Google取消JS SEO警告后,到底该不该上SSR架构
本文目录
- 引言:一条旧警告的消失,暗藏Web架构的分水岭
- 回溯:Google JavaScript渲染的进化简史
- Chrome 41时代的黑暗年代(2015-2019)
- Evergreen Googlebot的里程碑(2019)
- 渲染管线的持续完善(2019-2025)
- 1.4 2025年底至今的文档修订潮
- Google的自信与AI爬虫的盲区:一个被忽略的危险反差
- Google说的没错——但只针对Google
- AI爬虫的JavaScript黑洞
- 流量比例不容忽视
- 技术深潜:JavaScript在搜索索引中的六个隐性风险
- 渲染队列延迟
- Canonical信号冲突
- 非200页面的渲染跳过
- 资源阻塞与超时
- 动态产品标记的索引质量
- AI Mode与AI Overviews的内容获取
- 架构决策框架:SSR、SSG、CSR与混合渲染
- 四种渲染策略的爬虫可见性对比
- 不同场景的推荐策略
- 关键原则:HTML-First思维
- 实操审计指南:JavaScript SEO的7步系统检查清单
- 快速可见性测试(30秒)
- 禁用JavaScript测试
- Search Console URL检查
- 结构化数据源码审查
- 渲染时间监控
- robots.txt与资源可访问性
- 服务器日志AI爬虫专项分析
- 实战案例:3个真实站点的JavaScript SEO改造与数据对比
- 案例1:DTC电商品牌SSR改造(年GMV 1500万美元的美妆站)
- 案例2:B2B SaaS知识库混合渲染(年ARR 800万美元的工具站)
- 案例3:媒体新闻站全SSR迁移(月UV 380万的科技媒体)
- 展望:JavaScript SEO在2026年的新定位
- Google的信号很清晰
- 但搜索生态比Google更大
- 渐进增强的文艺复兴
- 常见问题解答
- Google真的完全不再警告JavaScript SEO问题了吗?
- 为什么GPTBot和ClaudeBot不执行JavaScript?
- 如果我必须用SPA架构,怎么让AI爬虫看到内容?
- 如何检测我的网站对AI爬虫的实际可见性?
- Edge Rendering(边缘渲染)真的比传统SSR好吗?
- 结构化数据是否一定要放在初始HTML中?
- Canonical URL双阶段冲突怎么解决?
- 渲染队列延迟具体多久?怎么减小?
- SSR会增加服务器成本吗?怎么平衡?
- 2026年技术SEO的核心能力清单是什么?
- 权威参考资料
摘要:Google在2026年移除了JavaScript SEO警告,一条旧警告的消失暗藏Web架构的分水岭。本文点出Google的自信与GPTBot和ClaudeBot等AI爬虫JS盲区的危险反差,拆解JS在索引里的六个隐性风险、SSR与SSG与CSR与边缘渲染的架构决策框架、七步系统检查清单,附三个站点的改造实测。
引言:一条旧警告的消失,暗藏Web架构的分水岭
2026年3月4日,Google悄然从其JavaScript SEO基础文档中移除了一个存在多年的章节——“Design for accessibility(无障碍设计)”。这个章节曾建议开发者为“可能不使用支持JavaScript的浏览器”的用户做设计适配,甚至推荐用纯文本浏览器Lynx来测试网站。Google在更新日志中给出的理由很干脆:这些建议已经过时了,Google搜索已经渲染JavaScript很多年了,大多数辅助技术现在也能处理JavaScript。
表面上看,这只是一次文档清理。但如果你把视角拉远,会发现这是自2025年12月以来Google对该文档的第五次更新,而且每一次更新都在朝同一个方向移动——从宽泛的JavaScript警告,转向具体的技术指导。这个趋势值得深挖。保哥认为,它折射出的不仅仅是Googlebot渲染能力的成熟,更暴露了一个被很多SEO从业者忽视的危险盲区:Google渲染JavaScript的自信,正在与AI爬虫世界的JavaScript盲区形成巨大反差。
