网站突然从谷歌消失,多半是robots.txt写废了
本文目录
- robots.txt到底是什么?为什么它不是你以为的那道门?
- 它是抓取建议,不是访问控制
- 它管抓取,不管收录——九成误用的总根源
- 搜索引擎到底是怎么解析一个robots.txt文件的?
- 位置和作用域:一个常被忽略的坑
- 分组匹配:爬虫只听它自己那一组的话
- Allow与Disallow冲突时,到底谁赢?
- 通配符 * 和行尾 $ 的真实语义
- RFC 9309标准化之后,各家引擎还是一套规则吗?
- RFC 9309定了什么,没定什么
- 错误码处置:最反直觉、最容易让服务器一抖整站掉抓
- 各家引擎差异速查
- 只想挡一个目录,怎么就把整站挡没了?
- 顺序错觉:以为先写先生效
- staging配置混进生产
- 用Disallow想“删掉已收录的页”——典型自锁
- 把CSS、JS也Disallow了
- robots.txt改了多久才生效?为什么看不到效果?
- 缓存:改完不是即时的
- 放开抓取,只是漫长链路的第一步
- 怎么验证它真的生效了
- AI爬虫时代,robots.txt还拦得住谁?
- 训练抓取和搜索抓取,必须分开决策
- 守不守规矩,看自觉
- 不同站点类型,robots.txt到底该怎么配?
- 几乎永远不该写进robots的东西
- robots之外,还要协同的几件事
- robots.txt误封后怎么诊断和恢复?
- 常见问题解答
- robots.txt能阻止页面出现在Google搜索结果里吗?
- robots.txt必须放在哪里?子域名要单独写吗?
- Allow和Disallow冲突时谁说了算?
- robots.txt里写noindex还有用吗?
- 改了robots.txt多久生效?
- 用robots.txt隐藏后台或敏感目录安全吗?
- 该不该用robots.txt封掉AI爬虫?
- 误写Disallow: / 整站掉了怎么紧急恢复?
- 权威参考资料
摘要:robots.txt管的是“要不要去抓”,不管“要不要被收录”。被它拦住的网址照样能凭一条外链进索引,在结果里露出一行“无法提供此页面的说明”。真正想让一个页别出现在搜索里,要用noindex——而noindex要被读到,那个页恰恰必须允许抓取,所以拿Disallow去“删页”是把自己锁死。再叠加各引擎对通配符、优先级、错误码的解析各不一样,写错一行的代价是两种极端:该藏的全曝光,或者整站从搜索里蒸发。这篇讲的是协议本身怎么被解析,不是某个建站程序怎么配。
先讲个真事。北美一个做户外家具的独立站,团队七八个人,年流水千万人民币级别,2021年初找过来的时候声音都在抖:自然流量三天里掉到几乎归零,订单跟着断崖。保哥让他们先别慌着改代码,第一件事是用curl把线上的/robots.txt原样拉下来看——开头第三行赫然写着Disallow: /。再一问发布流程就全明白了:开发在staging环境为了不让测试站被抓,写了一刀切的Disallow: /,结果那次上线把整个站点目录连同这份robots一起推到了生产,CI流水线里压根没有把robots.txt当成需要按环境区分的配置。技术体检全绿、没有任何手动处罚通知、服务器好好的——他们查了两天没查出问题,因为问题根本不在“站坏了”,而在一行文本告诉Google“整个站都别抓”。
这种“我明明只想挡一个目录,结果整站从搜索里消失”的事故,这些年处理过不止一次,剧本高度雷同:要么是staging配置带上生产,要么是有人凭直觉以为规则从上往下先匹配先生效,把Disallow: /顶在最前面想“先禁全站再放行例外”。根子都是同一个:大多数人对robots.txt到底是什么、搜索引擎到底怎么解析它,有系统性的误解。这篇不教你某个CMS怎么生成robots、也不是“电商该不该Disallow筛选器页”这类单点问答,而是把这个协议本身从机制层讲透——它管什么不管什么、一个文件被怎么逐行解析、各家引擎差在哪、改了多久生效、AI爬虫时代还拦得住谁、写错了怎么诊断恢复。把机制吃透,前面那些单点问题你自己就能判。
robots.txt到底是什么?为什么它不是你以为的那道门?
