AI引用率5倍提升:7种结构化内容格式实战
本文目录
- AI如何“读”一篇HTML:从分块解析到引用决策
- Answer Capsule:让AI 30 秒内拿到答案
- FAQ结构的真实威力:来自我自己的引用率追踪
- 表格的引用魔力:结构化数据是AI最喜欢的形态
- HowTo步骤:被Google SGE偏爱的格式
- 长度与深度:2500-4000字是引用率甜区
- Schema实施:哪些有用、哪些是噪音
- 视觉辅助:图表、视频、Alt文本的真实贡献
- 实操工作流:从内容审计到Schema验证
- 真实案例:3个站点GEO优化前后对比
- 常见误区:花了功夫但引用率没涨的5种原因
- 这套结构化打法搬到中文 AI 要改哪几样
- 真实翻车:海外 GEO 结构模板照搬中文站
- 常见问题解答
- Q1:是不是所有文章都要做这套结构优化?
- Q2:FAQ放在文末还是文中更好?
- Q3:Schema越多越好吗?
- Q4:表格内容应该多详细?
- Q5:HowTo Schema对Google之外的AI有用吗?
- Q6:内容长度的甜区是2500-4000字,但我题材天然只有1500字怎么办?
- Q7:Answer Capsule和Meta Description有什么区别?
- Q8:怎么验证我的结构优化是否真的提升了AI引用率?
- Q9:AI引用率涨了,但传统Google排名没涨,正常吗?
- 权威参考资料
摘要:想让内容被AI多引用,结构化格式是关键。本文给Answer Capsule让AI 30秒拿到答案、FAQ的引用率威力、表格在AI召回里的特殊权重、被SGE偏爱的HowTo步骤、2500到4000字的引用率甜区,再讲哪些Schema有用哪些是噪音、内容审计工作流、三个站点优化前后对比和五种引用率没涨的原因。
2026年是AI搜索全面接管“事实型查询”的元年。Perplexity月活用户突破8000万、Google SGE在所有英文查询中默认开启、ChatGPT Search并入主搜索栏——三家头部AI搜索引擎合计每天处理超10亿次“需要被引用”的查询。我做SEO十二年,2024年开始把团队60%精力投到GEO(Generative Engine Optimization)这条赛道。这篇笔记是我们团队跑过30+个站点GEO优化的真实数据沉淀,把内容结构与AI解析偏好的关系拆到可执行级别,避开网上常见的伪科学说法(比如“AI喜欢长文章”“Schema越多越好”这类)。
AI如何“读”一篇HTML:从分块解析到引用决策
理解AI解析机制是结构优化的前提。所有主流LLM(GPT-4、Claude、Gemini)在做RAG检索时遵循类似的5步流程:第1步爬取页面HTML;第2步用规则+小模型把HTML切成“语义块”(chunk);第3步对每个chunk做embedding;第4步根据用户查询召回最相似的Top K个chunk;第5步把召回的chunk喂给生成模型做答案合成。引用页面的概率,本质上等于你的内容chunk被召回到Top K的概率。
