服务器日志分析工具教程:读懂Googlebot抓取与预算浪费
本文目录
- 服务器日志能告诉你Search Console说不出口的什么?
- 工具是怎么把一行行日志解析成数据的?
- 它能识别哪些爬虫?真假Googlebot怎么分辨?
- 抓取预算到底是什么?为什么大站才要操心?
- 怎么用工具跑一次完整的爬虫日志分析?
- 日志里哪些信号说明抓取预算正在被浪费?
- 除了状态码,日志还能看出哪些SEO信号?
- AI爬虫该不该拦?日志怎么帮你做决策?
- 日志分析怎么和链接、锚文本审计串成闭环?
- 用日志数据做SEO决策时容易误判什么?
- 多大规模的站需要定期做日志分析?
- 常见问题解答
- 服务器日志分析和Search Console的抓取统计有什么区别?
- 抓取预算是不是所有网站都要操心?
- 怎么确认日志里的Googlebot是真的?
- 日志文件太大,浏览器打不开怎么办?
- 为什么有些日志行没有被解析?
- 发现大量抓取浪费后,最优先该做什么?
- 权威参考资料
摘要:服务器日志是了解Googlebot真实抓取行为的唯一途径——Search Console只告诉你抓了多少,日志才告诉你抓了哪些、返回什么状态码、有没有在死链和垃圾参数页上烧钱。这款日志分析器把Apache/Nginx的Combined日志按行解析,识别Googlebot、GPTBot等二十多种爬虫,统计状态码分布和热门URL,帮你揪出抓取预算的浪费点。保哥这篇讲透日志解析原理、真假Googlebot的辨别、抓取预算的本质,再用一个大型跨境服装站三成抓取预算被参数页吃掉的真实案例,演示怎么从日志里读出问题。
做技术SEO到一定阶段,你会遇到一个Search Console回答不了的问题:Googlebot到底把时间花在哪了?GSC的“抓取统计信息”能告诉你“过去一段时间抓了多少次、平均响应多少毫秒”,但它不会逐条告诉你——Googlebot这次抓的是你的核心产品页,还是一个早该删掉的 ?sessionid=xxx 垃圾参数页?是顺利返回200,还是撞上了一片404?
这些问题只有服务器日志能回答。日志是服务器对每一次访问的忠实记录,谁来的、要什么、给了什么状态码,一行不落。保哥这套日志分析器,就是把这堆又长又密的原始日志,解析成你能一眼看懂的图表和排行——爬虫占比、状态码分布、热门URL、抓取预算浪费分析。这篇教程不只教你上传日志点分析,更要讲清楚它怎么解析、能识别什么、以及最关键的——怎么从日志里读出“抓取预算正在被浪费”的信号。
服务器日志能告诉你Search Console说不出口的什么?
