AI内容写完谁来质检?人机分工与事实核查清单

本文目录
- 为什么发布前人工通读那一关一定会失效?
- 注意力会随篇数线性衰减
- 责任分散到没有人真正负责
- 没有成文标准,质量就会随心情漂移
- 那个崩掉的美妆客户,到底是哪一层没守住?
- AI该查什么,人该查什么,分工线划在哪里?
- 机械检查不是“扔给AI就行”,每项都有阈值
- 验收标准怎么量化,及格线卡在哪里?
- 一张可落地的加权评分卡
- 评分卡本身也要校准,否则等于没有
- 事实核查这一关,到底该怎么查才查得动?
- 统计数字的硬性核查协议
- 怎么快速识别AI幻觉的指纹
- 核查不必全量人肉,但要分对层
- 品牌声音和语气一致性怎么测,而不是凭感觉?
- 用禁用词表和风格指纹把语气量化
- 朗读检查:屏幕上看不出的别扭,读出来全暴露
- 内容到底有没有回答搜索意图,怎么判?
- E-E-A-T这种软信号,质检环节怎么落地?
- 新流程为什么必须先小范围试点再放量?
- 五到十篇试点要采集什么数据
- 放量之后清单不是冻结的
- 这条流水线常见的失败模式有哪些?
- 怎么把质检流程工程化,而不是靠某个人记着?
- 三个最小工程化动作
- 自动化闸别一次上全套,否则它自己会变成债
- 质检守住的那几项,怎么顺手提升被AI引用?
- 一份能直接抄走的分层质检清单
- 机器层(脚本/AI自动跑,人不介入)
- 事实层(人,一票否决)
- 语义层(人)
- 品牌与合规层(人)
- E-E-A-T与可引用层(人)
- 常见问题解答
- AI生成的内容到底能不能直接发布?
- 能不能让AI自己检查AI写的内容?
- 质检清单要做到多细才算够用?
- 小团队没人力做这么重的质检怎么办?
- 为什么新流程一定要先试点几篇再全量?
- 质检做好了对被AI搜索引用有帮助吗?
