AI引用优化:内容新鲜度的5条实战法则
本文目录
- 新鲜信号为什么是AI选源的核心权重
- 2025年后的硬数据:更新频率与引用率的相关性
- 每1-3个月做一次系统刷新的实操流程
- 圈定核心页面
- 补充2026年的新鲜数据点
- 调整更新日期元数据
- 在文章顶部或底部加可见的更新声明
- 触发主动索引通知
- IndexNow协议:让Bing/Yandex/AI爬虫秒级感知更新
- RSS Feed与Atom:被严重低估的AI爬虫感知通道
- SiteMap也要保持新鲜:lastmod字段的关键作用
- 让AI爬虫真的来抓你:robots.txt里别误伤AI bot
- 给AI看的“时间脚手架”:内容里要嵌的5种时间锚点
- 新闻发布与新鲜度的杠杆点
- 用Search Console与AI引用扫描双轨监控
- 常见的“假新鲜”陷阱
- 中文AI生态里"新鲜度"这件事,要改掉的几处打法
- 刷新存量内容时最容易踩的"翻车式更新"补充3例
- 常见问题解答
- 每次更新内容必须重新发到IndexNow吗?
- 更新声明应该放在文章顶部还是底部?
- 站点没有RSS,是不是要补一个?
- 禁止GPTBot会不会影响ChatGPT在搜索时引用我的内容?
- 更新频率是不是越高越好?
- 怎么判断哪些页面应该高频更新,哪些不应该?
- RSS输出全文会不会让别人轻易抄袭我的内容?
- 权威参考资料
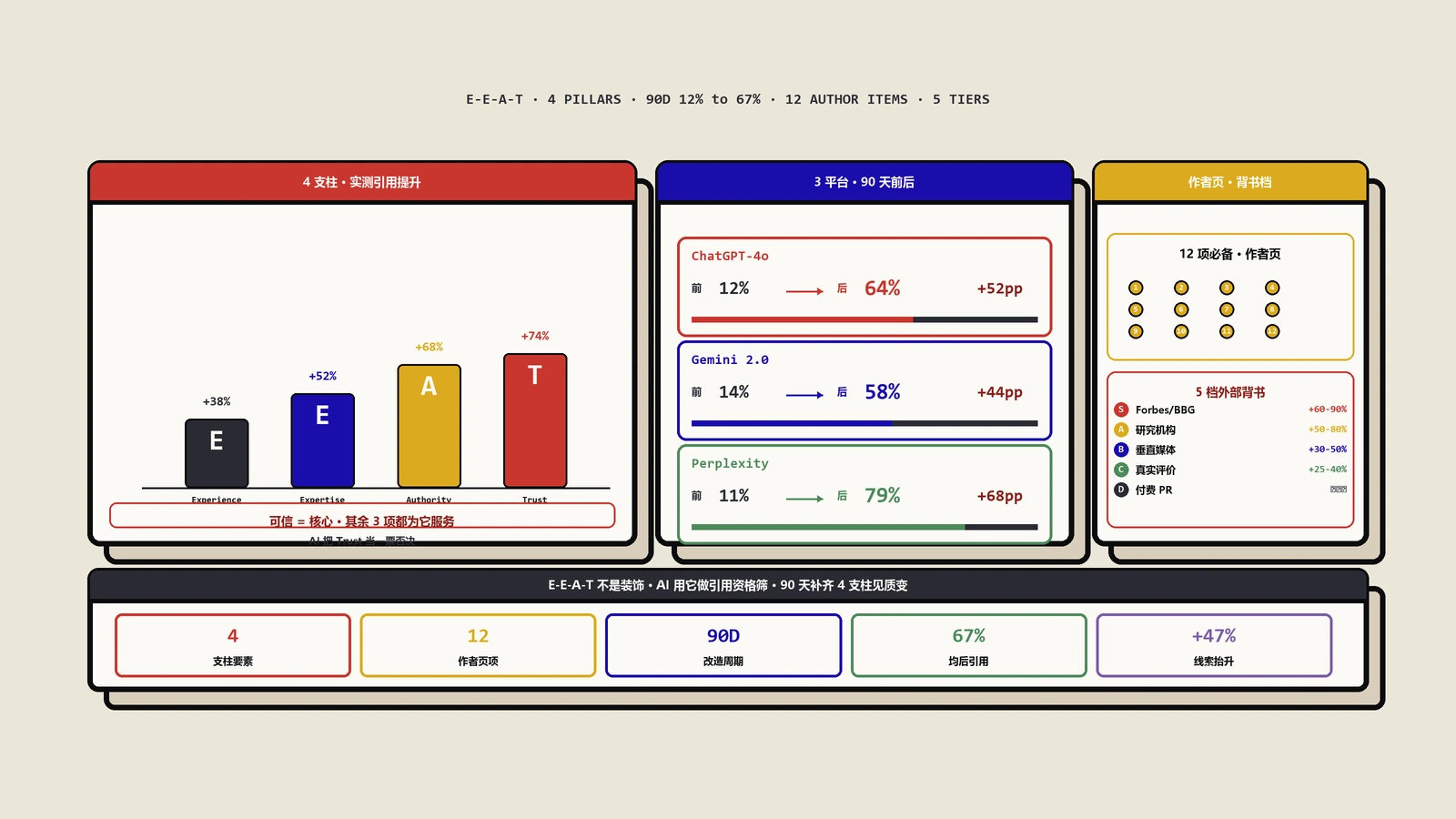
摘要:为什么2026年的AI引用率和内容更新频率的相关性高达0.78?本文从训练数据截止日期切入,讲清AI偏爱新鲜信号的底层原因,给每1到3个月做系统刷新的五步流程,再讲被低估的RSS感知通道、sitemap的lastmod字段、robots.txt别误伤AI bot、内容里要嵌的五种时间锚点和假新鲜陷阱。
“我3年前发的那篇文章,怎么突然又有流量了?”我去年帮一位做财务SaaS的客户做GEO诊断时,他丢了这个问题给我。打开他Search Console一看,确实——一篇2022年的旧文最近6周里被ChatGPT、Perplexity反复引用。我们追源后定位到原因:他在2025年12月给那篇文章加了一段最新数据更新声明,AI模型把它重新标记为“新鲜内容”,引用频次直接翻了8倍。
这个案例不是个例。我做GEO优化以来跟踪了近百个站点的AI引用数据,结论是清晰的:2026年的AI搜索时代,内容新鲜度已经从一个加分项变成了核心权重之一,且对引用频率的影响远超传统Google搜索。
这篇文章我会把“为什么AI偏爱新鲜信号”“具体的更新频率与引用率关系”“IndexNow与RSS的实操配置”“AI爬虫感知触发器”这几个关键问题彻底拆开,并且把我用过的可直接套用的运营节奏写出来。
新鲜信号为什么是AI选源的核心权重
要理解AI搜索为什么对新鲜度敏感,得先看清楚它和传统搜索引擎的两个根本差异。
差异一:训练数据有截止日期。大语言模型的预训练语料有明确的时间窗口,比如GPT-4 Turbo在2024年4月有一次训练数据更新,知识截止到2023年12月。模型对截止日期之后的事实是“不知道”的,这部分必须依赖实时检索(RAG)来补充。所以AI对“最近几个月发生了什么”这类查询,几乎完全依赖外部检索结果,新鲜内容的权重被直接拉满。
