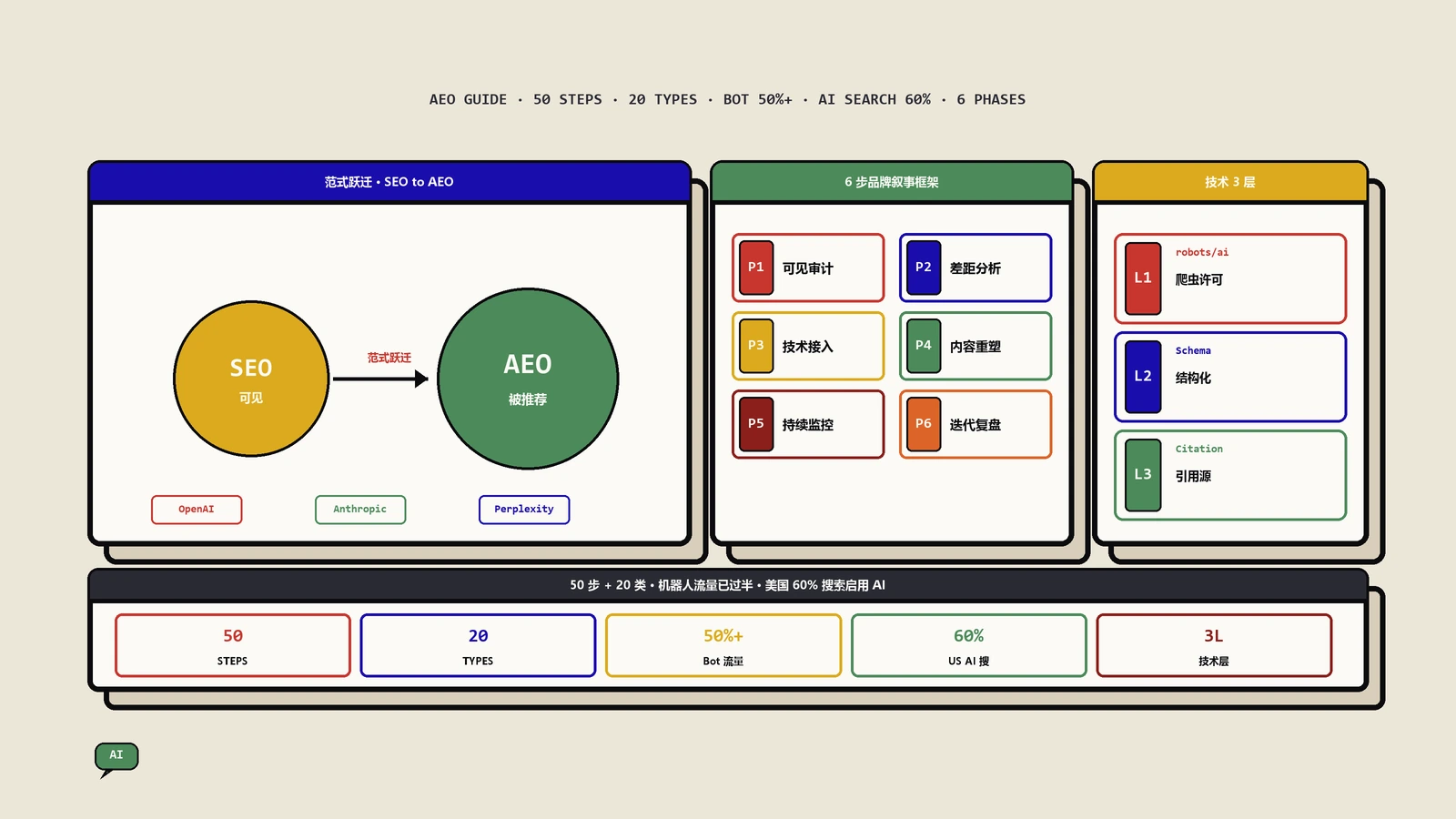
AEO优化从被看见到被AI推荐:三层框架加六步行动
本文目录
摘要:AEO答案引擎优化已是AI搜索时代的必备技能。本文先讲搜索范式正从SEO转向AEO、品牌要回答的四组关键问题,再解析AI爬虫的训练与索引与检索三种类型、做AI差距分析的三套方法、网站对AI不可见的四大根因,给从可见到被推荐的三层技术框架和掌控品牌叙事的六步行动框架。
如果你还在用传统SEO的思维来理解网站优化,那么你可能已经落后了一个时代。今天,当用户在ChatGPT中提问"哪个项目管理工具最适合远程团队"、在Perplexity中搜索"2026年最好的CRM系统"、或者直接在Google搜索结果页顶部阅读AI Overview生成的摘要时——背后真正在阅读你网站内容、判断你品牌价值、并决定是否向用户推荐你的,不是人类,而是AI爬虫。
这不是未来的趋势,这是正在发生的现实:当前超过50%的网站流量已经来自机器人,其中AI爬虫(如GPTBot、Google-Extended、PerplexityBot等)占据了越来越大的份额。据统计美国已有约60%的网络搜索启用了AI功能。本文将带你理解AI爬虫到底如何看待你的网站,为什么你的网站可能对AI完全不可见,以及一套完整的AEO(Answer Engine Optimization,答案引擎优化)实操方案。配套阅读 Schema结构化数据对AI搜索有用吗的官方与实测数据,能补全本文的Schema侧验证。
搜索范式正在从SEO转向AEO
AI搜索平台不是简单地给你一个链接——它们在替用户解读你的品牌。这就像一场传话游戏:AI需要猜测和填补的空白越多,最终传递给用户的信息就越偏离你的本意,你的竞争对手也就越容易在你关心的查询中抢占先机。
在传统SEO中,品牌最关心的核心问题是"我们的排名如何"。而在AEO时代,核心问题变成了"AI在如何谈论我们"。这不仅仅是措辞上的变化,而是底层逻辑的根本转变。SEO关注的是搜索引擎结果页(SERP)中的位置和点击率;AEO关注的是AI生成内容中的品牌可见性、准确性和情感倾向。
品牌需要回答的四组关键问题
在AEO语境下,每个品牌都需要系统性地审视以下问题:
- 可见性层面:当用户向AI平台提出与品牌相关的问题时,品牌是否会出现在回答中?是被提及还是被引用?在回答中处于什么位置——是首选推荐还是补充选项?
