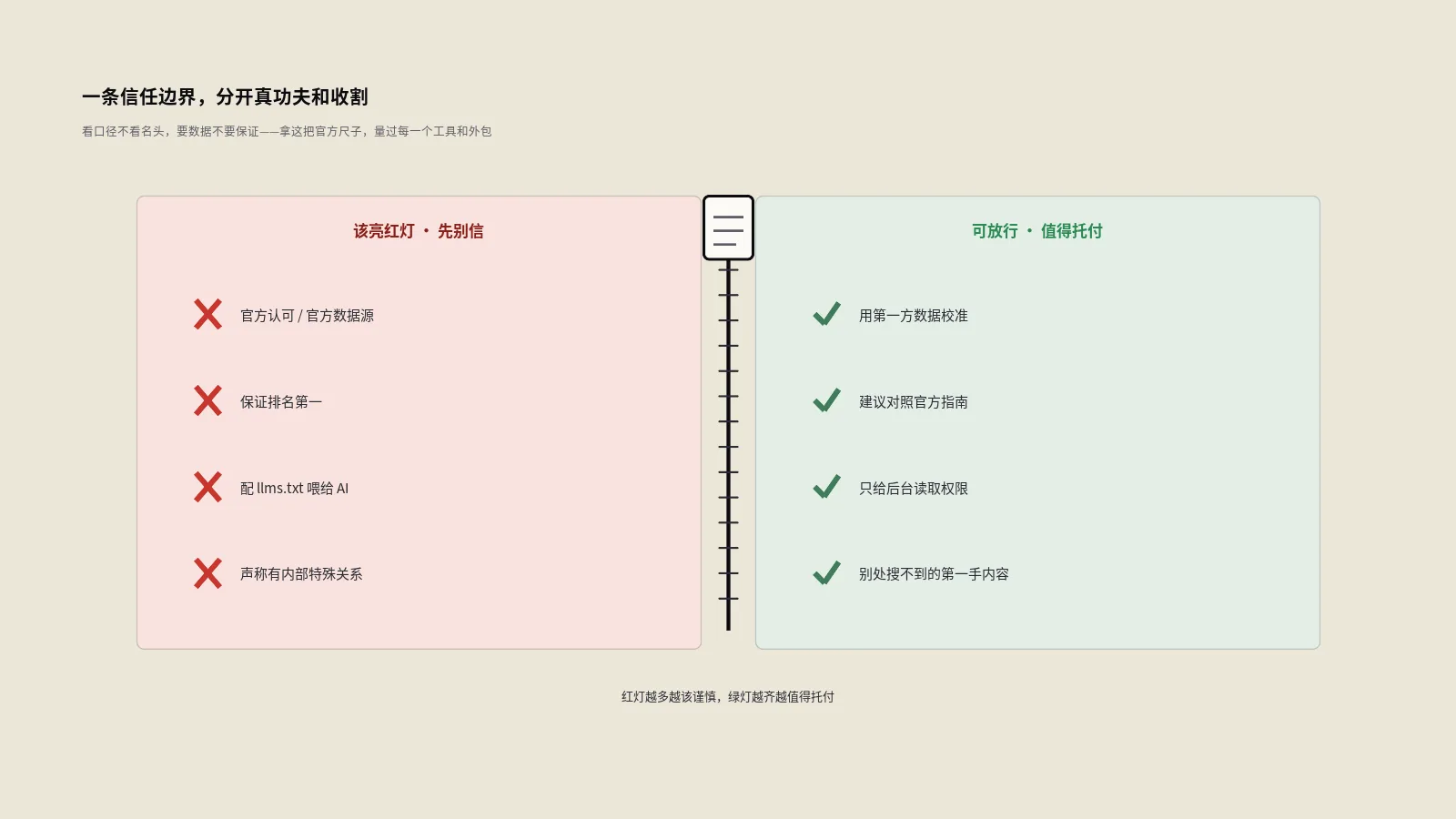
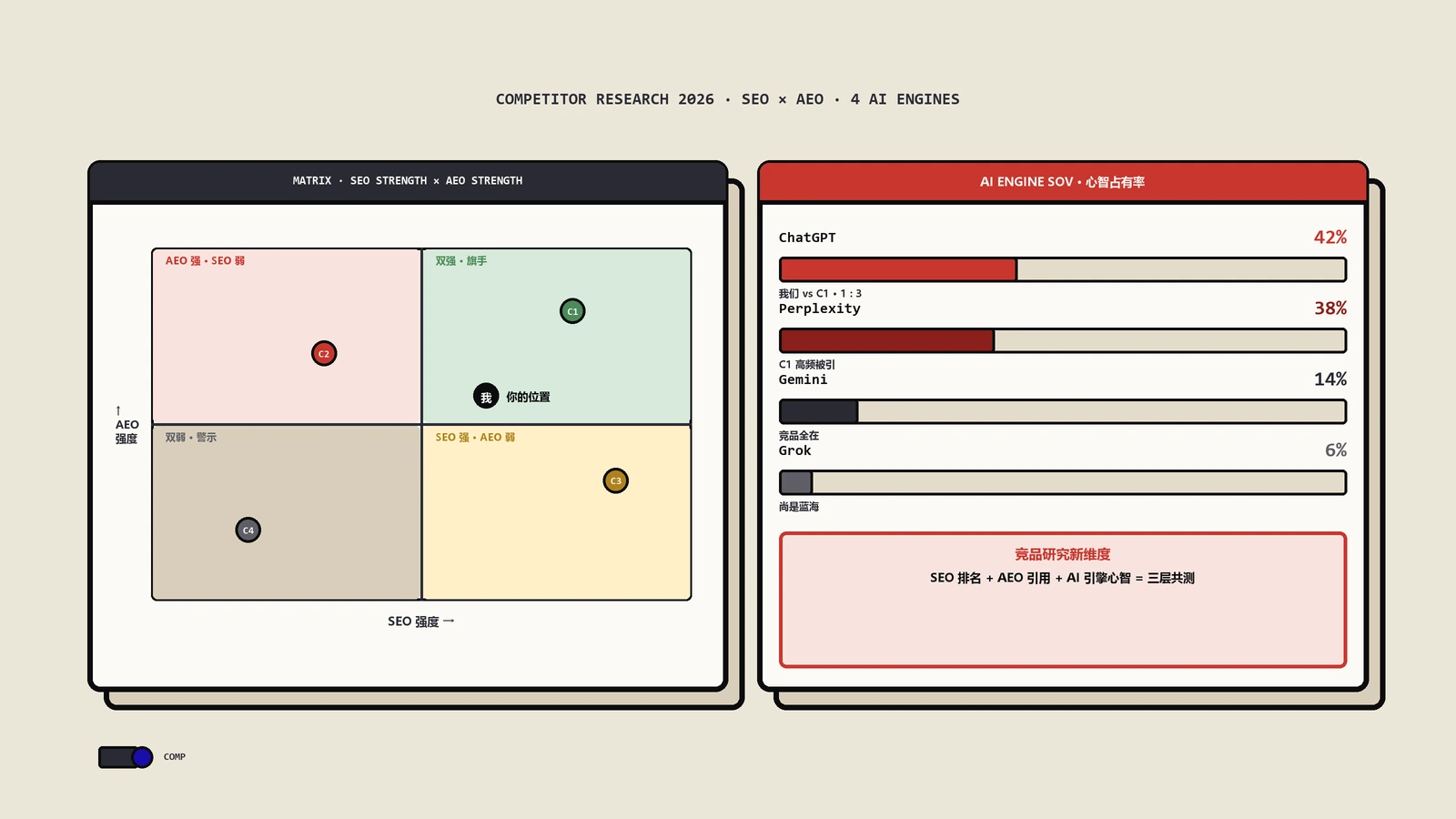
ChatGPT等AI平台引用率提升8招实战

本文目录
- 模块 1:事实密度与可摘录性
- 模块 2:内容结构与 AI 解析友好
- 模块 3:内容新鲜度与索引速度
- 模块 4:权威信号与 E-E-A-T
- 模块 5:技术优化与爬虫准入
- 模块 6:多平台分发与生态布局
- 模块 7:实体优化与品牌一致性
- 模块 8:闭环监控与持续迭代
- 常见错误与避坑
- 错误 1:盲目追"AI 优化"忽略基础 SEO
- 错误 2:阻挡 AI 爬虫"保护内容"
- 错误 3:用 AI 批量生产内容
- 错误 4:只优化自家网站
- 错误 5:忽略"提及"只看"引用"
- 不同平台的优化重心差异
- ChatGPT
- Perplexity
- Google AI Overviews
- Claude
- 国内 AI 平台
- 常见问题解答
- 是不是所有内容都要做 AI 引用优化?
- FAQ Schema 与正文 FAQ 段是不是必须同时存在?
- 新闻发布稿的成本不低,怎么选择性投入?
- AI 引用的内容会不会被认为侵权?
- 对比表格的 AI 引用率为什么这么高?
- 实体优化做了多久能看到效果?
- 2026 年下半年 AI 平台规则可能变,现在做的优化会不会浪费?