- 权威参考资料
摘要:AI内容翻车,几乎都不是因为模型太差,而是因为没有一道质检流水线把关。靠人在发布前通读那一遍,规模一上来必然失效——注意力会衰减,责任会分散,标准会漂移。真正能扛住规模的做法只有一种:把机械检查交给AI(拼写、格式、查重、链接体检),把判断检查留给人(事实核查、语气、意图、E-E-A-T),中间用一张带分值的验收卡卡死及格线,先拿五到十篇试点把清单磨准再放量。下面把这条流水线的每一层、每个阈值、每个失败模式拆给你,并给一份能直接抄走的分层质检清单。
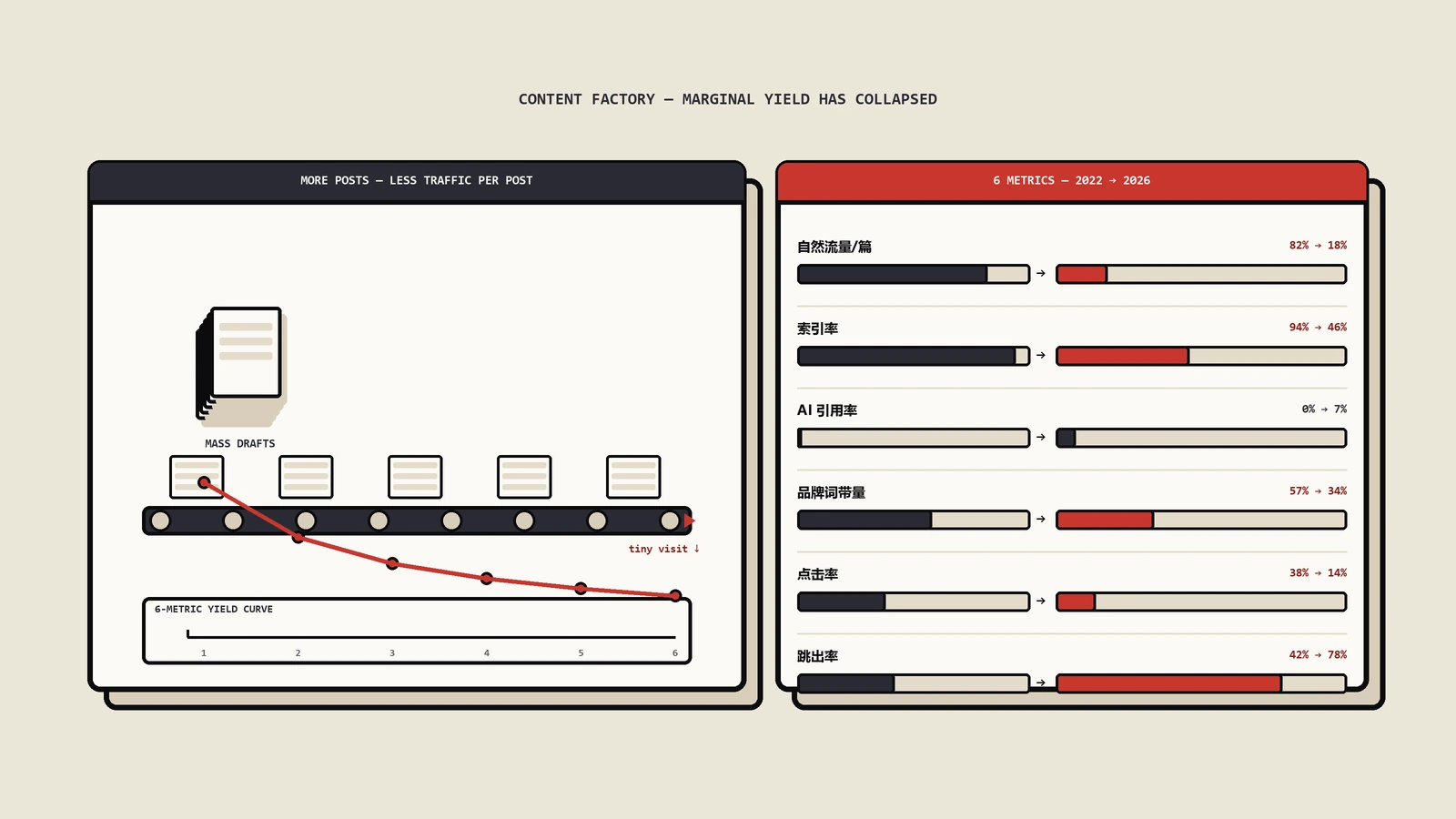
先说一个让人心里不舒服但必须承认的事实:现在大多数团队的AI内容质检,本质上就是发布前找个人从头到尾读一遍,觉得没硬伤就推上线。一篇两篇这么干没问题,一周三十篇、一个月两百篇还这么干,质量崩塌只是时间问题。保哥去年接过一个出海美妆DTC客户的内容诊断,他们用AI把博客产能从每月十几篇拉到一百多篇,三个月后自然流量不升反降——翻日志才发现,崩的不是模型,是那道唯一的人工通读关:审稿的人从一篇细看,到后面变成扫一眼标题和首段就过,AI把同一个错误的成分功效说法复制进了四十多篇文章,没有一道独立的事实核查环节拦得住。
这篇不讲“要重视质量”这种正确的废话,只讲一件事:一条能扛住规模的AI内容质检流水线到底长什么样,每一层谁来做、查什么、卡在哪条线就打回。它和站内已经写过的几篇是分工关系——AI批量生产内容为什么会撞上质量墙讲的是规模化失败的成因,本篇讲的是用什么样的验收纪律把那堵墙顶住;AI内容千篇一律怎么差异化讲的是怎么让产出本身不雷同,本篇讲的是产出之后怎么把不合格的拦在发布之前。两件事都做,规模化才立得住。
为什么发布前人工通读那一关一定会失效?
