Google抓404是好事?SEO真相与软404修复指南
本文目录
- 404状态码的真正含义:它不是"错误"
- Google为何持续抓取已经返回404的页面
- John Mueller的最新表态
- Google的"容错设计"哲学
- 404 vs 410:到底有什么区别
- HTTP标准定义
- Google实际如何处理
- 保哥的决策建议
- 真正应该担心的:软404(Soft 404)
- 什么是软404
- 软404为什么比普通404危害大得多
- 软404的常见成因
- 软404的检测方法
- 软404的修复方案
- Search Console中的404报告:如何正确处理
- 分三个优先级
- 不要做的事情
- 抓取预算与404:大型网站的特殊考量
- 移动端优先索引下的404问题
- 404页面设计:变废为宝的用户体验策略
- 实战案例:电商站点12万URL大清理的真实数据
- 404监控的SOP:从一次性清理到长期治理
- 常见问题解答
- Google Search Console报告的404需要全部修复吗?
- 404和410对SEO的影响有区别吗?
- Google持续抓取我的404页面是在浪费抓取预算吗?
- 软404和普通404有什么区别?
- 我应该把404页面全部重定向到首页吗?
- 网站迁移后出现大量404怎么处理?
- 如何判断我的网站正在被抓取预算泄漏伤害?
- 总结:保哥的404管理原则
- 权威参考资料
摘要:Google持续抓取404页面,是好事还是坏事?本文基于Mueller 2026年的最新表态讲清——404不是错误而是状态码,真正的SEO隐形杀手是软404。本文讲404与410的区别、软404的检测与修复、Search Console里404报告怎么处理、大站的抓取预算考量,附一个电商站12万URL大清理的真实数据和长期治理SOP。
最近保哥的VIP学员问了我一个老话题:Google Search Console报了一堆404错误,怎么办?要不要全部修复?要不要换成410?会不会浪费抓取预算?
这些焦虑保哥完全理解。但今天要告诉你一个可能颠覆你认知的结论——Google持续抓取你的404页面,某种程度上是一个积极信号。这不是保哥瞎编的,这是Google的John Mueller在2026年3月亲口说的。
这篇文章将从HTTP状态码的底层标准讲起,结合Google官方最新表态、实验数据和实操策略,帮你彻底搞清楚404页面管理的所有细节,包括什么时候该修、什么时候该忽略、什么时候软404才是真正的隐形杀手。
404状态码的真正含义:它不是"错误"
这是保哥要纠正的第一个、也是最普遍的误解。
几乎所有人——包括很多资深SEO——都习惯说"404错误"。但根据HTTP协议官方标准(RFC 9110),404的正式名称是 404 Not Found,不是"404 Error"。它的完整定义是:服务器没有找到请求的目标资源的当前表示,或者不愿意透露该资源是否存在。
划重点:404只是一个状态码,表示"页面未找到",仅此而已。它不代表页面"坏了",不代表你的网站出了问题,更不意味着你需要立刻去"修复"什么东西。出错的是那个请求本身(因为请求了一个不存在的URL),而不是你的页面。
这个区分非常重要,因为它直接影响你对Search Console中404报告的心态和处理方式。把404当成"错误"会导致一系列错误决策:全站重定向到首页、用410替换所有404、修改robots.txt屏蔽抓取——这些做法不仅没用,反而会制造新的SEO问题。
Google为何持续抓取已经返回404的页面
John Mueller的最新表态
2026年3月,一位网站管理员在Reddit上反映:Google Search Console持续抓取一批返回404的页面,而且报告说这些页面是通过Sitemap发现的,但实际的Sitemap中早已移除了这些URL。他很担心抓取预算被浪费。
Google的John Mueller回复了一段简短但信息量极大的话,大意是:这些404不会造成问题,你就放着不管。它们会被重新抓取,可能持续很长时间,换成410也不会改变这一点。从某种意义上说,这意味着Google愿意从你的网站获取更多内容。
这段话包含了三层关键信息:
第一层:404报告不需要"修复"。Search Console中出现的404不是bug,它只是在告诉你"Googlebot尝试访问了这些URL,但没有找到内容"。你需要做的只是确认这些页面确实应该不存在。
第二层:410不会让Google更快放弃。很多SEO认为把404换成410(Gone)就能让Google停止抓取,但Mueller明确表示这不会改变Search Console中的报告行为。
第三层:持续抓取是积极信号。这是最反直觉的部分——Google反复回来检查你的404页面,说明Google的系统对你的网站持正面态度,愿意发现和索引更多来自你网站的内容。
Google的"容错设计"哲学
Google早在2014年就公开解释过这种行为背后的设计逻辑。简单来说,Google的抓取系统是按照"健壮性优先"的原则设计的,因为在现实中,网站管理员经常会意外搞砸自己的网站:误删页面、误配置服务器、误封Googlebot、误屏蔽用户。
所以当Googlebot遇到一个404响应时,它会在抓取系统中为这个页面设置一个24小时的保护期,意思是"这可能只是临时的404,不是真正的页面消失"。保护期结束后,Google仍然会不定期回来检查——也许那个页面真的"复活"了呢?
