noindex和Canonical能同时用吗?9种场景怎么判断
本文目录
- noindex和Canonical的本质区别
- noindex是Google必须执行的硬指令
- Canonical是Google可以选择忽略的软信号
- 两者的根本性差异总结
- 为什么noindex和Canonical不应该同时使用
- 信号冲突给Google发送了自相矛盾的信息
- John Mueller的最终定论:选一个别混用
- 可能产生的实际负面影响
- 不同场景下的正确决策:noindex还是Canonical
- 纯粹的内部重复页面不关心权重传递
- 重复页面有外部链接指向需要传递权重
- 电商网站筛选与过滤器参数页面
- 多语言与多地区站点的区域性重复
- 页面完全消失且需要传递权重的场景
- 决策流程总结
- Google处理noindex页面的技术细节
- 抓取与索引是两个独立的过程
- noindex页面的链接权重会怎样
- 抓取预算的隐性消耗
- follow与nofollow的判断
- nofollow阻止权重传递
- 什么情况用nofollow
- 默认建议用follow
- 2019后nofollow的细分
- X-Robots-Tag HTTP头的高级用法
- HTTP头vs HTML meta优先级
- X-Robots-Tag的独特用途
- canonical也能走HTTP Link响应头,PDF和动态生成页救星
- self-referencing Canonical:容易被忽略的最佳实践
- 实战中常见的canonical和noindex错误
- 对Disallow的页面使用canonical或noindex
- canonical指向了一个noindex页面
- canonical指向了4xx或5xx的URL
- 依赖JavaScript渲染插入canonical
- 跨域canonical使用不当
- canonical成链或闭环,A指B、B指C、C又指回A
- URL大小写、斜杠、参数顺序不一致让自引用退化
- 实操检查清单:确保重复页面处理无误
- 从更宏观的视角看索引控制指令的协同体系
- 常见误区与进阶细节
- 常见问题解答
- noindex和nofollow有什么区别?
- 设了noindex后Google多久会从索引中移除该页面?
- 如果A页面有很多外链,只用noindex不浪费权重吗?
- self-referencing canonical是必须的吗?
- canonical标签放在head里和通过HTTP头返回有区别吗?
- robots.txt中Disallow和meta noindex哪个更好?
- 已经同时用了noindex和canonical,需要立刻改吗?
- 对图片或PDF这类非HTML文件如何使用noindex?
- Canonical主题集群:完整4篇延伸阅读
- 权威参考资料
摘要:noindex和Canonical能不能同时设?本文从指令与信号的本质差异讲起,讲清信号冲突的机制和Mueller的最新立场,按五个常见SEO场景给noindex、Canonical与301重定向的决策框架,再讲self-referencing Canonical这个容易忽略的最佳实践,附五类高频配置错误和八步核对清单。
你的网站有两个页面A和B,内容高度重复。你已经在A页面加了 meta name="robots" content="noindex" ,现在纠结:还要不要在A页面再加一个 link rel="canonical" href="B页面URL" ?
这个问题看起来只需要一句话就能回答——不需要。但如果你只停留在"不需要"这个结论,而不理解背后的原理,那么在面对更复杂的场景时(比如带参数的电商筛选页、多语言站点的区域性重复、CMS自动生成的归档页),你大概率会做出错误的决策。
保哥在做技术SEO审计的这些年里,见过太多网站把noindex和canonical混着用,结果导致权重传递失败、重要页面从索引中消失、甚至整站抓取效率大幅下降。今天这篇文章,会从底层原理到实操决策,把这件事彻底讲透。