得先把这个问题讲透,否则后面所有流水线设计都站不住脚。很多人觉得“我们有审稿环节啊”,问题恰恰在于,单纯靠人通读这一道关,在规模面前有三个结构性漏洞,不是态度问题,是机制问题。
注意力会随篇数线性衰减
人审第一篇和审第三十篇,投入的认知资源完全不是一个量级。前几篇还会逐句核对数据、查链接、想这段逻辑通不通,到后面大脑会自动进入模式匹配——只要句子读着顺、结构看着像那么回事,就默认它对。AI生成的内容最阴险的地方就在这里:它天然“读着顺”,语法永远对,句式永远流畅,幻觉和事实错误被包裹在通顺的外壳里,恰好专门骗过这种衰减后的扫读。越通顺的错误内容,越能穿过疲劳的人工审稿,这不是审稿人不负责,是把判断密度极高的活儿压给一个会疲劳的大脑去做规模化作业,设计上就错了。
责任分散到没有人真正负责
“发布前会有人看”这句话的潜台词是没有人对具体哪一项负责。事实有没有核实?算谁的。语气像不像品牌?算谁的。意图答没答到点上?也算谁的。当一个人要同时对一篇文章的二十个维度负责,结果就是每个维度都只扫到三成。责任不拆解到具体的人和具体的检查项,规模一大就会塌成“大家都看了,但谁都没真查”。这也是为什么很多团队事故复盘时会发现一个荒诞的事实:出问题的那篇,流程上明明“审过”,但没有任何一个人能说清自己当时到底负责确认了哪一项。
没有成文标准,质量就会随心情漂移
没有写下来的验收标准,每个审稿人脑子里的及格线都不一样,同一个人周一和周五的及格线也不一样。今天觉得这个开头还行,下周同样的开头觉得不行。读者和搜索引擎感受到的就是忽好忽坏、没有稳定预期的内容质量。规模化的敌人从来不是质量低,是质量不稳定且没人知道为什么——而不稳定的根因,几乎总是标准只在人脑里、没落到纸上。验证这一点有个很简单的实验:把同一篇内容发给三个审稿人各自打分,分差越大,说明你的标准越是不存在。
那个崩掉的美妆客户,到底是哪一层没守住?
把开头那个案例拆开复盘,比讲十条原则都有用,因为它几乎踩齐了上面三个漏洞。还原一下时间线:第一个月产能拉到一百多篇,审稿人还能逐篇看,没出事;第二个月人开始扛不住,审稿退化成扫标题和首段;第三个月,一个被AI反复生成的错误成分功效表述——把一种常见保湿成分的作用说成了具备某种它并不具备的功效——被复制进了四十多篇产品相关文章,没有任何一环拦住它。
关键不在于AI犯了这个错,而在于这个错本来有四道独立的关可以拦下来,结果一道都没设。机器层本可以用一张成分禁用/敏感词表把这个功效说法直接标红;事实层本可以要求每个功效断言点到一个可信来源,这个说法根本查无实据;品牌与合规层本可以把它当高风险表述一票否决,因为这类表述还涉及广告法风险;试点阶段本可以在前十篇里就发现“AI在成分功效上稳定地编”,从而把这一类单列成一条硬规则。四道关,对应的就是后面要讲的四层。这个客户的真正损失不是那四十多篇文章,是它证明了一件事:没有分层独立的关,单一通读关的失效会被产能放大成系统性事故,而且要到流量掉了才被发现。
AI该查什么,人该查什么,分工线划在哪里?
整条流水线的设计核心就一句话:让AI干机械的、可穷举规则的、不需要上下文判断的检查;让人干需要语境、需要常识、需要专业判断的检查。把这两类活儿混在一起交给同一道关,要么慢到没法规模化,要么漏到没意义。下面这张表是保哥实际在客户项目里用的分工基线,直接抄。
| 检查项 | 谁来做 | 为什么这么分 |
|---|---|---|
| 拼写、标点、格式一致性 | AI / 脚本 | 纯规则可穷举,人来做又慢又会漏 |
| 查重 / 抄袭比对 | AI / 工具 | 需要全网比对,人力不可能覆盖 |
| 死链、内链目标存在性、图片alt缺失 | 脚本 | 可自动化的硬性体检,零判断成分 |
| 关键词堆砌、可读性分数初筛 | AI | 统计型信号,AI给初判人复核 |
| 事实是否成立、统计是否真实 | 人 | 要回溯一手来源,AI自己就是幻觉来源 |
| 语气是否像品牌 | 人 | 需要对品牌调性的隐性判断 |
| 是否真回答了搜索意图 | 人 | 要理解用户真实诉求,不是关键词覆盖 |
| 有没有真实经验 / 专家视角 | 人 | E-E-A-T信号只能由懂行的人注入和确认 |
这张表里有一条最容易被搞反:千万不要用AI去核查AI生成内容里的事实。让一个会编造统计数字的模型去判断另一段是不是编的,它会很自信地告诉你“数据准确,来源可靠”,而那个来源根本不存在。事实核查必须是人回溯到一手出处,这是整条流水线里唯一绝对不能自动化的环节。
机械检查不是“扔给AI就行”,每项都有阈值
把检查交给机器不等于不用动脑,每一项自动化检查都要先把阈值和边界定清楚,否则它要么放水要么误杀。查重就是典型:阈值定太松,洗了一遍的抄袭照样过;定太死,正常引用一手数据和行业通用定义会被当成重复打回,审稿人被一堆假阳性淹没后干脆不看这一项了。正确做法是把“引用块、标准定义、代码片段”从查重计算里排除,再对正文主体设一个相对严格的相似度上限。死链体检也有个常被忽略的边界:很多链接是JS渲染后才生成的,只扫静态HTML会漏,要扫渲染后的DOM。可读性和关键词堆砌这类统计初筛,AI只该给“疑似”标记交人复核,绝不能让它直接判定通过——它对“读着顺”的判断恰恰是最不可信的那一项。机械层的设计原则是:宁可让它多标记、人来否掉假阳性,也不能让它替人做最终判定。
验收标准怎么量化,及格线卡在哪里?
