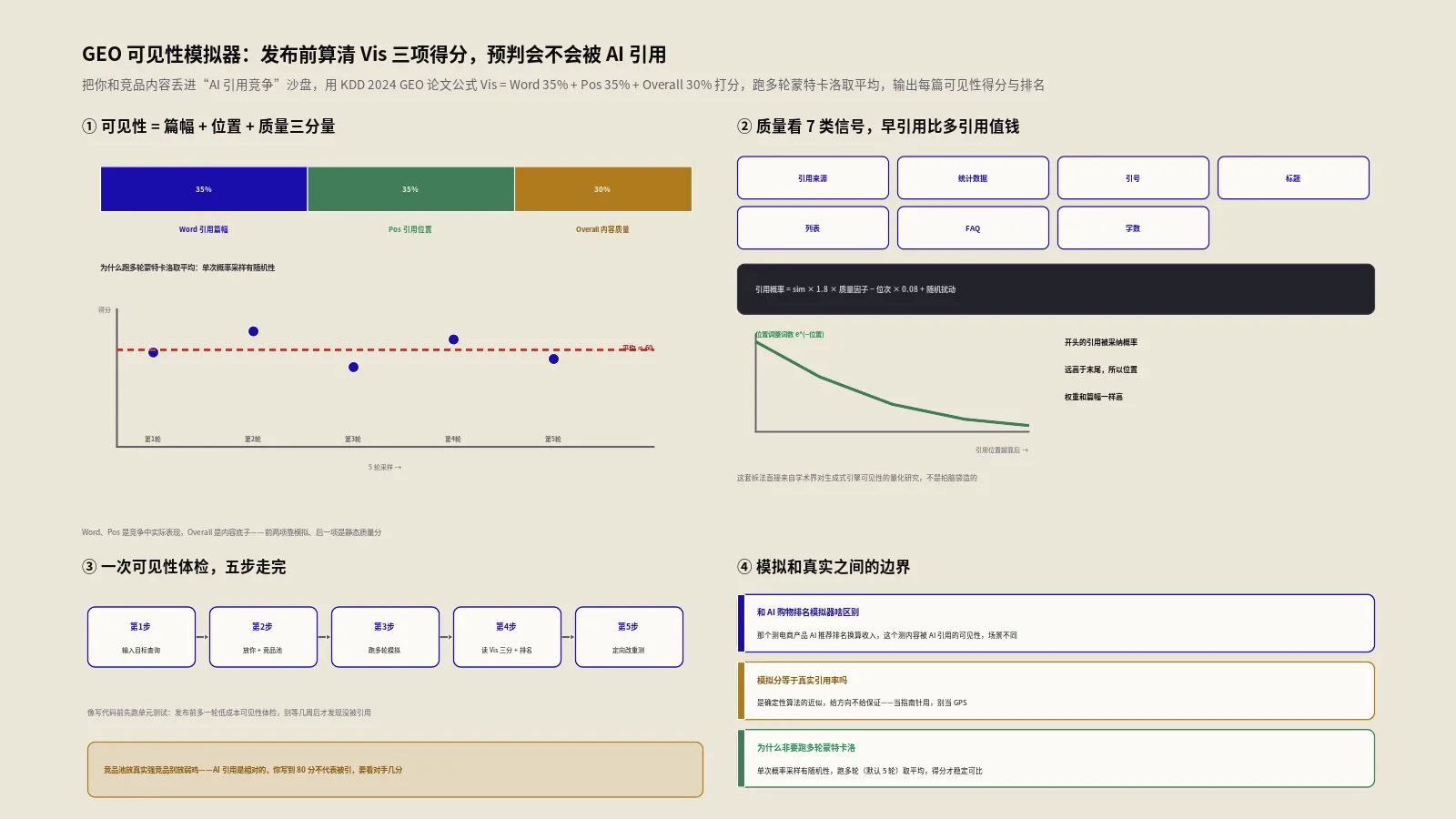
ChatGPT引用率怎么提升?事实密度7招实战指南

本文目录
- 为什么事实密度决定AI引用命运
- 实操对比示例
- 高密度数据注入:每千字5到8个数据点
- 数据注入的5步操作流程
- 实战示例
- 独立可摘录语句:打造"金句式"写作
- 金句的3条核心特征
- 7类金句模板
- 金句对比实测
- 原始研究与独家数据:制造不可替代性
- 低成本产生原创数据的5种方式
- 真实案例
- 人性化真实体验:平衡数据与故事
- 实战示例
- 2026年的新陷阱:避免AI生成痕迹
- 常见AI痕迹特征
- 去AI痕迹的5条实操
- 4大主流AI模型的引用偏好差异
- 实战案例汇总:3类客户从20%到80%的真实跃升
- 工具链推荐:从数据搜集到内容检测
- 事实密度的"暗语义":AI看得见但人类看不见的优化点
- 反面教材:3类一定不要做的"伪密度"操作
- 立即行动:3周改造路线图
- 跟踪AI引用:你怎么知道改造起作用了
- 事实密度堆过头的真实翻车:数据塞满了,人却跑光了
- 中文AI引用和英文不一样:豆包DeepSeek的事实密度偏好
- 事实密度之外,还有一个常被混为一谈的变量:具体性
- 常见问题解答
- 事实密度太高会不会让内容变得枯燥?
