Claude Code Skill怎么写才好用?一套经得起用的设计模式与避坑指南
本文目录
- Skill到底是什么,凭什么比斜杠命令更聪明?
- 一个SKILL.md最少需要写什么?
- name必须是动名词、description要压到20字以内吗?
- frontmatter里那些进阶字段都能干什么?
- 命令名到底由什么决定,自定义命令还存在吗?
- Skill放在哪一级,决定了谁能用它?
- 怎么让一个Skill既精简又强大?
- 有没有让Skill真正动起来的进阶玩法?
- 把这些模式串成一套可复用的设计原则,长什么样?
- 写Skill最容易踩哪些坑?
- 常见问题解答
- Skill的name字段必须是动名词形式吗?
- description是不是越短越好,最好20字以内?
- 自定义命令和Skill是两个不同的东西吗?
- 怎么让一个内容很多的Skill不浪费token?
- context: fork是干嘛用的?
- 什么样的任务才值得做成Skill?
- 权威参考资料
摘要:很多Skill教程会斩钉截铁地告诉你:name字段必填、还得是动词加ing的动名词形式,description要压到20字以内——这两条现在都不准了。按官方现行规范,name是可选的、不写就用目录名,你敲的命令也来自目录名而非name;description不是越短越好,它和触发说明合起来有1536字符的预算,关键是把最该命中的使用场景写在最前面。更要紧的是,真正决定一个Skill好不好用的,根本不止这俩字段:disable-model-invocation、allowed-tools、context:fork、附属文件、动态上下文注入这一整套机制,才是把Skill从“能跑”写到“好用”的关键。这篇按官方现行规范把frontmatter字段、四级作用域、渐进式披露、子代理执行讲透,给你一套真正经得起用的Skill设计模式。