分工划清楚之后,第二个必须解决的问题是:什么算合格?没有量化标准,质检就退化成审稿人“觉得行不行”,回到了标准漂移的老路。保哥给客户搭质检流程时,一律先逼他们把及格线写成一张带分值的评分卡,而不是一句“质量要过关”。
一张可落地的加权评分卡
权重要按“出错代价”来分,不是平均分。代价最高的是事实错误——一个编造的数据足以毁掉整篇的可信度,所以分值最重。下面这套是用得最多的基线,团队可以按行业微调,但权重次序不要乱动:
| 维度 | 分值 | 判什么 | 低于线的处理 |
|---|---|---|---|
| 事实准确性 | 30 | 所有数据、断言能不能回溯到可信一手来源 | 任一硬数据查不到出处,直接打回,不计其他分 |
| 品牌声音 | 25 | 读起来像不像自家品牌在说话,有没有禁用词 | 命中禁用词或语气明显跑偏,打回重写 |
| 原创深度 | 20 | 有没有比同主题前几名多出来的独到信息 | 通篇是公开常识的复述,打回补独到视角 |
| 结构与可扫读 | 15 | 层级清晰、能被读者和AI快速抽取要点 | 结构混乱影响抽取,退回重组 |
| 合规与风险 | 10 | 有没有违反广告法、行业监管、平台政策的表述 | 命中高风险表述,一票否决 |
关键不在这张表的具体数字,在两条铁规则。第一,事实准确性和合规这两项是一票否决项,不参与加总——只要这两项不过,其余四项分再高也直接打回,因为这两类错误的代价是不可逆的,不能被“写得好”抵消。把它做成加总项在数学上就错了:一篇语气满分、结构满分但编了个假数据的文章,加权分可能很高,可它该被毙,加总制会放它过去。第二,及格线要写死成一个具体数字(比如非否决项加总不低于75),而不是“审稿人综合判断”,否则评分卡又变回了主观判断的遮羞布。
评分卡本身也要校准,否则等于没有
一张评分卡发下去不等于标准统一了。同一篇内容,让三到五个审稿人各自按卡打分,看分差。分差小,说明卡写清楚了;分差大,说明每个人对“事实准确”“原创深度”的理解还是各打各的,卡上的描述太空。校准动作要定期做:拿打分差异最大的那几篇拉出来,逐项对齐“为什么你给28他给18”,把分歧点写回评分卡变成更具体的判定描述。一个客户的内容主管最初把及格线设成“看着差不多就行”,等于没设;改成硬分数线、再做了两轮打分校准之后,团队对同一篇的打分才收敛到可接受范围,这时评分卡才真正开始起作用。没经过多人打分校准的评分卡,只是一张让人误以为有标准的纸。
事实核查这一关,到底该怎么查才查得动?
