统计代码、客服插件、页面构建器这三个膨胀源,往往一查一个准。
真实翻车:一个 Shopify 出海站被 2MB 悄悄截断的排查实录
保哥处理过一个很典型的 Shopify 出海站案例,做的是户外装备,产品详情页特别长。现象是:部分长详情页底部的“品牌故事”“材质溯源”“第三方认证”这些 E-E-A-T 内容,在 Search Console 里明明显示已编入索引,可用 site 指令搜底部那几段的独特短语,却怎么都搜不到。
排查走的是 John Mueller 那套引号搜索法。先 curl -A Googlebot 抓页面,未压缩 HTML 体积 2.4MB,已经超线;再搜正文前段的句子,Google 能找到,搜“材质溯源”那一段的句子,搜不到——截断点确认就在 2MB 附近,后半截内容根本没进索引。
根因全是内容堆放方式不对。买家秀图片做成了 base64 直接内联在 HTML 里,本该走 Googlebot Image 单独抓取的图片,硬生生占满了 HTML 的字节预算;评论 app 把上千条评论全量服务端渲染内联,没做异步;底部“你可能还喜欢”一口气塞了 60 个产品卡片。这三样把最值钱的 E-E-A-T 内容挤到了 2MB 之外。修复也直接:base64 图片改回普通 img 引用,评论改异步、只内联前 15 条,推荐卡片从 60 个砍到 8 个,再把品牌故事、材质溯源、认证这些信任内容前置到参数表之后、评论之前。HTML 从 2.4MB 降到 410KB,一个月后这些长尾词的流量回来了。
这个案例有个特别本土化的教训:出海站老板普遍迷信“信任元素”,认证图标、买家秀、长篇评论拼命往详情页堆,以为堆得越多越显专业。可堆放方式不对,最值钱的 E-E-A-T 内容反而被推到截断线之外,Google 根本看不到,等于花力气堆了个寂寞。信任元素要堆,但得堆在前 2MB 以内,而且图片、评论这些重资产该外置的外置、该异步的异步,把宝贵的 HTML 字节留给真正需要被索引的文字。
常见问题解答
Q1:我的 HTML 用了 gzip 压缩,2MB 限制算压缩前还是压缩后?
算未压缩。Googlebot 接收的是 gzip/br 压缩流,但是解压后超过 2MB 就开始截断。所以即使你 gzip 后只有 200KB,未压缩 3MB 的 HTML 依然会被截断 33%。
Q2:Google 是从 HTML 顶部开始读 2MB 吗?还是会智能选择?
从顶部开始读字节流,到 2MB 就停。不会智能选择"重要部分"。所以"关键内容前置"原则才那么重要——你必须主动安排顺序。
Q3:HTML 嵌入的 SVG 是不是也计入 2MB?
计入。所有 inline 的内容都算 HTML 字节。复杂 SVG(如 icon 库、地图、信息图)建议外置为 .svg 文件或使用 SVG sprite。
Q4:CSR(客户端渲染)网站不受 2MB 影响吗?
表面看 CSR 站 HTML 体积小,但 Googlebot 现在会执行 JS 渲染。如果 JS 渲染后填充进 DOM 的内容超过 2MB,依然会被截断。Single Page App 的"无限滚动"页面是高危。
Q5:robots.txt 有体积限制吗?
有,500KB。超过后剩余规则被忽略。对正常站点来说远远够用,但聚合站、UGC 站如果用大量 user-agent 规则要留意。
Q6:sitemap.xml 有体积限制吗?
单个 sitemap 最大 50MB(未压缩)或 50000 个 URL。超过要拆分到多个 sitemap 通过 sitemap_index 索引。
Q7:Googlebot Image 抓取图片有大小限制吗?
Google 没公开具体数字,但实测单张图 5-10MB 都能抓。如果你的图超过 10MB,先用 imagemin / sharp 压一压,加载体验和 SEO 都好。
Q8:Bingbot、Yandex、Baidu 也有 2MB 限制吗?
各家爬虫的具体阈值没有公开,但通用经验是都有类似限制(普遍在 1-5MB 区间)。优化 HTML 体积是跨搜索引擎通用最佳实践,不只为 Google。
Q9:怎么检测我的页面是不是已经被截断索引了?
三种方法:用 John Mueller 的引号搜索法(搜页面后半段一句话,看 Google 能不能找到);在 Google Search Console 的 URL 检查里看"已抓取版本"的渲染源码长度;用 site:yoursite.com "页面尾部独特词" 看是否被索引。
Q10:HTML 体积优化和 Core Web Vitals 哪个更优先?
对绝大多数站点是 Core Web Vitals 更优先,因为它影响所有用户的真实体验。HTML 体积只在"页面 > 1.5MB"时才需要专门处理。但两者经常同源——一个 HTML 膨胀严重的页面,LCP、CLS 通常也都不好。先做 Core Web Vitals 审计,顺便检查 HTML 体积。
小结
Google 这次通过播客和文档更新透露的信息,对技术 SEO 从业者有三个核心启示:
第一,Google 的爬虫系统是灵活的、可配置的、多层次的。它不是一个固定参数的"铁板一块",而是一个类似 SaaS 的服务架构,不同的客户端(Google 搜索、Google 图片、Google 新闻等)有不同的配置。
第二,限制的目的是保护 Google 自身的基础设施,而非惩罚网站。理解这一点有助于你以正确的心态应对这些限制——它们不是 SEO 障碍,而是系统工程的合理约束。
第三,静默截断是最大的隐患。Google 不会在 Search Console 中告诉你"你的页面被截断了"。你必须主动检测、主动优化。使用 HTML 大小检测器等工具定期检查关键页面,是每个技术 SEO 从业者的基本功。
HTML 大小优化的优先级在技术 SEO 中不算最高——它远不如 Core Web Vitals、索引管理、结构化数据等议题重要。但它是一个低成本、高确定性的优化项。花半天时间审计和修复,就能彻底消除一个潜在的索引盲区。这种投入产出比,非常值得。
权威参考资料
本文标题:《Googlebot抓取2MB限制:8步实战优化指南》
本文链接:https://zhangwenbao.com/googlebot-crawl-limits-2mb-deep-analysis.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0