AI爬虫到底有没有抓你的站?日志分析一步步挖真相
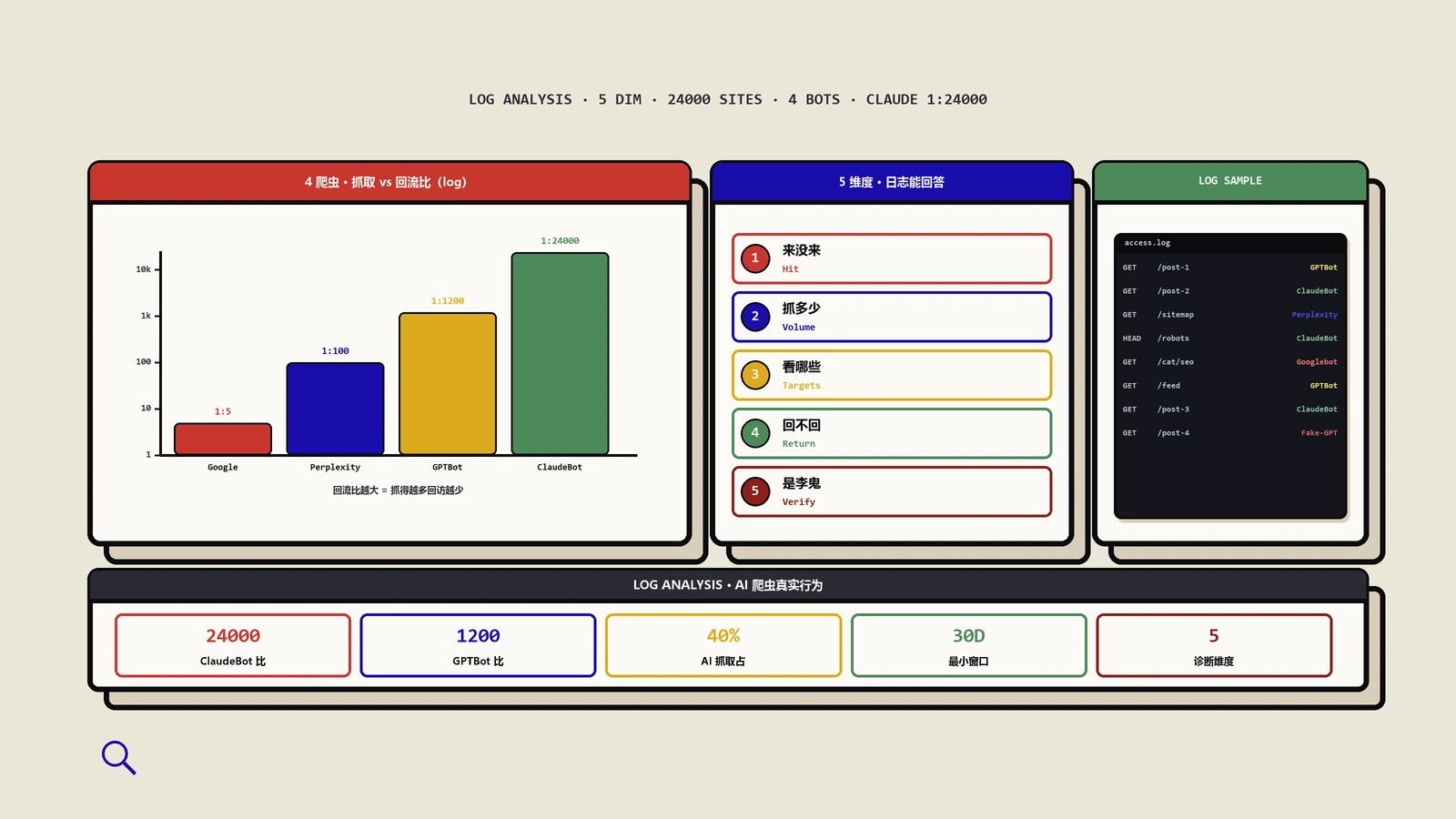
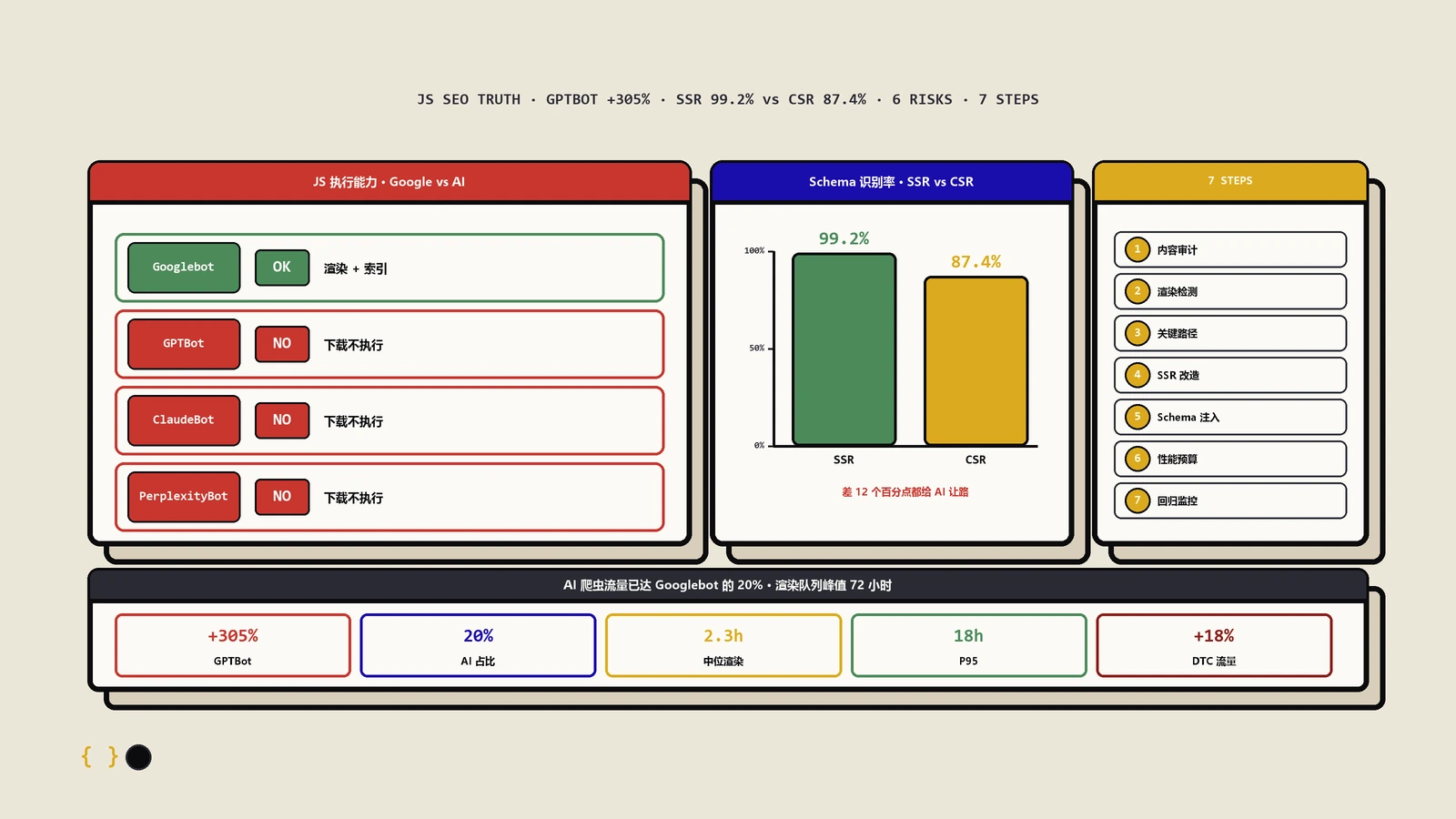
你的内容每天被AI爬虫抓走喂进ChatGPT和Claude的回答,但没有任何官方报表能让你看见这件事。这篇带你用服务器日志补上这块盲区:分清训练型与检索型爬虫为什么要区别对待、五层诊断怎么一步步深入、命令行