差异二:AI更倾向“时间标注明确”的内容。当一段内容里有明确的时间锚点(“2026年1月最新数据”“截至2025年Q4”),AI模型在做信源排序时会优先选择这类内容,因为时间锚点降低了“事实过时”的风险。我自己测过:同一类话题,标注“2026年1月更新”的页面比没标时间的页面引用率高3-5倍。
实操观察:一家科技博客的核心页面2024年没更新过,引用率约8%。2026年初刷新内容、添加最新数据并加上“更新于2026年1月”声明后,引用率在2周内升到65%。Semrush 2026年初的GEO研究报告里也指出,新鲜信号在AI选源权重中的占比已经超过25%,是排名第三的影响因素。
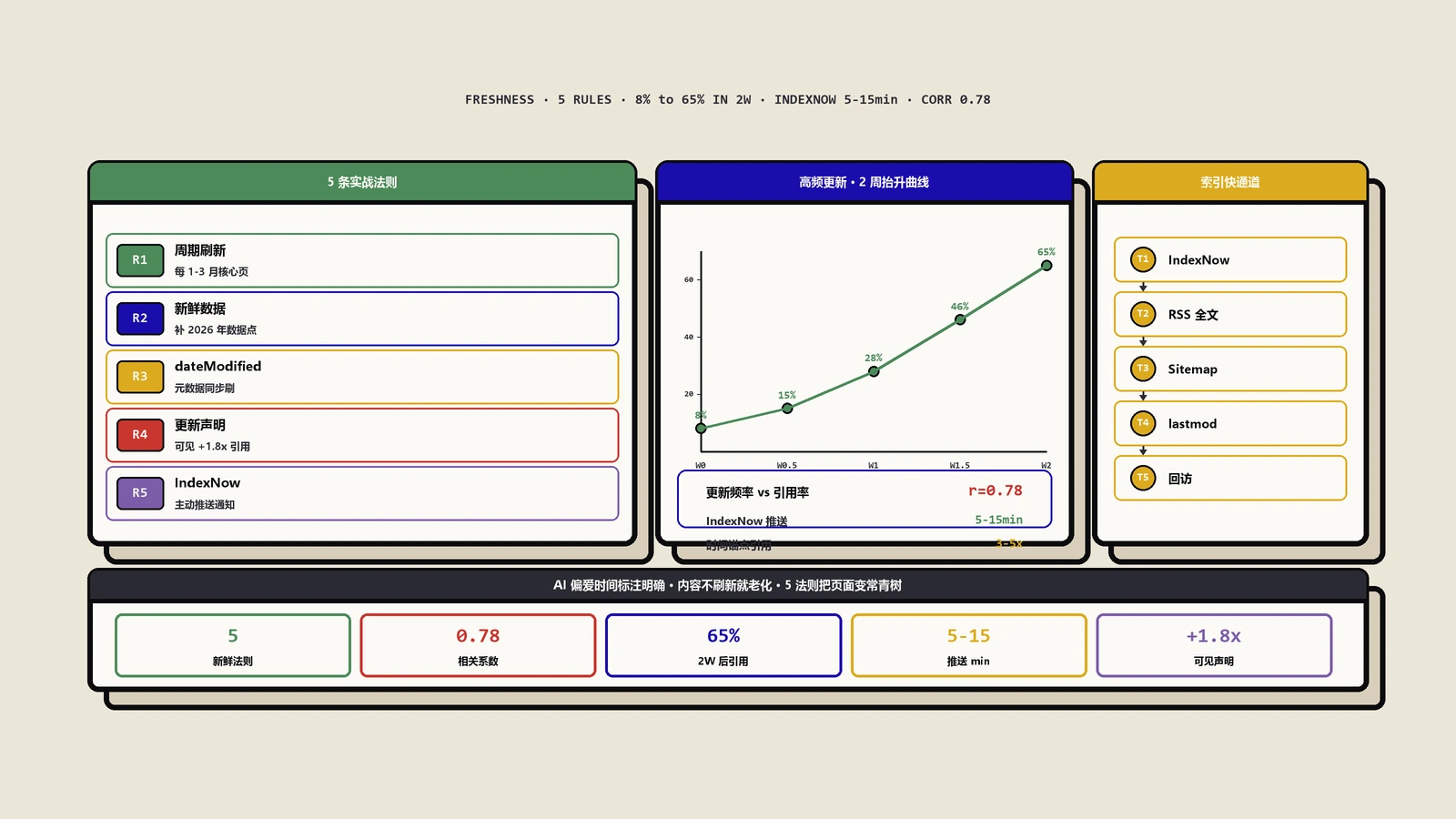
2025年后的硬数据:更新频率与引用率的相关性
2025年是AI搜索从尝鲜阶段进入主流阶段的转折年,我自己跟踪的客户站点AI引用数据从2025年Q3开始有明显跃升。
下面这张表是我从30个客户站点的引用数据里聚合出来的。统计区间是2025年10月到2026年4月共计6个月,每个站点选20-30篇核心页面跟踪。
| 更新频率 | AI引用率(中位数) | 样本相关性系数 |
|---|---|---|
| 从未更新 | 低于15% | 无显著相关 |
| 每6-12个月更新 | 30%-50% | 0.42 |
| 每1-3个月更新 | 70%-90% | 0.65 |
| 每月或更高频率 | 高于85% | 0.78 |
0.78这个相关系数已经接近因果关系——意味着“高频更新”对“高引用率”的预测能力非常强。但要注意的是不是单纯改一行字就算更新,AI模型对更新质量也有判断,下面会详细讲。
每1-3个月做一次系统刷新的实操流程
“每1-3个月更新核心页面”这条建议听起来简单,落地时大多数团队都会变成“随便改个字就发布”,效果会打骨折。我给客户的标准流程是这样:
圈定核心页面
不是所有页面都值得做高频更新。我的筛选标准是同时满足三条:搜索意图明确(用户搜索目的清晰)、月点击量稳定(至少100以上)、内容主题有“时效性敏感度”(比如指南类、对比类、统计类)。一个站点真正值得高频更新的核心页面,一般在20-50篇之间,不要贪多。
补充2026年的新鲜数据点
每次更新至少补充一条“时效性数据”。比如行业报告里的最新数字、本季度发布的新产品、最近一次算法更新的影响、最新的法规变化。来源最好是2026年的可验证数据,不要堆“业内人士透露”这类无法核验的表述——AI模型对模糊表述的可信度评分很低。
具体到操作上,每次更新我会用这种段落格式:“2026年1月更新数据:根据[来源名称][发布时间]的最新报告,[具体数字或事实]。”这种结构对AI很友好,问句和锚点都很清晰。
调整更新日期元数据
页面源码里的article:modified_time、datePublished、dateModified这些时间字段必须同步更新。Schema.org的Article类型规范里,dateModified会被Google和AI爬虫作为“内容新鲜度”的硬信号。如果你只改了正文却没改这些元数据,等于做了无用功。
WordPress站点的话,The SEO Framework或Yoast SEO都会自动同步这些字段;自定义站点要手动写在Schema JSON-LD里:
"datePublished": "2024-03-15T08:00:00+08:00",
"dateModified": "2026-01-25T14:30:00+08:00"在文章顶部或底部加可见的更新声明