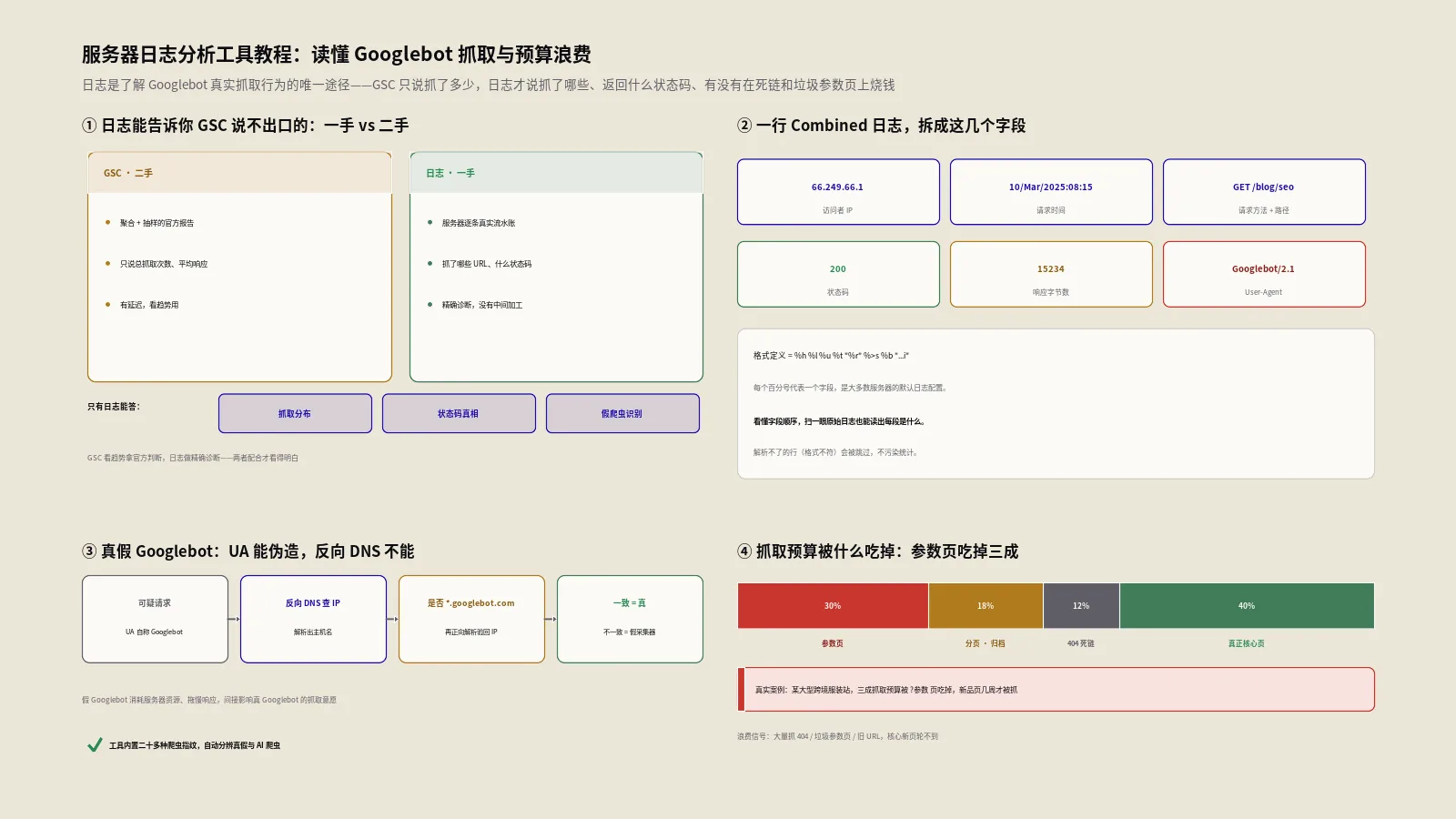
先把日志的不可替代性说透。Search Console是Google给你的“官方报告”,但它是经过聚合和抽样的二手数据;服务器日志是你自己服务器记下的一手流水账,没有任何中间加工。两者的差距,决定了很多问题只能靠日志解决。
第一类是“抓取分布”问题。GSC告诉你总抓取次数,但不告诉你这些次数怎么分配。可能Googlebot把六成预算花在了一堆无索引价值的筛选参数页上,你的新品页却几周才被光顾一次——这种结构性浪费,只有日志的热门URL排行能暴露。
第二类是“状态码真相”。GSC的覆盖率报告有延迟、有抽样,而日志记录的是每一次请求的真实状态码。Googlebot是不是在大量抓404?有没有撞上一批5xx?这些在日志里是精确到次的,不像GSC那样要等数据回填。
第三类是“假爬虫识别”。GSC只报告真正的Googlebot,但你的服务器其实天天被伪装成Googlebot的采集器、扫描器骚扰。这些假爬虫消耗服务器资源、拖慢响应,间接影响真Googlebot的抓取意愿。只有看原始日志里的IP和User-Agent,你才能发现它们。
保哥的经验是:GSC用来看趋势和拿Google的官方判断,日志用来做精确诊断。当GSC告诉你“有些页面发现了但未编入索引”,却不告诉你为什么时,答案往往藏在日志里——可能Googlebot压根没怎么来,也可能来了但被一堆垃圾URL带偏了。两者配合,才能把抓取这件事看明白。
工具是怎么把一行行日志解析成数据的?
