AI爬虫到底有没有抓你的站?日志分析一步步挖真相
本文目录
- 为什么AI搜索时代,日志突然变得不可替代?
- 一条日志到底记录了什么?
- AI爬虫和传统爬虫,行为根本不是一回事?
- 光看到“来没来”还不够,它的行为在说什么?
- AI爬虫的“抓取-回流比”到底有多悬殊?
- 怎么从手头的日志,一步步把AI爬虫行为挖出来?
- 为什么短期日志会骗你,必须长期留存?
- 声称是GPTBot的请求,怎么知道不是李鬼?
- 拿到行为数据后,robots.txt该怎么分层管?
- 网站迁移后,日志要验哪几关?
- 日志查出问题后,怎么变成开发能照做的事?
- 日志分析的常见误区与进阶细节
- 常见问题解答
- AI搜索时代,日志文件分析为什么变得不可替代?
- 用看Googlebot的方法分析AI爬虫,会有什么问题?
- 为什么短期日志分析AI爬虫会得出错误结论?
- 主机日志只保留几天,怎么解决长期留存?
- 日志里看不到AI爬虫,是不是就一定说明它没来?
- AI爬虫消耗大量资源回流又极低,应该全部屏蔽吗?
- AI爬虫只抓首页和浅层页,深层内容怎么办?
- 权威参考资料
摘要:AI搜索没有Search Console。ChatGPT、Claude、Perplexity每天在抓你的站、用你的内容生成答案,却没有任何一个后台告诉你它们来没来、抓了多深、有没有被你拦在门外。服务器日志是这件事唯一能被看见的地方。但你不能拿看Googlebot那套去看AI爬虫——它们的行为模式完全不同:训练型来得稀、检索型来得急,而且都是阵发性的,只看一两天的日志几乎一定会得出“它没来”的错误结论。这篇讲清楚AI爬虫的行为怎么读、日志怎么按爬虫类型拆开看、为什么必须长期留存,以及日志看不到的那部分到底是什么。
做技术SEO这些年,保哥见过太多团队把精力全砸在关键词、内容和外链上,对服务器日志视而不见。这在以前还能凑合,因为Googlebot的行为基本能靠Search Console推断个大概。但现在情况变了:你的内容正在被一批没有任何官方后台的爬虫抓走,喂进AI的答案里,而你对这件事的全部认知,可能只来自“好像流量里多了点AI来源”这种模糊体感。
这就是2026年日志文件分析突然从“高级可选项”变成“不可替代”的根本原因。下面从这个变化讲起,再一路讲到怎么把AI爬虫的真实行为从一堆纯文本里挖出来、哪些坑会让你读错、以及日志本身看不到的那部分边界在哪。
为什么AI搜索时代,日志突然变得不可替代?
先把话说透:传统SEO工具在AI爬虫这件事上,基本是瞎的。
Google Analytics这类分析工具,设计初衷就是追踪人,它会主动过滤掉机器人流量——你在GA里永远看不到GPTBot来过。Search Console只报Google自家爬虫,数据还是聚合采样的,你查不到某个具体页面被谁、什么时候抓过,更别说ChatGPT或Claude的爬虫。Screaming Frog这类工具模拟的是“爬虫理论上能访问什么”,不是“真实爬虫实际访问了什么”,两者经常对不上。
而AI这边,连一个能查的后台都没有。没有“ChatGPT Search Console”告诉你被抓了多少、被引用了几次。市面上确实开始冒出一些工具——Bing网站管理工具加了点Copilot相关的洞察,也有Scrunch、Profound这类专门做AI可见性追踪的产品。但它们有个共同的硬伤:大多只在一个固定的时间窗口里运作,没有你自己的历史基线。没有历史数据,你根本判断不了“这周AI爬虫活动变少了”到底是真的下滑,还是它本来就这么忽高忽低。
只有服务器日志,记录了每一次真实交互:谁、什么时间、请求了哪个URL、服务器回了什么。它是你网站上这场“AI抓取”唯一会留下痕迹的地方。日志不会告诉你全部真相(后面会讲它的盲区),但这场互动能被看见的部分,只在这里。这不是“多一个分析维度”的问题,是“要么看日志,要么完全摸黑”的问题。
一条日志到底记录了什么?