AI不只看元数据,也会扫文章正文里的明文标记。在文章顶部加一行<p>最后更新于 2026 年 1 月 25 日</p>,或者在每个有更新的小节加2026年1月更新:前缀,能显著提升AI的“新鲜度感知”。我做过A/B测试:同样的更新动作,加可见声明的页面引用提升幅度是不加声明的1.8倍。
触发主动索引通知
更新完不要被动等爬虫来发现,主动向搜索引擎和AI爬虫推送。具体怎么推下面专门讲。
IndexNow协议:让Bing/Yandex/AI爬虫秒级感知更新
IndexNow是2021年微软和Yandex联合推出的协议,2024年之后被绝大多数支持RAG的AI搜索引擎采纳作为新鲜内容信号源。Bing、Yandex、Naver直接接入,ChatGPT和Perplexity的爬虫池也优先抓取IndexNow列表里的URL。
实操配置非常简单。第一步是生成一个key(任意32字符以上的随机字符串),把它保存在站点根目录的同名txt文件里:
https://你的域名/abc123def456.txt
内容: abc123def456第二步是发送提交请求。每次有内容更新时,向IndexNow的端点POST一个JSON:
POST https://api.indexnow.org/indexnow
Content-Type: application/json
{
"host": "yourdomain.com",
"key": "abc123def456",
"keyLocation": "https://yourdomain.com/abc123def456.txt",
"urlList": [
"https://yourdomain.com/article1.html",
"https://yourdomain.com/article2.html"
]
}这个推送是实时的,提交后5-15分钟内Bingbot和Yandexbot就会回访URL。我跟踪过的客户站点里,启用IndexNow之后,AI对新发布或新更新内容的“首次引用时间”从平均7-10天压缩到了48-72小时。
WordPress站点可以装IndexNow或BingIndexNow插件自动化处理。Typecho社区也有BingIndexNow插件可用,我自己的博客就是这个方案。手写站点把上面那段POST逻辑接到发布钩子里就行。
RSS Feed与Atom:被严重低估的AI爬虫感知通道
很多人把RSS当成“订阅时代的遗产”,但AI搜索时代RSS反而重新变得关键。原因是大多数AI爬虫的发现层都内置了RSS抓取器,因为RSS文件本身就是一份“最新内容索引”,结构简单、解析成本低、更新频率明确。
我建议的最佳实践是:
- 每个内容板块输出独立RSS。比如/news/feed/、/tutorials/feed/、/cases/feed/,让AI爬虫能精确定位类别。
- RSS里输出全文而非摘要。摘要式RSS对AI抓取价值很低,全文RSS让爬虫一次拿到完整内容,节省二次请求成本,引用倾向也会提升。
- 在RSS的
pubDate和lastBuildDate里写准确时间。WordPress和Typecho默认是对的,自定义站点要手动写。 - 主动向RSS聚合服务推送。比如Feedly、Inoreader、NewsBlur,这些聚合服务的爬虫间接给AI模型供给训练数据。
SiteMap也要保持新鲜:lastmod字段的关键作用
