站内搜索URL该Disallow吗?4种方案对比
本文目录
摘要:站内搜索URL到底该不该用robots.txt屏蔽?本文梳理Google多年的官方立场、需要屏蔽的四类场景——重复内容、参数爆炸、低质感知、爬行预算,以及两类例外,再给Disallow、noindex follow、canonical、静态化四种方案的选型矩阵和精确写法,附大型电商案例、监控指标和按站点规模分级的实施清单。
站内搜索页面要不要在 robots.txt 里 Disallow,是保哥从 2017 年开始几乎每周都要在外贸站和国内电商独立站项目里被反复问到的一个问题。表面看是一行配置的事,往深挖一层就牵扯到爬行预算、重复内容判定、Canonical 选择策略、参数 URL 治理、Search Console 性能报告分析的整套逻辑。本文用一篇长文把这个话题讲透:什么时候该 Disallow、什么时候不该、与 noindex follow / canonical / 参数处理之间该如何取舍,最后附 Google 官方明确表态、4 种典型方案对比与一份完整 FAQ。
什么是站内搜索 URL,它为什么是个 SEO 隐患
所谓站内搜索 URL,是指用户在你的网站搜索框里输入关键词后跳转出来的那种 URL。最常见的形式是:
/search?q=red+shoes
/search?q=red+shoes&sort=price
/search?q=shoes&page=2&color=black这类 URL 有四个 SEO 上的"原罪":
- 无限可枚举。只要有人愿意输入,
?q=...后面可以是任何字符串,理论上能产生无穷多个 URL。爬虫一旦顺着内部链接(比如热搜词、相关搜索)发现入口,就会陷入这个坑里。 - 内容重复。搜索"红色鞋子"和"红 鞋子"和"red shoes"很可能给出几乎一样的结果列表,同一组商品在不同 URL 下被反复输出,极易触发 Google 重复内容检测,权重被稀释。
- 低质感知。搜索结果页通常没有原创编辑内容、没有结构化标记、没有面包屑导航。从 Google 的 helpful content 视角看,它们就是典型的"为搜索引擎而非用户而生"的页面。
- 消耗爬行预算。Googlebot 对每个站点都有一个动态调整的抓取额度(crawl budget),把它消耗在搜索结果页上意味着真正重要的产品详情页、分类页、博客文章被抓取得更少。
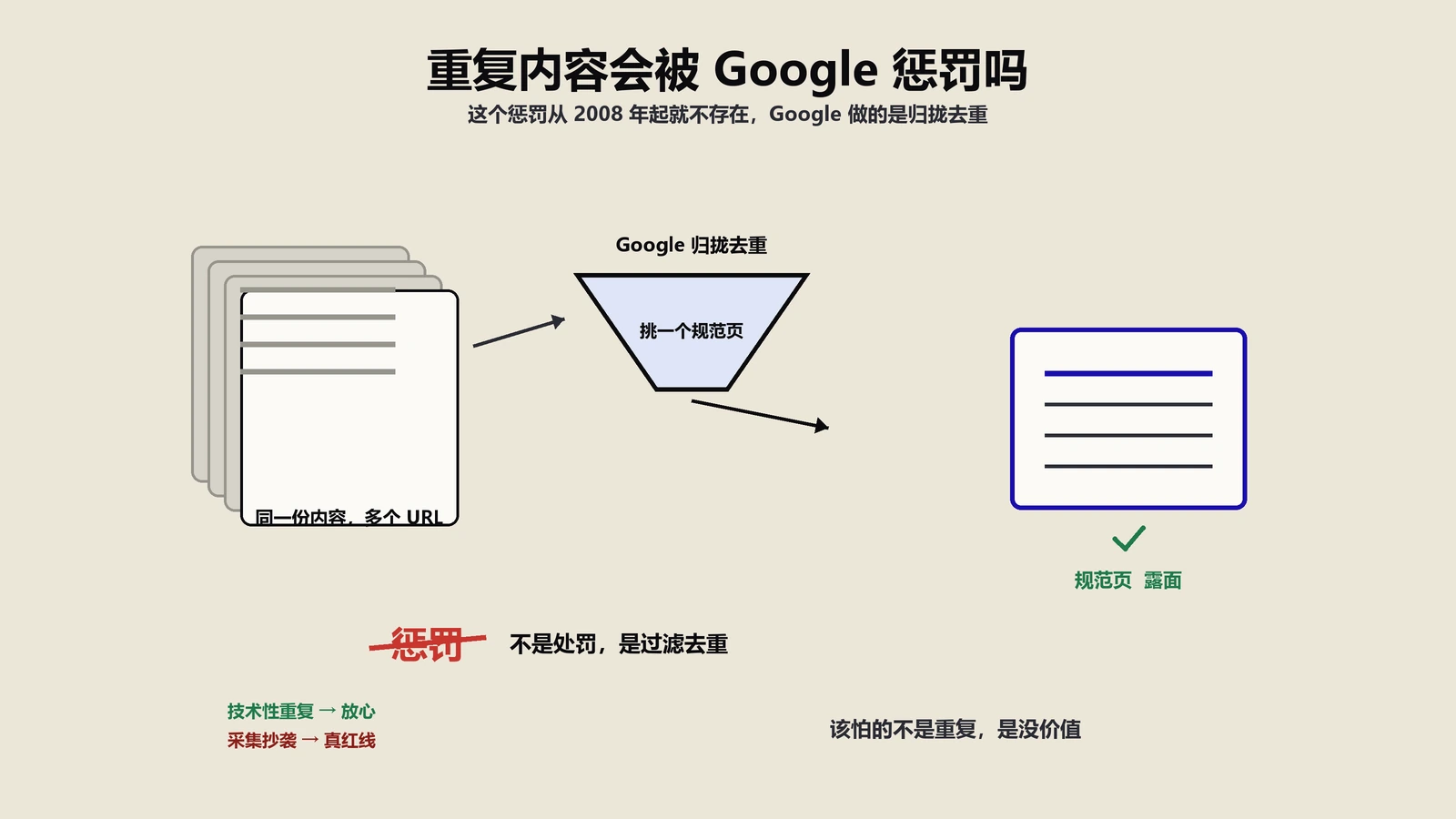
这四点叠加起来,就是为什么 Google 在 2007 年就明确建议站长用 robots.txt 把站内搜索页屏蔽掉。Matt Cutts 当年那篇官方博客《Google does not want search results pages》是行业入门必读。
