CLAUDE.md记忆术:四级作用域、自动记忆与配置模板完全指南
本文目录
- CLAUDE.md到底是什么,凭什么能让AI记住你?
- CLAUDE.md和技能、自动记忆,三者怎么分工?
- 四级作用域:CLAUDE.md到底能放在哪几个地方?
- 多个CLAUDE.md会不会互相覆盖?加载顺序是怎样的?
- 自动记忆是什么?为什么它改变了游戏规则?
- 初始化、追加、引用:四种操作方式怎么用?
- 项目大了,CLAUDE.md越写越长怎么办?
- CLAUDE.md和AGENTS.md冲突吗?/compact后规则会丢吗?
- 保哥的实战模板:个人级和团队级各怎么配?
- 从今天起,怎么把CLAUDE.md养成团队资产?
- 哪些东西千万别写进CLAUDE.md?
- 常见问题解答
- CLAUDE.md和CLAUDE.local.md有什么区别?
- CLAUDE.md应该写多长?真有200行的硬限制吗?
- 自动记忆会不会泄露我的隐私或把脏数据塞进项目?
- 多个CLAUDE.md会互相覆盖吗?
- 为什么我写进CLAUDE.md的规则Claude有时不照做?
- /init会覆盖我已有的CLAUDE.md吗?
- 权威参考资料
摘要:CLAUDE.md是你写给Claude Code的一份常驻说明书,让它每开一个新会话都先读一遍你的项目背景、代码规范和踩过的坑。2026年的官方版本早已不是"三层配置"那么简单——作用域升到四级(组织策略、用户、项目、本地),多个文件是拼接进上下文而非互相覆盖,还多了一套Claude自己写笔记的"自动记忆"和按文件路径生效的
.claude/rules/。这篇把官方现状、四级加载顺序、自动记忆、模块化拆分和一套可直接抄的实操模板一次讲透,照着配,AI第一次就懂你的项目。
用Claude Code的人几乎都撞过同一堵墙:昨天才掰扯清楚的事,今天开新对话又得从头说一遍。这个项目用的是ESM不能写require()、提交信息要用中文、测试文件别塞进src……每次重复都是在交一笔看不见的"沟通税"。
解药就是项目根目录里那个不起眼的CLAUDE.md。它的定位很像新人入职手册:写一次,往后每次会话Claude都自动读。但网上流传的多数教程还停留在2025年的旧认知,把它讲成"三层配置、后面覆盖前面"。保哥按官方最新文档把这套机制重新核对了一遍,发现变化不小,下面逐条说清楚。
CLAUDE.md到底是什么,凭什么能让AI记住你?
剥开各种花哨说法,CLAUDE.md的本质就是一份普通的Markdown文本。你用纯文本把希望Claude长期记住的东西写进去,它在每次会话开始时读取,并把内容当成上下文的一部分。
这里有个被大量教程忽略、却极其关键的细节:官方明确指出,CLAUDE.md的内容是以一条用户消息的形式、在系统提示之后注入的,它属于"上下文"而非"强制配置"。换句话说,Claude会努力遵守,但不保证百分之百照办,尤其当指令含糊或自相矛盾时。如果你需要的是雷打不动的硬约束——比如"提交前必须跑lint""禁止碰某个目录"——正确做法是用生命周期钩子(Hooks)在固定时机强制执行,而不是指望一句CLAUDE.md里的话。这条认知差,决定了你写出来的配置是"建议"还是"铁律"。
那CLAUDE.md里该写什么?官方给的判断标准很朴素:凡是你会反复跟Claude解释的事,就写进去。具体触发时机有四个——
- Claude第二次犯了同一个错;
- 代码评审挑出了一个它本应知道的项目惯例;
- 你又一次在对话框里敲下上次也敲过的那句纠正;
- 一个新同事要上手这个项目,也得先听你讲这段背景。
反过来,如果某条内容是"只在改某一块代码时才用得上"的多步流程,它就不该塞进CLAUDE.md,而该做成技能(Skill)或路径作用域规则——后面会讲这个区别。
CLAUDE.md和技能、自动记忆,三者怎么分工?
