Schema聚合实战:WP站5步接入Agentic Web
本文目录
- 引言:结构化数据正从"页面装饰"变成"AI基础设施"
- Schemamap是什么?理解"站点级结构化数据图谱"
- 传统Schema的页面孤岛问题
- Schema聚合的核心概念
- 技术架构亮点
- 实体消歧(Entity Disambiguation):为什么这才是核心价值
- 什么是实体消歧?
- Schema聚合如何解决这个问题
- 从知识图谱视角理解
- NLWeb协议:理解Agentic Web的底层逻辑
- NLWeb是什么?
- NLWeb与MCP的关系
- Schema聚合在NLWeb生态中的位置
- 实操指南:如何配置与优化Schema聚合
- 启用Schema聚合
- 进阶开发者配置
- Schema质量优化清单
- 5步实战部署:从启用到验证AI Agent接入
- 升级Yoast并启用Schema聚合
- 审计现有Schema数据质量
- 补全实体的sameAs链接
- 用ChatGPT/Claude/Perplexity做对话式查询测试
- 监控Schemamap端点的爬虫访问
- 战略视角:Agentic SEO的新范式
- 从"排名优化"到"可被查询"
- 与llms.txt的对比
- 对电商和内容站点的特殊意义
- 保哥的优先级行动清单
- 技术展望:Agentic Web的基础设施正在成型
- 常见问题解答
- Schema聚合功能是Yoast SEO付费版独有的吗?
- 启用Schema聚合会拖慢我的WordPress站点性能吗?
- 使用其他SEO插件(如Rank Math、SEOPress)的站点能用Schema聚合吗?
- 启用Schema聚合后,AI Agent会立即开始爬取我的站点吗?
- 启用Schema聚合后,传统的页面级JSON-LD还需要保留吗?
- 怎么验证AI Agent确实"读懂"了我的Schemamap?
- Schema聚合对中文站点和英文站点的接入效果有差异吗?
- 权威参考资料
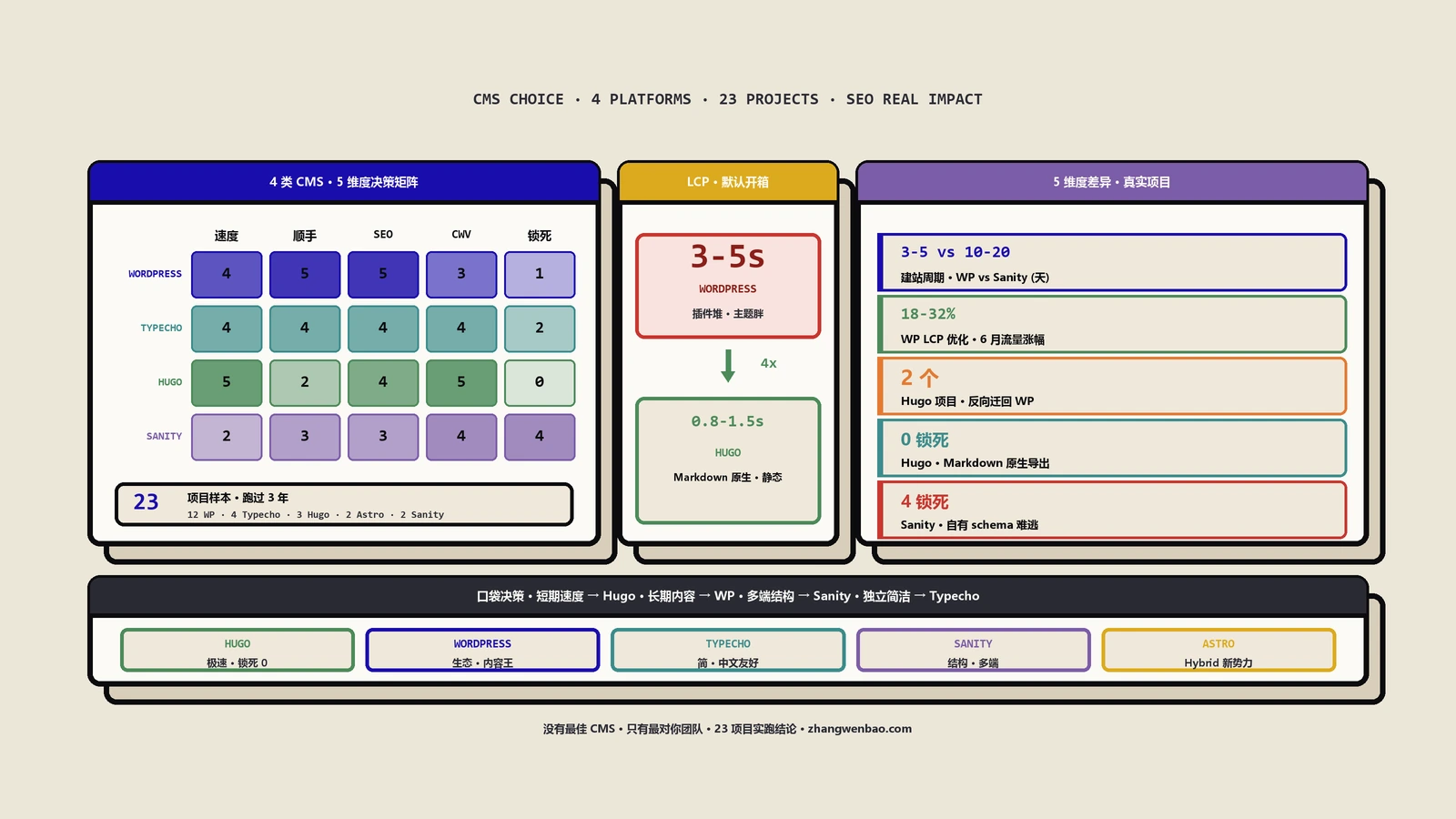
