做SEO量出74%的页面对爬虫和用户不一样,补上一组对照之后只剩2.2%
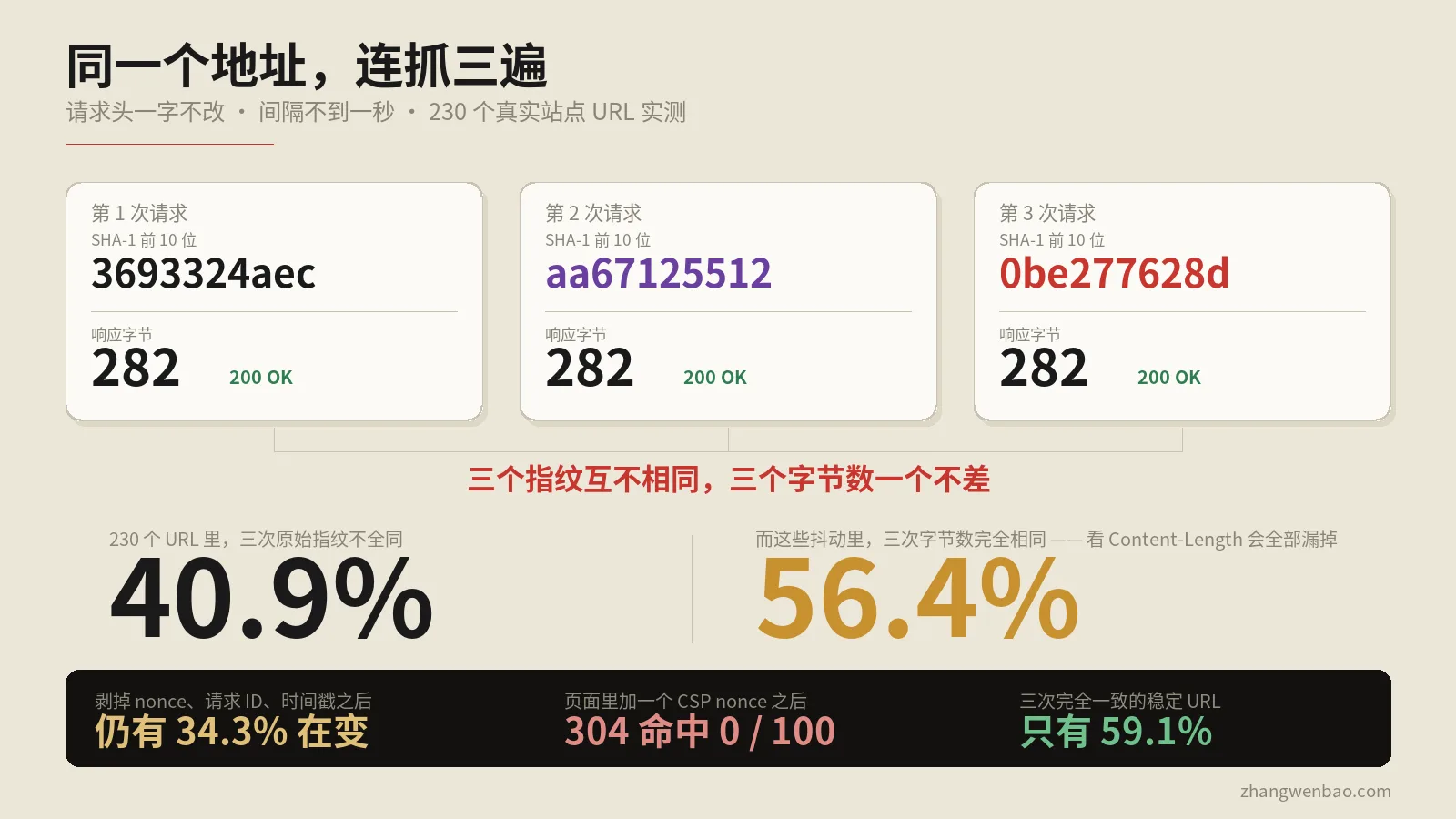
230个真实URL连抓三遍的实测:40.9%三次原始指纹不全同,其中56.4%三次字节数完全相同、靠Content-Length根本看不出来;剥掉nonce与请求ID等高熵串之后仍有34.3%在变;nginx实验台上一个CSP nonce把条件请求的304命中率从100/100打成0/100,另附抖动成因归类与五步基线测法。
标签
保哥笔记 抓取预算 标签下共 26 篇文章合集,含《做SEO量出74%的页面对爬虫和用户不一样,补上一组》《限速规则拒掉的第4个请求是robots.txt,全站》《nginx出厂只压HTML这一种类型,其余的字节全额》等,与 技术SEO、分面导航、软404 主题密切相关,覆盖 SEO/GEO 实战角度的深度解析与可落地方案。