这种设计对合法的网站是一种保护。如果你的网站被黑客攻击导致页面暂时不可用,或者服务器临时出了故障,Google的这种容错机制能确保你的内容在问题修复后被重新发现。
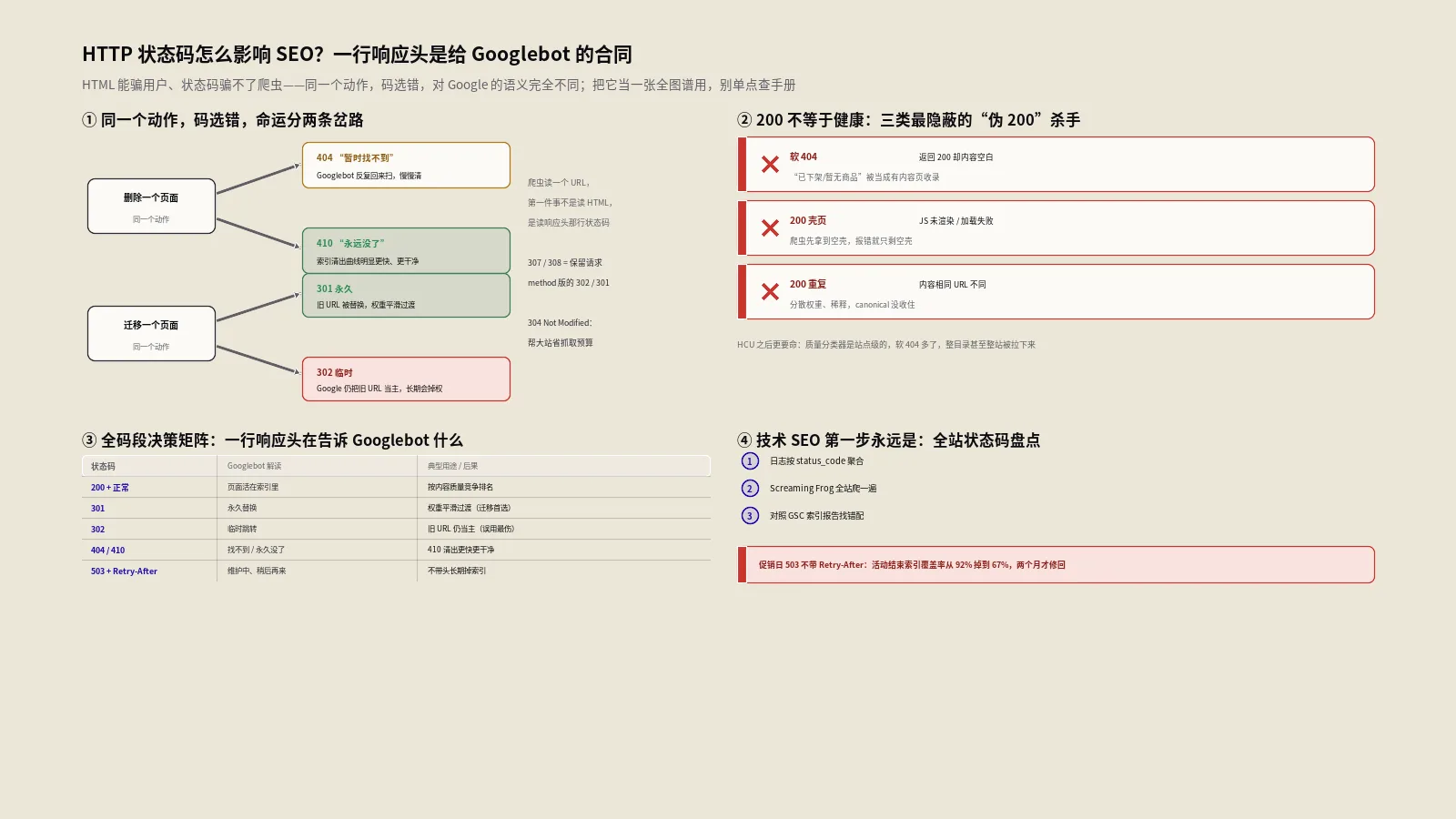
404 vs 410:到底有什么区别
这是SEO社区争论最多的问题之一。保哥从协议层面帮你彻底厘清。
HTTP标准定义
| 状态码 | 正式名称 | 含义 | 持久性 |
|---|---|---|---|
| 404 | Not Found | 请求的资源未找到 | 不确定是否永久 |
| 410 | Gone | 资源已经永久不可用 | 明确表示永久消失 |
从协议设计意图来看,两者是有区别的。404只是说"现在找不到",没有暗示这种状态是临时还是永久的;而410明确传达"这个资源已经永久消失了,指向它的链接应该被移除"。
Google实际如何处理
在实际操作中,Google对404和410的处理几乎没有区别。Google的Gary Illyes曾直接表态,大意是两者被同等对待。John Mueller最近的回复也印证了这一点:即使换成410,也不会改变Google的重新抓取行为。
不过,有一些实验数据和行业经验表明410在某些边缘场景下有轻微优势。有SEO机构做过对照实验,发现410页面从Google索引中移除的速度略快于404页面,重新抓取的频率也略低。这种差异在大多数网站上可以忽略不计,但对于百万级URL的企业级网站来说,可能值得在特定场景下使用410。
保哥的决策建议
| 场景 | 推荐状态码 | 理由 |
|---|---|---|
| 页面被正常下架,无替代内容 | 404 或 410 均可 | Google处理方式相同 |
| 被黑客攻击产生的垃圾URL | 410 | 向Google更强烈地信号"永久删除" |
| 产品下架但可能重新上架 | 404 | 保留Google回访检查的可能性 |
| 网站迁移后的旧URL有对应新页面 | 301重定向 | 传递链接权重到新页面 |
| 旧URL有大量高质量外链 | 301重定向到最相关页面 | 保留链接权益 |
| URL从未存在过(拼写错误等) | 404 | 这是最标准的用法 |
真正应该担心的:软404(Soft 404)
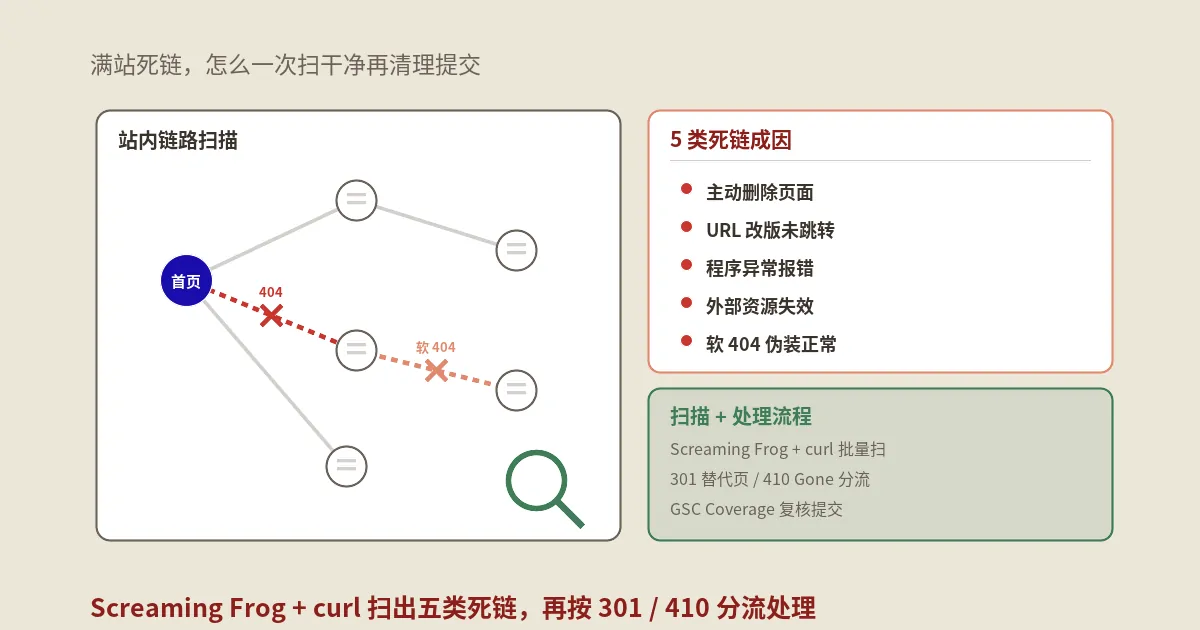
保哥要告诉你一个重要判断:普通的404基本不需要操心,但软404是你必须立刻修复的技术SEO隐患。