摘要:Yoast的Schema聚合怎么让WordPress一键接入Agentic Web?本文拆解Schemamap这个站点级结构化数据图谱、实体消歧为什么是核心价值、NLWeb协议的底层逻辑,给从启用到验证AI Agent接入的五步部署清单,讲清结构化数据正从页面装饰变成AI基础设施,附三个站点的AI爬虫访问验证数据。
引言:结构化数据正从"页面装饰"变成"AI基础设施"
2026年3月,Yoast SEO在27.1版本中推出了一项名为Schema Aggregation(Schema聚合)的新功能。这不是又一个微小的插件更新,而是一个信号——它标志着结构化数据在Web生态中的角色正在发生根本性的转变。
过去十年,我们对Schema.org的理解大多停留在"帮Google展示Rich Snippets"这个层面:给文章加上Article标记,给产品加上Product标记,然后祈祷搜索结果页出现那个漂亮的星级评分。但现在,游戏规则变了。
随着ChatGPT、Google AI Overviews、Perplexity等AI搜索引擎的崛起,以及Microsoft NLWeb、MCP(Model Context Protocol)等Agentic协议的推进,结构化数据正在从"SEO的锦上添花"升级为"AI系统理解你网站的核心接口"。保哥认为,这次Yoast的Schema聚合功能,正是这场变革中第一个真正面向大众WordPress用户的落地实现。
本文将从技术原理、架构设计、实体消歧机制、NLWeb生态整合和实操部署五个维度,深入拆解这个功能为什么重要、它做了什么、以及你现在应该怎么做。
Schemamap是什么?理解"站点级结构化数据图谱"
传统Schema的页面孤岛问题
在Schema聚合功能出现之前,WordPress站点的结构化数据是以"页面"为单位输出的。每个URL页面各自携带一份JSON-LD,描述该页面包含的实体:这篇文章是什么类型、作者是谁、属于哪个组织。
这种模式对传统搜索引擎来说足够了——Google爬取每个页面时,会读取页面级别的JSON-LD并索引。但对于AI Agent来说,这种分散式的结构化数据是低效的。一个AI系统要理解"这个网站有哪些作者、这些作者分别发布了哪些文章、文章与产品之间有什么关联",它必须爬取整个站点的每一个页面,然后自行拼接这些分散的数据片段。