Google 官方原话与近几年的表态变化
很多人不知道,Google 对这件事的态度从 2007 到 2026 年并没有翻盘,但在执行细节上有过几次松动。保哥把关键节点梳理一下:
- 2007 年:Google Webmaster Central 博客明确声明"我们不希望在搜索结果里显示其他网站的搜索结果页",鼓励站长用 robots.txt 屏蔽。
- 2014 年:John Mueller 在 Webmaster Hangout 上确认,搜索结果页对用户没有增量价值的时候,建议直接 Disallow。
- 2018 年:Google 推出 URL 参数处理工具(Search Console 老版本里的 URL Parameters),允许站长不动 robots.txt 的情况下指示 Googlebot 忽略某些参数。这个工具在 2022 年退役,参数治理重新回到 robots.txt + canonical 的传统组合。
- 2022 年:Mueller 在多次 Office Hours 里反复强调,Disallow 不等于 noindex——Disallow 的页面 Google 不会抓取,但如果有外部链接指向,依然可能被收录(只是没有正文内容)。所以重要的是确认你想要的最终目标是"不抓取"还是"不索引"。
- 2024-2026 年:随着 AI Overviews / SGE 上线,Google 进一步收紧低质量页面入选概率,对站内搜索结果页的态度比以往任何时候都更明确:除非你能证明这些页面本身有独特、深度的内容,否则建议屏蔽。
结论一句话总结:2026 年的官方立场仍然是默认建议 Disallow,特殊情况例外。
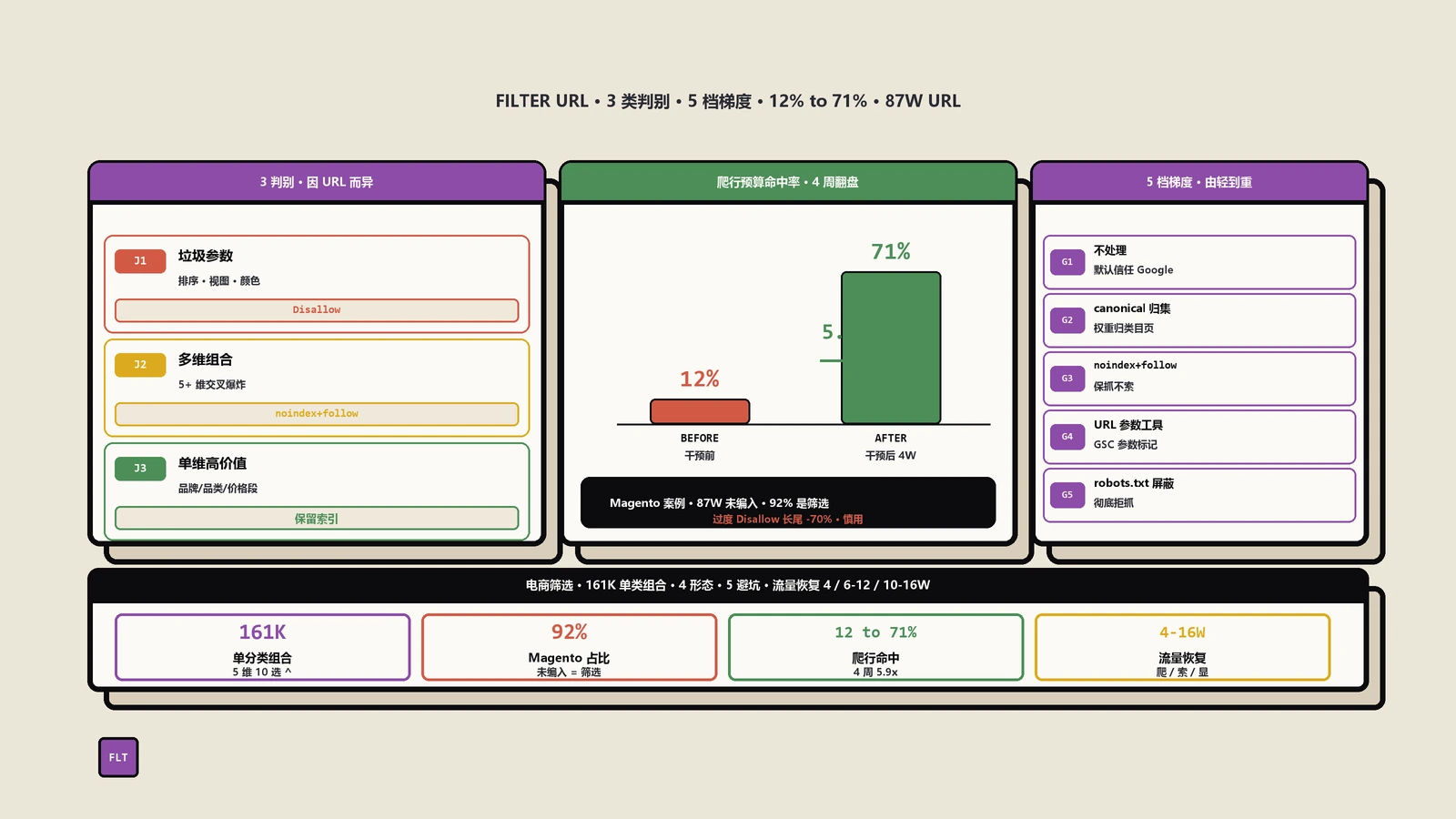
需要 Disallow 的四种典型场景
内容高度重复
站内搜索页本质是从分类页和详情页拼出来的瀑布流,跟分类页的内容重叠率往往超过 80%。比如搜索"运动鞋"得到的列表,和 /category/sneakers/ 几乎一致。Google 看到这种内容会判定其中一个为低优先级,权重被稀释。屏蔽搜索页能让分类页拿到更干净的权重信号。
参数组合爆炸
电商独立站常见的参数维度有:关键词、排序、分页、筛选(颜色/尺码/品牌/价格区间)。一个 8 维筛选系统,理论参数组合数能轻松突破 10 万。爬虫顺着内链一路展开,几天就把站点抓爆。Disallow: /*?q= 一行配置就能止血。
没有独特价值
典型表现:搜索页没有 H1 标题、没有面包屑、没有自定义文案、没有结构化数据。这种页面被索引也带不来流量,反而拉低站点整体质量评分。
爬行预算紧张