这是整条流水线里最重、也最容易走过场的一环。AI幻觉是可信度流失最快的通道,一篇文章里只要有一个“看起来很专业的假数据”被读者或同行抓出来,整个站点的信任都会被打折。但“认真核查”四个字落不了地,得给具体协议。
统计数字的硬性核查协议
对每一个出现在正文里的硬数据(百分比、金额、排名、研究结论),保哥要求客户团队走死规矩:每个数字必须能点到一个具体一手来源,这个来源原则上是近两年内发布的,并且关键结论要有至少两个相互独立的近期来源能对上。三个细节决定这条协议有没有用:
- 来源要的是原始出处,不是二手转述。“某媒体报道某研究显示”不算,要追到那份研究本身——AI最常见的幻觉就是把不存在的研究安到一个真实机构头上。
- 两个独立来源不能是同源的两次转载。互相引用对方的两篇文章,本质是一个来源,对不上孤证。
- 查不到出处的数字,删掉比留着安全。规模化场景下,“宁可少给一个数据点,也不让一个查无实据的数字进正文”要写成纪律,而不是看当时心情。
怎么快速识别AI幻觉的指纹
幻觉是有指纹的,识别它能让事实核查的效率高一截。最高频的几类:精确到小数点却给不出来源的统计(真实研究的数字AI往往记不全,编的反而特别工整);把通用结论安到一个具体但其实没说过这话的权威头上;引用一个域名格式合理但打开是404的链接;把不同年份、不同口径的数据混在一句话里制造出一个不存在的趋势。还有一个反直觉的指纹值得单独记:AI越是编造,往往说得越笃定——真实但记不清的数据它会含糊,编出来的反而斩钉截铁。看到“工整得反常的精确数字 + 含糊或过度笃定的来源指向”这个组合,默认它是编的,直到能反向查证为止。
核查不必全量人肉,但要分对层
有人一听“每个数字都要回溯一手来源”就觉得没法规模化。关键在于分层,而不是一刀切全量人肉。把内容按风险分级:涉及健康、医疗、金融、法律这类一旦出错代价极高的(也就是搜索引擎说的YMYL范畴),事实核查必须逐条全查,不抽样;一般信息类内容,硬数据全查、软性表述抽查;纯观点和方法论类,重点查里面引用的事实锚点。核查强度要和出错代价挂钩,而不是和文章数量挂钩——把人力按风险分配,才能在不放水的前提下扛住规模。这一关查的是“站不站得住”,和好内容为什么也排不上去里讲的可信度信号是同一件事的一体两面:能被验证的事实,本身就是排名和被引用的底层资产。
品牌声音和语气一致性怎么测,而不是凭感觉?
“听起来不像我们”是AI内容被退稿最常见的理由,也是最容易扯皮的一项——因为没人能说清“像我们”到底是什么。要让这一项可执行,得把它从感觉拆成可对照的东西。
用禁用词表和风格指纹把语气量化
给品牌声音落地的最有效办法不是写一篇“我们的调性指南”,是给两样具体的东西。一是一张禁用词/禁用句式表:哪些词永远不准出现(被用滥的营销词、把名词当动词用的腔调、行业黑话),这张表机器就能扫,是AI能帮忙的部分。二是风格指纹——别凭空写调性描述,去翻团队过往最被认可的十几二十篇内容,让人或AI从里面提取出共性特征(句子长短节奏、第一人称用不用、举例的密度、是否爱用反问),形成一张可对照的特征清单和三到五段标杆样本,审稿时拿待审内容和它对照着读。品牌声音不可能完全自动化,但可以把它从“凭感觉”降级成“扫禁用词 + 比对风格指纹”,这一步能消化掉这项检查八成的扯皮。语气漂移也有早期信号:当AI产出里开始大量出现那种谁都能写、放哪个品牌都成立的句子,就是声音在被稀释,比等读者说“你们最近文章没感觉了”要早得多。
朗读检查:屏幕上看不出的别扭,读出来全暴露
有一个成本极低、效果意外地好的方法,很多团队没坚持做:把待发布内容大声读出来。屏幕上扫读会自动脑补、跳过、顺过去的别扭句子、不自然的衔接、AI特有的那种“正确但没人这么说话”的腔调,一旦读出声就藏不住。这一步最好不止一个人做——不同的人对“读着别扭”的敏感点不一样,一个人顺过去的,另一个人会卡住。它查不出事实问题,但对语气和可读性是性价比最高的一关。
内容到底有没有回答搜索意图,怎么判?