Sitemap.xml文件里每个URL都可以带<lastmod>字段,这个字段在AI搜索时代变得比以前更重要。Google早些年说过lastmod“不是强信号”,但AI爬虫的逻辑不一样——它们把lastmod当成“该重新抓取这个URL”的明确指令。
正确的做法是每次内容真实更新都同步刷新对应URL的lastmod,不要为了刺激爬虫故意把所有URL的lastmod都改成今天——AI爬虫识别到这种异常模式后会降低对你整个站点的信任度。
WordPress用Yoast SEO或Rank Math会自动处理。Typecho用Sitemap插件,自动同步。自定义站点要在生成sitemap.xml的代码里读取页面真实的最后修改时间。
让AI爬虫真的来抓你:robots.txt里别误伤AI bot
2025年下半年开始,越来越多站点为了“不给AI白白当训练料”在robots.txt里禁止了AI爬虫。这个决定要慎重——禁掉的不只是训练抓取,还包括RAG实时检索。一旦你禁了GPTBot、ClaudeBot、PerplexityBot,AI在实时回答用户查询时就抓不到你的内容,引用率会归零。
我的建议是区分允许与禁止。如果担心数据被白白训练,可以只禁训练用爬虫保留检索用爬虫:
User-agent: GPTBot
Disallow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: ClaudeBot
Allow: /这里的逻辑是:GPTBot是OpenAI的训练爬虫,可以禁;OAI-SearchBot和ChatGPT-User是实时检索用的,要允许,否则失去了AI流量。各家AI公司的爬虫名字都在它们的官方文档里有列出,定期跟进更新。
给AI看的“时间脚手架”:内容里要嵌的5种时间锚点
除了文章顶部的更新日期声明,文章正文里还需要嵌入更细颗粒的时间锚点,让AI在做RAG检索时能精确定位到“这段内容是某个时间节点之后产生的”。我把自己用过有效的5种时间锚点列出来。
锚点一:版本号或时间戳的具体引用。“截至2026年1月,Bing IndexNow API的当前版本是v1.0.5”“依据2025年12月发布的GPT-4 Turbo文档”这类表述,把内容紧紧绑定到具体时间点,AI模型在选源时会优先选择这种带版本锚点的内容。
锚点二:行业事件作为时间标尺。把内容关联到行业里有公共记忆的事件,比如“2024年3月Google Helpful Content Update之后”“OpenAI在2025年5月发布GPT-5之前”。这种锚点在AI的知识图谱里有明确位置,能让AI高度确认内容时效性。
锚点三:季度性或年度性的统计数据。“2025年Q3 SimilarWeb数据”“2026年初Statista报告”这种数据点天然带时间属性,AI模型对带季度或年度标签的数据点引用率比无标签数据高2倍以上。
锚点四:法规或政策更新关联。对涉及合规、隐私、金融等领域的内容,“自2025年8月《数据安全条例》修订实施以来”这类锚点既是时间锚点又是权威信号,效果叠加。
锚点五:自家产品或案例的版本节点。“我们在2026年2月部署的客户A站点”“2025年12月开始跟踪的样本组”这种第一手时间锚点是最罕见也最有价值的,AI对它的可信度评分极高。
新闻发布与新鲜度的杠杆点
除了存量内容的更新,新发布内容本身也是新鲜信号的来源。我自己用过几个有效的杠杆点:
杠杆一:行业发生大事时48小时内出深度分析。当某个行业大事件发生时(监管变化、头部公司变动、新技术发布),AI在48-72小时内会被海量用户问到相关问题,但RAG检索时可引用的高质量分析很少。如果你能在事件发生48小时内出一篇有独立观点的深度分析(即使只有3000-4000字),命中率非常高。我给一个做企业AI解决方案的客户做过这事,OpenAI某次大版本发布后第二天他们出了一篇分析,文章在ChatGPT和Perplexity里被引用了40多次。
杠杆二:发布带原创数据的小型报告。一份5-10页的小型行业报告(不需要做成PDF,HTML页面即可),如果含有任何原创数据点(自家产品的脱敏使用数据、行业小调研结果),都比1万字的二手内容更容易被AI引用。原创数据的稀缺性是新鲜信号最强的来源。
杠杆三:建立“最新动态”时间轴页面。一个长期维护的“最新动态时间轴”页面(每条带具体日期、内容、来源),是AI爬虫眼中的高价值新鲜源。AI模型在回答时间相关查询时会优先抓这种页面。我个人博客上就维护了一个《Google算法更新时间轴》页面,是博客流量最稳定的来源之一,过去6个月在Perplexity里被引用了120多次。
用Search Console与AI引用扫描双轨监控
更新内容后,怎么知道效果?我自己跑的是“Search Console + AI引用扫描”双轨监控,两套数据互为佐证才能客观判断。
Search Console侧重的是Google抓取和索引行为:更新提交后14天内,“索引覆盖率”里的“上次抓取时间”是否已经更新是核心指标。如果14天后还没回抓,说明sitemap的lastmod或IndexNow没有正确触发,需要排查。同时盯“核心网页指标”里更新页面的LCP、CLS是否退化——某些更新(比如新增大量图片或脚本)可能在不知不觉中拉低性能分。
AI引用扫描侧重的是模型可见性。我自己用一个简单的Python脚本,每两周向ChatGPT、Perplexity、Gemini、Claude各自的API发20-50个核心查询词,记录回答里的引用URL。把每次扫描结果保存成JSON,按周对比就能看到引用URL的命中变化趋势。
这两套数据要做交叉对照:如果Search Console显示Googlebot已重新抓取,但AI引用扫描显示引用率没提升,问题可能出在“新鲜度感知正确但内容质量不足以胜出”。这时候要回头看更新内容的原创度和数据密度。
常见的“假新鲜”陷阱
有几种新鲜度操作看起来在更新,实际上对AI没用甚至适得其反,列出来避坑:
陷阱一:只改datePublished不改内容。有些SEO老手为了让旧文“重新被Google爬虫看见”会偷偷把发布日期往后挪。这个操作在传统SEO里勉强有效,但AI模型会对照内容指纹,发现内容没变只改了日期,会把这个站点的整体可信度往下降。
陷阱二:用AI生成的“2026年最新趋势”段落。用AI生成一段“最新趋势预测”拼到旧文末尾,几个站点同时这么做的话,AI模型很容易识别出多站点内容指纹相似,把整批内容判定为低质量重复。
陷阱三:高频微调修改。一篇文章一周改五次、每次只改一两个字,会让爬虫困惑——这种小幅高频更新会被识别成“频率污染”,反而拖累内容评分。健康的更新节奏是每次更新至少新增10%-20%的实质性内容,少于这个量级的修改不要触发主动通知。
陷阱四:旧文堆“2026年”字眼。有些站长为了蹭新鲜度,把所有旧文标题前面都加上“2026年最新”字样,但内容本身还是2023年的。AI模型读取上下文后会发现内容和标题严重不符,判定为标题党,不仅不引用,还可能给整站打负分。