判断方法:登录 Search Console → 设置 → 抓取统计信息,看每天 Googlebot 的请求数和已发现 URL 数。如果你的站点超过 5 万 URL、抓取频率只有几千/天,意味着每个 URL 平均几周才被复访一次——这时候 crawl budget 已经是瓶颈,必须把 Disallow 用起来。
不需要 Disallow 的两种情况
搜索结果页本身就是入口
有些站点的搜索页是经过深度优化的,比如知乎搜索 /search?q=... 页面会有 SEO 标题、相关问题摘要、用户互动数据;这种情况下搜索页本身就是一个高质量的内容入口,屏蔽反而损失流量。
已有完善的 canonical 策略
如果你在搜索结果页头部加了 <link rel="canonical" href="/category/sneakers/">,把所有搜索页的权重归集到对应的分类页,那么允许爬虫访问搜索页是没问题的,Google 会自动识别 canonical 关系并正确分配权重。
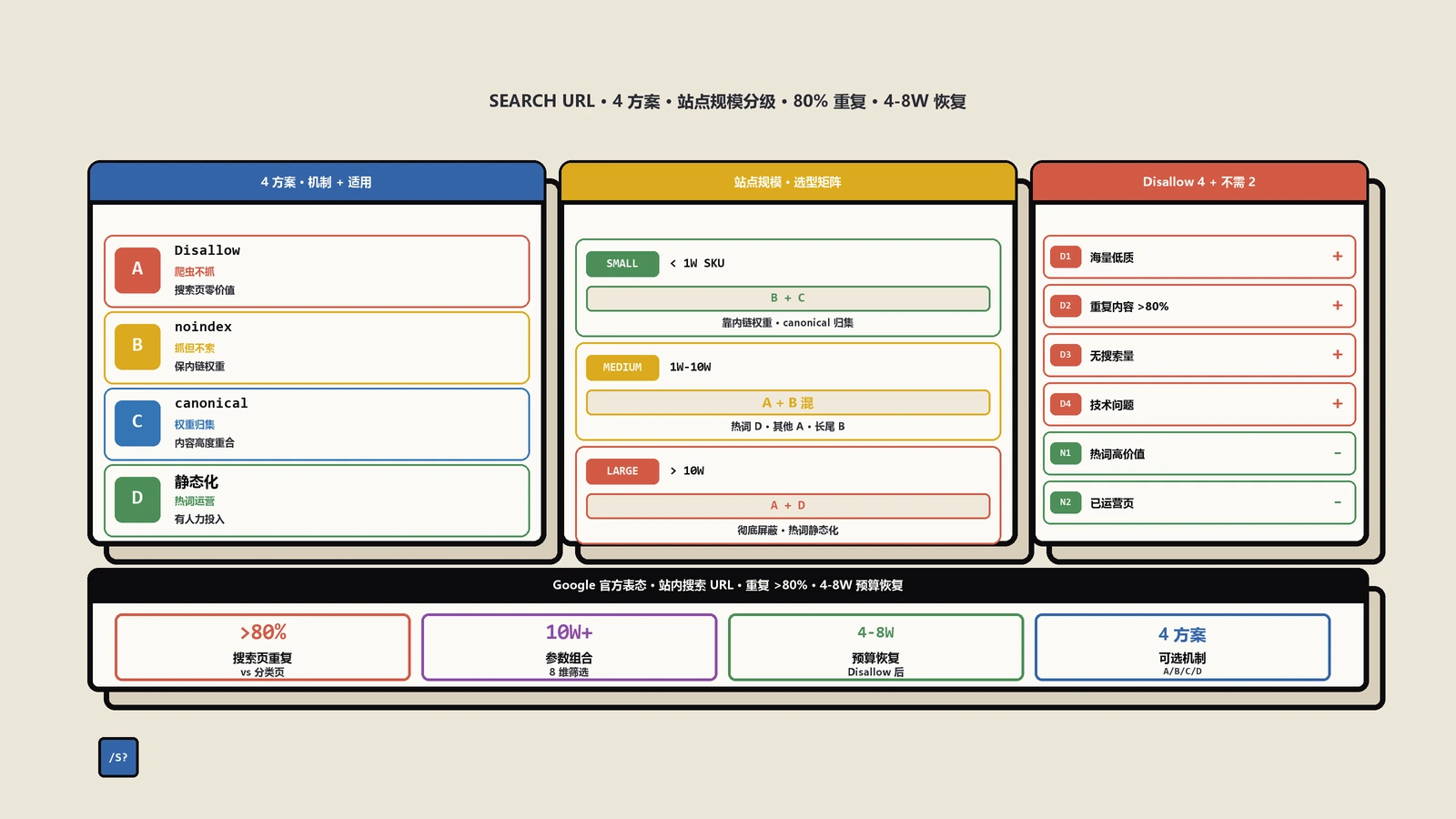
四种处理方案的选型矩阵
保哥把现实里能用的所有方案列在一起对比,按场景挑就行:
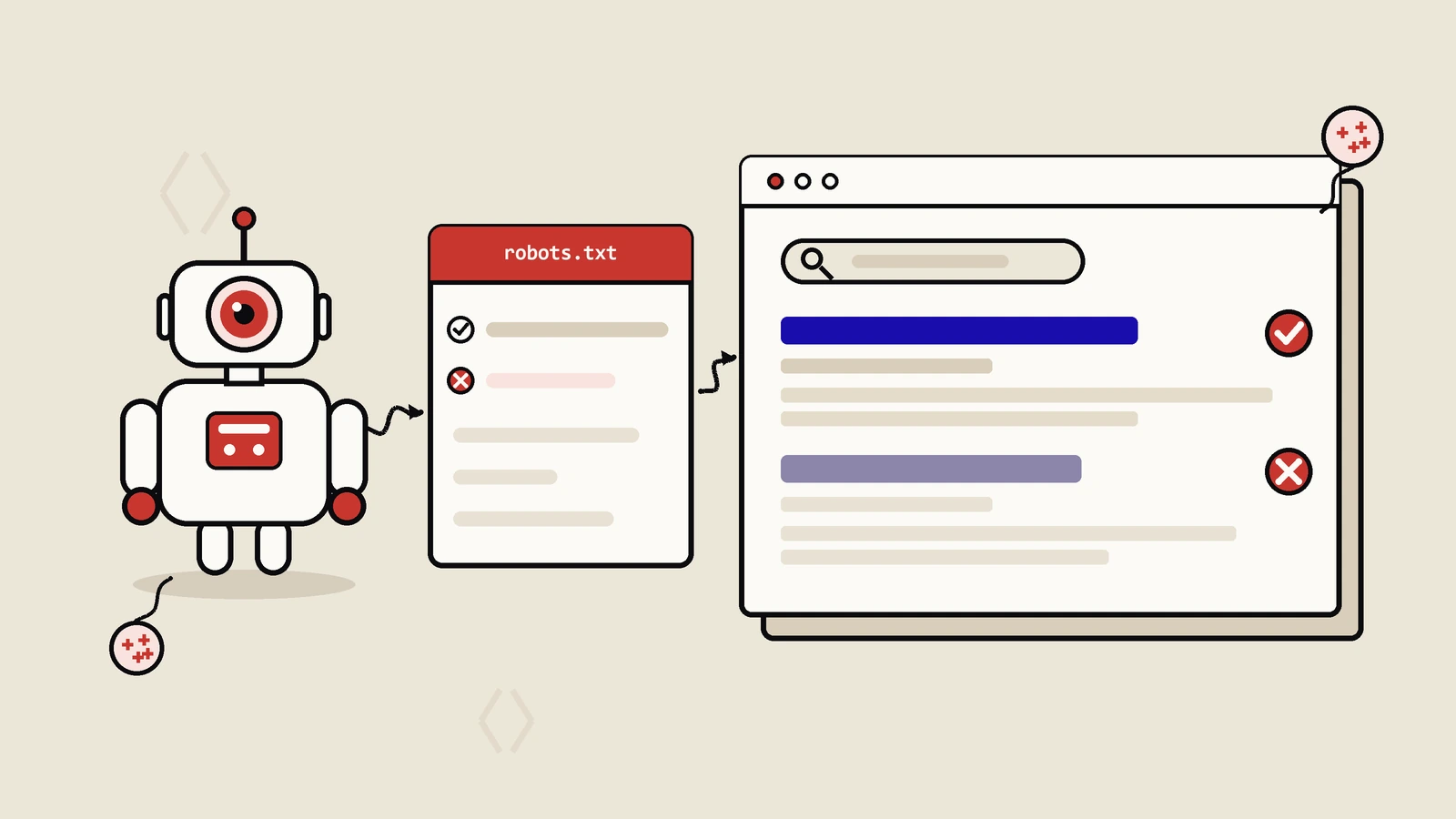
- 方案 A:robots.txt Disallow。最彻底,爬虫连页面都不会请求,节省爬行预算最多。代价是已有反向链接指向的页面可能依然被收录(无正文)。适合站点规模大、搜索页毫无价值的情况。
- 方案 B:meta robots noindex follow。允许爬虫抓取,但不索引;同时跟随页面上的链接传递权重。代价是爬行预算照常消耗。适合搜索页有内链价值、但页面本身不想被搜索结果展示的情况。
- 方案 C:rel=canonical 归集到分类页。爬虫照抓不误,但权重信号统一指向 canonical 目标。适合搜索页和某个分类页几乎等价的场景,比如
/search?q=red+shoes等价于/category/red-shoes/。 - 方案 D:URL 静态化 + 独立优化。把热门搜索词转成
/search/red-shoes/这种静态 URL,给独立的 H1、meta description、相关推荐,让搜索页成为流量入口。适合长尾词分布明确、有运营资源持续维护的站点。
多数中小型独立站的最佳实践是 A + C 组合:robots.txt 屏蔽掉所有 ?q= 形式,对少数运营重点的关键词手动建静态搜索页,并做 SEO 优化。
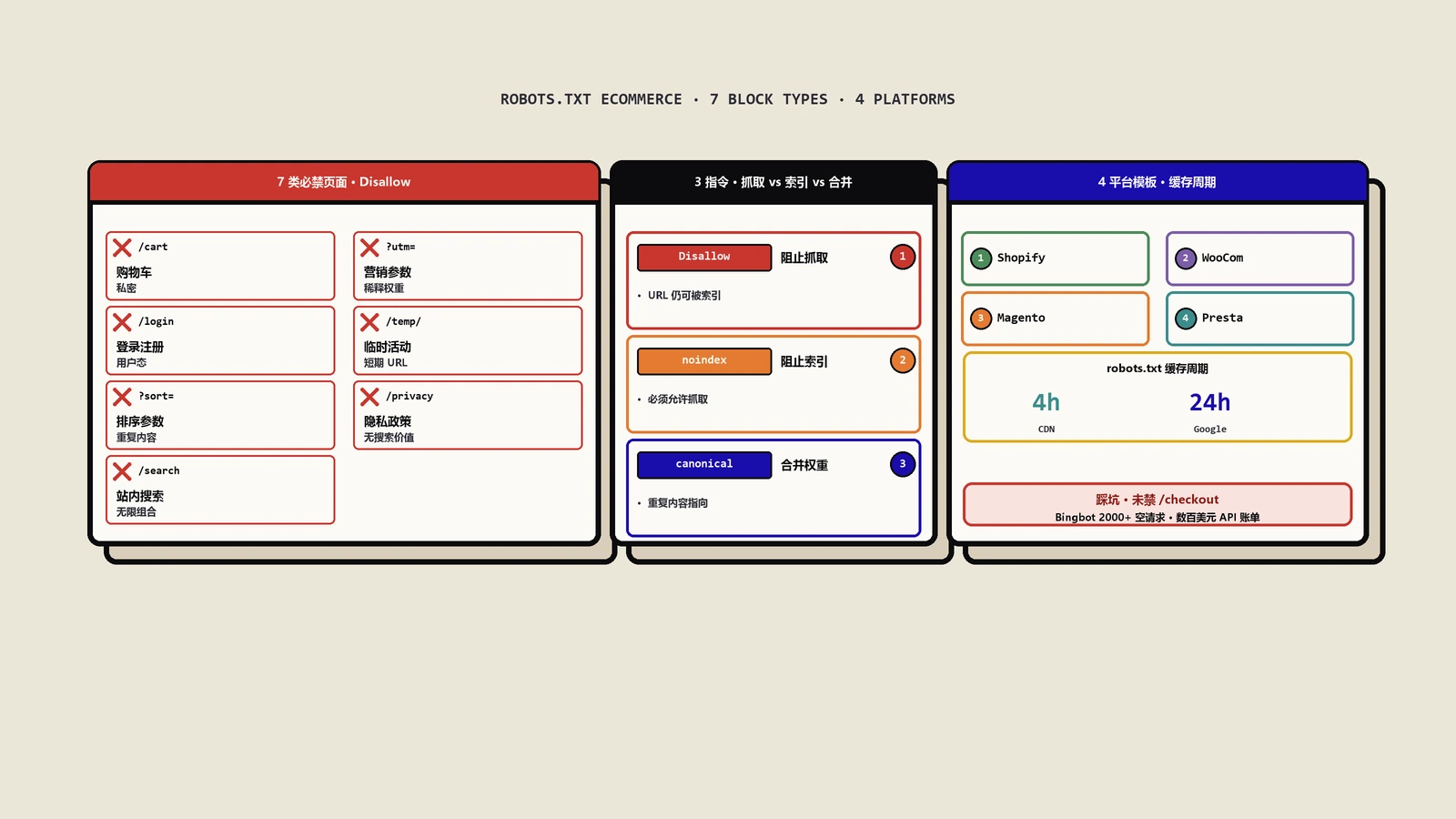
robots.txt 的精确写法
不同站点的搜索 URL 形式差异很大,下面给一份覆盖主流框架的模板:
User-agent: *
Disallow: /search
Disallow: /*?q=
Disallow: /*?s=
Disallow: /*?keyword=
Disallow: /*?search=
Disallow: /*&q=
Disallow: /*?sort=
Disallow: /*?filter=
# 允许 Googlebot 抓取分类页带 page 参数的分页
Allow: /category/*?page=
Sitemap: https://www.example.com/sitemap.xml几个细节需要注意:
- 通配符
*与锚点$。Disallow: /*?q=的写法会拦截所有路径下的?q=参数。$用于锚定结尾,比如Disallow: /*.pdf$只匹配以.pdf结尾的 URL。 - 大小写敏感。
Disallow: /Search和/search在 URL 路径上是两条规则。如果你的站点既有/search又有大写入口,要分别写。 - Allow 优先级。Allow 与 Disallow 同时匹配时,更"具体"(更长)的规则胜出。Google 的解析逻辑可参考 robotstxt.org 与官方文档。
- 不同搜索引擎差异。Bingbot 和 Yandex 对通配符支持没那么完善,必要时为 Bing 单独写一段更显式的
Disallow。 - 测试工具。Google Search Console 自带 robots.txt 测试器(在"设置"里),写完 robots.txt 一定要在测试器里跑几个典型 URL 验证拦截效果。
noindex 与 canonical 的实操写法
方案 B 的写法,在搜索结果页 <head> 里加:
<meta name="robots" content="noindex, follow">follow 的作用是让 Googlebot 仍然跟踪页面里的链接、传递权重,避免搜索结果页被视为"死胡同"。如果你不想让权重外溢,则可以用 noindex, nofollow,但实际项目里很少这么干。
方案 C 的写法:
<link rel="canonical" href="https://www.example.com/category/sneakers/">canonical 的关键点:
- 必须是绝对 URL。Google 会跟随相对 URL,但绝对 URL 减少歧义。
- 不能形成链状或回环。如果 A canonical 到 B、B canonical 到 C,权重信号会被稀释甚至忽略。
- canonical 是建议不是强制。Google 会综合考虑内容相似度、内链权重等信号,可能不采纳你的 canonical 提示。所以在重要页面上一定要确保 canonical 指向的页面真的内容更优质。