日志看起来是一堆乱码,其实有严格的格式。理解工具怎么解析,你才知道为什么有些行能解析、有些会被跳过。
最主流的是Apache/Nginx的Combined日志格式。一行典型的日志长这样:66.249.66.1 - - [10/Mar/2025:08:15:32 +0000] "GET /blog/seo-guide HTTP/1.1" 200 15234 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"。
这一行里依次是:访问者IP、两个占位的身份字段、方括号里的时间、引号里的请求行(方法+路径+协议)、状态码、响应字节数、来源页referer、最后是User-Agent。看懂了字段顺序,你自己扫一眼原始日志也能大致读出每段是什么。Apache在它的 mod_log_config官方文档里把这套格式定义为 %h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-agent}i\",每个百分号代表一个字段,这也是大多数服务器的默认日志配置。
工具用正则表达式按这个结构逐行匹配,把每一段抠出来变成结构化字段:IP、时间、方法、路径、状态码、字节数、referer、UA。还有一种更简单的Common格式,没有最后的referer和UA两段,工具也能识别——它会先尝试用Combined正则匹配,匹配不上再退回Common正则。
这就解释了一个常见疑问:为什么有些行没被解析?因为它们不符合这两种标准格式。常见原因有几个:用了自定义日志格式(字段顺序或内容不一样)、上传的是错误日志 error.log 而不是访问日志 access.log、或者日志里混入了多行的请求体。工具会显示解析成功率,如果成功率很低,多半是格式没对上。这时要么调整服务器的日志格式配置,要么先把日志转成标准格式再上传。CDN的日志(Cloudflare、Fastly等)格式可能和标准不同,用前最好确认一下。
它能识别哪些爬虫?真假Googlebot怎么分辨?
解析完字段,工具的核心工作之一是识别爬虫。它内置了二十多种爬虫的识别规则,按User-Agent字符串匹配,还按用途分了几类。
搜索引擎类有Googlebot、Bingbot、Baiduspider、YandexBot、DuckDuckBot、Applebot、Sogou、PetalBot等。AI类是这两年的新增重点:GPTBot、ClaudeBot、CCBot、ByteSpider等,它们抓你的内容是为了训练或回答用户的AI提问。SEO工具类有AhrefsBot、SEMrushBot、MJ12bot等,是各家SEO平台的数据采集器。
识别Googlebot时还有个容易被忽略的细节:工具会区分主Googlebot和Googlebot-Image、Googlebot-Video、Googlebot-News这些子爬虫,避免把图片抓取和网页抓取混为一谈。这点很实用——有时候你以为Googlebot抓得很勤,细看才发现大半是图片爬虫在抓图,真正的网页抓取并不多。
但这里有个所有日志工具都绕不开的局限:User-Agent是可以伪造的。任何人都能把自己的爬虫UA改成Googlebot的样子,所以仅凭UA字符串识别出来的“Googlebot”,未必是真的。保哥见过不少站,日志里“Googlebot”的请求量大得离谱,一查全是伪装的采集器在薅内容。
怎么辨真假?Google在它的验证Googlebot的官方文档里给了标准方法:对日志里那个IP做反向DNS查询,确认它解析出的域名是 googlebot.com、google.com 或 googleusercontent.com;然后再对这个域名做一次正向DNS查询,确认它解析回的IP和原IP一致。
这套“正向确认的反向DNS”(FCrDNS)才是可靠的验证——因为光做反向解析,伪造者也能把自己的反向DNS指成googlebot.com的样子,必须靠正向回查戳穿。这一步工具本身不做,它只按UA识别,需要你在服务器端用命令行完成,或者用Google公布的IP段列表批量比对。日志里那些可疑的高频“Googlebot”,验一下往往原形毕露。
抓取预算到底是什么?为什么大站才要操心?