230个真实URL连抓三遍的实测:40.9%三次原始指纹不全同,其中56.4%三次字节数完全相同、靠Content-Length根本看不出来;剥掉nonce与请求ID等高熵串之后仍有34.3%在变;nginx实验台上一个CSP nonce把条件请求的304命中率从100/100打成0/100,另附抖动成因归类与五步基线测法。
一条抄来的limit_req写在server级,爬虫抓到第4个页面就把配额吃光,接着robots.txt和sitemap.xml双双吃到503。而按官方规矩,robots.txt取不到会让Google前12小时停止抓取整站。想把它摘出来时才发现,limit_req off这条指令根本不存在。

把CSS、JS、XML补进类型清单,一套典型资源从605 KB降到153 KB;再把压缩级别从1提到6,只多省2.3个百分点。两件事的性价比差了25倍,而绝大多数教程的篇幅都花在后面那件上。

同一个页面,服务器答200要走12万字节,答304只要175字节。真正卡住的不是站长不肯配ETag,而是配完之后没有任何人告诉你它已经失效了——本文把16种服务器配置逐个打了一遍。

从默认站点的选定规则讲到add_header的继承边界、两种301对查询参数的相反处置、压缩类型清单里那个根本不存在的MIME,最后给出一套按边界输入逐项探测的检查顺序。
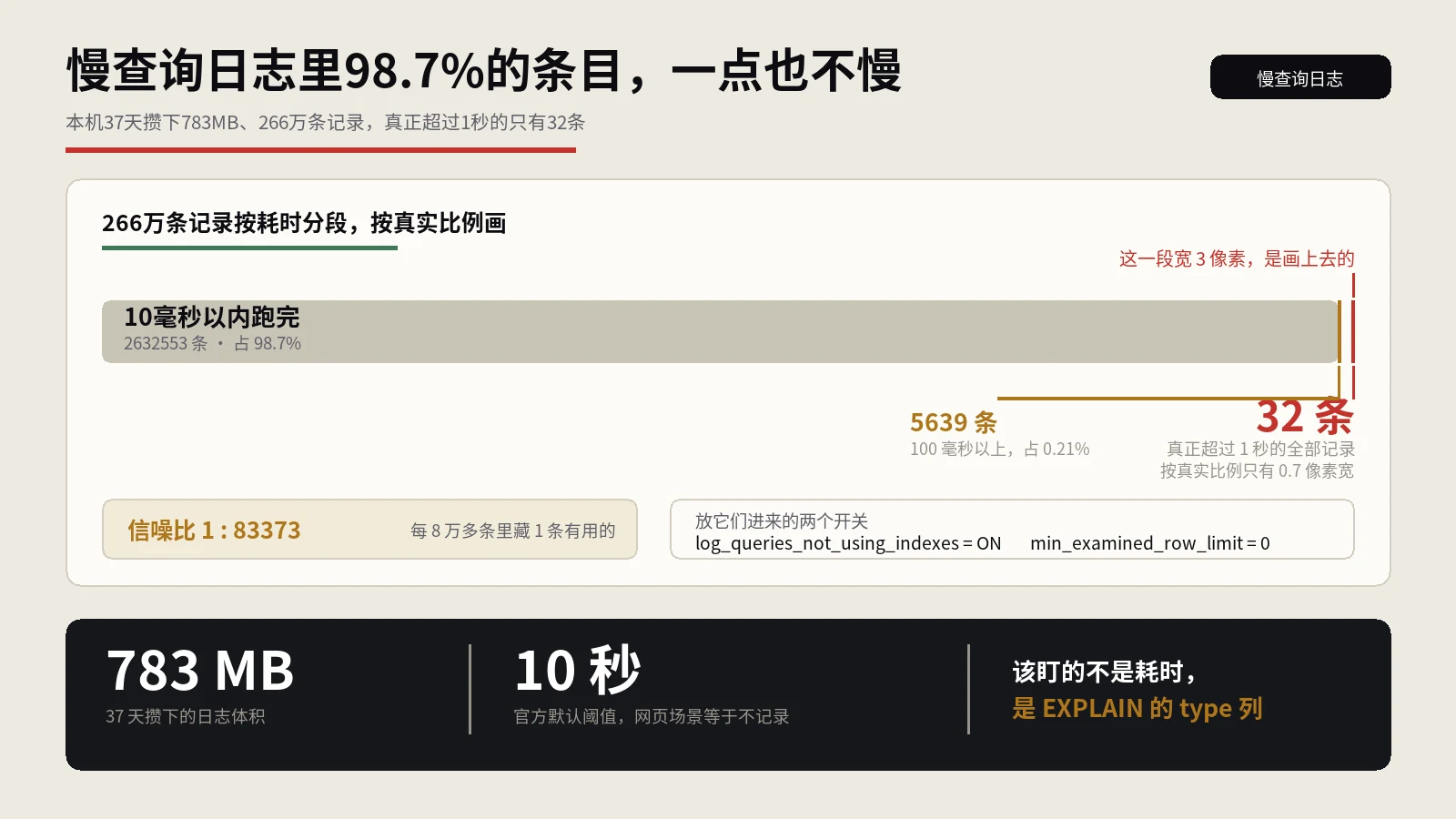
从两个记录开关讲到EXPLAIN的四列读法、最左前缀为什么让建好的索引落空、临时表与文件排序各自意味着什么,并给出一套清缓存冷启动验证的收尾办法与季度可复用的排查顺序。
平台自己不持有库存,商品全靠成千上万个卖家生成,这让它的搜索优化天生比自营站难一档。本文拆解怎么同时喂饱买卖两拨人相反的搜索意图、怎么靠平台规则批量抬高参差不齐的详情页质量、怎么驯服筛选参数生成的百万级链接不拖垮爬虫,并给出冷启动阶段先建哪几类页的排序框架,和一个出海撮合平台把自然流量做起来的实战复盘。

