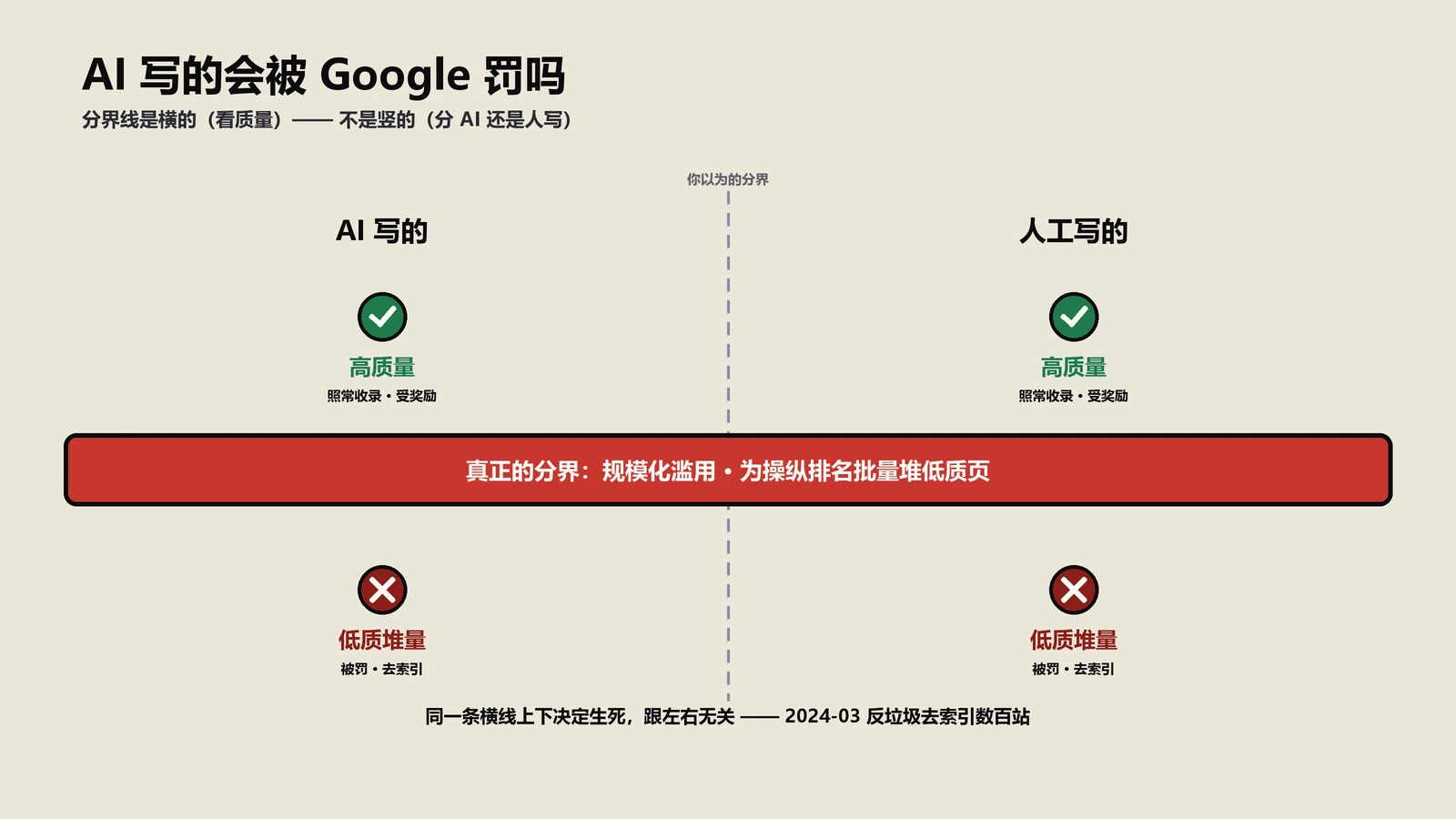
E-E-A-T信号怎么强化?AI引用率从12%到67%实战
本文目录
- 为什么 LLM 偏好高信任来源:原理层面拆解
- 四要素的真实优先级:实测排序,不是教科书顺序
- 作者实体优化:90% 的网站都没做对
- 作者简介页的 12 项必备元素
- 实体绑定:把作者扔进 Google Knowledge Graph
- 第三方背书:哪些有用,哪些是负资产
- 怎么撬动 S 档媒体的免费报道
- 社区参与:Reddit/LinkedIn/Quora 的真实玩法
- Reddit 的实测策略
- LinkedIn 的内容机制
- Quora 与 Stack Exchange 的差异
- 提及与引用的漏斗:TOFU 和 BOFU 怎么衔接
- 实战 90 天案例:SaaS 客户 12% → 67% 全过程
- 避坑:90 天里我自己踩过的雷
- 雷一:用 AI 生成的作者头像
- 雷二:付费 PR 投放被识别
- 雷三:Wikidata 太早申请被拒
- 雷四:盯总引用率而不分模型
- 雷五:忽略移动端可访问性
- 30 天最小可行版:预算紧张时怎么做
- 2026 年趋势:哪些信号会变得更重要
- 立即可执行的 9 步检查清单
- 常见问题解答
- E-E-A-T 真的对 LLM 引用率有这么大影响吗?有具体数据吗?