URL 静态化与长尾词运营
如果你打算把搜索页做成流量入口,2026 年常见的做法是这样几步:
- 抓取热门搜索词。从站内搜索日志、Search Console、第三方工具(Ahrefs、Semrush、5118)里筛出搜索量大、商业意图明显的长尾词。
- 批量生成静态页。用模板引擎自动渲染
/search/red-shoes/这类静态 URL,每个页面有独立的 H1、meta description、商品列表、用户问答区、相关搜索推荐。 - 结构化数据。给每个商品列表加 ItemList JSON-LD,给问答区加 FAQPage JSON-LD,提升搜索结果展示的信息密度。
- 内链布局。从首页热搜模块、分类页相关搜索区、商品详情页相关推荐里多角度链入。
- 持续监控。用 Search Console 追踪每个静态搜索页的展示量、点击率、平均位置,对低表现页面定期更新或合并。
这套打法的天花板很高——很多大型电商把站内搜索做成了主要的 SEO 流量来源,但代价是需要持续运营投入。中小站慎选,如果没运营资源,老老实实 Disallow 反而最稳。
Search Console 实战与监控指标
无论你选 A、B、C、D 哪种方案,部署完都要持续监控以下几个指标:
- "已被检索但当前未编入索引"(Crawled - currently not indexed)。在 Search Console → 网页索引报告里。如果这个数字突然飙升,且大量 URL 是搜索页路径,意味着你的方案没起效。
- "已发现 - 当前未编入索引"(Discovered - currently not indexed)。Googlebot 知道这些 URL 但选择不抓——通常是 robots.txt 屏蔽生效了。
- "含有 noindex 标记"。方案 B 部署后这里会出现搜索页 URL。
- 抓取统计信息。看 Googlebot 每天对站内搜索路径的请求数。屏蔽生效后这个数字应该接近 0。
- 性能报告。如果搜索页本来就有自然流量,方案 A 之后流量会消失,这是预期;如果是方案 B/C/D,自然流量应该稳定或上升。
大型电商案例参考
看几个大站怎么做的,有助于理解不同规模下的取舍:
- Amazon:搜索页 URL 形如
/s?k=red+shoes,robots.txt里允许爬取,但页面 head 用<meta name="robots" content="noindex">屏蔽索引。Amazon 选这个策略是因为它要把搜索页当作内链中转,但又不希望被收录。 - 京东:搜索页
