robots.txt和meta robots什么时候用哪个,别搞反了
本文目录
摘要:robots.txt控抓取、meta robots控索引、X-Robots-Tag控非HTML资源,三件套各管一段、谁也代替不了谁。把控抓取和控索引混为一谈,是出海独立站从Google消失最常见的原因。保哥用这篇文章给一张抓取与索引边界图、所有指令清单、优先级冲突规则、五类高频翻车场景,再配一份亲子启蒙益智玩具独立站12周修复误封的真实SOP,看完你能直接判断自己这套robots到底改不改、改在哪一档。
有些站长把robots.txt当万能锁,以为只要写一行Disallow就什么都拦得住。也有团队把meta robots当占位代码,每个页面都默认贴一句index、follow就完事。两种思路都会出大事。控抓取和控索引在Google系统里走的是两条完全独立的流水线,错配的后果不是细节翻车,而是整个域名或整批商品页直接从搜索结果里消失。
robots.txt和meta robots到底有什么本质区别?
要讲清楚区别,先把搜索引擎处理一个URL的内部流程拆开看。Google对任何一个网址都要走两步:第一步叫抓取(Crawl),就是Googlebot真的去访问这个网址、下载HTML和资源;第二步叫索引(Index),就是把抓回来的内容做分词、向量化、入库、参与排名。这两步是先后串行的,但控制它们的工具是两套不同的东西。
robots.txt控制的是第一步抓取。这个文件放在网站根目录,是Googlebot访问任何页面之前必须先读的一份"准入名单"。文件里写Disallow就等于告诉爬虫"这片路径你别进",爬虫遵守约定就不会访问被禁的URL。但请注意:不让访问,不代表不会出现在搜索结果里。如果有外部网站给被Disallow的页面挂了反向链接,Google可以只凭锚文本和上下文,把这个URL作为无描述的裸链条目放进索引。Search Console里这种情况会显示成"已编入索引,但被robots.txt屏蔽"。
meta robots控制的是第二步索引。它是放在HTML页面head里的一行meta标签,Googlebot必须先抓取页面才能读到这行指令。一旦读到noindex,Google会在下次更新索引时把这个URL从搜索结果里移除。这就引出一个常踩的逻辑陷阱:如果你既在robots.txt里Disallow了一个路径,又在那些页面上加了noindex,Googlebot根本进不去这些页面、读不到meta标签里的noindex,noindex指令就完全失效。要让noindex生效,必须先把Disallow撤掉、让爬虫能抓到页面、读到noindex、再走下一轮去索引。
X-Robots-Tag和meta robots功能一样、用法不一样。它是HTTP响应头里的一行字段,由Nginx、Apache、Cloudflare Worker等服务器或CDN添加,对网页和非HTML文件(PDF、JPG、MP4、JSON)一视同仁。PDF文件、产品图片、下载用的压缩包都没法塞meta标签进去,要控制这些资源的索引行为,X-Robots-Tag是唯一的合规手段。
把三者并排放一张对照表会清楚很多。
| 控制工具 | 管的阶段 | 放在哪里 | 对非HTML资源 | 典型用途 | 翻车后果 |
|---|---|---|---|---|---|
| robots.txt | 抓取 | 根目录文件 | 有效(拦抓取) | 挡爬虫、省抓取预算 | 页面仍可能被裸链入索引 |
| meta robots | 索引 | 页面head标签 | 无效 | 禁HTML页面入SERP | 被Disallow拦住时完全失效 |
| X-Robots-Tag | 索引 | HTTP响应头 | 有效 | 禁PDF、图片、视频入SERP | 配置在错的Location块全站误伤 |
看完这张表就能理解为什么有人在robots.txt里写noindex会被Google无视。Google官方早在2019年9月1日就停止支持robots.txt里的noindex、nofollow、crawl-delay这些非标准指令,理由是robots.txt设计上就只管抓取这一段,混进索引控制语义会把整个协议搞乱。现在还能在网上看到的"robots.txt写noindex"教程基本都是2019年前的老内容,照着抄会被认真打。
robots.txt文件怎么写才不会误封整站?
