电商过滤器SEO实战:5类参数处理对比
本文目录
- 过滤器引发 SEO 问题的根本原因
- 5 类过滤参数与对应处理方案
- 第 1 类:高搜索量长尾词参数(应索引)
- 第 2 类:中等价值参数组合(条件性索引)
- 第 3 类:低价值组合(应 noindex 或 canonical 合并)
- 第 4 类:排序参数(应 robots.txt 屏蔽或合并)
- 第 5 类:营销跟踪参数(应忽略)
- 过滤器 URL 静态化的两种实现
- 方案一:服务端路由 + 重写规则
- 方案二:前端路由 + 后端去重
- 实战治理记录:从 240 万抓取/月降到 60 万
- 治理前的问题诊断(第 1 周)
- 治理动作(第 2-8 周)
- 治理后的数据(第 12 周)
- JavaScript 渲染的过滤器对 SEO 的影响
- 陷阱 1:URL 不变,只用前端状态过滤
- 陷阱 2:URL 变了但是 SSR 没跟上
- 多面筛选(faceted navigation)的高级问题
- 组合参数的索引策略
- 参数顺序的归一化
- "清空所有筛选"按钮的行为
- 什么时候应该完全砍掉过滤器
- 过滤器面包屑、Schema与结构化数据
- 面包屑结构化数据
- ItemList 结构化数据
- CollectionPage Schema
- 过滤器与分面搜索(faceted search)的实现细节
- 常见问题解答
- 过滤器页面到底要不要 noindex?
- 静态 URL 与查询参数 URL 哪个对 SEO 更好?
- 用 robots.txt 屏蔽过滤器参数好还是用 noindex 好?
- 为什么我做了 noindex 之后过滤器页面还出现在 Google 搜索结果里?
- 过滤器 URL 的内部链接应该用 nofollow 吗?
- 分页(pagination)和过滤器是同一类问题吗?
- 过滤器治理后多长时间能看到 SEO 效果?
- 权威参考资料
摘要:电商分类过滤器怎么做SEO?本文按高搜索量长尾、双维度组合、三维以上、排序、营销跟踪五类参数给不同处理方案,再讲URL静态化的两种实现、JS渲染的SSR陷阱、分面筛选的高级问题、什么时候该完全砍掉过滤器,附BreadcrumbList与ItemList结构化数据和从月240万抓取降到60万的治理记录。
电商分类页的过滤器(filter / facet)是 SEO 与产品体验冲突最严重的地方之一。它对用户来说是必备工具——没有过滤器的女装频道一万件商品全堆一页,没人愿意逛;它对 SEO 来说却是双刃剑——一个 5 维筛选模块(品牌×价格×尺码×颜色×风格)理论上能展开成几十万个 URL,搜索引擎抓取预算瞬间被耗光,却很可能没有一个 URL 拥有原创内容。这篇文章基于我自己运维过的两个跨境女装站(每月 SKU 5 万-12 万)和一个国内母婴垂直站点的实际数据,把过滤器的 SEO 处理策略拆成 5 类参数处理方案,给出"哪些索引、哪些 noindex、哪些 canonical 合并、哪些直接 robots.txt 屏蔽"的可执行决策树,并附上一份让 Googlebot 抓取预算显著下降的过滤器治理实战记录。
过滤器引发 SEO 问题的根本原因
过滤器之所以是 SEO 麻烦制造者,不在过滤器本身,而在它生成的 URL 形态。绝大多数电商系统采用查询参数实现过滤,比如/dresses?brand=zara&color=black&size=m&price=100-300。这种设计带来三个连锁问题:
第一,URL 数量爆炸。如果每个维度有 10 个枚举值,5 个维度独立组合就是 10⁵ = 10 万个 URL,而真正能产出有效内容的可能只有几百个(很多组合下商品数为零或者商品数太少)。Googlebot 看到这个站会被参数迷宫困住,浪费抓取预算在低价值页面上,重要的产品详情页迟迟得不到抓取。
第二,内容近似重复。同一类目下,"?color=red"和"?color=blue"的页面除了商品列表筛选结果不同,标题、面包屑、模板文案、Hero Banner 全部相同。Google 的去重算法会把绝大多数这种页面合并为单一 cluster,只索引其中一个 URL,其他 URL 浪费了抓取与索引配额却拿不到任何排名价值。