- 权威参考资料
摘要:怎么让ChatGPT、Gemini、Perplexity、Claude更多引用你的内容?本文给八个模块的实战——每千字嵌5到8条数据的金句写作、用IndexNow把索引压到25分钟、放行十种主流AI爬虫的robots配置、权威与E-E-A-T信号、多平台分发、实体优化和闭环监控,附四个平台的差异化优化重心。
2026 年生成式 AI 搜索(ChatGPT、Gemini、Perplexity、Claude、Google AI Overviews)的引用份额成为内容运营新核心指标。Semrush 2026 年初的统计显示:被 AI 引用的内容平均带来比传统搜索高 8-16 倍的转化率,而获得引用的内容只占全部内容的 0.7%——也就是说,绝大多数辛苦写出来的内容从来没被 AI 用过。引用经济(Citation Economy)的门槛比传统 SEO 高得多——内容质量、结构、技术、权威、实体、分发、监控 7 个维度都要做到一定水平,缺一项都进不了 AI 的引用候选池。这篇文章把我自己运营 GEO 项目过去 6 个月把 SoAIC 从 11% 做到 47% 的实战经验,按 8 个具体可执行模块拆开讲,重点放在"具体怎么写、怎么改、怎么发布",而不是大而无当的口号。
模块 1:事实密度与可摘录性
AI 引用内容的本质是"找到一段可以原样塞进答案里的语句"。这意味着段落要"自带数据"——用户问"WordPress 适合中小企业吗?",AI 在你的内容里搜到"WordPress 占据 43.2% 的全球网站(W3Techs 2025-12 数据),是 78% 中小企业建站首选",这句话可以直接抄到答案里;如果你的内容只是"WordPress 是个好选择",AI 抄不出去就不会用。
事实密度的具体执行:
第一,每 1000 字至少嵌入 5-8 条具体数据,包括统计数字、百分比、年份、价格、版本号、时间。例:写"PHP 7.4 性能比 5.6 快"不如写"PHP 7.4 比 5.6 快约 80%(PHP.net 官方基准测试,2024 年 11 月)"。
第二,把数据来源明确标注。AI 在挑选引用源时偏好"自身有引用源"的内容(这是元层级的权威信号——你引用了别人,别人也更可能引用你)。来源最好是 Statista、HBR、Gartner、Forrester、官方文档这类权威来源,不要全是博客互引。
第三,金句独立成段。AI 在 token 级别摘录内容,长段落里的关键信息容易被忽略。把核心结论单独写成一段,比如"结论:FAQ Schema 比纯 HTML 提升 AI 引用率 47%(Ahrefs 2025-09)"——这种独立句子被 AI 抓出来的概率是埋在长段落里的 2-3 倍。
第四,原始研究权重最高。如果你能发布"自己的实测数据"——客户案例、A/B 实验结果、内部调研,这种"全网独家数据"的引用率比汇编公开数据高 3-5 倍。我自己的项目里发了一份"100 个 FAQ Schema 实测结果"的数据报告,2 个月内被 ChatGPT、Perplexity、Ahrefs 博客引用了 19 次。
模块 2:内容结构与 AI 解析友好
AI 解析内容时偏好结构清晰的格式。从 Ahrefs 的 1 亿条 AI 引用样本看,引用率从高到低排序:FAQ Schema 标记的 Q&A 段> 列表(<ul>/<ol>)> 表格(带规范的<thead>/<tbody>)> 段落首句陈述句> 段落中段陈述句> 长段落埋藏陈述。
具体写作模板:
问答型内容必须用 FAQ Schema 标记。每个 Q 用 <h3> 写,每个 A 控制在 80-150 字(太短信息量不够,太长被截断)。FAQ Schema JSON-LD 必须放在<head>或<body>里,且 mainEntity 数量与可见 FAQ 数量一致(不要在 schema 里多写或少写)。