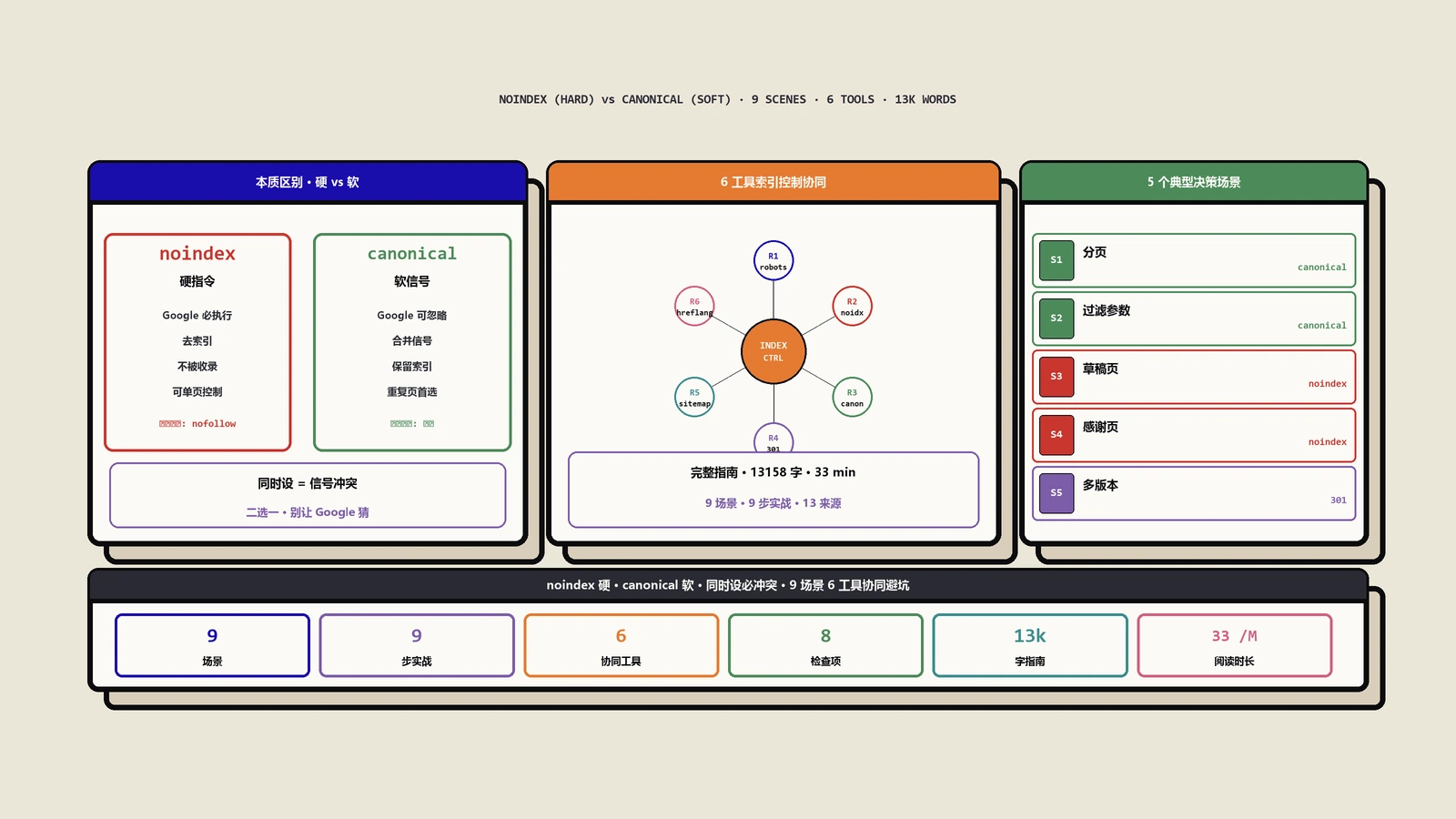
noindex和Canonical的本质区别
在讨论要不要同时使用之前,必须先搞清楚这两个指令各自在做什么。很多SEO从业者对它们的理解停留在表面,这是后续出错的根本原因。
noindex是Google必须执行的硬指令
meta robots的noindex是一条指令(directive),不是建议,不是信号。Google在抓取到这个标签后,必须遵守,不会将该页面纳入搜索结果索引。
noindex的核心作用是从搜索结果中移除页面。它不影响Google是否继续抓取这个页面,也不直接影响Google是否跟踪页面上的链接(默认情况下,Google仍然会跟踪noindex页面上的链接,除非你同时加了nofollow)。
一个关键的技术细节:Google要"看到"noindex标签,就必须先抓取并渲染这个页面。这意味着noindex页面仍然会消耗抓取预算。对于大型网站来说,如果有数万个noindex页面,这个成本是不容忽视的。
Canonical是Google可以选择忽略的软信号
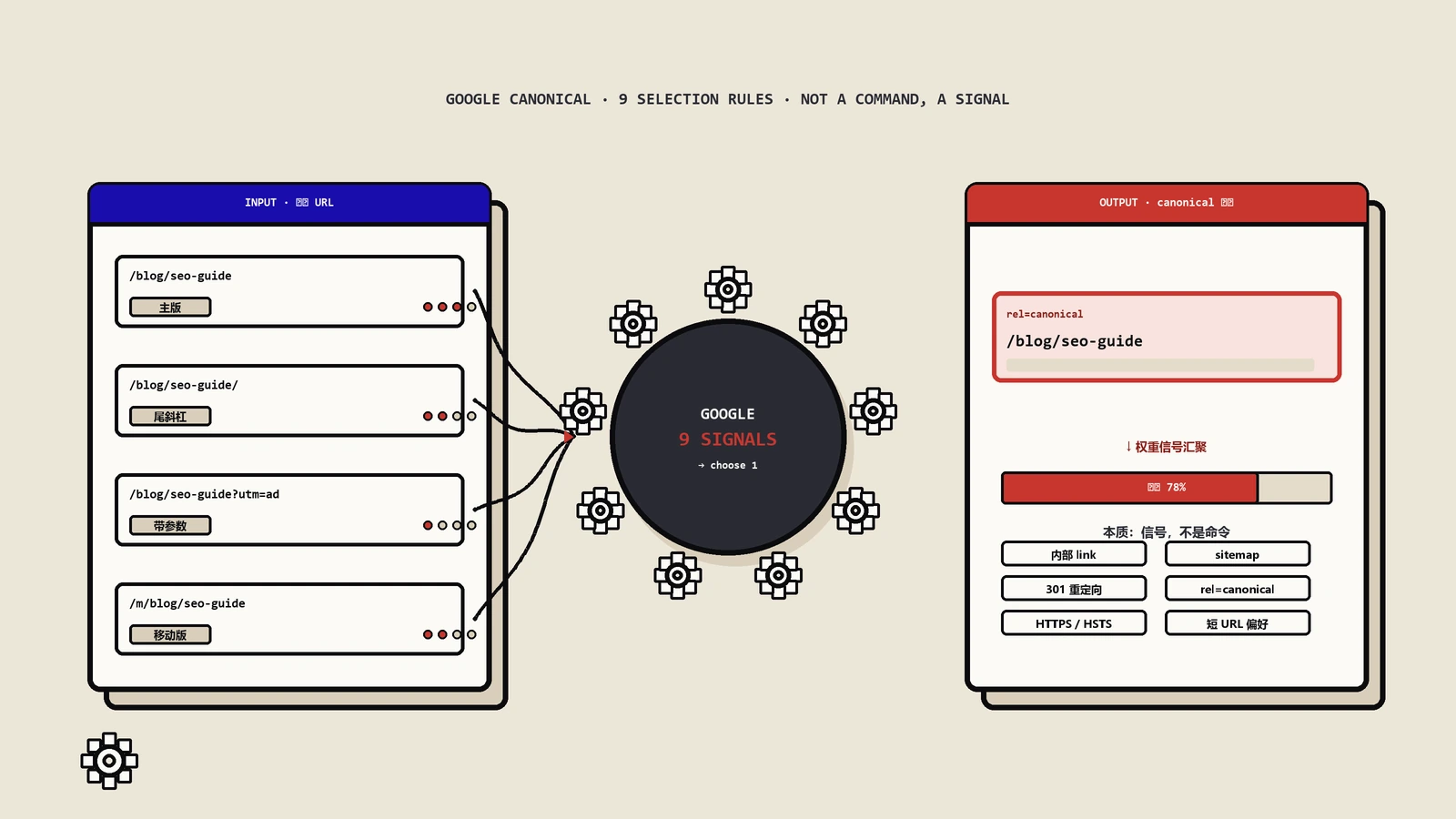
link rel="canonical"是一个信号(signal),是你对Google表达的"偏好"。Google的官方文档明确将其定义为"强信号"而非指令,这意味着Google保留最终决定权。
Canonical的核心作用是合并重复页面的信号。当Google看到A页面的canonical指向B页面时,它会尝试将A页面上的链接权重、锚文本等信号合并转移到B页面上,并优先在搜索结果中展示B页面。
但这里有一个很多人忽略的前提:Google只会在它认为两个页面确实内容相似时,才会遵守canonical指向。如果A和B的内容差异较大,Google完全可能无视你的canonical标签。
两者的根本性差异总结
| 维度 | noindex | Canonical |
|---|---|---|
| 性质 | 指令(directive) | 信号(signal) |
| Google是否必须遵守 | 是 | 否,可被忽略 |
| 核心目的 | 从索引中移除页面 | 合并重复页面信号到首选版本 |
| 对权重的影响 | 不主动传递权重 | 主动合并并传递权重 |
| 对抓取的影响 | 不影响抓取(页面仍被爬取) | 不影响抓取 |
| 适用场景 | 不想让页面出现在搜索结果中 | 有多个相似页面,想指定首选版本 |
为什么noindex和Canonical不应该同时使用
理解了两者的本质区别之后,再来看为什么Google官方明确建议不要同时使用。
信号冲突给Google发送了自相矛盾的信息
当你在同一个页面上同时放置noindex和canonical(指向另一个URL)时,你实际上在对Google说两句矛盾的话:
- noindex说:"不要索引我这个页面。"
- canonical说:"把我当作那个页面的副本,合并我的信号过去。"
问题在于:noindex是指令,canonical是信号。当两者冲突时,Google会优先执行noindex指令。这意味着页面确实不会被索引,但canonical的信号合并功能是否生效,就变成了一个不确定的"也许"。
John Mueller的最终定论:选一个别混用
这个话题在SEO圈里争论了好几年。Google的John Mueller在2021年的Office Hours视频中曾说过"也许可以同时用",这让很多SEO从业者误以为这是被认可的做法。
但在2024年,Mueller在Reddit上给出了更明确的立场:最好二选一,不要混用。他解释了为什么之前说"也许"——因为从技术实现上看,Google确实有可能在处理noindex页面时仍然读取到canonical信号(Gary Illyes在2020年的推文中解释过,noindex页面虽然不会进入服务索引,但抓取副本仍可用于链接图谱计算)。但"有可能"和"可靠地工作"是两回事。