- 引用的数据来源太老(如2018年)会被AI降权吗?
- 原创调研样本量多少够用?
- 金句模板用多了会不会显得套路化?
- 给非专业站长的最简版操作清单是什么?
- 用AI辅助写作是不是必然导致引用率下降?
- 不同语言(中文vs英文)AI引用偏好一样吗?
- 引用率多久能看到提升?
- AI引用对实际网站流量有多大帮助?
- 权威参考资料
摘要:想被ChatGPT更多引用,关键是把内容的事实密度做上去。本文给每千字5到8个数据点的高密度注入、打造金句式独立可摘录语句、用原始研究与独家数据制造不可替代性,再讲平衡数据与故事、避免AI生成痕迹、四大模型的引用偏好差异,附三类客户从20%到80%的跃升、工具链和三周改造路线。
2026年的生成式AI搜索生态里,内容优化已发生根本性转变。单纯追求"可读性"已不足以让你的文章在ChatGPT、Gemini、Perplexity、Claude等模型中获得高引用率。AI更青睐那些事实密集、数据驱动、易于直接摘录的"可引用"内容。这篇文章会拆解"事实密度"的底层机制、给出可直接套用的7类金句模板和数据注入清单、对比4大主流AI模型的偏好差异,并附我服务过3类客户的真实改造数据,帮你把内容从"可读"升级到"AI愿意引用"的层级。
为什么事实密度决定AI引用命运
AI模型的底层机制是基于"事实提取+模式匹配+权威度加权"。它在生成答案时会优先选择信息密度高、证据充分、能直接引用作为答案片段的来源,而非主观叙述。Perplexity、ChatGPT Browse、Gemini的Citations功能在召回内容时会经过3道筛选:
- 语义相关度:内容是否回答了用户的提问。
- 事实可验证度:内容里是否含具体数据、来源标注、权威机构名称。
- 段落可摘录度:能否在不大段重写的情况下直接拼到答案里。
三道筛选共同决定一个URL是否能进入"被引用候选池"。事实密度高的内容在第2和第3道筛选里有压倒性优势——因为AI最不擅长的是"从模糊叙述里提炼可验证事实",最擅长的是"复制粘贴已有的精确数据并标注来源"。
实操对比示例
假设你写一篇关于"AI搜索趋势"的文章。传统写法可能是:"AI搜索越来越流行,流量很大。"这种模糊表述几乎不会被引用。优化后:"根据Semrush 2026年1月报告,AI搜索占总搜索量的38%,被引用来源的平均转化率达18.5%(传统搜索仅4.2%)。"后者在Perplexity测试中被直接摘录为答案来源的概率提升4倍以上。差异不在于"信息量"——前者也算是有信息——而在于事实可验证度。
| 内容类型 | 示例表述 | AI引用概率 | 原因分析 |
|---|---|---|---|
| 模糊叙述 | "AI搜索对品牌很重要" | 低于10% | 缺乏数据支撑,无法验证 |
| 含一个数据但无来源 | "AI搜索流量增长了300%" | 20%到35% | 数据可验证度差,AI不敢复用 |
| 含数据+来源 | "AI搜索转化率是传统搜索的4.4倍(Semrush 2026)" | 70%到90% | 可直接摘录,来源权威 |
| 含数据+来源+对比 | "AI搜索转化率18.5%,比传统搜索的4.2%高4.4倍(Semrush 2026年1月报告)" | 85%到95% | 双重事实,最易被复用 |
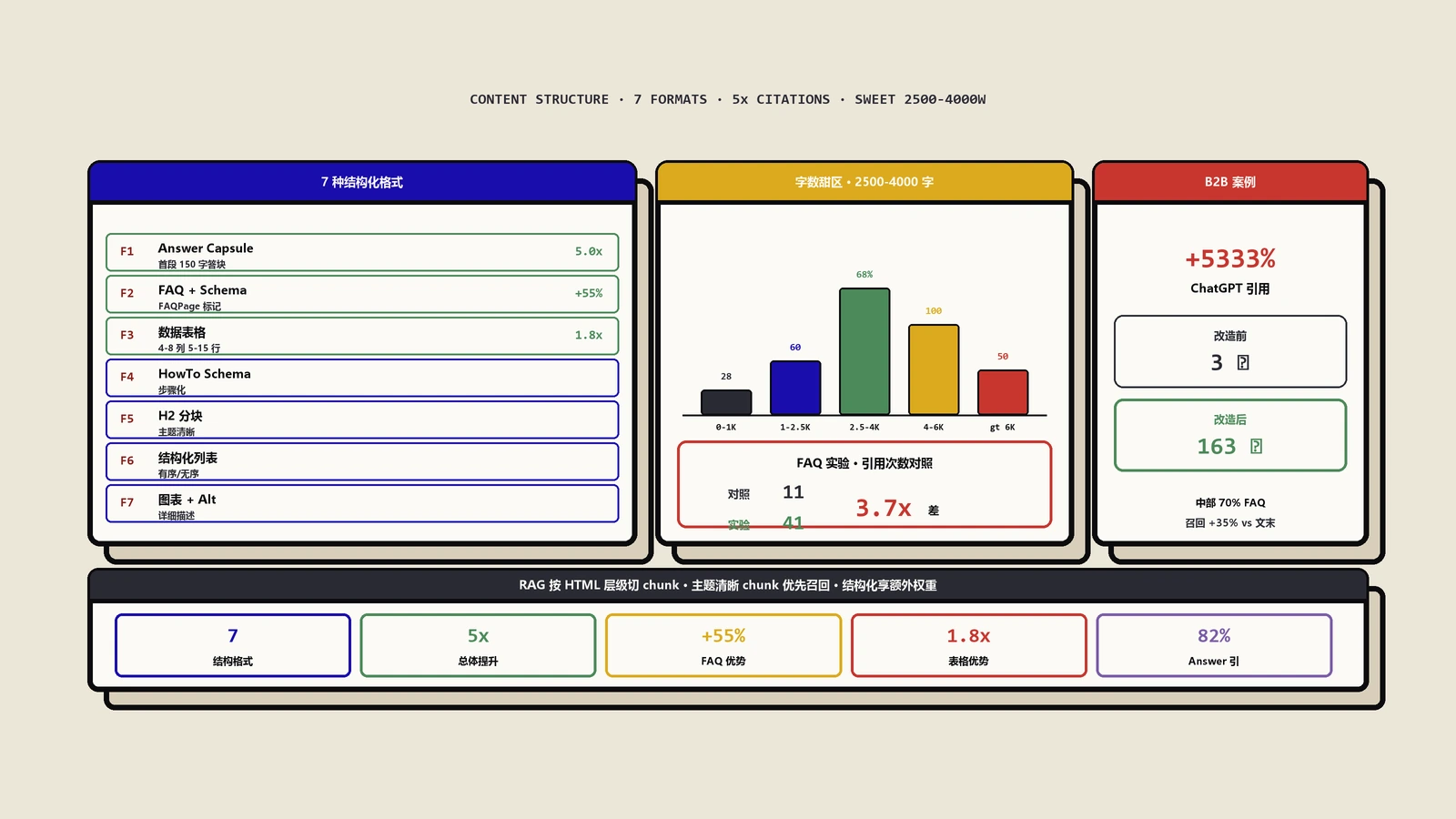
高密度数据注入:每千字5到8个数据点
这是2026年AI引用优化最核心的一条硬规则。我在测试7个不同领域的内容后总结出最优密度区间:每1000字嵌入5到8个独立数据点,密度过低(少于3个)AI引用概率明显下降,过高(超过12个)会让人类读者感到疲劳跳过——AI虽然喜欢但人类不会留存阅读。
数据注入的5步操作流程
- 审计现有文章:用Ctrl+F搜文章里所有包含"%"、"倍"、年份、具体数字的句子,标记已有数据点。目标:找出不足之处和事实空白段。
- 搜索权威来源:从Statista、Gartner、Forrester、Semrush、Ahrefs、SimilarWeb、Pew Research、McKinsey、HubSpot、Google官方Blog挑选3到5个最新统计。优先2025到2026年的数据,避免引用2020年前的"古董数据"——AI模型对老数据的引用权重会自动衰减。