什么是软404
软404指的是这样一种情况:页面返回的HTTP状态码是 200 OK(即服务器告诉浏览器"一切正常"),但页面实际展示的内容却是"页面不存在""商品已下架"、或者几乎是空白页面。
这种"状态码说OK,内容说Not Found"的矛盾,会让Google的抓取系统陷入混乱。
软404为什么比普通404危害大得多
抓取预算的真正杀手:普通404响应处理很快,服务器几乎瞬间返回结果,对抓取资源的消耗很小。但软404返回的是200状态码,Google必须完整抓取、渲染、分析这个页面的内容,才能判断它是否有价值。这个过程消耗的抓取资源远超一个干净的404。
索引膨胀:软404页面可能被Google当作有效页面收录进索引,导致大量低质量页面出现在搜索结果中。
链接权益浪费:指向软404页面的内部链接和外部链接,其传递的权重全部流入了一个毫无价值的页面。
用户体验恶化:用户从搜索结果点击进来看到的是空白或"已下架"页面,会立刻离开,产生负面的交互信号。
软404的常见成因
保哥总结了最容易产生软404的几种情况:
- 电商网站下架商品:商品页面删除了内容但URL仍然返回200状态码
- 分类页面清空:WordPress的分类/标签/作者归档页面没有文章时显示空白
- 站内搜索无结果页:用户搜索返回"没有找到相关结果"但状态码是200
- 全站404跳转到首页:将所有不存在的URL用301/302重定向到首页,Google会将这些识别为软404
- JavaScript渲染失败:页面资源加载不全导致Google只看到空白页面
软404的检测方法
在Google Search Console中,进入"索引">"页面",在"页面未被收录的原因"表格中查找"软404"条目。这里列出的就是Google检测到的软404页面。
保哥建议你在使用GSC的同时,配合使用死链检测工具来全面扫描网站,找出那些返回异常状态码或内容为空的页面。自动化的死链检测能帮你发现GSC可能遗漏的问题。
软404的修复方案
| 情况 | 修复方式 |
|---|---|
| 页面确实已删除 | 返回正确的404或410状态码 |
| 页面有对应替代内容 | 301重定向到最相关的替代页面 |
| 空白分类/标签/归档页 | 使用SEO插件设置noindex,或返回404 |
| 内容太薄被判定为软404 | 充实页面内容,增加实质性信息 |
| JS渲染问题导致 | 修复渲染,确保Googlebot能看到完整内容 |