Mueller的原话要点归纳如下:SEO的核心是向搜索引擎传递清晰、一致、确定的信号,而不是依赖"也许"。当你给Google发送矛盾信号时,处理结果就变得不可预测,这是任何严肃的SEO策略都不应该接受的。
可能产生的实际负面影响
同时使用noindex和canonical不仅仅是"没必要",在某些场景下还可能造成实际伤害:
权重传递失败:你本来希望通过canonical把A页面的外部链接权重传递到B页面,但因为noindex优先生效,canonical信号可能被忽略,导致这部分权重白白浪费。
Canonical信号反向污染:极端情况下,如果Google在处理过程中先识别了canonical,再处理noindex,可能会短暂地将noindex信号关联到B页面,虽然概率极低,但理论上存在这种风险。Google的Sitebulb审计工具也会将"canonical指向的目标页面是noindex页面"标记为严重错误。
增加调试复杂度:当网站出现索引异常时,混用信号会让问题排查变得困难。你需要花额外时间去判断是noindex在起作用还是canonical在起作用,还是两者的交互产生了意外结果。
不同场景下的正确决策:noindex还是Canonical
理论讲完了,接下来是实操。面对不同类型的重复页面,到底该用noindex还是canonical?保哥整理了一套完整的决策框架。
纯粹的内部重复页面不关心权重传递
典型例子:打印版页面、测试页面、CMS自动生成的归档页、带追踪参数的URL。
推荐做法:只用noindex。
原因:这类页面通常没有外部链接指向它们,不存在需要传递权重的场景。noindex可以干净利落地将它们从搜索结果中排除,操作简单、效果确定。
重复页面有外部链接指向需要传递权重
典型例子:产品的多个变体URL被外部媒体引用、旧域名页面被引用但已迁移。
推荐做法:只用canonical(或更好的方案——301重定向)。
原因:如果A页面有高价值的外部链接,你的核心诉求是把这些链接权重传递到B页面。这恰好是canonical的强项。用canonical而不是noindex,因为canonical是专门为"信号合并"设计的工具。
但保哥建议,如果技术上可行,301永久重定向是比canonical更优的方案。重定向是服务器层面的指令,比HTML层面的canonical更强、更可靠、更不容易出错。Google也多次表示,重定向是处理URL变更和重复内容的首选方式。
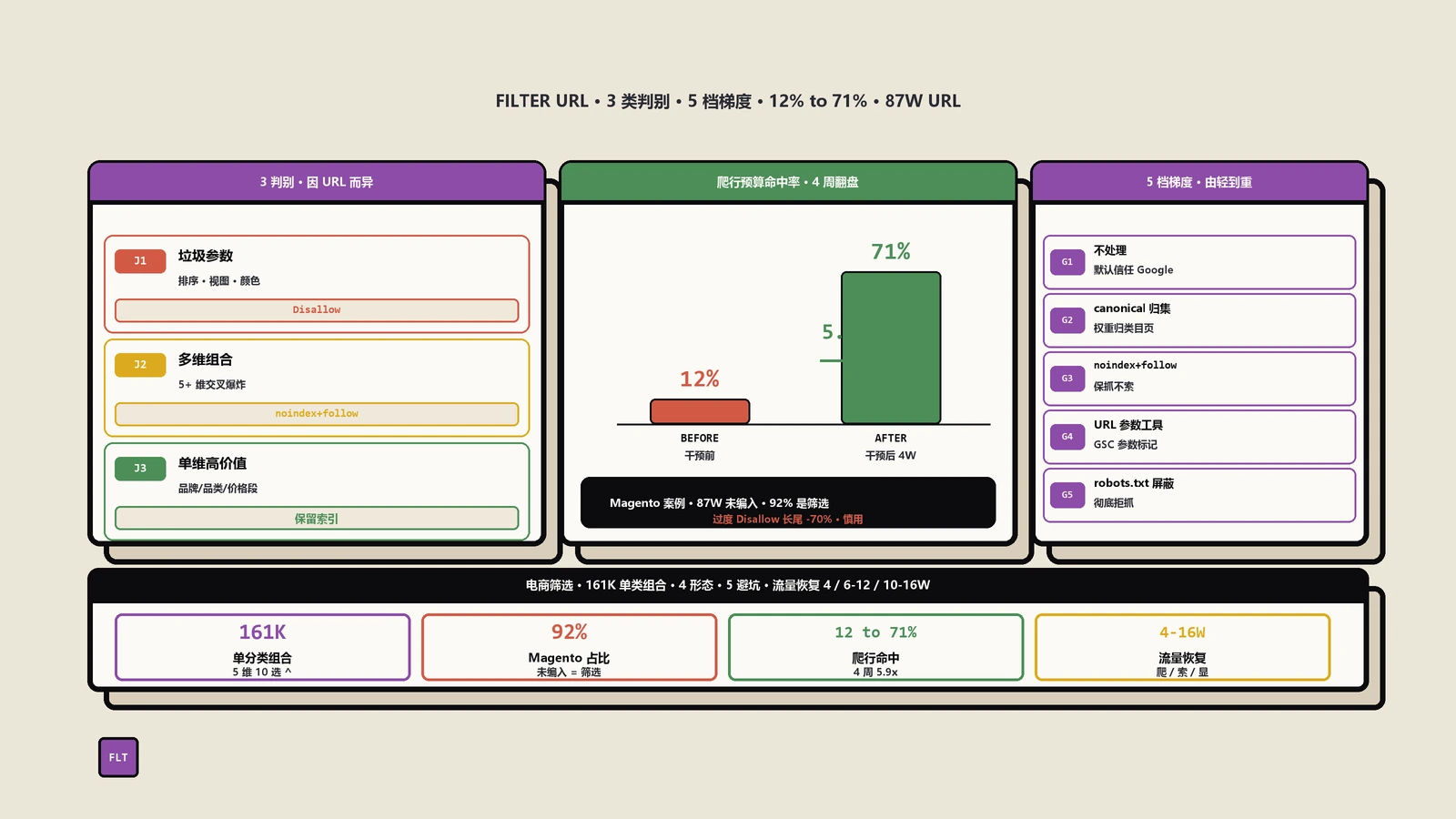
电商网站筛选与过滤器参数页面
典型例子:example.com/shoes?color=red 和 example.com/shoes?color=blue。
这是最常见也是最容易出错的场景。保哥在做电商网站过滤器SEO优化项目时,经常遇到客户把noindex和canonical都加上"以防万一"的做法。
正确做法取决于页面是否有独立的搜索价值:
- 如果 shoes?color=red 有独立的搜索需求(比如"红色运动鞋"有搜索量),应该让它可被索引,设置self-referencing canonical,并优化独立的内容。
- 如果它只是低价值的参数变体,没有独立搜索意义,使用canonical指向主分类页 /shoes 即可。
- 如果参数组合产生了大量无意义的页面(如 ?color=red&size=42&sort=price ),建议在robots.txt中直接禁止抓取这些URL模式,从源头节省抓取预算。
你可以使用robots.txt生成器来快速配置针对参数URL的抓取规则。
多语言与多地区站点的区域性重复
典型例子:英文内容同时出现在 .com 和 .co.uk 上。
推荐做法:使用hreflang标签,配合self-referencing canonical。
原因:这种场景下的"重复"其实是有意为之的区域化内容,不应该用noindex来处理。每个区域版本都应该被索引,用hreflang告诉Google它们之间的关系,再给每个页面加上指向自身的canonical。
页面完全消失且需要传递权重的场景
推荐做法:301重定向。