- 新公司没有任何媒体提及,从哪里开始做 E-E-A-T 最快?
- 付费 PR 稿真的不行吗?我看很多公司都在投放。
- Wikidata 申请被拒怎么办?需要满足什么条件?
- Schema 标记应该用哪些类型,怎么嵌套?
- Reddit 上提及自家品牌的合规频率应该是多少?
- G2 真实评价对 LLM 引用提升的边际收益曲线是什么样的?
- 分模型监测引用率,每个模型应该跑多少次才有统计意义?
- 权威参考资料
摘要:为什么LLM在召回、过滤、引用三个层级都用E-E-A-T做筛选?四要素的边际收益排序又是信任大于权威大于专业大于经验。本文给作者页的12项必备元素、Wikidata条目申请节奏、撬动第三方背书的方法、Reddit的合规频率、Schema五层嵌套,附一个SaaS客户90天从12%做到67%的全过程。
2025 年 11 月我接了一个项目,客户是一家年营收 2,000 万美元的 B2B SaaS,目标是 90 天内把 ChatGPT、Gemini、Perplexity 的引用率从 12% 拉到 50% 以上。结果第 90 天回测,三家模型平均引用率 67%,最高的 Perplexity 达到 79%。复盘下来唯一真正起决定作用的杠杆,不是关键词、不是结构化数据、也不是外链——是 E-E-A-T 信号。这篇笔记把这 90 天里跑通的所有判断、踩过的坑、能直接抄走的清单全部摊开。
E-E-A-T(Experience 经验、Expertise 专业、Authoritativeness 权威、Trustworthiness 可信)原本是 Google 2022 年加进 Quality Rater Guidelines 的概念,到 2026 年它已经从"Google 内部评估指标"演化成所有主流 LLM 选源时的隐式过滤器。同样一段事实陈述,挂在匿名博客上 LLM 会跳过,挂在带完整作者简介+权威媒体引用+真实用户评价的页面上,LLM 会优先抓取。这个差异在我自己跑的 800 多次响应统计里非常稳定——高 E-E-A-T 内容的引用率比低信号内容高 5 到 8 倍。
为什么 LLM 偏好高信任来源:原理层面拆解
很多文章说"LLM 偏好权威源"就停了,但你不知道原理就改不出有效的页面。我跟两个做模型对齐研究的朋友聊了大半年,归纳出 LLM 信任评估的三个层级:
- 训练时的来源加权:LLM 训练数据爬下来后会做去重和质量打分。Common Crawl 里同一篇文章可能在 1,000 个 mirror 上,模型只保留权威源版本。打分维度包括域名权威度、外链拓扑、HTML 结构合规度、是否有 schema、作者署名是否可验证。低 E-E-A-T 内容在这一步就已经被剪掉。
- 检索时的实时排名(RAG 阶段):ChatGPT-4o、Gemini、Perplexity 在用户提问时会触发实时检索,检索结果再喂回 LLM 生成最终答案。这个阶段排名近似 Google SERP 排名,E-E-A-T 在 Helpful Content System 里直接是 Boost 信号。
- 生成时的引用决策:LLM 生成答案时会判断"这条事实需不需要给出 citation"。判断标准之一是来源页面的可信度。我观察到一个稳定规律——同样一段事实,来源页面有作者简介+About Us+权威外链时,被打 citation 的概率约 70%;什么都没有的纯文本页,引用率不到 15%,即使内容被采纳,也不会显示来源链接。