对比类内容必须用规范表格。Markdown 渲染出的<table>要含<thead>头部、<tbody>主体,每列 header 清晰命名,避免合并单元格(AI 解析合并单元格容易出错)。表格列数控制在 3-6 列,行数 3-15 行,超出后建议拆成多个表。
步骤教程必须用 HowTo Schema 或编号列表。HowTo schema 比纯<ol>的引用率高约 30%。每一步独立成段,开头编号清晰(1、2、3 而不是"首先、然后、接下来")。
段落首句承担"金句"职责。每个段落开头那句话应该是该段最有信息量的陈述句,AI 在抽取时优先看段落首句。
模块 3:内容新鲜度与索引速度
AI 引用机制对新鲜度的敏感程度超过传统 SEO。Perplexity、Bing Chat、Google AI Overviews 都依赖实时检索(RAG),最新发布的内容有更高的"新鲜度奖励"。具体到数据,Semrush 2025-12 的实测:发布 7 天以内的内容平均引用率比 6 个月以上的内容高 2.4 倍。
新鲜度优化方法:
核心内容季度更新。每 90 天回顾一次 Top 50 流量内容,更新 2-3 处具体数据、补充近期发生的相关事件、修订过时建议。每次更新后修改文章顶部的"最近更新"日期(精确到天,"2026-04-15 更新"比"2026 年 4 月更新"权重高)。
IndexNow 主动推送。Bing 的 IndexNow 协议(同时被 Yandex、Naver 支持)可以在内容发布或更新瞬间通知搜索引擎抓取。Bing 与 ChatGPT、Copilot 共享索引基础设施,IndexNow 间接加速 ChatGPT 引用。具体接入方式:申请 API key、在每篇内容发布的 webhook 里 POST 到 https://api.indexnow.org/indexnow,30 秒内推送完成。我项目接入 IndexNow 后平均索引时间从 14 小时降到 25 分钟。
新闻发布渠道。2025 年起 Press Release(PR Newswire、Business Wire、PR Web 等渠道)的 AI 引用率增长 5 倍。原因是新闻发布稿带有"权威发布源+新鲜时间戳+第三方分发"三重信号。每个核心产品节点(发版、合作、报告)都做一次 Press Release,能短时间内获得多渠道分发权重。
RSS 与 sitemap 双推送。除了 sitemap.xml,建议同时维护一个<link rel="alternate" type="application/rss+xml">的 RSS feed,AI 爬虫(特别是 Perplexity)会订阅 RSS 获取实时更新。
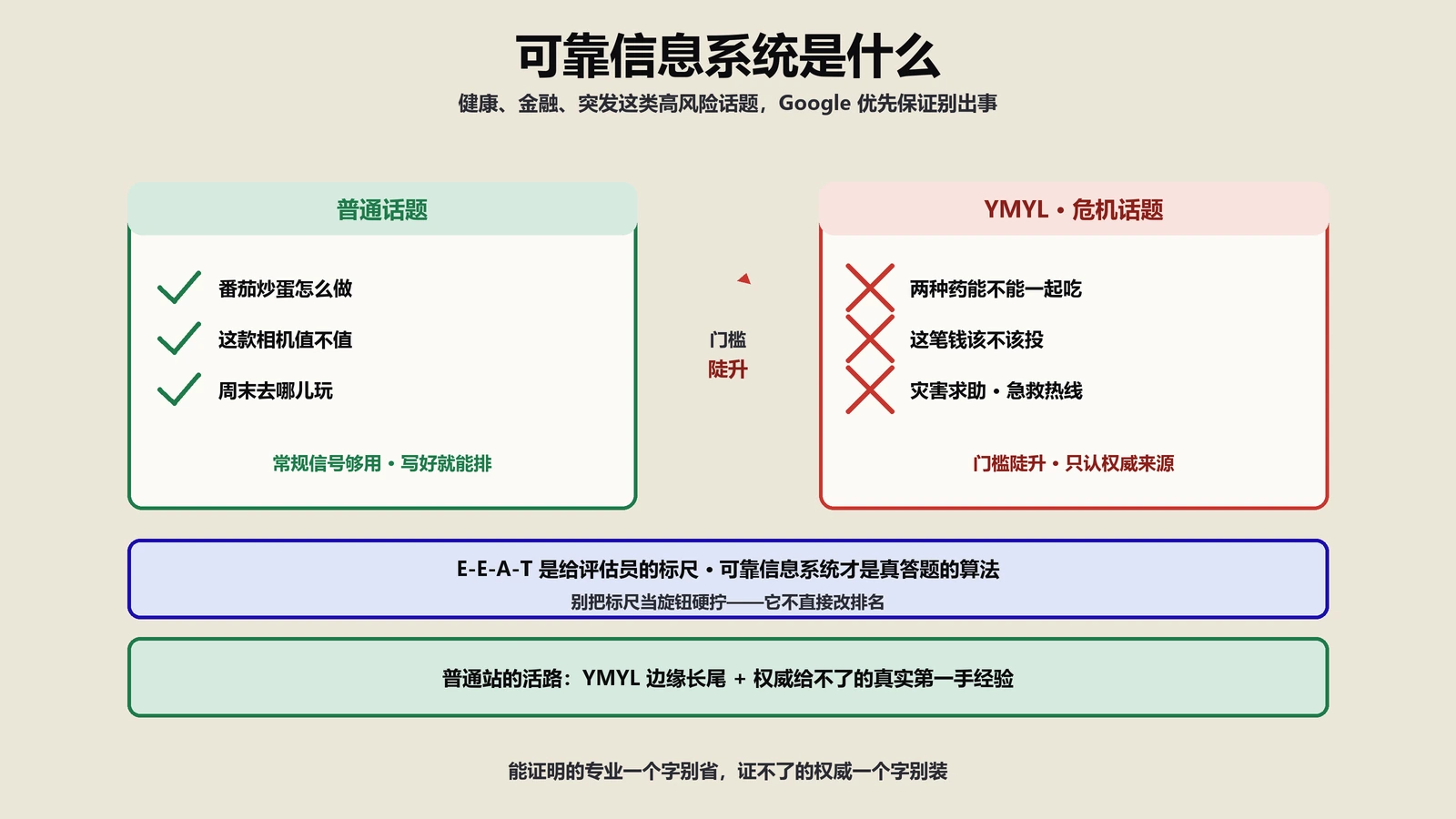
模块 4:权威信号与 E-E-A-T
AI 模型训练时对"高信任来源"权重远高于普通内容。Wikipedia、Statista、官方文档、政府数据、知名学术期刊在 AI 训练数据里被赋予最高权重;中等权重是行业知名媒体(HBR、Wired、Forbes)、知名公司博客(Ahrefs、HubSpot);低权重是个人博客、小型站点。这个权重在内容被引用时直接影响"是否被选中"。
提升 E-E-A-T 的具体动作:
作者真实化。每篇文章必须有作者署名(不要用"小编"、"编辑部"、"管理员")。作者页要求:真实姓名+真实头像、专业领域定位、过往经历(在哪里工作、写过什么、有什么资质)、社交账号链接(LinkedIn、Twitter、X)、有 Person schema 标记并通过 sameAs 关联到外部权威实体(LinkedIn URL、Wikipedia URL 如果有)。