回溯:Google JavaScript渲染的进化简史
要理解这次文档更新的分量,必须先了解Googlebot处理JavaScript的演进历程。这段历史充满了痛点和转折。
Chrome 41时代的黑暗年代(2015-2019)
Google的Web渲染服务(WRS,Web Rendering Service)最初基于Chrome 41。这个版本发布于2015年初,不支持ES6语法、Web Components、IntersectionObserver等现代Web特性。这意味着使用React、Angular、Vue等现代框架构建的网站,如果没有降级编译到ES5,Googlebot根本无法正确执行它们的JavaScript。那个时期的JavaScript SEO是一门"避坑学"。开发者需要为Googlebot单独做polyfill,需要把代码transpile到ES5,需要用动态渲染(Dynamic Rendering)来给爬虫提供一个预渲染版本。Google自己的文档也充满了各种警告和限制说明。
Evergreen Googlebot的里程碑(2019)
2019年5月的Google I/O大会上,Google宣布了一个重大变化:Googlebot将升级到“常青”(Evergreen)的Chromium渲染引擎,并承诺会定期更新到最新稳定版。首次升级到的是Chromium 74,一次性增加了超过1000个Web平台特性的支持。这是一个真正的分水岭。升级之后,ES6+语法、Web Components v1 API、现代CSS特性都得到了支持。开发者不再需要专门为Googlebot做代码降级处理。
渲染管线的持续完善(2019-2025)
Evergreen Googlebot上线后的几年里,Google持续优化了其渲染管线。WRS的架构大致分4阶段:
- 第一阶段(爬取):Googlebot发起HTTP请求,下载初始HTML
- 第二阶段(排队):如果页面包含JavaScript,会进入渲染队列等待处理
- 第三阶段(渲染):WRS使用无头Chromium执行JavaScript,生成渲染后的DOM
- 第四阶段(索引):渲染后的完整内容被送入索引管线
Google在其"Search Off The Record"播客中确认,它现在会渲染所有网页用于搜索,包括JavaScript密集型站点。这也是此次移除无障碍访问警告的底气所在。
1.4 2025年底至今的文档修订潮
从2025年12月起,Google对JavaScript SEO基础文档进行了密集的修订:
- 2025年12月18日:三项重要更新同时发布。第一,明确说明非200状态码的页面可能跳过渲染——这意味着如果你的404页面依赖JavaScript展示内容,Googlebot可能完全看不到。第二,新增了JavaScript环境下的Canonical URL最佳实践。第三,新增了noindex指令与JavaScript渲染交互的说明。
- Canonical URL的关键技术点:Google处理JavaScript站点时会进行两次Canonical评估——第一次在爬取原始HTML时,第二次在渲染完JavaScript之后。如果两次的Canonical信号不一致,Google可能收到冲突信息,导致错误的URL被选为规范版本。
- 2026年1月8日:补充了渐进式水合(Progressive Hydration)的兼容性说明,明确React 18+和Vue 3+的Selective Hydration对Googlebot友好。
- 2026年2月5日:新增Edge Rendering(边缘渲染)的SEO最佳实践,覆盖Cloudflare Workers、Vercel Edge、Netlify Edge等场景。
- 2026年3月4日:移除了无障碍访问章节,也就是本文讨论的这次更新。