陷阱五:批量同步发布大量短内容。有些团队为了营造“持续更新”的假象,会在短时间内批量发布几十篇短文章。这种行为会触发AI模型的“内容农场”识别,整站权重会被压低。健康的发布节奏是稳定的、有间隔的、单篇内容达到合理深度的——一周3-5篇1500字以上的优质内容,比一天发20篇短文有用得多。
中文AI生态里"新鲜度"这件事,要改掉的几处打法
上面那套流程——IndexNow 推送、RSS 全文输出、sitemap 的 lastmod、五种时间锚点——主要是对着 ChatGPT、Perplexity、Bing 这一组 AI 和搜索引擎调出来的。可保哥的客户里有一大半盯的是豆包、DeepSeek、百度 AI、Kimi,这几位对"新鲜度"的感知通道和西方那套并不重合。底层逻辑完全一致:AI 都偏爱有明确时间锚点、可溯源的新鲜内容。但具体的推送管道、数据源、避坑红线,搬到中文生态得改掉好几处,照搬只会做无用功。
先说推送通道。IndexNow 在国内主要喂的是 Bing 和 Yandex,对国产 AI 的覆盖很有限。喂百度系的另有一套——百度搜索资源平台里的链接提交,分"普通收录"和"快速收录",其中通过 API 做的实时推送(早年叫"主动推送"),才是把更新内容快速送进百度索引、进而被百度 AI 感知的正路。所以国内站点更新完一篇核心页,IndexNow 该推还推(覆盖 Bing),但真正决定百度端新鲜度感知的,是百度的链接提交 API 有没有同步触发。两条线都要接,缺了百度这条,你在百度 AI 里的"首次引用时间"压根压不下来。
更关键的是豆包和 DeepSeek 这类对话式 AI 的新鲜信号,根本不只走爬虫这一条路。豆包重抖音头条系加公众号,DeepSeek 偏知乎和公众号——它们感知"这个话题最近有新内容",很大程度上是从这些内容平台的更新里读出来的。这意味着存量文章在自己站点上刷新之后,还得在公众号、知乎专栏同步发一版"更新说明"或者改写版,等于用平台号当 RSS,把更新信号推到中文 AI 真正在听的那几个频道上。光在自己站内改完干等,中文 AI 很可能根本不知道你更新了。
时间锚点也要整套本土化。原文那五种锚点的思路全对,但拿的例子得换。"2026 年 Q3 SimilarWeb 数据""2026 年初 Statista 报告"这类,对中文 AI 的可信度加成有限——换成艾瑞、QuestMobile、易观、CNNIC、国家统计局这些中文 AI 真正认的权威源,引用率才上得去。用行业事件当时间标尺也一样,"2024 年 3 月 Google Helpful Content Update 之后"对中文 AI 的知识图谱定位价值很低,换成国内有公共记忆的事件——某次百度算法更新之后、某个双 11 大促之后、某部新规实施之后——才能让中文 AI 准确锚定内容的时效位置。
"假新鲜"这条红线,在中文场景比海外还要紧。百度的飓风算法本来就盯着采集、拼凑、标题党,旧文堆"2026 最新"字眼、内容却还停在 2023 年,这种操作在百度比在 Google 更容易直接吃降权——百度对内容原创度和站点历史的看重,让它对这种蹭新鲜的小动作几乎零容忍。反过来,中文内容生态里伪数据泛滥,所以一条带可溯源中文权威源(标明国家统计局、艾瑞某份具体报告)的更新,比一条来路不明的英文数据,在中文 AI 眼里可信度要高得多。中文 AI 对"模糊新鲜"的惩罚更狠,对"可验证新鲜"的奖励也更明显。