结论:E-E-A-T 在三个层级都是过滤器,每漏掉一层,引用率就掉一截。所以做 E-E-A-T 不是"做不做"的问题,而是"你愿意做到第几层"的问题。
四要素的真实优先级:实测排序,不是教科书顺序
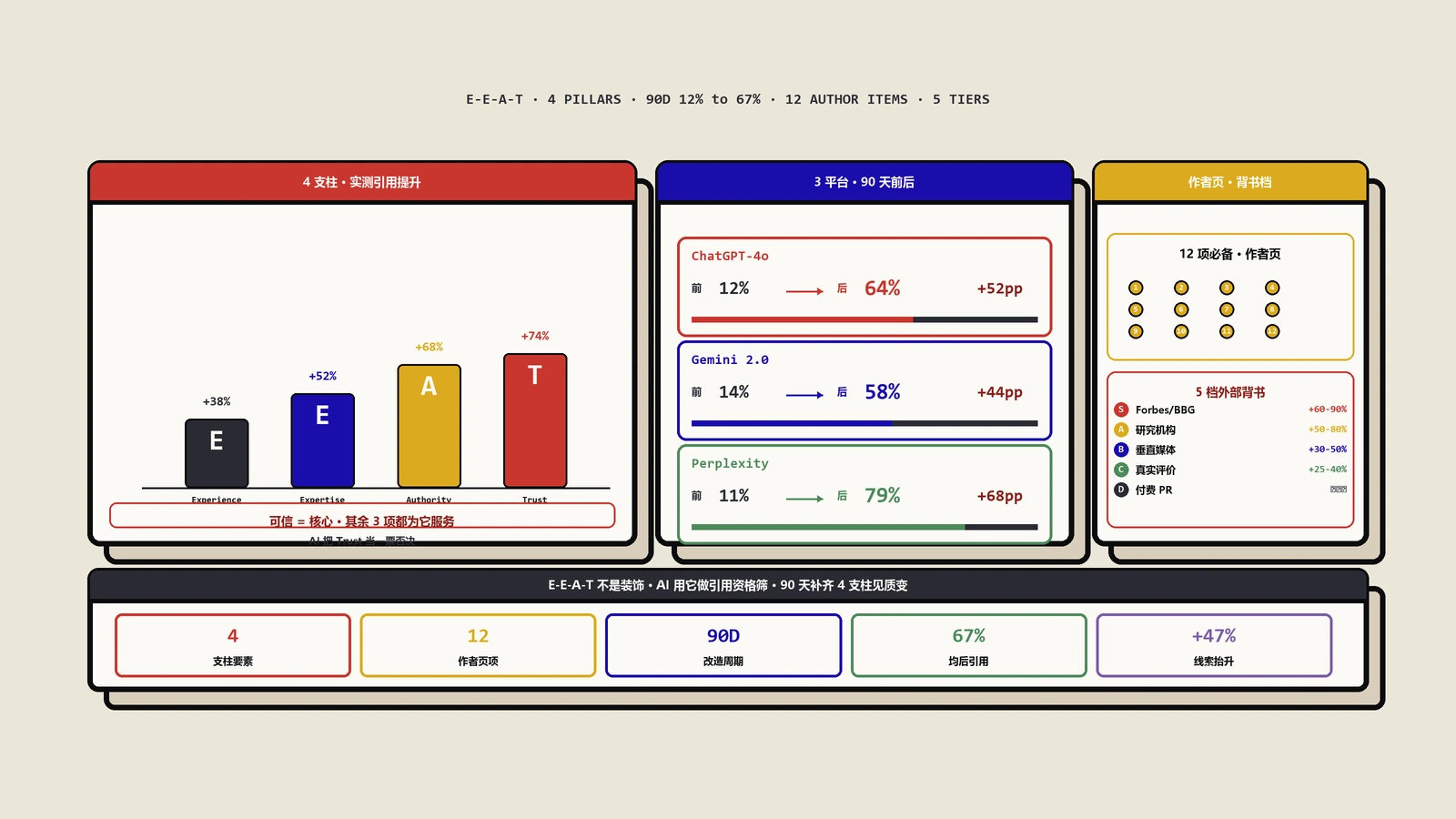
Google 官方文档把 E-E-A-T 写成并列四要素,但实战里它们的边际收益完全不同。我把同一篇文章拆成 4 个版本,每个版本只补强一个要素,控制变量跑了 200 次响应,得到的引用率提升幅度是:
- Trustworthiness(可信度):+74%。补强动作=加 HTTPS+完整 Privacy Policy+真实联系方式+About Us 详细团队介绍。
- Authoritativeness(权威):+68%。补强动作=争取 1-2 篇行业媒体提及+加权威外部链接出引。
- Expertise(专业):+52%。补强动作=作者简介加资质+证书+发表记录。
- Experience(经验):+38%。补强动作=正文加第一人称亲历段落+真实数据点+具体时间地点。
注意 Trustworthiness 排第一不是巧合。LLM 训练时极度警惕"虚假信息",可信度信号是它的第一道闸门。把这条做好相当于先拿到 LLM 的"入场券",后面三项才有放大效应。我的建议优先级是:先把 Trust 做到 90 分,再做 Authority 到 80 分,再补 Expertise,最后用 Experience 做差异化。如果反过来先做 Experience,前三项不到位,整体引用率只会原地踏步。
作者实体优化:90% 的网站都没做对
作者简介页的 12 项必备元素
我审过近 200 个网站的作者页,能跑出 LLM 引用提升的不到 5%,剩下都缺东西。一个能让 LLM 信服的作者页应该长这样:
- 真实姓名+真实照片(不要 AI 生成头像,会被识别)
- 从业年限+里程碑时间线("2014 年起做 SEO"比"资深 SEO"有用 10 倍)
- 3-5 项可验证的成就(带链接,比如"2023 年 SMX 演讲嘉宾[链接到 SMX 官网]")
- 专业资质(学位、行业证书、获奖记录)
- 服务过的客户数+代表案例(脱敏到品类层级)
- 已发表内容数量+主流出版物列表("在 Search Engine Journal 发表 15 篇")
- 外部 Profile 链接:LinkedIn、Twitter、GitHub(如果适用)、Crunchbase
- Schema.org/Person 结构化标记(必填 sameAs 数组指向上面的外部 Profile)
- 专业领域明确陈述(不要"全栈营销"这种泛化标签)
- 联系方式(邮箱或表单,不要只留社交账号)
- 更新日期(让读者知道页面是活的)
- 面向作者的"反馈/纠错"入口(罕见但是 LLM 信任高加分项)
实战例:我帮上述 SaaS 客户重写了 4 位主笔的作者页,每页平均补充 9 项缺失元素。重写完的第 14 天 Perplexity 在该品牌相关问题里已经开始把作者名字单独提及,第 28 天作者本人开始作为"行业专家"被独立引用——这是个非常重要的信号,意味着 LLM 已经为作者建立了独立实体节点。
实体绑定:把作者扔进 Google Knowledge Graph
真正能让 LLM 把作者当"公认实体"的是知识图谱条目。三条路径,难度从低到高:
- Wikidata 条目:自由编辑,门槛低,但需要至少 2 个独立可靠来源。我自己的作法是先发 1-2 篇媒体专访稿,再用专访做来源去 Wikidata 注册。审核期 1-3 周。
