robots.txt挡不住AI训练:Google被诉案摊开了内容进模型的4条路
Google-Extended这个令牌在服务器日志里永远看不到,因为它根本不是抓取器。这篇从一份57页起诉书原件讲起,把内容进入大模型的4条路径逐条摊开,说明为什么其中3条跟robots.txt没有任何关系,以及CCBot那一条该怎么单独写。

标签
保哥笔记 robots.txt 标签下共 14 篇文章合集,含《robots.txt挡不住AI训练:Google被诉》《Google有一整类抓取器不看robots.txt,》《robots.txt和meta robots什么时候》等,与 技术SEO、AI爬虫、disallow 主题密切相关,覆盖 SEO/GEO 实战角度的深度解析与可落地方案。
Google-Extended这个令牌在服务器日志里永远看不到,因为它根本不是抓取器。这篇从一份57页起诉书原件讲起,把内容进入大模型的4条路径逐条摊开,说明为什么其中3条跟robots.txt没有任何关系,以及CCBot那一条该怎么单独写。
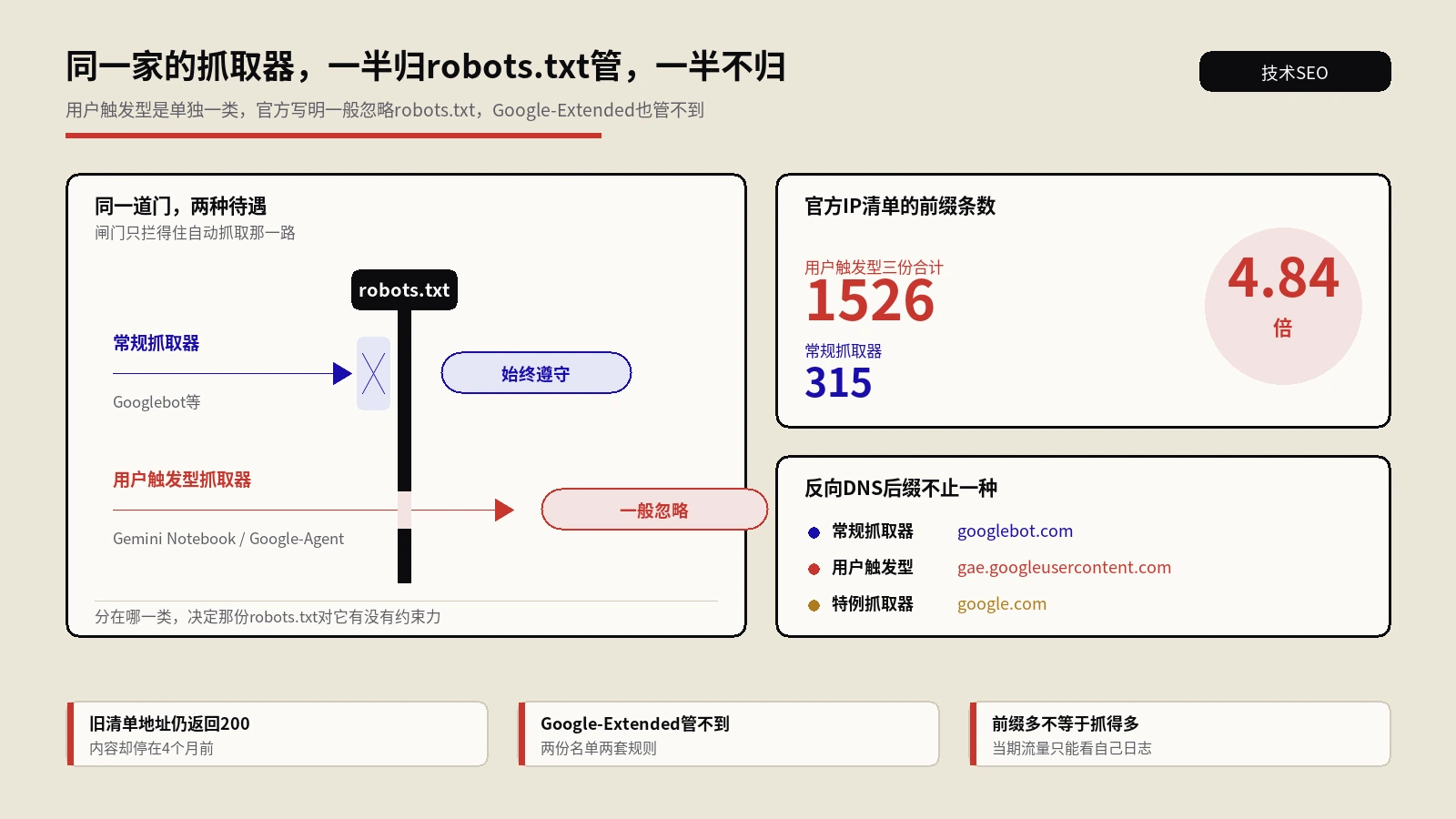
官方把用户触发型抓取器单列一类,并写明它们一般会忽略robots.txt,Google-Extended同样管不到。这篇从令牌改名讲起,把这一类的分类逻辑、五份官方IP清单的真实规模、反向DNS的三种形态,以及协议之外还剩哪几层能拦,逐条摊开。
很多出海独立站突然从Google消失,根因不是内容问题而是robots配置——把抓取和索引混为一谈、Disallow拦住想noindex的页面、X-Robots-Tag误覆盖全站。