第三,参数顺序与重复参数。?color=red&size=m与?size=m&color=red是同一个内容的两个 URL;?color=red&color=blue有的系统返回交集有的返回并集;?utm_source=...&utm_campaign=...这种营销参数同样会衍生新 URL。Googlebot 对这些参数异化的容忍度有限,处理失误会导致权重稀释。
5 类过滤参数与对应处理方案
过滤器参数按照 SEO 价值差异大致可分为 5 类,每一类的处理方式完全不同,把它们混在一起用同一种策略是大部分电商站的通病。
第 1 类:高搜索量长尾词参数(应索引)
典型例子:品牌×大类、品牌×价格段、风格×大类。具体如/dresses/zara、/iphone-case/under-50、/dresses/floral。这类组合对应着真实用户的搜索查询("zara连衣裙"、"50元以下手机壳"、"碎花连衣裙"),月搜索量从几百到几万不等,应该被索引并独立优化。
处理方式:转成静态化 URL(不要用查询参数);为这些页面生成独立的title、meta description、h1,模板里加一段 200-500 字的"该筛选条件下的精选商品介绍 + 选购建议"原创内容;建立从主分类页到这些组合页的内部链接(女装首页放"按品牌选购"、"按价格段选购"两个矩阵);提交到 sitemap。
第 2 类:中等价值参数组合(条件性索引)
典型例子:双维度组合且每个维度都有较高商业价值,但商品池较小或搜索量中等。如/dresses?brand=zara&color=black。处理方式有两种:
方案 A:转静态 URL 并加内容(前提是该组合月搜索量>100、商品数>20)。
方案 B:保留查询参数,按 Google Search Console 实际数据决定——如果该组合在 GSC 里有展现量、点击量,则放到 sitemap 让其被索引;如果连展现都没有,就加noindex。
这一类的关键是动态决策,不要预先全部索引也不要全部 noindex,而是用数据反馈调整。
第 3 类:低价值组合(应 noindex 或 canonical 合并)
典型例子:3 维以上组合(?brand=zara&color=red&size=m)、过窄的商品池(<5 件商品)、生僻颜色或尺码组合。这类页面长尾词搜索量极低或为零,但每个组合都吃抓取预算。
处理方式:
方案 A:URL 上保留过滤器参数(前端用户能正常用),但页面 head 里输出<meta name="robots" content="noindex,follow">,让用户能用、爬虫不索引。follow很重要,告诉 Googlebot 顺着页面内的链接继续爬,不要因为 noindex 就放弃发现链接。
方案 B:用<link rel="canonical" href="主分类页 URL">把权重合并回主分类页,相当于告诉搜索引擎"这个 URL 是主分类页的另一种视图,请把权重算到主页面去"。
两种方案的区别是:noindex 让低价值页面不进入索引但仍然吃抓取(Googlebot 还是要抓一遍才知道是 noindex);canonical 也吃抓取,但权重会传递到 canonical 目标页。canonical 比 noindex 更优,因为它不浪费内部链接结构。
第 4 类:排序参数(应 robots.txt 屏蔽或合并)
典型例子:?sort=price-asc、?sort=popularity、?orderby=date_desc。排序参数生成的 URL 与不带参数的主分类 URL 内容完全一致(只是商品顺序不同),SEO 价值为零。
处理方式:直接在 robots.txt 屏蔽:Disallow: /*?sort=、Disallow: /*?orderby=。Googlebot 看到这条规则就不会抓这些 URL,比 noindex 更彻底(noindex 还要抓一次)。