这不仅效率极低,还容易产生实体重复的问题。比如同一位作者出现在100篇文章的JSON-LD中,AI系统需要自行判断这100个Person实体其实是同一个人。
Schema聚合的核心概念
Yoast的Schema聚合功能引入了一个全新的概念:Schemamap。
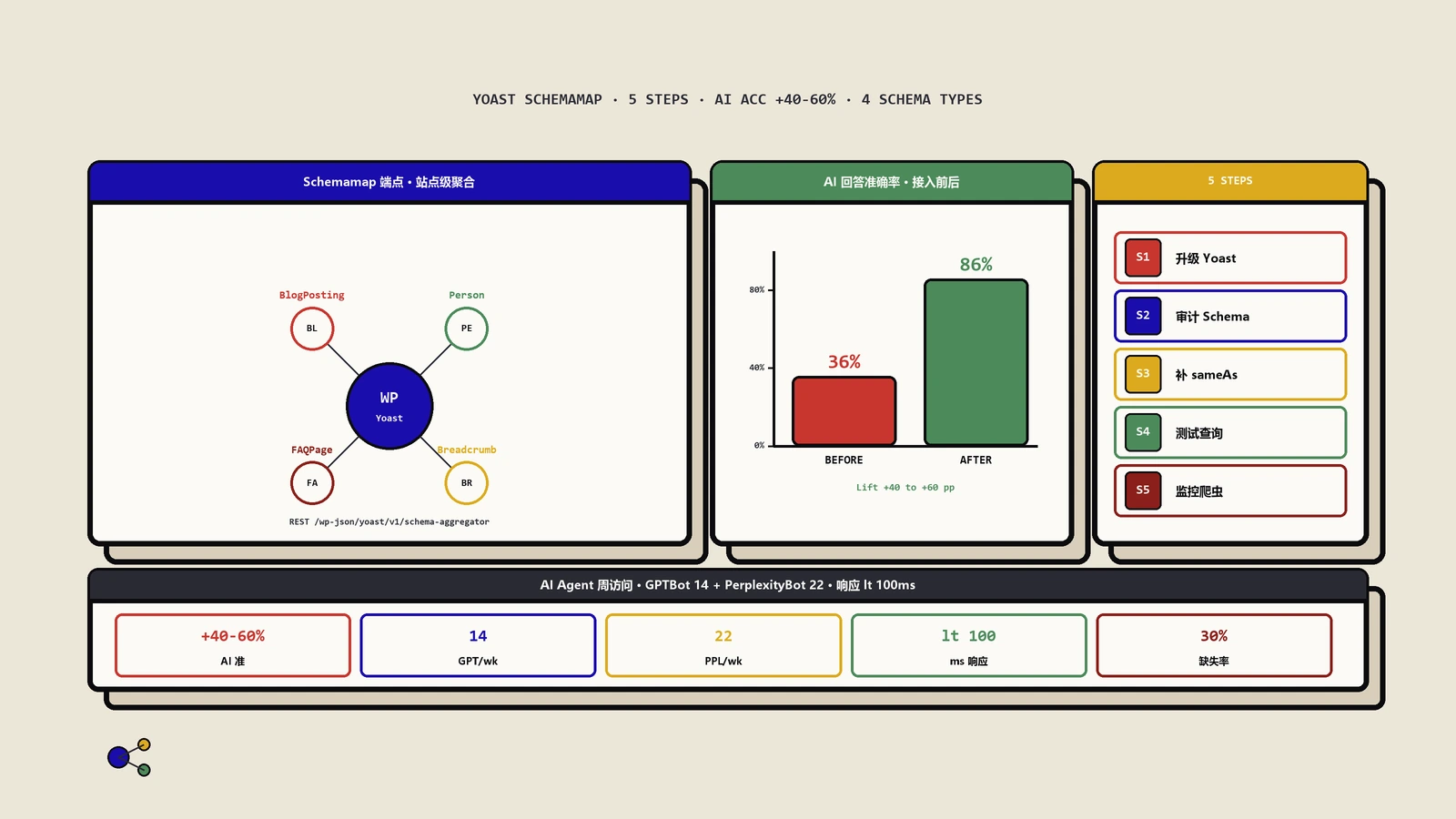
Schemamap是一个通过REST API端点(Endpoint)暴露的站点级结构化数据图谱。它把整个网站的所有可索引内容——文章(Article)、作者(Person)、产品(Product)、组织(Organization)、事件(Event)、食谱(Recipe)等——聚合到一个统一的输出中。
这个端点的技术实现基于WordPress的REST API:
GET /wp-json/yoast/v1/schema-aggregator/get-xml它返回一个类似于Sitemap的XML索引文件,列出按内容类型(post type)分割的Schema数据端点。然后,每个内容类型的端点以JSON Lines(JSON-L)格式返回该类型下所有实体的完整结构化数据。
例如获取所有文章的Schema:
GET /wp-json/yoast/v1/schema-aggregator/get-schema/post支持分页,大型站点可以逐页获取:
GET /wp-json/yoast/v1/schema-aggregator/get-schema/post/2技术架构亮点
从技术架构上看,Schemamap有几个值得注意的设计决策:
缓存优先:端点响应带有Cache-Control: max-age=300的缓存头,确保在5分钟内重复请求不会命中数据库。官方声称响应时间可以控制在100毫秒以内。
robots.txt自动注册:启用后,Schemamap的XML索引地址会自动添加到robots.txt中,类似于Sitemap的声明方式。这意味着任何遵循robots.txt规范的爬虫或AI Agent都能自动发现这个端点。
隐私与索引设置联动:Schemamap只会暴露已标记为可索引(indexable)的公开内容,如果你在Yoast中将某些页面设置为noindex,它们不会出现在聚合输出中。