robots.txt的语法非常简单,但简单恰恰让人轻视。一份标准的robots.txt由若干"规则组"组成,每个规则组以一行User-agent开头,后面跟若干条Disallow、Allow、Sitemap或注释行。基本结构长这样。
User-agent: *
Disallow: /admin/
Disallow: /tmp/
Allow: /admin/help/
User-agent: Googlebot
Disallow: /preview/
Sitemap: https://example.com/sitemap.xml逐条拆指令。User-agent指定这一组规则给哪些爬虫看,星号表示"对所有爬虫",写具体名字(Googlebot、Bingbot、Baiduspider、YandexBot)则只对那个爬虫生效。Disallow列出禁止访问的路径前缀,写斜杠斜杠等于禁整站、写空值等于不禁任何东西。Allow在Disallow覆盖的范围里开一个白名单口子。Sitemap指向XML网站地图的绝对URL,不分User-agent组、放在文件任何位置都行。注释用井号开头到行尾。
路径匹配规则有几条容易踩坑。第一,Disallow:/cart并不只匹配/cart这一个URL,而是匹配所有以/cart开头的路径,包括/cart-policy、/cartoon这种和原意完全没关系的URL。要精确匹配单一URL要写成Disallow:/cart$,美元符号代表路径结束。第二,星号通配可以在路径中间用,比如Disallow:/*?sort=匹配所有带sort参数的网址。第三,路径匹配区分大小写,/Cart和/cart在robots.txt眼里是两个不同路径。
Allow和Disallow冲突时,Google按"匹配字符更长更具体的规则胜出"原则裁决。Disallow:/admin/和Allow:/admin/help/同时存在时,访问/admin/help/setup走Allow、访问/admin/login走Disallow。Bing和百度的部分版本采用"按文件中出现顺序"的策略,跨引擎兼容的稳妥做法是把更具体的规则放在更宽的规则之后。
下面这张表列出robots.txt最常见的指令以及实际命中范围。
| 指令 | 作用 | Googlebot | Bingbot | Baiduspider | 典型用法 |
|---|---|---|---|---|---|
| User-agent | 指定生效爬虫 | 支持 | 支持 | 支持 | User-agent: * |
| Disallow | 禁止抓取路径 | 支持 | 支持 | 支持 | Disallow: /admin/ |
| Allow | 开白名单 | 支持 | 支持 | 支持 | Allow: /admin/help/ |
| Sitemap | 指向网站地图 | 支持 | 支持 | 支持 | Sitemap: https://... |
| Crawl-delay | 抓取间隔秒数 | 忽略 | 支持 | 支持 | Crawl-delay: 5 |
| noindex | 禁索引 | 2019年起忽略 | 不支持 | 不支持 | 请改用meta标签 |
| nofollow | 不跟随链接 | 2019年起忽略 | 不支持 | 不支持 | 请改用meta标签 |
独立站典型场景里该挡哪些路径?后台登录页、未完成的开发页、内部测试用站、用户的购物车和结账流程页、站内搜索结果页、按多维筛选生成的无穷无尽筛选URL、UTM/gclid等追踪参数变体。这些路径要么和搜索意图无关、要么会产生海量重复URL耗光爬取预算、要么会暴露隐私信息。但要注意一个反直觉的事:CSS、JS、图片这些渲染资源一律不能挡。Google渲染网页时需要读到这些资源才能判断布局和移动友好性,挡掉等于让Googlebot看一个残废版本,会拖累整页排名评估。
另一个高频翻车点是放上线那天忘了把开发期的Disallow:/全删掉。开发期间为了不让爬虫抓测试站,很多团队会写Disallow:/挡整站,上线那天忘记删除或没人记得检查,于是新版网站正式上线后Googlebot连首页都进不去、新内容半年也收不进索引。SOP是发布前必须有一项"robots.txt一致性检查"放在Code Review清单里,发布后24小时内用Search Console的robots.txt测试工具复检一遍。如果想系统学习这套协议的底层规则,可以参考robots.txt误封整站消失?协议机制完全指南这篇老文,里头把RFC 9309规范、各家爬虫差异、误封排查流程讲得非常细,能补本文不展开的协议层细节。
meta robots标签的所有指令都在做什么?