招聘类网站靠海量职位页吃流量,可职位又薄又短命,一年能攒下几千个死页拖垮收录。本文拆解职位页怎么进Google求职、过期职位怎么收尾才不挨罚、分面URL怎么治理,以及为什么真正扛排名的是聚合页而不是单条职位。
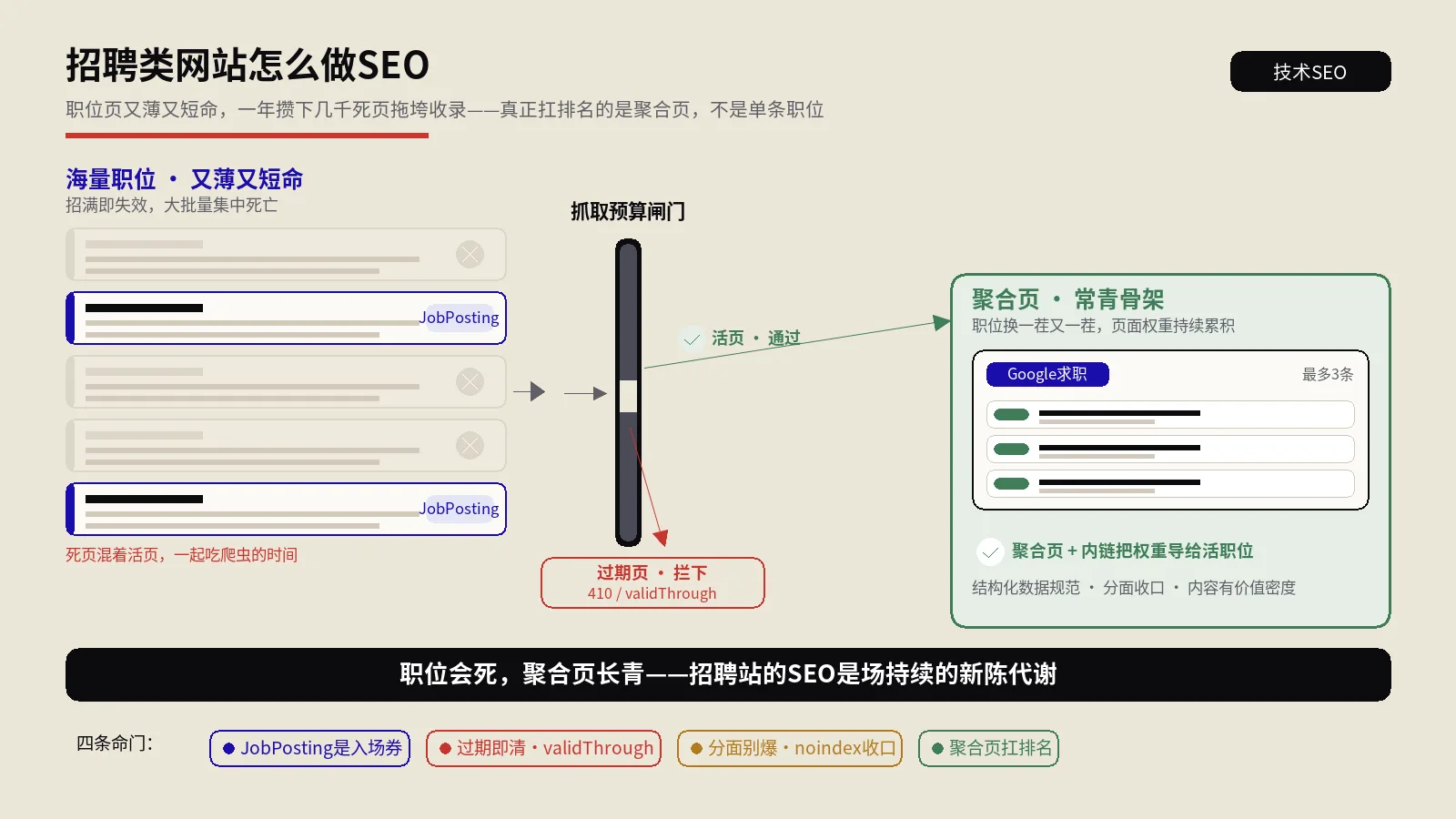
分面导航让用户叠加筛选找货,却在URL层面生出成千上万近重复地址,吃光抓取预算、撑爆索引、稀释内链权重。这篇讲清该先用搜索需求把筛选分成值得索引和纯噪声两堆,再分别用canonical、noindex、robots.txt和AJAX各管一段,附决策树与平台落地。
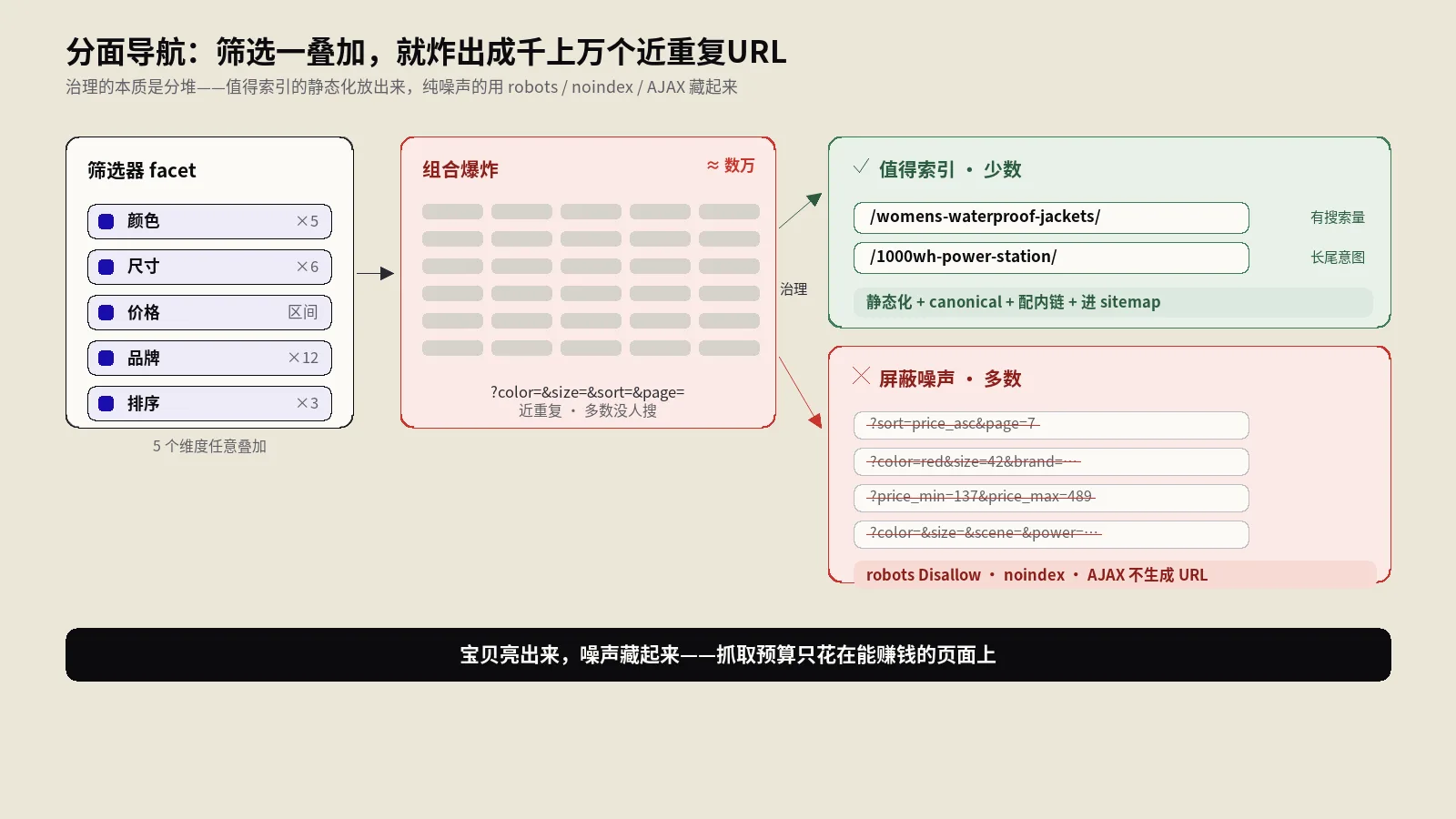
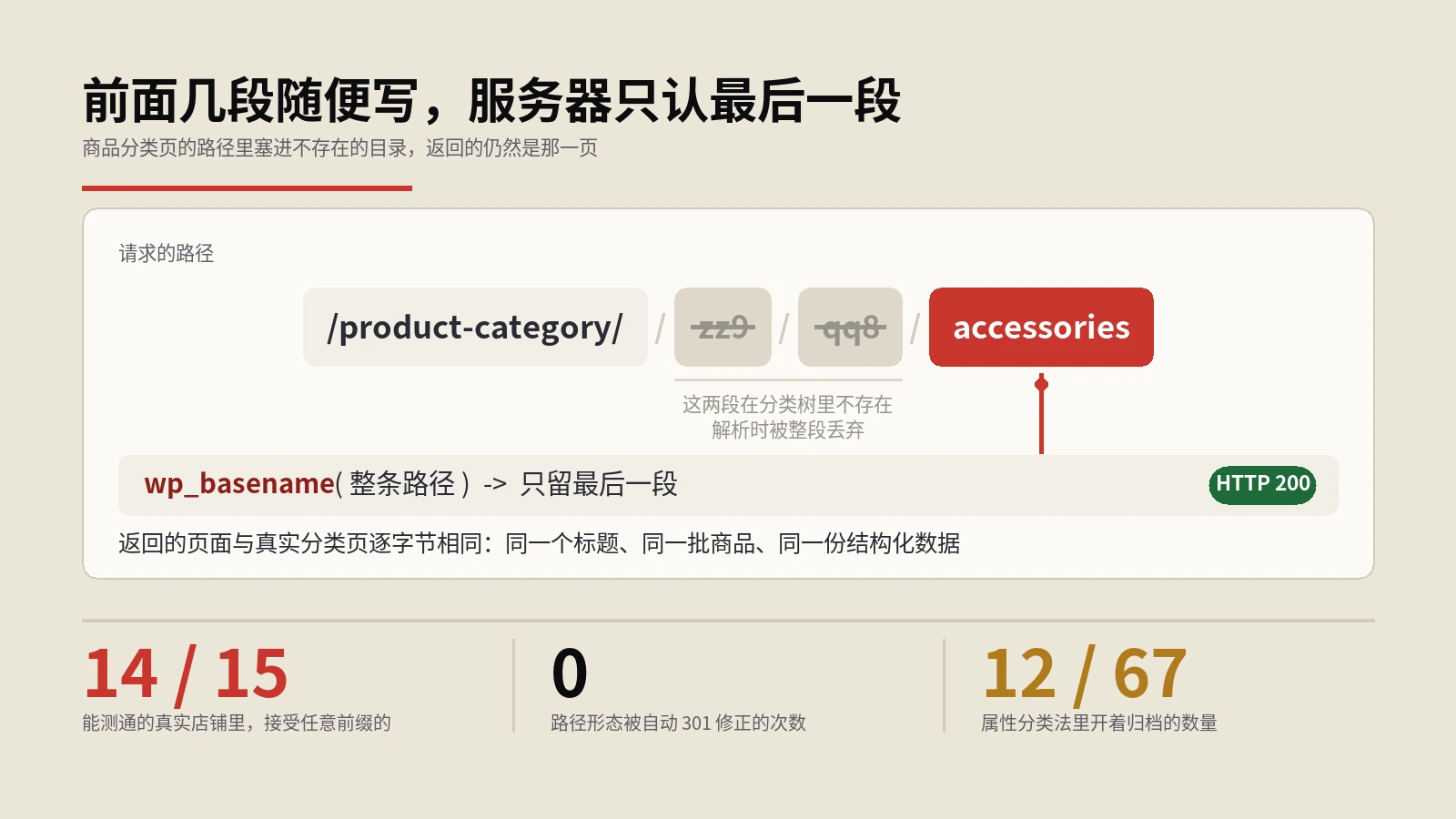