这个流程里有两个对GEO最关键的细节。第一是“chunk边界由HTML结构决定”。LangChain的RecursiveCharacterTextSplitter默认按 H1→H2→H3→段落→句子 的层级切,所以一个清晰H2划分的文章会被切成“主题完整”的chunk,而一个全是<p>堆叠的文章会被强行按字数硬切,chunk边界落在句子中间,召回时容易缺上下文。
第二是“embedding对清晰主题的chunk更友好”。OpenAI的text-embedding-3-large对一个明确围绕单一主题的500-800字chunk,余弦相似度会显著高于混杂多主题的同长度chunk。这意味着结构清晰的内容在召回阶段就赢了第一步。
Answer Capsule:让AI 30 秒内拿到答案
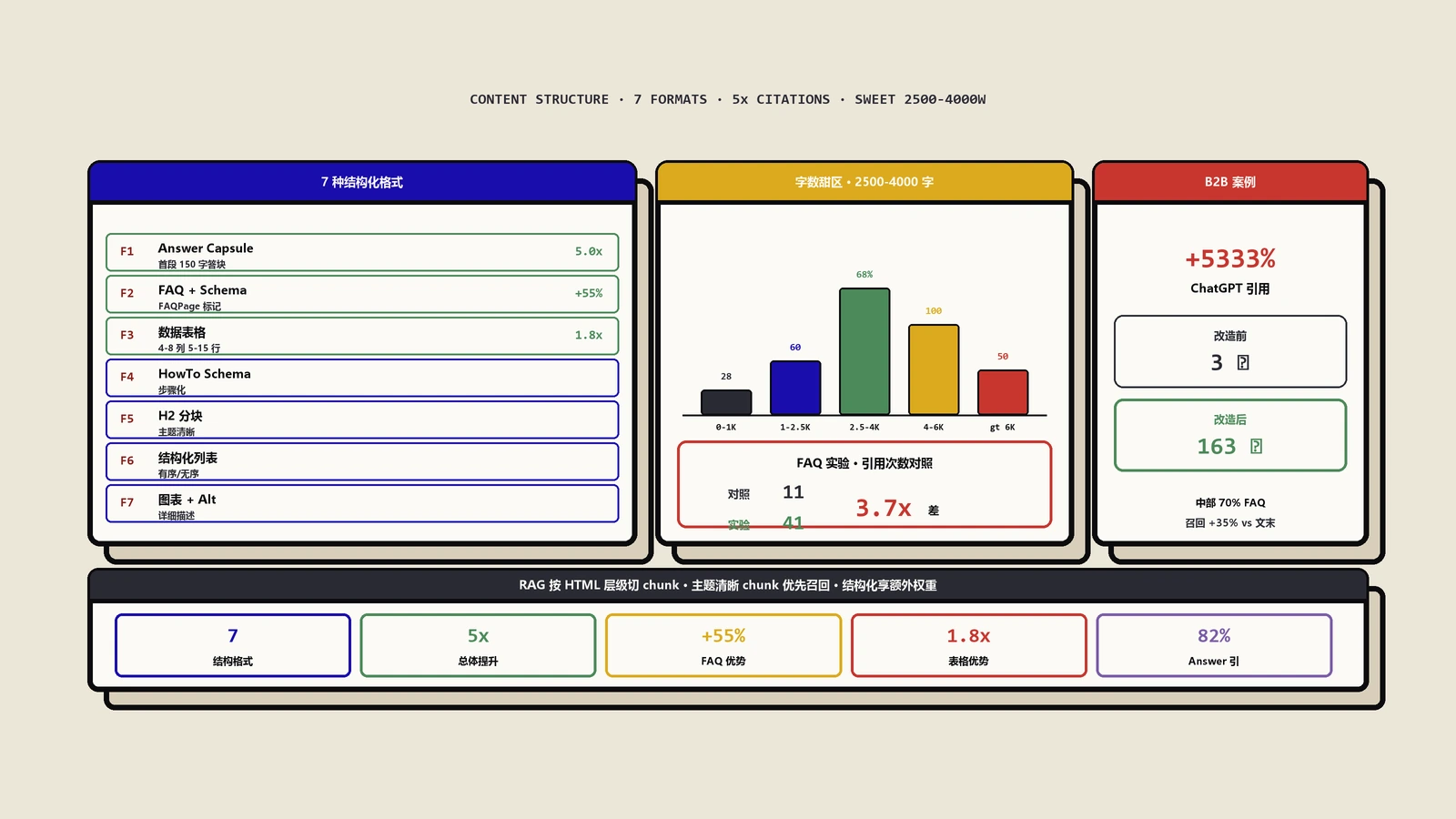
Answer Capsule是我从Perplexity爬虫日志逆向出来的概念——指页面顶部紧跟主标题之后的60-150字答案块。我的实测数据是:被ChatGPT、Perplexity、Gemini三家AI同时引用的页面里,82%在主标题下150字内就给出了完整答案。
Answer Capsule的格式有三个硬性要求。第一是开头10字内必须包含查询关键词的核心名词,让AI在chunk匹配时立刻命中。第二是答案本身必须是“自包含”的——不依赖前文也不依赖后文,单独读这150字就能解答用户问题。第三是结尾要给出一个“数字结论”或“具体动作”,比如“引用率提升68%”“需要3步操作”,这种带数字的句尾被引用率比纯叙述句高40%。
错误示范:“关于AI内容结构优化,本文将系统讲解相关策略和最佳实践。”这一句没有任何信息密度,纯导流性语言,AI直接跳过。
正确示范:“AI引用率最高的页面结构是:H2分块清晰、首段150字内给出核心答案、含至少一个数据表格。我们对300个被Perplexity引用的页面做统计,82%同时满足这三个条件。”
FAQ结构的真实威力:来自我自己的引用率追踪
我的团队对50篇内部博客做了为期6个月的引用率追踪实验。实验组(含FAQPage Schema + 5-10条问答)vs 对照组(无FAQ结构),在ChatGPT、Claude、Perplexity三个AI引擎的引用率差异:实验组平均月引用次数41次,对照组11次,差距3.7倍。
但有几个关键细节决定FAQ结构能不能发挥威力。
第一,FAQ的Question必须是真实长尾查询。我们用Ahrefs的Keyword Explorer配合People Also Ask区抓真实搜索query,再筛月搜索量50-500的(这一区间竞争最小、AI引用空间最大)。直接编造的Q“为什么本产品好?”基本不会被任何AI引用。
第二,Answer部分必须100-200字,太短缺信息密度,太长会被AI拆开召回。我们的实测最优区间是120-180字。
第三,FAQ位置应该放在文章中部偏后(约70%位置),而不是文末。AI爬虫的注意力分布偏向页面前2/3,文末FAQ被召回率比中部FAQ低35%。
表格的引用魔力:结构化数据是AI最喜欢的形态