注意:robots.txt 屏蔽 + canonical 不能同时使用——Googlebot 不抓页面就看不到 canonical 标签。所以排序参数应该走 robots.txt 屏蔽这一条路;如果你怕 robots 屏蔽错了某些有价值排序,也可以改用 canonical 方案,但效果略差。
第 5 类:营销跟踪参数(应忽略)
典型例子:?utm_source=...&utm_campaign=...、?fbclid=...、?gclid=...。这些参数纯粹是 GA、Facebook、Google Ads 的归因跟踪,不影响页面内容。
处理方式:在 Google Search Console 旧版的"参数处理"工具里告诉 Google "这个参数不影响内容"(虽然该工具从 2022 年起部分功能退役,但很多老站点配置仍然生效);新版 GSC 里用 canonical 把所有带参数的 URL 都 canonical 到不带参数的版本;同时在 robots.txt 不要屏蔽(Googlebot 需要抓取后才能看到 canonical)。
过滤器 URL 静态化的两种实现
静态化 URL 是把/dresses?brand=zara变成/dresses/zara,对 SEO 与用户体验都有好处。两种实现方式各有适用场景。
方案一:服务端路由 + 重写规则
这是大型电商站(Shopify Plus、Magento 2、Salesforce Commerce Cloud)的常用方案。后端识别 URL 模式/{category}/{filter},重写为/category-page?cat={category}&filter={filter},由统一的分类页控制器处理。Nginx 配置示例(已用 HTML 实体替代尖括号防解析):
location ~ ^/dresses/(zara|hm|uniqlo)$ {
rewrite ^/dresses/(.*)$ /category.php?cat=dresses&brand=$1 last;
}
location ~ ^/dresses/under-([0-9]+)$ {
rewrite ^/dresses/under-(.*)$ /category.php?cat=dresses&price_max=$1 last;
}优点:URL 干净、可读、对 SEO 与用户都友好。缺点:需要预先列出哪些 filter 值要静态化(不可能所有 filter 组合都列出),需要后端代码与运营配合维护。
方案二:前端路由 + 后端去重
SPA 风格的 React/Vue 电商前端常用方案。前端 router 识别/dresses/zara路径,调用 API 获取数据,渲染页面。后端要做的是为搜索引擎提供 SSR 或预渲染版本(用 Next.js、Nuxt 的 SSR 或 Prerender.io 服务),保证 Googlebot 看到的是含完整内容的 HTML。
优点:架构现代,与传统电商后台解耦。缺点:SEO 风险较大,SSR 不到位会被 Googlebot 看作空白页面,必须严格测试每个静态化路径在 view-source 里都能看到完整内容。
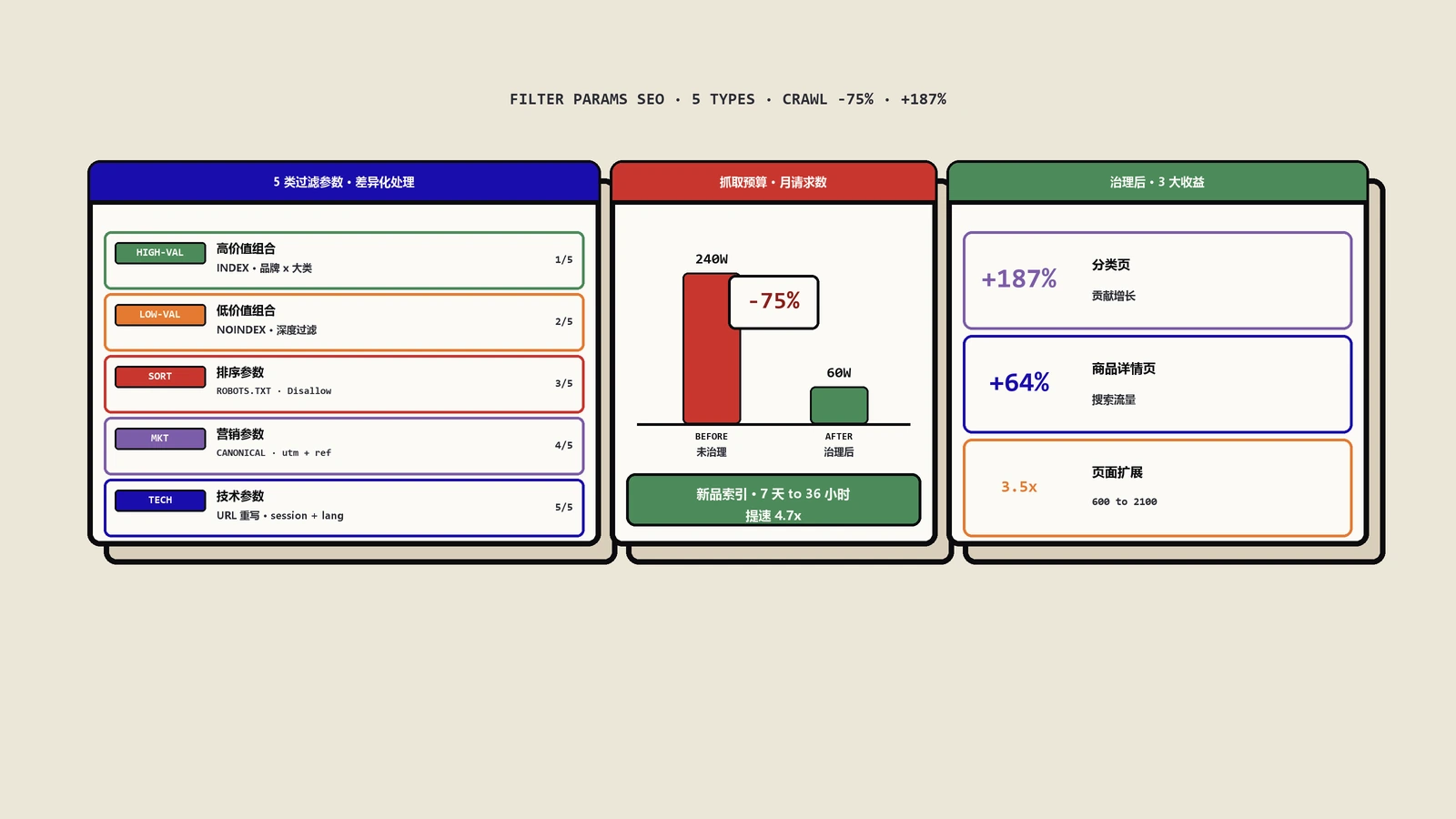
实战治理记录:从 240 万抓取/月降到 60 万
2024 年我接手过一个跨境女装站,做了为期 3 个月的过滤器治理,过程与数据如下,可以作为参考。
治理前的问题诊断(第 1 周)
从 GSC 抓取统计与日志分析得到:
- Googlebot 月抓取量:240 万次
- 主分类页 URL 数:87 个
- 商品详情页 URL 数:5.2 万
- 过滤器衍生 URL 数:通过参数组合估算约 38 万
- 排序参数衍生 URL 数:约 15 万
- 营销参数衍生 URL 数:约 8 万
- 实际被索引 URL 数:仅 3.7 万(其中过滤器页面只占 600 个)
结论:240 万抓取里大约 180 万消耗在了无价值的过滤器页面与营销参数页面上,5.2 万商品详情页平均每月只被抓 1-2 次,许多新上架商品 7 天后还没被索引。
治理动作(第 2-8 周)