/Search?keyword=在 robots.txt 里 Disallow,而且对热门关键词单独建静态页/list.html?cat=...,是典型的 A + D 组合。 - Shopify 默认:所有 Shopify 店铺的
/search路径默认在 robots.txt 里被 Disallow,且页面带noindex,这是模板自带的最佳实践。 - WooCommerce 默认:插件不会自动屏蔽搜索页,需要店主手动加。这也是为什么很多 WooCommerce 站点 SEO 表现不好的常见原因。
- 独立站常见错误:用 Sitemap 把搜索页 URL 也提交了。Sitemap 是"建议索引"信号,跟 Disallow 直接冲突,一定要把搜索页 URL 从 Sitemap 里清掉。
踩坑回顾
保哥过去几年踩过的几个典型坑:
- 把 Disallow 写错路径。曾有客户写成
Disallow: /search/(带斜杠),结果/search?q=...(不带斜杠的 path)没匹配上,搜索页继续被抓。建议同时写Disallow: /search和Disallow: /search/两条。 - Disallow 与 noindex 混用。有人在 robots.txt 里 Disallow 同时又给页面加
meta robots noindex。问题是:被 Disallow 的页面 Googlebot 根本不会抓取,看不到noindex标签,所以这两个不能叠加用。如果你的目标是"不索引但允许抓取链接",必须用 noindex 而不是 Disallow。 - Sitemap 包含被 Disallow 的 URL。Search Console 会反复报警提示。一定要把 Sitemap 生成器排除搜索页 URL。
- 用了 Cloudflare WAF 的"机器人挑战"。某些 WAF 规则会对
?q=请求触发 JavaScript 挑战,Googlebot 拿到的是 challenge 页面而不是真实搜索结果,本来准备用 canonical 归集权重的方案就失效了。
按站点规模分级的实施清单
不同体量站点的最优解差别很大,保哥按规模划分三档建议:
第一档:单页商品/着陆页类小站(<200 URL)。这种站点根本不需要操心搜索页 SEO,多数就没站内搜索功能。如果用 WordPress 装了搜索小工具,建议直接在 robots.txt 第一行写上 Disallow: /?s= 即可,5 秒钟搞定,不需要后续监控。
第二档:内容/博客/中型电商(200~1 万 URL)。建议方案 A + 简化版方案 D:robots.txt Disallow 通用搜索 URL,对 5~20 个核心关键词手动建静态搜索着陆页。监控指标聚焦在 Search Console 的"已发现-未编入索引"和"含 noindex"两栏,防止误屏蔽。