在挖AI爬虫之前,得先看懂一条原始日志。一条典型的Apache或Nginx访问日志长这样:
20.171.207.5 - - [16/Apr/2026:14:32:10 +0000] "GET /guides/sizing/ HTTP/1.1" 200 15432 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.2; +https://openai.com/gptbot"逐字段拆开看:
| 字段 | 示例值 | 对分析AI爬虫的意义 |
|---|---|---|
| IP地址 | 20.171.207.5 | 用来反查这个声称是某爬虫的请求是不是真的,伪装爬虫就靠这步揪出来 |
| 时间戳 | 16/Apr/2026:14:32:10 | 精确到秒,AI爬虫的阵发性规律全靠时间分布看出来 |
| 请求URL | GET /guides/sizing/ | 它到底在抓哪一层、哪类页面,是判断抓取深度的核心 |
| 状态码 | 200 | 403、429会暴露你是不是在不知情的情况下把AI爬虫拦了 |
| 响应大小 | 15432 | 累加起来就是某个爬虫消耗的带宽 |
| User-Agent | GPTBot/1.2 | 分辨爬虫身份的第一依据,但能被伪造,要配合IP反查 |
这些字段拼在一起,就是一条“谁在什么时间访问了哪个页面、服务器怎么回应”的完整事件。日志分析说到底,就是把成千上万条这样的事件,按你关心的问题重新组织起来。
AI爬虫和传统爬虫,行为根本不是一回事?
这是最多人踩的坑:拿看Googlebot的经验去看AI爬虫,然后得出一堆错误结论。AI相关的爬虫,至少要分成三类,每一类行为模式都不一样。
训练型爬虫:GPTBot、ClaudeBot、CCBot、Google-Extended这一类,目的是给大模型抓语料。它们出现得不频繁,抓取范围广但不挑,常常是大面积扫一遍就走。如果这类爬虫在你日志里压根不出现,那就不只是一个抓取问题,而是说明AI生态根本还没发现你这个站——这是个比“某页没被抓”严重得多的信号。
检索型/回答型爬虫:ChatGPT-User、PerplexityBot这一类,是用户当场提问时实时去取内容来生成回答的。它们的活动是事件驱动的、近实时的、而且很有针对性——往往就盯着回答某个具体问题需要的那几个URL。
传统搜索爬虫:Googlebot、Bingbot,仍然提供最基础的对照基线。它们的特点是持续、稳定、抓得深,正好和AI爬虫的“稀疏、阵发、浅”形成强烈反差,这个反差本身就是诊断材料。
下面这张表是日志里要盯住的主要爬虫,分清它是来训练还是来回答,处置策略完全不同:
| 爬虫名 | 所属 | 类型 | User-Agent关键词 |
|---|---|---|---|
| GPTBot | OpenAI | 训练为主 | GPTBot |
| ChatGPT-User | OpenAI | 用户实时检索 | ChatGPT-User |
| OAI-SearchBot | OpenAI | ChatGPT搜索 | OAI-SearchBot |
| ClaudeBot | Anthropic | 训练 | ClaudeBot |
| Google-Extended | Gemini/AI Overview训练 | Google-Extended | |
| PerplexityBot | Perplexity | AI搜索检索 | PerplexityBot |
| Bytespider | 字节跳动 | 训练(高消耗) | Bytespider |
| Meta-ExternalAgent | Meta | Llama训练 | meta-externalagent |
| Amazonbot | Amazon | Alexa及AI | Amazonbot |
| Applebot-Extended | Apple | Apple Intelligence训练 | Applebot-Extended |
光看到“来没来”还不够,它的行为在说什么?