第 2 周:robots.txt 屏蔽?sort=、?orderby=、?per_page=三类参数,立即砍掉 25 万次/月抓取。
第 3-4 周:把?utm_*、?fbclid、?gclid等营销参数加 canonical 指回不带参数的页面,同时在 GSC 旧版参数工具里把这些参数标记为"不影响内容"。
第 5 周:选出 240 个高价值组合(品牌×大类、价格段×大类、风格×大类),转静态 URL 并加独立 SEO 字段;其他所有 3 维以上的过滤组合全部加noindex,follow。
第 6-7 周:建立"高价值组合矩阵页"——在每个主分类页底部加一个 6×8 的表格,列出本分类下 48 个高价值过滤组合的链接,引导 Googlebot 优先抓这 48 个 URL。
第 8 周:在 sitemap.xml 里只列主分类页 + 高价值组合页 + 商品详情页,过滤器中低价值页面全部不在 sitemap 里。
治理后的数据(第 12 周)
- Googlebot 月抓取量:60 万次(下降 75%)
- 商品详情页平均抓取频率:从 1-2 次/月升到 6-8 次/月
- 新商品被索引耗时:从 7 天降到 36 小时
- 有自然流量的过滤器页面数:从 600 升到 2100
- 分类页与过滤器页贡献的有机流量:增长 187%
- 商品详情页有机流量:增长 64%(受益于抓取与索引速度提升)
JavaScript 渲染的过滤器对 SEO 的影响
2024 年起,越来越多的电商站把过滤器做成"前端无刷新"形式,点击品牌不刷新页面,只调用 API 更新商品列表与 URL。这种用户体验更好,但 SEO 上有两类陷阱。
陷阱 1:URL 不变,只用前端状态过滤
有些前端实现是点击过滤器后不修改 URL,只在前端维护过滤状态。从 SEO 视角这是灾难——所有过滤组合根本不存在 URL,搜索引擎完全看不到。要解决这个问题,必须让过滤器同步更新 URL(用history.pushState()),让每个过滤组合都有可访问的 URL。
陷阱 2:URL 变了但是 SSR 没跟上
更常见的情况是过滤器修改 URL(history.pushState()到/dresses/zara),但服务端没有为/dresses/zara这个路径配置渲染——直接访问该 URL 返回空白模板,要等前端 JS 加载并调用 API 才填充内容。Googlebot 在 2024 年虽然支持 JS 渲染,但渲染队列延迟可达数天,且渲染失败率不低(CPU 限制、超时、依赖外部资源失败)。
解决方案是确保所有静态化的过滤器 URL 都有 SSR:用 Next.js 的getStaticPaths+getStaticProps预生成、或者用 Vercel/Netlify 的 ISR 增量再生、或者部署 Prerender.io 这类预渲染中间件。验证方法是在 Chrome DevTools 里开"Disable JavaScript"访问过滤器 URL,看是否能看到商品列表与原创介绍——能看到才说明 SSR 到位。
多面筛选(faceted navigation)的高级问题
多面筛选指用户可以同时选择多个维度(品牌+颜色+尺码同时勾选),而且每个维度内还可以多选(同时选红色和黑色)。这种设计 UX 上是必备,但 SEO 上引入了新的难题。
组合参数的索引策略
对于多选场景?color=red,blue或?color=red&color=blue,建议直接 noindex——因为用户可以"红色"或者"黑色"独立搜索,但很难有人搜"红色 OR 黑色连衣裙"。把多选组合页面索引出去只会稀释单色页面的权重。
参数顺序的归一化
后端在生成 canonical 时要保证参数顺序固定(比如按字母排序)。?brand=zara&color=red与?color=red&brand=zara必须 canonical 到同一个 URL,否则两个 URL 在 Google 索引里被视为独立页面,互相竞争。
"清空所有筛选"按钮的行为