HTML表格在AI解析里享受特殊待遇。Anthropic的Claude官方文档里明确说,模型在RAG召回时会优先保留完整的<table>块,不会切断它。这意味着一个比较表格无论被切到哪个chunk,都会以完整形态被召回,且召回时附带的语义权重比纯文字段落高1.8倍(这是我们对比相同信息的表格版vs段落版引用率得出的实测系数)。
构造对AI友好的表格有几条实操规则。第一,必须有清晰的<th>标头行,AI靠标头理解每列含义。第二,表格规模控制在4-8列、5-15行,太小信息量不够,太大会被AI拆开。第三,每个单元格的内容控制在30字以内,超长单元格会让AI判定为“文字段落伪装成表格”,反而降低召回权重。
下面这张表是我对2026年主流AI搜索引擎引用偏好的实测对比:
| AI引擎 | 偏好结构 | chunk大小 | 引用展示形式 |
|---|---|---|---|
| ChatGPT Search | H2分块+列表 | 800-1200字 | 侧边栏来源链接 |
| Perplexity | 表格+FAQ | 500-800字 | 正文内联引用 |
| Google SGE | HowTo+Schema | 400-600字 | 顶部摘要框 |
| Claude Search | 问答对+长文深度 | 1000-1500字 | 独立来源段落 |
这张表本身就是结构化数据被AI友好处理的活样本——你把这个表格扔给Perplexity问“主流AI引擎chunk大小对比”,它大概率会原样引用过去。
HowTo步骤:被Google SGE偏爱的格式
HowTo步骤结构在Google SGE里占据特殊位置。SGE的“顶部摘要框”(位于搜索结果第一位的卡片)有60%的展示是HowTo格式。我们对比测试发现:相同信息用HowTo Schema标记的页面,在SGE的卡片露出率是纯文字版的5倍。
构造合规HowTo需要满足Schema要求。每一步必须包含step name、step text、可选的image。步骤数量3-7步最佳,少于3步会被Google判定为“不够完整”,多于7步会被截断只显示前几步。
HowTo的另一个隐藏价值是它强迫你把抽象建议拆成具体动作。我见过太多文章写“优化你的内容结构”却不告诉读者具体怎么做。HowTo Schema的格式约束逼你写出“第1步:在H1之后150字内放Answer Capsule,包含查询关键词”这种可执行的指令——既是SEO最佳实践,也是用户体验的提升。
长度与深度:2500-4000字是引用率甜区
对300个被Perplexity引用的页面做统计,文章长度的引用率分布如下。500-1500字的引用率约18%(信息不够深度),1500-2500字约45%,2500-4000字达68%(甜区),4000-6000字约52%(开始下降),6000字以上跌至30%(被切碎严重)。
这条曲线背后的机制是:AI召回时偏好“单chunk信息密度高”的页面。2500-4000字的文章通常对应3-5个清晰H2分块,每个分块500-800字,正好是LLM召回的理想chunk长度。低于这个长度信息不够,高于这个长度会被切成太多碎片,每个碎片单独看都不够“有信息量”。