meta robots是写在HTML页面head区域的一行meta标签,告诉爬虫这一页该不该入索引、要不要跟随链接、能不能存快照、SERP里答案片段最多展示多长。基本写法长这样。
<meta name="robots" content="noindex, follow">
<meta name="robots" content="index, nofollow">
<meta name="robots" content="noindex, nofollow, noarchive">
<meta name="robots" content="max-snippet:160, max-image-preview:large">
<meta name="googlebot" content="noindex, follow">name属性可以写robots表示对所有爬虫生效,也可以写具体爬虫名(googlebot、bingbot、baiduspider)只对那个爬虫生效。content里多个指令用逗号分隔,不区分大小写。下表给出所有标准指令的含义和触发场景。
| 指令 | 作用 | 对应场景 | 常见误用 |
|---|---|---|---|
| index | 允许入索引 | 默认值,可省略 | 显式写出无意义但不报错 |
| noindex | 禁止入索引 | 购物车、结账、感谢页、低质重复页 | 同时被robots.txt Disallow导致失效 |
| follow | 跟随页面链接 | 默认值,可省略 | 把noindex follow写成noindex单独使用 |
| nofollow | 不跟随链接(页面级) | 论坛、UGC、外链汇总页 | 误把它当链接级rel=nofollow用 |
| noarchive | 禁止显示缓存快照 | 会员墙、付费内容、时效极强的实时数据 | 实质用处随Google关闭快照已大幅缩小 |
| nosnippet | 禁止显示摘要片段 | 极少数严禁内容外泄的合规场景 | 用了等于把自己CTR按死,慎用 |
| noimageindex | 禁止图片入Google Images | 独家产品图、艺术作品防搬运 | 对手仍可重新拍同款,效果有限 |
| nositelinkssearchbox | 禁止SERP生成站内搜索框 | 不希望品牌词SERP暴露搜索入口 | 对大多数站没必要写 |
| unavailable_after | 指定日期后从索引移除 | 促销页、活动页、限时内容 | 日期格式不符RFC 850导致被忽略 |
| max-snippet:N | 限定摘要最大字符数 | 付费墙站想控制免费暴露量 | 设得太小拉低点击率 |
| max-image-preview:[none|standard|large] | SERP图片预览大小 | Discover流量需要large才显示大图 | 留默认standard会错失Discover曝光 |
| max-video-preview:N | 视频预览秒数 | 视频内容需要保留更长预览促点 | 设0等于禁视频预览 |
组合使用是常见模式。比如电商网站的购物车页面写noindex、follow——不让它出现在搜索结果,但允许Googlebot跟着页面内的"继续购物"链接爬回商品列表,不浪费爬取预算。站内搜索结果页通常写noindex、follow——挡掉低质量重复内容,但保留链接传递。会员制内容墙后面的页面可能写noindex、nofollow、noarchive——既不入索引也不传权重也不留快照,三件套全开。
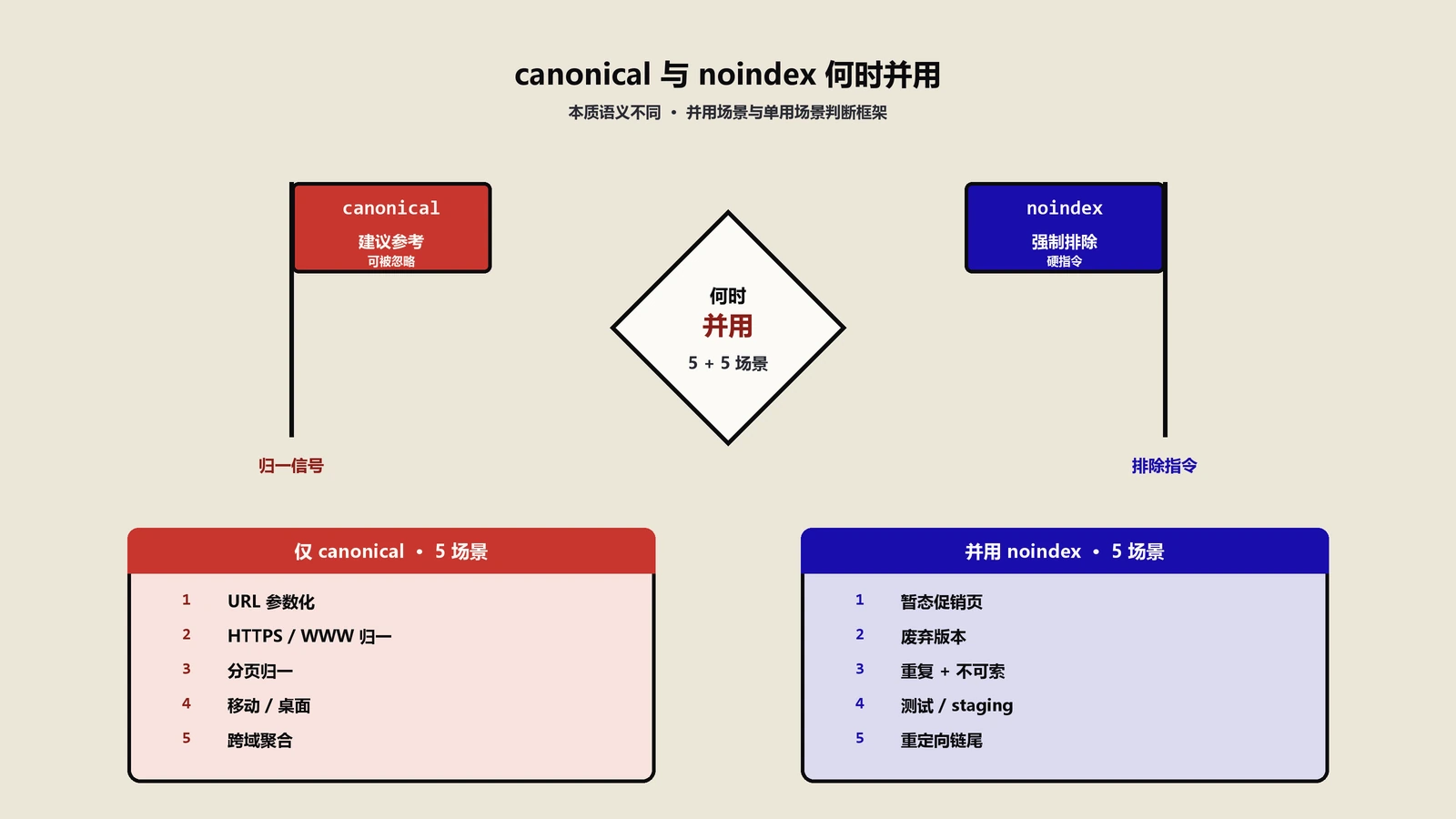