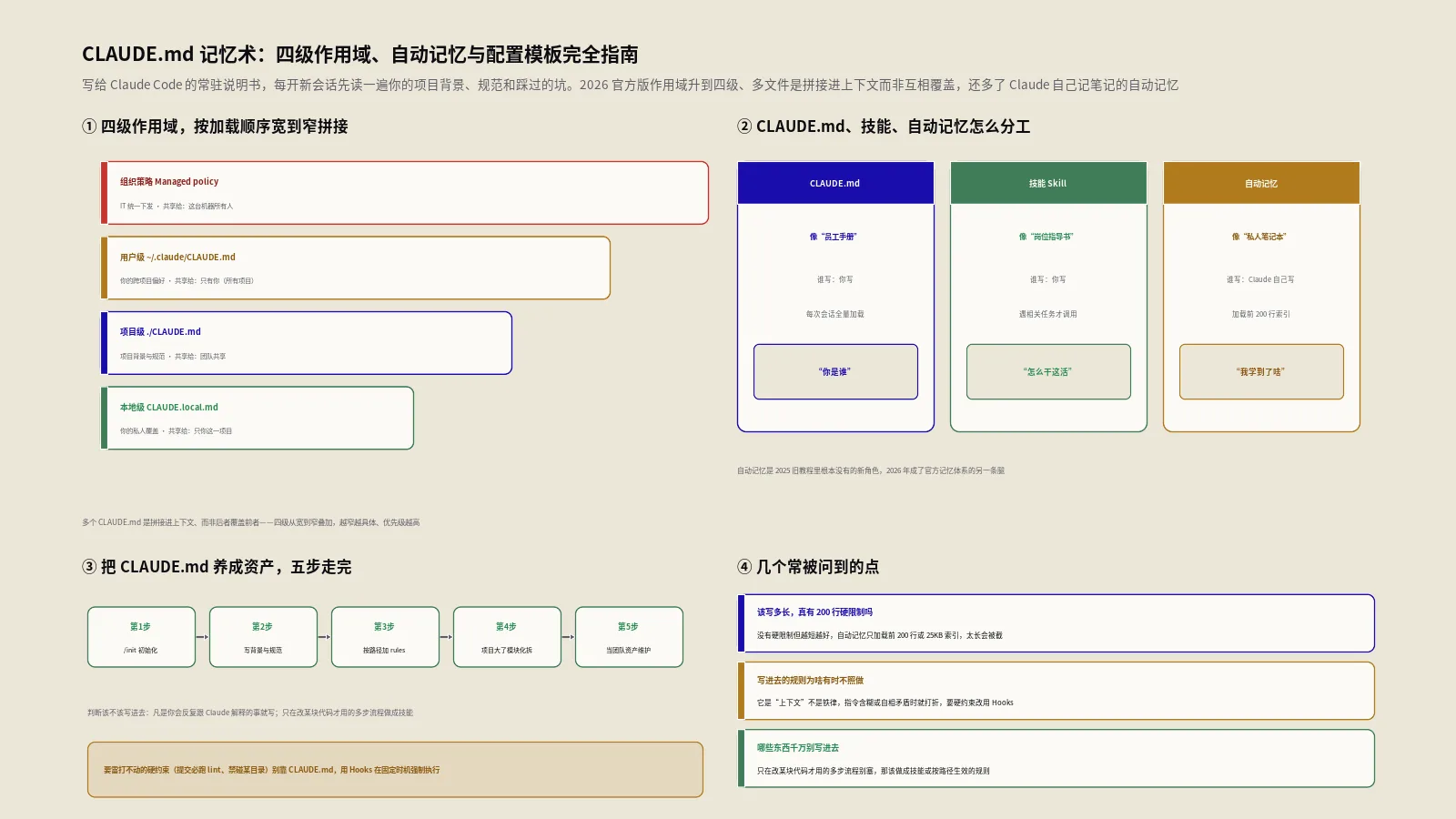
很多人把CLAUDE.md、技能、记忆混为一谈,其实它们各管一摊。最干脆的理解是:CLAUDE.md定义"你是谁",技能定义"怎么干这件活",自动记忆则是Claude自己攒下的"我学到了什么"。
| 维度 | CLAUDE.md | 技能(Skill) | 自动记忆(Auto memory) |
|---|---|---|---|
| 谁来写 | 你 | 你 | Claude自己 |
| 装什么 | 项目背景、规范、偏好 | 某类任务的执行流程 | 构建命令、调试心得、被你纠正过的偏好 |
| 何时生效 | 每次会话自动全量加载 | 遇到相关任务才调用 | 每次会话加载索引(前200行或25KB) |
| 类比 | 员工手册 | 岗位作业指导书 | 老员工的私人笔记本 |
这张表里,"自动记忆"是2025年那批教程里根本没有的新角色。它在2026年成了官方记忆体系的另一条腿,下面单独开一节细说,因为它真正改变了配置CLAUDE.md的方式。
四级作用域:CLAUDE.md到底能放在哪几个地方?
这是更新幅度最大的一块。旧教程普遍讲"三层:项目级、个人级、全局级"。Claude Code官方记忆文档里,作用域已经是四级,按加载顺序从最宽到最窄排列如下:
| 作用域 | 文件位置 | 用途 | 共享给谁 |
|---|---|---|---|
| 组织策略(Managed policy) | Linux/WSL:/etc/claude-code/CLAUDE.md;macOS:/Library/Application Support/ClaudeCode/CLAUDE.md;Windows:C:\Program Files\ClaudeCode\CLAUDE.md | 由IT统一下发的全公司规则 | 这台机器上的所有人 |
| 用户级 | ~/.claude/CLAUDE.md | 你个人的跨项目偏好 | 只有你(所有项目) |
| 项目级 | ./CLAUDE.md或./.claude/CLAUDE.md | 团队共享的项目规范 | 团队(随版本库走) |
| 本地级 | ./CLAUDE.local.md | 你在本项目的私人偏好 | 只有你(当前项目) |