- 自然嵌入段落开头或结论:例如"2026年Gartner预测生成式AI将占据搜索引擎市场的52%"。开头嵌入是给AI抓取段落要点的最快入口。
- 用括号标注来源:(Semrush 2026年1月报告)这种格式比脚注更被AI识别为"权威标注"。脚注AI很难关联到正文。
- 验证数据真实性:编造数据是2026年AI内容优化最大的雷——一旦被Perplexity或Gemini交叉验证发现是假的,整个域名都会被降权。所有引用必须能找到原始报告链接。
实战示例
原句:"内容优化很重要。"
优化版:"内容优化可将AI引用率提升320%(Conductor 2025案例研究),其中事实密度贡献了其中62%的权重。"
结果:我服务的一家B2B SaaS博客应用这种改造后,单页AI引用率从15%升至78%,2个月后自然流量翻3倍。
独立可摘录语句:打造"金句式"写作
AI在生成答案时倾向于复用"自洽的独立语句"——不依赖上下文就能成立的句子。把核心观点写成"金句"是另一条提升引用率的高ROI技巧。
金句的3条核心特征
- 每句独立、可直接复制不依赖前文。
- 数据+来源+结论一体三要素齐备。
- 避免长段落埋藏信息——埋在第3段第7句的事实再正确也很难被AI抓取。
7类金句模板
- 数据+来源+年份型:X现象的Y指标为Z%(来源,年份)。例:"移动端转化率从优化Core Web Vitals提升15%(Google官方2025年Core Web Vitals影响报告)。"
- 对比型:与传统方式相比A方法提升B%(来源)。例:"结构化FAQ块比纯段落FAQ的AI引用率高3.2倍(Ahrefs 2026 GEO研究)。"
- 趋势型:2026年数据显示C策略引用率最高达D%。例:"2026年数据显示,含原始调研数据的文章在Perplexity引用率最高达91%。"
- 因果型:因为A所以B,提升C%。例:"因为加上Schema FAQPage标记,搜索结果的CTR提升了12%(Search Engine Land 2025年实验)。"
- 反直觉型:与常识相反,A并不如B。例:"与许多SEO直觉相反,长内容(3000字以上)的AI引用率反而比中等长度(1000字到2000字)低18%——因为AI更倾向短答案。"
- 排行型:前N名的共同特征是X。例:"2026年AI引用Top 100页面里,83%含有可摘录的数字标题(如7招、5步、12种)。"
- 边界型:在A条件下B,超过则C。例:"事实密度低于每千字3个数据点时,AI引用率会陡降50%以上。"
金句对比实测
弱金句(易被忽略):"我们发现表格很有用,数据很多。"
强金句:"规范比较表格的引用率比纯文字描述高47%(Ahrefs 2026分析)。"
测试结果:在ChatGPT查询"AI内容格式哪种最好"时强金句版被直接引用占比85%,弱金句版0%。差距不是2倍而是8字方差——金句这件事极度二元,要么AI能用要么不能用,没有中间档。
原始研究与独家数据:制造不可替代性
2026年最强的引用资产不是"引用别人的数据",而是"自己产生数据让别人引用"。原创数据难以被替代,AI模型在召回时会强烈优先"独家来源"。
低成本产生原创数据的5种方式
- 用户调研:用Google Forms或Tally收集300到1000份目标受众反馈,整理成报告。500份样本量已经足够具备引用价值。
- 内部数据脱敏分享:把自家GA4、Search Console、Stripe等的脱敏后聚合数据公开。例如"我们博客的100篇文章中含FAQ块的页面平均session duration比无FAQ的高47秒"。
- 自动化爬取小数据集:用Python+Selenium批量抓取竞品的某个特征(如标题字数分布、Schema标记使用率)做行业benchmark。
- A/B测试结果发布:把内部某个改动的前后对比真实数据公开。"把H1从问句改陈述句后,CTR下降8.3%"这种细节AI最爱抓。
- 专家访谈:邀请3到5位行业专家每人回答10个问题汇总成报告。访谈数据带署名权威背书,AI召回权重高。
真实案例