“抓取预算”这个词被说滥了,但很多人没真正理解它。保哥用Google官方的定义来讲清楚。
Google在大型网站抓取预算管理文档里说得很明白:网络几乎是无限大的,超出了Google能够探索和索引每一个URL的能力,所以Googlebot花在任何单一站点上的时间是有限的。这个有限的量,就是抓取预算。它由两部分决定:一是“抓取容量上限”——你的服务器能承受多大的抓取压力而不变慢;二是“抓取需求”——Google觉得你的内容有多大价值、多需要被重新抓取。
关键来了:抓取预算对大多数中小站点根本不是问题。如果你的站只有几百个页面,Googlebot的预算绰绰有余,每个页面都能被勤快地光顾,你完全不用操心。Google自己也说,抓取预算主要是大型站点(通常指上万个URL以上)才需要管理的事。
那什么样的站要操心?典型的是SKU海量的电商站、内容海量的资讯站、以及那些会自动生成大量URL的站(比如带各种筛选、排序、分页参数的)。这些站的URL数量远超Googlebot愿意分配的预算,于是就出现了“僧多粥少”——预算如果被低价值URL占用,真正重要的页面就抢不到抓取机会。Google给的提升预算的办法其实只有两条:提升服务器的抓取承载能力,以及(更重要的)提升内容对搜索者的价值。但在那之前,先得堵住浪费——这正是日志分析的用武之地。
怎么用工具跑一次完整的爬虫日志分析?
把流程走一遍。保哥拆成可复制的步骤。
第一步,拿到日志文件。Apache默认在 /var/log/apache2/access.log,Nginx在 /var/log/nginx/access.log,也可以通过宝塔面板、cPanel或云服务商控制台下载。日志文件往往很大,建议先用命令行过滤出爬虫的行再上传,比如 grep -i "bot\|spider\|crawler" access.log > bots.log,浏览器处理50MB以内的日志比较稳。
第二步,上传并选对格式。把文件拖进去或粘贴内容,格式选Apache Combined(Nginx默认也兼容这个)。工具会逐行解析并显示成功率。如果成功率很低,回去确认是不是格式没对上、或者传错成了error.log。
第三步,先看爬虫占比和状态码。结果出来后,第一眼看两个东西:Googlebot占了多少请求、状态码分布健不健康。重点盯4xx比例——Google建议Googlebot抓取的页面里4xx应低于5%,超了说明死链太多在浪费预算。再看有没有连续的5xx,那会直接导致Googlebot大幅减少抓取。
第四步,查热门URL排行。这是最出问题的地方。看Googlebot抓得最多的那些URL,是不是你的核心产品页、重要内容页?还是一堆 ?sort=、?filter=、?sessionid= 的参数页?如果预算大量花在后者上,就是典型的浪费。
第五步,定位浪费并动手。找到浪费点后,对症下药:用robots.txt屏蔽低价值的参数URL、修复404死链、把多跳的重定向链改成直链、给重要页面提交sitemap引导优先抓取。处理完,过段时间再下载新日志复查,看Googlebot的抓取分布有没有改善。
日志里哪些信号说明抓取预算正在被浪费?