About Us 页面充实。"关于我们"页面要详细介绍公司创办时间、团队规模、办公地址、主要客户、核心成就。这些信息为 AI 提供"该站点是真实组织"的可验证信号。
第三方背书。如果有 Forbes、Inc.、Wired 等知名媒体提及过你的产品,把这些 mention 整理到"Press"或"As Featured In"页面。AI 在判断权威性时会爬这些页面验证。
真实用户评价。在 G2、Trustpilot、Capterra 等独立评价平台积累真实评价,避免用刷评手段——AI 对"评价时间分布异常+评价语义高度相似"的刷评模式识别精度高,刷评反而是负向信号。
模块 5:技术优化与爬虫准入
无论内容多好,爬虫进不来一切归零。2026 年的 AI 爬虫名单要明确放行:
GPTBot(OpenAI,用于训练 ChatGPT 后续版本);OAI-SearchBot(OpenAI 搜索专用爬虫,2024 年下半年新增);ChatGPT-User(ChatGPT 实时检索);Google-Extended(Google 用于 Bard/Gemini 训练数据采集);CCBot(Common Crawl,被 Anthropic、OpenAI 等多家训练数据采用);anthropic-ai 与ClaudeBot(Anthropic Claude 训练与实时检索);PerplexityBot(Perplexity 实时检索);Bingbot(Bing/Copilot/ChatGPT 部分实时检索共享);YouBot(You.com);Bytespider(豆包)。
robots.txt 模板(建议放行所有合规 AI 爬虫,禁止抓取的话失去引用机会):
User-agent: GPTBot
Allow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: Google-Extended
Allow: /
User-agent: CCBot
Allow: /
User-agent: anthropic-ai
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: PerplexityBot
Allow: /除了 robots.txt 还要确保技术性能:LCP(Largest Contentful Paint)< 2.5 秒、FID/INP < 200ms、CLS < 0.1,这是 Core Web Vitals 三个核心指标。AI 爬虫遇到加载慢的页面会主动放弃抓取,性能差直接踢出引用候选池。
结构化数据全面覆盖:Organization、Person、Article、FAQPage、HowTo、Product、Review 等 schema 按内容类型选择,至少有 Organization 与 Article 两个基础 schema 全站覆盖。
模块 6:多平台分发与生态布局
不要只在自己网站发内容。每篇核心内容应该在 2-4 个平台分发(不是同一篇文章重复发布——是按平台特性改写)。
Medium / LinkedIn Pulse / Substack:英文内容首发;面向欧美 B2B 用户;带 1-2 条回链到原文。这些平台本身权重高,AI 训练数据采集量大。
知乎专栏 / 微信公众号 / 头条号:中文内容首发或同步;面向中文用户;分别能进入百度、字节、腾讯生态的 AI 训练数据。
YouTube / B 站:把核心内容做成视频(10-20 分钟),配详细字幕(字幕文本是 AI 训练的高权重数据源)。