Skill到底是什么,凭什么比斜杠命令更聪明?
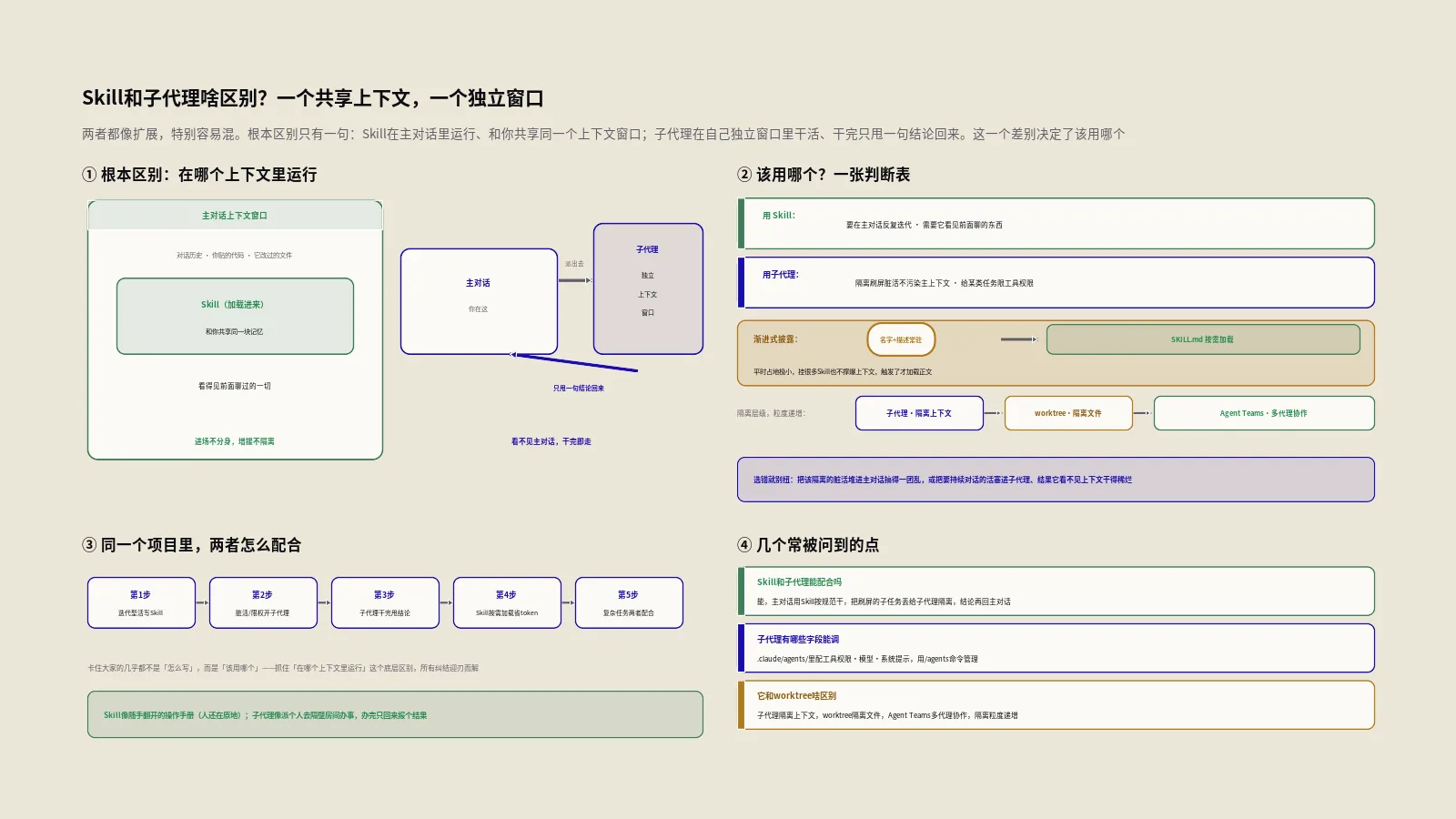
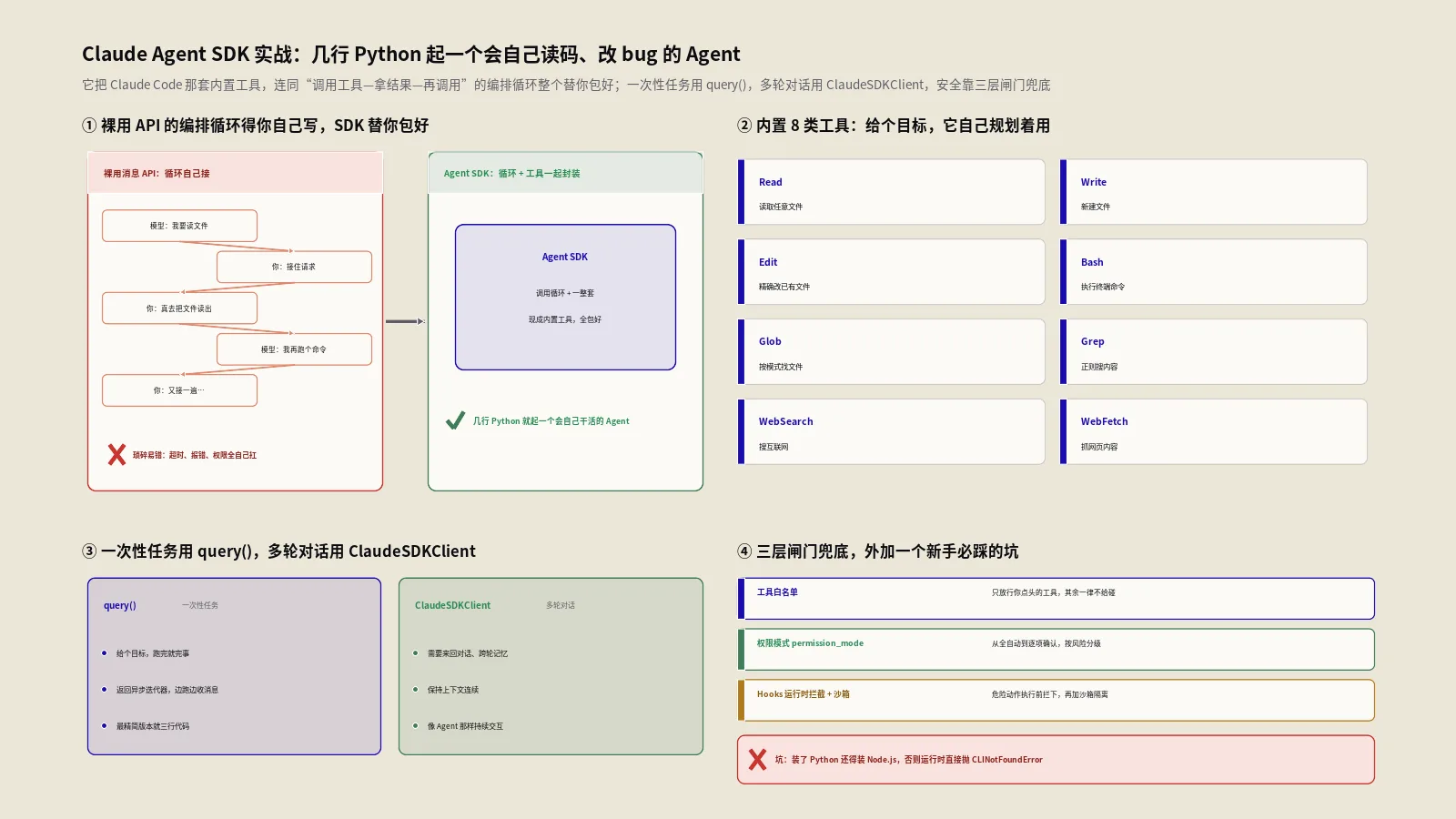
先把定位说准。Skill是把一套专业知识、工作流程或最佳实践打包成的“能力单元”——你写一个SKILL.md文件,Claude Code就把这项能力收进工具箱。它和你手动敲斜杠命令最大的不同在于:Claude能根据对话上下文自动判断什么时候该用它,就像一个有经验的同事,看你在干什么、主动凑过来搭把手,而不必你每次点名。
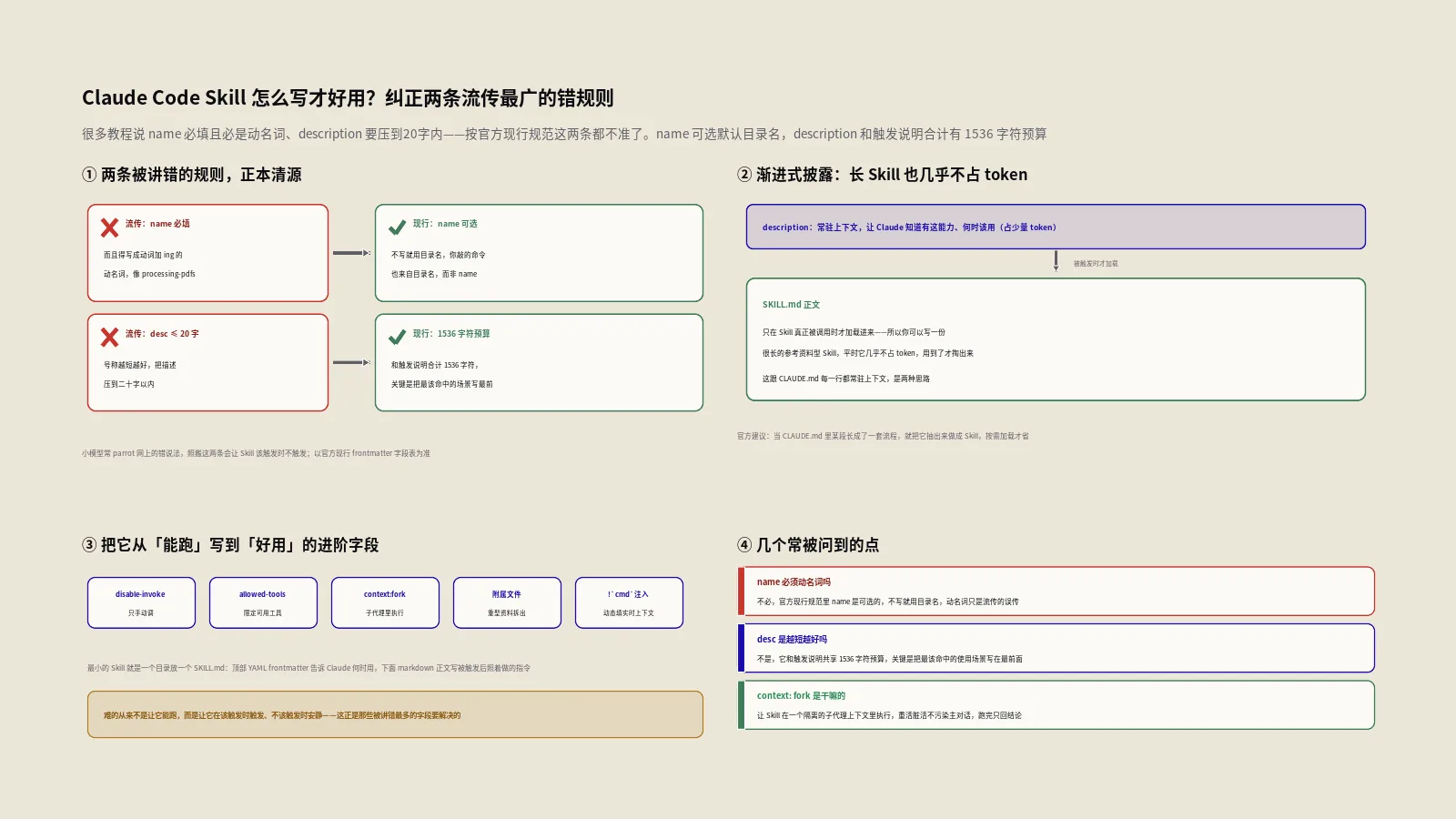
但“更聪明”只是表象,底下真正值钱的是一套省token的机制,官方叫渐进式披露。Claude Code官方的Skills文档把这个机制讲得很清楚:一个Skill的description会常驻在上下文里,好让Claude知道“有这么个能力、什么时候该用”,但它的正文只有在真正被调用时才加载进来。这意味着你可以写一份很长的参考资料型Skill,平时它几乎不占token,用到了才掏出来。这跟CLAUDE.md把每一行都常驻上下文是两种思路——也正因如此,官方建议当CLAUDE.md里某段长成了一套流程,就该把它抽出来做成Skill。这两者怎么分工,保哥在CLAUDE.md和README该写什么那篇里专门掰扯过,这里不重复,你只要记住:Skill是“按需加载的能力”,这是它一切设计的出发点。