这一项最容易被质检流程整个跳过,因为它不像错别字那样显眼,但它决定了内容发出去到底有没有用。AI特别擅长写出“关键词全都覆盖到了,但根本没解决用户真实问题”的内容——表面贴题,实际答非所问。
判断标准不是“关键词出现了没有”,是“一个带着这个查询来的真实用户,读完能不能直接拿去用、少踩坑、省时间或省钱”。具体到可操作的检查动作:把目标查询真的搜一遍,看前几名和AI概览到底在回答什么问题、用什么形式回答(是要步骤、要对比、要参数、还是要判断标准),再回头看这篇有没有正面接住那个真实诉求,还是只是在关键词周围绕圈。举两个AI最容易写偏的具体例子:用户搜“某工具怎么收费”,真实诉求是要一张能一眼看懂的价格档位对照,AI却很容易写成一篇“影响定价的几大因素”的泛泛分析,关键词全中、意图全错;用户搜“X和Y怎么选”,要的是一张分场景的决策对照,AI却写成两段分别夸X和Y的介绍,让用户读完更不知道该选哪个。这两种稿子发出去既留不住人,也进不了AI概览,因为它没给出那个查询真正要的那个形式。质检时这一项最快的判定动作,就是先一句话写下“用户要的是一张表、一组步骤、一个判断标准还是一个直接答案”,再回去看这篇给的到底是不是那个东西,形式对不上就退回重组,不要在文字润色上浪费时间。搜索引擎和AI抓取、理解、排序内容的底层逻辑决定了一件事:意图错配的内容,技术上做得再干净,也接不住对应那批用户的流量,因为它压根没在回答他们带来的那个问题。意图对齐查的不是文章写得好不好,是它有没有在回答正确的问题——问题错了,写得再漂亮也是废稿。
E-E-A-T这种软信号,质检环节怎么落地?
谷歌一再强调经验、专业、权威、可信,AI内容天然在这四项上薄弱,因为它没有亲历、没有专业身份、没有立场。质检环节不能只看“有没有硬伤”,还得主动确认这篇有没有注入只有真人能给的东西。
可执行的检查项是问三个具体问题:这篇里有没有至少一处真实的一手经验(具体到行业、规模、时间、踩过的具体坑,而不是“在很多情况下”)?有没有一处是行业里有经验的人才给得出的判断或反常识结论,而不是公开资料的复述?关键论断有没有给到具体、可验证的出处,而不是“业内普遍认为”?这三项里至少要命中两项,这篇才算注入了人味。注入E-E-A-T不只是为了搜索引擎,也是为了被AI引用——可被验证的经验和权威细节,正是强化权威信号提升AI引用率那篇拆过的核心抓手。能加进一段真实经历、一个专家判断、一处可查的权威细节,是证明“这篇有人深度参与过”最硬的证据,也是AI内容和纯机器产物之间最难被模仿的护城河。
新流程为什么必须先小范围试点再放量?
很多团队一拿到质检清单就想立刻全量铺开,这是规模化崩盘的另一个高频死法。质检清单第一版几乎不可能是对的——它一定有覆盖不到的盲区,也一定有AI在你这个行业里反复踩的特定坑,是清单里没写的。
五到十篇试点要采集什么数据
放量前先拿五到十篇真实的AI生成内容跑完整条流水线,目的不是“看看能不能用”,是专门采集三组数据:每篇被打回的原因归类(哪一层拦下的、拦的是什么类型的问题),AI在这个行业、这类选题上稳定犯的错误TOP3(出现频率最高的那几类,要在清单里给它们单列硬规则,开头那个美妆客户的成分功效问题就该在这一步被揪出来),以及整条流水线最耗时、卡成瓶颈的是哪一环。试点的产出不是几篇文章,是一份被现实数据修正过的清单v2。跳过试点直接全量,等于拿两百篇文章的代价去试错一张没验证过的清单——错误会在规模上被乘以两百倍,这正是那个美妆客户三个月才发现问题的根因。
放量之后清单不是冻结的
试点修正完不等于结束。AI模型在升级,平台政策在变,业务重点也在挪,去年管用的清单今年可能漏掉新的坑。把回看做成有触发条件的固定动作:每季度定期回看一次,外加两个即时触发——换了主力模型之后必须重测一轮(模型一换,它稳定犯的错类型会整体变),平台政策或行业监管有重大调整时立即更新合规层。一张三年没动过的质检清单,和没有清单的差别没有想象中那么大。
这条流水线常见的失败模式有哪些?