如果你的目标是"A页面从搜索结果消失"加上"A页面的权重转移到B页面",那么301重定向是唯一能同时满足这两个需求的方案。它比noindex加canonical的组合更可靠、更清晰、Google处理起来也更高效。
决策流程总结
| 你的需求 | 推荐方案 | 不推荐 |
|---|---|---|
| 页面不被索引,不关心权重 | noindex | noindex加canonical |
| 页面不被索引,需要传递权重 | 301重定向 | noindex加canonical |
| 多个相似页面,指定首选版本 | canonical | noindex |
| 页面彻底移除并转移权重 | 301重定向 | noindex加canonical |
| 多语言区域化内容 | hreflang加self-canonical | noindex |
Google处理noindex页面的技术细节
深入理解Google如何在底层处理noindex页面,能帮助你做出更精准的技术决策。
抓取与索引是两个独立的过程
很多人混淆了"抓取"和"索引"。noindex只影响索引,不影响抓取。Google的爬虫Googlebot仍然会定期访问noindex页面,因为它需要:
- 确认noindex标签是否还在(如果你移除了noindex,Google需要知道)
- 发现页面上的链接(默认情况下,Google会跟踪noindex页面上的链接)
- 获取页面内容用于内部计算(如链接图谱)
noindex页面的链接权重会怎样
这是一个技术上非常微妙的问题。Google的Gary Illyes在2020年明确说过:noindex页面虽然不会进入服务索引,但Google保留其抓取副本用于链接图谱计算。
这意味着什么?假设A页面是noindex的,A页面上有链接指向C页面。Google可能仍然会计算这条链接的权重并传递给C。但注意——John Mueller后来补充说,长期被noindex的页面,Google最终会降低甚至停止跟踪其上的链接。
所以,如果你有一个noindex页面,上面有重要的内部链接指向其他页面,长期来看这些链接的权重传递效果会逐渐减弱。这也是为什么对于需要传递权重的场景,301重定向永远是更好的选择。
抓取预算的隐性消耗
每一个noindex页面仍然会被Google定期抓取。对于小型网站来说这不是问题,但对于拥有数十万甚至数百万页面的大型电商或内容网站,大量noindex页面会显著消耗抓取预算。
更高效的做法是:对于确定不需要被Google发现的页面,直接在robots.txt中禁止抓取(Disallow),而不是让Google抓取后再通过noindex告诉它"不要索引"。当然,robots.txt禁止抓取的页面,Google也无法看到你的noindex或canonical标签,所以这三种工具各有适用范围,不能互相替代。
follow与nofollow的判断
nofollow阻止权重传递
noindex标签的第二个参数是follow/nofollow:
noindex,follow:不索引此页,但允许跟随此页面上的链接,传递权重。noindex,nofollow:不索引此页,也不传递权重。等同"权重黑洞"。
什么情况用nofollow
- 页面上的链接指向不可信内容、付费链接、不信任的第三方站点。
- 临时页面或测试页面,明确不希望搜索引擎跟随。
- 用户生成内容区(如未审核的评论区/留言板/用户论坛)。
默认建议用follow
如果没有特殊安全考量,保持follow。这样可以帮助搜索引擎抓取站点结构、理解页面间联系。多数场景用noindex,follow而非noindex,nofollow。
2019后nofollow的细分
Google在2019年把nofollow拆分成三种:
rel="nofollow":通用nofollow,原意。rel="sponsored":广告/赞助链接,明确指出商业性质。rel="ugc":用户生成内容里的链接(评论、论坛)。
新版nofollow被定义为hint not directive——Google把它当参考,不一定完全遵守。但这变化对meta robots的follow/nofollow影响很小,主要影响a标签上的rel属性。