理解了这条,你就明白为什么Skill的写法处处透着“精打细算”:description要让Claude准确判断何时触发,正文要在被加载时直奔主题不啰嗦,重型参考资料要拆到附属文件里别一股脑塞进来。下面这些字段和模式,本质上都是围绕“怎么让这项能力在对的时机、用最省的代价、被准确地用起来”展开的。
一个SKILL.md最少需要写什么?
门槛比你想的低。一个Skill就是一个目录,里面放一个SKILL.md当入口。这个文件分两部分:顶上用---夹起来的YAML frontmatter,告诉Claude什么时候用这个Skill;下面是markdown正文,写Claude被触发后该照着做的指令。最小到什么程度?其实只要一段描述加几句指令就能跑:
---
description: 总结未提交的改动并标出风险点。当用户问改了什么、想要提交信息、或要审查diff时使用。
---
## 当前改动
!`git diff HEAD`
## 指令
把上面的改动用两三句话总结,再列出你注意到的风险,
比如缺少错误处理、写死的值、需要更新的测试。若diff为空,就说没有未提交的改动。
把它存成~/.claude/skills/summarize-changes/SKILL.md,重启Claude Code,你问“我改了什么”,它就会自动触发;或者你直接敲/summarize-changes手动调。注意里头那行!`git diff HEAD`——它不是给Claude看的指令,而是Claude Code在把Skill内容送进去之前就先跑掉、把真实的diff结果填进来,这是个很有用的进阶玩法,后面专门讲。眼下你只要看清一件事:跑起来一个Skill,真的就这么点东西。难的从来不是让它能跑,而是让它在该触发时触发、不该触发时安静——这就要回到那些被讲错最多的字段上了。