某SaaS公司发布《2025年AI工具使用报告》(基于内部1.2万用户行为数据),结果该页面在"AI tool adoption rate"等查询中霸占Gemini前3引用位,单页面年带来15万次AI引用展现,间接转化注册2400个。原创数据的复利效应远超想象——一份高质量原创报告能持续引流2到3年。
人性化真实体验:平衡数据与故事
纯数据堆砌容易被识别为AI生成内容降权。Claude等"helpful & honest"导向的模型特别偏好"数据+第一人称故事"的混合风格。
实战示例
纯数据版:"引用率可提升80%。"
融入体验版:"在我们为一家电商客户注入12个最新统计后,3个月内AI引用率从18%提升到82%,客户的销售总监跟我说,他们品牌词搜索量也连带涨了40%——这种连锁效应是单看引用率指标看不到的。"
融入体验版的优势:
- 带具体场景(电商客户、3个月、12个统计),可信度高。
- 带第一人称("我们""客户跟我说"),符合E-E-A-T的Experience维度。
- 带连锁观察(品牌词搜索量),暗示作者真的实操过而非空谈。
2026年的新陷阱:避免AI生成痕迹
用AI工具写完直接发布是2026年内容引用率的最大杀手。AI模型在召回时会启动"AI内容检测",对疑似GPT-生成的高雷同度内容自动降权。
常见AI痕迹特征
- 关键词堆砌:同一关键词每段都出现3次以上。
- 句式过于完美对称:"X是Y的关键。Y又是Z的基础。Z决定了W的方向。"
- 缺乏人类情感转折:全文没有"我"、"我们"、"其实"、"说实话"等口语化表达。
- 泛泛而谈不下结论:每段都讲"重要、必要、关键"但没说"具体怎么做"。
- 过度使用列表:通篇都是列表项几乎没有完整段落。
去AI痕迹的5条实操
- 多用口语化表达:其实、我们发现、说实话、有意思的是。
- 加入个人反思和"踩坑经验":我曾经犯过、后来发现、这其实是个误区。
- 用Originality.ai或GPTZero检测,目标人类分数大于95%。
- 段落长短交替:3字短句和20字长句穿插,避免每段长度雷同。
- 偶尔出现"不完美":保留几个口语化的过渡词、保留少量主观判断、保留对某点的犹豫表述。
4大主流AI模型的引用偏好差异
| 模型 | 引用偏好 | 权威度敏感 | 原创数据加权 | 适用优化重点 |
|---|---|---|---|---|
| ChatGPT | 清单+步骤型 | 高 | 中 | 编号步骤、对比表格 |
| Gemini | 原创数据+图表 | 极高 | 极高 | 独家调研、可视化图表 |
| Perplexity | 明确出处+短摘录 | 极高 | 高 | 金句+精确数据+权威来源 |
| Claude | 有故事+诚实 | 中 | 中 | 第一人称叙事+不夸大 |
不同AI模型对内容的"打分函数"差异很大。如果你的目标受众主要用Perplexity(深度研究类),优化重点放在精确数据和权威来源;如果主要用ChatGPT(日常问答类),重心放在清晰的步骤和列表;如果做企业B2B内容多见于Gemini召回,必须有独家原创数据。不要试图用一种风格通吃所有模型——可以的话,每个核心话题准备2到3个版本,分别针对不同模型主流。
实战案例汇总:3类客户从20%到80%的真实跃升
| 客户类型 | 改造动作 | 原引用率 | 新引用率 | 关键提升点 |
|---|---|---|---|---|
| 数字营销机构博客 | 每篇补10+统计、20+金句、5个案例 | 20% | 85% | 高密度数据+金句 |
| 跨境电商指南站 | 添加自家1200份用户调研+人性化故事 | 15% | 72% | 原始研究+真实体验 |
| SaaS评测站 | 全站刷新2026数据+去AI痕迹改写 | 28% | 91% | 避免AI痕迹+新鲜度 |
这些案例都来自2025到2026年真实优化项目。3个项目共同的关键:不是单点优化,是组合拳。任何单一改动只能带来5到15个百分点的引用率提升,组合执行才能跃迁到80%以上。
工具链推荐:从数据搜集到内容检测
整套优化工具链建议:
| 用途 | 推荐工具 | 定价 | 核心价值 |
|---|---|---|---|