第三档:大型电商/多语言站点(>1 万 URL)。需要把 4 种方案组合用:robots.txt 屏蔽默认搜索 URL;对带语言/地区前缀的搜索路径单独配置;用 hreflang + canonical 处理多语言重复;同时在生产环境部署日志分析(比如 ELK 抓 Nginx access log)实时观察 Googlebot 行为。这一档建议每月做一次完整的 SEO 健康检查。
与其他参数化 URL 治理的关系
站内搜索 URL 只是参数化垃圾 URL 的一类,真正完整的治理还要覆盖以下几种:
- 追踪参数:
?utm_source=、?fbclid=、?gclid=等。这些不应该被索引但通常需要保留功能,建议在 canonical 里去掉,配合 robots.txtDisallow: /*?utm_。 - 会话参数:老 PHP 站点的
?PHPSESSID=是经典灾难,必须立刻在服务端关掉 URL 重写。 - 排序与筛选参数:
?sort=price_asc、?color=red这类如果都让 Google 收录会产生数倍重复。建议主排序作为 canonical 默认,其他用noindex follow或直接屏蔽。 - 分页参数:
?page=2历来争议大,2019 年 Google 取消了rel="next"/"prev"提示后,多数 SEO 建议是允许分页被索引但 canonical 指回第一页(如果分页内容差异不大)。 - 历史遗留:早期网站迁移留下的
?id=12345类老 URL,建议 301 到对应 slug 化新地址,robots.txt 里同步 Disallow 兜底。
这些 URL 类型各有处理逻辑,但思路一致:"对用户有意义的保留并 canonical 归集,对用户无意义的直接 Disallow",这也是 Google 最认可的参数 URL 治理哲学。
顺手提一点:很多团队把搜索页治理交给开发,开发又不熟悉 SEO,结果 Disallow 的写法和 robots 标签互相冲突,最后 Search Console 报告里出现一堆"已编入索引但已被 robots.txt 拦截"的奇怪状态。保哥的建议是:SEO 同学直接维护 robots.txt 文件并纳入 Git 版本控制,每次改动走 PR 评审,开发只负责把 robots.txt 文件部署到 web 根目录,分工明确才不会踩坑。如果团队规模小,至少每季度对照 Search Console 抓取统计跑一次健康检查,把不该收录的搜索页清理一遍。
常见问题解答
Q1:robots.txt Disallow 之后,已经收录的搜索页 URL 还会保留多久?