本文给一张三件套边界图、所有指令清单、优先级裁决规则和出海亲子玩具独立站12周修复误封的真实SOP,看完就能直接判断自己这套robots到底改不改、改在哪一档。
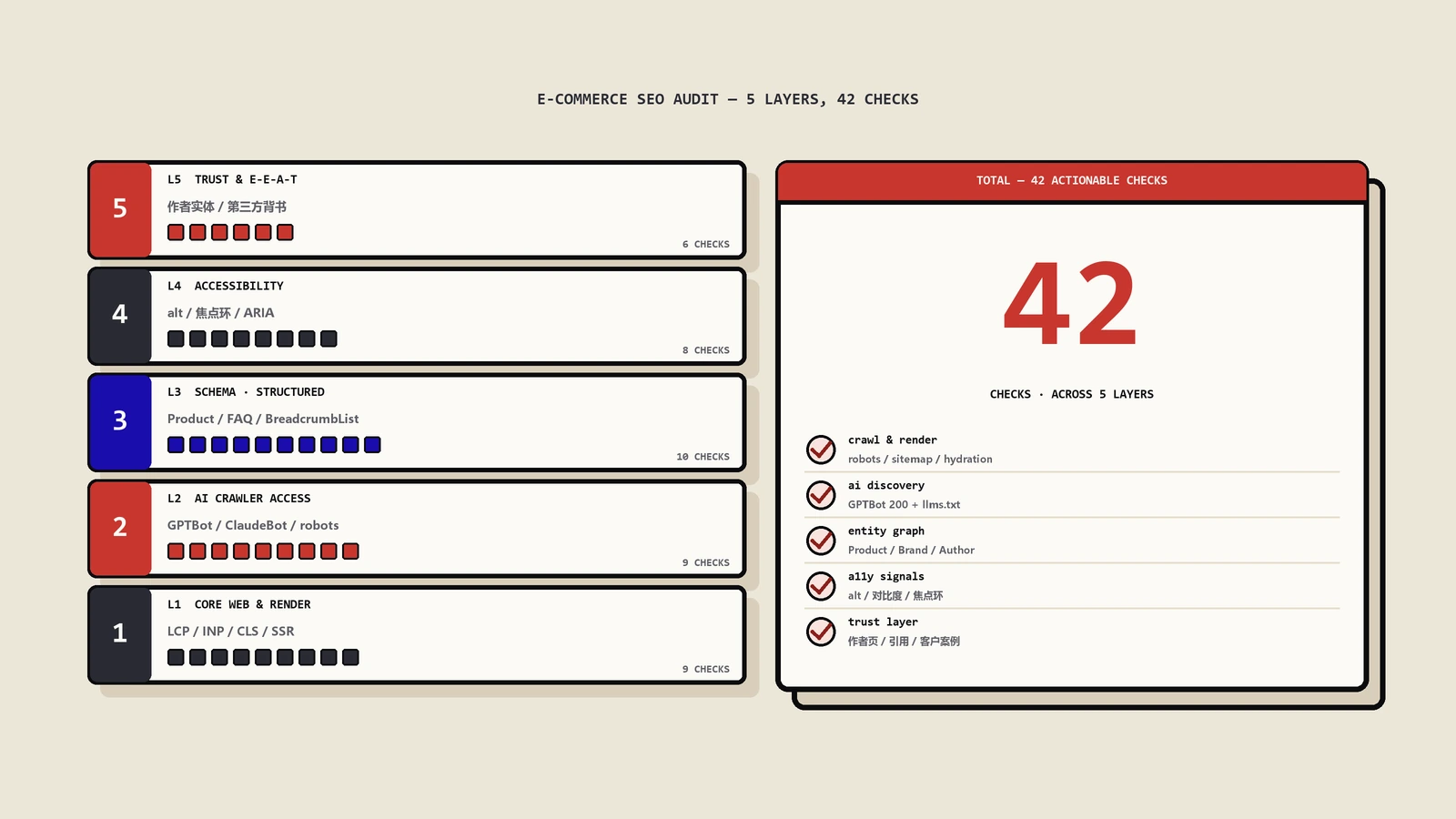
Site Audit跑出来500个问题不代表要修500个——技术SEO修复必须按业务影响排序,而不是按工具的问题计数。本文拆解ICE、RICE、PIF三套打分模型的实操差异,给出7类常见技术问题的真实ICE评分对照表,再补5个Quick Wins可复制模板和4个向老板汇报的真业务指标。

Cloudflare 2026-Q1数据显示30.6%全网流量来自bot。传统技术SEO审计针对Googlebot的那套对GPTBot/ClaudeBot/PerplexityBot不够用。