把前面所有环节倒过来看,质检流程最常见的四种死法,几乎每一种在客户项目里都撞见过现场。用“症状—根因—急救”的方式对照,比单纯罗列更好用:
| 失败模式 | 典型症状 | 急救动作 |
|---|---|---|
| 没有成文标准 | 质检全靠审稿人当场判断,同一篇不同人打分差很大 | 先做评分卡和硬及格线,再做多人打分校准 |
| 标准写了但太松 | 清单全是“内容要优质”这种没法证伪的句子 | 每条改写成“低于哪条具体的线就打回” |
| 全交给AI检 | 事实、语气、意图全漏,出事都在判断项上 | 判断密集环节强制改回人工,AI只做机械层 |
| 全靠人肉检 | 慢到没法规模化,审稿人疲劳后判断项也崩 | 机械检查前置自动化,把人力省给判断项 |
这四种失败模式有个共同点:要么把判断的活儿交给了机器,要么把机械的活儿压给了人,要么压根没定义什么算合格。流水线设计对了,这三件事各归各位,规模化才不是赌博。
怎么把质检流程工程化,而不是靠某个人记着?
最后一层,也是最容易被忽略的一层:质检流程本身得像工程一样被管理,不能依赖某个负责的人脑子里记着所有规矩。那个人请假、离职、或者那周特别忙,质检就空转了。
三个最小工程化动作
一,清单是一份所有人能看到、有版本号、改动有记录的文档,不是某人脑子里的隐性知识——清单每改一条都要记“为什么改、什么时候改的”,否则半年后没人知道某条诡异规则是干嘛的,也不敢删。二,每一项检查都有明确的单一责任人,不是“团队一起把关”这种没人负责的说法;用一张简单的责任矩阵把“谁执行、谁最终拍板、出问题找谁”写死。三,机械检查项尽量做成发布流程里自动跑的闸——具体可以自动化的有:死链与内链目标存在性、全网查重、禁用词与敏感表述扫描、字数与标题层级硬阈值、图片alt缺失、JSON结构与结构化数据合法性,这些不通过连人工环节都进不去。这一层不做,前面所有设计都会随着关键的人离开而蒸发——质检流程的稳定性,最终取决于它有多不依赖某个具体的人。
自动化闸别一次上全套,否则它自己会变成债
这里有个反直觉的坑,很多团队工程化时栽过:把所有机械检查一口气全做成强制闸同时上线。结果第一周被大量假阳性淹没——查重把正常的行业通用定义判成重复、禁用词表把上下文里合理的词也标红、结构阈值卡掉了本来没问题的短文,审稿人每天要否掉几十个误报,几天后他们的应对不是去调阈值,是直接养成“这个闸的提示不用看”的习惯,于是这道闸等于没上,还顺带训练出了对所有自动提示的无视。正确的上线顺序是按“误杀率从低到高”分批:先上几乎不会误判的(死链、图片alt缺失、字数与标题层级),跑稳一周确认没噪声,再上需要调阈值的(查重、可读性初筛),最后上最依赖语境、最容易误报的(禁用词与敏感表述),每上一个观察一周假阳性率、调到团队愿意认真看它的程度,再上下一个。自动化的价值不在“上得全”,在“审稿人是否还信任它的提示”——一道被无视的闸,比没有这道闸更糟,因为它给了你已经在把关的错觉。
质检守住的那几项,怎么顺手提升被AI引用?