和Python脚本怎么落地、日志为什么必须搬出主机长期存,以及robots.txt分层和迁移验真该怎么做。
标签
保哥笔记 Googlebot 标签下共 7 篇文章合集,含《AI爬虫到底有没有抓你的站?日志分析一步步挖真相》《Googlebot抓取2MB限制:8步实战优化指南》《User-Agent生成器怎么用?模拟Googleb》等,与 技术SEO、AI爬虫、Google渲染 主题密切相关,覆盖 SEO/GEO 实战角度的深度解析与可落地方案。
你的内容每天被AI爬虫抓走喂进ChatGPT和Claude的回答,但没有任何官方报表能让你看见这件事。这篇带你用服务器日志补上这块盲区:分清训练型与检索型爬虫为什么要区别对待、五层诊断怎么一步步深入、命令行和Python脚本怎么落地、日志为什么必须搬出主机长期存,以及robots.txt分层和迁移验真该怎么做。
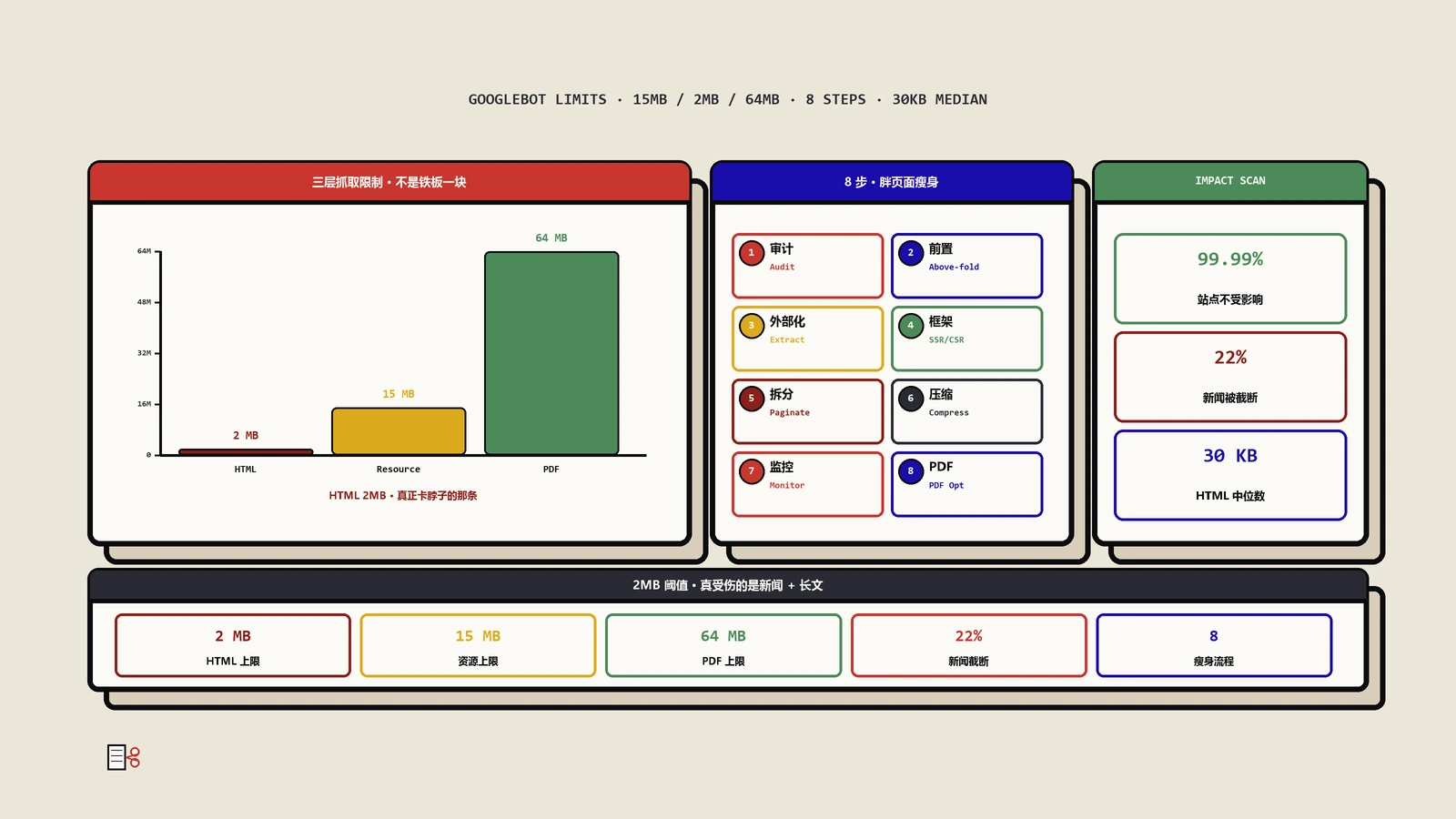