- 准确性层面:AI对品牌的描述是否准确?产品功能、定价、定位是否与实际一致?是否存在过时或错误信息?
- 竞争力层面:与竞争对手相比,AI是否更倾向于推荐竞争对手?竞争对手的哪些内容策略在影响AI的回答?
- 溯源层面:AI在回答中引用的信息来源是什么——是你自己的网站、竞争对手的网站,还是第三方评测站?
可以把AI搜索想象成一场传话游戏:你的网站是信息源头,AI爬虫是中间传递者,最终用户是接收者。中间环节越多、理解越模糊,信息失真的概率就越大。这意味着品牌必须确保内容本身足够清晰明确,内容的技术交付方式对AI友好,AI不需要猜测或脑补就能准确获取你要传达的核心信息。
AI爬虫的三种类型与主要清单
并非所有AI爬虫的行为模式都一样。理解它们的分类,是制定正确策略的前提:
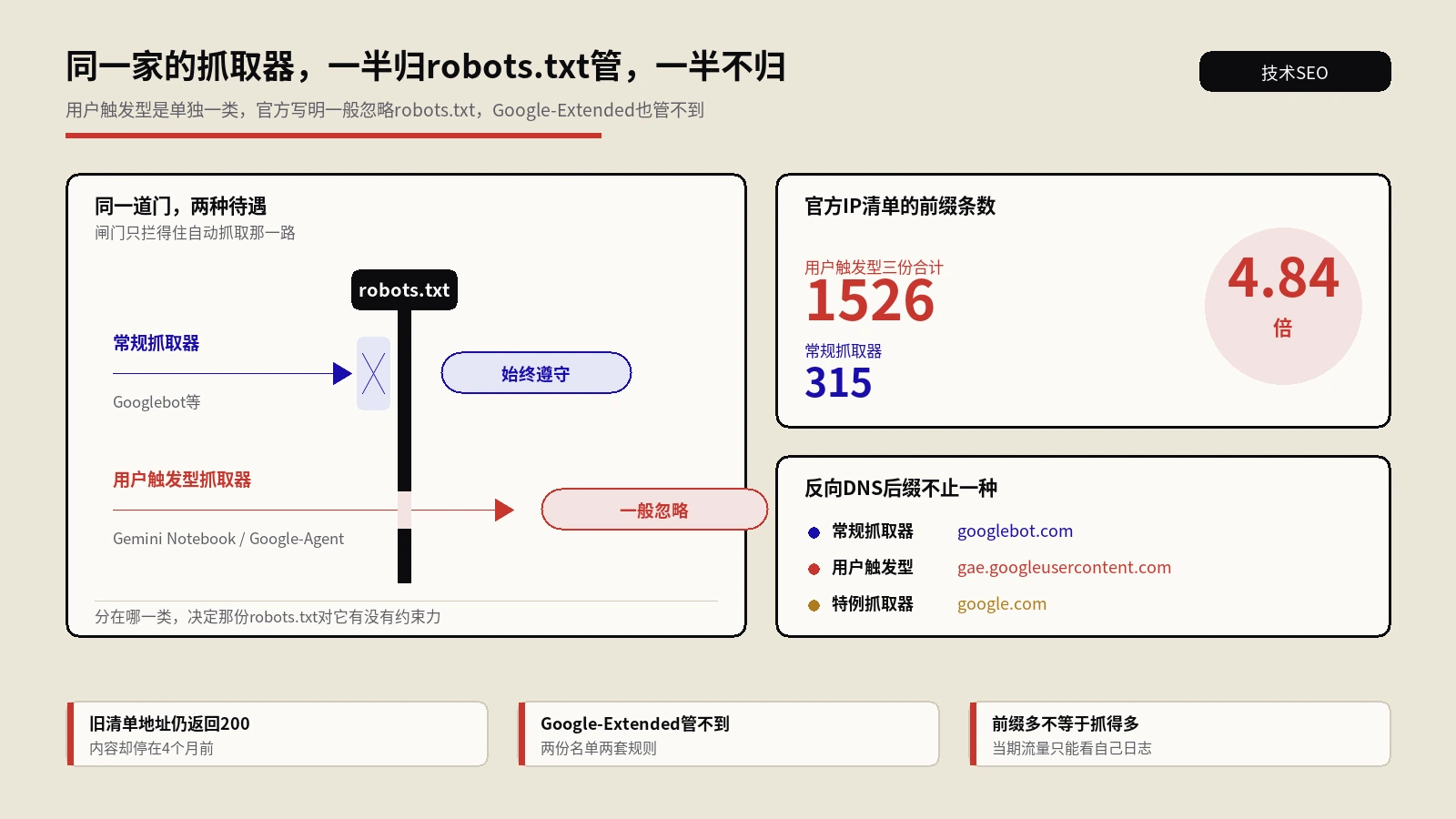
- 训练型爬虫(Training Bots):这类爬虫大规模抓取网页内容,用于训练大语言模型。它们的访问通常是批量的、非实时的。代表性的如早期的GPTBot的部分功能。品牌是否允许这类爬虫访问,取决于对AI模型训练数据贡献的商业判断。
- 索引型爬虫(Indexer Bots):类似于传统搜索引擎的爬虫,负责构建AI平台自身的内容索引。它们定期访问和更新对网站内容的理解。
- 检索型爬虫(Retrieval Bots):这是最关键也最容易被忽视的一类。当用户在AI平台输入提示词后,检索型爬虫会实时访问你的网站,即时获取内容来生成回答。这类爬虫的特点是实时性强、对响应速度要求高、直接影响AI生成的最终回答。
| 爬虫名称 | 所属平台 | 类型 | User-Agent标识 |
|---|---|---|---|
| GPTBot | OpenAI (ChatGPT) | 训练/检索 | GPTBot |
| ChatGPT-User | OpenAI (ChatGPT) | 检索 | ChatGPT-User |
| Google-Extended | Google (Gemini/AI Overview) | 训练 | Google-Extended |
| Googlebot | 索引 | Googlebot | |