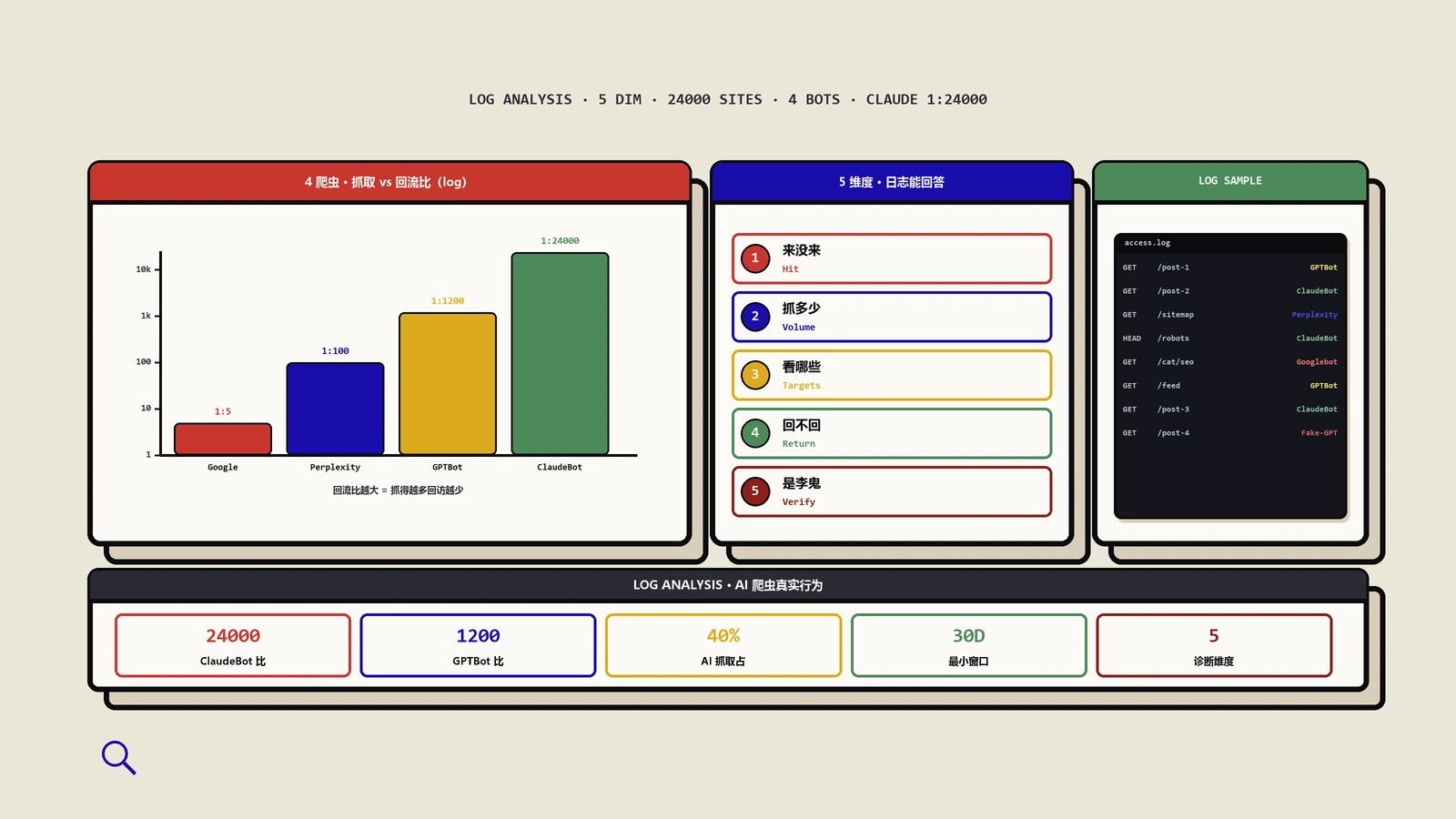
很多人查日志,查到“GPTBot来过”就停了。其实“来过”只是第一层,AI爬虫的行为里藏着五个递进的诊断角度,一层比一层有用。
一、有没有被抓到?最基本的一问。它根本没出现,还是出现频率远低于传统搜索爬虫?前者是发现问题,后者是优先级问题,处理方向完全不同。
二、抓得有多深?这是AI爬虫和Googlebot差别最大的地方。AI爬虫经常只停在顶层页面,首页、主导航、几个被直接链接的页面抓一抓就走,再深一点的长尾内容根本不碰。这意味着,你那些埋得深的优质长尾页,对传统搜索是可见的,对AI很可能是不存在的。
三、它沿着什么路径走?把AI爬虫访问的URL拉出来排个序,你会看到它的活动高度集中在一小撮URL上——通常就是首页、一级导航、和从首页一两跳能到的页面。这条路径直接映射你的站点架构:架构越扁平、重要内容离首页越近,AI爬虫能覆盖到的就越多。这一点和AI爬虫抓取量已超Googlebot那篇讲的策略转向是一体两面——抓取量大不等于抓得到你想让它抓的页。
四、在哪卡住了?按状态码过滤AI爬虫的请求,403(被拒)和429(被限速)最值得警惕。很多站是在完全不知情的情况下,被一层安全防护或托管平台默认规则把AI爬虫挡在门外的——你以为没被AI引用是内容不行,其实是请求根本没进来。这种“托管环境默默拦掉AI爬虫”的情况,托管WordPress悄悄拦AI爬虫那篇有完整的真实案例可以对照。
五、和Googlebot比,差在哪?把同一时间段的Googlebot和AI爬虫放一起对比:Googlebot覆盖深、稳定、连续,AI爬虫稀、浅、阵发。差距出现在哪些目录、哪类模板,那里就是你“传统可见但AI不可见”的具体位置。这种交叉比对,比单看任何一个爬虫都有用。
还有一个容易漏的角度叫“可抓vs实抓”:把技术上允许被抓的URL清单(Sitemap、内链可达的页面),和日志里AI爬虫实际抓过的URL清单做差集。差集里那些“本该能抓、却从没被AI碰过”的页面,就是你AI可见性的黑洞,也是优化最该先下手的地方。
AI爬虫的“抓取-回流比”到底有多悬殊?