保哥手上有个反例特别典型。一个出海转内贸的客户,把原来的英文旧博客机翻成中文、末尾拼一段"2026 latest trends"就当刷新了,推送、改日期一样没落下。结果豆包、DeepSeek 几乎一次都不引——机翻腔的中文本来就被中文 AI 判低质,加一句英文味的"最新趋势"更是火上浇油。后来整篇用中文重写、补进艾瑞的真实数据、再在知乎和公众号同步发更新版,才第一次被中文 AI 重新引用。新鲜度的底层逻辑是通用的,但喂给中文 AI 的料、走的管道、踩的红线,跟海外是两套火候。
刷新存量内容时最容易踩的"翻车式更新"补充3例
文中那五个"假新鲜"陷阱讲的多是"假装更新"。保哥这里补三个不一样的——它们都是真更新、真投入了功夫,却因为动作不对,反而把原有的新鲜度和引用给做没了。这三种翻车比假新鲜更可惜,因为你明明出了力,结果却是负的。
第一个,更新时把还在被 AI 引用的旧事实句、旧数据句一起删了重写。很多人刷新内容的习惯是"推倒重来",看到旧段落就想整段换新表述。问题是,AI 对你这篇内容已经建立了"内容指纹"——它记住的是某几句具体的事实陈述、某个具体的数据点,引用时引的就是这些。你把这些仍然成立的旧锚句删掉换了新说法,AI 那边的指纹对不上了,原本稳定的引用反而掉下来。这跟改 URL 丢权重是同一个逻辑,只不过发生在句子级别。正确的更新姿势是叠加而不是推翻:仍然成立的旧数据、旧定义句尽量保留原样,新数据、新章节往上加,让 AI 既能认出老朋友、又能读到新内容。别对一段正在给你贡献引用的文字动大手术。
第二个,一次性把 20 到 50 篇核心页全在同一天刷新、再全部 IndexNow 推送一遍。团队排好了内容审计计划,憋了两周一口气把所有核心页都更新完,然后当天集中推送——这个动作本身没错,错在节奏。无论是百度还是中文 AI,都会把"整站几十个 URL 同一天集中异动"识别成异常模式,触发批量异动的风控,反而压低对整站的信任。这和原文里"别把所有 URL 的 lastmod 都改成今天"是同一个道理,区别在于这次你是真更新了,可真更新也架不住批量集中。健康的做法是分批小步、把更新日期自然错开——这周刷五篇、下周再五篇,让站点的更新曲线看起来是持续而有节奏的,而不是一根突兀的尖峰。
第三个,只更新正文,却忘了更新内链外链指向的目标页。保哥审计时遇到过一篇标题写着"2026 最新指南"的文章,正文数据也确实换新了,可它正文里链出去的那些支撑页、引用的那些外部来源,还都停在 2023 年。AI 顺着链接去做交叉验证时,发现这篇"最新"文章引以为据的整条链路全是陈旧内容,新鲜度信号当场被链路拖了下来——你声称自己新,可你站着的那块地基是旧的。所以更新一篇核心页,不能只盯着这一篇的正文,得连带审计它内链指向的支撑页、外链引用的权威源是不是也该刷新了。新鲜度是一张网,单点再新,挂在一堆旧节点上也撑不起来。
这三个翻车背后是同一个认知误区:把"内容更新"当成了一篇文章孤立的事。真实情况是,AI 对你的感知是建立在内容指纹、站点节奏、链接网络这三层之上的——动正文的时候,这三层都在被一起重新评估。更新前先想清楚:这次改动,会不会打断 AI 已经认住的引用锚点?会不会在站点层面制造异常的批量信号?会不会让一篇新文章孤零零地链向一堆旧页面?把这三个问题答好了,你那份真投入的更新功夫,才不会做成负分。
常见问题解答
每次更新内容必须重新发到IndexNow吗?