本文拆AI爬虫准入robots.txt策略、SSR成准入门槛、JSON-LD的AI加成、accessibility tree审计、内容位置和可提取性5层框架。
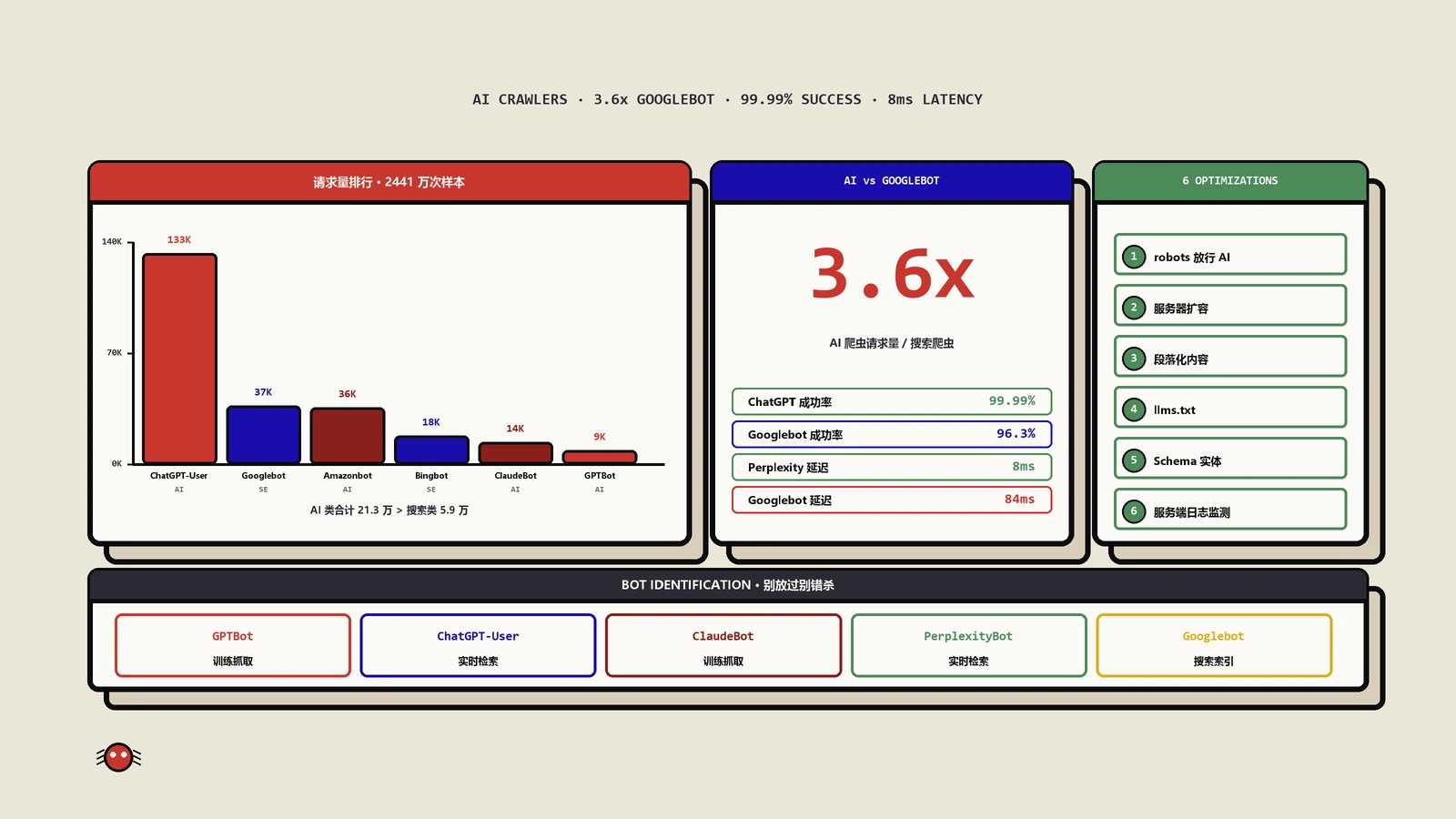
2400万次请求数据揭示,ChatGPT爬虫抓取量已达Googlebot的3.6倍。本文深度解析AI爬虫生态格局,提供robots.txt配置、抓取预算优化、AI搜索可见性提升等实操策略。
在robots.txt中直接禁止UTM参数会导致Google Ads广告被拒登、索引混乱、抓取预算浪费等严重危害。本文讲解UTM等追踪参数原理与种类,对比SPM、自定义参数等不同跟踪技术,并推荐用规范标签、Meta Noindex和URL重写等方式正确处理参数化URL,避免重复内容稀释权重。