这里有三个老教程几乎都写错或漏掉的点,逐个点名:
第一,最顶上多了"组织策略"这一级。它是给企业IT用MDM、组策略、Ansible统一推送的,普通开发者改不了也排除不掉——这正是它的设计目的:公司的安全合规底线必须无条件生效。个人玩具项目用不上,但在团队里它是最高优先级。
第二,项目级可以放在./.claude/CLAUDE.md,不止根目录的./CLAUDE.md。把它收进.claude目录能让项目根目录更干净,两个位置官方都认。
第三,也是最容易踩的——多个CLAUDE.md不是"后面覆盖前面",而是全部拼接。这点后面单开一节讲,因为它直接影响你怎么组织规则。
多个CLAUDE.md会不会互相覆盖?加载顺序是怎样的?
旧教程里那句"全局→项目→个人,后面覆盖前面"是个流传很广的误解。官方的真实机制是:Claude Code从当前工作目录开始沿目录树向上逐层查找,把沿途每一级目录里的CLAUDE.md和CLAUDE.local.md都找出来,然后全部拼接进上下文,谁也不覆盖谁。
拼接的先后是从文件系统根目录往工作目录方向排:越靠近你启动Claude那个目录的指令,越靠后被读到。在同一级目录里,CLAUDE.local.md排在CLAUDE.md之后,所以你的私人笔记是这一级最后被读的。举个例子,你在foo/bar/里启动,加载进上下文的顺序就是:foo/CLAUDE.md → foo/bar/CLAUDE.md → foo/bar/CLAUDE.local.md。
理解"拼接而非覆盖"为什么重要?因为它意味着你不能靠在子目录写一条同名规则去"推翻"父目录的规则——两条会同时进上下文。一旦它们打架,Claude可能随机挑一条执行。所以官方反复强调:定期检查各级CLAUDE.md和规则文件,把过时或冲突的指令清掉。在大型单体仓库里,如果上层夹带了别的团队的CLAUDE.md干扰你,用claudeMdExcludes设置按路径或通配符跳过它们。
还有个贴心的细节:子目录里的CLAUDE.md不会在启动时全量加载,而是等Claude真的去读那个子目录里的文件时才按需带入。这样大仓库里上百个CLAUDE.md不会一股脑挤爆上下文。
自动记忆是什么?为什么它改变了游戏规则?