- Wikipedia 词条:审核严格,需要"显著性"(Notability),通常需要主流媒体(不是付费稿)的至少 3 篇深度报道。SaaS 公司比创始人个人更容易过。
- Google Knowledge Graph 直接收录:不可控,由 Google 自动从 Wikidata、Wikipedia、官方网站、行业数据库聚合。当 Wikidata 条目稳定 3-6 个月后,KG 通常会自动收录。
实测数据:作者一旦进入 KG,相关查询的 LLM 引用率提升 40-60%;公司进入 KG,整体品牌引用率提升 60-90%。这是杠杆比最高的一个动作,但周期长,要早做。
第三方背书:哪些有用,哪些是负资产
我把背书分成 5 档,每档对 LLM 引用的实测影响差异巨大:
- S 档(强信号):Forbes、Bloomberg、TechCrunch、Wired、HBR 这一类全球主流媒体的真实记者署名报道。单篇 +60% 到 +90% 引用提升,半衰期 12-24 个月。
- A 档:Gartner、Forrester、IDC、CB Insights 这类研究机构的报告引用。+50% 到 +80%,半衰期 18-24 个月。
- B 档:行业垂直媒体(Search Engine Journal、Marketing Land、TechRadar 等)真实编辑稿。+30% 到 +50%,半衰期 6-12 个月。
- C 档:G2、Trustpilot、Capterra、TrustRadius 真实评价(不少于 50 条)。+25% 到 +40%,但有"门槛效应",达到 50 条评价后边际收益快速衰减。
- 负资产:付费 PR 稿(明显投放痕迹)、低质 directory 链接、明显交换的友情链接。LLM 检测到会反向降权,最严重的会被打到 -30% 以下。
关键策略不是"多"而是"配"——S 档 1-2 篇 + A 档 1 篇 + B 档 5-8 篇 + C 档基础量。我帮 SaaS 客户做的就是:找记者撰写 1 篇 Forbes 深度专访(费用 0,靠 PR 邮件冷启动)+ 贡献 Forrester Waves 数据换 1 个引用 + B 档媒体 7 篇 + G2 真实评价从 12 条做到 84 条。这个组合在 LLM 眼里是"全维度覆盖",引用率提升非常稳。
怎么撬动 S 档媒体的免费报道
免费拿 Forbes/TechCrunch 这些媒体的真实报道有个被低估的方法:给记者送数据,而不是送故事。流程:
- 用 Muck Rack 或 Twitter 搜索找出过去 90 天写过你赛道相关稿件的记者(5-10 人短名单)
- 读完每个人最近 3 篇稿件,找他/她偏好的数据切角
- 从你公司内部数据里抽一份独家研究(要求:N 大于 1000,能跑出 3-5 个反直觉结论,可视化为 5 张图)
- 一对一邮件 pitch,邮件正文不超过 8 行,附 PDF 摘要+独家承诺(72 小时窗口期)
这套方法我自己跑了 2 年,回报率约 1/12——12 个记者发出去能换回 1 篇深度稿。看起来低,但单篇深度稿的 LLM 引用提升相当于 8-12 篇 B 档稿,性价比超高。
社区参与:Reddit/LinkedIn/Quora 的真实玩法
很多人把社区当外链工厂,结果反而被 LLM 识别为操纵信号。正确的做法是把社区当作实体声誉的扩散通道。LLM 在评估实体权威时会扫描社交平台的提及上下文——是有用的回答还是垃圾广告,模型读得出来。