X-Robots-Tag HTTP头的高级用法
HTTP头vs HTML meta优先级
除了<meta name="robots">,还可以用HTTP响应头X-Robots-Tag实现同样的效果:
X-Robots-Tag:noindex,followApache.htaccess配置:
<Files"search.php">Header set X-Robots-Tag"noindex,follow"</Files>Nginx配置:
location=/search{add_header X-Robots-Tag"noindex,follow";}HTTP头的优先级比meta高。当两者并存时HTTP头胜出。
X-Robots-Tag的独特用途
X-Robots-Tag能控制非HTML资源——比如:
- PDF/Word/Excel文档:
<FilesMatch"\.(pdf|doc|xls)$">Header set X-Robots-Tag"noindex"</FilesMatch> - 图片:
<FilesMatch"\.(jpg|png|gif)$">Header set X-Robots-Tag"noimageindex"</FilesMatch> - 视频:
<FilesMatch"\.(mp4|webm)$">Header set X-Robots-Tag"noindex"</FilesMatch>
这些场景meta robots不适用(PDF没有head标签),X-Robots-Tag是唯一选择。
canonical也能走HTTP Link响应头,PDF和动态生成页救星
X-Robots-Tag解决了非HTML资源的noindex问题,很多人不知道canonical也能通过同样的HTTP响应头部署。语法是Link: <https://example.com/canonical-url>; rel="canonical",这条头能告诉Google把当前PDF、Word、动态生成页指向某个HTML首选版本。
实际场景里这一招很救命:白皮书PDF被外站引用产生反向链接,但HTML版本才是你想让Google展示的,HTTP Link头一加,PDF的链接权重就能合并到HTML首选页。Apache配Header set Link "<...>; rel="canonical""、Nginx配add_header Link "<...>; rel="canonical"",写法都不复杂。唯一注意点:HTML link标签和HTTP Link头只用一种,不要两种并发,避免Google解析时两条信号冲突。
self-referencing Canonical:容易被忽略的最佳实践
在讨论A页面该怎么处理的同时,别忘了检查B页面。
B页面应该有一个指向自身的self-referencing canonical标签。这是Google官方推荐的做法,虽然不是强制要求,但它能明确告诉Google:"这个URL就是我内容的首选版本"。
为什么这很重要?因为Google在选择canonical URL时会参考多个信号:页面内容相似度、内部链接结构、站点地图中的URL、HTTPS协议偏好等。如果你不主动指定,Google会自己决定哪个URL是canonical——它的选择不一定是你想要的。
保哥见过不少案例,网站没有设置self-referencing canonical,结果Google把带有URL参数的版本(如 ?ref=homepage )选为了canonical URL。这会导致你精心优化的干净URL反而不被优先展示。你可以使用页面Meta信息检测工具来批量检查网站各页面的canonical设置是否正确。
实战中常见的canonical和noindex错误
对Disallow的页面使用canonical或noindex
如果页面已经被robots.txt禁止抓取,Google根本无法看到页面HTML中的任何标签,包括canonical和noindex。这两个标签在这种情况下完全无效。