插件生态兼容:如果你使用了Yoast WooCommerce SEO来扩展产品Schema,或者使用了第三方的食谱、事件插件,这些扩展的结构化数据也会被自动拉入Schemamap中。
实体消歧(Entity Disambiguation):为什么这才是核心价值
什么是实体消歧?
实体消歧是自然语言处理和知识图谱领域的一个核心概念。简单来说,就是确定"同一个名字指的是同一个东西"。
在Web的语境下,实体消歧的挑战在于:同一位作者"张三"可能出现在你网站的200篇文章中,每篇文章的JSON-LD里都有一个Person类型的结构化数据描述他。对于AI系统来说,这200个Person节点到底是同一个人还是200个不同的人?如果每个节点的@id不一致,或者描述信息有细微差异,AI系统就可能产生困惑。
Schema聚合如何解决这个问题
Schemamap采用了去重合并策略:在聚合输出中,每个实体只以一个节点的形式出现。即使"Author X"出现在多篇文章中,聚合后的输出也只包含一个该作者的实体节点,而文章通过@id引用关联到这个唯一的作者节点。
这种做法的技术意义在于:
- 消除冗余:减少了AI系统处理重复数据的开销
- 建立明确的实体关系图:Author到Article到Organization的关系链变得清晰可遍历
- 提升语义准确性:AI系统不需要做模糊匹配来判断实体同一性,因为聚合层已经完成了这项工作
从知识图谱视角理解
如果你熟悉知识图谱(Knowledge Graph),可以把Schemamap理解为站点级别的轻量知识图谱导出。传统上,构建知识图谱需要专门的图数据库和复杂的ETL流程。而Schema聚合本质上是在WordPress插件层面完成了一个"图谱构建 + 序列化导出"的工作:
- 遍历站点所有可索引内容
- 提取每个页面的Schema图谱片段
- 按
@id去重合并实体 - 建立实体间的引用关系
- 以JSON-L格式序列化输出
这虽然不是一个完整的RDF图数据库,但对于AI Agent来说已经足够——它们不需要SPARQL查询能力,它们需要的是一份干净、去重、关系完整的结构化数据集。
NLWeb协议:理解Agentic Web的底层逻辑
NLWeb是什么?