三层抓取限制体系(15MB/2MB/64MB)+静默截断陷阱+8步优化清单+前端框架内联state排查+财经新闻站真实案例+10条FAQ。
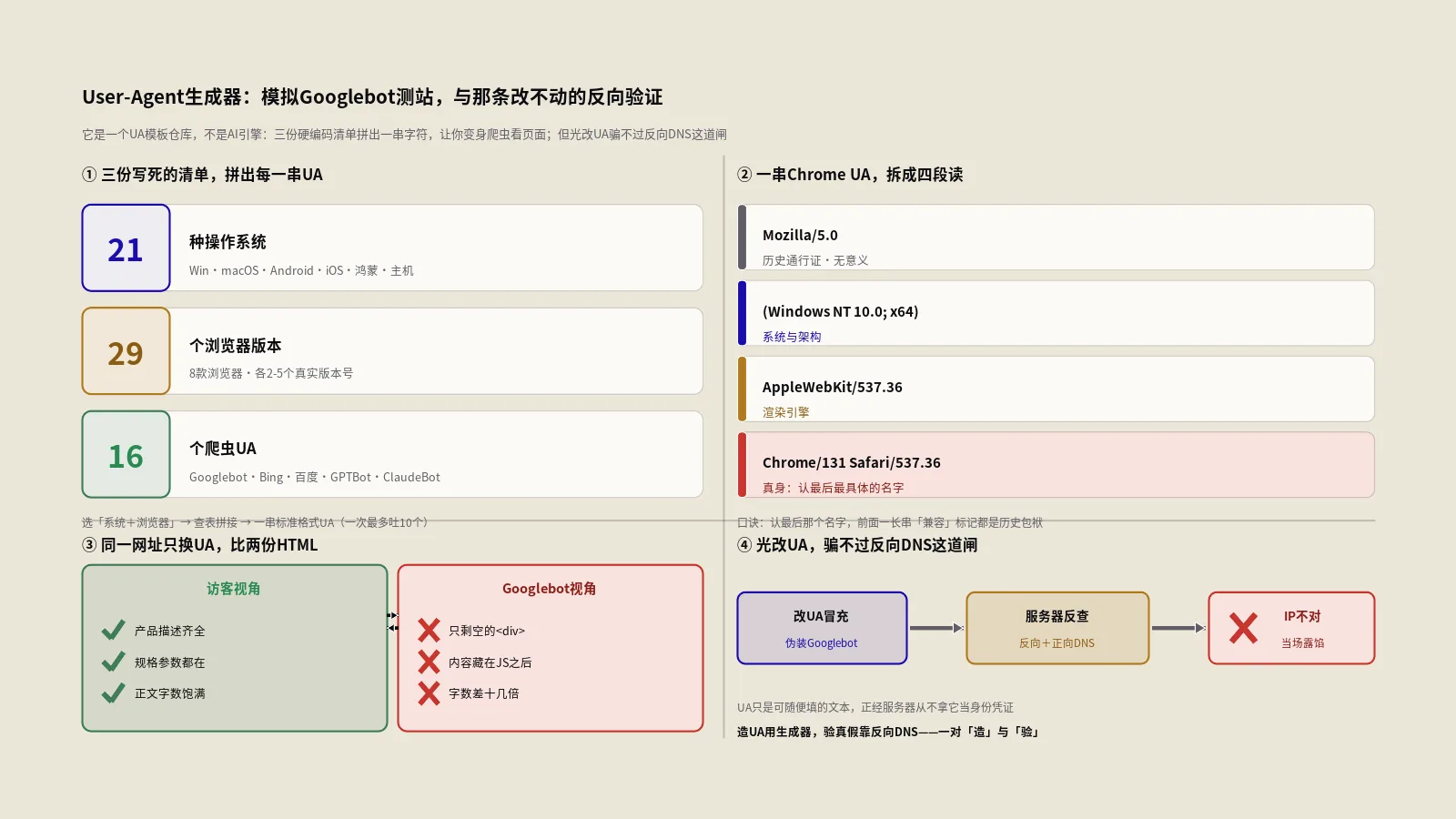
这是一款技术SEO常备的UA字符串工具:选好系统和浏览器,或直接挑一个搜索引擎蜘蛛,它就还你一串规范的身份标识。把它复制进curl或脚本,你就能以蜘蛛的视角重新打开自己的页面,看清收录异常、前端框架空壳、手机版错配这些只在爬虫眼里现形的毛病。
