电商robots.txt到底该屏蔽哪些页面?这7类加Shopify实操
本文目录
- 必须在 robots.txt 中禁止抓取的 7 类页面
- 购物车、结账和支付页面
- 用户登录和注册页面
- 过滤和排序页面
- 搜索结果页面
- 不必要的参数化页面
- 动态生成的临时页面
- 隐私政策、条款与协议等页面
- 示例的 robots.txt 设置
- 在 robots.txt 禁止这些页面,有没有必要?
- 节约抓取预算(Crawl Budget)
- 避免重复内容问题
- 提升页面质量得分
- 提升用户体验
- 保护隐私和安全
- Disallow vs noindex meta vs canonical 三者的区别
- 各搜索引擎对 robots.txt 通配符的支持差异
- 常见误屏蔽 CSS/JS 的灾难案例
- 是否一定要屏蔽所有这些页面?
- 主流电商平台的默认 robots.txt 模板
- Shopify 默认配置
- WooCommerce 推荐配置
- Magento 2 推荐配置
- PrestaShop 推荐配置
- Shopify 类型网站的 robots.txt 详解
- 什么时候需要手工定制 robots.txt
- 用 Google Search Console 验证 robots.txt 是否生效
- robots.txt 在 CDN 下的缓存陷阱
- 常见问题解答
- 避免禁止任何关键产品或品类页面,以确保重要页面的可见性和流量。
- Disallow 了的页面还会被收录吗?
- robots.txt 改完多久生效?
- 对于包含大量重复参数的 URL,怎么处理更好?
- 子域名的 robots.txt 独立吗?
- 能不能针对不同搜索引擎给不同规则?
- noindex 还能写在 robots.txt 里吗?
- PWA 或 SPA 站点的 robots.txt 有什么特殊?
- 权威参考资料
摘要:电商的robots.txt到底该禁哪些页面?本文先列必须禁止抓取的七类页面和示例配置,再讲Disallow与noindex meta与canonical三者的区别、各搜索引擎对通配符的支持差异、误屏蔽CSS和JS的灾难案例,给出主流电商平台和Shopify类型的默认模板、用GSC验证生效,以及robots.txt在CDN下的缓存陷阱。
在电商网站中,通过 robots.txt 文件来禁止搜索引擎抓取某些页面类型可以提升 SEO 效果。这类页面通常是对用户和搜索引擎不必要或重复的页面,或是可能引起搜索引擎抓取浪费的内容。我从 2018 年开始给独立站电商客户做 SEO 顾问,调过的 robots.txt 不下 100 份,这篇文章把我的全部经验沉淀下来:哪 7 类页面该禁、为什么禁、各电商平台默认配置、误屏蔽 CSS/JS 的灾难案例、以及怎么用 Search Console 验证。
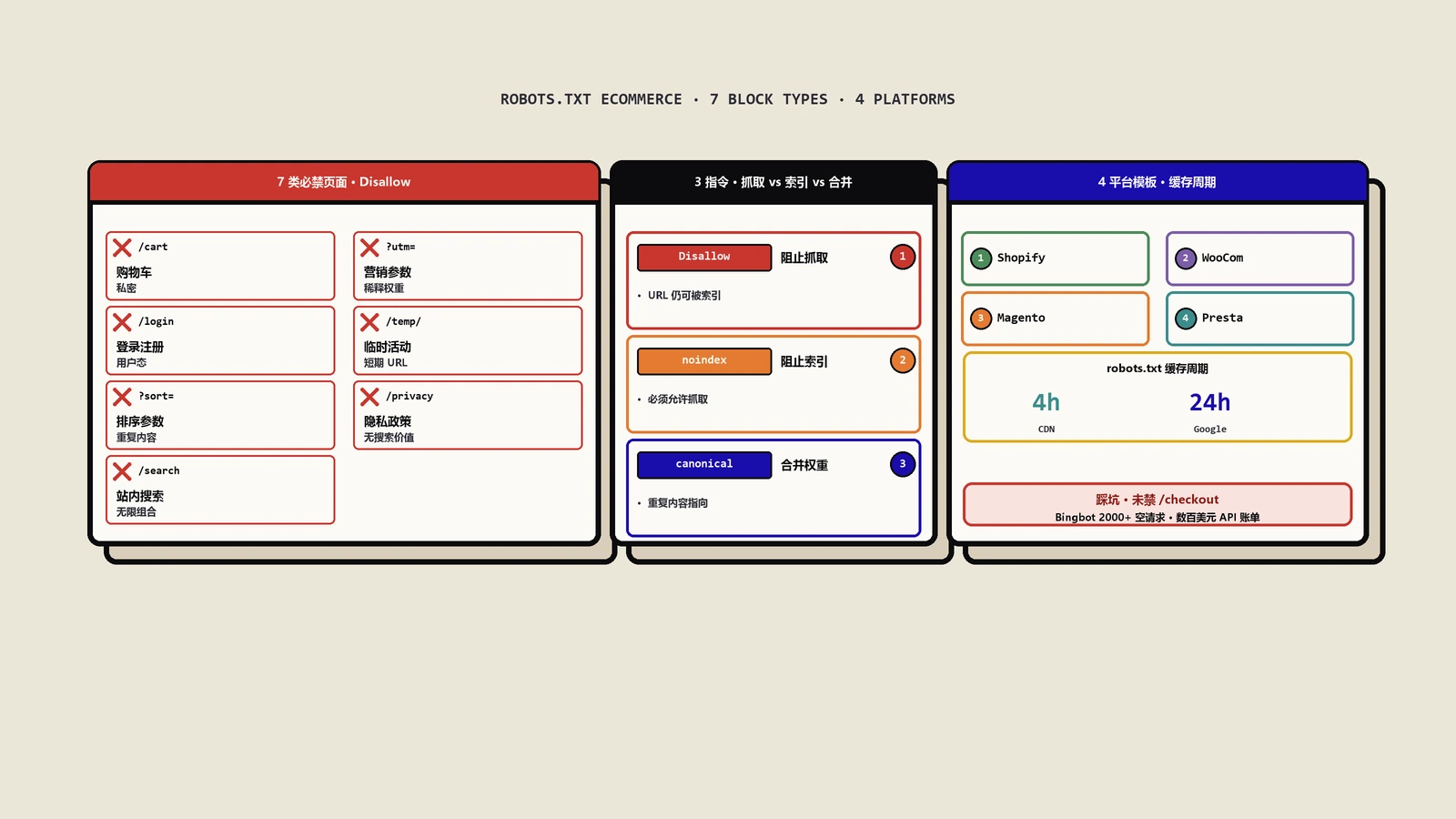
必须在 robots.txt 中禁止抓取的 7 类页面
购物车、结账和支付页面
URL 示例:/cart, /checkout, /payment
这些页面没有对搜索引擎的索引价值,通常是用户购买流程中的隐私页面,因此建议禁止抓取。爬虫真的爬这些页面还可能产生异常事务、占用支付网关 API 配额。我手头一个客户曾经因为没屏蔽 /checkout,被 Bingbot 触发了 2000+ 个空购物车支付请求,账单里多了好几百美元的 Stripe API 调用费。