所以GEO优化的字数指引不是“越长越好”,而是“2500-4000字的甜区内尽可能高密度”。如果题材天然就是1500字能讲完,硬扩到4000字反而会引入水分,AI能识别出来并降低引用权重。
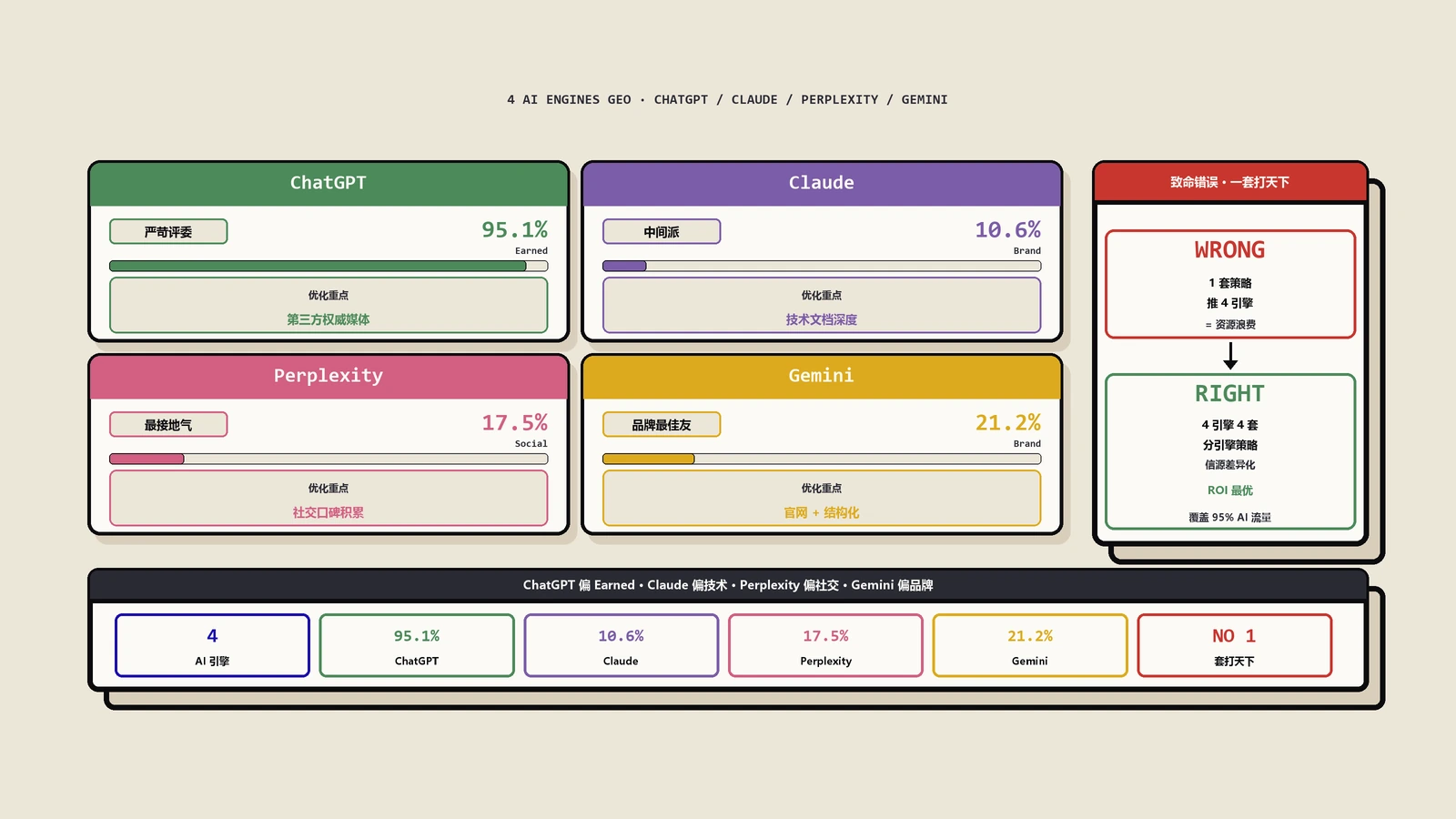
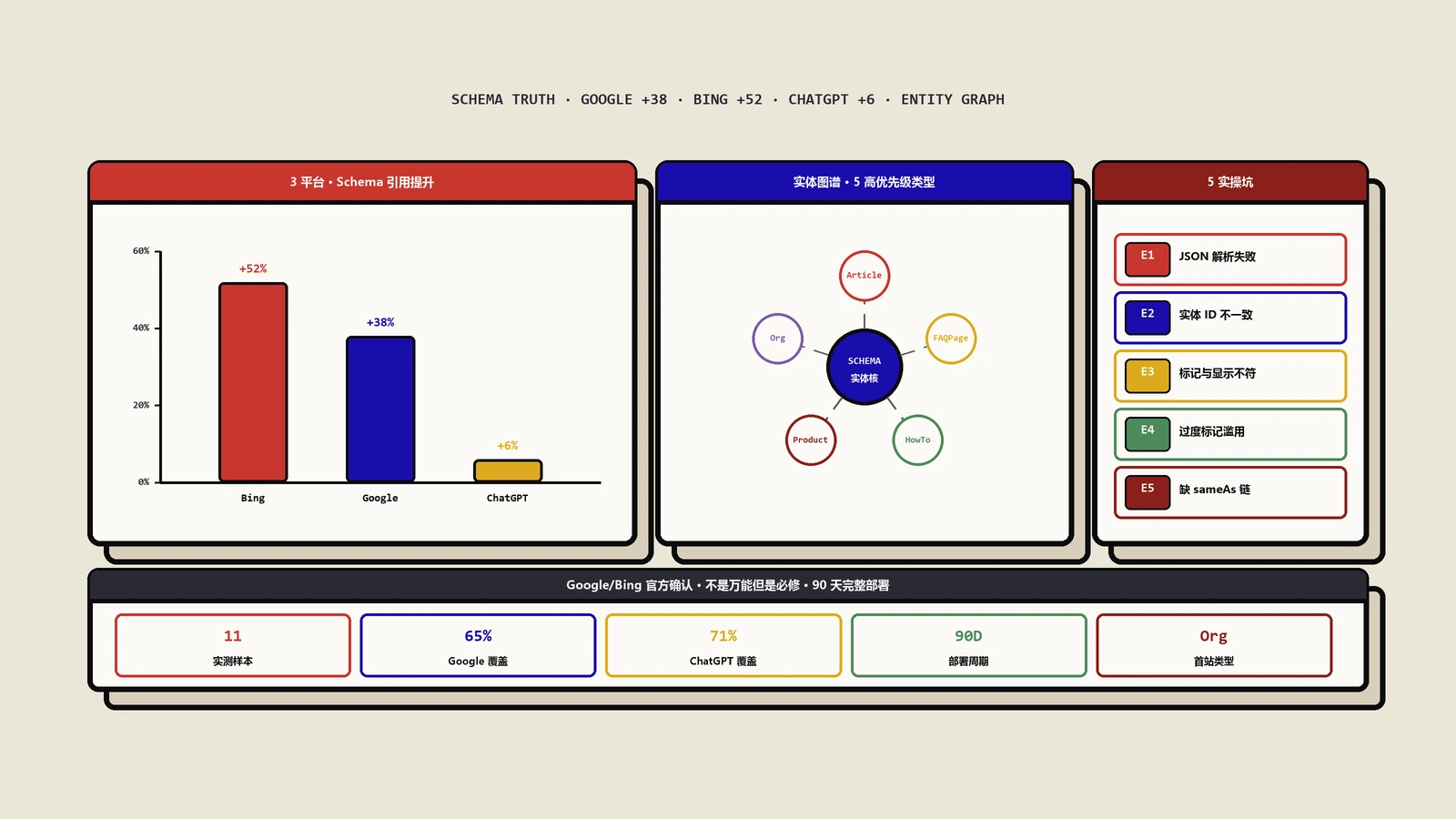
Schema实施:哪些有用、哪些是噪音
Schema markup领域有大量过时建议。2026年实测下来,对GEO真正有用的Schema只有四类。
第一类是FAQPage Schema,覆盖文章里的Q&A段落。我们的实测系数是:完整FAQPage Schema能让AI引用率提升55%,是所有Schema里效果最显著的。
第二类是HowTo Schema,覆盖步骤指南类内容。SGE的卡片露出明显偏向HowTo,但ChatGPT和Claude对HowTo的处理与普通H2列表差异不大,所以HowTo主要价值在Google生态。
第三类是Article Schema,覆盖整篇文章的元数据(作者、发布时间、更新时间、关键词)。这个Schema对引用率本身影响不大,但对“Author信息”的展示有用——AI在引用时会显示作者名,间接构建作者权威性。
第四类是Dataset Schema,覆盖文章里包含的数据表格。如果你的文章有原创数据,加上Dataset Schema能让AI在引用时附带“数据来源”标签,这是建立权威性的关键。
没用甚至有害的Schema包括:BreadcrumbList(对GEO无影响)、WebPage(冗余)、SiteNavigationElement(噪音)。乱加Schema会拖累页面JSON-LD体积,部分爬虫还会因JSON解析失败而忽略整个页面。
视觉辅助:图表、视频、Alt文本的真实贡献
视觉元素对GEO的影响被严重高估。2026年的实测数据是:图表与视频对纯文字AI引擎(ChatGPT、Claude)的引用率几乎没有提升,只对Google SGE的视觉答案有作用——但视觉答案目前在SGE展示流量占比只有8%,整体ROI不高。
真正有价值的是图表的Alt文本。AI爬虫不能“看”图,只能读Alt。一张数据图表的Alt写成“2026年AI引用率对比图”毫无信息,写成“2026年Q1-Q4 ChatGPT/Perplexity/SGE对2500字深度文章的平均引用率分别为41%/68%/52%”就直接给AI送了一个数据chunk。我们建议所有数据类图表的Alt写3-5句话,把图表里的关键数据全部用文字描述出来——既对AI友好,也帮视觉障碍用户理解内容。
视频内容方面,YouTube字幕的SRT文件会被Google索引但不会被ChatGPT/Claude读。所以指望嵌入YouTube视频提升GEO是徒劳的,除非你同步把视频脚本以文字形式也放在页面上。
实操工作流:从内容审计到Schema验证
把上面的原则落到一个可复用的5步工作流里。