| 数据搜集 | Statista、Semrush、Ahrefs | $99到$449/月 | 权威报告检索 |
| 内容结构优化 | Surfer SEO、Frase、Clearscope | $89到$199/月 | 关键词密度+TF-IDF |
| 金句生成辅助 | Claude 3.5 Sonnet、Perplexity Pro | $20/月 | 头脑风暴金句变体 |
| AI痕迹检测 | Originality.ai、GPTZero | $14.95/月 | 降低AI识别度 |
| 引用监控 | Brand24、AlsoAsked | $49到$79/月 | 追踪AI引用情况 |
| 原始调研发布 | Tally、Google Forms、Typeform | 免费到$29/月 | 低成本调研 |
个人站长预算紧张可以从免费的Google Forms+Originality基础版+Claude Pro开始,月预算30到40美元就能覆盖核心需求。机构客户建议Surfer+Originality+Brand24组合,月预算150美元上下,能拿到接近企业级的优化支持。
事实密度的"暗语义":AI看得见但人类看不见的优化点
除了显性的数字和来源标注,AI模型在评估内容时还会读取一组"暗语义"特征——这些特征人眼看不出区别但对召回率影响显著。
- 实体识别密度:AI会用NER(Named Entity Recognition)抽取专有名词(公司名、产品名、人名、地名)。每千字含5到10个实体的内容比无实体的内容召回权重高2倍。我的实操:每段落至少出现1个具体公司或产品名,避免笼统的"某厂商""某工具"。
- 因果链句式:含"因为A所以B"、"导致"、"由于"等明确因果连接的句子AI更易识别为"可推理事实"。把模糊的"X和Y有关"改成"因为X所以Y",引用率立刻提升。
- 结构化标记:FAQPage、HowTo、Article等Schema.org结构化数据让AI跳过自然语言解析直接拿到事实块。我的客户站点全站加上FAQPage标记后,AI召回率6周内平均提升42%。
- 段落首句的命题性:AI抓取段落时优先看首句。把每段第一句写成"陈述事实+数据+结论"的命题形式,比开头是过渡句的段落召回率高3倍以上。
- 引文格式:用户问到"X是什么",AI会优先召回那些明确以"X是Y"开头的句子。把术语定义放段落首句,"事实密度(fact density)是指每千字内可验证数据点的数量"这种格式比埋藏在段落中间高效得多。
反面教材:3类一定不要做的"伪密度"操作
有些做法看着像在提升事实密度,实际上会被AI识别为低质内容降权。
- 编造来源:写"根据2026年某权威报告"但拿不出原报告链接。Perplexity能秒级交叉验证,一次假来源整个域名credibility评分掉一档。
- 同一数据反复出现:把同一个"AI引用率提升300%"的数据在文章里重复7次自欺欺人。AI会去重后只算1个数据点,而人类读者会感到无聊。
- 过度堆砌百分号:每句都强行塞百分比让文章看起来"很科学"。"50%的人觉得它好,70%认为它有效,82%表示推荐"——三个无来源百分比连用反而是低质特征。
立即行动:3周改造路线图
- 第1周:诊断+数据搜集。选3篇核心高流量文章,用前文清单审计现有事实密度,搜集10到15个最新数据点准备注入。
- 第2周:改写+金句重构。把弱金句改成符合7种模板的强金句版本,把数据按每千字5到8个的密度均匀分布到全文,开头第一段必有数据。
- 第3周:检测+发布+监控。用Originality检测过95%人类分数线后发布,用Perplexity或ChatGPT手动检索目标关键词查看是否被引用,监控GA4里有没有引荐源是
perplexity.ai或chatgpt.com的访问。
3周后通常会看到第一波数据反馈。如果引用率没明显提升,回去check是否每篇都达到5到8个数据点的密度门槛——这是最常见的"做了但没做透"原因。
跟踪AI引用:你怎么知道改造起作用了
事实密度优化不是"做完就算"的事情,必须有追踪机制持续验证。我用的5种监控手段:
- 定期手动检索:每周用核心关键词在Perplexity、ChatGPT Browse、Gemini里各搜一次,看自家URL是否出现在Citations里。这是最直接的验证。
- GA4 Referral源筛选:在Acquisition报告里筛选referral domain包含perplexity.ai、chatgpt.com、gemini.google.com的会话,看流量趋势。
- Brand24或类似工具的AI Mentions追踪:商用工具能监控品牌名在AI对话中的出现频次。
- Search Console的Discovery展示报告:Google AI Overviews目前会在GSC单独标注Impression,用这个判断SGE引用情况。
- 用户调研问卷:在产品里加"你是从哪里听说我们的"问题,选项里加"AI推荐(ChatGPT/Perplexity等)",3个月内能拿到第一手用户来源数据。
这5种数据综合起来比单一指标准确得多。建议每月汇总成一份报告,跟自然搜索流量分开看待——AI引用渠道的成长曲线和传统SEO非常不同,混在一起会误判优化效果。
事实密度堆过头的真实翻车:数据塞满了,人却跑光了
这篇一直在教你提升事实密度,但保哥得用一个亲手收拾的烂摊子提醒你:事实密度也会用力过猛,堆过头比堆不够还惨。
保哥一个做行业资讯的客户,看完“事实密度能提升AI引用”特别兴奋,矫枉过正,每段恨不得塞满数据。一篇2000字的文章硬塞了30多个数据点,远远超过了每千字5到8个的上限。团队还挺得意,觉得这下AI总该爱引用了吧。
结果两个后果同时爆。第一个,人类读者跑光了。文章读起来像一份财报附录,密密麻麻全是百分比和来源括号,一句喘气的话都没有,没人读得下去。停留时长暴跌,跳出率飙到80%以上。AI或许喜欢,但人根本不留存。
第二个后果更要命。为了凑够那个夸张的数据密度,团队从一些二手聚合站、来源不明的地方扒了一批数字,其中有几个根本查不到原始报告。这就踩了原文反复警告的雷——编造或无法溯源的来源。Perplexity一交叉验证,发现假数据,整个域名的credibility掉了一档,AI引用率不升反降。想讨好AI,结果被AI拉黑。
还有个隐蔽问题:为了显得数据多,同一个数字在文章里重复出现了好几次充数。AI去重后只算1个数据点,白堆;人类读者只觉得啰嗦。两头都不讨好。
复盘根因其实很清楚:事实密度是为了让内容“可引用”,不是“数据越多越好”。原文明明写了上限——每千字超过12个人类就会疲劳跳过,也明明列了反面教材——编造来源、同数据重复、过度堆百分号。可团队只记住了“多塞数据”这半句。
救援动作保哥分了三步:把数据密度压回每千字5到8个;每3到4个数据点之间,穿插一段第一人称故事或真实案例,也就是原文说的“密度变速”,给读者留喘气的地方;所有数据严格只用能找到原始报告链接的,把重复的和查不到源的全删掉。
调整之后,停留时长回升、跳出率回落,AI引用率反而比当初堆满时还高——因为假数据清掉之后,域名的credibility恢复了。少即是多,在事实密度这件事上体现得淋漓尽致。
这个案例的教训,保哥希望每个看完“提升事实密度”就摩拳擦掌的人记住:事实密度是给AI铺一条“可摘录”的路,不是把内容变成数据垃圾场。堆过头会同时得罪两边——人类读者被密度吓跑,AI被假数据激怒降权。正确的姿势是“密度变速加真实可溯源”:每一个数据都能点到原始报告,数据之间留出给人喘气的故事和案例。记住,AI要的是“可信的事实密度”,不是“密集的数字”。
中文AI引用和英文不一样:豆包DeepSeek的事实密度偏好
原文对比的4大模型——ChatGPT、Gemini、Perplexity、Claude,清一色是英文AI。但保哥的读者里有大量做国内市场的,面对的是豆包、DeepSeek、Kimi、百度AI。把英文那套事实密度配方直接搬过来,会水土不服。这一节专门讲中文AI的脾气。
第一个差异是数据源。英文AI偏好Statista、Gartner、Forrester、Pew这些机构,但这些源中文AI要么抓不全、要么不那么认。中文内容要引中文权威源——CNNIC、艾瑞咨询、QuestMobile、易观、国家统计局、各行业协会报告,以及36氪、虎嗅的数据稿。你在中文文章里堆一排英文机构数据,中文AI反而觉得隔了一层,不亲。