name必须是动名词、description要压到20字以内吗?
这是流传最广、也错得最离谱的两条规则,必须正本清源。不少教程言之凿凿:name字段必填,而且得写成动词加ing的动名词形式,像processing-pdfs;description要言简意赅,最好20字以内。按官方现行规范,这两条都不成立。
先说name。在官方的frontmatter参考里,name是可选字段,不是必填;不写它,就默认用Skill所在的目录名。更关键的是,你敲进去触发Skill的那个命令名,来自目录名,而不是frontmatter里的name——name只是显示在Skill列表里的一个标签。所以纠结“name要不要动名词、要不要动词开头”基本是白费劲,真正决定命令叫什么的是你给目录起的名字。把目录命名得清晰、贴合功能,比抠name字段的词性有用得多。
再说description。它不该被无脑压短,恰恰相反,它是Claude判断“何时该用这个Skill”的唯一依据,写得太短反而把帮助命中的关键词给砍没了。官方的规则是:description和可选的when_to_use合起来,在Skill列表里被截断的上限是1536字符——这是个相当宽裕的预算,远不是“20字以内”。真正的要诀不是短,而是把最该命中的使用场景写在最前面,因为列表空间紧张时是从后往尾巴上截。一句话总结:description要写得具体、带上用户会自然说出口的关键词、把核心用例顶到最前,而不是一味求短。这一条写好了,Skill触发的准头能上一个台阶;写砸了,它要么该出手时哑火,要么动不动乱触发。
frontmatter里那些进阶字段都能干什么?