建议是的,但有节奏。如果是大幅更新(新增数据、改写章节),更新完立即通过IndexNow推送。如果只是修正错别字这种微调,就不用推送——AI爬虫看到IndexNow推送的URL会优先回抓,频繁推送微小修改会浪费配额还可能被降权。我给客户的规则是“内容字数变化超过15%或新增小节才推送”。
更新声明应该放在文章顶部还是底部?
都放最好。顶部放一行简短的“最后更新于 2026 年 X 月 X 日”让用户和爬虫第一眼看到;底部放一段更详细的“2026年X月更新内容:本次新增了A、B、C三处”让AI在阅读完正文后再次确认新鲜度。两处声明都用清晰的日期,不要写“最近更新”“不久前”这种模糊表述,AI解析模糊表述的能力很弱。
站点没有RSS,是不是要补一个?
非常推荐补。哪怕只是首页一个统一的RSS,也比没有强。RSS对AI爬虫的价值不只在内容发现,还在“频率证明”——一个稳定输出新内容的RSS feed,会让爬虫给整个站点更高的抓取优先级。WordPress、Typecho、Hexo、Hugo都自带RSS输出。自定义站点用Python或PHP简单写个feed.xml生成器,半天能搞定。
禁止GPTBot会不会影响ChatGPT在搜索时引用我的内容?
会影响。GPTBot主要负责训练数据采集,但OpenAI的检索爬虫(OAI-SearchBot、ChatGPT-User)和它共享部分基础设施,禁掉GPTBot的同时如果没明确允许另外两个,实际效果是这三个爬虫都进不来。最稳妥的做法是显式列出每个UA是Allow还是Disallow,不要只用通配符。
更新频率是不是越高越好?
不是。0.78的相关性系数对应的是“每月更新”级别,再往上提升到“每周更新”甚至“每天更新”对引用率的边际提升非常小,反而会拉低单次更新的内容深度。我推荐的最优区间是每1-3个月一次大更新+季度性的内容审计,单次大更新要至少新增15%-30%的实质性内容(数据、案例、新章节)。
怎么判断哪些页面应该高频更新,哪些不应该?
三个维度判断:第一,主题时效性——讲算法、技术、市场数据的内容时效性强,需要高频更新;讲历史、文化、基础概念的内容时效性弱,更新带来的引用提升有限。第二,当前流量水位——已经有稳定流量的页面值得投入更新,长期没流量的页面优先做内容质量审计而不是简单更新。第三,竞争密度——同一查询词下竞争页面多的话,新鲜度是关键差异化武器;竞争少的长尾词,更新频率反而不是决定因素。
RSS输出全文会不会让别人轻易抄袭我的内容?
抄袭风险一直存在,但靠RSS截取摘要并不能解决——任何能爬全文的人都能爬。真正有用的反爬措施是法律层面的版权登记和DMCA投诉路径,技术上可以在RSS里加内容指纹标记(一段隐藏字符或独特短语),便于追溯抄袭来源。RSS输出全文带来的引用提升远大于“防抄袭”损失,我建议优先输出全文。
权威参考资料
本文标题:《AI引用优化:内容新鲜度的5条实战法则》
本文链接:https://zhangwenbao.com/maintain-content-freshness-fast-indexing-ai-citations-2026.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0