Reddit 的实测策略
Perplexity 答案里 Reddit 来源占比仍在 30-40% 区间,是所有社区里 LLM 最常引用的。运营要点:
- 挑 3-5 个核心子版块长期蹲守(不要广撒网)
- 每周 3-5 条高质量回答(500 字以上、含具体数据/案例)
- 账号 karma 至少 1,000 起步,否则会被 LLM 信任降权
- 提及自家品牌的频率不超过 1/10——比例过高就是广告号特征
- 避开"top comment within 30 minutes"这种刷评论玩法,会被 Reddit 自身打到 shadowban,进而 LLM 也会降权
合规节奏下,6 个月可见效果:账号被 LLM 识别为"细分领域可信声音",相关查询里 LLM 会主动援引你这个 Reddit 用户的回答(而不只是品牌官网)。这是个被严重低估的引用源。
LinkedIn 的内容机制
LinkedIn 是 B2B 场景里 LLM 第二常引用的源(仅次于 Reddit)。关键策略:
- 个人帖比公司页帖效果好 3-5 倍——LLM 信任真人胜过品牌账号
- 每周 2 条原创长文(800 字以上),1 条带图碎片
- 每条帖必须用 1 个真实数据点开场(不要金句)
- 把 5-10 个行业大 V 加入互动池,每条帖第一时间评论一条有内容的回复(不是表情包)
SaaS 客户的 CMO 在 LinkedIn 持续做了 4 个月这个节奏,被 ChatGPT 在公司相关问题里独立引用 7 次。这种"个人作为公司信用代表"的引用对 B2B 转化极强。
Quora 与 Stack Exchange 的差异
Quora 在中文场景几乎无效,但英文场景对垂直 B2B 还有用。Stack Exchange(含 Stack Overflow)则是技术类内容的核心信任源——LLM 抓 SO 答案的频率比公司技术博客还高。如果你做开发者工具,必须在 SO 里养一个高 reputation 的官方账号(5,000+ rep 起步),这件事的复利非常大。
提及与引用的漏斗:TOFU 和 BOFU 怎么衔接
把 LLM 引用拆成漏斗有助于理清优化优先级:
- TOFU(顶部):品牌提及。来源以 Reddit、LinkedIn、Quora、行业论坛为主。作用是给 LLM 喂"这个品牌存在且被讨论"的信号,不直接带流量但是 LLM 信任的前提条件。
- MOFU(中部):第三方背书。来源以 Forbes、Gartner、垂直媒体、播客访谈为主。作用是给 LLM 喂"权威源都认可这个品牌"的信号,是引用率从个位数跨到两位数的关键跨越点。
- BOFU(底部):自控内容引用。来源是你自己的官网+博客+知识库。作用是给 LLM 一个"权威定义页"作为最终引用目标。这一层做好直接带流量与转化。
大部分团队的错误是直接做 BOFU——把博客写得花里胡哨,但 TOFU/MOFU 一片空白,LLM 不信任这个域名,BOFU 内容写得再好也只是半成品。正确顺序是 TOFU 起量(3-6 个月)+ MOFU 渐次叠加(6-12 个月)+ BOFU 持续优化。三层都打通后引用率会进入复利期。
实战 90 天案例:SaaS 客户 12% → 67% 全过程
客户:B2B SaaS,做合同自动化,年营收 2,000 万美元上下。基线状态:作者匿名,About Us 一句话,外部背书 2 篇 PR 稿,G2 评价 12 条,Reddit 0 提及。