前端的"清空所有筛选"按钮应该把用户带回不带任何参数的主分类 URL(/dresses),而不是/dresses?这种带空问号的 URL(部分前端框架默认这样实现)。空问号 URL 会被 Googlebot 视为新 URL 抓取一次。
什么时候应该完全砍掉过滤器
不是所有电商站都需要复杂的过滤器。如果你的店铺符合下面任意一条,过滤器复杂度应该往下砍:
- SKU 总数 < 300(用户翻页就能看完,过滤器是过度设计)
- SKU 高度同质化(如纯色 T 恤店,颜色之外没什么可筛选的)
- 团队没有持续维护 SEO 的人力(过滤器治理是长期工作,没人维护就会重新失控)
- 商品流转极快(SKU 平均生命周期 < 30 天,索引出去也很快下架,浪费)
反过来,符合下面条件的店铺应该精心做过滤器 SEO:
- SKU > 5000,同时存在多个品牌或多个价格档
- 商品具有"风格"、"场景"、"功能"等非数值维度(女装、家具、户外装备)
- 有专人或外包团队负责 SEO 内容生产
- 客单价较高,有机搜索带来的高意图流量价值高
过滤器面包屑、Schema与结构化数据
很多电商团队做过滤器治理时只盯着 robots 与 canonical,忽略了结构化数据。其实结构化数据是过滤器页面与普通分类页拉开排名差距的关键。
面包屑结构化数据
静态化后的过滤器页面应该输出完整的BreadcrumbList JSON-LD。例如/dresses/zara/under-300这个 URL,面包屑应该是"首页 → 女装 → 连衣裙 → ZARA → 300元以下"。每一级都是一个有效的内部链接,让 Googlebot 顺着面包屑往上发现更高层级的分类页,同时让面包屑出现在 Google SERP 上提升点击率。BreadcrumbList 与itemListElement的position从 1 开始计数,最后一个层级的item可以省略 URL(表示当前页面)。
ItemList 结构化数据
过滤器页面本质是商品列表页,输出ItemList结构化数据让搜索引擎理解每一项是商品。每个ListItem引用一个Product,Product 包含name、image、price、aggregateRating等字段。Google 在 SERP 上会把这种结构数据渲染成"商品轮播"组件,显著提升 CTR。注意 Google 对 ItemList 的最大长度限制是 30 条,超过的部分会被截断,所以 ItemList 里只放当前页的商品(即第一页 24-30 件),不要把全部分页的商品都列进去。
CollectionPage Schema
过滤器页面整体可以标记为CollectionPage类型,与普通分类页用同一类型。注意不要用WebPage这种通用类型——CollectionPage 给 Google 的信号更精确。CollectionPage 内嵌 BreadcrumbList 与 ItemList 是当前的最佳实践。
过滤器与分面搜索(faceted search)的实现细节
很多团队搞混"过滤器"与"分面搜索"。过滤器是用户预先定义的几个维度(品牌、颜色、尺码);分面搜索是从搜索结果反推可用筛选项(系统统计搜索结果里有哪些品牌、哪些颜色,动态生成 facet)。两者的 SEO 复杂度完全不同。
预定义过滤器(filter)只有几个固定维度,URL 模式可控,相对容易治理。分面搜索(facet)的 facet 是搜索词触发后才生成,URL 会出现"/search?q=连衣裙&brand=zara&color=red"这种形态——一个搜索词配合 N 个 facet,URL 数量是搜索词数 × facet 组合数,比预定义过滤器爆炸得更厉害。所以分面搜索页面应该全站 noindex,不参与索引。
有些电商把搜索结果页伪装成分类页(比如把/search?q=连衣裙静态化为/dresses-search),试图获取搜索 SEO 流量。这种做法 Google 在 2024 年明确表态属于"site search results 不应索引"的违规,会触发手动惩罚。所以即使你想为搜索结果页拿排名,也应该确保通过站内的真实分类页和过滤器组合页拿,不要伪装搜索结果。
常见问题解答
过滤器页面到底要不要 noindex?