这是2026年最值得补课的新机制,旧教程一个字都没提。自动记忆(Auto memory)让Claude在干活过程中自己记笔记——构建命令、调试时发现的坑、架构判断、你纠正过的代码风格,它觉得"以后还用得上"就主动存下来。需要Claude Code v2.1.59及以上,默认开启。
它存在哪?每个项目一个独立目录:~/.claude/projects/<项目>/memory/。<项目>这个路径是从git仓库推导出来的,所以同一仓库的所有worktree和子目录共用一份自动记忆。目录里有一个MEMORY.md作为索引,外加若干主题文件:
~/.claude/projects/<项目>/memory/
├── MEMORY.md # 简洁索引,每次会话都加载
├── debugging.md # 调试模式的详细笔记
├── api-conventions.md # API设计决策
└── ... # Claude按需创建的其他主题文件加载逻辑很克制:每次会话开始只把MEMORY.md的前200行或前25KB(哪个先到算哪个)读进上下文,超出部分不加载;主题文件平时不加载,等Claude需要时用文件工具按需读取。这套设计的高明之处在于——它把"记得越多、上下文越重"这个矛盾化解了:索引常驻、细节按需。
实操上你会在界面里看到"Writing memory""Recalled memory"的提示,那就是Claude在读写这个目录。它不是每次都存东西,而是自行判断哪些值得记。你随时可以用/memory命令打开这个文件夹审查、编辑甚至删除——全是纯Markdown,完全透明可控。想关掉它,/memory里有开关,或在项目设置里写"autoMemoryEnabled": false。
一个实在的判断是:CLAUDE.md管"你主动告诉它的规矩",自动记忆管"它从你身上学到的习惯",两者互补。你不必把所有东西都手写进CLAUDE.md了,很多偏好让它自己攒着就行——这是2026年配置思路最大的转变。
初始化、追加、引用:四种操作方式怎么用?
把一个CLAUDE.md从空白养到好用,官方给了几条顺手的路子。
用/init生成初稿。它会让Claude分析你的代码库,自动生成一份含构建命令、测试方式、项目惯例的起步版本。如果已有CLAUDE.md,/init不会覆盖,而是给改进建议。想要更细的交互式流程,可设环境变量CLAUDE_CODE_NEW_INIT=1,它会分阶段问你要不要顺带配技能和钩子,先用子代理探查代码库、补问缺口,最后给一份可审阅的方案再落盘。
用/memory查看与编辑。这个命令会列出当前会话加载的所有CLAUDE.md、CLAUDE.local.md和规则文件,能开关自动记忆,点任意文件直接在编辑器里打开。想确认"我这条规则到底有没有被加载",跑一下/memory最直接——列表里没有,就说明Claude根本看不见它。
让Claude帮你记。你直接说"记住,这个项目一律用pnpm不用npm",Claude会把它存进自动记忆;如果你明确说"把这条加到CLAUDE.md里",它就写进CLAUDE.md。两条路径分得很清楚。
用@语法引用其他文件。CLAUDE.md里可以用@路径把别的文件拉进来一起加载,相对路径以引用它的文件为基准、不是工作目录。被引用的文件还能再引用别的,最多嵌套四层。比如:
See @README for project overview and @package.json for available npm commands.