绝大多数误用,源头是一句话没想清楚:robots.txt不是一道门,是贴在门口的一张告示。它的全称是“爬虫排除协议”(Robots Exclusion Protocol),核心是一份给“守规矩的自动化爬虫”看的抓取建议清单。注意每一个限定词——它只对“守规矩的”爬虫有约束力,它给的是“建议”不是“强制”,它约束的是“抓取”这个动作。
它是抓取建议,不是访问控制
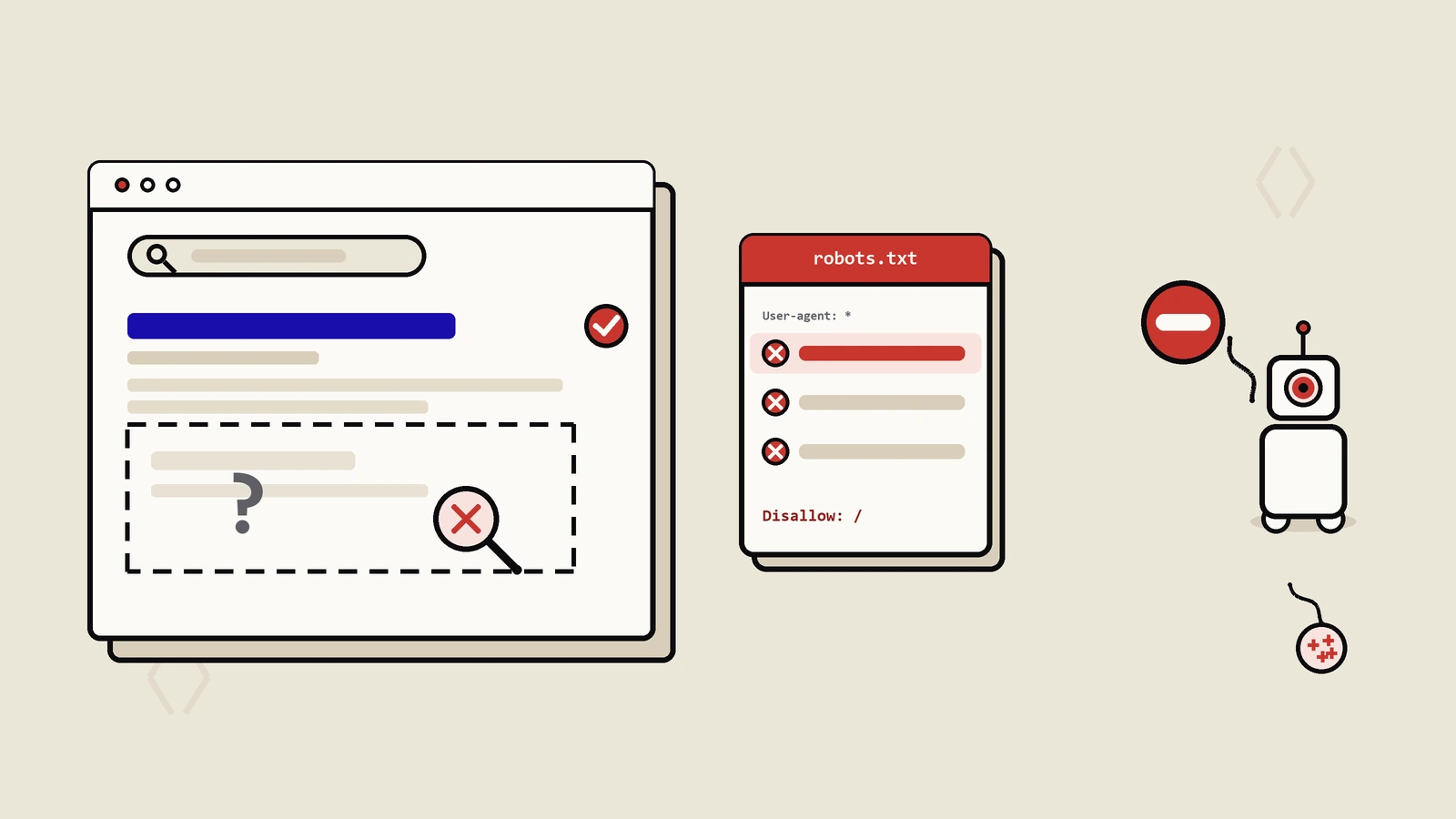
被Disallow的网址,任何人在浏览器里直接敲网址照样能打开,任何不守规矩的脚本照样能抓。robots.txt没有任何技术手段去“拦住”谁,它只是礼貌地说“这些路径希望你别来抓”。这就引出第一个致命误用:拿robots.txt当访问控制去“隐藏”敏感路径,等于把藏宝图公开挂在网站根目录。你写一行Disallow: /admin-secret/,等于主动告诉全世界你有个叫这个名字的后台。真要保护资源,靠的是身份鉴权、IP白名单、把文件挪出web根目录,而不是robots。这条认知错了,后面全错。
它管抓取,不管收录——九成误用的总根源
这是整篇最该先扭过来的一点。抓取(crawl)和收录(index)是两件事:抓取是爬虫把页面内容读下来,收录是搜索引擎决定把这个网址放进它的索引库、让它有资格出现在结果里。robots.txt只拦前者。问题在于,一个网址进不进索引,并不只取决于它有没有被抓到内容——只要别的网站有一条链接指向它,Google就可能在“没读过这个页内容”的情况下,仅凭那条链接的存在和锚文本,把这个网址收进索引。这时候你会在搜索结果里看到这个网址,标题可能就是网址本身或外链锚文本,描述位置写着一行“由于该网站的robots.txt,系统目前无法提供关于此网页的说明”。
很多人第一次见到这个画面会更慌:我都Disallow了它怎么还在搜索里?因为你用错了工具。robots.txt永远做不到“让一个页从搜索结果里消失”,它从设计上就不负责这件事。想理解抓取与收录为什么是两条独立的链路,可以顺带看下搜索引擎抓取、索引、排名三步是怎么运转的——把这三步分开看,robots.txt的位置和边界就一目了然:它只作用在第一步的入口,对第二步的“收不收”几乎没有正向控制力。
那到底哪个工具管哪件事?这张表照着记,能避开大半的误用:
| 手段 | 拦抓取吗 | 能把已收录的页从索引里清掉吗 | 能省抓取预算吗 | 典型适用 |
|---|---|---|---|---|
| robots.txt Disallow | 能 | 不能(且会让noindex读不到,反而清不掉) | 能 | 不想被抓、且不在意是否被收录的批量低价值路径 |
| meta noindex / X-Robots-Tag | 不能(必须允许抓取才会被读到) | 能 | 不能(仍要被抓) | 想让某页不出现在搜索结果里 |
| canonical | 不能 | 不能(是合并信号不是删除指令,且可被忽略) | 不能 | 多个近重复页想归并权重到主版本 |