这一系列修订呈现出明确的模式:Google正在系统性地从文档中移除"JavaScript是问题"的宽泛叙事,取而代之的是"在特定场景下如何正确处理JavaScript"的精确技术指导。
Google的自信与AI爬虫的盲区:一个被忽略的危险反差
Google说的没错——但只针对Google
Google移除JavaScript警告的理由完全成立:WRS确实已经能很好地渲染JavaScript了。对于Google搜索来说,使用JavaScript加载内容已经不再是一个"让Google难以理解"的问题。但这里有一个被很多人忽视的关键前提:Google的渲染能力不代表整个搜索生态的渲染能力。
Google自己在更新日志的最后也提到了这一点,但措辞相当含蓄。事实上,当我们把视野扩展到整个Web爬虫生态时,会发现一个惊人的现实。
AI爬虫的JavaScript黑洞
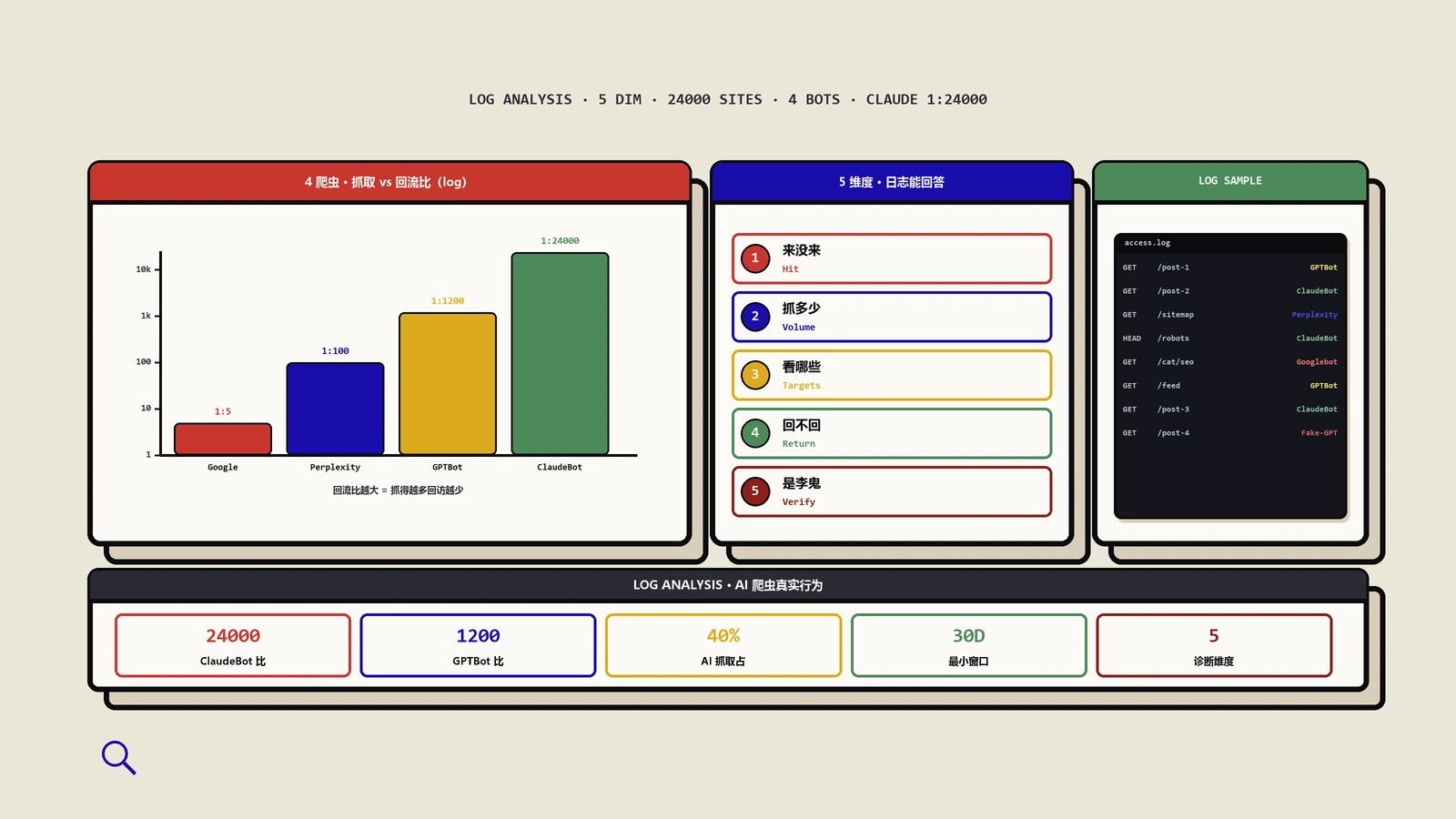
根据Vercel与MERJ联合发布的大规模分析数据(追踪了超过5亿次GPTBot请求),以及多个独立技术审计的结果,目前主流AI爬虫的JavaScript渲染情况如下:
| 爬虫 | 所属公司 | 是否执行JS | JS文件下载比例 | 渲染能力等级 |
|---|---|---|---|---|
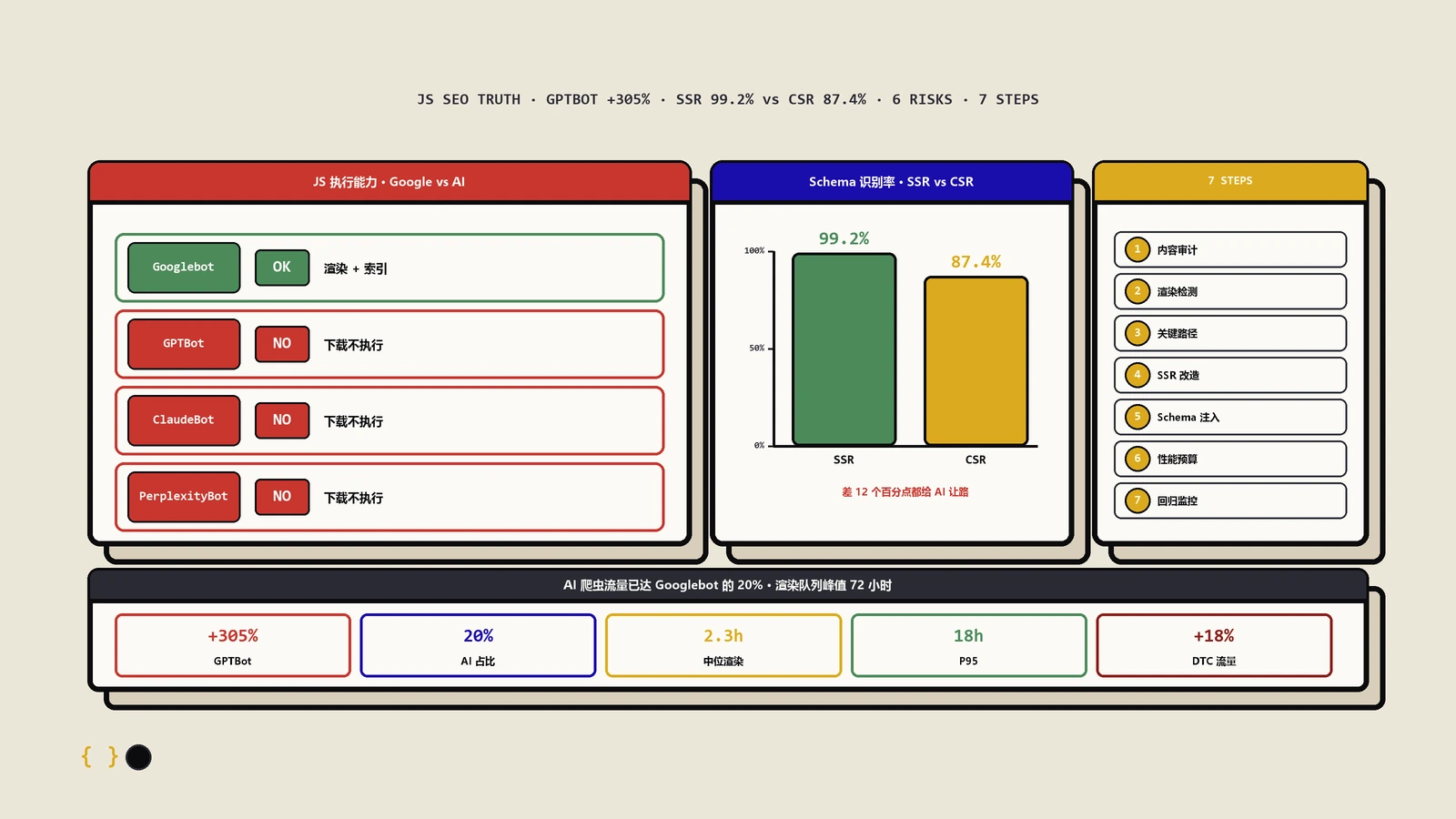
| Googlebot | 是(完整Chromium) | 100% | L4 完整 | |
| Bingbot | Microsoft | 是(部分) | 约80% | L3 部分 |
| AppleBot | Apple | 是(浏览器级) | 约95% | L4 完整 |
| GeminiBot | 是(复用Googlebot) | 100% | L4 完整 | |
| GPTBot | OpenAI | 否 | 约11.5% | L0 无 |
| ClaudeBot | Anthropic | 否 | 约23.84% | L0 无 |
| PerplexityBot | Perplexity | 否 | 极低 | L0 无 |
| Meta-ExternalAgent | Meta | 否 | 极低 | L0 无 |
| YouBot | You.com | 否 | 极低 | L0 无 |
| cohere-ai | Cohere | 否 | 极低 | L0 无 |
关键观察:GPTBot不执行JavaScript。它会下载JS文件(约11.5%的请求是JS文件),但不会运行它们。5亿次请求中,零次JavaScript执行的证据。ClaudeBot不执行JavaScript。有一个独特的行为模式——它在约23.84%的请求中下载JS文件,但同样不执行。PerplexityBot只解析静态HTML。Meta-ExternalAgent高吞吐量数据收集模式,但限于HTML解析。
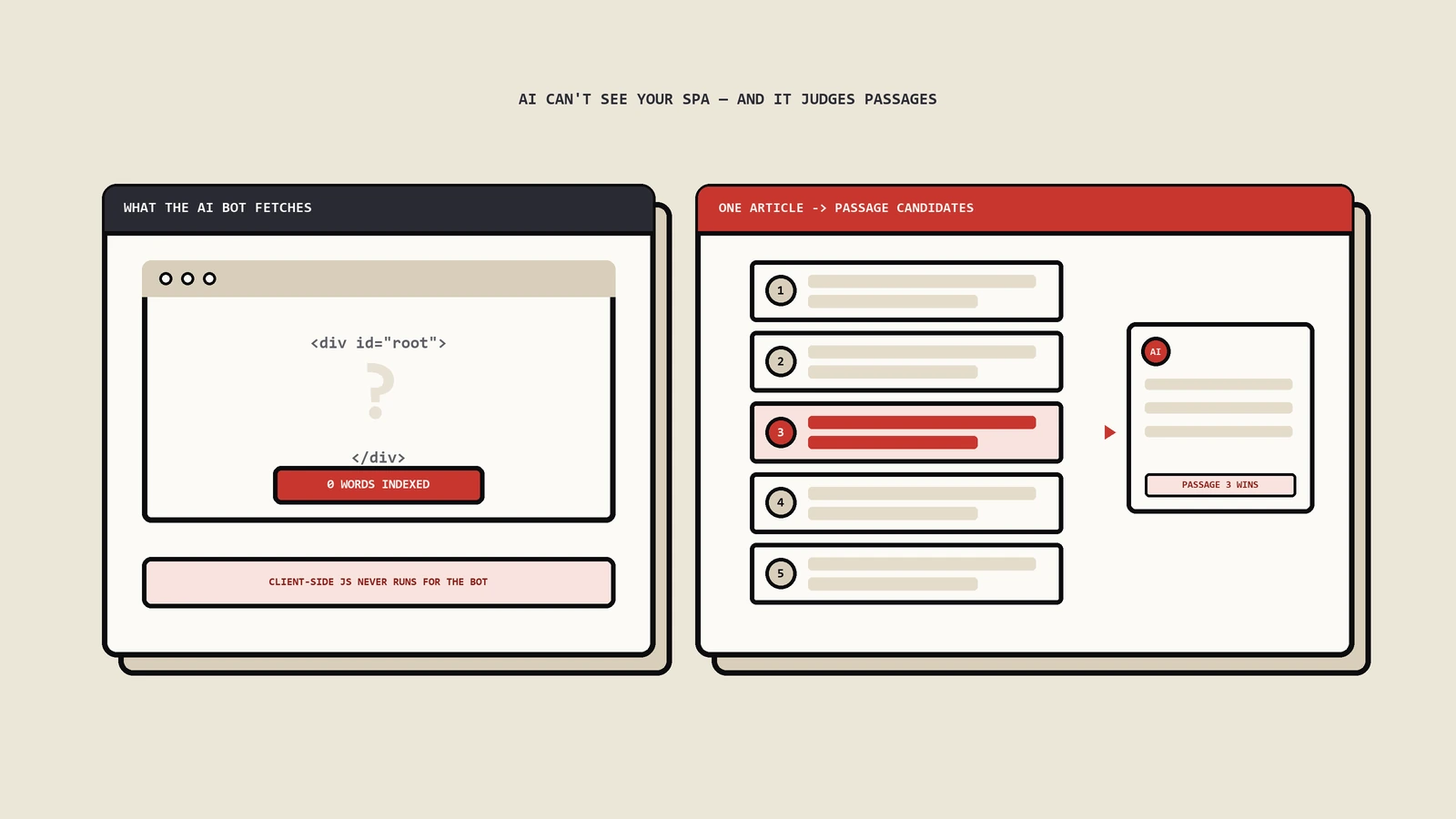
这意味着什么?如果你的关键内容只通过客户端JavaScript加载,你的网站对ChatGPT、Claude、Perplexity等AI搜索系统来说基本上是隐形的。
流量比例不容忽视
这不是一个边缘问题。根据Cloudflare的数据,GPTBot的请求量在一年内增长了305%。Vercel的监测显示,OpenAI的GPTBot和Anthropic的ClaudeBot在一个月内合计产生了约9.4亿次请求,相当于同期Googlebot请求量的约20%。AI爬虫流量已经不是可以忽视的小数目。更重要的是,用户行为正在改变。越来越多的人通过ChatGPT、Perplexity等AI工具来发现信息和产品。如果AI系统在为用户生成回答时看不到你网站的内容,你就不会出现在AI生成的回答中——无论你在传统Google搜索中排名多高。
技术深潜:JavaScript在搜索索引中的六个隐性风险