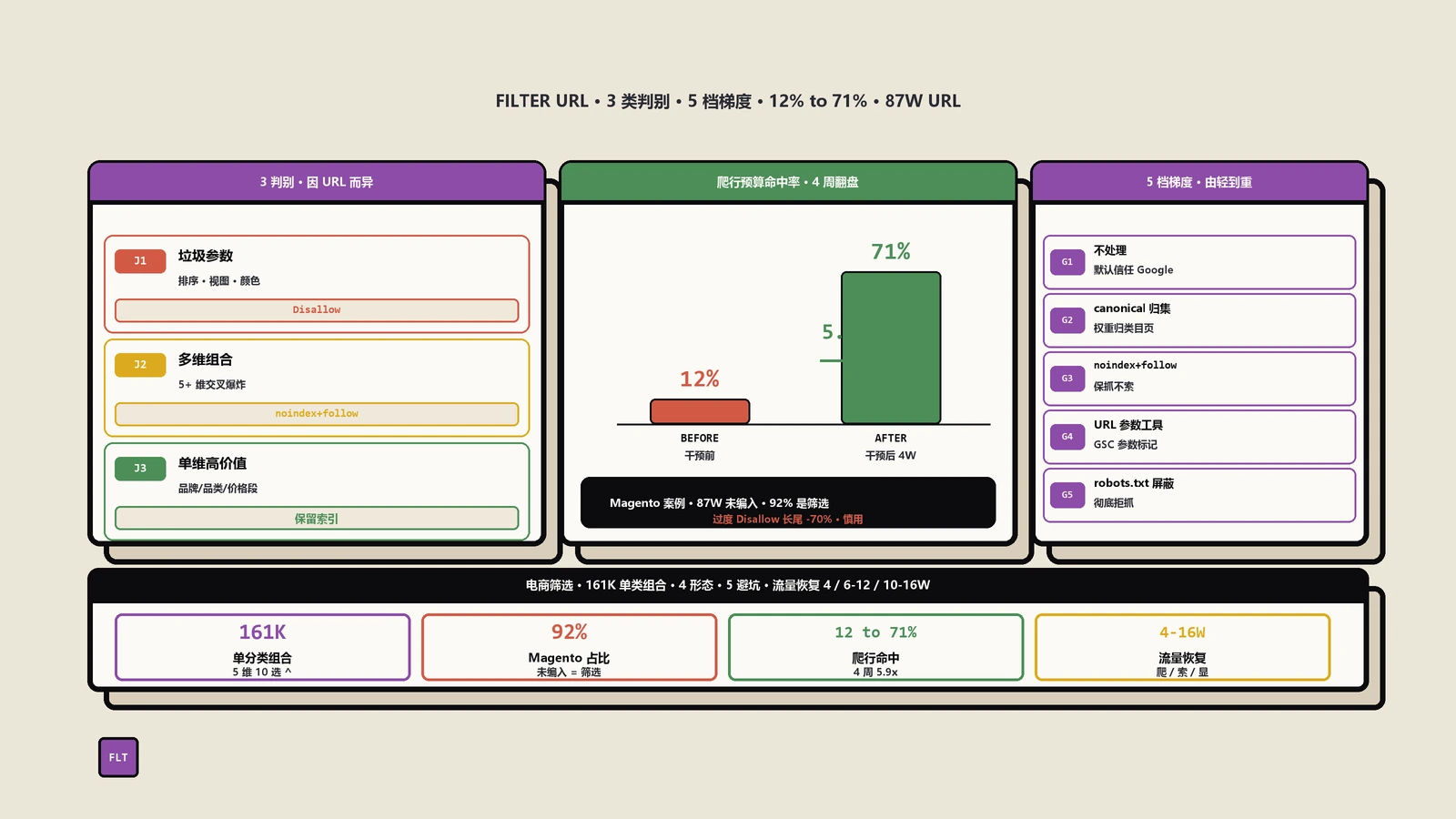
电商筛选器一不小心就把Googlebot爬行预算吃光,乱写robots.txt Disallow又会把高搜索价值的色彩品牌价格筛选页一起屏蔽。保哥用2个真实案例(Magento 2跨境站爬行预算从92%浪费修到71%命中商品页,国内ECShop站因过度Disallow长尾流量损失70%)演示3类判别法和5档阶梯式处理策略,并附WooCommerce、Shopify、百度SEO的具体写法。
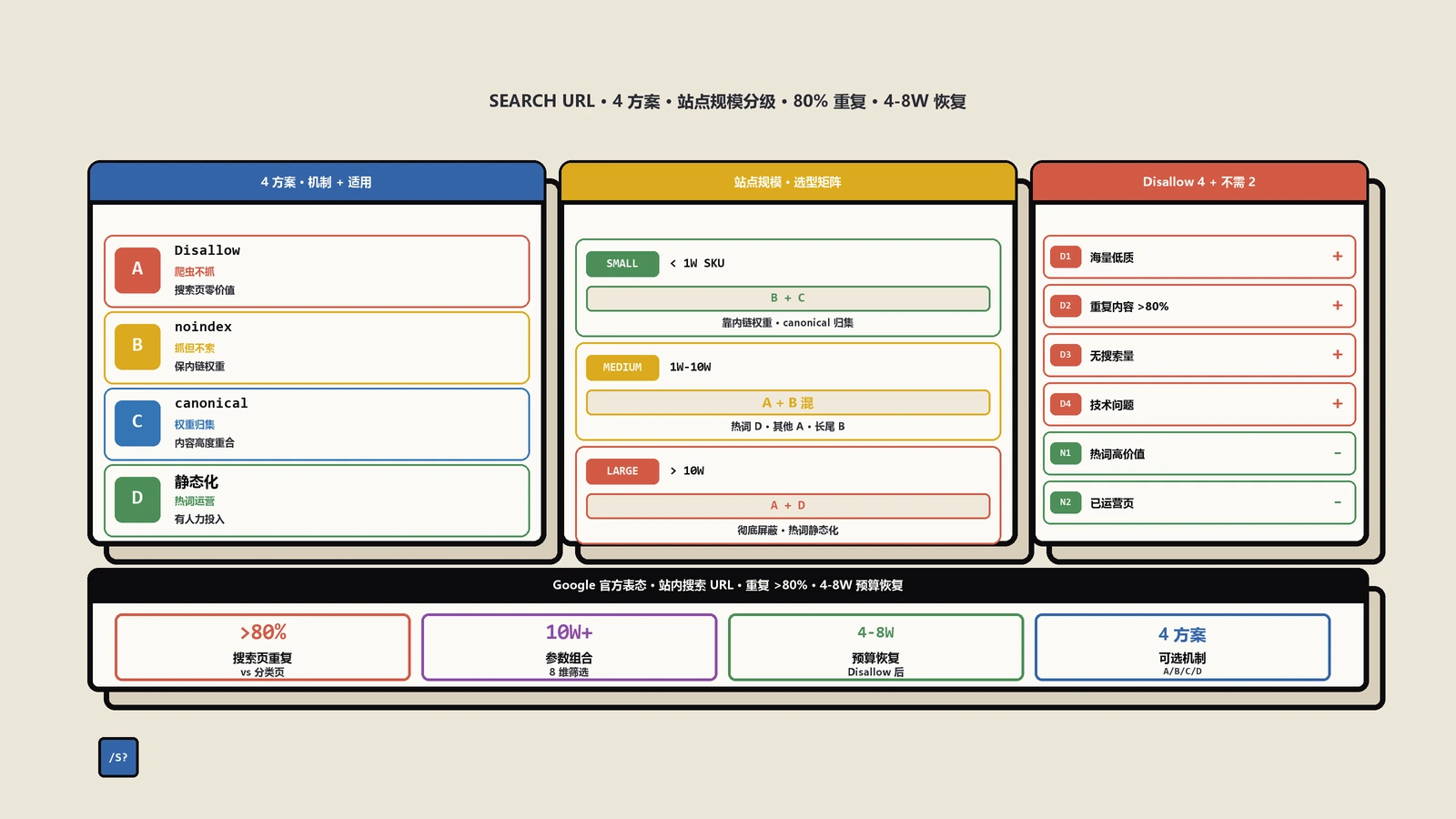
站内搜索页面会产生大量参数化低质 URL,要不要在 robots.txt 里 Disallow?