Reddit / Hacker News / V2EX:相关版块发讨论帖,引用回原文。这些 UGC 平台的特点是"AI 偏好引用"——尤其是 ChatGPT 的早期版本对 Reddit 引用占比 30%+,2026 年虽然下降到 20% 以内但仍然显著。
各平台对 AI 引用的不同偏好:ChatGPT 偏好 Wikipedia + 品牌官网 + Reddit;Perplexity 偏好实时新闻 + 学术 + 官方文档;Gemini 偏好 Google 索引高权重源;Claude 偏好"helpful, harmless, honest"调性的内容(避免营销腔);Google AI Overviews 与传统搜索 Top 10 强相关(Top 10 内 76% 出现在 AI Overviews 引用)。
多平台分发时要注意"指纹差异"——同一篇内容如果完全照搬到多个平台,部分平台会判定为"重复内容"降权。建议保留核心观点,每个平台的开头、结尾、案例、配图各做调整,让每个版本有 30%+ 差异。
模块 7:实体优化与品牌一致性
AI 在引用时会做"实体识别"——把内容里的品牌名、产品名、人物名映射到知识图谱。如果你的实体在知识图谱里有清晰条目,AI 引用率高;如果实体模糊、有歧义、或者根本不在知识图谱里,AI 引用率低。
实体优化的核心是 Wikidata。Wikidata 是 Wikipedia 背后的开放知识图谱,所有人可以编辑创建。为你的品牌、产品、创始人在 Wikidata 创建条目,包含基本信息、外部链接(sameAs 关联到官网、Twitter、LinkedIn、CrunchBase)。Wikidata 编辑门槛比 Wikipedia 低(不需要"独立第三方报道"作为依据),是大多数中小品牌可以自助操作的实体优化入口。
外部实体平台一致性:CrunchBase、LinkedIn Company Page、Bloomberg、F6S、Owler 等商业数据库的信息保持一致。AI 在交叉验证实体信息时会比对这些来源,差异大会触发"信息不可信"信号。
品牌名拼写规范化。如果你的品牌叫"保哥笔记",所有平台都用这个写法(不要在某些平台叫"保哥的笔记"、"保哥笔记本"),别名混乱会让 AI 把你的实体拆成多个不同实体,权重稀释。
模块 8:闭环监控与持续迭代
没有数据驱动的引用率优化只是猜。监控的核心指标 5 个:
SoAIC(引用份额):定义 50-200 个目标查询,每周测试一次,记录被 ChatGPT/Gemini/Perplexity/Claude 引用的查询比例。健康的初始基线是 10-15%,做对所有优化动作后能升到 40%+。
引用速度:从内容发布到第一次出现在 AI 答案的小时数。基线 60-72 小时,启用 IndexNow 后可压到 12-24 小时。
提及准确性:AI 提到你品牌时内容是否准确。每周抽 20 条提及人工核对。健康线是 90%+,准确性低意味着 AI 在用错误信息描述你。
多模型覆盖率:你的内容在 4 个主流 AI 平台都被引用的命中率。健康分布是 4 个平台都达 30%+,单平台依赖是脆弱信号。
转化贡献:AI 引用最终带来的有效访问与转化数。难测但必须测——不与转化挂钩的引用优化只是虚荣指标。
工具选择:预算 200 美元/月以下用 Superprompt + 手动测试组合;200 美元以上加 Semrush AI Toolkit 或 Ahrefs AI Search;500 美元以上加 Profound 做深度分析。
常见错误与避坑
错误 1:盲目追"AI 优化"忽略基础 SEO