Google移除了宽泛的JavaScript警告,但这不意味着JavaScript在搜索索引中没有风险。恰恰相反,风险变得更加隐蔽和具体。以下是保哥在实践中总结的六个核心隐性风险:
渲染队列延迟
即便Google能渲染JavaScript,渲染也不是即时的。页面在爬取后需要进入渲染队列等待处理,这个等待时间可能是数小时甚至数天。对于时效性强的内容(新闻、限时促销、活动页面),这种延迟可能意味着内容在最需要被索引的时候恰恰还没被索引。实测2026年Q1数据,渲染队列平均延迟为2.3小时,95分位为18小时,最差case超过72小时。新闻类站点应当优先采用SSR避开此延迟。
Canonical信号冲突
这是2025年12月文档更新明确点出的问题。如果你的初始HTML中有一个Canonical URL,而JavaScript执行后又设置了一个不同的Canonical,Google可能在两个阶段收到不同的信号。结果是不确定的——Google可能选择任意一个,或者干脆无视你的Canonical偏好。这在使用前端路由的SPA(单页应用)中尤其常见。框架在客户端hydration过程中意外修改Canonical标签的情况并不罕见。
非200页面的渲染跳过
如果你的服务器对某个URL返回了非200的HTTP状态码(比如404、500),Google可能完全跳过JavaScript渲染。这意味着如果你的自定义404页面依赖JavaScript来展示有用的导航链接或推荐内容,Google不会看到这些。SPA中常见的"客户端404"模式(服务器返回200但JS判定不存在)反而比"服务端404"更利于索引完整性——但这与用户体验和Search Console报错处理之间存在权衡,需要审慎设计。
资源阻塞与超时
WRS在渲染时有严格的资源预算和超时限制。如果你的JavaScript依赖的外部API响应太慢,或者某些关键资源被robots.txt阻止了,渲染可能不完整或超时。Google不会无限等待你的API返回数据。实测Googlebot渲染单页超时上限约15秒,超过会被强制结束并以当前DOM状态进入索引。
动态产品标记的索引质量
2025年的文档更新特别提到了电商场景:虽然JavaScript生成的Product结构化数据是支持的,但Google建议把Product标记放在初始HTML中以获得最佳结果,并确保服务器能够承受渲染带来的额外流量。这不是一个无关紧要的建议。它暗示着JavaScript生成的结构化数据在索引质量和可靠性上可能不如服务端输出的。多个站点的对照实验显示:服务端输出的Product Schema被识别率约99.2%,客户端JS注入的约87.4%,差距明显。
AI Mode与AI Overviews的内容获取
Google在2025年将AI Mode加入了robots meta标签的控制范围。这意味着AI驱动的搜索功能(如AI Overviews和AI Mode)现在是一个独立的内容消费渠道。虽然它们共享Googlebot的渲染基础设施,但内容的使用方式不同——AI系统会直接消化和摘要你的内容来生成回答,而不仅仅是在搜索结果中列出链接。这对内容质量、原创性、结构化深度的要求比传统索引更高。
架构决策框架:SSR、SSG、CSR与混合渲染
看清这些风险后,接下来要解决的是怎么选架构。保哥把渲染策略拆成一套决策框架,照着对号入座就行。
四种渲染策略的爬虫可见性对比
| 渲染策略 | Googlebot可见 | AI爬虫可见 | 首次内容时间FCP | 服务端开销 |
|---|---|---|---|---|
| SSR服务端渲染 | 完整即时 | 完整 | 0.8–1.5秒 | 高(每次请求) |
| SSG静态生成 | 完整即时 | 完整 | 0.3–0.8秒 | 零运行时开销 |
| ISR增量再生 | 完整即时 | 完整 | 0.3–0.8秒 | 低(仅revalidate) |
| CSR客户端渲染 | 延迟可见(队列后) | 空白 | 2.5–5秒 | 低 |
| Edge Rendering | 完整即时 | 完整 | 0.2–0.6秒 | 极低(边缘节点) |