保哥结合 Google 官方表态梳理 4 种处理方案:robots.txt Disallow、meta noindex follow、rel=canonical 归集、URL 静态化运营,并按站点规模给出三档实施清单与典型踩坑回顾。
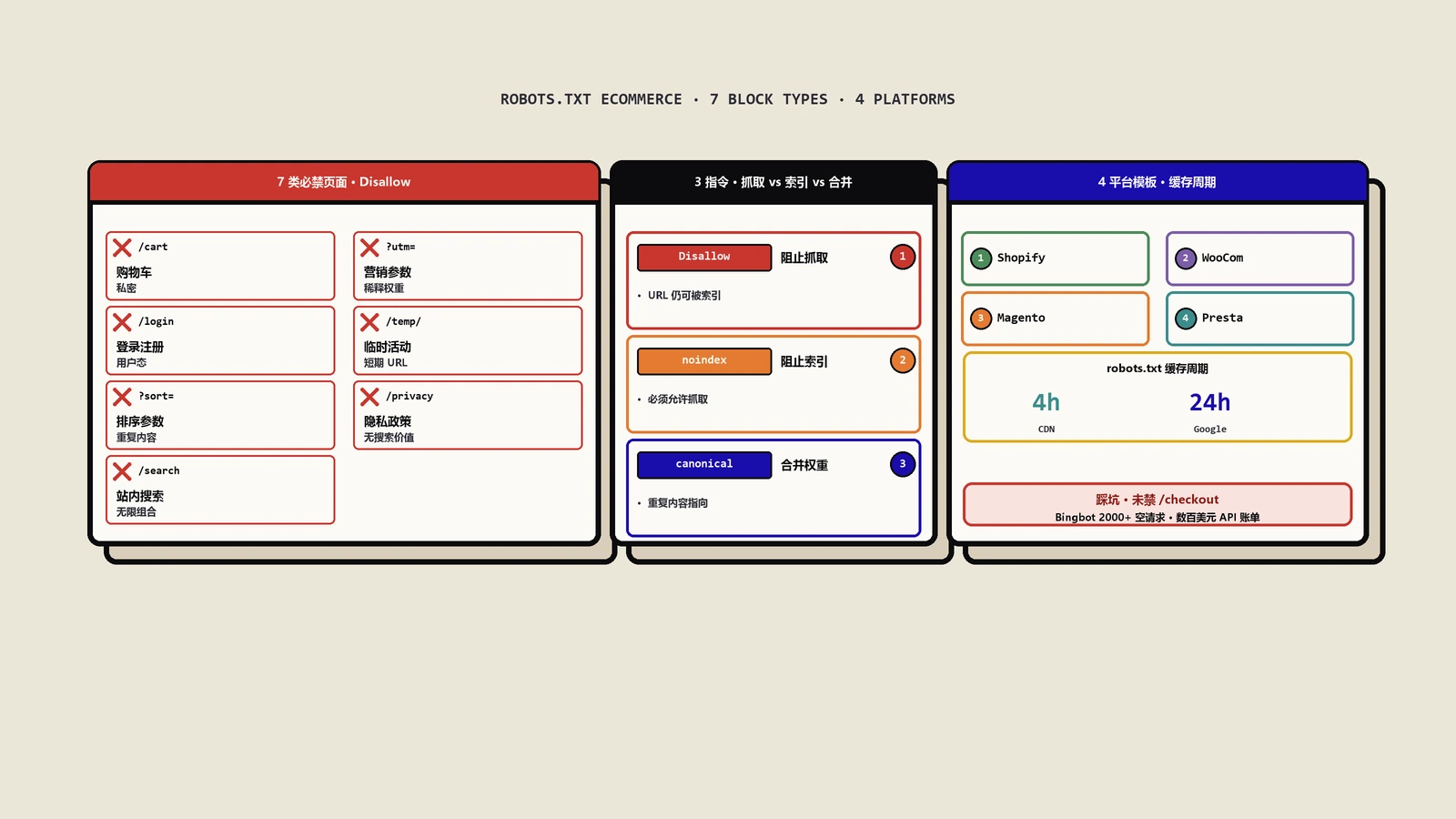
做了8年电商SEO顾问的保哥总结:电商站需要在robots.txt里禁止抓取的7类页面(购物车、登录、过滤排序、内部搜索、参数化、临时活动、隐私条款),附Shopify/WooCommerce/Magento/PrestaShop四种平台的完整模板与CSS/JS误屏蔽灾难案例。
2024年下半年Cloudflare一键拦AI爬虫上线之后,行业里一边倒地讨论怎么拦。但拦完真的好吗?这两年带客户实测发现,盲拦让AI引用率从月均320次掉到接近零,营收损失远超被爬走的内容价值。