看清楚行为之后,会引出一个让人不太舒服的事实:AI爬虫消耗你大量资源,却几乎不给你回流量。保哥看到一组2026年初的行业数据,对照非常刺眼:
- ClaudeBot:每抓约24000个页面,才换来1次访问回流。
- GPTBot:每抓约1200多个页面,回流1次。
- PerplexityBot:每抓约100多个页面,回流1次(检索型确实比训练型“划算”)。
- Google搜索:每抓约5个页面,回流1次。
这组数字说明AI爬虫正在大量吃你的服务器资源和抓取预算,回报却极不对等。在企业级站点上,AI爬虫有时能占到全部抓取活动的四成,这些都是可能挤占Googlebot抓取效率的真实消耗。所以日志分析在这里的价值是双向的:一边是抓取预算优化那篇讲的“别让爬虫把劲使在没用的页上”,另一边是“评估要不要为某些低回流爬虫设限”。但设限之前必须先有数据,没有日志就拍脑袋封爬虫,往往封错对象。
怎么从手头的日志,一步步把AI爬虫行为挖出来?
原理讲完,给一套能照做的流程。每一步都对着前面讲的诊断角度。
第一步,先用你手头已有的日志。别一上来就纠结工具。Apache一般在 /var/log/apache2/access.log,Nginx在 /var/log/nginx/access.log,云托管和CDN通过面板或对象存储导出。要注意:不同主机的日志保留期差别巨大,很多默认只留几小时到几天——这一点后面会专门讲,它是AI爬虫分析最大的隐形杀手。
第二步,用一个日志分析工具把数据变得能用。原始日志是一行行纯文本,直接看会疯。命令行先做粗筛:
# 统计各AI爬虫的请求量
grep "GPTBot" access.log | wc -l
grep "ClaudeBot" access.log | wc -l
# 把所有AI爬虫请求单独导出
grep -E "GPTBot|ClaudeBot|PerplexityBot|ChatGPT-User|Google-Extended|Bytespider|meta-externalagent" access.log > ai_crawlers.log
# AI爬虫最常抓的URL Top 20(看抓取深度和路径)
awk '{print $7}' ai_crawlers.log | sort | uniq -c | sort -rn | head -20要做结构化对比,再上专业的日志分析工具做可视化,或用下面这段Python按爬虫聚合:
import re
from collections import Counter
ai_bots = ['GPTBot', 'ClaudeBot', 'PerplexityBot', 'ChatGPT-User',
'Google-Extended', 'Bytespider', 'meta-externalagent',
'OAI-SearchBot', 'Amazonbot', 'Applebot-Extended']
bot_hits = Counter()
bot_urls = {}
with open('access.log', 'r') as f:
for line in f:
for bot in ai_bots:
if bot in line:
bot_hits[bot] += 1
m = re.search(r'"GET\s(\S+)', line)
if m:
bot_urls.setdefault(bot, Counter())[m.group(1)] += 1
for bot, c in bot_hits.most_common():
print(f"{bot}: {c} 次")
for bot, urls in bot_urls.items():
print(f"\n{bot} 最关注的URL:")
for u, c in urls.most_common(5):
print(f" {u}: {c}")第三步,按爬虫类型分桶——这一步是整个分析的胜负手。不分桶,所有请求糊成一团,你只能得出“爬虫挺多”这种没用的结论。一旦按训练型/检索型/传统型把User-Agent隔开分别看,规律才会浮出来:哪类只来一次大扫荡、哪类天天针对性来取几页、哪类稳定深抓。没有分桶,一切都是噪音;有了分桶,模式才开始显形。
第四步,把抓取行为和站点结构对着看。从“它来没来”进到“它怎么走”。把AI爬虫抓的URL映射到你的目录和层级上,看它是不是只在浅层打转、深层内容是不是整片空白。
第五步,用状态码定位卡点。专门过滤AI爬虫的非200响应,重点看403和429,确认有没有被安全层或限速规则误伤。
第六步,做“可抓vs实抓”差集。前面讲过,这一步直接产出你的优化清单。
第七步,认清日志看不到的部分。这是最容易被跳过、却最重要的一步:如果你站前面挂着CDN或安全防护,很多请求在到达源站之前就被它们处理掉了。被CDN缓存命中的、被安全层直接拦掉的、被限速挡回去的请求,很可能压根不会出现在你的源站日志里。也就是说,你看到的“AI爬虫没怎么来”,有时候是它来了但全被前面那层吃掉了,你根本不知道。要完整看,必须同时拿CDN的边缘日志,不能只看源站日志就下结论。日志告诉你的是“到达了你网站的那部分”,不是全部。
为什么短期日志会骗你,必须长期留存?