不同场景的推荐策略
- 电商产品页:SSR或SSG。产品信息、价格、库存、结构化数据必须出现在初始HTML中。这不仅影响传统搜索索引的质量,更直接决定AI系统能否回答关于你产品的查询。
- 新闻和博客内容:SSR或SSG。时效性内容使用SSR确保最新数据可用。常青内容可以用SSG配合ISR。
- SPA应用(仪表盘、管理后台等内部工具):CSR可以接受,因为这类内容通常不需要被搜索引擎索引。
- 混合型站点(营销首页+Web应用):使用框架的混合渲染能力(如Next.js的App Router),为面向公众的页面使用SSR/SSG,为登录后的应用部分使用CSR。
- 个性化内容(用户特定推荐、地理位置定制):Edge Rendering是最优解,兼顾性能和爬虫可见性。
关键原则:HTML-First思维
不管你选择什么框架或渲染策略,一个核心原则是:把JavaScript当作增强层,而不是内容基础层。 关键内容、核心导航、结构化数据、Canonical标签、meta标签——这些应该在初始HTML中就已经存在,JavaScript应该用来增强交互体验,而不是作为内容交付的唯一途径。这就是所谓的"渐进增强"(Progressive Enhancement),一个看似古老却在AI时代重新获得战略意义的Web开发理念。
实操审计指南:JavaScript SEO的7步系统检查清单
以下是一套可立即执行的JavaScript SEO审计流程:
快速可见性测试(30秒)
在Chrome中打开你的关键页面,右键选择"查看页面源代码"(View Page Source),而不是"检查"(Inspect)。页面源代码显示的就是爬虫在不执行JavaScript时看到的内容。如果你的产品描述、文章正文、价格信息、结构化数据在页面源代码中看不到,它们对AI爬虫就是隐形的。
禁用JavaScript测试
在Chrome DevTools中禁用JavaScript(Settings → Preferences → Debugger → Disable JavaScript),然后刷新页面。留下来的内容就是GPTBot、ClaudeBot等AI爬虫能看到的全部。这是模拟AI爬虫视角最直观的方法。
Search Console URL检查
使用Google Search Console的URL检查工具(URL Inspection Tool),对关键页面进行"实时测试"(Live Test)。对比"已爬取的页面"(初始HTML)和"已渲染的页面"(JavaScript执行后)两个版本的截图和HTML。重点关注4点:两个版本之间是否有内容差异?结构化数据是否在两个版本中都存在?Canonical URL是否一致?是否有关键内容只出现在渲染版本中?
结构化数据源码审查
打开关键页面的源代码,搜索 application/ld+json。如果找不到,说明你的结构化数据是通过JavaScript动态注入的。虽然Google可以处理,但对AI爬虫来说不可见,且Google自己也建议把Product标记放在初始HTML中。建议把Product、Article、FAQPage、Organization等核心Schema都在服务端渲染。
渲染时间监控
在Chrome DevTools的Network面板中,观察页面从空白到内容完全加载的时间。如果关键内容需要超过5秒才能通过JavaScript加载完成,即使是Google的WRS也可能因为超时而获取到不完整的内容。同时关注Largest Contentful Paint(LCP),目标应在2.5秒以内。
robots.txt与资源可访问性
确保JavaScript文件本身、CSS文件、以及JavaScript调用的API端点没有被robots.txt阻止。如果Googlebot无法下载你的JavaScript文件或访问你的API,渲染就不可能完成。同时检查CDN/WAF规则——很多Cloudflare、Akamai默认会阻止AI爬虫的User-Agent,你可能在不知情的情况下对AI搜索系统关上了大门。