用户登录和注册页面
URL 示例:/login, /signup, /account
用户登录、注册、个人信息管理页面无索引价值,同时有隐私风险,应禁止抓取。这些页面通常需要 session、cookie 才能正常显示,爬虫拿到的页面也是空壳,没意义。
过滤和排序页面
URL 示例:/category?sort=price_asc, /category?filter=color:red
这些页面可能会导致重复内容问题,因为产品列表的内容会因不同过滤和排序参数产生大量重复页面。一个有 5 个颜色、4 个尺寸、3 种排序方式的电商分类页,组合下来就是 60 个高度相似的 URL,全被收录会严重稀释主分类页的权重。
搜索结果页面
URL 示例:/search?q=
内部搜索结果页面会产生大量重复内容和低质量页面,且这些页面无法为搜索引擎用户提供直接价值,建议禁止抓取。另外搜索关键词如果被恶意构造(搜索"viagra"之类的灰词),那些页面被收录后会让你站点在 SERP 里被识别成垃圾站。
不必要的参数化页面
URL 示例:如带有 ?sessionid=, ?ref=, ?utm_*=, ?fbclid= 等无关 SEO 的参数页面
这些页面通常会因为参数导致重复内容问题,不利于 SEO,建议屏蔽。UTM 参数尤其要小心——Google Analytics 推荐的追踪参数会让同一个落地页因为流量来源不同产生几十个 URL 变体。
动态生成的临时页面
URL 示例:动态生成的临时页面(如促销页面、产品快速浏览页面)
临时或仅用于用户特定交互的页面,无需被搜索引擎索引,可在 robots.txt 中禁止。但注意:黑色星期五大促这类高搜索量的活动页是例外,那种值得专门做 SEO 的临时页要 allow。
隐私政策、条款与协议等页面
URL 示例:/privacy-policy, /terms-of-service
虽然这些页面必要,但它们没有 SEO 价值,不需要在搜索引擎结果中展示。这个建议有争议——Google 在 2022 年 EEAT 算法更新后实际上是把"隐私政策、关于我们、联系方式"这三个页面当作"trust signal"看的,存在反而加分。所以我现在的建议是:让它们被收录但不参与排名(用 noindex meta),别完全 Disallow。下面 Disallow vs noindex 章节有详解。
示例的 robots.txt 设置
User-agent: *
Disallow: /cart
Disallow: /checkout
Disallow: /payment
Disallow: /login
Disallow: /signup
Disallow: /account
Disallow: /search
Disallow: /*?sort=
Disallow: /*?filter=
Disallow: /*?sessionid=
Disallow: /*?ref=
Disallow: /*?utm_source=
Disallow: /*?fbclid=
Disallow: /*?gclid=
# 允许 CSS / JS / 图片被抓取(关键)
Allow: /*.css$
Allow: /*.js$
Allow: /*.svg$
Allow: /*.webp$
Sitemap: https://example.com/sitemap.xml注意三件事:
- Allow 规则放在 Disallow 后面,越具体的越靠前
- 结尾要带 Sitemap 行,告诉爬虫去哪找索引清单
- 千万别 Disallow 整个 /assets/ 或 /static/,那会把 CSS/JS 全屏蔽
在 robots.txt 禁止这些页面,有没有必要?
禁止这些页面的抓取在许多情况下是有必要的,特别是当电商网站规模较大、页面类型复杂时。通过 robots.txt 禁止一些特定类型页面的抓取,能够优化搜索引擎的抓取资源分配,使其专注于高价值页面(如产品页面、分类页等),从而提升整个网站的 SEO 效果。以下是几个关键的原因和考虑因素:
节约抓取预算(Crawl Budget)
对于大中型电商网站,搜索引擎有一定的抓取预算。如果抓取到大量不必要的页面(如搜索、过滤等动态生成的页面),会消耗抓取预算,影响到更重要页面的抓取频率。通过屏蔽这些页面,可以将抓取资源集中在更有价值的内容上。
判断你的站是不是"抓取预算敏感",最直接的办法是看 Google Search Console 的“设置 - 抓取统计信息”报告。一个 200 SKU 的小站,每天大约被抓 100-300 次就够;一个 5 万 SKU 的中型站每天可能要 2 万次以上才能让重要页面 48 小时内被抓到一次。Googlebot 给你的预算不是无限的,按你的"站点健康分"动态分配。
避免重复内容问题
过滤、排序和参数化页面通常会生成大量 URL,这些 URL 虽然内容接近,但可能会被搜索引擎识别为不同页面,从而导致重复内容问题。重复内容会稀释网站的权重,使 SEO 效果降低。禁止搜索引擎抓取这些页面有助于减少重复内容问题。
提升页面质量得分
一些无价值页面(如购物车、结账页面)对用户和搜索引擎都没有独立的价值。这些页面出现在索引中会影响整体页面质量得分,降低网站的 SEO 效果。
提升用户体验
如果不屏蔽无关页面,用户在搜索品牌或关键字时可能会进入购物车、结账或账户页面,这对他们来说不是理想的结果。屏蔽这些页面可以让用户更容易找到更有用的内容(如产品和信息页),提升用户体验。
保护隐私和安全
登陆、账户和支付页面可能包含用户信息或其他敏感数据。这些页面不需要被索引,且抓取这些页面会增加隐私和安全风险。禁止抓取有助于保护用户隐私,减少潜在的安全隐患。
Disallow vs noindex meta vs canonical 三者的区别
这是电商 SEO 里最容易混淆的三个概念。我用一张表说清楚:
| 机制 | 爬虫是否访问 | 是否进入索引 | 是否传递权重 | 典型场景 |
|---|---|---|---|---|
| Disallow(robots.txt) | 否 | 可能进(如有外链) | 否 | 购物车/搜索/过滤 |
| noindex meta(HTML) | 是(要看到才知道 noindex) | 否 | 否 | 隐私政策/条款 |
| canonical link | 是 | 归并到 canonical 上 | 是,归到 canonical | UTM 参数页/过滤页 |
| X-Robots-Tag header | 是 | 否 | 否 | PDF/图片资源 |
| nofollow link | 不阻止访问 | 不直接影响 | 否(链接级别) | 站外链接 |
三大典型组合:
- 纯隐私页(购物车):Disallow 即可。即使被外链指向,索引里也只显示 URL 不显示内容