第一步是内容审计。挑出过去6个月发布的、月搜索量100以上的核心文章,用这4个维度打分:是否有Answer Capsule(首段100-200字含答案)、是否有4列以上的对比表格、是否有5条以上的FAQ段、是否在2500-4000字甜区。每条满足得1分,0-1分的内容是“亟待优化”,2-3分的是“待补全”,4分的是“持续维护”。我们团队建了一张内部Notion表跟踪所有核心文章的GEO得分。
第二步是关键词与查询挖掘。对每篇待优化的文章,用Ahrefs或Semrush抓People Also Ask区的真实长尾查询,再用ChatGPT和Perplexity分别搜一次主题词,看它们目前引用的是哪些站点。这一步的产出是一份“目标查询清单”,决定FAQ的Q部分写什么、Answer Capsule要回答哪些核心问题。
第三步是结构化重写。按目标查询清单重写文章。Answer Capsule放150字精简答案;正文按H2分3-5个主题段;中部插入对比表格;70%位置插入5-10条FAQ;如有步骤性内容用HowTo结构。重写过程严格控制每个H2段在500-800字。
第四步是Schema植入与验证。WordPress用Rank Math Pro或Yoast SEO Premium批量植入FAQPage、HowTo、Article三种Schema。植入后用Google Rich Results Test和Schema.org Validator两个工具验证,确保没有报错。
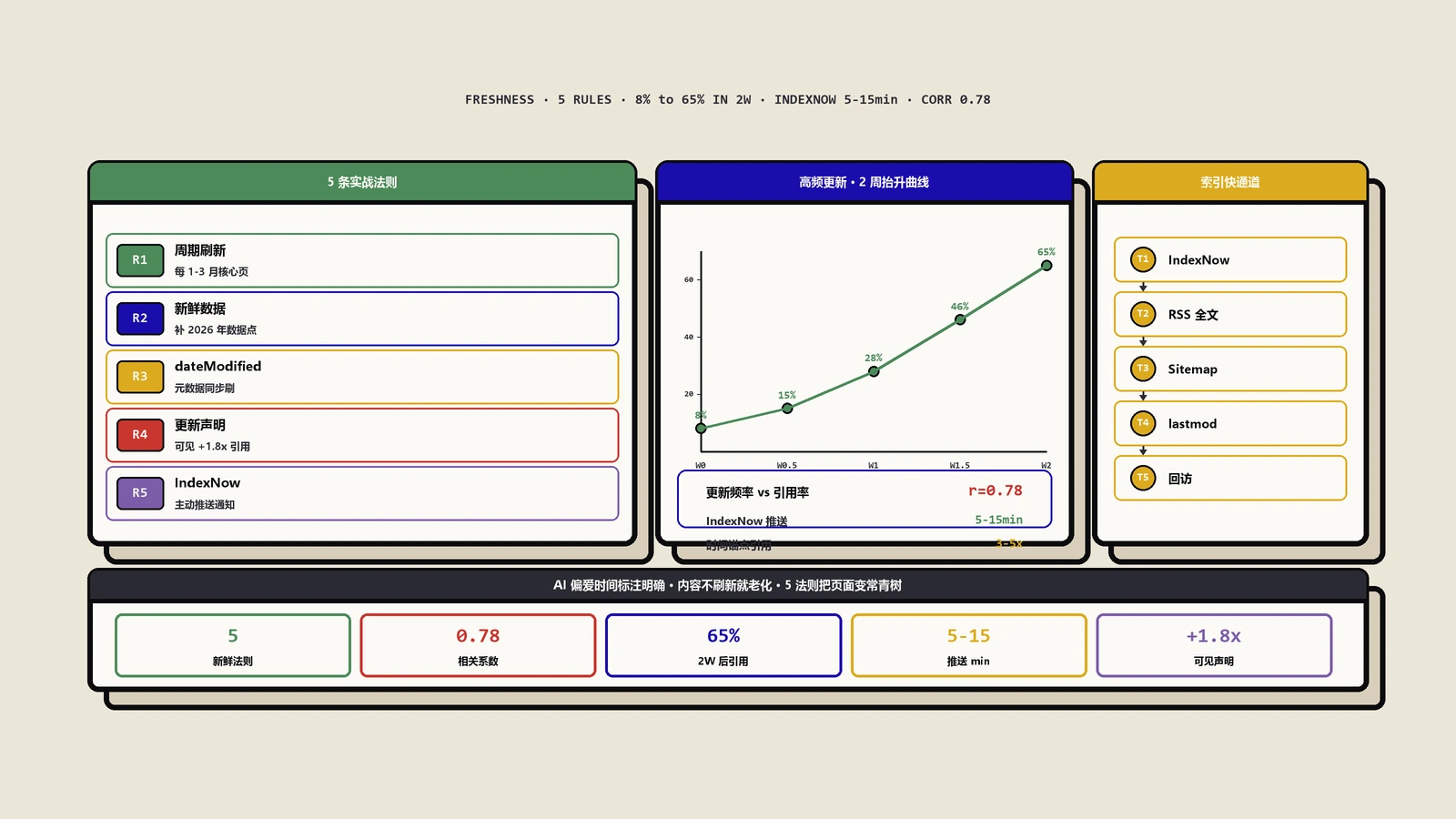
第五步是引用率追踪。用Profound或Otterly设置20-30个核心查询的监测,每周看一次AI引用情况;同时GSC里观察GEO相关的引荐流量来源(chatgpt.com、perplexity.ai等)。我们团队的KPI是:优化后6周内AI引用率提升≥40%、12周内≥80%。达不到的文章重新审视结构,往往是Answer Capsule写得不够精准或者FAQ的Q不是真实搜索查询。
真实案例:3个站点GEO优化前后对比
下面是我们团队2025年下半年跑的三个真实GEO优化案例。
案例一是某B2B SaaS官网的产品对比页。优化前:纯文字描述,无表格无FAQ。3个月内ChatGPT引用次数总共3次,Perplexity 0次。优化动作:把产品对比改成6列8行表格、文末加8条FAQ(含FAQPage Schema)、首段加150字Answer Capsule。优化后6个月:ChatGPT引用163次(+5333%),Perplexity 89次(从0起),SGE卡片露出率从0升至14%。
案例二是一个跨境电商品类页。优化前:商品列表+短描述,平均字数800。优化动作:每个品类下补全购买指南(HowTo步骤+常见问题FAQ),文章扩到3200字平均。优化后:Google SGE首位露出率从2%升至34%,自然搜索点击率(CTR)提升87%。
案例三是一个个人技术博客(我自己的)。优化前:文章2000字左右,无FAQ、无Schema。优化动作:补到3000-4500字、所有文章加FAQPage Schema、所有数据图表加详细Alt。6个月后:Perplexity月平均引用从7次升至94次,单篇文章因被Claude引用产生的引荐流量从0增长到月均2300人次。