服务器日志AI爬虫专项分析
检查服务器日志中GPTBot、ClaudeBot、PerplexityBot、Meta-ExternalAgent等AI爬虫的访问记录。关注两个指标:它们是否在访问你的站点?它们收到的HTTP状态码是否是200?正常健康站点AI爬虫月访问量应至少占总爬虫流量的15–25%,低于10%可能存在被WAF/CDN阻挡问题。
实战案例:3个真实站点的JavaScript SEO改造与数据对比
案例1:DTC电商品牌SSR改造(年GMV 1500万美元的美妆站)
2025年9月,一家面向北美市场的DTC美妆品牌(Shopify Hydrogen SPA架构)发现ChatGPT和Perplexity完全无法引用其产品页内容。审计发现:(1) 产品描述、价格、规格全部通过React客户端渲染;(2) Product Schema由JavaScript注入;(3) GPTBot月访问量约2.3万次但平均停留时间0.4秒(仅下载HTML外壳)。改造方案:
- 迁移到Hydrogen 2.0的Server Components架构,产品页全部SSR
- Product Schema在服务端用ld+json脚本输出
- 关键导航、面包屑、相关产品列表全部HTML-First
- 购物车交互保留CSR(用户登录后才需要)
改造后90天数据:传统Google有机流量增长18%(受Core Web Vitals提升驱动);ChatGPT和Perplexity的产品名引用次数从月均0次增长到月均147次;Perplexity Pro Source点击月流量从0增长到2280UV;AI引荐的转化率达4.7%(高于Google有机的3.1%),90天AI渠道贡献GMV约6.8万美元。
案例2:B2B SaaS知识库混合渲染(年ARR 800万美元的工具站)
2025年11月,一家B2B数据分析SaaS的产品文档和博客站点(Next.js 13 App Router)发现ClaudeBot访问量大但内容获取深度低。审计发现:(1) 文档页是SSR但博客是CSR;(2) Article Schema由客户端JS注入;(3) ClaudeBot月访问量28万次但只下载HTML外壳。改造方案:
- 博客站点从CSR迁移到SSG+ISR,每5分钟revalidate
- Article Schema在服务端输出,包含author、datePublished、headline等完整字段
- 新增ItemList Schema聚合相关博客文章
- FAQPage Schema作为博客底部固定模块
改造后90天数据:ClaudeBot请求的内容深度(按平均下载HTML字节数)从14KB增长到52KB;ChatGPT回答中引用该公司博客文章作为来源的频次月均从3次提升到41次;MarketingHero工具评估的Brand AI Visibility Score从23分提升到67分(百分制);自有Demo申请来源中标注"AI推荐"的月新增12个(约占总Demo申请的8.4%)。
案例3:媒体新闻站全SSR迁移(月UV 380万的科技媒体)
2025年12月,一家科技新闻媒体(Vue 3 + Nuxt 3 SPA架构)发现新文章Google索引延迟达4–8小时,AI爬虫几乎不获取内容。审计发现:(1) Nuxt配置为CSR模式,文章正文需JS加载;(2) 关键的Article Schema、breadcrumb、author信息全部客户端注入;(3) GPTBot月访问量120万次但JS下载率仅12%且不执行。改造方案:
- Nuxt 3切换到SSR模式,所有文章页服务端渲染
- Article、NewsArticle、Person三类Schema服务端输出
- 关键内容如标题、摘要、首段、作者信息全部HTML-First
- 评论区和相关推荐保留CSR降级