Google移除无障碍JS警告引发的Web架构分水岭。回溯Chrome 41到Evergreen Googlebot渲染演进、Canonical双阶段冲突、AI爬虫JS黑洞、HTML-First原则与7步审计清单。
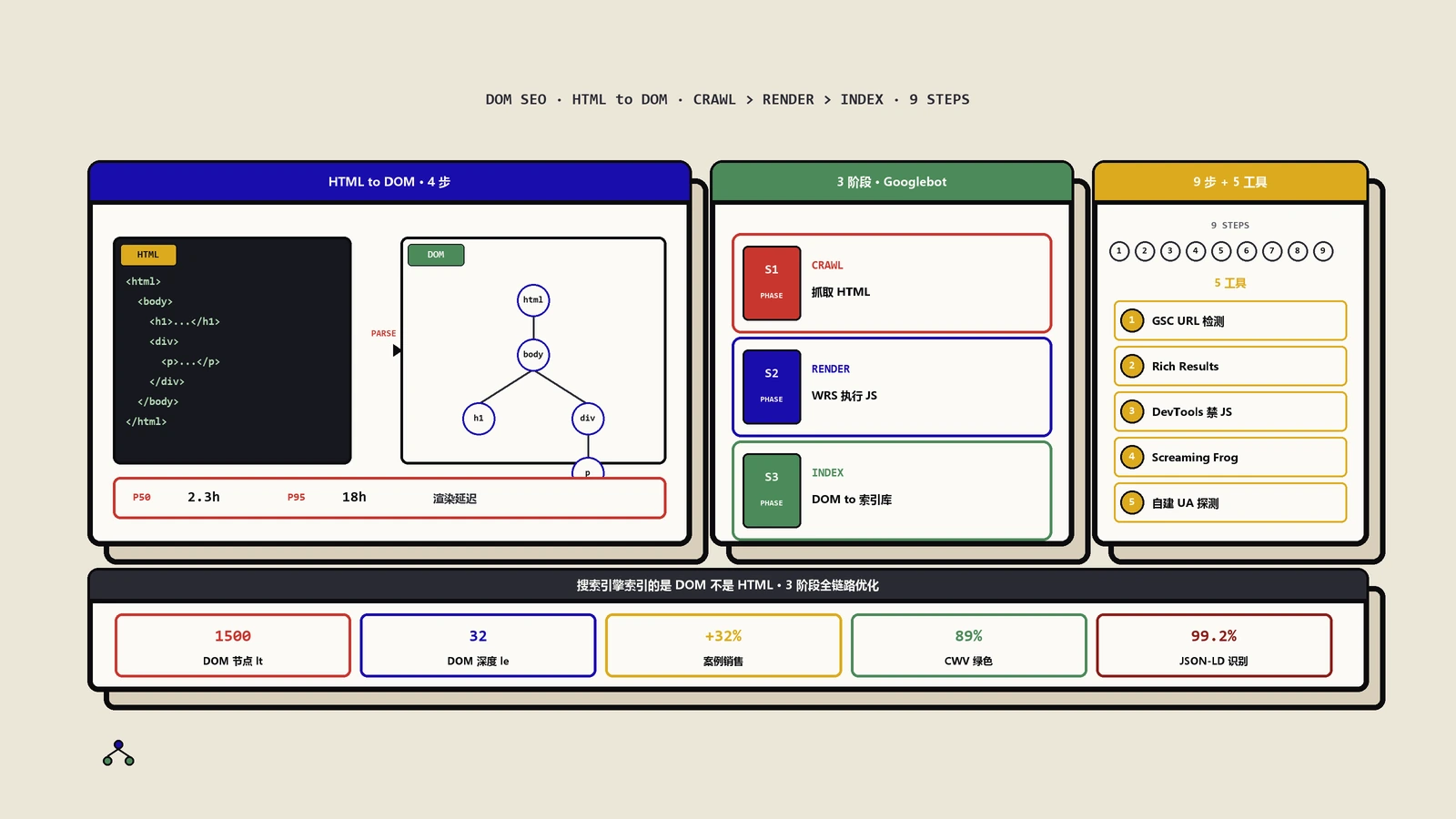
技术SEO必修课:从字节到DOM树的4步构建、WRS渲染机制、Headless