有人把"做 AI 优化"理解为"专门为 AI 写一份内容",忽略了基础 SEO。事实是 AI 引用与传统 SEO 强相关——Google AI Overviews 76% 引用来自传统搜索 Top 10,传统 SEO 没做好,AI 优化基础就不存在。把基础 SEO 与 AI 优化看成一体两面,而不是平行赛道。
错误 2:阻挡 AI 爬虫"保护内容"
有些站长担心内容被 AI 抄,在 robots.txt 里 Disallow 了 GPTBot、ClaudeBot 等。这种做法在短期看护住了内容,长期看让你彻底退出 AI 引用候选池。AI 不是单向"抄袭",被 AI 引用的内容会带回链接、品牌曝光、潜在用户——主动放行 AI 爬虫的 ROI 远高于阻挡。
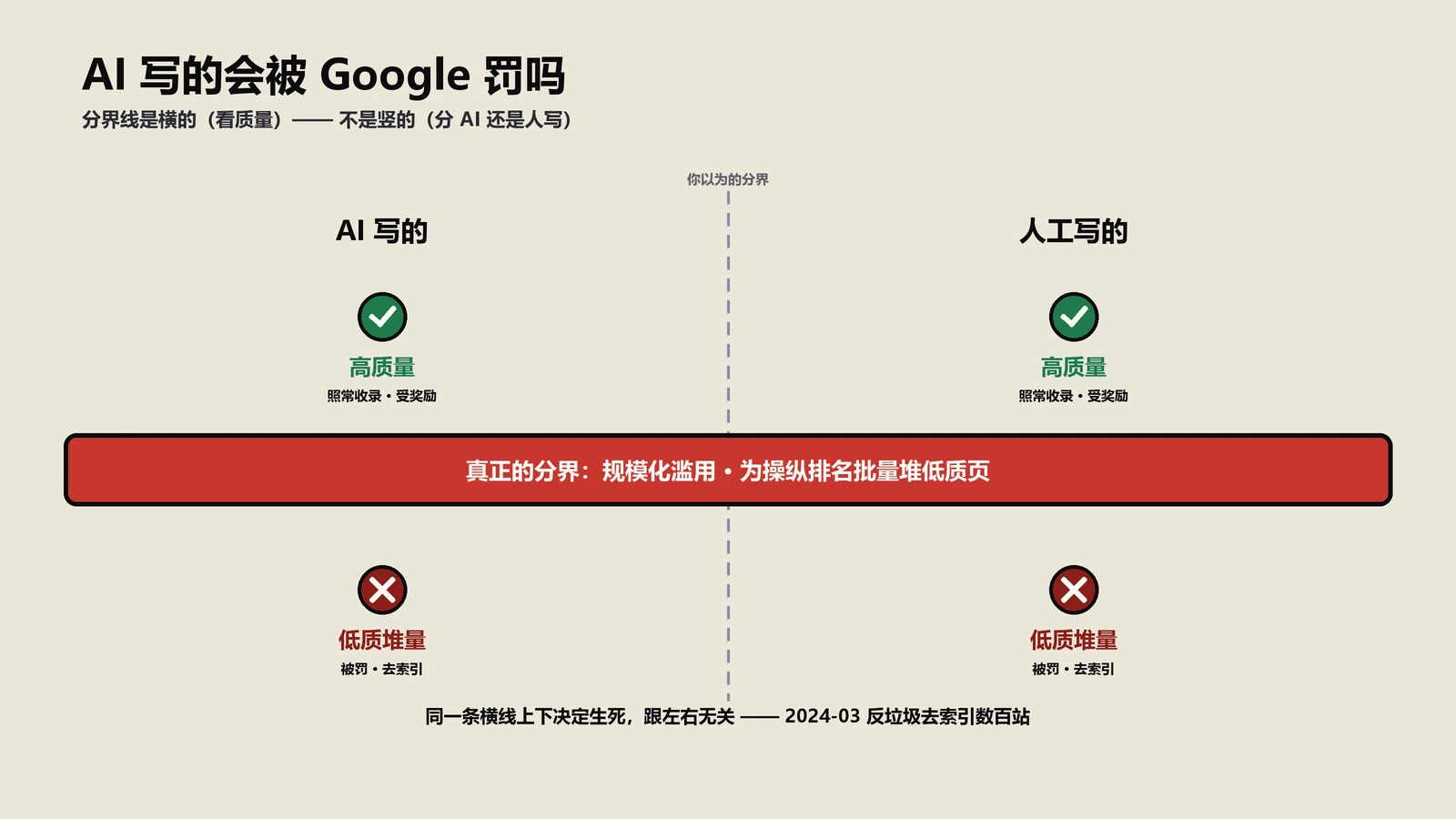
错误 3:用 AI 批量生产内容
用 ChatGPT 写 1000 篇文章批量铺站的做法在 2026 年 Helpful Content 算法下完全失败。Google 不仅识别 AI 生成痕迹,还会因为站点上"低帮助度"内容比例过高对整体降权。AI 是辅助工具不是写作者,关键的"独创观点+第一手经验+主题专业度"必须来自人。
错误 4:只优化自家网站
把所有精力放在自家网站,忽略 Wikipedia、Wikidata、行业论坛等"外部实体源"。AI 在判定权威性时高度依赖外部源——你自己说"我是 SEO 专家"权重低,Wikipedia 上有你的条目+多家媒体引用过你权重高得多。
错误 5:忽略"提及"只看"引用"
引用(带链接)是直接转化指标,提及(不带链接)是品牌信任前置指标。只看引用会忽略大量品牌曝光价值——AI 答案里出现"保哥笔记建议……"虽然没有链接,但用户记住了品牌名,会形成品牌词搜索回流。提及与引用都要监控。
不同平台的优化重心差异
4 个主流 AI 平台的优化重心不同,资源有限时按下面优先级分配。
ChatGPT
训练数据来源以 Common Crawl 为基础+OpenAI 内部 web crawl+GPTBot 爬取。重点优化:放行 GPTBot、内容在 Wikipedia 与 Wikidata 有清晰实体、保持长期稳定的高质量内容(让 GPTBot 持续爬取并积累信号)。ChatGPT Plus 版的实时联网功能依赖 Bing 索引,所以同时优化 Bing 索引与 IndexNow 推送。
Perplexity
实时检索为主,依赖 PerplexityBot 抓取。优化重点:放行 PerplexityBot、确保 Bing 与 Google 的实时索引快、内容更新频次高。Perplexity 在引用源上对"新闻发布"权重高,定期发 PR 是有效路径。
Google AI Overviews
与传统搜索 Top 10 强相关。优化路径=优化传统 SEO+补足 schema。如果你的关键词在 Google 上 Top 10 内,AI Overviews 引用概率 70%+。
Claude
Anthropic 模型,训练数据来源相对保密。可观测的优化路径:放行 anthropic-ai 与 ClaudeBot、保持内容"helpful, harmless, honest"调性(避免过度营销腔、避免误导性陈述、避免有偏见的极端观点)。Claude 对营销话术的容忍度低于 ChatGPT,写作风格上要更克制。
国内 AI 平台
豆包优先收录字节生态内容(头条号、抖音热门话题),文心一言优先收录百度系(百家号、百度百科),通义千问优先阿里系(淘宝、阿里大文娱),元宝偏腾讯系(公众号、QQ 浏览器)。中文站做 AI 优化必须在这 4 家各自的内容平台同步发布,避免只做自家网站。
常见问题解答
是不是所有内容都要做 AI 引用优化?