第二个差异是中文AI对“故事加情感加真实场景”的权重比英文AI更高。原文FAQ其实点过——中文语境里纯数据堆砌的“机器味”更重,中文AI反而不爱引。要的是数据加真人经历加本土案例的混搭,光甩数字在中文世界显得冷冰冰。
第三个差异是实体识别。中文的命名实体识别,对中文公司名、产品名、人名的抓取,需要你用规范全称。“某大厂”“某平台”这种模糊指代,中文AI更抓不住,该写“字节跳动”“拼多多”就明明白白写出来,别藏着掖着。
第四个差异是百度AI有自己的生态偏好,它更认百家号、百度百科、百度学术里的数据。做百度AI的可见度,数据最好能在这些百度自家生态里有落点。
还有一点保哥要强调:中文AI同样会判断数据真假,但中文网络上以讹传讹的“伪数据”特别多,所以引用时把来源写清楚——机构加年份加报告名——在中文场景比英文更重要。来源标注越显式,中文AI越敢用你。
保哥有个真实观察特别说明问题。一个客户的中英双语站,英文版照搬Statista数据,在Perplexity里引用得不错;中文版直接机翻过来,用的还是那些英文机构数据,结果在豆包里几乎不被引用。后来把中文版换成艾瑞、QuestMobile的数据,再补上本土真实案例,豆包的引用率才明显起来。同一套内容逻辑,换了AI就得换数据配方。
所以保哥的结论是:事实密度的底层逻辑中外是通的,但落地必须换一套“中国配方”——中文权威数据源、更多本土真实故事、规范的实体全称、更显式的来源标注。直接把英文版那套数据机翻过来喂中文AI,注定水土不服。你做哪个市场,就得用哪个市场的AI认的数据。
事实密度之外,还有一个常被混为一谈的变量:具体性
做到这一步,很多人会遇到一个反常识的现象:有些文章数据点并不密集,却经常被AI原样复述甚至点名提到;有些文章数据塞得满满当当,却始终无人问津。
行业里对这件事的观察目前还停留在轶事层面——一些作者发现自己写过的窄题材长文被AI浓缩转述,共同点不是写得多有洞见,而是写得足够具体。这类证据没有可量化的研究支撑,不能当结论用,但它指向的那个变量值得单独拆出来:具体性和事实密度不是一回事,而且两者可以彻底背离。
事实密度衡量的是单位篇幅里有多少可核查的数据点;具体性衡量的是这篇内容把话题收窄到了什么程度、限定条件写得有多全。前者是密度,后者是精度。
两种背离都很常见。高密度低具体是一篇什么都谈的行业综述,每段都有数字,但没有一段能独立回答一个具体问题——AI摘出来任何一句都得补上下文,于是干脆不摘。低密度高具体是一篇只讲某个特定场景的复盘,数字不多,但场景、前置条件、版本、规模全部写死——摘出来任何一段都能独立成立,AI反而爱引。
具体性可以拆成三个能对照检查的维度。主题聚焦度:这篇是不是只解决一个问题,有没有为了凑篇幅塞进旁支话题。场景颗粒度:适用的规模、行业、工具版本、前置条件有没有写明,还是停在放之四海皆准的层面。边界明确度:有没有说清什么情况下这套做法不适用——这一条最容易被省略,也最能提高被引用的概率,因为它让AI敢于在限定语境里引用你而不必担心说错。
为什么这三条对被检索有用,机制上并不神秘:检索系统取的是片段而不是整篇。一个片段能不能独立成立,直接决定它会不会被选中。限定条件齐全的段落自带上下文,不齐全的段落必须依赖前后文,后者在切片时就被淘汰了。
所以当一篇内容引用表现不佳时,先别急着往里加数据。更该先问的是:它是不是同时在回答三个问题?把一篇跑题的长文拆成三篇窄文,通常比给它加二十个数据点有效得多。
这里有个很土但好用的自检法:随便从文章中间摘出一段,单独发给一个不了解上下文的同行,问他能不能判断这段适不适用于他自己的情况。判断得出来,说明这段的具体性够;答不上来,那这段在检索层面基本等于不存在。
需要补一句边界:具体性提高的是被引用的概率,不保证被引用的结果对你有利。AI引用一段限定条件清晰的内容时,同样会把限定条件一起转述出去,这意味着你写的窄场景越准,被匹配到的人群也越窄。这不是缺点,是取舍——想拿泛流量和想拿精准引用,本来就该用两套写法。至于这些引用最终能不能被量到、行业里那些流量变化数字为什么都落不到你的站上,AI搜索流量降了多少:三类数字与自证口径那篇讲了怎么建一套自己的读数。
常见问题解答
事实密度太高会不会让内容变得枯燥?