| PerplexityBot | Perplexity | 检索 | PerplexityBot |
| ClaudeBot | Anthropic (Claude) | 训练/检索 | ClaudeBot |
| Applebot-Extended | Apple | 训练 | Applebot-Extended |
| Bytespider | 字节跳动 | 训练 | Bytespider |
| Meta-ExternalAgent | Meta | 训练/检索 | Meta-ExternalAgent |
传统的机器访客要么是搜索引擎的索引爬虫(抓取信息由算法处理排序),要么是恶意爬虫(品牌通常选择屏蔽)。但AI时代的检索型爬虫完全不同——它们实时访问你的网页,解读你的产品和服务描述,然后决定是否向真实客户推荐你。它们传递回的内容,直接决定了你的品牌在用户眼中的形象,或者决定了你的品牌是否根本不可见——而这一切,用户甚至从未亲眼看过你的网站。
AI搜索差距分析的三套方法
在制定优化策略之前,你需要先了解现状。下面是一套系统化的AI搜索差距分析方法。
手动Prompt测试法:这是最直观的方式,目标是亲身体验用户在AI搜索中如何感知(或无法感知)你的品牌。具体操作:打开主流AI搜索平台(建议覆盖ChatGPT、Gemini、Perplexity以及Google搜索的AI Overview,因为不同平台的信息来源和生成逻辑存在差异)。模拟真实用户的提问场景,覆盖三类查询——广泛品类查询(如"最好的项目管理工具有哪些")、具体产品对比查询(如"Notion和Asana哪个更适合小团队")、问题-解决方案查询(如"如何提高远程团队的协作效率")。系统记录每次查询的结果,关注:品牌是否被提及?是否被引用为信息来源?在回答中的位置排序如何?回答的情感倾向是正面、中性还是负面?
竞品对比分析法:在手动Prompt测试的基础上,进一步进行竞品对比。直接要求AI将你的品牌与竞争对手进行对比(如"比较X和Y的优缺点")。要求AI推荐品类最佳选项(如"推荐最适合B2B企业的CRM系统")。重点关注哪些品牌在各平台的回答中持续出现,以及AI引用的信息来源是哪些网站。需要判断的关键问题:AI的回答对你的品牌是否有利?信息是否准确?AI引用的信息来源是你自己的网站、竞争对手的网站,还是第三方测评网站?