| 身份鉴权 / 密码 | 能(爬虫拿不到内容) | 能(最终会掉出索引) | 能 | 真正的私密内容 |
| 410 / 404 | 不拦,但反复410后停抓 | 能(最干净的删除信号) | 长期能 | 确实要永久删除的页 |
把这张表的逻辑用一句话钉死:要“别抓”用robots,要“别出现在搜索里”用noindex,要“归并重复”用canonical,要“真保密”用鉴权——四件事四个工具,混用就是事故。Google官方文档反复在说同一句话,精神就是:robots.txt is not a mechanism for keeping a web page out of Google。这句话值得贴在每个运维的显示器边上。
搜索引擎到底是怎么解析一个robots.txt文件的?
知道了它管什么,接下来是更要命的部分:同一份文件,搜索引擎逐行读的时候,判定逻辑和大多数人脑子里想的完全不一样。误配事故几乎都出在这一层。
位置和作用域:一个常被忽略的坑
robots.txt必须放在主机的根路径,也就是https://example.com/robots.txt,放在子目录里(如/blog/robots.txt)对爬虫完全无效。更隐蔽的是作用域:它按“协议 + 主机 + 端口”绑定,不跨边界继承。https://example.com/robots.txt不管http://example.com,也不管https://www.example.com、不管https://shop.example.com、不管https://example.com:8443。保哥见过一个B2B客户做了站点HTTPS迁移,HTTPS版的robots写得很规范,却忘了HTTP版还留着一份上古的Disallow: /——结果所有还没跳转完的HTTP入口被判全禁,迁移期掉了一大块抓取。每一个host、每一种scheme,都要单独确认它那一份robots.txt是对的。这一点和多区域站尤其相关,做国际化与hreflang部署时,每个国家子域或子目录对应的抓取策略都要单独核,别指望主域那份能管到所有区域。
分组匹配:爬虫只听它自己那一组的话
一个robots.txt由若干个组构成,每组以一行或多行User-agent开头,后面跟着该组的Allow/Disallow规则。关键机制是:一个具体的爬虫来了,它会在所有组里找“最具体匹配自己名字”的那一组,只执行那一组,其它组(包括通配的User-agent: *)对它完全无效。这意味着如果你写了一个User-agent: Googlebot的专属组,哪怕只为它写了一行规则,Googlebot就只看这一行,User-agent: *里那一大堆Disallow它一概不看。无数“我在*里禁了一堆为什么Googlebot还在抓”的疑问,根子都在这:你给它开了小灶,它就只吃小灶。名字匹配大小写不敏感、取最长前缀匹配,没有任何组匹配上才落到*。
Allow与Disallow冲突时,到底谁赢?