只知道name和description,你连Skill的一半都没用上。官方frontmatter里还有一长串字段,每个都对应一种很实际的控制需求。挑最常用的几个讲清楚:
| 字段 | 作用 |
|---|---|
description | Claude判断何时触发的依据,写具体、关键词靠前(最该写好的一个) |
when_to_use | 补充触发场景和示例请求,接在description后面一起算进1536字符预算 |
disable-model-invocation | 设为true则只有你能手动调、Claude不会自动触发,给有副作用的操作用 |
user-invocable | 设为false则只有Claude能调、不在斜杠菜单露面,给纯背景知识用 |
allowed-tools | Skill激活时这些工具免确认直接用,比如放行特定git命令 |
context | 设为fork则在隔离的子代理上下文里跑这个Skill |
agent | 配合context:fork,指定用哪种子代理来执行 |
argument-hint | 自动补全时提示该传什么参数 |
这里头藏着两个特别实用的设计点。一个是disable-model-invocation: true——凡是带副作用、你想牢牢攥住触发时机的操作,比如部署、提交、给客户发消息,都该加上它,免得Claude看你代码顺眼就自作主张跑了部署。另一个是user-invocable: false,反过来用:某些纯背景知识型的Skill,比如“某个老系统是怎么运作的”,对人来说/某某根本不是个有意义的动作,但Claude在相关时该知道——这种就藏起来只让Claude用。把这两个字段配合起来,你就能精细地控制每个Skill到底是“你的命令”“Claude的本能”还是“两者都行”。这种颗粒度,正是Skill比一根光秃秃的斜杠命令强的地方。
表里没展开的还有几个值得一提的字段,它们让Skill的控制粒度更细。model能指定这个Skill激活时用哪个模型,比如一个简单的格式化Skill就让它走便宜的小模型、不必动用最贵的那档,省钱;effort则单独调这个Skill的思考力度。paths用glob模式限定Skill只在你处理匹配的文件时才自动加载,比如一个只管前端规范的Skill,设上paths: "src/web/**",你在改后端时它就不会来插嘴,触发更精准。shell能指定动态注入命令用bash还是PowerShell,对Windows用户有用。这些字段平时未必都用得上,但知道它们存在,遇到“想让某个Skill只在特定情况下、用特定代价生效”的需求时,你就知道该去拧哪个旋钮,而不是硬在description里绕。
命令名到底由什么决定,自定义命令还存在吗?
顺着name的话题,把命令名这件事彻底讲清,因为它牵出另一个大变化。前面说了,放在~/.claude/skills/或.claude/skills/下的Skill,命令名来自目录名:.claude/skills/deploy-staging/SKILL.md对应的命令就是/deploy-staging。这个规则简单可靠,记住“目录名即命令名”基本不会错。
那以前在.claude/commands/下写的自定义命令呢?官方已经把自定义命令并入了Skills——一个.claude/commands/deploy.md和一个.claude/skills/deploy/SKILL.md,都会生成/deploy命令,行为一致。你原来.claude/commands/里的文件照样能用,不用迁移;但Skill多了几样东西:可以带附属文件、能用frontmatter控制由谁触发、还能让Claude在相关时自动加载。所以新写的话,优先用Skill的目录形式,能力更全。这条变化很多老教程没跟上,还在把“自定义命令”和“Skill”当两个东西讲,其实它们早就合流了。
Skill放在哪一级,决定了谁能用它?