服务器日志分析法:这是技术层面的关键步骤,目标是确认AI爬虫是否真的在访问你的网站。审查你的Web服务器访问日志,识别AI爬虫的User-Agent标识。将爬虫按训练型、索引型、检索型进行分类统计。分析哪些页面被AI爬虫频繁访问,哪些页面完全没有AI爬虫的访问记录。重要提醒:2025年7月Cloudflare开始默认屏蔽AI爬虫。这意味着如果你的网站使用了Cloudflare的服务,AI爬虫可能在你毫不知情的情况下就被拒之门外。请务必检查Cloudflare的Bot Management配置。如果你在日志中完全看不到AI爬虫的流量,这是一个强烈的信号:你的网站存在AI可访问性问题,需要立即排查。
网站为什么对AI不可见
完成差距分析后,如果发现品牌在AI搜索中表现不佳,原因通常可以追溯到网站本身。你的网站可能为人类用户精心设计了各种炫酷的交互体验——JavaScript渲染的动态组件、精美的轮播图、延迟加载的内容模块。但这些设计中的每一个,都可能在对AI爬虫隐藏关键内容。核心原则是:AI看不到的内容,等于不存在的内容。
JavaScript渲染问题:大多数现代网站大量使用客户端JavaScript渲染内容(如React、Vue、Angular单页应用)。人类用户的浏览器会执行JavaScript并渲染出完整页面,但大多数AI爬虫(尤其是检索型爬虫)不会执行JavaScript,或者执行JavaScript的能力非常有限。它们只能读取服务器直接返回的HTML源码。典型场景:你的产品详情页上,核心的产品描述、功能列表、价格信息、客户评价全部通过JavaScript动态加载。人类用户看到的是一个信息丰富的页面,但AI爬虫看到的可能是一个几乎空白的HTML骨架,只有一个div id=app标签和一堆script标签。解决方案:实施服务端渲染(SSR)或预渲染(Prerendering),确保页面的核心内容在HTML源码中直接可读,不依赖客户端JavaScript的执行。
robots.txt配置错误:许多网站的robots.txt配置可能在无意中屏蔽了AI爬虫。常见错误配置是把 User-agent: GPTBot 配 Disallow: /,等于直接屏蔽。推荐配置思路是:
User-agent: GPTBot
Allow: /products/
Allow: /blog/
Allow: /about/
Disallow: /admin/
Disallow: /internal/
User-agent: ChatGPT-User
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: ClaudeBot
Allow: /决策建议:对于训练型爬虫,品牌可以根据自身商业策略选择是否允许。但对于检索型爬虫(如ChatGPT-User、PerplexityBot),强烈建议开放访问——因为屏蔽它们等于直接放弃了在AI搜索结果中出现的机会。
内容延迟加载与动态加载:为了优化人类用户的页面加载体验,许多网站采用了懒加载、无限滚动、Ajax动态加载等技术。这些技术对AI爬虫来说是致命的,因为爬虫不会滚动页面、不会点击加载更多按钮。解决方案:关键内容(产品核心信息、服务描述、FAQ、定价等)应始终包含在初始HTML响应中,不依赖用户交互触发加载。
Cloudflare等CDN/安全服务的默认屏蔽:Cloudflare已于2025年7月开始默认屏蔽AI爬虫。其他CDN和安全服务可能也有类似策略。这意味着你的robots.txt即使正确配置了,AI爬虫的请求也可能在到达你的服务器之前就被CDN层拦截。解决方案:审查CDN和WAF(Web应用防火墙)的Bot Management配置,确保主要AI爬虫的User-Agent被加入白名单。
AEO技术优化的三层框架
理解了为什么不可见之后,下面是一套系统化的技术优化方案。整体框架围绕三个维度展开:内容可访问性、内容交付质量、内容本身质量。
内容可访问性(Content Accessibility):目标是确保AI爬虫能够物理地触达你的网页内容。检查清单:网站是否存在robots.txt文件?robots.txt是否允许主要AI爬虫(GPTBot、ChatGPT-User、PerplexityBot、ClaudeBot、Google-Extended)访问核心内容页面?CDN/WAF层是否将主要AI爬虫加入了白名单?是否存在IP级别的访问限制影响AI爬虫?Sitemap文件是否完整且保持更新?