- 有 SEO 但不要参与排名(条款):noindex meta,让搜索引擎"知道存在但不收录"
- 过滤排序参数页:canonical 指向原分类页,让权重归集
很多人把 Disallow 当万能药,结果导致:"Disallow 的页面我反而看到 SERP 里显示了 URL"——这是因为 Disallow 只阻止抓取不阻止索引。如果外站链了这个页面,Google 依然会把这个 URL 收录进索引,只是没正文摘要。要彻底从索引消失,必须用 noindex(前提是允许抓取才能让爬虫看到 noindex meta)。
各搜索引擎对 robots.txt 通配符的支持差异
| 引擎 | * 通配符 | $ 行尾 | Allow 优先级 | 注释 |
|---|---|---|---|---|
| Googlebot | 支持 | 支持 | 更具体的规则赢 | 2019 年起 robots.txt 协议草案的事实参考实现 |
| Bingbot | 支持 | 支持 | 同 Google | 跟 Google 完全一致 |
| Baiduspider | 支持 | 支持 | 规则先后顺序 | 对中文 URL 支持有 bug,建议都 percent-encode |
| Yandex | 支持 | 支持 | Allow 总是赢 | 有 Clean-param 等独有指令 |
| 360 Spider | 部分 | 不支持 | 规则先后 | $ 行尾匹配不稳,少用 |
| Sogou Spider | 支持 | 支持 | 规则先后 | — |
所以如果你的电商站要面向所有引擎兼容,建议:少用 $ 行尾匹配(360 不支持稳)、Allow 和 Disallow 都从具体到通用排列、中文 URL 用 percent-encode。
常见误屏蔽 CSS/JS 的灾难案例
Google 在 2014 年明确声明:"抓取 CSS 和 JS 是渲染页面必需的,屏蔽会影响 SEO 评分"。但很多电商主题模板的开发者图省事,写出过这种 robots.txt:
# 不要这样写!
User-agent: *
Disallow: /assets/
Disallow: /static/
Disallow: /wp-content/themes/
Disallow: /modules/这种写法会把整个站点的 CSS、JS、字体、图片全部屏蔽,导致 Googlebot 渲染出来的页面是个"裸 HTML"——没有样式、没有交互、布局错乱。最直接后果是移动端友好性评分崩、Core Web Vitals 评分崩、最终影响排名。
正确写法是显式 Allow 静态资源:
User-agent: *
Disallow: /modules/admin/
Disallow: /modules/internal/
# 允许 CSS/JS/字体/图片
Allow: /modules/*.css$
Allow: /modules/*.js$
Allow: /modules/*.woff2$
Allow: /modules/*.png$
Allow: /modules/*.jpg$
Allow: /modules/*.webp$验证办法:用 Google Search Console 的"网址检查 - 测试实际网址"工具,能看到 Googlebot 实际渲染出来的页面截图。如果截图是裸 HTML 没样式,立刻去检查 robots.txt 是不是误屏蔽了 CSS。
是否一定要屏蔽所有这些页面?