这是最反直觉、也最容易写出事故的一条。绝大多数人凭直觉以为是“顺序优先”——先写的规则先生效,或者从上往下第一条匹配的说了算。对Google而言,判定规则不是顺序,是“匹配路径最长的那条规则胜出”;当Allow和Disallow命中的路径长度完全相等时,Allow赢。举个具体例子,规则是Disallow: /folder/加Allow: /folder/public-page.html,请求/folder/public-page.html时,Allow那条匹配长度更长,所以放行;请求/folder/other.html时只有Disallow命中,所以拦截。理解了这条,你就明白为什么“把Disallow: /放最前面,下面再Allow几个例外”这种写法在Google这边能跑通(最长匹配会让具体的Allow例外胜出),但它极其脆弱:任何一个你没单独Allow的路径都会被那条Disallow: /吞掉,而且这个逻辑在别家引擎未必一样——下一节会讲到差异。一条硬建议:永远别用“全禁 + 逐个放行”这种写法管一个还要被收录的站,它的容错率是零。
通配符 * 和行尾 $ 的真实语义
另一个高频翻车点是把*当成shell里的glob去想。在robots规则路径里,*表示“任意长度的任意字符序列”,$表示“路径到此结束”(锚定结尾)。看几个对照就清楚了:
| 规则 | 含义 | 命中示例 | 不命中示例 |
|---|---|---|---|
Disallow: /*.pdf$ | 路径以 .pdf结尾的全拦 | /files/report.pdf | /files/report.pdf?v=2(结尾不是 .pdf) |
Disallow: /*.pdf | 路径里出现 .pdf即拦(没锚结尾) | /a.pdf、/a.pdf?x=1、/pdf-guide/ | /files/report.PDF(大小写不同) |
Disallow: /*? | 所有带问号的网址全拦 | /list?page=2 | /list(无查询串) |
Disallow: /private | 以 /private开头的路径全拦(前缀匹配) | /private、/private-data、/privatestuff | /my/private |
Disallow: /private/ | 只拦 /private/ 这个目录及其下 | /private/a.html | /private-data(不是该目录) |
表里第四行和第五行的区别,是踩坑重灾区:Disallow: /private会顺手把/private-data、/privatestuff这种你根本没想拦的路径一起拦掉,因为它是前缀匹配不是目录匹配。差一个斜杠,影响范围天差地别。还有一个隐性事实:robots路径匹配区分大小写,Disallow: /Admin/拦不住/admin/,URL大小写不规范的站在这里很容易出现“以为禁了其实没禁”。
RFC 9309标准化之后,各家引擎还是一套规则吗?
很多人不知道,爬虫排除协议在被发明后的将近三十年里,一直只是1994年一份没有正式标准地位的“君子协定”草案,各家引擎怎么解析全凭自觉和约定俗成。直到2022年9月,IETF才把它正式标准化为RFC 9309。所以“各家是不是一套规则”这个问题,答案是:标准化定了一部分,但留了一大片各家自己说了算的灰色地带。
RFC 9309定了什么,没定什么
RFC 9309把这些写成了正式标准:基本语法、Allow/Disallow的存在、爬虫至少要能处理500 KiB的内容(超出部分允许不解析)、robots.txt返回4xx时视为“没有限制、全部允许抓取”、返回5xx(含429)时视为“暂时全部禁止抓取”、以及解析器要尽量宽容地忽略不认识的字段。它没有写进标准、留给各家实现的,包括:crawl-delay怎么处理、sitemap指令、通配符*和$的精确语义、Allow/Disallow冲突的判定细则。也就是说,前一节讲的“最长匹配胜出”是Google的实现规则,不是RFC强制——这正是跨引擎差异的来源。Google早在2019年7月就把自己的robots.txt解析器开源了,想抠细节可以直接看它的实现,这也是判断Google行为最权威的依据,比任何二手解读都准。
错误码处置:最反直觉、最容易让服务器一抖整站掉抓
这一条要单独拎出来强调,因为它造成的事故最隐蔽。robots.txt自身返回不同状态码,后果完全不同,而且大多与直觉相反:
| robots.txt自身的返回 | 主流引擎的处置 | 潜在事故 |
|---|---|---|
| 200 + 内容 | 按内容解析 | 内容写错则按错的执行 |
| 404 / 其它4xx | 视为没有任何限制,全站允许抓 | 一般安全;但若你靠robots拦着大量垃圾页,robots一旦404这些会被放开 |
| 5xx / 429 | 视为全站暂时禁抓;若长时间持续,Google会逐渐改按缓存、再久则可能当404放开 | 服务器抖动、限流误伤、robots路径报500,会让Googlebot短期内大面积停抓,掉抓掉收录 |