实操建议是用curl命令模拟AI爬虫访问,检查服务器实际返回的内容:
# 模拟 GPTBot 访问
curl -A "Mozilla/5.0 AppleWebKit/537.36 (compatible; GPTBot/1.0; +https://openai.com/gptbot)" https://yoursite.com/important-page
# 模拟 PerplexityBot 访问
curl -A "PerplexityBot" https://yoursite.com/important-page如果返回的内容是空白或403/503错误,说明存在访问性问题。
内容交付质量(Content Delivery):目标是确保AI爬虫获取到的内容是完整的、结构化的、可快速解析的。检查清单:页面核心内容是否能在不执行JavaScript的情况下交付?页面是否实施了服务端渲染(SSR)或预渲染?检索型爬虫是否能成功获取预渲染版本的内容?页面加载速度(TTFB、FCP)是否对爬虫足够快?页面是否返回正确的HTTP状态码(200)?页面的Content-Type响应头是否正确标识为HTML?
实操验证可用curl统计页面纯HTML的p标签数量,或者用Lynx文本浏览器查看AI爬虫"看到"的内容:curl -s URL | grep -c "<p>" 看返回的段落数,lynx -dump URL 看纯文本结构。SSR/预渲染方案选型可参考下表:
| 方案 | 适用场景 | 典型技术栈 | 复杂度 |
|---|---|---|---|
| SSR服务端渲染 | 内容频繁更新的动态页面 | Next.js、Nuxt.js、Remix | 中 |
| SSG静态站点生成 | 内容相对固定的页面 | Next.js Static、Gatsby、Hugo | 低 |
| 动态预渲染 | 已有SPA改造成本敏感 | Prerender.io、Rendertron | 中低 |
| 混合渲染 | 大型站点不同页面需求不同 | Next.js ISR | 中高 |
内容本身质量(Content Quality):目标是确保AI能完整阅读并准确理解你的内容。检查清单:页面内容是否足够简洁,确保AI能在Token限制内完整读取?页面的Title和Meta Description是否与页面实际内容高度相关?页面的非JavaScript版本(纯HTML版本)与JavaScript渲染版本的内容是否实质一致?内容结构是否使用了语义化HTML(H1-H6层级清晰、使用article、section、main等标签)?是否部署了结构化数据标记(Schema.org JSON-LD)?核心事实性内容(产品功能、定价、联系方式)是否准确且更新及时?
AI模型处理单个页面时存在上下文窗口(Token)的限制。如果页面内容过长(例如超过10,000字的巨型产品页),AI可能无法完整读取。建议将长内容拆分为逻辑清晰的独立页面,每个页面聚焦一个核心主题。结构化数据示例(产品页):
{
"@context": "https://schema.org",
"@type": "Product",