商品分类归档在WooCommerce里会悄悄长出成倍的等价地址,后台完全看不见。这里拆解注册参数与解析机制,给出十分钟自查方法和按分类法分档的处置矩阵。
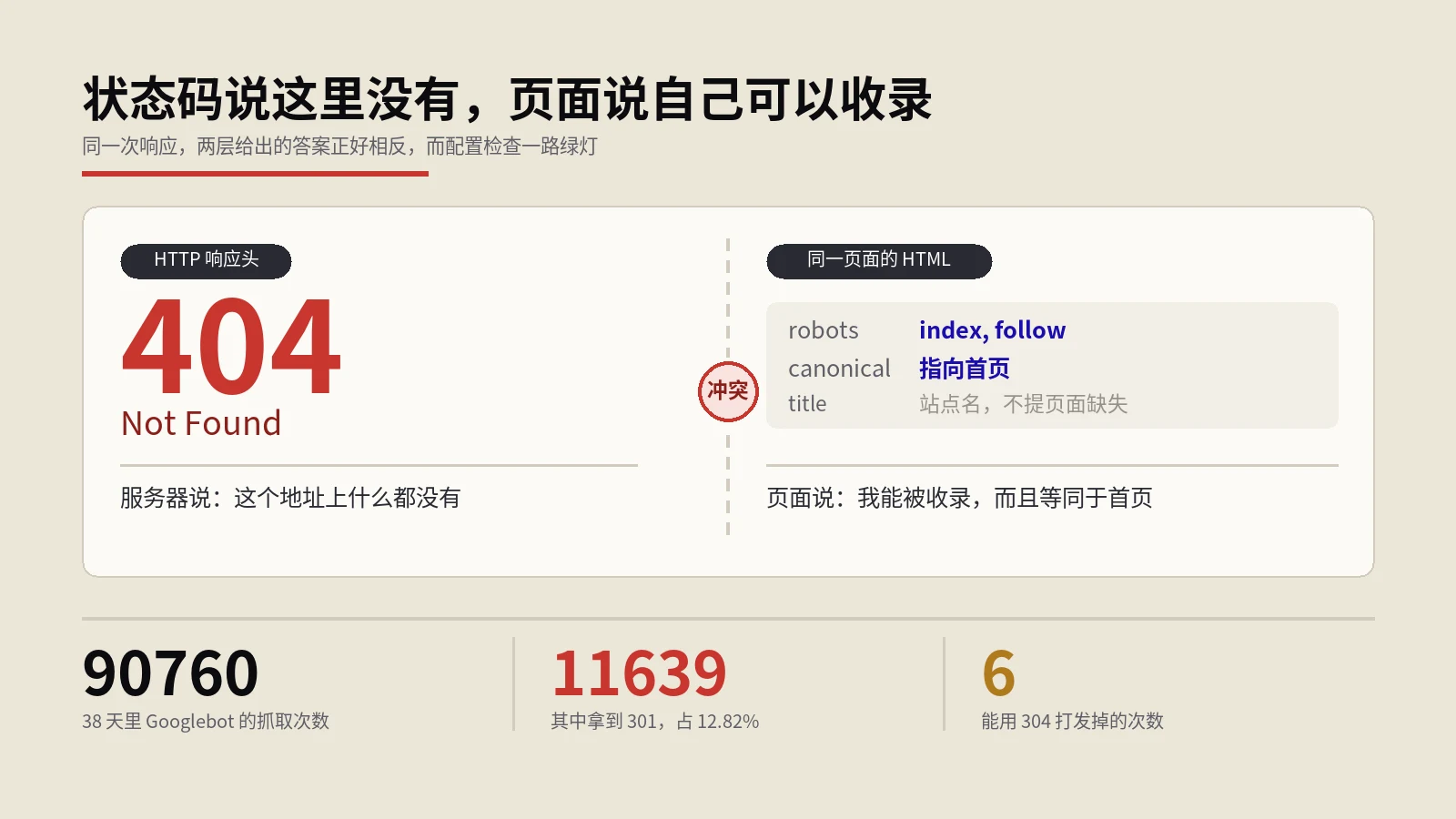
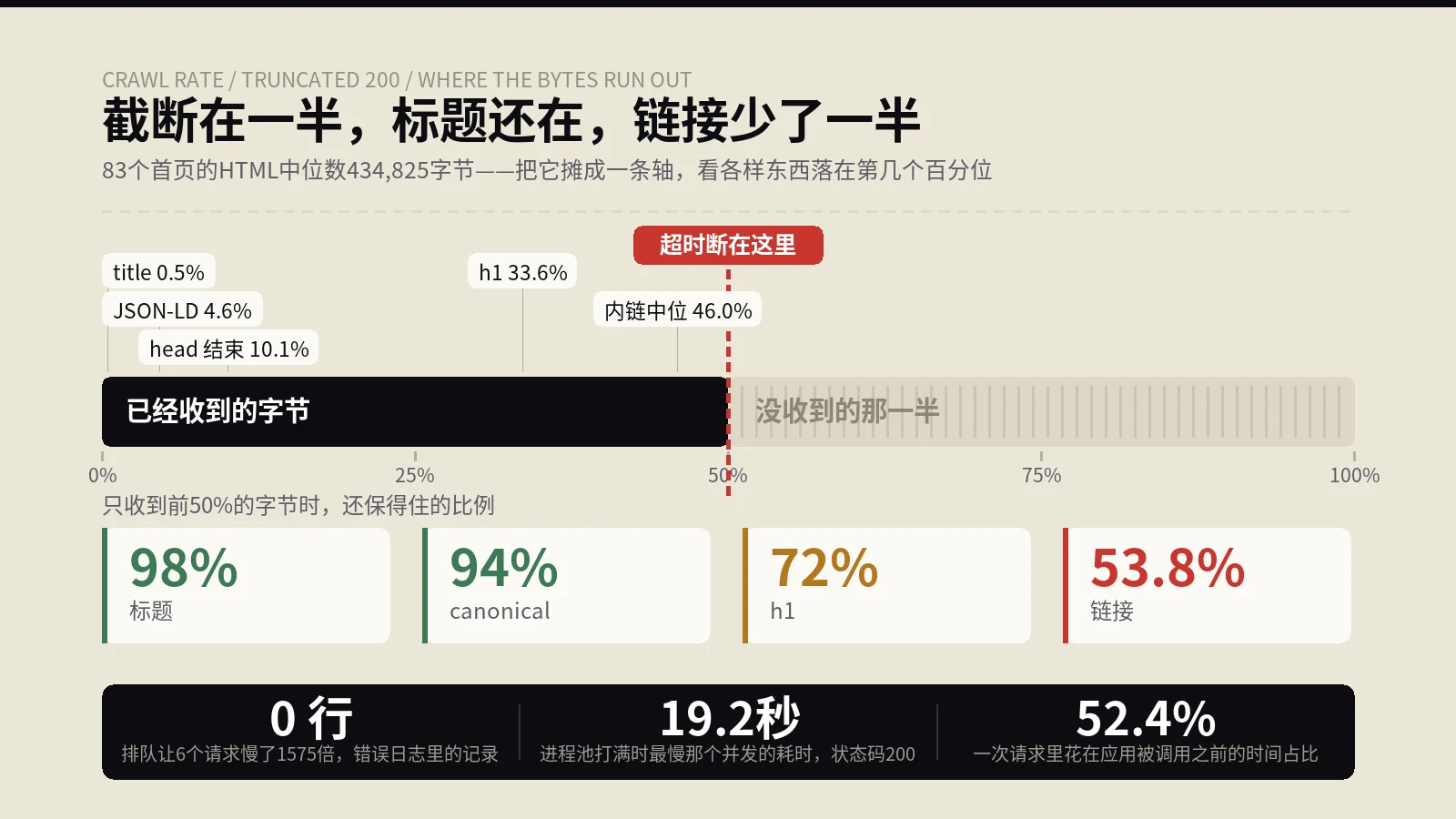
Google把抓取容量算成服务器为它保持连接的总时长,所以变慢和报错是同一件事。可排队的6个请求全返回200、错误日志一行没有;进程池打满让并发从8.2秒排到19.2秒,状态码还是200。这一族故障共同的特征是:全部以2xx收场。
Site Audit跑出来500个问题不代表要修500个——技术SEO修复必须按业务影响排序,而不是按工具的问题计数。本文拆解ICE、RICE、PIF三套打分模型的实操差异,给出7类常见技术问题的真实ICE评分对照表,再补5个Quick Wins可复制模板和4个向老板汇报的真业务指标。