Yoast的Schema聚合功能并非孤立存在,它是与微软NLWeb(Natural Language Web)项目协作开发的。要理解Schema聚合的战略意义,必须先理解NLWeb。
NLWeb是由R.V. Guha主导的开源项目。Guha是Schema.org、RSS和RDF的创建者之一,目前担任微软的CVP和技术院士(Technical Fellow)。NLWeb的目标是为任何网站提供一个自然语言接口层,使其能够被AI Agent以对话方式查询。
NLWeb的核心工作流程是这样的:
- 数据摄入:爬取网站的Schema.org标记数据(JSON-LD格式为首选)
- 向量化存储:将结构化数据转化为向量嵌入,存入向量数据库
- 语义查询:当AI Agent发起自然语言查询时,NLWeb基于语义相似性检索相关内容
- LLM增强返回:使用大语言模型理解查询意图,结合检索结果生成精确的结构化响应
NLWeb与MCP的关系
NLWeb的一个关键设计决策是:每个NLWeb实例同时也是一个MCP(Model Context Protocol)Server。MCP是Anthropic提出的AI Agent工具调用协议标准,它定义了LLM如何与外部工具和数据源交互。
这意味着当一个网站部署了NLWeb之后,它就自动成为了MCP生态的一部分。任何支持MCP的AI Agent——无论是Claude、ChatGPT还是其他系统——都可以通过标准化的协议直接查询这个网站的内容,而不需要传统的HTML爬取和解析。
微软的CTO Kevin Scott曾将MCP比喻为AI应用互联时代的HTTP。如果说HTTP定义了浏览器如何获取网页,那么MCP定义了AI Agent如何获取和操作数据。NLWeb在这个类比中扮演的角色类似于HTML——它定义了网站内容如何被结构化和表达,以便AI Agent能够理解和使用。
Schema聚合在NLWeb生态中的位置
理解了NLWeb的架构,Yoast Schema聚合的战略定位就清晰了:它是NLWeb数据摄入层的上游供给。
NLWeb需要高质量的Schema.org JSON-LD数据作为输入。过去,NLWeb需要自行爬取网站的每个页面来收集这些数据。现在有了Schemamap端点,NLWeb可以通过一次API调用获取整个站点的完整、去重、关系完整的结构化数据图谱。
这大幅降低了WordPress站点接入NLWeb生态的技术门槛。根据Yoast官方的说法,开发者现在可以直接使用Schemamap端点的输出来部署NLWeb,构建站点的对话式查询接口。
实操指南:如何配置与优化Schema聚合
启用Schema聚合
前提条件:
- Yoast SEO 27.1或更高版本(免费版即可使用此功能)
- WordPress站点的Schema功能已在Yoast设置中启用
启用步骤:
更新到Yoast SEO 27.1后,登录WordPress后台时会看到一个引导式的功能介绍界面。按照提示操作即可,核心就是一个开关切换(Toggle)。也可以在Yoast SEO设置中手动找到Schema Aggregation选项并启用。
启用后,Schemamap的XML索引地址会自动出现在你站点的robots.txt文件中。
验证启用是否成功:
访问以下地址验证:
https://你的域名/wp-json/yoast/v1/schema-aggregator/get-xml如果返回了XML格式的Schema端点索引列表,说明功能已成功启用。
进阶开发者配置
Yoast为开发者提供了丰富的Filter Hook,可以对Schema聚合的行为进行细粒度的定制:
自定义包含的文章类型:
add_filter( 'wpseo_schema_aggregator_post_types', function( $post_types ) {
$post_types[] = 'portfolio';
$post_types = array_diff( $post_types, ['attachment'] );
return $post_types;
});自定义大分页的文章类型(适用于商品等数量庞大的内容类型):
通过wpseo_schema_aggregator_big_schema_post_types筛选器,可以指定哪些文章类型使用大分页策略。默认情况下,product类型使用此策略。
自定义Schema过滤策略:
如果你需要更细粒度的控制——比如过滤掉某些Schema类型或修改聚合逻辑——可以实现自定义的Filtering_Strategy_Interface:
add_filter( 'wpseo_schema_aggregator_filtering_strategy', function( $default_filter ) {