| 抓取超时 / 网络错误 / DNS失败 | Google短期内沿用上次成功抓到的缓存版本,长期取不到则趋向保守 | CDN配错、防火墙误封Googlebot,会让robots取不到,行为变得不可预期 |
真实事故举一个:一个媒体站把/robots.txt这个路径也套进了全站的限流规则,正常用户没事,但Googlebot抓robots的频率触发了429,连续几天后Googlebot把整站当“暂时禁抓”,抓取量肉眼可见地往下掉,编辑那边表现为新文章迟迟不收录。查的时候没人会想到去看robots这个文件本身的返回码——大家默认它“就是个文本文件不会出问题”。robots.txt这个URL本身必须像首页一样被监控可用性,它的5xx比内容写错更危险,因为没人会怀疑它。
各家引擎差异速查
把主流引擎对那些“RFC没管”的部分摆在一起对照,跨引擎部署时照着核:
| 维度 | Bing | 百度 | Yandex | |
|---|---|---|---|---|
| crawl-delay | 不支持,抓取频率走Search Console设置 | 支持 | 有自己的抓取压力反馈机制,文档不强调crawl-delay | 支持 |
| Allow/Disallow冲突 | 最长匹配胜出,等长Allow赢 | 大体同Google思路 | 以更具体规则为准,细则未完全公开 | 最具体规则胜出 |
| sitemap指令 | 读取 | 读取 | 读取(也支持主动推送) | 读取 |
| 通配符 * $ | 支持 | 支持 | 支持(细节与Google略有出入) | 支持 |
| 大小写(路径) | 区分 | 区分 | 区分 | 区分 |
| 文件大小上限 | 500 KiB,超出截断 | 有上限,量级相近 | 有上限 | 有上限 |
跨引擎一个实战结论:如果你既要服务Google又要管Bing或Yandex的抓取节奏,crawl-delay得照写(Google会忽略它不会报错,正好),Google那边的抓取频率单独去Search Console里调。别指望一行crawl-delay能让所有引擎都听话。
只想挡一个目录,怎么就把整站挡没了?
前面把机制铺完,这一节专门把“误配导致整站消失”这类事故的几种典型成因摆开,每一种保哥都在客户站上见过真实版本。
顺序错觉:以为先写先生效
最常见的一种。运维想“先把全站禁了,再放行我要的几个目录”,于是写Disallow: /在前、若干Allow:在后,心理模型是“规则从上往下跑,先匹配先算”。在Google这边因为最长匹配规则,具体的Allow例外确实能胜出,看起来像是“能用”,于是这种写法被当成经验传开。但它有两个致命问题:一是任何没被单独Allow的路径都被那条Disallow: /吞掉,新增一个目录忘了加Allow,那个目录就静默消失;二是这个“能用”依赖的是Google的最长匹配实现,换到判定细则不同的引擎,行为可能完全两样。把全站Disallow当默认、靠白名单放行,是容错率为零的写法,一个站只要还想被收录就不该这么写。
staging配置混进生产
开篇那个户外家具站就是这一类,也是工程团队最容易栽的一类。测试环境为了不被抓,理所应当地写Disallow: /;事故发生在发布流水线没有把robots.txt当成“按环境不同”的配置去管理,一次常规上线就把测试站那份robots连同代码推到了生产。这类事故的解法不在SEO,在工程纪律:robots.txt必须进环境差异化配置,生产环境的robots单独有一份并在部署后自动校验关键行,CI里加一条“生产robots不得包含Disallow: /”的硬断言,比任何事后排查都省事。
用Disallow想“删掉已收录的页”——典型自锁
这个误用值得单独讲,因为它形成一个死锁,很多人越弄越糟。场景是:某批页面被收录了,你不想要了,于是给它们加上Disallow,想着“禁止抓取它们就会从搜索里消失”。结果恰恰相反——你一Disallow,爬虫就再也读不到这些页面上的noindex标签或410状态了,删除信号永远传不进去,这些页就卡在索引里出不来,甚至长期带着那行“无法提供说明”留在结果里。正确顺序永远是:先放开抓取,让爬虫读到noindex或410,等它们真正掉出索引之后,如果还想省抓取预算,再考虑加Disallow。顺序反了就是给自己上锁。要批量处理这种已收录又想清掉的页,还可以配合Search Console的移除工具做临时遮蔽(约六个月)争取时间,但永久解决靠的还是noindex或彻底删除,不是Disallow。
把CSS、JS也Disallow了
历史遗留写法里很常见:为了“干净”,把/assets/、/static/、.css、.js整体Disallow。后果是Google渲染你的页面时拉不到样式和脚本,看到的是一个排版崩坏、功能缺失的版本,进而可能判定移动端不友好、主要内容渲染不出来。渲染所必需的资源永远不该被robots拦——Google需要像浏览器一样看到你的页面,挡掉它的眼睛只会伤自己。
robots.txt改了多久才生效?为什么看不到效果?