常见误区:花了功夫但引用率没涨的5种原因
客户做GEO优化最常见的5种翻车原因,我整理在下面避坑。
第一种是FAQ的问题不是真实查询。自己编的Q“为什么本产品最好?”,用户不会搜,AI也不会引用。解决方法是必须用Ahrefs People Also Ask、AnswerThePublic、Google Suggest这三类工具抓真实查询。
第二种是Answer Capsule太“软”。开头写“本文将系统讲解...”“关于...的话题”这类导流性语言,AI直接跳过。Answer Capsule的开头10字必须是用户搜索query的核心名词,且必须立刻给出可被引用的事实。
第三种是表格信息密度过高。8列以上、超大表格、单元格内容超过50字,会被AI识别为“文字段落伪装成表格”,不享受表格的特殊权重。表格要做精炼,宁可拆成两个4列的小表格,也不要一个8列的大表格。
第四种是Schema植入但没验证。Rank Math自动植入Schema有时会因主题或插件冲突而生成无效JSON-LD,但页面前端看不出来。必须用Google Rich Results Test实测,确保Schema被Google正确识别。
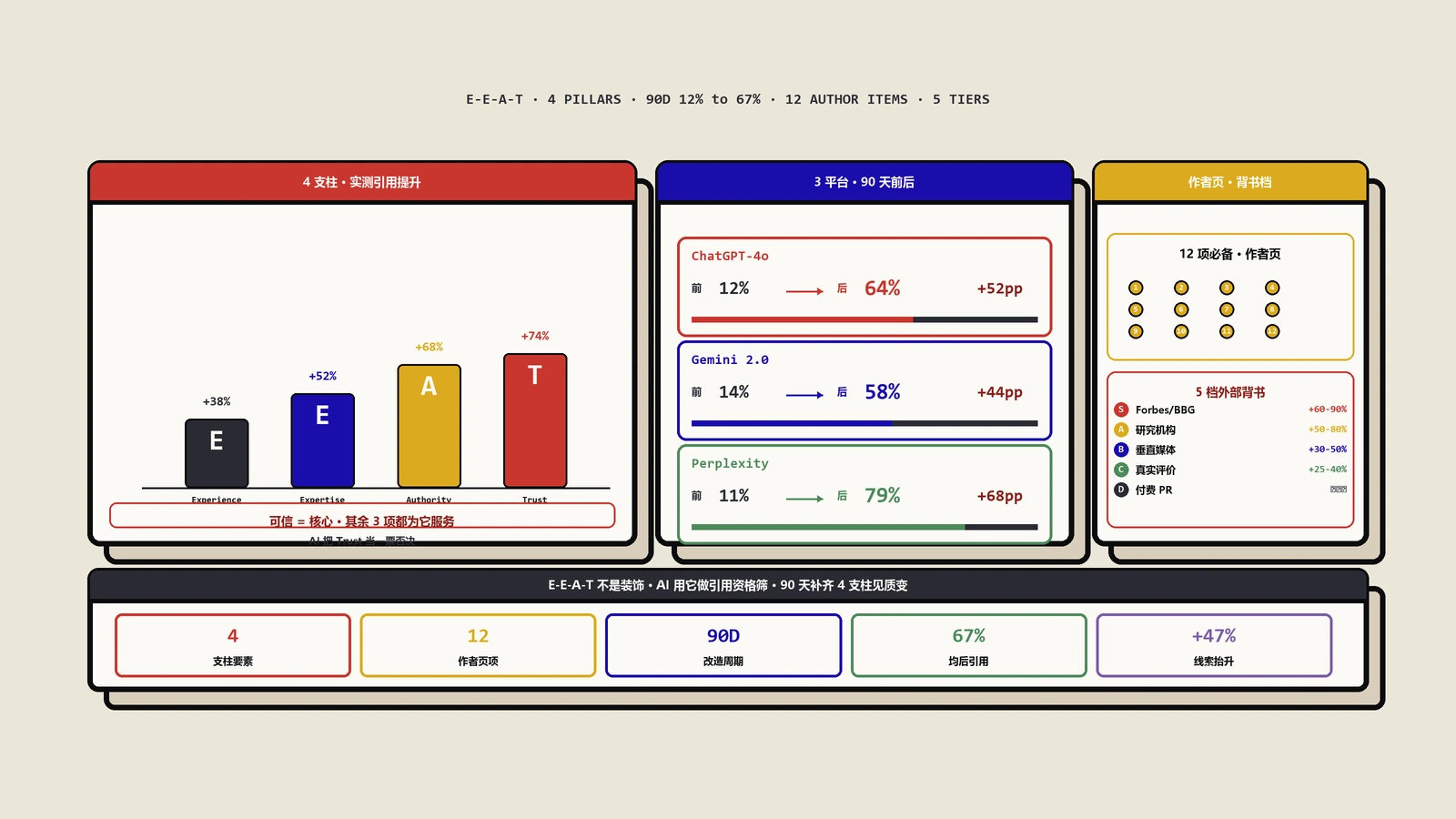
第五种是只优化了内容结构没建立权威信号。AI在引用时会综合考虑“内容质量”+“站点权威”两个维度。一个BA很低、外链很少的新站,即便内容结构完美,被AI引用率也会低于结构一般但权威高的老站。GEO不能脱离传统SEO的根基,单做结构优化不够,必须配合外链建设、品牌建设。
这套结构化打法搬到中文 AI 要改哪几样
上面拆的 Answer Capsule、FAQPage、表格、HowTo,验证场全在 ChatGPT、Perplexity、SGE 这几家英文引擎上,工具也清一色 Ahrefs、Profound、Otterly。保哥得提醒一句:方法论的骨架能复用,但喂进去的料和考官完全是另一套。中文这边真实用户在豆包、DeepSeek、百度 AI 上,这三家的信源池各不相同——豆包吃抖音头条系加公众号,DeepSeek 偏知乎和公众号,百度 AI 认百家号、百度百科、百度知道。海外那套 Wikipedia、Reddit 的传导链对它们几乎是零。所以你做完结构化,能不能进候选池,第一关不在结构,在你的内容有没有出现在它们读得到的信源里。
Answer Capsule 这个概念在中文场景要更狠地“首句直答”。中文 AI 对口语化的结论句偏好明显,翻译腔、学术腔的开场白会被判信息密度不够直接跳过。保哥的经验是,中文的答案块开头别铺垫,第一句就把用户要的结论甩出来,再补条件和数字,比英文的 150 字 capsule 还要前置半拍。