这是日志分析最值钱的部分。保哥用一个真实案例来讲,怎么从日志里读出浪费。
有个做大型跨境服装电商的站,SKU上万,商品有颜色、尺码、价格区间、排序方式等一堆筛选维度。运营一直纳闷:明明天天上新品,很多新款上线两三周了Googlebot才慢悠悠来抓一次,收录奇慢。保哥让他们导出一周的Googlebot日志扔进分析器,问题一目了然。
那一周Googlebot总共来了约12000次。状态码分布上,200占62%、301占18%、404竟然占了12%——远超5% 的健康线,说明站内有大批死链(多是下架商品没做处理)。但更触目惊心的是热门URL排行:抓取量最高的几十个URL,几乎全是 ?color=red&size=M&sort=price 这种筛选参数页,真正的新品详情页排在很靠后。粗算下来,光是筛选参数页和404加起来,就吃掉了将近三成的抓取预算。难怪新品抓不过来——Googlebot的预算全耗在这些无索引价值的组合页和死链上了。
诊断清楚,修复方案就明确了:第一,用robots.txt屏蔽掉那些筛选排序参数的抓取(这些组合页本就不该进索引);第二,把下架商品的404统一做成301跳到对应分类页,消灭死链;第三,给新品详情页单独出一个高频更新的sitemap,引导Googlebot优先抓。三招下去,一个月后再看日志,筛选参数页的抓取量降到个位数百分比,404降到3% 以下,新品的平均收录时间从两三周缩短到了两三天。
这个案例的启示是:抓取预算浪费几乎都长一个样——爬虫的精力被低价值URL(参数页、死链、重定向链、无限日历这类陷阱)大量占用,核心页反而饿着。日志分析器的状态码分布和热门URL排行,就是专门用来抓这两个信号的。看到4xx偏高、看到热门URL全是垃圾参数页,基本就实锤了。
除了状态码,日志还能看出哪些SEO信号?
状态码分布和热门URL是日志分析的主菜,但日志里还藏着几个常被忽略、却很有价值的信号。保哥每次分析都会顺手看一眼。
第一个是抓取频率的时间分布。把Googlebot的请求按小时、按天铺开,你能看出它来的节奏。如果某天抓取量突然断崖式下降,往往预示着技术故障——服务器那天是不是宕过、响应是不是变慢了、robots.txt是不是被误改了。抓取频率的异常下跌,常常比排名下跌更早发生,是个很灵的预警信号。反过来,发布新内容后看Googlebot有没有在随后几天加大抓取,也能判断新内容有没有被及时发现。
第二个是文件类型分布。Googlebot的预算不只花在HTML页面上,CSS、JS、图片它也抓。如果你发现爬虫在图片、静态资源上花的请求量异常高,而HTML页面占比偏低,可能意味着资源没设好缓存、或者有大量重复资源在被反复抓。对预算紧张的大站,让Googlebot少在静态资源上耗、多抓HTML,是个优化方向。
第三个是HTTP方法和referer。正常的爬虫抓取以GET为主,如果日志里冒出大量POST、HEAD或奇怪的方法,值得警惕是不是有异常行为。referer字段则能帮你理解流量来源,虽然对纯爬虫分析用处有限,但在排查异常流量、识别盗链时很有用。
这些信号单看都不起眼,但合起来能拼出一幅更完整的“爬虫到底怎么对待你的站”的画像。日志分析的功力,很大程度上就体现在能不能从这些边角信号里读出门道。
AI爬虫该不该拦?日志怎么帮你做决策?
这两年日志分析多了一个新维度:AI爬虫。GPTBot、ClaudeBot、CCBot、ByteSpider这些爬虫抓你的内容,不是为了传统搜索排名,而是为了训练大模型或回答用户在AI里的提问。该不该让它们抓,是个新问题。
日志分析器能帮你先看清现状:这些AI爬虫在你站上的抓取量有多大、抓的是哪些页面。有了数据,决策才不盲目。保哥的基本判断是——如果你在意GEO(让你的内容出现在AI的回答里、被AI引用),那就不该一刀切地拦AI爬虫,因为它们抓不到你的内容,AI自然不会引用你。这跟传统SEO里“让Googlebot抓到才能被收录”是一个道理,只是舞台换成了ChatGPT、Claude这些AI。
但也有该拦的情况。如果某个AI爬虫抓取量大到影响服务器性能、或者你的内容是付费/独家不希望被白嫖去训练,那可以通过robots.txt或服务器规则限制。关键是别凭感觉拦——先从日志看清楚每个AI爬虫的真实抓取量和行为,再决定放还是拦。盲目拦掉所有AI爬虫,在AI搜索越来越重要的今天,可能等于主动放弃了一块新流量入口。
这里同样有真假问题:AI爬虫的UA一样能被伪造,有些采集器会假冒GPTBot来薅内容。所以从日志看AI爬虫时,重要决策前最好也做一次来源验证,别被假冒的UA带偏了判断。
日志分析怎么和链接、锚文本审计串成闭环?