“我已经把那行删了,为什么流量还没回来”——这是误配恢复期最常见的焦虑,背后是对“生效”这件事的两段链路没分清。
缓存:改完不是即时的
Google不会每次抓页面前都现拉一遍robots.txt,它会缓存。这个缓存通常在一天上下这个量级(会受你robots.txt响应里Cache-Control的影响)。也就是说你刚把Disallow: /删掉,接下来还有一段时间Google用的是旧的那份、继续以为整站禁抓。想加快,可以在Search Console里请求重新抓取robots.txt,并确认robots响应没有设过长的缓存头。
放开抓取,只是漫长链路的第一步
这是预期管理的关键。把误封的robots改对,只完成了“允许抓”这一步。后面还有:Google重新发现这些URL、重新抓取、重新评估、重新放回索引并给到合理排名——这是一条按页面重要度走的、长得多的链路,重要页面可能几天内回来,长尾页面要数周甚至更久,而且不保证一比一回到原来的位置。误封恢复是台阶式的,不是开关式的:改对那一刻不会立刻反弹,要盯的是抓取量曲线先回升、收录数再跟上、流量最后才回来这个先后顺序。哪一步没动,就知道卡在哪。
怎么验证它真的生效了
别靠感觉,靠证据,三个证据源交叉看:一是直接curl线上的/robots.txt,确认改对了、字节数正常、返回200;二是Search Console里用URL检查工具对关键页做实时抓取测试,看它现在判定为“允许抓取”还是仍“被robots.txt阻止”,同时注意区分“已编入索引的版本”和“实时抓取测试”这两个结果;三是看服务器日志里Googlebot对受影响路径的抓取记录有没有从“断点”重新爬起来。三个都对上,才算真的生效,缺一个就还没完。
AI爬虫时代,robots.txt还拦得住谁?
这两年绕不开的一个新问题:除了搜索引擎,大模型的训练和检索爬虫也来了,robots.txt在它们面前还有没有用。答案是:对声明遵守它的,有用;但你得先分清楚来的到底是谁、它来干嘛。
训练抓取和搜索抓取,必须分开决策
最容易出事的一刀切,是分不清这两类爬虫就整体封杀。以Google为例,Googlebot负责搜索收录,Google-Extended是专门用来控制你的内容要不要被用于Gemini等模型训练的——它和搜索收录是两个独立开关。你封掉Google-Extended不影响Google搜索照样收录你;你要是手一抖把Googlebot也封了,那就是把搜索流量也一起断了。OpenAI那边同理,GPTBot偏训练抓取,OAI-SearchBot偏搜索结果检索,ChatGPT-User是用户在对话里触发的实时取页,三者用途和你该不该放,逻辑完全不同。
守不守规矩,看自觉
RFC 9309的约束力本质上是君子协定。主流公司的爬虫大多公开声明遵守robots.txt,但灰色地带真实存在:同一家公司可能有多个UA、爬虫会改名、上游数据源(如Common Crawl的CCBot,很多模型的语料经由它)让“封了某一个就没事”变得不那么简单,更别说恶意抓取根本不报真实UA。robots.txt对不守规矩的抓取零约束力,真要硬挡,得在边缘层按“已验证的UA + 官方IP段”做拦截,而验证UA的可靠方法是对来访IP做反向DNS再正向解析回去对得上,不是看UA字符串本身。UA字符串是可以随便伪造的,只信它等于没防。
下面这张表把常见的AI相关爬虫摆清楚,决策时对着看:
| UA名 | 归属 | 主要用途 | 封它影响什么 |
|---|---|---|---|
| Googlebot | 搜索收录 | 断Google自然搜索(几乎永远不该封) | |
| Google-Extended | Gemini等模型训练 | 内容不被用于其模型训练,不影响搜索收录 | |
| GPTBot | OpenAI | 模型训练抓取 | 内容不进OpenAI训练语料 |
| OAI-SearchBot | OpenAI | ChatGPT搜索检索 | 可能失去在ChatGPT搜索里被引用的机会 |
| CCBot | Common Crawl | 公共语料库抓取(多家模型上游) | 影响面广但封不全,因语料经多手流转 |