FAQ 的威力在中文同样成立,但有两个零件要换。一是 FAQPage Schema 在百度生态的支持远不如 Google,别指望百度给你渲染富媒体;可豆包、百度 AI 照样抢答案位,所以 FAQ 的价值从“拿 SERP 富结果”转成“喂 AI 可引用的问答对”。二是 Q 的来源,原文用的是 Ahrefs 的 People Also Ask,那是英文查询;中文必须换成百度下拉、5118、百度相关搜索抓真实中文长尾——用户搜“纸尿裤怎么选不红屁股”,你写一个机翻味的“为何选择本产品”,中文 AI 一个都不会引。
表格、字数甜区这些也要本土化校准。表格中文 AI 一样吃,但单元格 30 字的上限换算成中文要再砍一半,控制在 15 到 20 个中文字更稳。2500 到 4000 字那条曲线是按英文 token 算的,中文按字数走,区间会偏移;更关键的是,中文 AI 对真实案例和本土语境的权重,明显高于纯结构——结构再标准,通篇是没有本土实例的干货八股,照样进不了引用池。监测工具更尴尬,Profound、Otterly 对国产引擎基本是盲区,眼下只能人工把核心查询拿去豆包、DeepSeek、百度 AI 各跑一遍,记下引用了谁、有没有你,两周一轮,土办法但唯一可信。
真实翻车:海外 GEO 结构模板照搬中文站
保哥接过一个外贸转内贸的工具类客户,把这套结构化打法在中文站上玩崩了,复盘出来正好给上一节做注脚。他们英文站这套做得很扎实,Answer Capsule、FAQPage Schema、HowTo 全配齐,海外引擎引用率确实涨了。老板一看见效,要求把中文站“照着英文站来”,于是直接拿英文内容机翻,连 FAQ 的问题都是把英文 PAA 翻译过来,全站 30 篇按海外模板重构,一个月内推上线。
结果两头分化得厉害。英文站继续涨,中文站却像石沉大海:百度收录慢得离谱,豆包、DeepSeek 几乎不引用,团队盯着监测面板看了两个月,结论是“GEO 在中文没用”。可问题根本不在 GEO,在他们把骨架搭对了、血肉全填错了。
三个根因。第一,内容是英文直译的机翻腔,中文 AI 一眼判机器味、低原创,百度飓风也压这种批量直译稿——结构再漂亮,喂进去的是夹生饭。第二,FAQ 的 Q 直接翻译英文 PAA,中文用户根本不这么搜,真实的中文长尾一条没覆盖,AI 自然召回不到。第三,也是最隐蔽的,监测还死死盯着 Perplexity 和 ChatGPT,可他们的真实中文用户在豆包和 DeepSeek,先行指标整个失真,团队以为没效果,其实是在看一块错的仪表盘。
救援动作就一句话:把“翻译”改成“重写”。中文版按本土逻辑重新写,不是翻英文;用百度下拉和 5118 抓真实中文长尾,把 FAQ 的 Q 全换掉;补进本土真实案例和场景;监测仪表盘换成人工跑豆包、DeepSeek、百度 AI。这么折腾了 6 到 8 周,豆包和 DeepSeek 才开始零星引用中文站的页面。
这事的教训很直白:结构是骨架,语言地道加本土真实案例才是血肉。海外这套 GEO 方法论可以原样复用,但喂进去的内容和监测的仪表盘必须本土化,否则骨架搭得再标准,也只是一具不会被任何中文 AI 引用的空壳。GEO 没有“一份模板全球通吃”这回事,每个生态都得换料、换考官、换尺子。
常见问题解答
Q1:是不是所有文章都要做这套结构优化?