有几个边界要分清。第一,meta robots的nofollow是页面级别,整个页面上所有链接都不传递权重;要对单个链接做nofollow,要写在a标签的rel属性里。第二,noindex和Canonical能不能同时用是另一个高频问题,详细决策树可以看noindex和Canonical能同时用吗?避坑指南,结论是除少数过渡性场景外不要并用,原因是Google对"Canonical指向的目标页面如果是noindex"会陷入解析死循环。第三,CMS层面的meta robots默认值经常被主题或插件覆盖,Typecho、WordPress、Shopify各家的默认逻辑都不一样,详见Typecho各页面meta robots与canonical这篇老文里Typecho各页面类型的默认配置。
X-Robots-Tag HTTP头什么时候非用不可?
X-Robots-Tag是HTTP响应头里的一行字段,由服务器在返回任何资源时携带。它和meta robots的指令完全相同(noindex、nofollow、noarchive等),不同的是它通过HTTP头而非HTML标签传递,所以对非HTML文件(PDF、图片、视频、JSON、压缩包)也生效。这是它存在的核心理由。
典型用法是给特定文件类型批量加索引控制。比如想让所有PDF文件不进Google搜索结果,但又不想在每个PDF上手工修改(PDF本来也塞不进meta标签),最干净的做法是在Nginx配置里加这么一段。
location ~* \.(pdf|doc|docx|xls|xlsx)$ {
add_header X-Robots-Tag "noindex, nofollow" always;
}Apache用户用.htaccess写法类似。Cloudflare Worker、Vercel Middleware、Netlify Edge Functions都能在边缘层注入这个头,对不能改服务器的SaaS站点也适用。下面这张表对比meta robots和X-Robots-Tag的覆盖范围。
| 对比项 | meta robots | X-Robots-Tag |
|---|---|---|
| 放置位置 | HTML页面head | HTTP响应头 |
| HTML页面 | 有效 | 有效 |
| PDF/Office文档 | 无法添加 | 有效 |
| 图片/视频/音频 | 无法添加 | 有效 |
| JSON/XML/RSS | 无法添加 | 有效 |
| 批量配置 | 需逐页改 | 一段规则覆盖整类 |
| 动态条件 | 需CMS层改模板 | 可按UA、IP、查询参数动态设 |
| 排查难度 | 查HTML源码即可 | 需curl -I或开发者工具看响应头 |
什么时候非X-Robots-Tag不可?三种典型场景:第一,发票PDF、合同模板、内部白皮书这种文件不该在Google搜索结果里被外人翻到。第二,独立站产品图被搬到Google Images被竞品做反向溯源,加X-Robots-Tag: noimageindex能堵掉这条线(虽然挡不了对方重新拍)。第三,需要按访问条件动态决定能不能索引——比如同一个URL登录前显示落地页、登录后显示用户面板,可以在中间件层根据Cookie判断、动态注入不同的X-Robots-Tag。
X-Robots-Tag最容易翻车的点是Location块写错位置。如果把"add_header X-Robots-Tag noindex always"误放在站点根Location里,整站所有资源都会带上noindex头,结果是整个域名全部消失。出海独立站这种事故通常发生在凌晨发版后没有人盯HTTP响应头,等运营第二天发现自然流量归零的时候已经损失了12到36小时。修复后还要等Googlebot下一次重新评估,整个动作链通常拉到一两周才完整回稳。
抓取和索引混淆是怎么把流量打没的?