这是AI爬虫分析和传统爬虫分析最不一样、也最反直觉的一点,单独拎出来讲。
Googlebot是持续来的,你看三天日志,大致就能推断它的常态。AI爬虫不是。训练型爬虫可能半个月才大扫荡一次,检索型爬虫完全看有没有用户在问相关问题——它的活动是阵发的、不连续的。这意味着,如果你只看一两天甚至一周的日志,极大概率会得出“某个AI爬虫没来过”的结论,而真相只是它的来访周期比你的观察窗口长。基于这种假“缺席”去做决策(比如断定内容没被AI关注、甚至去封某个看起来没价值的爬虫),就是在错误数据上做不可逆动作。
问题是,绝大多数主机的日志保留期短得可怜,常常只有几小时到几天,等你想分析时,能说明问题的那段历史早被滚没了。解法是把日志留存从主机里独立出来:
- 挪到对象存储:把日志定期推到Amazon S3、Cloudflare R2这类便宜耐放的对象存储,留存期从“几天”变成“想留多久留多久”,成本极低。
- 自动化采集:靠人记得去下载日志是不可能长期坚持的。用一个能跑定时任务的工具(比如n8n这类)设一个定时SFTP作业,在主机的保留窗口过期之前自动把日志抓走归档。这一步做好,你才真正拥有AI爬虫分析所需要的历史纵深。
保哥的建议很实在:日常分析至少要有连续30天的窗口才敢对AI爬虫下判断,诊断网站迁移这类具体事件则要迁移前后各两三周的对比数据。能不能对AI爬虫得出靠谱结论,第一前提不是分析技巧,是你到底留没留住足够长的日志。这件事没做,后面所有分析都是在沙子上盖楼。
声称是GPTBot的请求,怎么知道不是李鬼?
这一步在AI时代比以前重要得多,但很多人完全跳过了。User-Agent是可以随便伪造的——一行字符串而已。日志里写着GPTBot,不代表它真是OpenAI的爬虫。