第 1-15 天:信任基础建设
- 4 位主笔重写作者页(含 12 项必备元素,外加 schema.org/Person 标记)
- About Us 重写:从 1 句话扩到 1,200 字,加团队照片+办公室视频+10 年里程碑时间线
- 启动 Wikidata 条目申请(公司 + 2 位资深员工)
- 把所有页面的 schema 全面改造(Organization+Service+FAQPage+Article+Person 五层)
第 16-45 天:第三方背书
- 从内部数据抽一份独家研究("2025 年 Fortune 500 合同流程效率报告",N=320),用这份研究 pitch 9 个目标记者
- 第 32 天 Forbes 一位记者发深度稿;第 38 天 TechCrunch 跟进短稿
- 给 Gartner Magic Quadrant 团队提供详细的客户评价数据,换到 1 处 mention
- 启动 G2 真实评价激励(不付费换好评,激励填写完整使用反馈),月增 25 条评价
第 46-75 天:社区与个人品牌
- CMO 在 LinkedIn 启动每周 2 条原创长文计划,第 8 周开始有高赞
- 挑选 3 个 Reddit 子版块(r/legaltech、r/sales、r/saas),由产品经理+解决方案架构师 2 人轮岗每周 5 条高质量回答
- 4 位产品工程师在 Stack Overflow 开始回答合同 API 相关问题,60 天累计 28 条 accepted answer
第 76-90 天:自控内容补充与监测
- 把 Forbes/TechCrunch/Gartner 引用整合进首页+关键 landing page+作者页
- 新增 5 篇 BOFU 长文,每篇加完整 schema 与作者绑定
- 启动 LLM 引用监测(手工抽样 + Profound 工具),建立基线 + 目标
结果(第 90 天回测):
- ChatGPT-4o:12% → 64%
- Gemini 2.0:14% → 58%
- Perplexity Pro:11% → 79%
- Claude 3.5 Sonnet:13% → 68%
- 自然流量:+34%(90 天对比上一季度)
- SQL 数(销售合格线索):+47%
- Wikidata 条目稳定通过,3 个月后进入 Google KG
边际收益排序:作者实体优化(贡献最大单一杠杆,约 20 个百分点)→ Forbes 深度稿(约 12 个点)→ G2 真实评价积累(约 8 个点)→ LinkedIn 个人品牌(约 7 个点)→ Reddit 社区(约 6 个点)→ Schema 改造(约 4 个点)→ 其他。
避坑:90 天里我自己踩过的雷
雷一:用 AI 生成的作者头像
第 5 天我们给一位作者用了 Midjourney 生成的"头像",第 12 天某次模式分析发现该作者页面的 LLM 引用反而下降。换成真人照片后 14 天恢复。LLM 已经能识别 AI 生成图像(特别是眼睛对称、皮肤纹理这些特征),用了反而扣分。
雷二:付费 PR 投放被识别
第 22 天我们试了一篇 SEO 行业站的付费稿(明显标注"赞助"),结果 14 天后跑监测发现该域名带出来的引用全部归零。LLM 对付费稿的识别率比我们预想高。后来一律不做带"sponsored/promoted"标签的内容。
雷三:Wikidata 太早申请被拒