真正让出海独立站掉量的不是单纯写错一行指令,而是把"控抓取"和"控索引"两件事搞混。下面列五类高频翻车场景,每一类都见过不止一次。
场景一:Disallow拦住了想noindex的页面。团队想把购物车页面从SERP移除,于是同时做了两件事——在robots.txt里写Disallow:/cart/,又在购物车页面加meta robots noindex。结果Googlebot根本进不去/cart/路径,永远读不到noindex标签,购物车URL继续以裸链形式出现在Google搜索结果里。修复办法是把Disallow撤掉、让爬虫能抓到noindex、等下一轮索引刷新(通常2到4周)后再视情况决定要不要重新Disallow(绝大多数情况不需要再加)。
场景二:把开发环境的robots.txt带上线了。开发或预发环境写Disallow:/挡整站,发布脚本没区分环境配置,正式站上线后这份禁全站的robots.txt也跟着上去了。Googlebot连首页都进不去,新内容入索引时间无限拉长,几个月后自然流量肉眼可见下滑。SOP是发布管道里加一道robots.txt diff检查,正式环境的robots.txt和预发环境必须有显式差异。
场景三:Allow顺序写反让规则全失效。原意是禁止/admin/但允许/admin/public/,错写成Disallow:/admin/public/和Allow:/admin/,导致Allow的范围反而比Disallow更大,整个/admin/路径意外开放。Google按"更具体的规则胜出"裁决时,错把/admin/public/的Disallow当成更具体的、把/admin/的Allow当成更宽的,结果和你设想相反。
场景四:把CSS和JS也Disallow掉了。有人为了"省抓取预算",把/assets/、/static/、/js/这些路径全Disallow,结果Googlebot渲染页面时拿不到样式表和脚本,看到一个布局塌掉的版本,移动友好性、Core Web Vitals全部判劣。Search Console的网址检查工具里"已渲染HTML"会显示一片空白或样式混乱,这是最直观的信号。
场景五:误以为noindex能阻止外站链入。noindex只控制自己这一页要不要进索引,挡不住别人给你挂链。如果一个页面挂了大量低质外链,光靠noindex不够,还要在源头处理(让对方撤链、用GSC Disavow工具)。把noindex当万能挡链工具是典型的认知错配。
这五种翻车里,场景一最隐蔽——表面看"我两个都做了",实际效果是"两个都没生效"。出海独立站每年都有不止一家踩这个坑。
三种控制方式的优先级到底谁说了算?
当robots.txt、meta robots、X-Robots-Tag三者之间产生冲突时,Google按什么规则裁决?答案不是"谁优先级高",而是"看哪个能被Googlebot真正读到"。这个规则推导出来的结论可能反直觉,但理解它能避开90%的配置陷阱。
核心逻辑只有三句:第一,robots.txt是访问门禁,没过这关的页面,Googlebot根本进不去、读不到meta标签也读不到HTTP头。第二,meta robots要起作用,前提是Googlebot能抓到HTML并解析head区域。第三,X-Robots-Tag要起作用,前提是Googlebot能发出HTTP请求并读到响应头——不需要解析HTML,所以对二进制文件也能生效。
把这三条翻译成日常配置决策,画一张优先级流程图最直观。
| 需求 | 正确做法 | 错误做法 | 错误后果 |
|---|---|---|---|
| 禁HTML页面入索引 | 放行抓取+页面加meta noindex | robots.txt Disallow | 页面仍以裸链出现在SERP |
| 禁PDF入索引 | X-Robots-Tag: noindex HTTP头 | 试图给PDF加meta标签 | PDF不支持meta,操作无效 |
| 省抓取预算 | robots.txt Disallow明显低价值路径 | 用meta noindex省预算 | noindex还是要先被抓到 |
| 禁HTML页面入索引且不传权重 | 放行抓取+meta noindex nofollow | robots.txt Disallow+加noindex | noindex读不到完全失效 |
| 临时下架活动页 | meta unavailable_after指定到期日 | 过期当天再加noindex等下次抓取 | 过期到下次抓取之间继续展示 |
| 整站维护期间 | 返回503状态码+Retry-After头 | 把首页改成维护通知 | Googlebot误以为内容变成纯文字 |
表里"整站维护"那行特别值得注意。临时维护时正确的姿势是HTTP返回503 Service Unavailable状态码并附上Retry-After头告诉爬虫几小时后再来,绝对不能改首页内容、也不能临时全站noindex。前者Googlebot能识别为短期维护、不会动你的索引;后者Googlebot会以为你的内容真的全换了或者主动要求下架,损失基本不可逆。如果维护持续超过24小时,503才会被Google开始按真实下线对待。
出海独立站常见的robots错误有哪些?