日志分析是链接审计这条流水线的最后一环,也是最容易被跳过、却最能验证前面工作的一环。
前面两个工具解决的是“理论”。内链外链分析器帮你把链接结构理顺——内链够不够、有没有死链、相对绝对写法对不对。锚文本分析器帮你把锚文本画像调自然,避开Penguin。但这两件事做完,都还停留在“你认为页面结构应该被这样抓取”的层面。
日志分析器解决的是“现实”:Googlebot实际上怎么抓的?你以为内链都通了,但日志里那些重要页面真的被高频抓取了吗?你修了死链,Googlebot真的不再撞404了吗?日志是唯一能验证前两步有没有落地的镜子。理论和现实对上了,链接审计才算闭环。
📊 链接审计三件套,到这里闭环:
服务器日志分析工具 — 本文主角,解析爬虫日志、状态码分布、抓取预算浪费分析。
内链外链分析器 — 流水线第一步,理清单页链接结构与rel属性。
锚文本分析器 — 流水线第二步,查锚文本分布自然度与Penguin风险。
三个工具连起来就是“结构 → 画像 → 抓取”的完整链条:链接分析器看结构对不对,锚文本分析器看画像自不自然,日志分析器看爬虫到底认不认。保哥做技术审计时基本是这个顺序,前两步定方向,最后一步用真实数据验收。关于抓取预算和缓存、性能怎么互相牵动,也可以参考保哥写过的 TTFB与多层缓存如何同时影响抓取那篇。
用日志数据做SEO决策时容易误判什么?
日志数据很硬,但解读不当一样会带偏决策。保哥总结几个高频误判。
第一个误判:把UA显示的Googlebot当成真Googlebot。前面强调过,UA能伪造。如果你看到“Googlebot”请求量异常高就以为Google很重视你,可能是空欢喜——得先做反向DNS验证。保哥写过的 AI Agent抓取日志解码那篇里就拆过多种UA的真假辨别,可以配合着看。
第二个误判:用一天的日志下结论。Googlebot的抓取有波动,单日数据可能正好赶上它的高峰或低谷。看抓取频率趋势至少要一周,看结构性问题(比如热门URL分布)则一周到一个月更可靠。拿一天的数据说“抓取量下降了”,很可能只是正常波动。
第三个误判:只看爬虫,忽略真实用户的对照。日志里既有爬虫也有真人。有时候一个页面爬虫抓得勤但真人几乎不来,说明这页可能对用户没价值,抓取预算花在它身上其实也是种浪费。把爬虫行为和真实流量对照着看,判断会更准。
第四个误判:忽略响应时间这个隐藏变量。很多人只看状态码和URL,忽略了响应耗时。如果Googlebot抓取你的页面普遍很慢,它会主动降低抓取频率以免拖垮你的服务器——这是Google明说的机制。所以服务器响应慢,本身就会缩减你的抓取预算。看日志时如果格式里带了耗时字段,别放过它。
多大规模的站需要定期做日志分析?