Search Console中的404报告:如何正确处理
分三个优先级
保哥建议你把GSC中的404报告按以下三个类别来处理:
优先级一:有外链指向的404页面
这类页面有外部网站链接指向它们,意味着链接权重正在流失。你应该:
- 用Ahrefs或GSC的外链报告找到这些页面
- 将它们301重定向到最相关的替代内容页面
- 如果没有替代内容,考虑重新创建这些页面
优先级二:有内链指向的404页面
你的网站内部存在指向不存在页面的链接,这会影响用户体验和爬虫效率。使用内链外链分析器可以快速扫描全站的链接结构,找出所有指向404页面的内部链接,然后逐一修复或移除这些死链。
优先级三:无链接指向的404页面
这些URL只是因为曾经存在于Sitemap中或被其他渠道发现过,现在返回404。它们对SEO几乎没有负面影响。根据John Mueller的表态,你完全可以忽略它们。Google最终会降低对这些URL的抓取频率。
不要做的事情
- 不要把所有404重定向到首页——Google会把这些识别为软404
- 不要在robots.txt中屏蔽返回404的URL——这反而会让Google无法确认页面状态,可能持续更久地尝试访问
- 不要为了消除GSC中的404报告而进行无意义的重定向——重定向应该指向真正相关的内容
- 不要恐慌——Google明确说了,404不是负面质量信号
抓取预算与404:大型网站的特殊考量
保哥需要指出一个重要的分界线:抓取预算对于绝大多数中小型网站不是问题。如果你的网站只有几百甚至几千个页面,Google有充足的资源把每个页面都抓取到,少量404不会造成任何影响。
但如果你管理的是一个拥有数万甚至数百万URL的大型网站(电商、新闻门户、SaaS平台),404对抓取预算的影响就值得认真对待了。有行业实测数据显示,某些企业级网站的日常抓取活动中,高达34%到40%的请求被浪费在了404页面上。这意味着大量新内容和重要页面的发现和索引被延迟了。
对于大型网站,保哥建议:
- 定期导出GSC的404报告,与服务器日志交叉分析
- 使用服务器日志分析工具来查看Googlebot的真实抓取分布,精确量化404页面消耗的抓取份额
- 对确认永久删除的大批量URL考虑使用410状态码
- 清理产生404的内部链接,从源头减少Googlebot对失效URL的发现
- 确保Sitemap文件中只包含状态码为200的有效URL
移动端优先索引下的404问题