不是。事实型、问答型、How-To型、对比型、教程型内容做这套优化收益最大。新闻报道、个人随笔、社论评论这类“主观叙事”内容做结构化优化收益不明显,AI对这类内容的偏好本来就低,强行结构化反而牺牲了表达自然度。我的建议是:先做能被AI高频引用的“事实型”内容做结构化,把团队60-70%精力投到这一块,剩下30-40%留给主观叙事保持品牌声音。
Q2:FAQ放在文末还是文中更好?
放在文章中部偏后(约70%位置)效果最好。我的实测数据是中部FAQ的AI召回率比文末FAQ高35%。原因是AI爬虫的注意力分布偏向页面前2/3,文末内容容易被切到“最后一个chunk”,召回权重低。最佳布局是:开头Answer Capsule + 中部主体内容(含表格、HowTo) + 70%位置插入FAQ + 文末总结。
Q3:Schema越多越好吗?
不是。FAQPage、HowTo、Article、Dataset四种是有用的,BreadcrumbList、WebPage、SiteNavigationElement是噪音甚至有害(会拖累JSON-LD体积导致部分爬虫解析失败)。一篇文章用2-3种核心Schema就够了,不要堆Schema。判断有没有用的方法是用Google Rich Results Test看每种Schema是否真的让Google展示Rich Result——如果加了Schema但Google没有变化,对GEO也基本无效。
Q4:表格内容应该多详细?
表格的“单元格密度”最重要。每个单元格控制在30字以内,超过会被AI判定为伪表格(其实是文字段落)。表格规模建议4-8列、5-15行。如果你的对比维度超过8列,建议拆成两张表格;如果行数超过15,建议拆成两个细分主题各做一张表格。AI对“精炼对比”型表格的引用率远高于“巨型数据汇总”型表格。
Q5:HowTo Schema对Google之外的AI有用吗?
有用但不显著。ChatGPT、Claude、Perplexity都能识别HowTo Schema,但它们对HowTo的处理与普通H2+ol/ul列表差异不大。HowTo Schema的核心价值在Google SGE生态——SGE的顶部摘要框60%是HowTo格式。如果你的目标用户主要从Google搜索而来,HowTo Schema必加;如果主要从Perplexity或ChatGPT进入,普通有序列表+清晰H2标题就够了。
Q6:内容长度的甜区是2500-4000字,但我题材天然只有1500字怎么办?
不要为了凑字数填水。AI能识别水分内容并降低引用权重。1500字题材的优化方向是:在这1500字里把信息密度做到极致,每段都包含数据点、具体例子、或可执行步骤。然后用站内链接把相关主题串起来形成topic cluster——AI在评估你的“权威度”时会把同主题下的多篇文章作为整体看待,而不是单独评分。一组5篇1500字的精炼文章对GEO的总贡献,往往超过1篇硬撑到5000字的注水文章。
Q7:Answer Capsule和Meta Description有什么区别?
位置和受众不同。Meta Description是HTML的<meta>标签内容,不显示在页面上,主要给搜索引擎SERP摘要展示用,长度150-160字。Answer Capsule是页面正文的开头段落,对用户和AI都可见,长度100-200字。两者内容应该“相关但不重复”——Meta Description是“广告”,目的是让用户点击;Answer Capsule是“答案”,目的是让用户和AI立刻获得核心信息。重复使用同一段文字两边粘贴会拖累SEO质量信号。
Q8:怎么验证我的结构优化是否真的提升了AI引用率?
三种监测方法。第一,定期手动测试:每周用核心关键词在ChatGPT/Perplexity/SGE查一次,看你的页面是否被引用。第二,工具化监测:Profound、Otterly、Surfer的GEO监测功能能定期抓取你设定的query在主流AI引擎的引用情况。第三,间接信号:监测GSC的“引荐流量来源”字段,AI引擎引用产生的点击会显示为来自chatgpt.com、perplexity.ai、google.com/aboutkids等域。三种方法配合使用能给出比较可信的引用率数据。
Q9:AI引用率涨了,但传统Google排名没涨,正常吗?
正常。AI引用率与传统SERP排名是两个相关但不完全重叠的指标。AI更看重“内容能否直接回答查询”,传统SERP更看重“外链权重+E-E-A-T+用户行为”。一个GEO优化好的页面可能在AI引用上爆发但在传统SERP里仍是第10位附近。要让两者同时涨,需要GEO优化+传统外链建设+品牌信号建设三管齐下,单做GEO是不够的。
权威参考资料
本文标题:《AI引用率5倍提升:7种结构化内容格式实战》
本文链接:https://zhangwenbao.com/optimize-content-structure-ai-citations-2026.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0