除了上面五类抓取与索引混淆,出海独立站还有一些这个语境下特别高频的错误,单独拎出来讲。
错误一:Shopify、WordPress、Wix平台的默认robots.txt直接套用。每个CMS自动生成的robots.txt是为通用场景写的,不一定贴你这个站的实际需求。Shopify默认会Disallow掉/checkout/和/cart/,但不会处理筛选器URL爆炸;WordPress默认对/wp-admin/和/?p=做了基础处理,但插件生成的额外URL要自己加。上线第一周必须人工审一遍robots.txt并按业务实际场景增删。
错误二:多语言子目录或子域名忘记同步robots.txt。站点架构是example.com/en/、example.com/de/、example.com/fr/这种子目录结构时,robots.txt只能放根目录、对所有子目录生效,不能每个语言版本一份。但如果是de.example.com、fr.example.com这种子域名架构,每个子域名要独立放一份自己的robots.txt——很多团队忘了这件事,导致非英文站点的robots.txt默认放行整站。
错误三:测试期间用过的Disallow:/没清理。预发环境、staging环境、测试站点上线后忘记同步robots.txt到正式环境配置,正式站点继续禁全站。这种事故的发现路径通常是2到4周后才看到自然流量崩盘,事后回查才知道根因。
错误四:误把sitemap指令写错协议或写到不可访问的URL。Sitemap指令里URL要写完整绝对路径,包括协议(https://)和域名。Sitemap: /sitemap.xml这种相对路径写法是无效的;Sitemap: http://example.com/sitemap.xml在https站上是无效的(协议必须一致)。
错误五:用robots.txt挡反向链接来源。有团队为了不让"低质量外链来源页"被Google抓到,试图在自己的robots.txt里Disallow别人的域名——这是对协议完全的误解,robots.txt只能控制自己这个域名下的路径,挡不了别的站。要处理低质量反向链接走GSC的Disavow Tool。
每一类错误都对应一条SOP检查项,把检查项做成发布前清单是把翻车率压到接近零的最有效办法。如果想把抓取预算这一块做到极致,详见Google抓取预算优化2026:12项实操指南这篇深文,里头把抓取预算的计算方式、优化策略、监控指标都拆得很细。
GSC报“已编入索引,但被robots.txt屏蔽”要不要管?
有个场景几乎每个上规模的电商站都会撞到:打开Search Console的页面收录报告,突然冒出几万条“已编入索引,但被robots.txt屏蔽”的警告,点开一看全是?add-to-cart=、?orderby=这类动作型参数URL。一个WooCommerce独立站光这一类就能攒出5万条,站长第一反应往往是“糟了,robots是不是写错了”,然后手一抖就想去动那行Disallow。先别动——这恰恰是被误读最多的一条GSC警告。
原理和前面场景一是一回事:robots.txt只挡抓取、不挡索引。这些“加入购物车”的按钮在页面里是带?add-to-cart=参数的普通链接,Google顺着内链发现了这串地址,虽然被Disallow挡着抓不到正文,却照样把这个网址收进了索引——它收进去的是“这个地址存在”这条信息,不是页面内容。
Google官方的robots.txt说明里把这点写得很直白:被robots.txt挡住的网址,只要有别的页面链接到它,仍然可能被编入索引;想真正把页面挡在搜索结果之外,得靠noindex或密码保护这类方法,而不是robots.txt。所以“被屏蔽”和“被索引”同时出现,并不矛盾,是机制使然。
但关键的判断来了:对这种纯动作型URL,正确做法不是照搬场景一去“撤Disallow再加noindex”,原因有三。第一,catch-22绕不开——你得先撤掉Disallow才能让爬虫读到noindex,可一旦放开抓取,这5万条毫无价值的参数URL就会反过来吃光抓取预算,得不偿失。
第二,这些地址几乎不会真出现在搜索结果里:Google官方一贯的说法是,除非有人原样去搜索这一整串URL(真实用户没人这么干),否则它们不会被展示出来。第三,它们本来就不是你想拿排名的页面。所以这条警告在这里是良性的,不是着火点,盯着GSC硬把这个数字清零纯属白费力气。
那要不要彻底无视?也不必。索引是顺着内链进来的,要止血就从内链下手:把加入购物车、排序、筛选这些动作尽量渲染成按钮或POST表单,别用带参数的GET链接明晃晃挂在页面里;实在改不动模板,至少给这些动作链接加上rel="nofollow"当作弱提示,再用爬虫工具把指向参数URL的多余内链揪出来精简掉。源头不再喂,新的参数URL就不会继续往索引里灌,存量也会随着时间慢慢淡出。
把这条警告该不该管收成一句判断:看被屏蔽又被索引的到底是什么页。如果是你本来就想拿排名、却被robots.txt误挡的正经页面,那是真故障,回到场景一撤Disallow加noindex;如果是购物车、排序、会话ID这类零搜索价值的工具URL,留着屏蔽、无视警告、只清内链就行,别条件反射地把GSC每个告警都当成必修题。
保哥见过最贵的robots事故,从来不是“看到警告没去管”,而是“看到警告吓一跳、一把撤掉Disallow”,结果把几万条垃圾URL全放进了抓取队列,抓取预算被掏空、真正的产品页反而排队等抓取。流程永远是先读懂警告、再分清这URL是哪一类,最后才决定要不要动手。
真实案例:出海亲子启蒙益智玩具独立站怎么12周修复robots误封?