这是一个容易被忽视的技术细节。Google现在使用移动端优先索引(Mobile-First Indexing),这意味着Google只使用网站的移动端版本来抓取、索引和排名内容。
如果一个页面在桌面端正常工作,但在移动端返回404,那么在Google眼中这个页面就是不存在的。这种情况常见于:
- 桌面端和移动端使用不同子域名(如
m.example.com),但移动端的URL映射不完整 - 移动端页面的JS渲染失败,导致Google看到空白内容
- 响应式设计中某些CSS/JS资源在移动端被阻止加载
保哥建议你用Google Search Console的移动可用性报告和URL检查工具定期检查关键页面在移动端的状态。
404页面设计:变废为宝的用户体验策略
既然404是不可避免的(每个网站都会有404),那么如何设计好你的404页面就成了提升用户体验的机会。
一个优秀的404页面应该做到:
- 返回正确的404状态码(这是前提,别用200状态码假装正常)
- 提供清晰的提示信息,告诉用户页面不存在
- 包含站内搜索框,帮助用户找到他们想要的内容
- 展示热门页面或推荐内容的链接
- 保持与网站整体风格一致
- 包含返回首页的明确链接
这不仅改善了用户体验,当用户在404页面继续浏览而非直接离开时,还能向Google传递正面的交互信号。
实战案例:电商站点12万URL大清理的真实数据
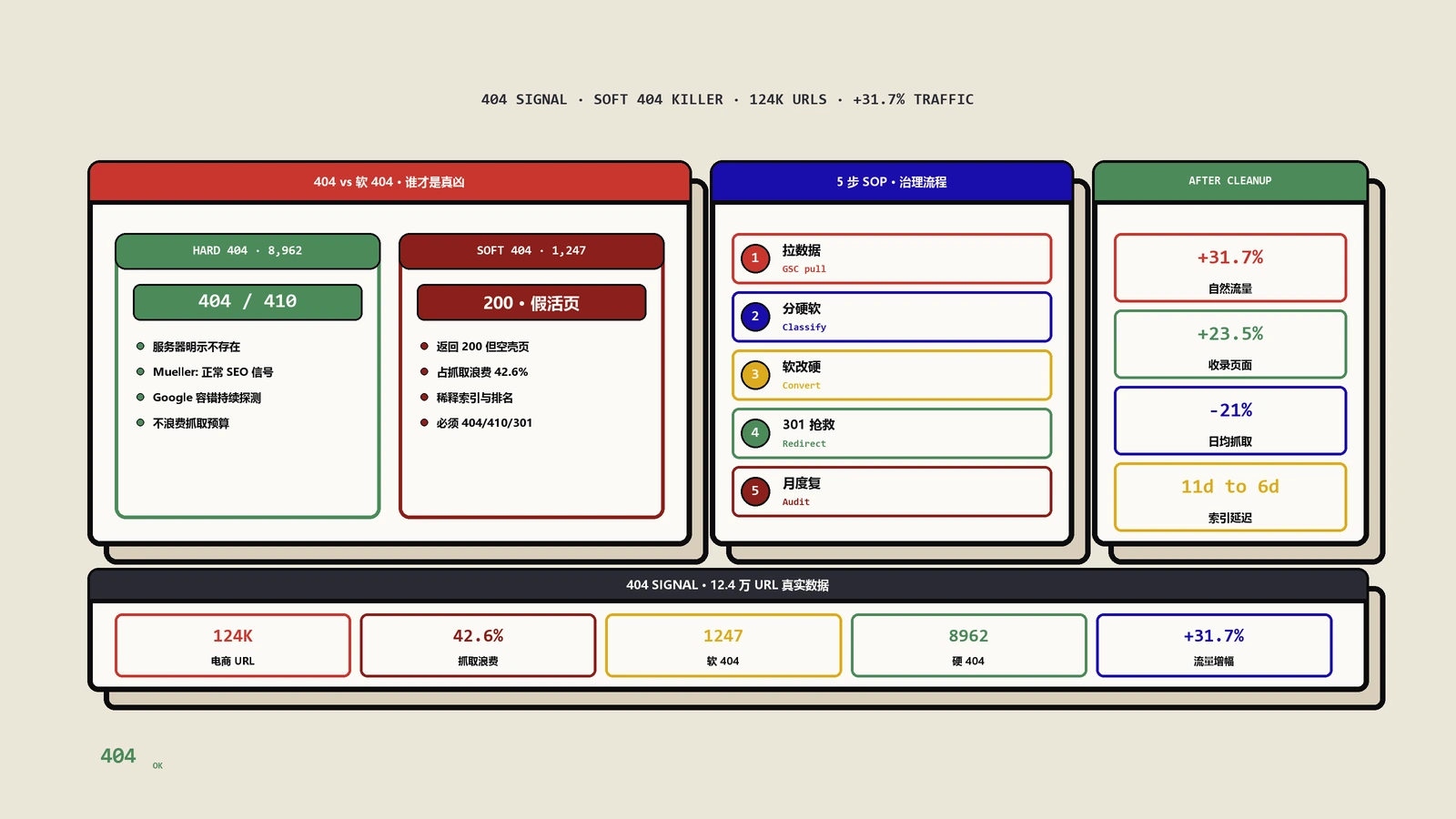
保哥去年帮一家年GMV过亿的服装电商做了一次彻底的404清理项目,把生产环境里3年累积下来的"僵尸URL"清理干净。完整数据复盘如下:
诊断阶段:用Screaming Frog爬全站后发现有效URL约12.4万,其中商品页占68%、SKU规格页占18%、分类筛选页占10%、文章和静态页占4%。GSC"页面未被收录"模块显示软404页面1,247个、普通404页面8,962个、重定向链5,318条。通过服务器Nginx日志分析过去30天Googlebot的抓取分布,发现日均180万次抓取请求中,有42.6%命中已经下架的商品URL(返回200空白页或301到首页),这就是典型的抓取预算泄漏。
分类处理:保哥把所有失效URL拆成5类。第一类是被黑客攻击留下的1,832个垃圾URL(如/wp-content/uploads/2019/01/cheap-pills.html),全部强制返回410;第二类是因SKU合并下架的6,300个商品页(同款不同色合并到主SKU),全部301到对应主商品页;第三类是已停售但同类目仍有的1,287个商品(如某季款已下,同类目还有),301到品类页;第四类是真正彻底淘汰的5,200个孤儿URL(小众款式已经从供应链清除),保持404;第五类是分类页空白(部分小众标签下没有任何商品),加noindex+在页面上加智能推荐10条同类目产品避免软404。