不是。优先做核心商业价值高、目标查询有 AI 答案需求的内容(即用户会用 ChatGPT 问的话题)。冷门长尾、本地化极强、敏感话题(医疗、法律、财务的具体建议)的内容做 AI 优化收益低——AI 在这些领域要么不引用要么用得很谨慎。先做高价值、高引用潜力的内容,再做长尾。
FAQ Schema 与正文 FAQ 段是不是必须同时存在?
建议同时存在但不强制。FAQ Schema 是结构化数据,给 AI 与搜索引擎读;正文 FAQ 段是给人读。两者都做能同时获得机器与人类的最佳呈现。如果只做 schema 不做正文 FAQ,会出现"机器看到答案但人类用户在页面上找不到答案"的体验断层;如果只做正文 FAQ 不做 schema,AI 解析效率会显著下降。我的实测是只做 schema 的引用率约为同时做的 60%,只做正文的约 40%。
新闻发布稿的成本不低,怎么选择性投入?
每个核心产品节点投一次。常见节点:产品发版(重大功能、版本号变化)、合作伙伴宣布(与知名公司合作)、年度报告发布、获奖(行业奖项、媒体榜单)、关键人事变动(高管入职/离职)。不需要每月发,1 个季度 1-2 篇高质量稿件比每月 1 篇凑数稿件效果好。预算紧张可以选低价 PR 渠道(如 EIN Presswire 单篇 200-500 美元),高预算可选 PR Newswire 或 Business Wire(单篇 1000-3000 美元)。
AI 引用的内容会不会被认为侵权?
取决于 AI 平台的引用方式。带链接的引用通常被视为"合理使用"——AI 给出原文链接,用户可以点击访问,原作者获得流量与曝光,与传统搜索引擎的 snippet 性质相同。无链接的提及与摘录在版权上有争议,2024 年 New York Times 起诉 OpenAI 案就是这一争议的代表。但目前实务上 AI 引用没有引发个人创作者大规模维权,大部分人接受这种"流量交换"。如果你坚持要保护内容,可以用 robots.txt 屏蔽特定 AI 爬虫,但代价是失去引用机会。
对比表格的 AI 引用率为什么这么高?
因为表格是 AI 直接复用最高效的格式。AI 在生成"X vs Y"类对比答案时,最理想的是直接复用一个现成的对比表格,省去自己生成对比逻辑。规范的<table>标签结构(<thead>、<tbody>、<tr>、<th>、<td>)让 AI 解析与重组成本最低。Markdown 渲染出的不规范表格(缺<thead>)解析准确率下降明显,建议在 Markdown 写作时显式用 HTML <table> 替代纯 markdown 表格语法。
实体优化做了多久能看到效果?
Wikidata 条目创建后 2-4 周开始有效(AI 重新爬取知识图谱并更新内部表示)。完整效果(AI 在引用你品牌时使用规范化的实体表示、提及准确性明显提高)通常需要 2-3 个月。如果你的品牌名有歧义或者被多个不相关实体共用,效果时间更长——需要先消歧义。建议优先在 Wikidata 创建条目+在自家官网的 schema 里用 sameAs 关联,这两步几乎可以即刻提升 AI 引用准确性。
2026 年下半年 AI 平台规则可能变,现在做的优化会不会浪费?
5 个核心动作不会浪费——内容质量、E-E-A-T、技术性能、实体优化、结构化数据。这 5 项对 2026 年所有 AI 平台都是正向,对未来 2-3 年内的算法变化也是正向。容易过时的是"具体的渠道与工具策略"——某个 PR 平台的 5x 增长红利可能 6 个月就消退、某个监控工具可能下架,这些应保持灵活调整。把投入分成 70% 在核心动作、30% 在渠道策略,整体 ROI 最稳。
权威参考资料
本文标题:《ChatGPT等AI平台引用率提升8招实战》
本文链接:https://zhangwenbao.com/2026-ai-seo-optimization-strategies.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0