这一层是很多团队没意识到的红利:质检流水线认真守住的几项,恰好和内容能不能被AI搜索抽取引用高度重合,等于一套动作拿两份结果。
具体对应关系是清楚的:结构与可扫读这一项守的“层级清晰、要点能被快速抽取”,正是AI抽取内容时最吃的结构友好度;事实准确性守的“每个数据点得到一手来源”,对应的是AI更愿意引用高事实密度、可验证的内容;原创深度守的“比同主题多出独到信息”,本质就是信息增益,是被AI选为答案来源而不是被跳过的关键。所以质检阶段可以顺手加两个面向引用的检查动作:一是看关键结论是不是以能被独立抽取的形式存在(一段话能不能脱离上下文单独成立为一个答案),二是看核心事实有没有紧挨着出处、方便AI连同来源一起引用。把质检和被引用当成一件事来设计,守质量的成本就同时买到了AI可见度,这是规模化内容里少有的一鱼两吃。
一份能直接抄走的分层质检清单
把前面所有环节收敛成一份可执行清单,按从机械到判断的顺序排,前面的自动化、后面的留给人,每一项都给到能判定通过与否的具体标准而不是空话。
机器层(脚本/AI自动跑,人不介入)
- 拼写、标点、全角半角一致性,零错别字放行。
- 全网查重,排除引用块与标准定义后,正文相似度超阈值直接退回,不进人工环节。
- 死链体检:外链可达、站内链接目标真实存在、渲染后DOM里的链接也算、图片alt不缺失。
- 禁用词与敏感表述扫描:命中任一禁用词或高风险句式自动标红。
- 字数、标题层级、结构与结构化数据合法性硬阈值:不达标不进下一关。
事实层(人,一票否决)
- 每个硬数据都点得到一个近两年的一手来源,关键结论有两个独立来源对得上。
- 没有“工整精确数字 + 含糊或过度笃定来源”这种幻觉指纹组合。
- 引用的研究、机构、人物的具体表述,都经过反向查证确实说过。
- YMYL类内容逐条全查不抽样,查不到出处的数字已删除。
语义层(人)
- 把目标查询真的搜过,确认这篇正面回答了用户的真实诉求而非绕关键词。
- 读完能直接拿去用、少踩坑、省时间或省钱,不是看完一笑。
- 比同主题前几名多出至少一个别处读不到的具体点。
品牌与合规层(人)
- 拿风格指纹和标杆样本对照,语气距离在可接受范围内。
- 大声朗读过(最好不止一人),没有读出声就别扭的句子。
- 无违反广告法、行业监管、平台政策的高风险表述(一票否决)。
E-E-A-T与可引用层(人)
- 至少一处真实一手经验,具体到行业、规模、时间。
- 至少一处行业经验者才给得出的判断或反常识结论。
- 关键论断有具体可验证出处,且核心结论以能被独立抽取的形式存在。
这份清单不是让你照单全抄就万事大吉——它本身就是要被你这五到十篇试点修正的对象。但它给了一个正确的起点结构:机械的归自动化,判断的归人,每一项都有能判定的具体线,先小范围磨准再规模化放量。把这套流水线真正跑起来,AI内容才从“产能上去了但不敢看”变成“产能上去了而且敢署名发出去”。
常见问题解答
AI生成的内容到底能不能直接发布?
不能直接发,但也不必每篇都重写。正确做法是过一条人机分工的质检流水线:机械检查交给脚本和AI,事实、语气、意图、E-E-A-T这些判断项必须人来把关,过了带分值的及格线才发。
能不能让AI自己检查AI写的内容?
机械类检查可以,比如拼写、格式、查重初筛。但绝对不能让AI核查自己生成内容里的事实——它本身就是幻觉来源,会很自信地给假数据背书。事实核查只能由人回溯一手出处。
质检清单要做到多细才算够用?
标准是每一项都能回答“低于哪条具体的线就打回”。写“内容要优质”等于没写;写“每个硬数据点得到近两年一手来源、否则删”才算可执行。太空的清单和没有清单差别不大。
小团队没人力做这么重的质检怎么办?
先把机械检查全自动化,把省下的人力按风险分级集中砸在事实和意图两项一票否决的关上。宁可少发几篇守死这两关,也别全量铺开后靠一个人疲劳通读,那是规模化崩盘的标准死法。
为什么新流程一定要先试点几篇再全量?
质检清单第一版必有盲区,也必有AI在你这行反复踩的特定坑没写进去。先用五到十篇真实内容跑完整流程,采集打回原因、AI高频错误、瓶颈环节三组数据,拿现实修正出清单第二版再放量。
质检做好了对被AI搜索引用有帮助吗?
有,而且是直接的。结构清晰、事实可验证、有独到信息和权威细节的内容,正是AI搜索更愿意抽取和引用的特征。质检守住的这几项,恰好和提升AI引用率的抓手高度重合,一套动作两份结果。
权威参考资料
本文标题:《AI内容写完谁来质检?人机分工与事实核查清单》
本文链接:https://zhangwenbao.com/ai-content-qa-workflow-human-ai-review-checklist.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0