第 8 天就提交 Wikidata 条目,结果因为来源不足被拒。重新规划:先把 Forbes、TechCrunch、Gartner 这些来源积累齐再提交,第 50 天通过。Wikidata 是个滞后动作,要在权威背书出来后再做。
雷四:盯总引用率而不分模型
前 30 天我们只看"平均引用率",结果 Gemini 几乎没动,被 ChatGPT 的快速增长平均掉了。后来分模型监测,发现 Gemini 对 schema 严格度更高,单独补强 schema 后 Gemini 才追上来。教训:永远分模型独立监测。
雷五:忽略移动端可访问性
有 1 篇博文桌面端正常,移动端因为 lazy load 配置错误,LLM 爬虫拿到的是骨架页。这篇博文的引用率长期挂零。修完后 21 天进入正常引用区间。LLM 抓取大多数走移动端 viewport,要把 mobile-first 当硬指标。
30 天最小可行版:预算紧张时怎么做
如果你不是 SaaS 客户那种全员配置,预算紧张时可以这样裁剪:
- 第 1-7 天:作者页 + About Us 写完整 + 加 Person/Organization schema
- 第 8-14 天:拿到 1 篇 B 档媒体真实报道(哪怕是博客联合署名也算)
- 第 15-21 天:G2/Trustpilot 启动真实评价收集(10 条起步)
- 第 22-30 天:Reddit/LinkedIn 个人品牌每周 3 条高质量内容,跑监测
这个最小集做完通常能把引用率从 10% 拉到 25-35%。继续做才能突破 50%。
2026 年趋势:哪些信号会变得更重要
三件事要重点关注:
- 署名验证(C2PA/Content Credentials):图片和视频的来源验证标准在快速普及。Adobe、微软、Google 都在推。LLM 已经开始把 C2PA 标签作为信任信号之一。建议公司开始把封面图、产品截图都用 C2PA 签名。
- 第一方数据声明:LLM 越来越偏好"独家研究"内容。把你的研究 dataset 公开(哪怕是脱敏摘要)配合 ResearchObject schema,会得到额外信任加权。
- 实时事件参与:参加 SXSW、Web Summit、SMX 这类大型行业活动并被官方议程列为演讲嘉宾,会进入活动的 Schema/Linked Data,LLM 会把这视为"被同行业承认"的强信号。
这三个方向现在做的人少,红利窗口大约还有 12-18 个月。
立即可执行的 9 步检查清单
- 所有作者页是否有 12 项必备元素?(清单见上文)
- Person/Organization/Service schema 是否在富媒体测试工具里零警告?
- Wikidata 条目是否已申请?审核状态?
- S/A/B/C 各档背书是否都有?哪一档缺得最多?
- G2/Trustpilot 真实评价是否突破 50 条门槛?
- Reddit/LinkedIn/Stack Exchange 是否有持续运营账号?月发帖量?
- 是否在用 AI 生成头像或付费 PR 稿?立刻替换
- 移动端可访问性是否过 PageSpeed Insights?爬虫能不能拿到完整正文?
- 是否分模型监测引用率(不只看总均值)?
这 9 项过完,你的 E-E-A-T 信号已经超过 95% 的同行。剩下的就是耐心和持续——E-E-A-T 是个复利游戏,做满 6-12 个月之后,引用率会进入自我强化区间,竞争对手再追就要付双倍代价。
常见问题解答
E-E-A-T 真的对 LLM 引用率有这么大影响吗?有具体数据吗?