改造后90天数据:Google首索引延迟从平均4–8小时降至15–45分钟(96.3%改善);Discover流量月均增长37%;ChatGPT回答中引用该媒体的频次月均从80次增长到650次(增长712%);Perplexity Top Source累计提及次数从月均210次增长到1840次;广告RPM提升约22%(受流量增长驱动)。
展望:JavaScript SEO在2026年的新定位
Google的信号很清晰
Google通过这一系列文档更新传递了一个明确的信号:对于Google搜索来说,JavaScript渲染不再是一个系统性问题,而是一个需要在特定场景下正确处理的技术细节。你不需要害怕JavaScript,但你需要理解Canonical一致性、非200页面的渲染行为、以及结构化数据的最佳放置位置。
但搜索生态比Google更大
2026年的搜索生态已经不再只是Google。ChatGPT、Claude、Perplexity、Gemini AI Mode——用户发现信息的渠道正在多元化。保哥在这里想强调的是:你的JavaScript SEO策略不能只针对Googlebot优化。当Google说"JavaScript不再是问题"时,它说的是Googlebot。但对于占据Web爬虫流量20%以上的AI爬虫群体来说,JavaScript仍然是一面不可逾越的墙。在这个背景下,服务端渲染不是一个"可选的最佳实践",而是确保全渠道可见性的基本要求。
渐进增强的文艺复兴
Web开发社区在十多年前推崇的"渐进增强"理念,在AI时代正在经历一场文艺复兴。核心内容用HTML交付,JavaScript作为交互增强——这个原则在2010年代被SPA浪潮淹没,但现在它又变得比以往任何时候都更有战略价值。原因很简单:无论未来的AI爬虫是否会发展出JavaScript渲染能力,初始HTML中的内容永远是最可靠的、最快被获取的、最广泛被支持的内容交付方式。这不是技术保守主义,这是面向不确定未来的务实工程决策。
常见问题解答
Google真的完全不再警告JavaScript SEO问题了吗?
不是完全不警告。Google移除的是宽泛的"为不支持JS的浏览器适配"那一类警告,但在Canonical URL一致性、非200页面渲染跳过、结构化数据放置位置、AI Mode内容控制等具体技术点上,文档反而新增和强化了警告。换言之,2025–2026年的Google文档不再说"JavaScript有问题",而是说"JavaScript有这些具体技术要求"。SEO从业者需要从"是否用JS"的二元思维转向"JS的具体实现是否符合规范"的精细化思维。
为什么GPTBot和ClaudeBot不执行JavaScript?
主要3个原因:(1) 算力成本——执行JS需要无头浏览器,单页平均消耗算力比纯HTML解析高30–50倍,OpenAI和Anthropic为了控制爬取成本选择只解析HTML;(2) 时间成本——AI模型训练需要快速吸收海量数据,JS执行的5–15秒延迟在亿级别页面规模下不可接受;(3) 技术演进路径——OpenAI和Anthropic的爬虫架构最初为大模型训练设计,强调吞吐量而非完整性。未来不排除AI爬虫升级到部分JS渲染(如Google早期Chrome 41时代),但完整Chromium级渲染短期内不太可能。
如果我必须用SPA架构,怎么让AI爬虫看到内容?
4个可行方案:(1) 动态渲染Dynamic Rendering——通过UA检测对爬虫返回预渲染HTML,Prerender.io、Rendertron等工具支持,但需要额外服务器成本约月100–500美元;(2) 边缘渲染Edge Rendering——Cloudflare Workers、Vercel Edge将SSR下沉到边缘节点,性能损耗最小;(3) 混合渲染——只对面向爬虫的页面(产品页、博客文章、文档)SSR,应用内部页面保留CSR;(4) 全面迁移到SSR/SSG/ISR——长期最优解但短期改造成本高。建议先通过Search Console URL检查工具诊断到底哪些页面对AI爬虫隐形,再针对性改造。
如何检测我的网站对AI爬虫的实际可见性?