"name": "你的产品名称",
"description": "产品核心描述,确保准确传达核心价值",
"brand": {"@type": "Brand", "name": "你的品牌名称"},
"offers": {
"@type": "Offer",
"price": "99.00",
"priceCurrency": "USD"
},
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.5",
"reviewCount": "328"
}
}从可见到被推荐的进阶策略
完成上述基础优化后,你的网站应该对AI爬虫变得可见了。但可见只是起点,被推荐才是目标。
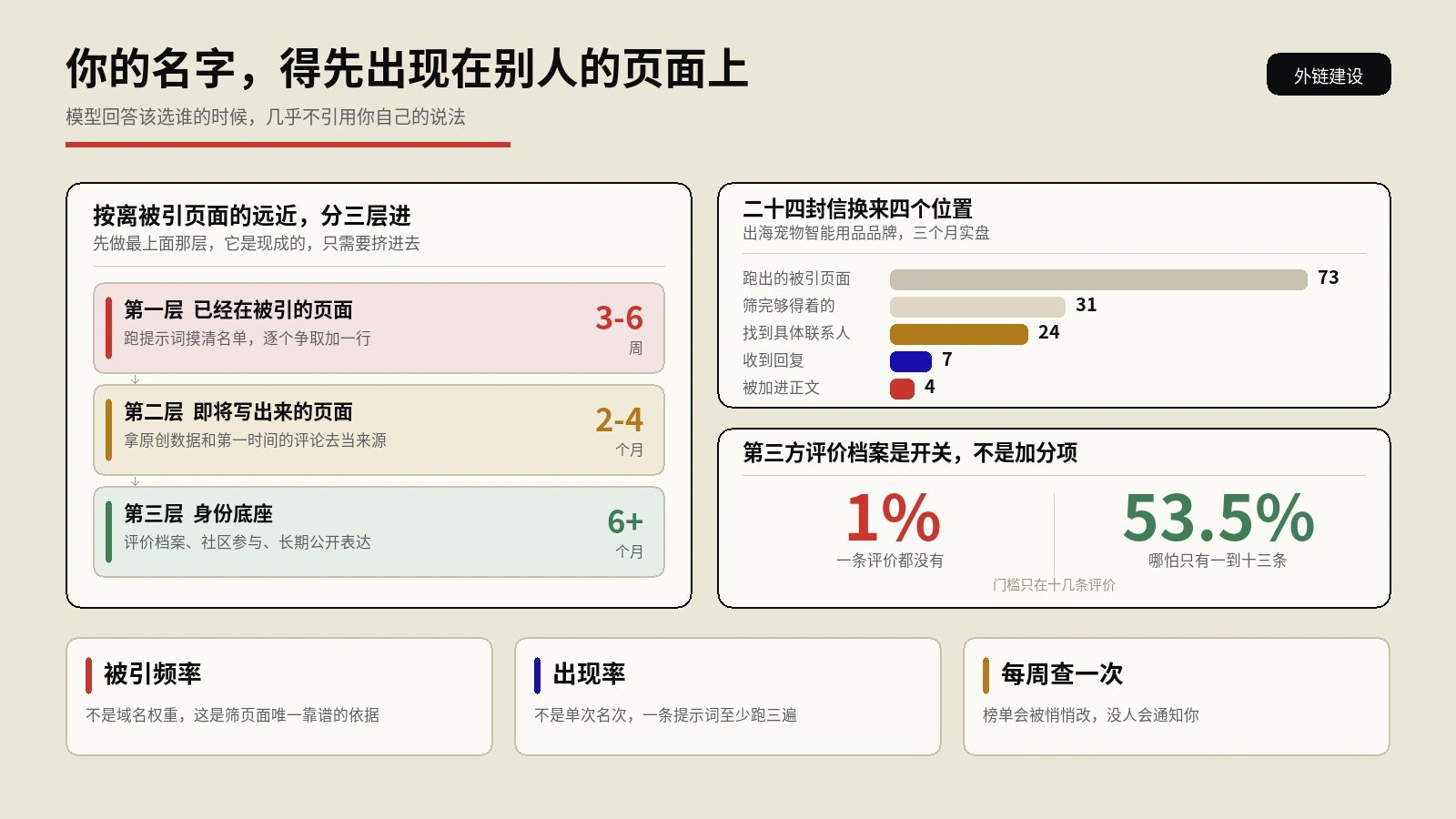
内容权威性建设:AI在生成回答时,会优先引用它认为具有权威性的信息来源。提升权威性的策略包括发布原创的行业研究数据和报告(AI倾向于引用第一手数据源)、保持内容的时效性(定期更新关键页面的信息,陈旧的内容会降低AI对信息源的信任度)、建立丰富的外部引用网络(当多个权威第三方网站引用你的内容时,AI会将其视为可信度信号)。品牌实体本身的身份建设可以参考 实体主页Entity Home在AI搜索时代的品牌身份地图指南。
FAQ与问答型内容优化:AI搜索的本质是回答问题。因此直接以问答格式组织的内容天然适合被AI引用。建议为每个核心产品/服务页面建立结构化的FAQ部分,使用真实用户的提问措辞(通过客服记录、社区提问等渠道收集),并部署FAQPage结构化数据标记。具体到Shopify场景下的FAQPage实施可参考 Shopify博客文章添加FAQPage结构化数据指南。
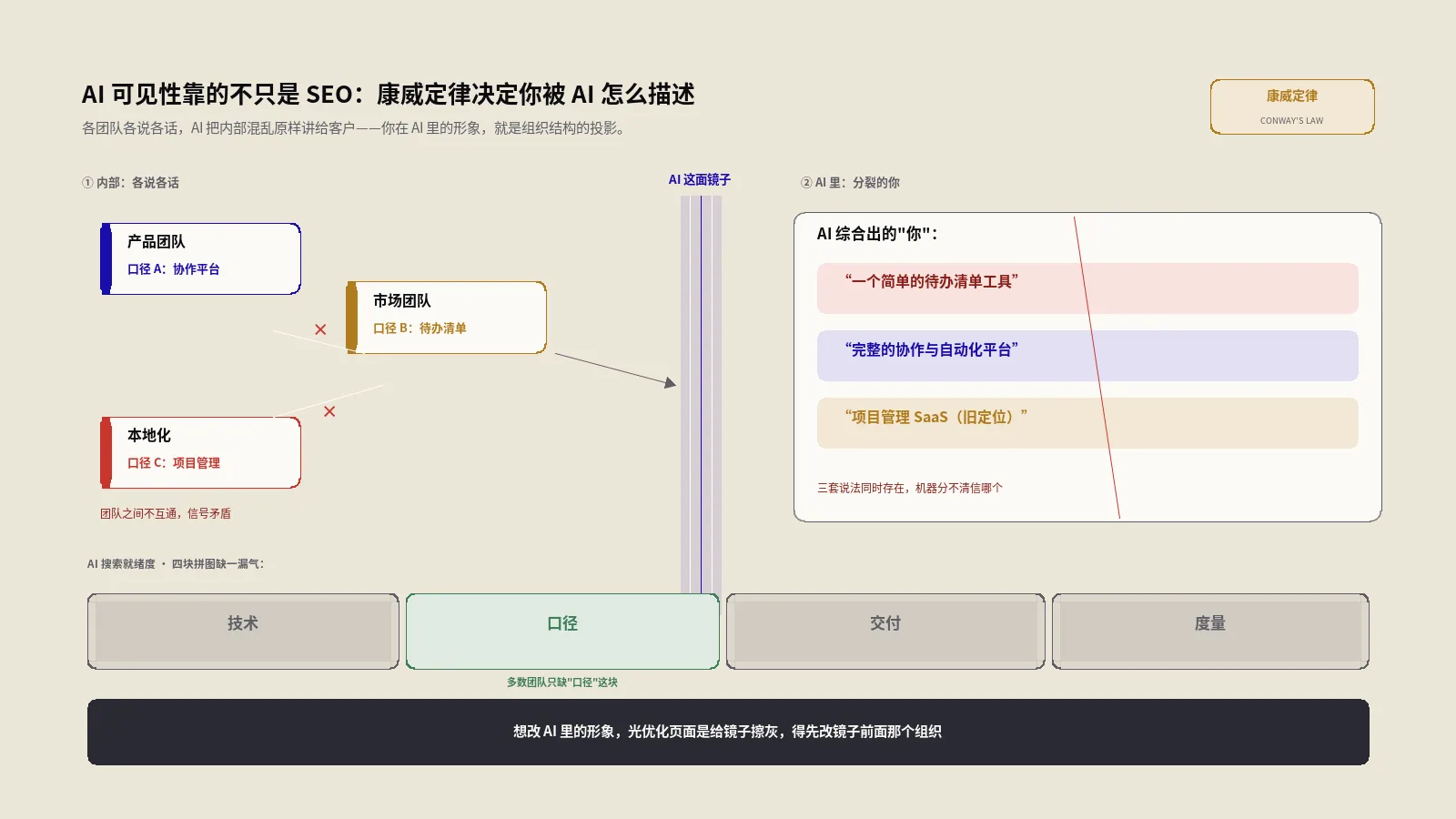
品牌叙事一致性:确保你的品牌在所有线上渠道(官网、社交媒体、第三方平台、新闻报道)中的核心叙事保持一致。AI在合成信息时会交叉验证多个来源,叙事不一致会导致AI生成的回答模糊或矛盾。
持续监测与迭代:AEO不是一次性项目,而是需要持续监测和迭代的过程。建议建立定期(至少每月一次)的AI搜索表现审查机制:在主流AI平台上测试核心品牌查询和品类查询,记录变化趋势,并根据结果调整内容和技术策略。
常见误区与避坑指南
AEO就是换了个名字的SEO:虽然AEO和SEO有重叠(都关注内容质量和技术规范),但AEO有其独特要求。SEO优化的目标是搜索引擎算法和链接排名;AEO优化的目标是AI对内容的语义理解和生成推荐。仅仅做好SEO不等于AEO也做好了。
只要放开robots.txt就行了:允许AI爬虫访问只是第一步。如果你的内容依赖JavaScript渲染、页面加载缓慢、内容结构混乱,AI即使能访问你的页面,也无法正确提取和理解内容。技术优化和内容优化必须同步进行。
屏蔽所有AI爬虫来保护内容版权:这是一个需要审慎权衡的商业决策。屏蔽训练型爬虫可能有其知识产权保护的合理性,但如果同时屏蔽了检索型爬虫,你的品牌将从AI搜索结果中彻底消失。在AI搜索占比快速增长的今天,这可能带来远超版权风险的商业损失。