不是每个站都得天天盯日志。保哥按规模和场景给个分级建议。
小站(几百页以内):基本不用专门做。这类站抓取预算绰绰有余,Googlebot想抓随时能抓完。除非出现收录异常,否则不必定期分析日志。真要排查问题时,临时导一次日志看看就够了。
中型站(几千到上万页):每季度抽检一次。到了这个量级,开始有“预算够不够分”的隐忧。建议每季度导一次日志,重点看4xx比例和热门URL分布,确认核心页有被正常抓取、没有大批垃圾URL占预算。改版或大规模上新后额外加测一次。
大站(上万页以上):每月一次,列入常规监控。这是抓取预算管理的主战场。海量SKU、海量内容、各种参数URL,浪费几乎是必然存在的,区别只是多少。建议每月分析一次日志,把它和Search Console的抓取统计交叉验证,持续优化robots屏蔽规则和内链引导,把预算尽量集中到能带来收益的页面上。
保哥的总结是:日志分析的必要性和站点规模、URL复杂度正相关。站越大、自动生成的URL越多,抓取预算的浪费就越隐蔽、越值钱去治。而无论站大站小,当你遇到“页面发现了却不被索引”“新内容收录极慢”这类靠GSC查不出原因的怪事时,第一反应都应该是——导一份日志出来看看。它是技术SEO工具箱里那把能照见真相的手电筒。
常见问题解答
服务器日志分析和Search Console的抓取统计有什么区别?
Search Console的抓取统计是Google提供的聚合、抽样后的报告,告诉你总抓取次数、平均响应时间等概览,有延迟。服务器日志是你自己服务器记录的一手流水账,精确到每一次请求,能看到具体抓了哪个URL、返回什么状态码、是哪个爬虫。GSC适合看趋势和拿Google官方判断,日志适合做精确诊断。两者交叉验证最可靠,遇到GSC查不出原因的收录问题,日志往往有答案。
抓取预算是不是所有网站都要操心?
不是。Google明确说抓取预算主要是大型站点(通常上万URL以上)才需要管理。几百个页面的小站,Googlebot的预算绰绰有余,每页都能被勤快抓取,完全不用操心。真正需要管理预算的是SKU海量的电商站、内容海量的资讯站、以及会自动生成大量参数URL的站。这些站URL数量超过Googlebot愿意分配的预算,才会出现重要页面抢不到抓取机会的问题。
怎么确认日志里的Googlebot是真的?
User-Agent可以伪造,所以不能只看UA。Google官方推荐的方法是“正向确认的反向DNS”:先对该IP做反向DNS查询,确认域名是googlebot.com、google.com或googleusercontent.com;再对这个域名做正向DNS查询,确认解析回的IP和原IP一致。两步都通过才是真Googlebot。也可以用Google公布的IP段列表批量比对。这一步在服务器端用命令行完成,工具本身只按UA识别。
日志文件太大,浏览器打不开怎么办?
先在命令行过滤。最常用的是只保留爬虫的行:grep -i "bot\|spider\|crawler" access.log > bots.log,文件会小很多。也可以按日期或状态码进一步过滤。浏览器端处理50MB以内的日志比较稳,超大日志建议先拆分或过滤。所有解析在浏览器本地完成,日志数据不会上传到任何外部服务器,敏感数据可以放心。
为什么有些日志行没有被解析?
因为它们不符合Apache/Nginx标准的Combined或Common格式。常见原因:服务器用了自定义日志格式(字段顺序或内容不同)、上传的是错误日志error.log而非访问日志access.log、日志里混入了多行请求体、或者是JSON等非标准文本格式。工具会显示解析成功率,成功率很低时要回去确认格式。CDN日志格式可能不同,必要时先转成标准格式再分析。
发现大量抓取浪费后,最优先该做什么?
按影响面排序。最优先是用robots.txt屏蔽那些占用预算最多的低价值URL,通常是筛选、排序、会话参数页——它们本就不该进索引,屏蔽后立刻释放预算。其次是修复4xx死链,把它们做成301跳到合理目标,让Googlebot不再白跑。再次是消除多跳重定向链。最后给重要页面提交高频更新的sitemap引导优先抓取。先堵浪费,再引导,效果最快。
权威参考资料
本文标题:《服务器日志分析工具教程:读懂Googlebot抓取与预算浪费》
本文链接:https://zhangwenbao.com/log-analyzer-crawl-budget-googlebot-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0