这篇把robots.txt+User-Agent黑名单+WAF三层方法各自的能挡什么、挡不住什么、维护成本、误屏蔽风险一次拆透,含三层选型决策矩阵+出海手作钢笔DTC品牌一年盲拦后引用归零的失败复盘+NYT/Reuters/Reddit/Sta…
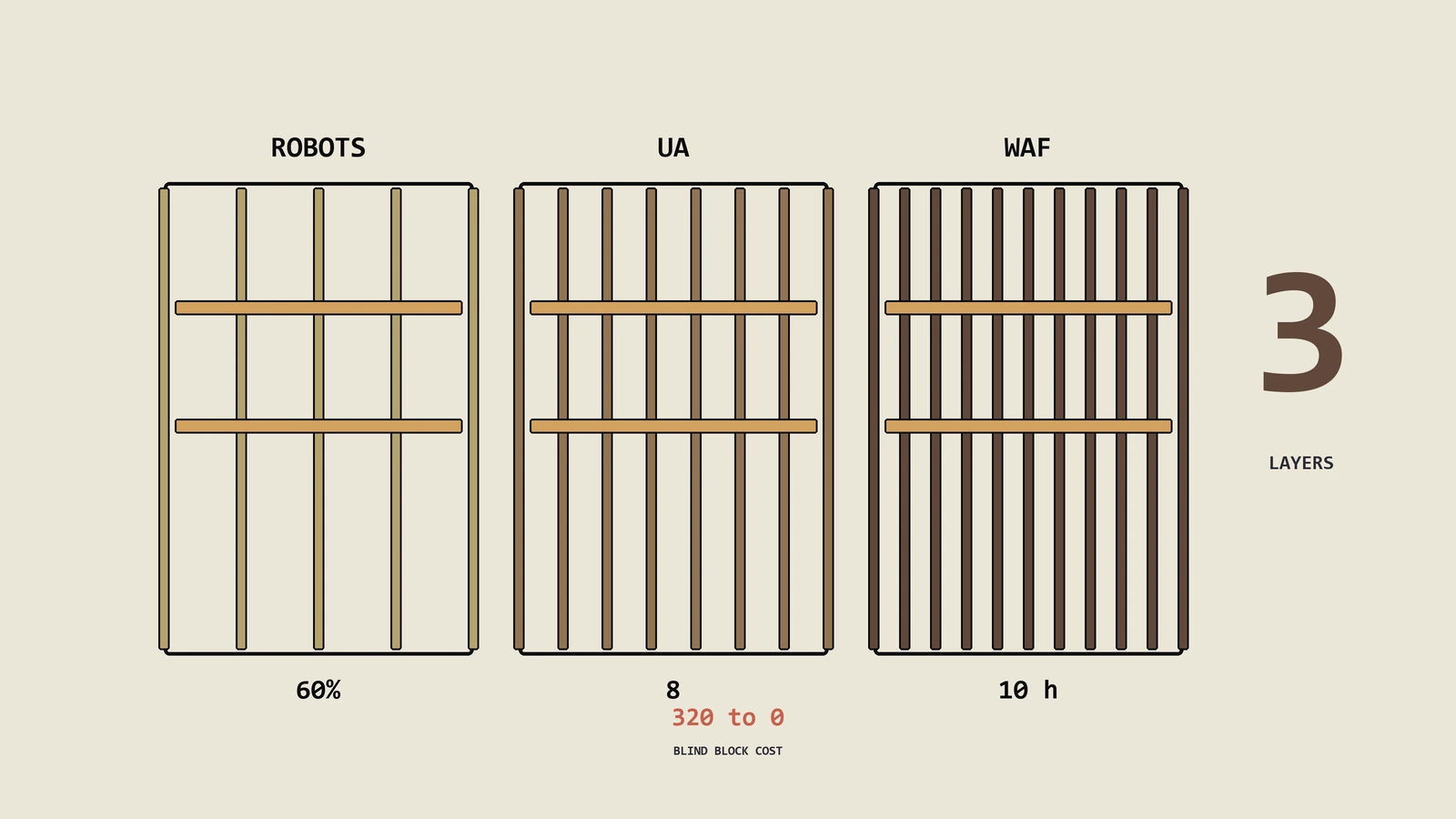
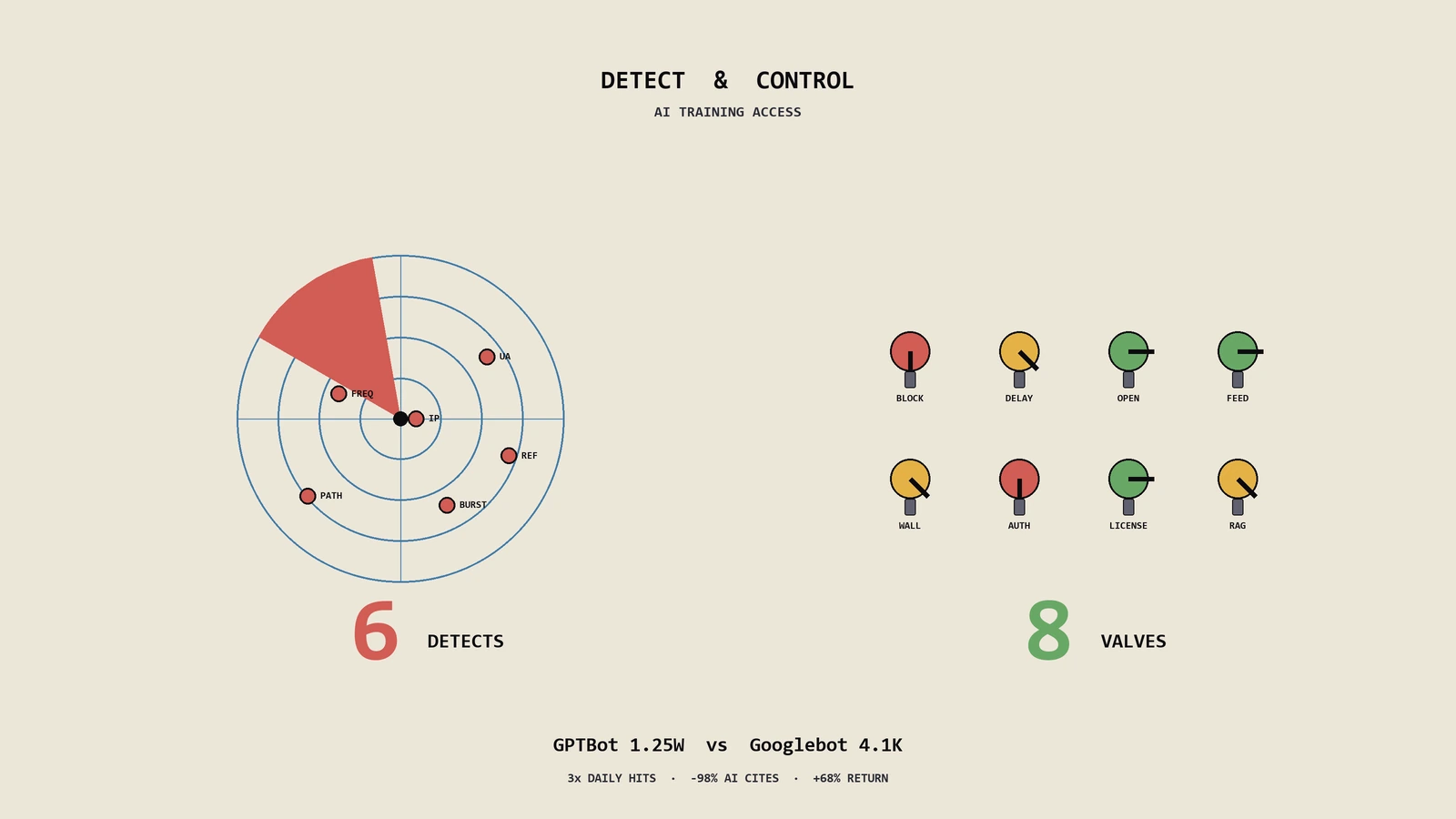
出海精油护肤DTC客户上周拿来一份Cloudflare日志,问我那批名字奇怪的爬虫是不是在偷她家产品文案训练AI。答案多半是,但靠常规思路盲拦不是好路子,需要先用6种方法把检测做实,再按内容资产价值、流量回路、品牌曝光、法律边界4维度走8种授权选择决策矩阵,最后把AI引用反向变成新流量入口。
WordPress 的 robots.txt 写错会让 Google 抓不到内容、写『通用版』反而屏蔽掉 CSS/JS 让移动友好性扣分。本文给出 2026 年标准模板:虚拟 robots.txt 与物理文件的优先级判定、wp-content/wp-includes 不再屏蔽的理由、GPTBot/ClaudeBot 等 AI 爬虫的拦放分类、Allow/Disallow 在 Google/Bing/百度的优先级差异、附件页处理、Site…

只想挡一个目录,整站却从Google搜索里消失,技术体检全绿也查不出处罚——问题往往出在robots.txt的解析机制没搞懂。本文系统讲透这个协议本身:它管抓取不管收录的边界、Allow与Disallow的最长匹配判定、通配符和错误码语义、RFC 9309后各引擎差异、AI爬虫该不该封,以及误封后的五步诊断恢复流程。