有时,根据业务需求和网站情况,可能会选择性屏蔽。比如:
- 规模小的电商网站,页面类型相对简单、抓取预算富余时,可能不需要屏蔽太多页面。
- 个别动态页面(如优惠活动页)如果内容独特、对 SEO 有帮助,也可以允许抓取。
- tag 标签页如果内容质量高(每个 tag 下有 10 篇以上的相关产品),值得 allow 让它做长尾词流量。
在大多数情况下,禁止抓取上述类型的页面是有必要的,尤其对于规模较大的电商网站,通过合理屏蔽,能有效提升整体 SEO 效率和抓取质量。不过,可以根据网站的具体情况来调整 robots.txt 策略,以平衡抓取效率和页面展现需求。
主流电商平台的默认 robots.txt 模板
Shopify 默认配置
从 2021 年起 Shopify 允许通过 robots.txt.liquid 自定义。默认配置已经屏蔽 /admin、/cart、/orders、/checkout、/account、/policies 等。要进一步定制:
{%- comment -%} robots.txt.liquid {%- endcomment -%}
{%- for group in robots.default_groups -%}
{{ group.user_agent }}
{%- for rule in group.rules -%}
{{ rule }}
{%- endfor -%}
# 自定义追加:屏蔽过滤排序参数
Disallow: /collections/*?sort_by=
Disallow: /collections/*?filter=
Disallow: /collections/*?pf_p=
# 屏蔽 tag 页(如果你的 tag 内容质量低)
Disallow: /collections/*/tagged/
{{ group.sitemap }}
{%- endfor -%}WooCommerce 推荐配置
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-content/plugins/
Disallow: /cart/
Disallow: /checkout/
Disallow: /my-account/
Disallow: /?add-to-cart=
Disallow: /*?orderby=
Disallow: /*?filter_*=
Disallow: /*?s=
Allow: /wp-admin/admin-ajax.php
Allow: /wp-content/uploads/
Sitemap: https://example.com/sitemap_index.xmlMagento 2 推荐配置
User-agent: *
Disallow: /catalogsearch/
Disallow: /checkout/
Disallow: /customer/
Disallow: /index.php/
Disallow: /*?p=
Disallow: /*?dir=
Disallow: /*?order=
Disallow: /*?limit=
Disallow: /*?cat=
Allow: /pub/static/
Allow: /pub/media/
Sitemap: https://example.com/sitemap.xmlPrestaShop 推荐配置
User-agent: *
Disallow: /classes/
Disallow: /config/
Disallow: /controllers/
Disallow: /modules/
Disallow: /tools/
Disallow: /translations/
Disallow: /upload/
Disallow: /vendor/
Disallow: /*?orderby=
Disallow: /*?orderway=
Disallow: /*?id_currency=
Allow: /img/
Allow: /themes/*/css/
Allow: /themes/*/js/
Allow: /themes/*/img/
Sitemap: https://example.com/sitemap.xmlShopify 类型网站的 robots.txt 详解
一般来说,Shopify 默认提供的 robots.txt 配置已经能满足大部分商店的需求,涵盖了主要的抓取屏蔽需求,因此绝大多数 Shopify 商店不需要手工定制 robots.txt。Shopify 默认会自动屏蔽一些无关 SEO 的页面(如 /checkout 和账户页面),并合理配置了搜索引擎抓取规则,以帮助商家专注于产品和分类页面的 SEO 优化。
不过,在某些特定情况下,手工定制 robots.txt 可能会对 SEO 产生帮助,比如:
什么时候需要手工定制 robots.txt
网站结构复杂,需要进一步优化抓取预算
对于大型的 Shopify 商店,如果页面数量庞大(比如拥有大量带过滤或排序参数的页面),手工定制 robots.txt 可以进一步优化抓取预算。例如,屏蔽掉带有 ?sort_by= 参数的页面,可以避免重复内容,提高抓取效率。
需要禁止额外的特定页面或目录
有时,商店会创建一些临时页面(如短期促销活动或不对外展示的页面),这些页面可能不会在默认的 robots.txt 中自动屏蔽。如果希望搜索引擎不要抓取这些页面,可以通过手工定制 robots.txt 来禁止抓取。
避免标签页(Tags Pages)被抓取
Shopify 默认允许标签页(如 /collections/all/tagged/tag-name)被抓取。如果标签页产生了大量重复内容,或没有实际 SEO 价值,可以在自定义 robots.txt 中手动屏蔽它们。
屏蔽自定义应用生成的页面
如果商店使用了第三方应用,且这些应用生成了多余的页面或 URL(例如特殊活动页面、动态内容页面),可以通过手工定制 robots.txt 来屏蔽它们,避免不必要的抓取。
用 Google Search Console 验证 robots.txt 是否生效