Google 会在数周到几个月内自然清理掉这些 URL。如果想加速,可以在 Search Console 里用"删除请求"功能(旧称 URL Removal Tool)批量提交移除请求。注意删除请求只屏蔽 6 个月,超期会重新出现,所以根本上还是要靠 Disallow 持续生效。
Q2:Disallow 和 noindex 到底该用哪个?
看你的目标。Disallow 的本质是"不抓取"——节省爬行预算最有效,但已有反向链接的页面仍可能被收录(无内容快照)。noindex 的本质是"不索引"——爬虫照抓但不展示给用户,适合需要传递内链权重的搜索页。两者不能叠加用,因为 Disallow 之后爬虫看不到 noindex 标签。多数电商独立站推荐 Disallow,知识型/内容型站点可考虑 noindex follow。
Q3:用 canonical 把搜索页指向分类页可行吗?
可行,但前提是搜索页和分类页内容确实近似(商品列表大致重叠)。如果搜索结果是跨多个分类的混合内容,canonical 反而会误导 Google 判断。建议在搜索 URL 里嵌入 category 参数时,根据参数动态决定 canonical 目标;纯关键词搜索 ?q= 形式则直接 Disallow 更简单。
Q4:站点已经因为搜索页太多被 Google 限流了,怎么补救?
第一步立刻在 robots.txt 里 Disallow 所有搜索页路径;第二步通过 Search Console 的"删除请求"批量提交清理;第三步检查站点是否还有其他参数化垃圾 URL(比如 ?utm_source= 类追踪参数被错误索引);第四步重新提交干净的 Sitemap,把高质量页面优先级提上去。整套流程走完,爬虫预算通常会在 4-8 周内回到正常水平。
Q5:Disallow 之后内链权重会不会被浪费?
会有少量损失。Google 在抓取被 Disallow 的页面时不会读取页面内容,自然也不会跟随上面的链接传递权重。如果你的搜索页是站内重要的内链中转节点,建议改用 noindex follow 而不是 Disallow。但实测下来,多数电商独立站搜索页对内链结构并不关键,主导航和分类页才是权重传递主力,Disallow 的代价基本可以忽略。
Q6:Bing 和 Yandex 是不是也认 robots.txt Disallow?
认。Bing 和 Yandex 都遵循 robots.txt 协议,但它们对通配符 * 的解析没 Google 那么宽松。如果你的目标是国际市场(包括俄语、东欧),建议把 Disallow: /*?q= 换成更具体的写法,比如 Disallow: /search/?q=,覆盖率会更稳。
Q7:站内搜索页里有没有可能被 AI 搜索(SGE/AI Overviews)抓取?
2026 年的现状是:Google 的 AI Overviews 和 AI Mode 沿用 Googlebot 索引,Disallow 的页面同样不会被 AI 引用。所以传统的 Disallow 策略对 AI 搜索同样有效。但要注意 OpenAI 的 GPTBot、Anthropic 的 ClaudeBot 等 AI 爬虫各自有独立的 user-agent,需要在 robots.txt 单独声明:User-agent: GPTBot + Disallow: /search。
把这一整套思路落地,站内搜索页在 SEO 维度的"原罪"基本就被驯服了。保哥的最佳实践仍然是优先 Disallow,特殊场景再叠加 canonical 或静态化,下一步如果你的搜索流量还想继续放大,可以参考第八节的长尾词运营框架。
权威参考资料
本文标题:《站内搜索URL该Disallow吗?4种方案对比》
本文链接:https://zhangwenbao.com/should-search-page-urls-be-disallowed-in-robots-txt.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0