Chromium、SSR/SSG/CSR/Edge渲染对比、TTDC新指标、AI时代DOM可见性优化策略与诊断Checklist。
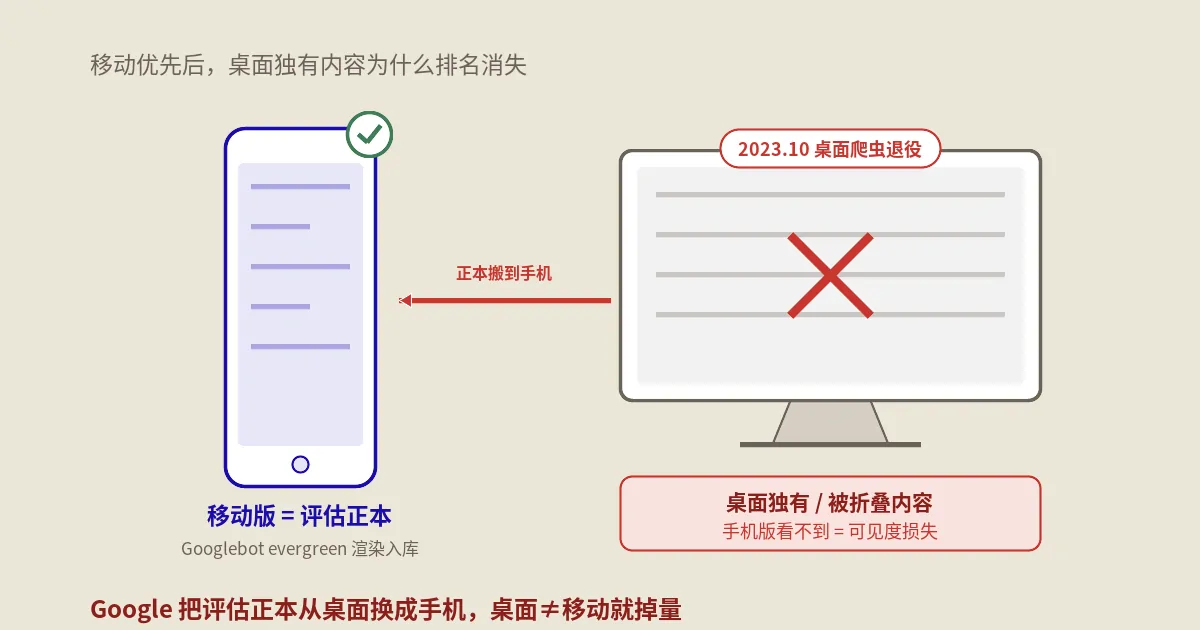
移动优先索引从2018年公开滚动到2023年彻底退役桌面爬虫,把整套排名底座的“页面”定义换掉了。本篇按算法机制、Googlebot渲染演变、桌面≠移动型掉量诊断三段拆开,附响应式、独立m.站、动态适配三型落地决策。