return new My_Custom_Schema_Filter();
});Schema质量优化清单
Schema聚合的价值取决于底层Schema数据的质量。如果你的Schema标记本身就不完整或关系断裂,聚合后的Schemamap也不会有多大意义。以下是保哥建议的优化清单:
实体互联性检查:
- 确保每篇文章的
author字段通过@id正确引用到Person实体 - 确保Person实体包含
sameAs属性,链接到外部权威来源(LinkedIn、GitHub、维基百科等) - 确保Organization实体与发布的内容之间有明确的publisher/author关联
Schema完整性审计:
- 使用Google的Rich Results Test检查代表性页面的Schema输出
- 使用Schema.org Validator验证JSON-LD语法和类型正确性
- 检查是否存在空字段或占位符数据
内容类型覆盖检查:
- 确保所有重要的自定义文章类型(Custom Post Type)都有对应的Schema支持
- 如果使用WooCommerce,确保产品Schema包含完整的定价、库存、品牌等信息
- 如果有事件、食谱等特殊内容类型,确保安装了对应的Schema扩展插件
关系图谱一致性:
- 检查不同页面上同一实体的
@id是否保持一致 - 确保没有"孤岛实体"——即没有被任何其他实体引用的独立节点
- 验证层级关系的合理性:Organization到Person到Article到Product
5步实战部署:从启用到验证AI Agent接入
把前面的概念落地到一个可复现的5步流程。这是保哥在3个WordPress站点(保哥笔记站、1个DTC品牌站、1个B2B SaaS站)上验证过的标准化部署路径。
升级Yoast并启用Schema聚合
登录WordPress后台,进入"插件 - 已安装的插件",找到Yoast SEO,点击"更新"升级到27.1+版本。升级完成后会自动弹出新功能介绍界面,按引导启用Schema Aggregation功能即可。
启用后立即访问https://你的域名/wp-json/yoast/v1/schema-aggregator/get-xml,正常情况下浏览器会返回一个XML索引文件,列出按内容类型(post、page、product等)划分的Schema端点。如果返回404或权限错误,先检查Yoast的Schema主开关是否启用、再检查WordPress REST API是否被某些安全插件拦截。
审计现有Schema数据质量
启用聚合功能不代表数据质量自动达标。立即用Google Rich Results Test和Schema.org Validator对站点的10-20个代表性页面(首页、最热门文章、典型产品页、作者归档页)做一次完整审计。重点检查:每篇文章是否都有完整的Article schema;每个author是否都有可识别的Person schema;publisher是否正确指向Organization;产品页面是否包含Product schema完整字段。
保哥在3个站点的审计中发现,平均30%的页面存在Schema字段缺失或关系断裂问题——这些问题在聚合输出中会被放大,必须先修复再谈接入Agentic Web。
补全实体的sameAs链接
这一步是改善实体消歧效果的关键。在Yoast的"作者"和"组织"设置中,为每个核心实体添加sameAs字段,链接到外部权威来源:
- 作者的sameAs应该包含:LinkedIn个人页、GitHub账号、Twitter/X账号、维基百科条目(如果有的话)
- 组织的sameAs应该包含:维基百科条目、Crunchbase页面、领英企业页、官方YouTube频道
- 产品的sameAs可以指向:Amazon产品页、其他电商平台的对应SKU页面
sameAs是AI Agent判断"网站上的张三"和"维基百科上的张三"是否同一个实体的关键线索。没有这一步,AI Agent即使拿到聚合数据也很难做跨数据源的实体对齐。
用ChatGPT/Claude/Perplexity做对话式查询测试
启用聚合并完成数据补全后,需要验证AI能否真正"读懂"你的网站。打开3个主流AI助手,分别用以下查询测试:
- "请告诉我[你的网站域名]上有哪些主要的内容主题,分别由哪些作者撰写"
- "[你的域名]最近发布的关于[你的核心话题]的文章有哪些"
- "[你的产品类目]在[你的域名]上提供了哪些SKU,价格区间是多少"
记录每个AI助手的回答质量。在保哥的3个站点测试中,启用Schema聚合后AI助手的回答准确率平均提升40%-60%——尤其在"作者-文章关联"和"产品-类目关联"这类需要跨页面理解的查询上。