如果你需要对已被Disallow的页面传递权重,只有一个办法:移除Disallow规则,让Google能抓取到页面,然后使用canonical或301重定向。
canonical指向了一个noindex页面
如果A页面的canonical指向B页面,但B页面本身有noindex标签,那你就把权重合并到了一个不会被索引的页面上。这是一个非常严重的配置错误,会导致相关内容从搜索结果中完全消失。
canonical指向了4xx或5xx的URL
canonical标签指向的目标URL必须是可正常访问的(返回200状态码)。如果目标URL是404或500,Google会忽略这个canonical声明,并自行决定canonical版本。
依赖JavaScript渲染插入canonical
如果你的canonical标签是通过JavaScript动态插入的,存在Google不能及时渲染并识别的风险。canonical标签应该放在HTML的初始源码中(服务器端渲染),而不是依赖客户端JavaScript。
跨域canonical使用不当
跨域canonical(如从 siteA.com/page 指向 siteB.com/page )是被Google支持的,但只应在两个网站的内容完全相同时使用。如果内容有差异,Google大概率会忽略跨域canonical。
canonical成链或闭环,A指B、B指C、C又指回A
这个坑在大型站和电商站最容易踩,模板嵌套、多套SEO插件叠加、再加上人工临时补的几行canonical,绕来绕去就成了一条环。保哥前段时间帮一个DTC客户排查索引异常,发现产品页指向品牌墙、品牌墙指向促销专题页、促销专题页又指回当初那个产品页,三个URL在Google眼里像三只手互相握住,谁也松不开。
Google对canonical环路的处理很冷酷,整条提示链直接作废,自己挑一个最像“原版”的去索引,剩下两个URL的权重就这么散在风里。修复方法只有一条主轴:用Screaming Frog或Sitebulb跑canonical报告导出闭环检测,把环里的URL用301合并到同一个最终页,再让那个最终页做自引用canonical,三步走链条立刻拉直。
URL大小写、斜杠、参数顺序不一致让自引用退化
很多人以为加了self-referencing canonical就万事大吉,其实没那么简单。Google对URL是字符级敏感的,/Page和/page是两个URL、/home/和/home是两个URL、?a=1&b=2和?b=2&a=1也是两个URL。自引用canonical只要跟当前访问URL差一个字符,Google就判定“这页指向了另一个URL”,自引用瞬间退化成跨URL提示,效果大打折扣。
保哥的固定打法就两步:服务器层用301把所有变体强制统一到标准形(小写、固定带或不带尾斜杠、参数按字母序排),canonical里再写绝对URL并和标准形一字不差。两步做完,自引用才是真自引用,不然就是个看起来像但其实没用的装饰品。
实操检查清单:确保重复页面处理无误
完成noindex或canonical配置后,建议逐项核对以下清单:
- 确认目标明确:你是想让页面从索引消失(用noindex),还是想合并信号到首选版本(用canonical或301)?
- 检查信号一致性:同一页面上不要同时存在noindex和指向其他URL的canonical。
- 验证首选页面的self-canonical:B页面(首选版本)是否有self-referencing canonical?
- 检查robots.txt:目标页面是否被Disallow?如果是,HTML标签无效。
- 验证canonical目标URL状态码:目标URL是否返回200?
- 检查站点地图:noindex的页面不应出现在sitemap.xml中;canonical指向的首选页面应该在sitemap中。
- 在Google Search Console中验证:使用"网址检查"工具,确认Google识别到的canonical URL是否与你设置的一致。