很多团队习惯在站内链接上挂utm_source做点击归因,却没意识到这会让搜索引擎反复抓重复URL、让分析工具错记流量来源。这篇拆解追踪参数从抓取预算、归因、链接权重到AI访问的四重伤害,并给出把追踪迁移到DOM数据属性的完整落地步骤与验证方法。
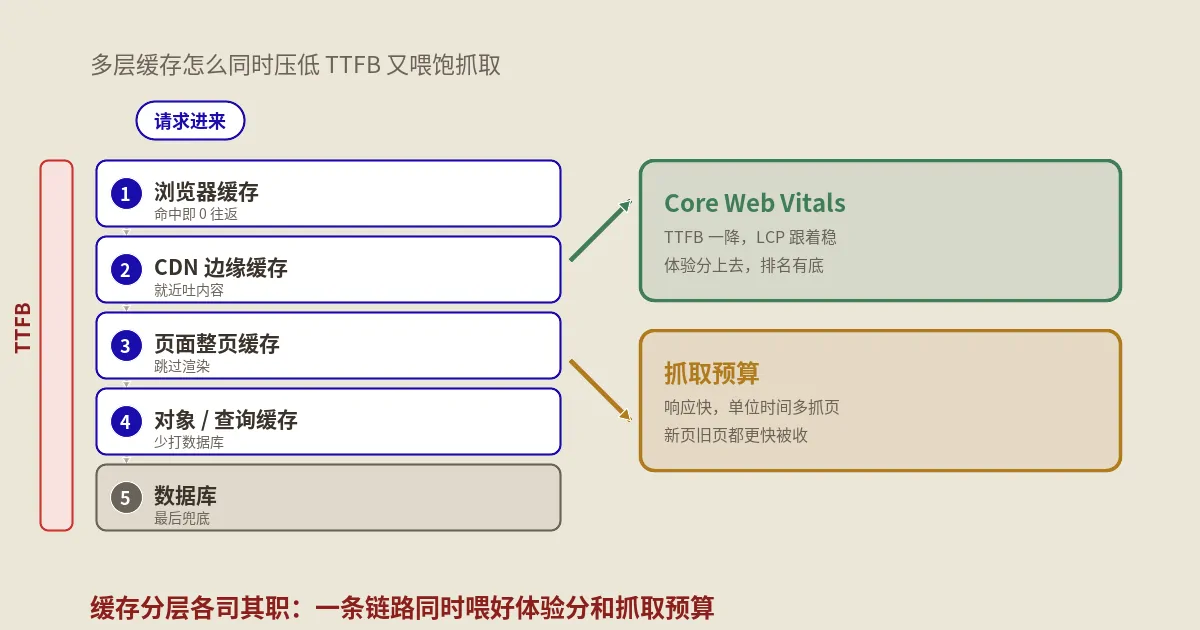
聊页面速度,大家都盯着图片压缩和JS拆包,却忽略了最底层的TTFB——浏览器在下载任何资源之前,得先等服务器吐出第一个字节。保哥这篇专讲这块隐形地基:TTFB慢到底慢在从点击到首字节的哪一段,一个请求要穿过浏览器、CDN、全页缓存、对象缓存到数据库的几层缓存,全页缓存怎么和登录态、购物车这类动态内容共存,为什么缓存命中反而可能让Google抓到旧价格旧canonical,TTFB和LCP是什么关系,服务器响应快真能让Google多抓页面…
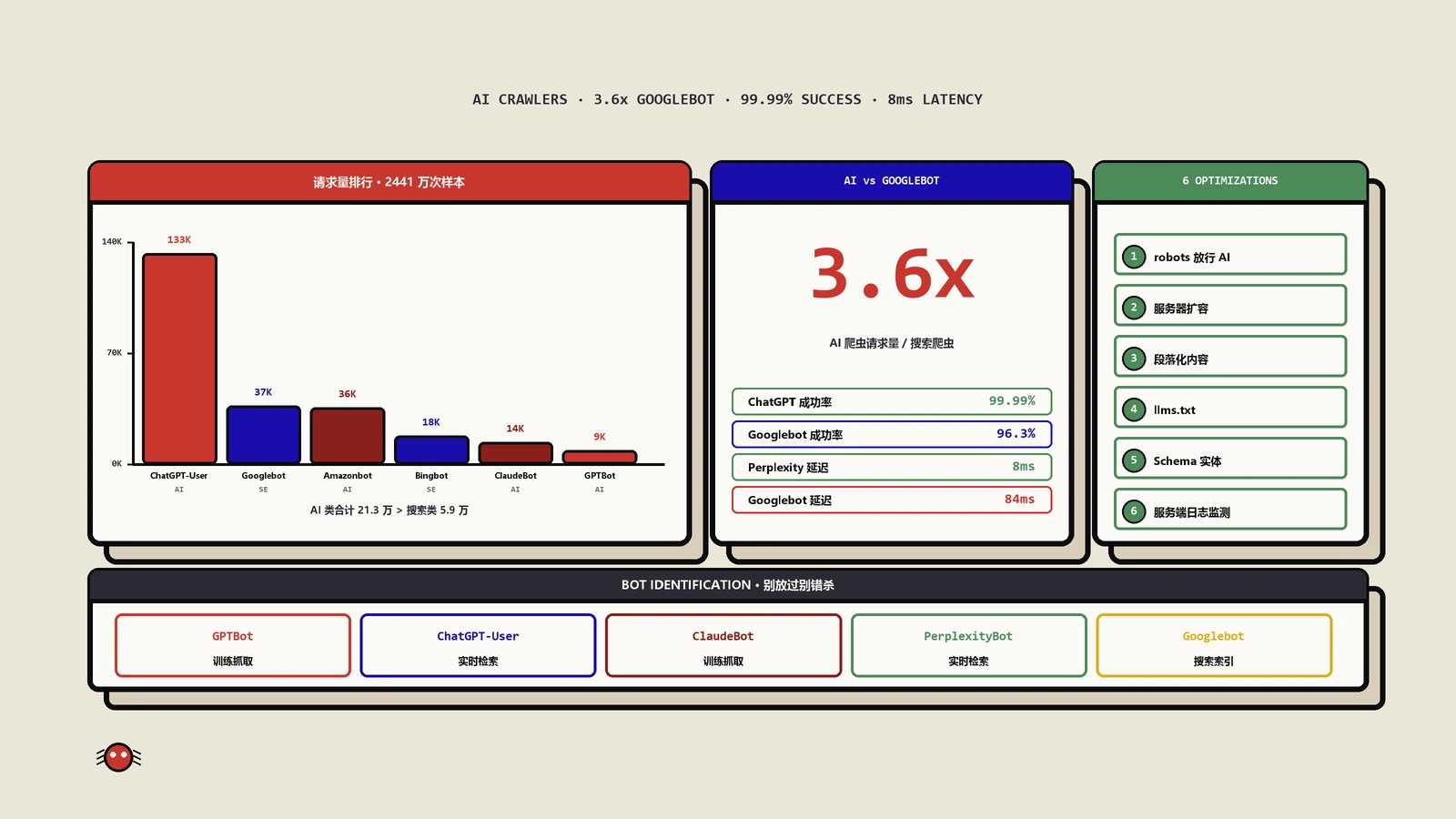