每次改完 robots.txt 都要验证。三步验证流程:
- 登录 Search Console,进入"设置 - 抓取 - robots.txt 报告"
- 看 Google 缓存的 robots.txt 时间是否更新(缓存通常 24 小时刷新一次)
- 用"网址检查"工具输入一个被你 Disallow 的 URL,应该看到"由 robots.txt 屏蔽"
如果想立即让 Google 重新抓取 robots.txt 而不等 24 小时,可以在 Search Console 里点"请求重新抓取"按钮。
另外推荐两个第三方测试工具:
- technicalseo.com/tools/robots-txt/ - 在线 robots.txt 测试,能逐行模拟 Googlebot 解析
- tame.dev/robots-checker/ - 类似工具,免费且无登录
robots.txt 在 CDN 下的缓存陷阱
如果你的站点用了 Cloudflare、Akamai 或者 AWS CloudFront,robots.txt 会被 CDN 边缘节点缓存。我帮客户改过一次 robots.txt,10 分钟后用 curl 看还是旧版——查了半天发现是 Cloudflare 把 robots.txt 当静态资源缓存了 4 小时。
处理方法:
- Cloudflare:进 Caching - Configuration - Purge Cache - "Custom URL" 输入 https://example.com/robots.txt 手动清
- 原服务器 robots.txt 响应头加 Cache-Control: max-age=300(5 分钟),CDN 自动跟从
- 用 curl -H "Cache-Control: no-cache" https://example.com/robots.txt 绕过 CDN 缓存验证
常见问题解答
避免禁止任何关键产品或品类页面,以确保重要页面的可见性和流量。
这是底线原则。一个常见的事故是:开发把 /collections/ 整个 Disallow 了,结果整个站的分类页全消失。改 robots.txt 前先把要禁的 URL 模式在浏览器手动访问几次,确认它们确实是辅助页面而不是核心商品页。
Disallow 了的页面还会被收录吗?
会。robots.txt 只阻止抓取,不阻止索引。如果有外链指向被 Disallow 的页面,Google 依然会把这个 URL 收录进索引(但因为没抓到正文,SERP 里只显示 URL 不显示摘要)。要彻底从索引移除,必须允许抓取 + 在页面加 noindex meta,或者用 Search Console 的"移除工具"主动申请。
robots.txt 改完多久生效?
Googlebot 在抓站时每次都会检查 robots.txt 是否更新,缓存有效期通常 24 小时。你改完后最长 24 小时后所有爬虫都会按新规则抓。但对已经收录的页面,下次抓取被发现 noindex 或 disallow 才会从索引移除——这个过程可能要 1-4 周。急的话用 Search Console 的"请求重新抓取"主动加速。
对于包含大量重复参数的 URL,怎么处理更好?
Google Search Console 的"参数处理"工具在 2022 年已经下线,现在的最佳实践是:能走 canonical 的全走 canonical,让权重归集到主页;不能用 canonical 的(比如内部搜索)就用 Disallow。UTM 参数特殊:因为对营销追踪必要,建议在主 URL 的 head 里加 canonical 指向无参数版本,让 UTM 参数变体被合并。
子域名的 robots.txt 独立吗?
独立。robots.txt 严格按主机名匹配,blog.example.com 和 www.example.com 各需要一份独立的 robots.txt。多语言子目录(example.com/en/)共用一份;多语言子域名(en.example.com)各一份。Cloudflare Workers 可以让你在不动源站的情况下给不同子域返回不同的 robots.txt。
能不能针对不同搜索引擎给不同规则?
能。在 robots.txt 里写多个 User-agent 块即可:User-agent: Googlebot 后面是 Google 专用规则,User-agent: Baiduspider 是百度专用,User-agent: * 是兜底。每个爬虫只会读匹配它 user-agent 的那个块,不会叠加多个块。这个机制对"国内国外双策略"特别有用:比如百度可以更严格,Google 可以更宽松。
noindex 还能写在 robots.txt 里吗?
不能。Google 在 2019 年 9 月 1 日起停止支持 robots.txt 里的 Noindex 指令。以前有些教程教你写 Noindex: /admin/ 这种,现在已经无效。要 noindex 必须在 HTML head 里写 meta robots,或者在 HTTP 响应头加 X-Robots-Tag。
PWA 或 SPA 站点的 robots.txt 有什么特殊?
SPA(React/Vue 等单页应用)的特殊点:URL 路径都是前端路由,爬虫抓到的可能只是空 div。要么用 SSR(Next.js/Nuxt.js)保证爬虫拿到完整 HTML,要么在 robots.txt 里 allow 所有路径的同时确保 sitemap.xml 列全。另外 PWA 的 manifest.json 和 service-worker.js 默认要 allow 抓取,否则 PWA 评分崩。
权威参考资料
本文标题:《电商robots.txt到底该屏蔽哪些页面?这7类加Shopify实操》
本文链接:https://zhangwenbao.com/page-types-to-block-in-robots-txt-for-ecommerce.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0