- 监控索引状态变化:配置完成后持续观察2-4周,确认变更生效且无异常。
从更宏观的视角看索引控制指令的协同体系
noindex和canonical只是Google索引控制工具链中的两个环节。要真正做好重复内容管理和抓取效率优化,你需要理解整个体系的协同关系。
如果你想深入了解Canonical URL的完整设置指南和最佳实践,建议阅读保哥之前写的那篇详细教程。
整个索引控制工具链包括:
| 工具 | 层级 | 作用 | Google是否必须遵守 |
|---|---|---|---|
| robots.txt Disallow | 抓取层 | 阻止爬虫抓取页面 | 是(但不阻止索引已知URL) |
| meta robots noindex | 索引层 | 阻止页面进入索引 | 是 |
| X-Robots-Tag noindex | 索引层(HTTP头) | 同上,适用于非HTML资源 | 是 |
| rel=canonical | 索引层 | 指定首选URL并合并信号 | 否(强信号,可被忽略) |
| 301重定向 | 服务器层 | 永久转移URL并传递权重 | 是 |
| sitemap.xml | 发现层 | 帮助Google发现和确认URL | 否(提示,非指令) |
在2026年的Google算法环境下,一个核心原则始终不变:给Google发送清晰、一致、不矛盾的信号。无论你选择哪种工具,都要确保它们之间不产生冲突。当多种工具的信号相互矛盾时,Google通常会执行最严格的那一个,但过程中的不确定性可能带来你意料之外的结果。
除了“是否必须遵守”这一栏,工具之间还有冲突时的优先级序,这个序表里没显示出来但实操中决定一切。保哥的经验序是:301/308重定向 > meta robots noindex 或 X-Robots-Tag noindex > rel=canonical(HTML link标签或HTTP Link头都算)> sitemap里的URL声明 > 内部链接锚文本和指向。
这个序的意义在于:当你给Google同时发出多种信号、又恰好不一致时,Google会按这个顺序从强到弱采纳,越往下越像建议。所以做技术SEO的第一原则其实是让这五层信号从最强到最弱方向一致——重定向、noindex、canonical、sitemap、内部链接都指向你心目中的同一个首选URL。一致到这个程度,Google不需要二次判断,索引效率直接上一个台阶。
常见误区与进阶细节
除了上面讲的明显错误,还有几个容易被忽略的细节值得单独点出来。
把noindex和Disallow当成同义词:许多新手把"不希望某页面出现在Google"等同于在robots.txt里加Disallow。事实是Disallow只是禁止抓取,被禁止抓取的URL仍可能因为外链而显示在搜索结果(只是没有摘要)。要真正不被索引,必须是允许抓取并加noindex,而不是Disallow。
对临时下架页面用noindex而不是410:临时下架的页面用noindex是可以的,但要长时间保持。如果页面已永久下架,用410状态码比noindex更明确——Google对410页面的索引清理速度比noindex快得多。
误把JS渲染当作完全等同于服务端渲染:虽然Google已经能渲染绝大部分JS内容,但延迟是真实存在的。对于canonical这种关键SEO标签,强烈建议放在初始HTML中由服务端输出,避免被JS渲染延迟影响识别。
忽略移动版与桌面版的canonical一致性:移动适配方式不同(响应式、动态分发、独立移动站)会影响canonical策略。响应式无需特别处理;独立移动站必须用canonical+alternate相互声明。错配会导致Google把桌面版和移动版当成两个独立URL。
不监控Google Search Console的Coverage报告:noindex和canonical配置完后必须长期跟踪。Coverage报告会显示"已发现但未索引""已抓取但未索引""Google 选择的规范网址与用户声明的不同"等关键提示。这些都是隐藏问题的信号。
常见问题解答
noindex和nofollow有什么区别?