保哥去年带过的一个真实案例。客户是个出海亲子启蒙益智玩具独立站,做欧美和澳新市场,主打3到8岁儿童的桌游、拼图、积木、磁力片、感官玩具几个品类,SKU大约600款。上线18个月,自然流量稳定在月均6到8万。然后大改版上线那周,自然流量在14天内掉到月均4000,跌幅超过90%。诊断从robots层入手。
第一周梳理出根因。新主题在开发期间为了不让爬虫抓预发站,技术团队在robots.txt里写了Disallow:/,开发完成时这份禁全站的robots.txt也被一起发到正式环境。同时新主题的产品页模板里因为复制粘贴自一个会员墙模板,默认在head里加了meta robots noindex、follow,所有商品详情页全部带noindex上线。两个错误叠加,整站不仅大部分页面被禁抓取,少数能被抓到的也被强制不索引。Search Console里"提交但未编入索引"的URL数量在三天内从40涨到580,"已抓取尚未索引"也涨到200多。
第二到三周做修复动作。robots.txt先回到上线前版本,只保留Disallow:/cart/、/checkout/、/account/、/search、/wp-admin/这些明确不该抓的路径。产品页模板里把meta robots noindex改回index、follow,分类页保留为index、follow,购物车结账页改为noindex、follow。同时在GSC里给主分类页和热门商品页一个个手工提交"请求索引",加速重新评估。整改完后立刻用GSC的网址检查工具把改动验证一遍,确保"已抓取的HTML"和"已渲染HTML"两个视图里robots配置都正确。
第四到六周观察。Googlebot重新抓取整站需要时间,索引覆盖率报告里"有效"页面数从最低谷的120缓慢回升到280、450、620。自然流量同步从月均4000涨到1万、2万、3万8。这阶段的失败模式是有团队成员看到流量恢复不够快、忍不住改其他不该改的东西,反而引入新问题。这阶段的纪律是只盯robots相关KPI、所有其他SEO动作冻结,避免污染观察口径。
第七到九周做加固。整理一份robots.txt SOP,包括每月一次GSC robots报告人工审核、发布前必跑robots diff检查、新增页面类型必须先评审meta robots默认值。同时给Nginx加上X-Robots-Tag控制,PDF和发票文件全部带noindex头,独立站产品图加noimageindex防被反向溯源。X-Robots-Tag的Location块写完后用curl -I把每一类资源都验一遍,避免误伤其他正常HTML。
第十到十二周收尾。自然流量回到月均5万8左右,离改版前的6到8万还差一档但已稳定回升。索引覆盖率"有效"页面回到改版前的水位(780),"已编入索引但被robots屏蔽"从最高的50多降到接近0。复盘清单里写了7条新增SOP,团队约定任何涉及robots、meta robots、X-Robots-Tag的改动从此走双人Review、有专门的回滚预案。
整件事的根因不复杂,但暴露的是发布纪律——开发环境的禁抓取配置和模板模板的默认值这两件事都没有人盯,叠加之后就是一次彻底灾难。这种案例过去四五年见过不止一家,模式高度一致,提早做robots SOP就是省下12周抢救期。
怎么验证robots设置没翻车?