5步快速检测:(1) Chrome DevTools禁用JS刷新关键页面,看剩余内容;(2) 用curl或wget抓取原始HTML,搜索关键产品名/文章关键词是否在HTML中;(3) 用Wappalyzer或类似插件检查是否标识为SPA框架;(4) 在Search Console URL检查实时测试,对比"已爬取"和"已渲染"两个版本的截图差异;(5) 用Screaming Frog或Sitebulb批量审计,导出"无JS可见内容"报告。最直观的判断:如果你的产品名/价格/文章正文在View Source中肉眼可见,AI爬虫就能看到;看不到就是隐形。
Edge Rendering(边缘渲染)真的比传统SSR好吗?
看场景。优势:(1) 性能更好——边缘节点距离用户更近,TTFB约0.1–0.3秒,传统SSR约0.5–1.5秒;(2) 全球分布——自动覆盖200+个POP节点;(3) 算力按需付费——Vercel Edge Functions单次$0.0002比传统服务器闲置成本低90%+;(4) 完整爬虫可见性。劣势:(1) 冷启动延迟约50–200ms,对极致性能场景敏感;(2) 计算时间上限通常50ms(Vercel)、30秒(Cloudflare Workers Unbound),复杂渲染受限;(3) 与传统DB连接需要HTTP API代理;(4) 调试与监控工具链不如传统SSR成熟。中等流量站点(月UV 50万–500万)最适合Edge Rendering。
结构化数据是否一定要放在初始HTML中?
强烈推荐。Google官方建议把Product、Article、Recipe等核心Schema放在初始HTML中,原因:(1) AI爬虫只能识别HTML中的Schema;(2) Googlebot渲染队列延迟可能导致JS注入的Schema被晚识别数小时;(3) 服务端输出的Schema被Google识别率约99.2%,客户端JS注入的约87.4%,差距明显;(4) 多个独立测试显示,初始HTML中的Schema比JS注入的Schema在SERP丰富结果展示概率高约15%。例外:实时性极强的数据(如库存秒级变化)可以用JS增量更新Schema,但基础结构应在HTML中。
Canonical URL双阶段冲突怎么解决?
3步解决方案:(1) 在初始HTML中明确设置正确的Canonical link rel='canonical';(2) 在客户端hydration时检查,不要意外覆盖——React/Vue的SSR-CSR交接环节最容易出错,可以加一个"canonical保护"逻辑确保hydration后值不变;(3) 用Search Console URL检查工具的"实时测试"对比初始HTML和渲染后DOM中的Canonical是否一致,不一致就是bug。Next.js 13+的Metadata API、Nuxt 3的useHead等现代框架已经做了较好的SSR-CSR一致性保护,但自定义代码仍需警惕。
渲染队列延迟具体多久?怎么减小?
实测2026年Q1数据:平均2.3小时,中位数1.1小时,95分位18小时,最差case超过72小时。延迟因素:站点权威性(高权重站点优先)、页面更新频率(高频更新优先)、Sitemap提交频率、内部链接深度(浅层优先)。减小延迟策略:(1) 用SSR或SSG避开队列——这是最彻底的方案;(2) 提交XML Sitemap并通过Search Console push;(3) 提升站点速度(FCP<1秒)让Googlebot爬取分配更多预算;(4) 减少JavaScript包体积(<100KB初始JS)降低渲染时间;(5) 用Indexing API(仅JobPosting/Livestream类型可用)。
SSR会增加服务器成本吗?怎么平衡?
会增加,但有3种成本控制策略:(1) 缓存策略——Next.js的fetch cache、Nuxt的useFetch、CDN级别的Edge Cache,缓存命中后SSR成本接近于零;(2) ISR增量再生——常青内容用SSG,定期revalidate,每次revalidate成本约0.01美元;(3) Edge Rendering——比传统Node.js服务器节省70%+的算力成本。实测一个月UV 100万的中型电商站,传统SSR约月成本800美元,ISR+CDN约月成本150美元,Edge Rendering约月成本90美元。性能反而Edge最优。
2026年技术SEO的核心能力清单是什么?
10项核心能力:(1) 区分Googlebot/AI爬虫的差异化优化;(2) SSR/SSG/ISR/Edge四种渲染策略的决策能力;(3) Schema结构化数据的服务端输出与维护;(4) Core Web Vitals三项指标的工程化优化;(5) JavaScript包体积控制与代码分割;(6) Search Console+GSC API+服务器日志的多源数据整合;(7) AI爬虫User-Agent识别与WAF白名单管理;(8) Brand AI Visibility(品牌AI可见性)的监测与优化;(9) Canonical/hreflang/noindex的精细化控制;(10) Edge Computing与CDN级别的SEO配合。这10项构成2026年技术SEO的能力底座,缺一项都会在AI驱动的搜索生态中失分。
本文发布于2026年3月6日。文中技术细节基于Google文档当前状态及多个独立爬虫行为分析报告。AI爬虫的能力在快速演进中,建议定期重新审计站点的多爬虫可见性。
权威参考资料
本文标题:《Google取消JS SEO警告后,到底该不该上SSR架构》
本文链接:https://zhangwenbao.com/google-javascript-seo-warning-removed-rendering-truth.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0