noindex告诉Google不要将当前页面纳入搜索结果索引,但默认仍会跟踪页面上的链接。nofollow告诉Google不要跟踪页面上的链接或传递链接权重。两者可以单独使用,也可以组合使用(noindex, nofollow),但它们解决的是完全不同的问题——noindex管的是"这个页面是否出现在搜索结果中",nofollow管的是"这个页面上的链接是否传递权重"。
设了noindex后Google多久会从索引中移除该页面?
通常在Google下次抓取该页面时就会处理noindex指令,但从搜索结果中完全消失可能需要几天到几周。具体时间取决于Google对该页面的抓取频率。如果页面很少被抓取,可以通过Google Search Console的"网址检查"工具手动请求重新抓取来加速这个过程。
如果A页面有很多外链,只用noindex不浪费权重吗?
确实可能浪费。noindex不会主动将权重传递给其他页面。如果A页面有高价值的外部链接,最优方案是做301重定向到B页面,这样既能让A从搜索结果消失,又能最大限度地传递链接权重。如果因技术原因无法做重定向,那用canonical(不加noindex)是次优选择。
self-referencing canonical是必须的吗?
从技术角度说不是必须的,Google在没有canonical标签时也能自行判断首选版本。但强烈建议加上。因为如果不主动指定,Google可能选择你不希望的URL版本作为canonical(比如带参数的版本)。self-referencing canonical是一种低成本、高确定性的防御措施。
canonical标签放在head里和通过HTTP头返回有区别吗?
功能上没有区别,两种方式Google都认可。HTML中使用link rel="canonical"适用于常规网页;通过HTTP响应头的Link rel="canonical"形式适用于非HTML资源(如PDF文件)。对于普通网页,建议使用HTML标签方式,因为更易于检查和调试。
robots.txt中Disallow和meta noindex哪个更好?
取决于场景。robots.txt Disallow阻止Google抓取页面,节省抓取预算,但Google可能仍会基于外部链接将URL显示在搜索结果中(只是没有摘要)。meta noindex需要Google先抓取页面才能生效,会消耗抓取预算,但能确保页面不出现在搜索结果中。对于需要彻底从搜索结果消失的页面,noindex更可靠;对于大量无意义的参数URL,robots.txt更高效。
已经同时用了noindex和canonical,需要立刻改吗?
不需要恐慌。同时使用虽然不推荐,但在大多数情况下不会造成灾难性后果——noindex会正常生效,页面不会被索引。只是canonical的信号合并功能可能无法正常工作。建议在下次技术SEO维护时统一清理:如果核心目的是不被索引,保留noindex、移除canonical;如果核心目的是传递权重,改用301重定向。
对图片或PDF这类非HTML文件如何使用noindex?
非HTML资源(如PDF、图片)无法在HTML中插入meta标签,需要通过HTTP响应头返回X-Robots-Tag实现。在服务器配置中加 X-Robots-Tag: noindex 即可让Google不索引该资源。这是处理批量文件不希望被搜索的标准做法。
Canonical主题集群:完整4篇延伸阅读
本文是Canonical主题集群的一部分。如果你想系统理解Canonical标签从基础概念、算法决策、与noindex联动到CMS实现的完整链路,建议继续阅读以下3篇:
- Canonical URL是什么?SEO优化必备的规范网址设置指南——基础概念入门:定义、作用、设置方法,含分页/电商筛选/AMP/PC-移动端/hreflang多场景实操指南。
- Google选择Canonical URL的9大决策逻辑与排查实操指南——Google内部决策机制深度解析:精确重复/部分匹配/URL参数推断/移动端版本/渲染失败等9种场景,附canonical被选错的系统化排查流程。
- Typecho各页面meta robots与canonical SEO规则——Typecho站点的实战代码示例:分页权重稀释、搜索页低质量索引、归档页爬虫预算浪费的差异化处置规则。
权威参考资料
本文标题:《noindex和Canonical能同时用吗?9种场景怎么判断》
本文链接:https://zhangwenbao.com/noindex-canonical-duplicate-page-seo.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0