内容越多越好:AI不是靠内容的数量来判断权威性的。一个充斥着低质量、重复性内容的网站,反而可能降低AI对品牌整体可信度的评估。聚焦高质量、高相关性、有独特价值的内容,远比单纯追求数量更有效。
掌控品牌叙事的六步行动框架
AI搜索时代的到来,意味着品牌不能再被动等待用户通过搜索引擎找到自己。从AI爬虫在你的网站上看到什么,到AI平台向用户讲述关于你的什么故事——这条完整链路上的每一个环节,都是可观察的、可度量的、可优化的。核心行动框架:
- 诊断现状:通过手动Prompt测试、竞品对比分析、服务器日志分析,了解你的品牌在AI搜索中的当前表现。
- 打通访问:确保robots.txt、CDN/WAF配置、服务器响应层面不存在阻碍AI爬虫的技术壁垒。
- 优化交付:实施SSR/预渲染,确保核心内容以纯HTML形式交付,不依赖JavaScript执行。
- 提升质量:使用语义化HTML和结构化数据,确保内容简洁、准确、结构清晰。
- 建立权威:通过原创研究、高质量内容和一致性品牌叙事,提升AI对品牌的信任度和推荐倾向。
- 持续迭代:建立常态化的AI搜索表现监测机制,根据数据反馈不断优化。
不要让AI在传话游戏中扭曲你的品牌。掌控信息源头,就是掌控品牌在AI时代的命运。
常见问题解答
AEO和传统SEO能完全替代关系吗
不是替代关系,而是互补关系。SEO的所有基础动作(站内结构、外链、内容质量、技术性能)依然是AI爬虫识别和理解内容的前提,AEO是在SEO的基础之上加一层"让AI能完整、准确读取并合成你内容"的优化目标。短期内传统搜索和AI搜索会并存,两类流量都不能放弃。实操上的差别是:SEO关注关键词排名和点击,AEO关注实体识别、Schema标记完整度、内容是否能被AI完整提取作为回答素材。
屏蔽训练型AI爬虫但允许检索型爬虫怎么操作
在robots.txt中精准区分User-Agent。训练型爬虫如Google-Extended、Applebot-Extended、Bytespider可以设置 Disallow: /,检索型爬虫如ChatGPT-User、PerplexityBot必须设置 Allow: /。GPTBot本身兼具训练和检索功能,建议至少开放产品页和博客页给它,避免完全屏蔽导致ChatGPT回答中品牌消失。CDN层(Cloudflare/Akamai)也要做同样的细分白名单,不能在边缘层粗暴拒绝所有AI爬虫。
SSR成本太高小团队怎么折中
三种折中方案:第一是只对Top 20-50个核心页面做预渲染(用Prerender.io或Rendertron的免费额度),其余页面保留SPA,先解决最关键页面的可见性;第二是用静态站点生成(SSG)的方式发布产品介绍页和博客页(Hugo/Astro都是低门槛选择),交互复杂的应用页保留客户端渲染;第三是用Next.js或Nuxt.js的增量静态再生(ISR)模式,按访问频率动态生成静态快照,工程量比全SSR小一个量级。
怎么验证AI爬虫真的看到了我想让它看到的内容