为什么这事在AI时代格外要紧?因为越来越多的内容抓取者,会故意把自己伪装成GPTBot、ClaudeBot这类“看起来正当”的AI爬虫。一来很多站会专门给AI爬虫放行(想被AI引用),伪装成它就能绕过你的封锁;二来真出了带宽异常或内容被盗的问题,你对着日志还以为是某个大厂AI在抓,方向从一开始就错了。不验真的日志分析,相当于让对方自己填身份证还不核对。
验真的标准动作是反向DNS加正向核对,四步:
- 从日志里把所有声称是某AI爬虫的请求IP提取出来。
- 对IP做反向DNS解析,看它解析到的域名。
- 确认这个域名属于该爬虫官方公布的域(比如真Googlebot会解析到
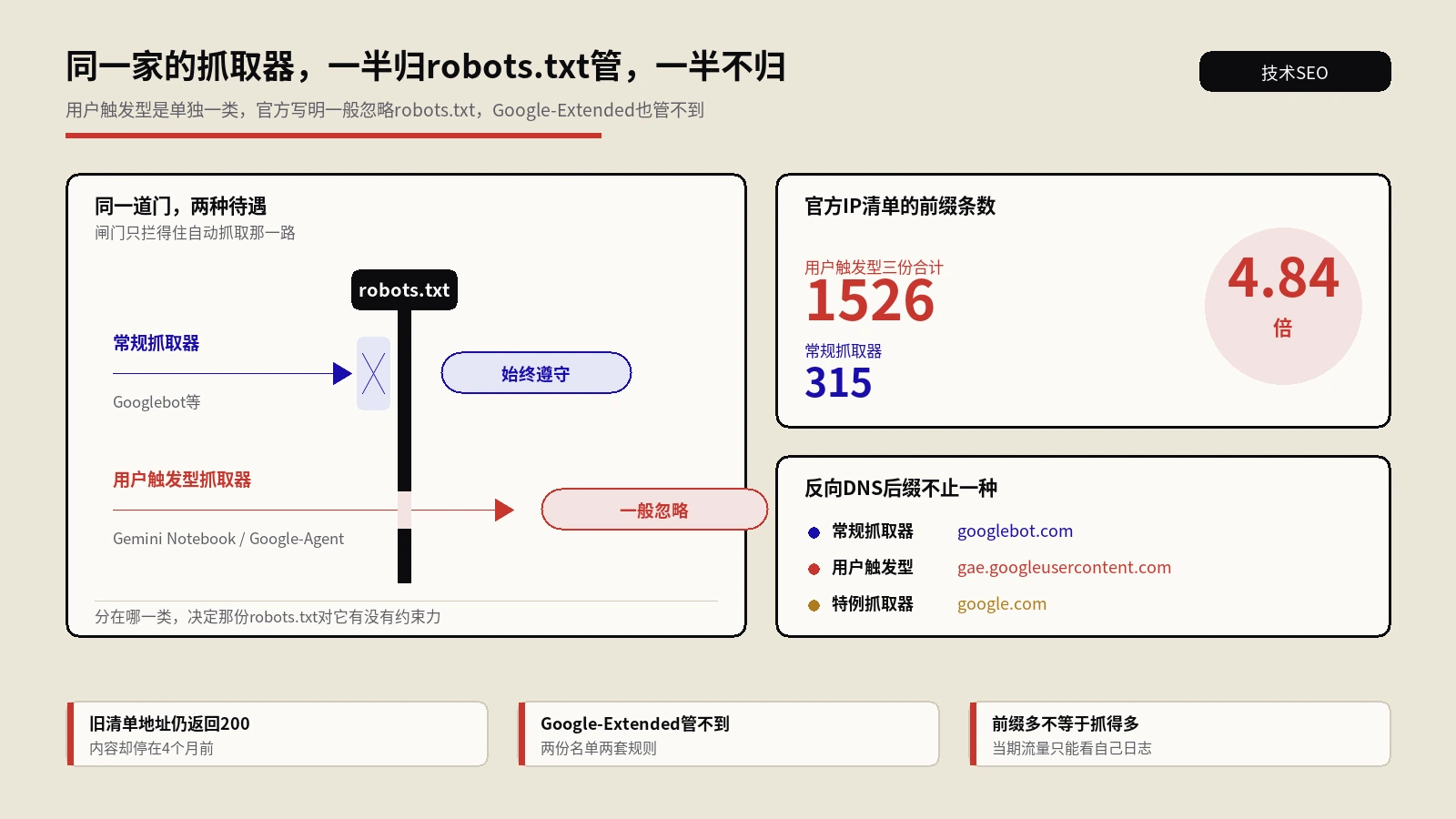
googlebot.com或google.com,主流AI厂商也各自公布了爬虫的官方IP段或域)。 - 再用正向解析把域名转回IP,和原始请求IP核对一致,防止反向DNS被伪造。
这步的现实意义不只是“揪假”。它还能帮安全团队和SEO团队达成一致:安全团队封可疑IP时,经常一不小心连真Googlebot、真GPTBot一起误封,结果你这边发现某类爬虫突然在日志里集体消失,排查半天才知道是自己人封的。日志的验真结果,是这两个团队对话的共同事实基础。这种“误封了重要爬虫却以为是对方不来抓”的情况,和站内那篇讲托管WordPress悄悄拦AI爬虫的文章本质是同一类隐形事故,只是这里的拦截来自你自己的安全策略而不是托管平台默认规则。
拿到行为数据后,robots.txt该怎么分层管?