设置完不验证等于没做。下面是一份完整的验证清单,新人也能照着做。
第一步,robots.txt语法验证。Search Console的"robots.txt测试工具"(旧版GSC里还能用,2023年后主GSC界面里被弱化但仍可访问)能逐行解析你的robots.txt并标红语法错误。另一个免费工具是Google官方开源的robots.txt parser,可以本地跑、贴文件内容自动语法检查。
第二步,单URL测试。对你最关心的页面(首页、热门分类页、热门商品页)用GSC的"网址检查"工具逐个跑一遍。它会显示"是否被robots.txt允许抓取"、"已抓取的HTML源码"、"已渲染HTML"、"覆盖率状态"、"如何被发现"五个维度的诊断。任何一项异常都直接告诉你哪里错了。
第三步,HTTP响应头检查。对涉及X-Robots-Tag控制的资源,用curl命令行验证响应头。比如curl -I https://example.com/whitepaper.pdf应该返回X-Robots-Tag: noindex;curl -I https://example.com/正常页面则不应该有这个头。Chrome开发者工具Network面板里也能看每个资源的响应头,但curl更便于批量验证。
第四步,索引覆盖率监控。GSC的"网页"报告里"已编入索引"、"未编入索引"、"已抓取但未编入索引"、"已编入索引但被robots屏蔽"四个分类要每周看一次。任何一类的URL数量在一周内异常飙升都是预警信号。出海独立站推荐把这四个数字接到内部Dashboard做趋势监控,比每周手工查省很多事。
第五步,noindex生效时长跟踪。给页面加了noindex之后,从加上到真正从SERP消失通常要几天到几周——具体取决于Googlebot重抓该页的频率。这段时间内可以用site命令行查询验证页面是否已被移除,也可以在GSC的URL检查里看覆盖率状态变化。
把这五步做成发布前必跑、发布后24小时复检的固定动作,robots翻车几乎可以归零。保哥见过的所有大规模误封事故,回头看都是这五步里至少有两步被跳过。
常见问题解答
robots.txt里写了Disallow,Google还会把页面放进搜索结果吗?会。Disallow只是阻止抓取页面内容,但如果有外部链接指向该页面,Google可能只凭锚文本就把网址列入索引,显示成无描述的裸链结果。要真正不出现在SERP,必须放行抓取并在页面上加noindex。
在robots.txt里写noindex能用吗?不能。Google官方早在2019年9月就停止支持robots.txt中的noindex指令,现在写进去会被无视。控制索引只有meta robots noindex标签或者X-Robots-Tag HTTP头这两种合规方式。
PDF或图片这种非HTML文件怎么禁止索引?用X-Robots-Tag HTTP响应头,在Nginx或Apache配置里给.pdf或.jpg等扩展名追加X-Robots-Tag: noindex头。这是唯一对非HTML资源生效的标准方式,meta标签写不进二进制文件里。
已经写了noindex的页面,多久会从Google消失?通常需要Googlebot再抓一次该页确认到noindex后才会移除,时长从几天到几周不等。如果之前用Disallow拦着抓取,要先把Disallow撤掉让爬虫读到noindex,否则就会一直留在索引里。
Allow和Disallow写冲突时谁优先级更高?匹配字符更长更具体的规则胜出。比如Disallow:/admin/和Allow:/admin/help同时存在时,访问/admin/help路径Allow生效,其他/admin/路径继续被禁。Bing和百度部分版本按写入顺序判断,跨引擎稳妥的做法是把更具体的规则放在更宽的规则之后。
User-agent写星号通配,robots.txt里的Crawl-delay对Googlebot生效吗?不生效。Googlebot明确说过Crawl-delay指令一律忽略,要调整抓取频率得在Search Console的旧版抓取速率设置里改或者交给Google自适应。Bing、Yandex、百度部分情况下会读Crawl-delay,但对Google来说这行就是装饰。
robots.txt是不是越严越好?不是。过严会把CSS、JS、图片这些渲染资源也拦掉,Googlebot无法完整渲染页面就会按一个残废的版本评估内容质量,反而拉低排名。原则是只挡真正没价值的页面,渲染资源全放行。
结语
robots.txt、meta robots、X-Robots-Tag这三件事在搜索引擎技术栈里像三层不同的门:robots.txt是大门、meta robots是房间门、X-Robots-Tag是保险柜门。每扇门都有自己负责的边界和钥匙,混用钥匙就开不了门。出海独立站做大改版、换主题、换平台、做多语言扩展的时候,这三件事永远应该提前一周做一次预演、上线后24小时内做一次复检,把翻车窗口压到最小。把这套流程做扎实,比追逐任何高深SEO技巧都更能保住基本盘。
权威参考资料
本文标题:《robots.txt和meta robots什么时候用哪个,别搞反了》
本文链接:https://zhangwenbao.com/robots-txt-and-meta-robots.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0