源文里多半只提到了个人级和项目级两种,其实官方现在是四级作用域,放哪儿决定了谁能用、能用在哪:
| 层级 | 路径 | 作用范围 |
|---|---|---|
| 企业级 | 由托管设置部署 | 组织内所有用户 |
| 个人级 | ~/.claude/skills/ | 你的所有项目 |
| 项目级 | .claude/skills/ | 仅当前项目,可提交共享 |
| 插件级 | 插件目录下的skills/ | 启用该插件处 |
分层的逻辑跟CLAUDE.md那套作用域一脉相承:你个人不管在哪个项目都想要的Skill,放个人级;只跟某个项目相关、且想让队友也能用的,放项目级并提交进仓库;想打包分发给一群人的,做成插件。同名时企业级压个人级、个人级压项目级,插件级则用插件名:Skill名的命名空间,不会跟其他层冲突。一个实用习惯是:先在个人级把一个Skill调顺手,确认好用了,再决定要不要下沉到项目级共享给团队——别一上来就往项目仓库里塞半成品Skill,污染队友的环境。
怎么让一个Skill既精简又强大?
这是Skill设计里最考验功力的平衡。Skill被调用后,它的正文会作为一条消息进入对话、并在整个会话里一直待着,所以正文的每一行都是会反复消耗的token,写臃肿了就是持续烧钱、还稀释注意力。但你又常常需要给某个能力配上大段的参考资料。怎么两头兼顾?答案是附属文件。
一个Skill目录里,SKILL.md是必需的入口,但你可以再放别的文件:详细的API参考、示例集、能执行的脚本,让SKILL.md只保留精炼的概览和导航,把重料拆到单独文件里,用到了Claude才去读。官方建议SKILL.md正文控制在500行以内,超了就该往附属文件搬。目录大致长这样:
my-skill/
├── SKILL.md 必需,概览与导航
├── reference.md 详细参考,用到才加载
├── examples.md 示例集,用到才加载
└── scripts/
└── helper.py 脚本,被执行而非读进上下文
关键动作是:在SKILL.md里用一句话点明每个附属文件装了什么、什么时候该看,比如“完整API细节见reference.md”。这样Claude心里有数,需要时才按图索骥去加载,平时这些重料一个token都不占。这正是渐进式披露落到实处的样子——把“常驻的导航”和“按需的细节”分开,是Skill不发胖的核心一招。配合前面说的“正文只说做什么、不解释为什么”,你的Skill就能既轻又能打。脚本类附属文件还有个额外好处:它是被Claude执行的,不是读进上下文的,所以你可以塞进任意复杂的逻辑(生成可视化、跑校验、批处理),由脚本干重活、Claude只管编排。
有没有让Skill真正动起来的进阶玩法?
到这儿你的Skill已经会精打细算了,再上一个台阶,让它能接入实时数据、甚至开出独立的工作空间。两个官方机制值得专门学。
第一个是动态上下文注入,就是开头见过的!`命令`语法。它的作用是:在Skill正文被送给Claude之前,先把这些命令跑掉,用输出替换掉占位符。于是Claude拿到的不是一句“去看看diff”,而是已经填好的真实diff内容。这招用来给Skill喂实时数据特别顺,比如总结PR时先把!`gh pr diff`的结果注进来。要注意这是预处理、不是让Claude去执行,它只看到最终填好的结果;而且!要出现在行首或紧跟空白才生效。
第二个更重——用context: fork让Skill在一个隔离的子代理里跑。加上这个字段,Skill的正文就变成驱动一个子代理的任务提示,它不带你当前的对话历史、自己开一片干净的上下文去干活,干完把结果汇报回来。配合agent字段还能指定用哪种子代理,比如用只读、专为代码探索优化的Explore代理去跑一个研究型Skill:
---
name: deep-research
description: 彻底研究某个主题。当需要在代码库里深入排查、跨多文件梳理时使用。
context: fork
agent: Explore
---
彻底研究 $ARGUMENTS:
1. 用Glob和Grep找到相关文件
2. 读懂并分析代码
3. 给出带具体文件引用的结论
这段里还出现了$ARGUMENTS——它是参数占位符,你敲/deep-research支付回调逻辑,这串就被替换进去。需要按位置取参时还能用$0、$1这种简写。context: fork的价值在于把重型、发散的任务隔离出去跑,不污染你主对话的上下文,这跟MCP、子代理这些机制其实是一套组合拳,保哥在三大扩展机制怎么选里讲过它们各管一段,搭起来用威力才出得来。Agent Skills开放标准本身也是跨工具通用的,Claude Code在它基础上加了触发控制、子代理执行这些扩展,所以你学到的这套设计模式,迁移性也不差。
把这些模式串成一套可复用的设计原则,长什么样?