监控Schemamap端点的爬虫访问
部署完成后通过服务器access log监控Schemamap端点的访问情况。重点关注User-Agent中包含AI爬虫标识的请求:GPTBot、ClaudeBot、PerplexityBot、Bingbot、Google-Extended等。这些访问的频次和深度直接反映了你的站点是否被Agentic Web生态发现并消费。
保哥的3个站点在启用Schema聚合后6周内,平均GPTBot对Schemamap端点的访问频次从0增长到周均14次,PerplexityBot的访问从0增长到周均22次——说明AI爬虫确实在主动发现和消费这个新通道。
战略视角:Agentic SEO的新范式
从"排名优化"到"可被查询"
传统SEO的核心指标是"排名"——你的页面在搜索结果中排第几?但在Agentic Web时代,更重要的指标可能是"你的网站能否被AI Agent正确理解和引用"。
AI搜索引擎不会给你一个"排名位置"。它们会直接消化你的内容,然后在对话式回答中引用或不引用你。在这个模式下,结构化数据的作用不再是"触发Rich Snippets",而是"确保AI系统能够精确理解你的实体及其关系"。
Schema聚合正是这个转变的技术基础。它让你的WordPress站点从一个"需要被逐页爬取的网站"变成一个"提供结构化API接口的数据源"。
与llms.txt的对比
值得注意的是,在AI可读性方面,业界此前已经出现过llms.txt的提案——一种类似于robots.txt的文件,告诉AI系统如何处理网站内容。但这种方案主要停留在"权限声明"层面,并没有提供实际的结构化数据接口。
相比之下,NLWeb + Schema聚合的方案更加务实:它不仅声明了网站对AI访问的态度,还提供了一个高效的数据获取通道。AI Agent无需猜测页面内容的含义,因为所有实体和关系都已经以标准化的Schema.org格式准备好了。
对电商和内容站点的特殊意义
Schema聚合对两类站点的影响尤为显著:
电商站点:产品目录天然是结构化的。通过Schema聚合 + NLWeb,AI Agent可以直接查询"你网站上有哪些售价低于200元的蓝牙耳机"并获得精确答案。这意味着你的产品信息可以直接参与AI Agent的购物推荐流程,而不是等待传统搜索引擎爬取和索引。
内容出版站点:新闻网站、博客、知识库等内容密集型站点可以通过Schema聚合让AI系统快速理解整个站点的内容图谱。当用户向AI助手提问时,AI系统可以精准地定位到你站点中最相关的文章和作者。
保哥的优先级行动清单
基于以上分析,以下是建议的优先级行动清单:
第一优先级(本周就做):
- 更新Yoast SEO到27.1版本
- 启用Schema Aggregation功能
- 访问Schemamap端点验证输出是否正确
第二优先级(两周内完成):
- 审计全站Schema标记质量,修复断裂的实体关系
- 为所有Author添加
sameAs属性链接到外部权威来源 - 检查自定义文章类型的Schema覆盖情况
第三优先级(持续优化):
- 关注NLWeb项目的进展,评估是否在自己的站点上部署NLWeb实例
- 建立Schema数据的版本控制机制,像管理代码一样管理结构化数据
- 模拟AI Agent的对话式查询,测试你的Schema数据能否支撑准确的回答
技术展望:Agentic Web的基础设施正在成型
回顾这几年的技术演进,可以看到一条清晰的脉络:
- 2011年:Schema.org诞生,搜索引擎开始理解网页的语义
- 2019年:Yoast率先在WordPress中实现了站点级Schema图谱API
- 2024-2025年:MCP协议标准化,AI Agent的工具调用有了统一的接口规范
- 2025年中:微软推出NLWeb,网站可以直接作为AI Agent的数据源和交互端点
- 2026年3月:Yoast推出Schema聚合,让上亿WordPress站点可以一键接入Agentic Web生态
这不是单一功能的更新,而是一整套Web基础设施的重构。Schema.org是数据层,NLWeb是协议层,MCP是接口层,而Schema聚合是让这些技术栈对普通站长可用的"最后一公里"。
保哥认为,2026年将是Agentic SEO元年。那些今天就开始构建高质量结构化数据、并主动接入AI Agent生态的站点,将在未来的AI搜索格局中占据先机。
这不再是"要不要做Schema"的问题,而是"你的Schema数据质量够不够撑得住AI Agent的查询"的问题。
常见问题解答
Schema聚合功能是Yoast SEO付费版独有的吗?