# Additional Instructions
- git workflow @docs/git-instructions.md要注意:@引用只帮你做组织拆分,并不省上下文——被引用的文件照样在启动时全量加载进来。真正想"按需加载、省上下文",得用下一节的路径作用域规则。
项目大了,CLAUDE.md越写越长怎么办?
先纠正一个流传很广的旧数字。老教程说"超过500行再拆分",官方的真实建议是单个CLAUDE.md控制在200行以内——文件越长,吃的上下文越多,Claude的遵守度反而越差。这是个很反直觉但有数据支撑的结论:不是写得越细越好,而是写得越准越短越好。
当指令确实多起来,官方给的正解是.claude/rules/目录,而不是把CLAUDE.md撑大。把规则按主题拆成多个文件:
your-project/
├── .claude/
│ ├── CLAUDE.md # 主项目说明
│ └── rules/
│ ├── code-style.md # 代码风格
│ ├── testing.md # 测试约定
│ └── security.md # 安全要求规则文件最妙的能力是按文件路径作用域生效。在文件头部用YAML声明paths,这条规则就只在Claude碰到匹配的文件时才进上下文:
---
paths:
- "src/api/**/*.ts"
---
# API开发规则
- 所有API端点必须做输入校验
- 用统一的错误响应格式
- 补全OpenAPI文档注释没写paths的规则则无条件常驻,优先级和.claude/CLAUDE.md一样。通配符支持**/*.ts、src/**/*、src/**/*.{ts,tsx}这类写法。这意味着你可以把前端规范、后端规范、测试规范分别绑到各自的目录,前端任务里不会被后端的规矩占着上下文——这是单体仓库和大项目控制上下文体积的关键招式。
规则目录还支持软链接,能把一份公司公共规则链接进多个项目;~/.claude/rules/下的用户级规则则对你机器上所有项目生效,优先级低于项目规则。
CLAUDE.md和AGENTS.md冲突吗?/compact后规则会丢吗?
这两个是实战里高频踩的坑,旧教程基本没覆盖。
关于AGENTS.md:Claude Code只读CLAUDE.md,不读AGENTS.md。如果你的仓库已经为别的编程工具维护了AGENTS.md,最干净的办法是建一个CLAUDE.md用@AGENTS.md把它引进来,两边共用一份指令不重复,再在下面追加Claude专属的内容:
@AGENTS.md
## Claude Code
改动 src/billing/ 下的代码时走计划模式。跑/init时如果仓库里已有AGENTS.md,它会自动读取并把相关部分并进生成的CLAUDE.md,连.cursorrules、.windsurfrules也会一并参考。
关于/compact压缩后规则丢失:很多人压缩对话后发现Claude"忘了"某条规矩。真相是——项目根目录的CLAUDE.md能扛过压缩,压缩后Claude会从磁盘重新读一遍再注入;但子目录里的嵌套CLAUDE.md不会自动重注入,要等下次读那个子目录的文件时才重新加载。所以如果某条指令压缩后消失了,它要么只是你在对话里随口说的(没写进文件),要么躺在还没重新加载的嵌套CLAUDE.md里。结论很明确:凡是希望长期生效的,一律写进文件,别只在对话里说。
还有个省上下文的小技巧:CLAUDE.md里的块级HTML注释<!-- 维护者备注 -->在注入前会被剥掉,不占token。你可以用它给人类维护者留话,而不浪费Claude的上下文(代码块内的注释会保留)。
保哥的实战模板:个人级和团队级各怎么配?