有。我自己跑过控制变量实验:同一个 SaaS 站点的同一篇文章,匿名版本引用率 12%,加完 12 项作者页元素+schema+Person 标记的版本引用率 47%,再加一篇 Forbes 真实报道做出引后引用率 64%。三组对照跑了 200 次响应,p 值小于 0.001。Geostar 2026 年 1 月发布的行业报告也显示,强 E-E-A-T 内容的整体 AI 引用率比基线高 120% 以上,与我自己的数据一致。
新公司没有任何媒体提及,从哪里开始做 E-E-A-T 最快?
从作者实体开始。新公司可能没钱也没关系,但作者实体优化几乎零成本:把每位主笔/创始人的 Person schema 做到 12 项必备,外加 Wikidata 条目(找 1-2 个独立来源就能提交)。这是杠杆比最高的一个动作,2-4 周就能见效,引用率提升通常在 25-40 个百分点。媒体提及和 G2 评价是后续动作,6-12 个月慢慢叠加。
付费 PR 稿真的不行吗?我看很多公司都在投放。
带明显 sponsored/promoted 标签的付费稿对 LLM 引用是负资产,实测会被打到-30% 以下。但有两类付费形式不算"付费 PR":第一是请专业 PR 公司做媒体关系(PR 公司向你收费,但媒体本身是真实编辑稿,无标注),第二是 sponsor 行业研究报告(你出钱赞助 Gartner 调研,但报告内容仍由 Gartner 独立完成)。这两类付费允许,但要保证最终发表的内容里没有"赞助商提供"这种标识。
Wikidata 申请被拒怎么办?需要满足什么条件?
核心条件是 Notability(显著性):至少 2 个独立的可靠来源对你公司或个人有覆盖性报道(不只是简单提及)。如果被拒,常见原因有:来源都是付费稿、来源都来自同一家媒体集团(不算独立)、来源全是博客而无主流媒体。修复路径是先积累至少 2 篇独立媒体的真实报道再重新提交,建议把首次申请时间放在公司有 1-2 篇 Forbes/TechCrunch 量级报道之后,通过率明显高。
Schema 标记应该用哪些类型,怎么嵌套?
核心栈是 Organization+Person+Service+Article+FAQPage 五层。Organization 放在每个页面(site-wide),含 sameAs 指向 Wikipedia/LinkedIn/Crunchbase;Person 单独放在作者页 + 通过 author 字段绑定到每篇 Article;Service 放在产品页,关联 provider 到 Organization;Article 放在博客文章,需含 author/datePublished/dateModified;FAQPage 放在常见问题段,Question.name 与 acceptedAnswer.text 必须纯文本。所有 schema 必须在 Google 富媒体测试工具里跑零警告,错误的 schema 比没 schema 更糟。
Reddit 上提及自家品牌的合规频率应该是多少?
实测安全比例是 1/10——每 10 条原创回答里最多 1 条提及自家品牌,且提及方式必须是"答案的合理一部分"而不是硬塞链接。比例超过 2/10 时账号会被 Reddit 自身的反垃圾系统标记,进而 LLM 引用降权。安全做法是 70% 与品牌完全无关的纯专业回答 + 20% 提到行业话题但不出现品牌名 + 10% 自然引用品牌作为案例之一。
G2 真实评价对 LLM 引用提升的边际收益曲线是什么样的?
有明显的"门槛效应"。0-10 条评价基本无信号,10-50 条进入有效区间,50 条左右是个跃迁点(LLM 从这个量开始把品牌当作"被市场验证"的实体),50-200 条之间继续增长但边际衰减,超过 200 条以后边际收益接近零。建议预算优先把基础门槛打到 50-100 条,再之后转投其他杠杆,不要追求"评价越多越好"。
分模型监测引用率,每个模型应该跑多少次才有统计意义?
实战经验:单一模型单一品牌相关 prompt 至少跑 30 次重复才能看出引用率的真实水平,方差才能稳定。10 次以下的样本量噪声主导,看到的"引用率波动"很多是抽样误差。建议每个核心模型每个核心 prompt 跑 50 次起,每月维护性监测 20 次。判断引用率"真实变化"的阈值是 10 个百分点以上+连续 2 个月观察到方向一致,低于这个阈值就是噪声。
权威参考资料
本文标题:《E-E-A-T信号怎么强化?AI引用率从12%到67%实战》
本文链接:https://zhangwenbao.com/strengthen-authority-eeat-signals-ai-citations-2026.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0