有了真实数据,才谈得上管理。最忌讳的是凭印象一刀切——要么全开,要么把所有非Googlebot爬虫全封。正确做法是基于日志里各爬虫的“消耗vs回流”表现,在 robots.txt 里做分层:
# 传统搜索引擎:必须全开
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# 有检索回流的AI爬虫:开放有价值的内容目录
User-agent: PerplexityBot
Allow: /blog/
Allow: /guides/
Disallow: /api/
Disallow: /admin/
# 高消耗低回流的训练型:限制到核心内容目录
User-agent: GPTBot
Allow: /blog/
Disallow: /
User-agent: ClaudeBot
Allow: /blog/
Disallow: /
# 纯资源消耗型:直接挡掉
User-agent: Bytespider
Disallow: /
User-agent: CCBot
Disallow: /这里有个绕不开的权衡:屏蔽训练型爬虫,意味着你的内容不会进入对应AI助手的回答,这是个GEO(生成式引擎优化)层面的取舍,不是纯技术决策。还要特别提醒一句,robots.txt 一行写错就可能让整站从某类爬虫视野里消失,它的优先级、通配符、Allow与Disallow的覆盖关系都有坑,动手前最好对照robots协议机制那篇把规则核一遍——这种改动属于“写错了日志要好几天后才看得出后果”的高风险操作,值得慢一点。
网站迁移后,日志要验哪几关?
迁移是日志价值最集中的场景之一。保哥每次做迁移项目,日志都是事后验真的第一道关,按这个清单走:
- 301验证:确认旧URL在日志里返回的是301,不是302或其他状态码。
- 重定向链检测:揪出A→B→C这种多跳链,它会白白烧掉抓取预算。
- 新结构发现速度:观察Googlebot和各AI爬虫发现并抓取新URL的时间线,AI爬虫这条线通常明显更慢,要有预期。
- 遗留URL清理:找出还在被爬虫访问的旧版本URL(旧子域名、HTTP版本等)。
- 抓取量恢复曲线:盯总抓取量迁移后的回升趋势,分爬虫类型看,别用Googlebot的恢复速度去预期AI爬虫。
日志查出问题后,怎么变成开发能照做的事?
日志分析最后一公里,常常死在这里:分析做得很漂亮,输出却是一份开发看不懂、也排不上优先级的报告,于是结论躺在文档里没人动。日志的价值不在“分析出了什么”,在“有没有变成被修掉的工单”。
一份能落地的日志报告,至少要有四样东西,缺一样开发就有理由不动:
| 报告要素 | 反例(没人会动) | 正例(能直接派活) |
|---|---|---|
| 问题具体化 | “部分页面抓取异常” | 附上具体URL清单和复现请求,开发能一键重放 |
| 趋势可视化 | “最近5xx变多了” | 给出按天的错误码趋势图,看得到拐点对应哪次发布 |
| 优先级排序 | “这些都建议修” | 按业务影响排序:先修挡住AI爬虫抓核心商品页的那条 |
| 修复建议 | “请优化” | 每个问题给出技术动作,比如“这条安全规则把GPTBot的UA也匹配进去了,调整正则” |
排序那一栏是重点。日志里能查出几十个问题,但开发的带宽永远有限,没有按业务影响排过序的报告,等于把决定优先级的活甩回给了开发,而他们没有SEO视角,最后修的往往不是最该修的。一个实用的排序口径:直接影响核心转化页被抓被引用的问题排最前,影响抓取预算分配的次之,纯卫生问题(少量历史遗留404之类)放最后。
日志分析的常见误区与进阶细节
- 只盯Googlebot的日志:AI爬虫已占总爬虫流量的相当比重,只看Googlebot等于对一半战场视而不见。至少要同时统计Googlebot、Bingbot、GPTBot、ClaudeBot、Google-Extended五条线的占比变化。
- 把非Googlebot爬虫一律封掉:AI爬虫回流比虽差,但封掉GPTBot等于主动退出ChatGPT的答案。先按“有检索回流”和“纯训练”分类,再分层管,别一刀切。
- 日志只用来事后复盘:日志最值钱的用法是接入实时监控告警——对5xx激增、Googlebot抓取异常、AI爬虫流量突变设阈值告警。事前发现的成本,比事后复盘低一个量级。
- 进阶:JS渲染验证:如果日志显示Googlebot或AI爬虫只取了基础URL、没有触发渲染所需的后续请求,说明你靠JavaScript异步加载的内容很可能没被看到,要考虑服务端渲染或预渲染,并检查是不是有规则误挡了关键脚本。
- 进阶:采样vs全量:月日志超过百GB的大站可对趋势性分析做采样(如10%),方向通常一致;但诊断性分析、尤其是AI爬虫这种本来就稀疏的对象,必须全量,采样会把本来就少的信号采没。
- 进阶:Server-Timing:在响应头里用Server-Timing标记DB查询、模板渲染、缓存命中等阶段耗时,日志记录后能定位慢响应的根因,对提升爬虫抓取效率很关键。
- 进阶:Cookie同意条的影响:用JavaScript实现的Cookie同意弹层,可能让爬虫看到的页面和真实用户不一样,日志能帮你验证爬虫是否被弹层挡住、要不要对爬虫返回简化版。
- 合规:日志含个人信息:日志里的IP地址在GDPR等法规下属于个人可识别信息,分析前要对IP做匿名化(如截断末段)、设定合理的保留与销毁策略、把日志放在有访问控制的环境里。乙方接客户日志尤其要先把这套合规口径谈清楚,否则客户大概率不愿把原始日志给你,分析就无从谈起。
常见问题解答
AI搜索时代,日志文件分析为什么变得不可替代?