| PerplexityBot | Perplexity | 检索与引用 | 可能失去在该平台被引用的入口 |
| ClaudeBot | Anthropic | 抓取 | 内容不被其抓取 |
保哥给客户的取舍是这样的:纯训练类爬虫(如GPTBot、Google-Extended)封不封,看你的内容是不是核心资产、被白嫖训练有没有实际损失,这是商业判断没有标准答案;但检索/引用类爬虫(如OAI-SearchBot、PerplexityBot)要慎封——封了等于主动放弃在AI答案里被引用、被带流量的入口,这和很多人花大力气做的事情正好相反。一刀切User-agent: *加Disallow: /去“防AI”,往往是把搜索和被引用一起断了,得不偿失。具体怎么争取被AI引用是另一个话题,这里只给robots这一层的边界:别在这一层把自己的入口堵死。
不同站点类型,robots.txt到底该怎么配?
讲完机制,落到地上。robots.txt没有一份能套所有站的模板,按站点类型决策才对。下面这张矩阵是实际给不同客户定策略时的判断框架:
| 站点类型 | 该Disallow的 | 绝对别碰的 | 重点 |
|---|---|---|---|
| 新站 / 小内容站 | 站内搜索结果页、登录注册等功能页 | 正文、CSS/JS | 越简单越好,别过度优化robots,先把内容做出来 |
| 大型电商 | 排序/分页/筛选产生的参数组合页(择优)、购物车、结算 | 商品页、分类着陆页、渲染资源 | 核心是治理筛选器组合爆炸,但robots只是其中一环 |
| 多区域国际站 | 各区域内的功能页(每区域单独确认) | 任一区域的正文、跨区域跳转逻辑依赖的页 | 每个host/子目录的robots单独核,别一份管全球 |
| 前端渲染(SPA)站 | 纯接口路径中确实无SEO价值的 | 渲染所需的JS/JSON接口、API | 挡了渲染依赖等于让Google看到白屏 |
| 媒体 / 资讯站 | 标签翻页深处、打印版、低价值聚合页 | 文章页、栏目页、robots.txt自身的可用性 | 更新频繁,盯紧robots自身别报5xx影响新文收录 |
电商那一行要补一句:用robots去Disallow筛选器组合页,只是控制抓取这一个侧面,治不了已经被收录的近重复薄页,也救不了内部权重在这些路径上空转——筛选器/分面导航这套组合爆炸是个需要robots、noindex、canonical、前端架构一起上的系统工程,单靠robots一锅端往往按下葫芦起了瓢。这块的系统治理逻辑,可以专门看分面导航与筛选器URL的爬虫陷阱怎么系统治理,那里把多工具决策矩阵讲透了,这里不重复。
几乎永远不该写进robots的东西
把这几条记成黑名单,能避开最常见的自伤:渲染必需的CSS/JS(挡了Google渲染不出页面);想被noindex的页(一Disallow就读不到noindex自锁);想做canonical归并的重复页(爬不到就读不到canonical标签,归并失效);非HTML资源(如PDF)想做noindex时——这类资源加不了meta标签,noindex只能通过X-Robots-Tag响应头下发,而响应头要被读到,前提同样是这个URL允许抓取。这里的统一逻辑就一句:凡是“需要爬虫读到某个指令才能生效”的处理,都不能用robots把它挡在门外。
robots之外,还要协同的几件事
robots.txt不是孤立的。它里面可以(也建议)放Sitemap:指令,指向站点地图的绝对地址,帮各引擎更快发现URL——但要注意sitemap指令不受user-agent分组约束,是全局的;站点地图本身该怎么组织、lastmod有哪些信用陷阱,是另一套学问,可以看XML Sitemap完全指南里该放什么和lastmod陷阱。再加上前面反复提到的noindex与canonical各管一摊,记住这张职责切分:robots管要不要抓、noindex管要不要出现在搜索、canonical管重复怎么归并、X-Robots-Tag管非HTML资源的索引指令——四者协同而不是互相替代。
robots.txt误封后怎么诊断和恢复?