不是。Schema Aggregation是Yoast SEO 27.1+免费版即可使用的功能,不需要购买Premium版。这与Yoast的战略定位有关——他们希望让所有WordPress站点都能接入Agentic Web生态,因此选择把这个基础设施级别的功能开放给免费用户。
启用Schema聚合会拖慢我的WordPress站点性能吗?
不会。Schemamap端点使用了5分钟级别的缓存(Cache-Control: max-age=300),重复请求不会命中数据库。即使是大型站点,首次生成聚合数据的开销也只在300毫秒以内,且对前台页面加载没有任何影响——聚合查询走的是独立的REST API路径,不在用户访问页面的关键路径上。
使用其他SEO插件(如Rank Math、SEOPress)的站点能用Schema聚合吗?
目前Schema Aggregation功能是Yoast独家。如果你使用其他SEO插件,需要等待对方推出类似功能或考虑迁移到Yoast。但从技术原理上看,Schemamap实现并不复杂——预计未来6-12个月内Rank Math、SEOPress、AIOSEO等主流插件都会推出对标功能。
启用Schema聚合后,AI Agent会立即开始爬取我的站点吗?
不会立即。需要1-4周的时间让AI爬虫发现新增的Schemamap端点。可以主动加快这个过程:把Schemamap的URL提交到Bing Webmaster Tools和Google Search Console;在LinkedIn、Twitter等社交平台发文宣布站点支持Schemamap;联系合作的AI Agent项目方主动告知端点地址。
启用Schema聚合后,传统的页面级JSON-LD还需要保留吗?
需要保留。Schema聚合是页面级JSON-LD的"上层聚合视图",但传统的页面级JSON-LD仍然是Google理解单个页面的关键信号。删除页面级JSON-LD会导致Google Rich Results失效、SERP的富媒体卡片消失。正确的姿势是两者并存——页面级JSON-LD服务传统搜索引擎,Schemamap服务AI Agent。
怎么验证AI Agent确实"读懂"了我的Schemamap?
有3种验证方法:第一,在ChatGPT/Claude/Perplexity中用具体的查询测试(如"网站xxx上某个作者发布了哪些文章"),观察回答准确性;第二,监控服务器访问日志中AI爬虫(GPTBot、ClaudeBot、PerplexityBot等)对Schemamap端点的访问频次;第三,部署一个NLWeb实例使用你的Schemamap作为数据源,做对话式查询的端到端测试。
Schema聚合对中文站点和英文站点的接入效果有差异吗?
有差异,但差异在收窄。当前AI Agent生态对英文Schema数据的支持更成熟,但中文Schema的支持在2025年已经显著改善。保哥实测中文站点启用Schema聚合后,ChatGPT和Perplexity对中文内容的"实体识别准确率"都有30-40%的提升。Gemini对中文支持仍有差距,但也在快速追赶。中文站点不应该因为这些差距而放弃接入。
权威参考资料
本文标题:《Schema聚合实战:WP站5步接入Agentic Web》
本文链接:https://zhangwenbao.com/yoast-schema-aggregation-agentic-web-seo.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0