因为ChatGPT、Claude、Perplexity没有任何类似Search Console的官方后台,你查不到它们抓没抓你、抓了多少、有没有引用你。Google Analytics过滤机器人流量,Search Console只报Google自家且是聚合采样,爬虫模拟工具只反映理论可达。只有服务器日志记录了AI爬虫每一次真实请求,是这场互动唯一能被看见的地方。
用看Googlebot的方法分析AI爬虫,会有什么问题?
会得出错误结论。AI爬虫分训练型(GPTBot、ClaudeBot,来得稀、扫得广)、检索型(ChatGPT-User、PerplexityBot,事件驱动、近实时、针对性强)、传统型三类,行为模式各不相同且普遍阵发。拿Googlebot那种持续稳定的预期去套,最常见的错误就是把“它来访周期长”误判成“它没来”,进而在假缺席数据上做决策。
为什么短期日志分析AI爬虫会得出错误结论?
因为AI爬虫活动是阵发不连续的——训练型可能半月才扫一次,检索型看有没有用户在问。只看一两天或一周,极大概率把“观察窗口比它来访周期短”误读成“这个爬虫没来过”。基于这种假缺席去判断内容没被AI关注、甚至去封爬虫,就是在错误数据上做不可逆动作。日常至少要连续30天窗口。
主机日志只保留几天,怎么解决长期留存?
把留存从主机独立出来。定期把日志推到Amazon S3、Cloudflare R2这类便宜的对象存储,保留期就不再受主机限制;再用能跑定时任务的工具设一个定时SFTP作业,在主机保留窗口过期前自动抓走归档。靠人手动下载无法长期坚持,自动化是前提,否则等你想分析时历史早被滚没了。
日志里看不到AI爬虫,是不是就一定说明它没来?
不一定。一是可能观察窗口太短,撞不上它的阵发来访;二是如果站前挂着CDN或安全防护,请求可能在到达源站前就被缓存命中、拦截或限速处理掉,根本不进源站日志。要排除第二种,必须同时看CDN边缘日志。日志反映的是“到达了你网站的那部分”,不是全部真相。
AI爬虫消耗大量资源回流又极低,应该全部屏蔽吗?
不建议一刀切。屏蔽训练型爬虫(GPTBot、ClaudeBot)意味着内容不会进入ChatGPT、Claude的回答,影响GEO可见性。正确做法是基于日志里各爬虫的消耗与回流数据,把“有检索回流”和“纯训练”分开,在robots.txt里分层管理:对高价值目录开放、对低价值目录或纯消耗型限制。
AI爬虫只抓首页和浅层页,深层内容怎么办?
这正是日志暴露的典型问题:AI爬虫往往只覆盖首页、主导航和直接链接的页面,深层长尾对它近乎不存在。对策是从站点架构下手——压平层级,让重要内容离首页更近,强化指向深层页的内链路径,必要时用Sitemap和站内推荐提高这些页被发现的机会,再用日志复查是否真的被抓到了。
权威参考资料
本文标题:《AI爬虫到底有没有抓你的站?日志分析一步步挖真相》
本文链接:https://zhangwenbao.com/seo-log-file-analysis-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0