2400万次请求数据揭示,ChatGPT爬虫抓取量已达Googlebot的3.6倍。本文深度解析AI爬虫生态格局,提供robots.txt配置、抓取预算优化、AI搜索可见性提升等实操策略。
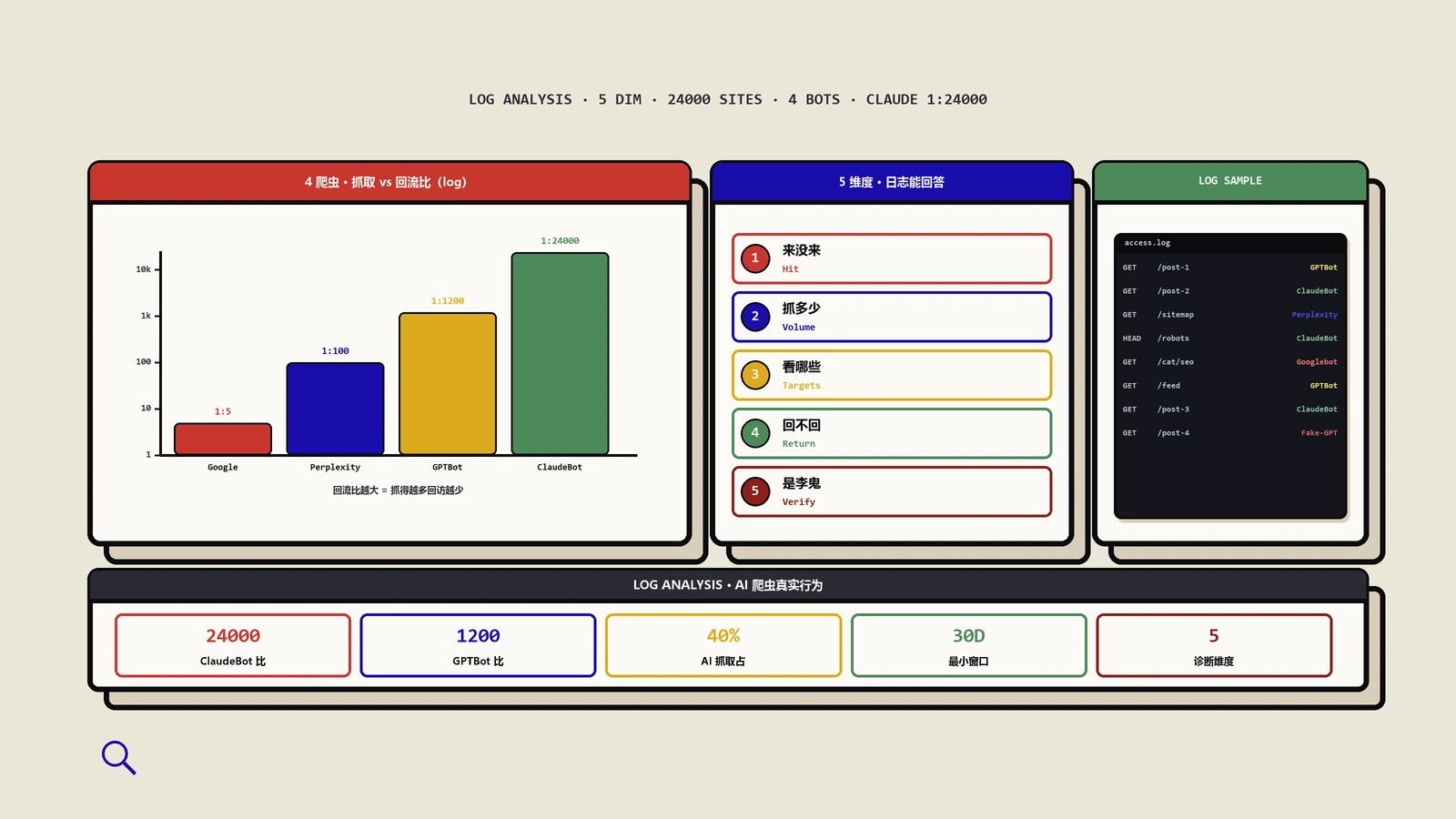
你的内容每天被AI爬虫抓走喂进ChatGPT和Claude的回答,但没有任何官方报表能让你看见这件事。这篇带你用服务器日志补上这块盲区:分清训练型与检索型爬虫为什么要区别对待、五层诊断怎么一步步深入、命令行和Python脚本怎么落地、日志为什么必须搬出主机长期存,以及robots.txt分层和迁移验真该怎么做。
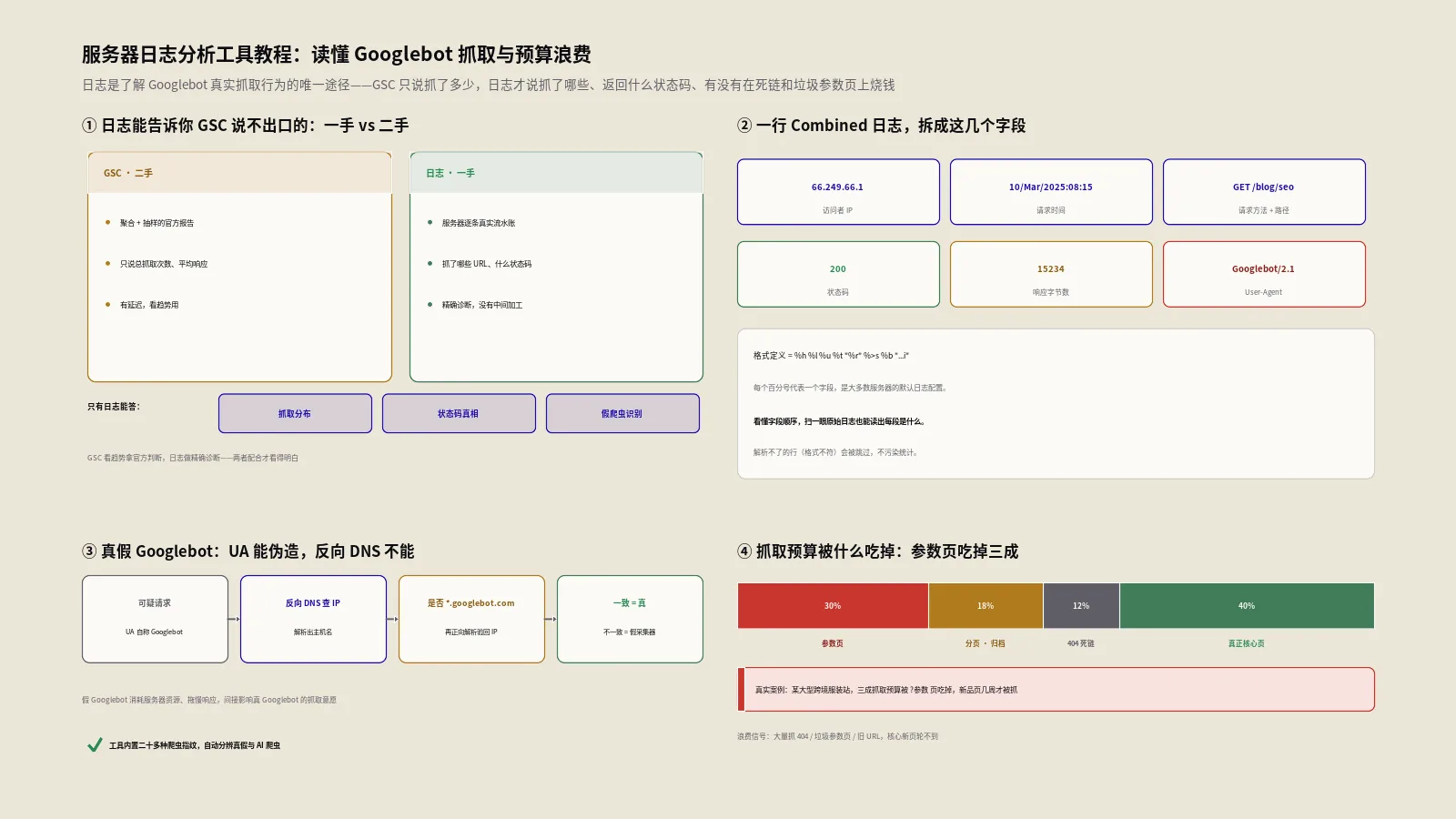
Search Console只告诉你抓了多少,日志才告诉你抓了哪些、有没有在死链和参数页上烧钱。这款工具解析爬虫日志,几分钟揪出抓取预算浪费点。