讲了一堆机制,落到地上就是模板。保哥在自己带的独立站和SEO工具项目里长期用下面这两套,给大家直接抄。
个人级(放~/.claude/CLAUDE.md,跨所有项目生效),核心是说清"我是谁、我的口味":
# 关于我
我是一名独立站开发者,长期做Shopify和WordPress二开。
## 编码偏好
- 代码注释用中文
- Git提交信息用中文,格式:type: 描述
- 变量命名要有意义,不用a、b、temp这类
- 不写多余注释,代码本身要可读
## 工作习惯
- 改完代码先跑一遍lint
- 提交前确认没有TypeScript报错
- 一次别改太多文件,小步提交
## 我不喜欢的
- 过度封装
- 没必要的设计模式
- 超过50行的函数团队级(放项目CLAUDE.md,提交进Git),核心是说清"这个项目长什么样、规矩是什么":
# 项目名称
一句话描述这个项目。
## 技术栈
- 框架:Next.js(App Router)
- 语言:TypeScript(strict模式)
- 样式:Tailwind CSS
- 数据库:PostgreSQL + Prisma
- 测试:Vitest
## 命名规范
- 文件名:kebab-case,如user-profile.tsx
- 组件名:PascalCase,如UserProfile
- 函数变量:camelCase
- 常量:UPPER_SNAKE_CASE
## 常用命令
- pnpm dev 启动开发
- pnpm build 生产构建
- pnpm test 跑测试
- pnpm lint 代码检查
## 注意事项
- 所有API请求必须处理loading和error状态
- 敏感信息放.env.local,绝不提交到Git
- 新功能必须配单元测试这两套模板刻意都压在百行以内,符合"短而准"的原则。团队级里那些"个人口味"的东西——比如你爱用什么快捷键——别往里塞,那是个人级和自动记忆的活。两边各司其职,团队的CLAUDE.md才不会因为掺了私货而需要频繁合并冲突。
顺带一提,做SEO和内容工程的同行可以把站点的URL规范、结构化数据要求、内链策略这类"项目铁律"写进团队级CLAUDE.md。不少做内容工程的团队就把"标题不超过多少字、描述必须自然可读不堆关键词、内链用绝对地址"这类硬规则固化进去,AI代笔时一次就对,省掉大量回改——这是把CLAUDE.md当成内容生产SOP的一种用法。
从今天起,怎么把CLAUDE.md养成团队资产?
把前面的机制串成一条可执行的路线,保哥建议这么走:
- 起步:在项目根目录跑
/init生成初稿,删掉它瞎猜的、补上它猜不到的。 - 日常:每当你第二次敲同一句纠正,就停下来把它写进CLAUDE.md或交给自动记忆;代码评审挑出的项目惯例,顺手补进去。
- 控量:CLAUDE.md逼近200行就该拆——把按目录/文件类型生效的规则挪进
.claude/rules/用paths作用域,保持主文件精悍。 - 协作:团队级
CLAUDE.md提交进Git形成共识,私人偏好放CLAUDE.local.md并加进.gitignore,新人入职第一件事就是读它。 - 硬约束:凡是"必须在某时刻强制执行"的(提交前跑测试、禁改某目录),别指望CLAUDE.md,写成Hooks。
CLAUDE.md的终极价值,是把"只装在你脑子里的项目知识"固化成全队、甚至AI都能复用的资产。AI本身没有记忆,但你可以亲手给它装一个——而且2026年的它,已经聪明到能自己往这个记忆里添东西了。
哪些东西千万别写进CLAUDE.md?