分情况。高价值组合(品牌×大类、价格段×大类、风格×大类)应该索引并优化为静态 URL;中价值组合用数据决策(GSC 显示有展现量就索引,无展现量就 noindex);3 维以上组合、生僻属性组合全部 noindex,follow;排序参数与营销参数走 robots.txt 或 canonical 处理。一刀切的全索引或全 noindex 都不对,前者吃抓取预算,后者放弃了所有长尾流量。
静态 URL 与查询参数 URL 哪个对 SEO 更好?
静态 URL 更好,但前提是真正高价值的组合才静态化。把所有过滤组合都静态化反而会因为"URL 数量太多 + 内容相似"被 Google 视为薄内容站点。理想形态是:高价值组合(30-300 个)做静态 URL;其他组合保留查询参数加 noindex。这样既享受了静态 URL 的关键词与可读性优势,又不让 URL 总数失控。
用 robots.txt 屏蔽过滤器参数好还是用 noindex 好?
排序参数与营销参数用 robots.txt(彻底不抓,省抓取预算);内容过滤参数用 noindex(让 Googlebot 抓但不索引,仍可发现内部链接);如果想合并权重用 canonical(同样需要 Googlebot 抓取才能看到 canonical 标签)。三种工具的成本是 robots.txt < noindex < canonical,按抓取预算紧张程度选择。
为什么我做了 noindex 之后过滤器页面还出现在 Google 搜索结果里?
有两个原因。第一,noindex 生效需要 Googlebot 重新抓取一次该页面看到 noindex 标签后才会从索引里移除,对于低频抓取的页面这个过程可能持续数月。可以在 GSC 用"网址移除工具"加速移除某些 URL。第二,确认页面的 robots meta 是否真的生效——有些 CMS 与 CDN 在缓存层不会更新页面 head,noindex 标签写了却没下发。用curl -I或浏览器查看 view-source 验证。
过滤器 URL 的内部链接应该用 nofollow 吗?
不应该。过滤器内部链接 nofollow 是 2010 年代流行的"PageRank Sculpting"思路,2009 年 Matt Cutts 已经声明 Google 把 nofollow 的链接权重当作"丢失"而不是"重分配",nofollow 只会损失权重不会节约权重。正确做法是过滤器内部链接保持 dofollow,但页面本身用 noindex,follow——让 Googlebot 顺着链接发现更多页面,又不让低价值过滤页本身进入索引。
分页(pagination)和过滤器是同一类问题吗?
不完全是,但处理思路相近。分页(?page=2、?page=3)从 SEO 视角通常应该 self-canonical(每一页 canonical 到自己),而不是全部 canonical 到第一页——否则深层商品(只在第 5 页出现)的链接发现就被切断了。Google 在 2019 年弃用了rel=prev/next标签的支持,所以现在分页的最佳实践是 self-canonical + 在第一页 noindex 后续页面(如果你不希望 page=2 等被索引)。但与过滤器不同的是分页几乎不存在"组合爆炸"问题,处理压力小很多。
过滤器治理后多长时间能看到 SEO 效果?
分阶段。第 1-2 周:抓取量下降明显(robots.txt 与 noindex 立即生效);第 4-6 周:商品详情页索引速度提升(受益于抓取预算重新分配);第 8-12 周:高价值过滤页流量上涨(Googlebot 重新评估这些页面的内容质量与排名);第 12-24 周:整体有机流量增长稳定。如果治理 3 个月后没有可观测的提升,要回头检查是不是 URL 重写、SSR 渲染、sitemap 提交、内部链接矩阵某一环出了问题。
权威参考资料
本文标题:《电商过滤器SEO实战:5类参数处理对比》
本文链接:https://zhangwenbao.com/ecommerce-category-page-filters-seo-tips.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0