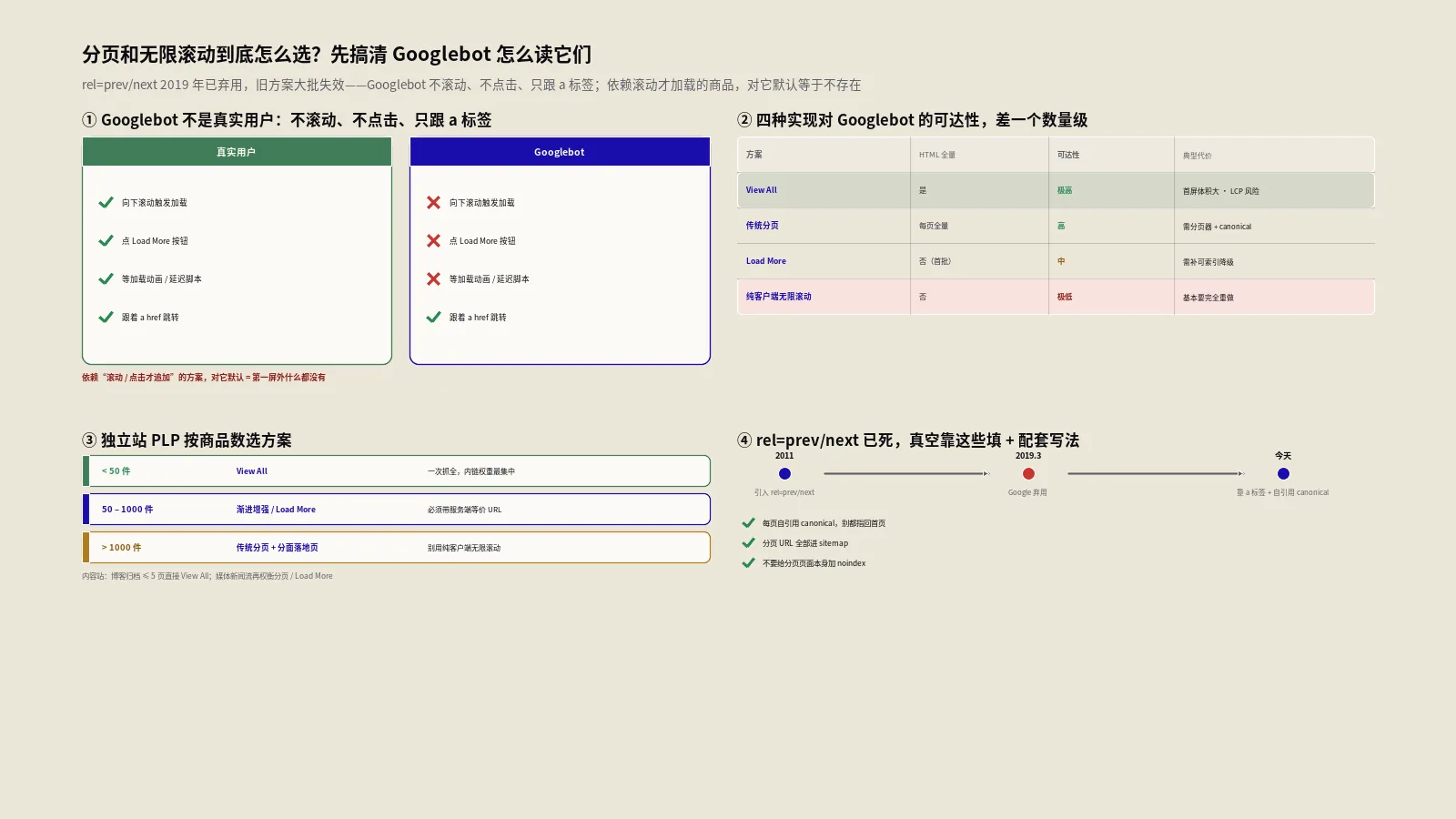
保哥做独立站SEO那些年,见过太多大型电商把无限滚动当默认选项,结果集合页深层商品页根本进不了Google索引。这事的根本不是哪种方案最好,而是搞清Googlebot怎么模拟浏览者向下翻、怎么读rel=prev/next死后的SEO信号、四种实现的索引覆盖率和权重稀释程度。本文按机制拆,附独立站PLP实测复盘。