Google官方确认高频抓取是积极信号,但抓取激增也可能暗藏无限空间陷阱。保哥从Crawl Budget双引擎原理出发,给出12项实操策略、5个真实案例、GSC数据解读与服务器日志分析完整方法。

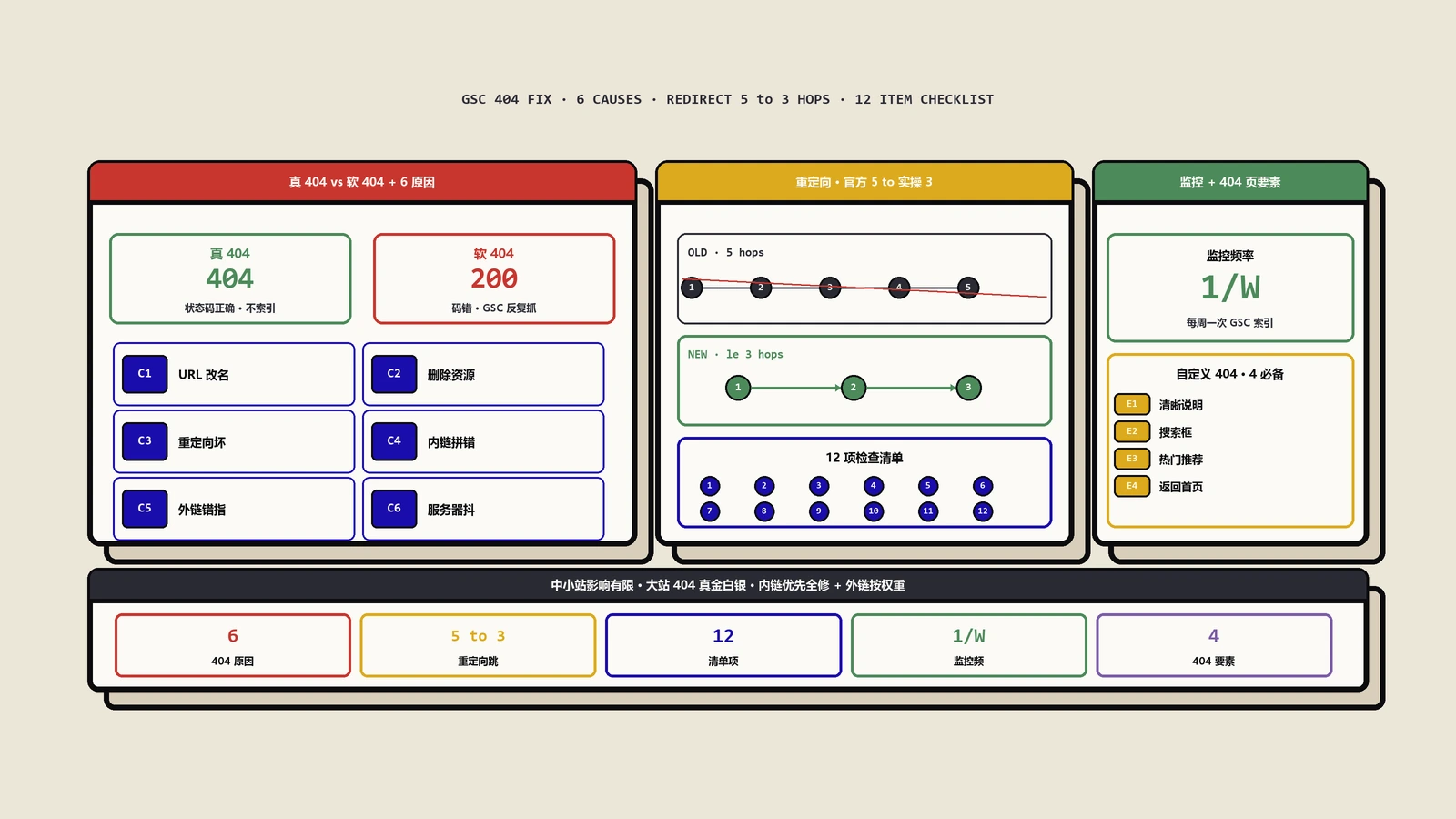
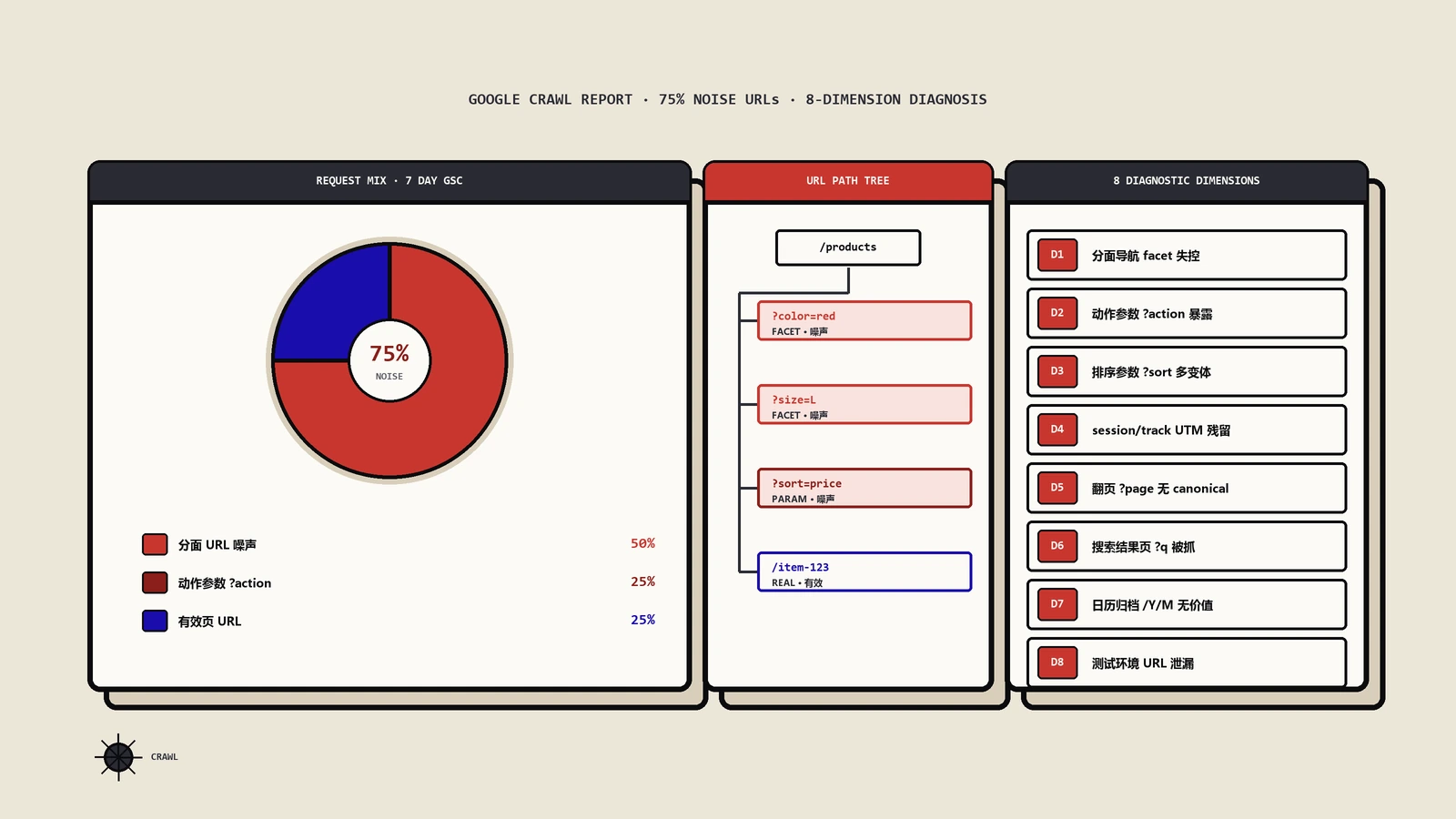
网站收录上不去、新页面几周不被抓,大概率不是内容差,而是URL结构在批量造垃圾链接。本文按Google公布的抓取问题成因分布——分面导航五成、动作参数两成半——教你对号入座、按占比排修复优先级,并给出每一桶(尤其最被忽视的动作参数那25%)的具体处置与验证口径。
Google Search Console满屏404错误怎么办?本文从404与软404的本质区别讲起,到GSC精准定位、六大常见原因分析、不同场景下的修复策略,提供.htaccess和Nginx的完整配置代码,并讲解抓取预算优化和外链权重抢救的高阶技巧。