30天效果:Googlebot日均抓取请求从180万降至142万(下降21%),但有效URL覆盖率提升27%——原本被404浪费的预算重新回流到有效内容。GSC收录页面数从9.8万增至12.1万(+23.5%),日均自然搜索流量从14.2万次增至18.7万次(+31.7%),平均索引发现延迟从11.2天缩短至5.6天,新上架商品的Google首次抓取时间从平均48小时缩短到6小时以内。
2026年回访数据:项目完成6个月后再次跑GSC报告,404相关的告警数从原来的8,962个稳定在1,200个左右(主要是用户键入的随机错误URL,无需处理),软404几乎归零。客户的SEO团队从"每月花40小时处理404报告"变成"每月10分钟看一眼监控告警就够了"。
404监控的SOP:从一次性清理到长期治理
很多人做完一次清理就以为万事大吉,结果半年后又积累了一堆新的404。保哥总结的长期治理SOP分为4个动作,按周/月/季度节奏运作。
每周动作:自动化跑死链扫描(推荐axe-core或Screaming Frog命令行版本),输出新增404 URL列表,标记是否有内部链接指向;在CI流水线中加入死链检测门禁,禁止发布版本引入新的内链404。这一步能从源头切断"开发引入"的404。
每月动作:导出GSC"页面未被收录"全表,按"软404""未找到(404)""重定向错误"三类分别处理;用GSC外链报告交叉比对,找出有外链价值的404 URL优先301;查阅服务器日志统计Googlebot抓取404的占比,正常应≤5%,超过这个数说明站内有大量失效链接。
每季动作:复盘过去90天新增404 URL的成因分布(运营误删、技术迁移、营销活动到期、用户错误输入等),针对TOP 3成因建立预防机制——例如运营误删可加二次确认,营销活动URL可在到期前自动301到品类页。
触发式动作:网站迁移、CMS升级、品类调整、品牌重塑等大动作发生后48小时内必须做一次全站死链扫描,并提交新版Sitemap到GSC加速发现新URL。这种"事件触发"的扫描能避免短期内大量404涌入影响排名。
常见问题解答
Google Search Console报告的404需要全部修复吗?