讲完该写什么,更值钱的是说清不该写什么——这恰恰是绝大多数教程不讲的。CLAUDE.md不是越满越好,每多一行都在跟你的对话抢上下文。下面这几类内容,写进去往往是负收益。
第一,能被代码自己说清的东西别重复写。比如"我们用React""项目用TypeScript"——Claude读一眼package.json就知道了,写进CLAUDE.md只是浪费token。真正该写的是代码里看不出来的隐性约定,比如"调用支付接口前必须先查用户状态,否则会500"这种血泪教训。
第二,只在局部用得上的多步流程别塞主文件。"发布一个新版本要跑哪七步""数据库迁移的完整SOP"这类长流程,写进CLAUDE.md会让它常驻每一次会话,哪怕你这次只是改个CSS。正解是做成技能,遇到相关任务才加载;或者用.claude/rules/的paths把它绑到对应目录。
第三,含糊的形容词别写。"代码要优雅""注释要清晰""性能要好"——这类话Claude无从验证,等于没说。把它翻译成可检查的具体规则:"单个函数不超过50行""每个导出函数都要有JSDoc""列表渲染必须带key"。官方反复强调的"具体性"原则,本质就是把价值观翻译成可执行的判据。
第四,互相打架的规则别共存。因为多个CLAUDE.md是拼接而非覆盖,子目录里写一条和父目录矛盾的规则,不会"覆盖"掉父规则,只会让两条同时进上下文、逼Claude随机二选一。每次新增规则前,先扫一眼有没有和旧规则冲突的,比新增本身更重要。
第五,硬约束别用CLAUDE.md表达。"绝对不能删生产数据库""提交前一定要跑测试"——这类不容商量的红线写进CLAUDE.md只是"建议",Claude仍可能在某次判断里绕过。真要拦住,得用Hooks在PreToolUse等时机以脚本强制执行。把红线交给钩子、把惯例交给CLAUDE.md,这条分工想清楚,你的AI协作才算上了保险。
记住一句话:CLAUDE.md的质量不看长度看密度。每一行都该是"Claude不知道、且每次都用得上"的事实。删到不能再删,才是一份好的记忆文件。
常见问题解答
CLAUDE.md和CLAUDE.local.md有什么区别?
两者都放在项目里、加载方式完全一样,区别只在共享范围。CLAUDE.md提交进Git、团队共享,写项目级规范;CLAUDE.local.md加进.gitignore不提交,写你个人在本项目的私货(如本地沙箱URL、偏好的测试数据)。在同一级目录,CLAUDE.local.md排在CLAUDE.md之后被读取。
CLAUDE.md应该写多长?真有200行的硬限制吗?
200行不是硬限制,是官方建议的上限目标。文件越长吃的上下文越多,Claude遵守度反而下降。超过这个量级时,正确做法不是删内容,而是把按路径生效的规则拆进.claude/rules/,让它们只在相关文件被操作时加载。注意@引用只帮你做组织、不省上下文,被引用文件照样全量加载。
自动记忆会不会泄露我的隐私或把脏数据塞进项目?
自动记忆是机器本地的,存在~/.claude/projects/<项目>/memory/,不跨机器、不跨云环境同步,也不会进你的Git仓库。它存的全是纯Markdown,你随时能用/memory打开审查、编辑、删除。不放心可以直接关:/memory里有开关,或在设置里写"autoMemoryEnabled": false。
多个CLAUDE.md会互相覆盖吗?
不会。所有被发现的CLAUDE.md和CLAUDE.local.md都拼接进上下文,从文件系统根目录往工作目录方向排序,谁也不覆盖谁。正因为如此,子目录写同名规则推翻不了父目录的规则——两条会同时存在,冲突时Claude可能随机挑一条,所以要定期清理矛盾指令。
为什么我写进CLAUDE.md的规则Claude有时不照做?
因为CLAUDE.md是以用户消息形式在系统提示之后注入的"上下文",不是强制配置,不保证严格遵守。先用/memory确认它确实被加载了;再把指令写得更具体("用2个空格缩进"胜过"格式化好看点");最后检查有没有跨文件的冲突指令。如果某条必须在固定时机强制执行,改用Hooks,那才是客户端层面的硬约束。
/init会覆盖我已有的CLAUDE.md吗?
不会。/init检测到已有CLAUDE.md时,给的是改进建议而非覆盖。它会分析代码库、补全构建命令和项目惯例。设CLAUDE_CODE_NEW_INIT=1可启用更细的交互式多阶段流程,连技能和钩子都能顺带配,并在落盘前给你一份可审阅的方案。
权威参考资料
本文标题:《CLAUDE.md记忆术:四级作用域、自动记忆与配置模板完全指南》
本文链接:https://zhangwenbao.com/claudemd-memory-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0