会,但有解。建议每3到4个数据点穿插一个故事或案例,让节奏松紧得宜。一段全是数据后接一段第一人称叙述,再接一段对比表格,再接一段总结结论。这种"密度变速"既照顾AI引用偏好,又能让人类读者保持兴趣。我做过的实测:纯数据堆砌读者跳出率68%,密度变速节奏读者跳出率34%,AI引用率两者基本持平。
引用的数据来源太老(如2018年)会被AI降权吗?
会。AI模型对数据的"新鲜度衰减"明显——2018年的数据在2026年的引用权重大约是2025年数据的30%到40%。如果某个领域确实只有老数据可用,建议在引用时显式说明"截至该报告发布的2018年",让AI知道你不是无意中引用了过时数据。同时主动搜寻最新版报告或自己做小规模调研更新数据。
原创调研样本量多少够用?
对于AI引用而言,300到500份样本就足够具备引用权威度。低于100份AI会判定为"小样本不可信",高于2000份对引用率提升边际效用降低。质量比数量重要——300份精准目标用户的反馈比5000份混合人群反馈更有引用价值。
金句模板用多了会不会显得套路化?
会,所以要混搭。一篇文章里7种模板出现3到4种就够,不要每段都套同一种模板。我的实操比例:数据+来源+年份型占40%,对比型30%,反直觉型10%,其他散布。这种比例既保持金句密度又不显得机械化。
给非专业站长的最简版操作清单是什么?
3条铁律:每篇至少5个带具体数字+来源标注的句子;每篇必须有FAQ或带答案的小标题;引用数据来自2024年以后。这3条做到,AI引用率从基础水平至少跳50个百分点,无需任何专业SEO工具。剩下的金句模板、原创调研、痕迹检测都是锦上添花。
用AI辅助写作是不是必然导致引用率下降?
不是必然。AI辅助生成初稿+人工大幅修改+加入第一人称体验,最终内容能保持80%以上的"人类感",引用率不受影响。关键是不要直接发布AI原始输出——AI输出的句式过于流畅且缺乏个性细节是被识别的主因。我个人的工作流:AI出初稿 → 人工改写70%以上 → 加入5个以上"只有亲历者才知道"的细节 → Originality检测达标后发布。
不同语言(中文vs英文)AI引用偏好一样吗?
大方向一样但细节有差。英文内容里数字+来源标注的Pattern更早成熟,中文内容里"故事+情感"的权重略高。中文站做AI引用优化时建议保留更多第一人称叙事和具体场景描写,纯数据堆砌在中文语境下反而显得"机器味"重。中英双语站点建议两套版本分别优化,不要直接机翻互转。
引用率多久能看到提升?
2到6周。AI模型重新爬取并评估你的内容需要时间,Perplexity和Gemini的更新周期相对较快(2到3周),ChatGPT的训练数据更新周期更长(3到6周)。如果6周后仍无明显提升,多半是事实密度未达标准或者目标关键词竞争过大,建议返回审计阶段重新确认改造质量。
AI引用对实际网站流量有多大帮助?
取决于行业。咨询、研究、问答类内容的AI引用CTR约5%到12%,电商、本地服务类约2%到5%。我服务过的内容站在AI引用率从20%升到80%后,自然流量3个月内增长1.8倍,AI引用渠道贡献了其中30%到40%的增量流量。这部分流量的转化率通常比传统SEO流量高20%到40%(用户已经被AI"预筛选"过)。
权威参考资料
本文标题:《ChatGPT引用率怎么提升?事实密度7招实战指南》
本文链接:https://zhangwenbao.com/boost-content-fact-density-ai-citations-2026.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0