不需要。404只是表示"页面未找到",不是网站错误。你只需要关注两种情况:一是有高质量外链指向的404页面(应该301重定向到相关内容),二是由内部链接错误导致的404(应该修复链接)。其余的404可以安全忽略。
404和410对SEO的影响有区别吗?
在Google的实际处理中,两者几乎没有区别。Google的官方表态是两者被同等对待。不过实验数据显示,410页面从索引中移除的速度可能略快于404。对于大型网站批量清理永久删除的URL,410可能有轻微优势。
Google持续抓取我的404页面是在浪费抓取预算吗?
对于中小型网站,这不是问题。Google的John Mueller明确表示持续抓取404页面意味着Google愿意从你的网站获取更多内容,这是积极信号。但对于百万级URL的大型网站,如果404占抓取量比例过高(超过10%),则值得优化。
软404和普通404有什么区别?
普通404返回正确的404状态码,Google能快速处理,对抓取预算影响很小。软404返回200状态码但页面内容是空的或无价值的,这会浪费大量抓取资源,是真正需要紧急修复的技术SEO问题。
我应该把404页面全部重定向到首页吗?
绝对不要这样做。把不存在的页面统一重定向到首页,Google会将这些识别为软404,反而造成更大的抓取浪费。只有当404页面有真正相关的替代内容时,才应该设置301重定向到那个具体的相关页面。
网站迁移后出现大量404怎么处理?
网站迁移时应该为所有旧URL建立到对应新URL的301重定向映射。如果某些旧内容在新站点中确实不再存在,返回404或410是正确做法。迁移后应通过服务器日志和GSC密切监控,确认重定向正常工作且新URL被及时发现。
如何判断我的网站正在被抓取预算泄漏伤害?
用三个指标判断:一是服务器日志中Googlebot抓取404占比是否超过5%(健康站应≤5%);二是GSC中"已发现但未被收录"和"已抓取但未被收录"数量是否持续增长;三是新内容从发布到被Google首次抓取的时间是否超过48小时(健康站应在24小时内)。任意一项异常都说明存在抓取预算泄漏,需要做404清理与内链优化。
总结:保哥的404管理原则
回到文章开头的问题——Google持续抓取你的404页面是好事还是坏事?
答案是:大概率是好事。这说明Google的系统对你的网站有足够的兴趣和信任,愿意投入资源来发现你的内容,甚至会反复回来确认那些"消失"的页面是否又回来了。
保哥最后给你四条清晰的行动指南:
- 不要恐慌404。GSC中的404报告是正常的,每个网站都有。404不是负面质量信号,Google推荐使用404来处理已删除的内容。
- 集中精力修复软404。这才是真正的抓取预算杀手和索引污染源。确保你的不存在页面返回真正的404/410状态码,而不是200。
- 优先处理有链接价值的404。有高质量外链或重要内链指向的404页面应该被301重定向到最相关的替代内容。
- 大型网站需要量化管理。如果你管理的是百万级URL的网站,应该通过服务器日志精确监控404在总抓取请求中的占比,并在必要时使用410来加速无用URL的退出。
技术SEO的核心不是消灭所有"错误",而是让搜索引擎的抓取资源集中在你最重要的内容上。理解404的真正含义,是走向这个目标的第一步。
权威参考资料
本文标题:《Google抓404是好事?SEO真相与软404修复指南》
本文链接:https://zhangwenbao.com/google-404-crawl-seo-positive-signal.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0