最后给一套可直接执行的排错流程。处理过的所有robots误封事故,基本都是按这个顺序拆,五步,顺序别乱。
第一步,看证据不靠猜。三个证据源同时拉:线上curl https://你的域名/robots.txt原样看内容和返回码;Search Console里看“抓取统计”有没有“被robots.txt阻止”的请求曲线突然抬升、以及索引覆盖报告里相关状态的变化;服务器日志里Googlebot对掉量路径的抓取量有没有一个明确的断点。三者通常会指向同一个时间点和同一类路径,那就是案发现场。
第二步,用最长匹配手算到底是哪条规则命中。把受影响的代表性URL拿出来,按“所有命中规则里匹配路径最长的胜出、等长Allow赢”这条,一条条手工套,定位到具体是哪一行把它拦了。别凭印象,机制怎么判你就怎么算。
第三步,改对并压低缓存。把那条规则修正,确认robots响应没有设过长的Cache-Control,让新版本尽快被各引擎重新拉取。
第四步,主动催重抓。Search Console里请求重新抓取robots.txt,对最重要的几个受影响页用URL检查工具请求编入索引,把恢复链路的起点往前提。
第五步,按台阶式预期监控恢复。盯三条曲线的先后:Googlebot抓取量先回升、收录数随后跟上、自然流量最后才回来。给业务方的预期要讲清楚——robots缓存层面是一天上下,整体收录和流量恢复按页面重要度从数天到数周不等,重要页快、长尾慢,且不保证百分百回原位。
用这套流程收过一个真实的尾。一个做工业设备选型内容的B2B站,2023年中改版时被工程师误加了一条Disallow: /products/把整个产品库挡了,三周后市场部才发现询盘掉了一半来找。按上面五步:证据指向产品库路径的抓取在改版当天归零,最长匹配手算确认就是那条Disallow: /products/,改对、压缓存、催重抓。抓取量在大约一周后开始回升,主力产品页两周内陆续回到索引,长尾型号页拖到第五周才基本补齐,整体流量在第六周回到事故前八成多——典型的台阶式恢复,不是改完就反弹,但只要诊断准、顺序对,它一定会回来。robots误封是少数“可以完全恢复”的SEO事故,前提是你别在恢复期又因为着急乱改第二刀。
常见问题解答
robots.txt能阻止页面出现在Google搜索结果里吗?
不能。它只拦抓取不管收录,被Disallow的网址只要有外链就可能仍被收录,在结果里显示一行“无法提供此页面的说明”。想让页不出现在搜索里要用noindex,不是robots。
robots.txt必须放在哪里?子域名要单独写吗?
必须放在主机根路径,放子目录无效。它按协议加主机加端口绑定、不跨边界继承,所以每个子域、HTTP与HTTPS、不同端口都要各自单独有一份并单独确认正确。
Allow和Disallow冲突时谁说了算?
对Google是匹配路径最长的那条规则胜出,路径长度相等时Allow赢,不是按书写顺序先到先得。别家引擎判定细则未必一致,跨引擎部署要单独核。
robots.txt里写noindex还有用吗?
没用,Google早已不支持robots里的noindex指令。noindex要写在页面的meta标签或X-Robots-Tag响应头里,且该页必须允许抓取,否则这个指令读不到、不生效。
改了robots.txt多久生效?
Google缓存robots大约在一天量级,改完不是即时。放开抓取后还要经历重新发现、重抓、重排,重要页几天、长尾页数周,是台阶式恢复不是开关式。
用robots.txt隐藏后台或敏感目录安全吗?
不安全,反而更危险。Disallow行本身就把目录名公开列了出来,等于给攻击者指路。真正的保护靠身份鉴权、IP限制、把文件移出web根目录,robots做不了访问控制。
该不该用robots.txt封掉AI爬虫?
要先分清训练类还是检索引用类。训练类封不封是商业判断;检索引用类(如OAI-SearchBot、PerplexityBot)慎封,封了等于放弃被AI答案引用带流量的入口。别一刀切。
误写Disallow: / 整站掉了怎么紧急恢复?
先curl确认线上robots内容、改掉那条、压低缓存头,再去Search Console请求重抓robots并对核心页请求编入索引,然后按抓取量、收录、流量先后顺序监控台阶式恢复,恢复期别再乱改。
权威参考资料
本文标题:《网站突然从谷歌消失,多半是robots.txt写废了》
本文链接:https://zhangwenbao.com/robots-exclusion-protocol-mechanism-complete-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0