三个验证手段。第一用curl带AI爬虫的User-Agent访问目标URL,把返回的HTML扔进文本编辑器,搜索你期望AI能识别的关键词、产品名、价格、FAQ等是否真的出现在源码里。第二用Lynx文本浏览器(lynx -dump URL)看纯文本结构,这就是检索型爬虫"看到"的内容。第三在ChatGPT/Perplexity里直接搜索你的品牌+特定问题,看AI引用的事实是否准确——如果AI胡编乱造,多半是它没真的爬到你的页面。
结构化数据JSON-LD应该放在head还是body
head和body都行,主流AI爬虫都能识别两个位置的JSON-LD。但放在head里的好处是:JSON-LD最先被爬虫读到,即使后续body内容加载失败,结构化数据本身已经完整传达;放在body末尾的好处是:方便在服务端模板里把多块Schema一起拼接、调试和维护。我自己的标准做法是Organization、WebSite这种全局Schema放head,Article、Product、FAQPage这种页面级Schema放body末尾</main>之后。
AI搜索的引用怎么追踪能否做到Analytics级别
目前没有Google Analytics那样精细的官方API,但有几种近似方案:一是用Ahrefs Brand Radar或SE Ranking AI Tracker订阅服务,自动跑预设的查询变体并记录引用情况;二是自建脚本调用ChatGPT API或Perplexity API,每天跑10-20个核心查询,把返回结果存进数据库做趋势分析;三是在自己网站的服务器日志里识别ChatGPT-User、PerplexityBot的referer,反推AI给你带了多少点击(虽然这些爬虫不一定带referer,覆盖率有限)。组合用这三种方式能拼出80%的可见性数据。
如何识别恶意爬虫冒充AI爬虫
主要AI厂商都公开了爬虫的User-Agent和IP段,可以做反向验证。OpenAI的GPTBot和ChatGPT-User官方文档里有公开的IP段,可以拿来做白名单。请求来的User-Agent声称是GPTBot但IP不在OpenAI公布的段内,几乎可以认定是冒充——这类请求多半是某些SEO工具或者爬虫程序伪装的,可以在Nginx层做fail2ban拦截。同样的方法适用于PerplexityBot和ClaudeBot,Anthropic和Perplexity也都公开了官方IP段。
AEO优化多久能见到效果
分两层看。技术层面的优化(robots.txt放开、CDN白名单、SSR部署)见效最快——AI爬虫1-2周内就能开始抓取新内容。AI引用层面的变化需要更长——主流AI平台对网页内容的"消化吸收"有一个延迟,从被爬到内容进入回答素材库一般要4-8周,部分平台甚至2-3个月。所以做AEO要有耐心,第一个月主要看技术层指标(爬虫访问次数、4xx错误率),第二、三个月开始看可见性指标(AI回答中的品牌出现率),第六个月才能看到稳定的趋势。
权威参考资料
本文标题:《AEO优化从被看见到被AI推荐:三层框架加六步行动》
本文链接:https://zhangwenbao.com/ai-crawler-aeo-optimization-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0