字段和机制讲了一圈,最后把它们收拢成几条能直接照着用的设计原则,省得你下次写Skill还得从头琢磨。第一条,description优先:它是触发的命门,永远先把它写具体、把核心用例顶到最前,宁可在它身上多花十分钟,也别让一个好Skill因为描述模糊而总不触发。第二条,正文越精炼越好:只写“做什么”的指令,不写“为什么”的解释,重料一律拆去附属文件,把SKILL.md当导航而非仓库。第三条,按副作用决定触发权:纯查询、纯生成的安全操作放手让Claude自动触发,带部署、提交、对外发送这类副作用的,一律加disable-model-invocation攥在自己手里。第四条,按作用域分层:个人习惯放个人级,团队约定放项目级提交共享,这套分层思路和CLAUDE.md的四级作用域是一以贯之的。
拿个真实场景把这套原则走一遍。保哥带的一个做宠物用品独立站的团队,每周要给十几个核心竞品做一轮“上新与改价”巡检,过去是人工一个个翻、整理成表,又慢又容易漏。后来把它做成了一个Skill:description写得很具体——“巡检竞品上新和价格变动并汇总成表,当用户要做竞品周报、对比竞品价格时使用”,关键词全带上,触发又准又不误伤;正文只留五步精炼指令,详细的竞品清单和字段口径拆进了同目录的reference.md,平时不占token;因为这活要跑一堆抓取、属于重型发散任务,给它加了context:fork扔到子代理里跑,不污染主对话;又因为它只查不改、没有副作用,就放开让Claude在相关时自动触发。这么一套配置下来,运营同事只要说一句“出本周竞品周报”,成品表就自己躺出来了。你看,前面那些零散的字段,落到一个真实需求上,立刻就拼成了一个顺手的工具——这就是设计模式的意义:不是背字段,是知道在什么场景该拧哪个旋钮。
写Skill最容易踩哪些坑?
把高频翻车点收个尾,照着自查能少走很多弯路。
第一坑,目录结构错了Skill直接失效。SKILL.md必须放在一个目录里,比如.claude/skills/my-skill/SKILL.md,不能图省事写成.claude/skills/my-skill.md;文件名也得是大写的SKILL.md,大小写敏感。这个错最隐蔽,因为不报错,就是单纯不触发,对着一个“怎么调都没反应”的Skill查半天,根子常在路径上。
第二坑,触发不准。该触发时哑火,多半是description没写好——没带上用户会自然说出口的关键词,Claude匹配不上。回去把description写具体、把核心用例顶到最前。反过来,乱触发、该安静时插嘴,是description写得太泛,把它收窄,或者干脆加disable-model-invocation: true改成只手动调。第三坑,正文写太长。前面反复说过,正文常驻上下文、每行都烧token,长流程和大参考资料该拆去附属文件,SKILL.md只留精炼指令。最后一坑是过度工程化——不是每件小事都值得做成Skill,一句话能交代清楚的事硬包成Skill,纯属给自己添维护负担。判断标准很简单:你是不是反复在把同一套指令、清单或多步流程贴进对话?是,才值得固化成Skill;偶尔用一次的,随手说就好。把这几坑记牢,你写出来的Skill就既好触发、又好维护了。
常见问题解答
Skill的name字段必须是动名词形式吗?
不必,而且name根本不是必填。按官方现行规范,name是可选字段,不写就默认用Skill所在的目录名,而你敲进去触发Skill的命令名也来自目录名、不是frontmatter里的name。所以纠结name要不要动词加ing基本没意义,把目录名起得清晰贴合功能才是正经事。那条动名词规则是过时说法。
description是不是越短越好,最好20字以内?
恰恰相反。description是Claude判断何时触发的唯一依据,太短会把帮助命中的关键词砍没。官方规则是description和when_to_use合起来上限1536字符,相当宽裕。要诀不是短,而是写具体、带上用户会自然说出口的关键词、把最该命中的使用场景顶到最前面,因为空间紧张时从尾部截断。
自定义命令和Skill是两个不同的东西吗?
已经合流了。官方把自定义命令并入了Skills,一个.claude/commands/deploy.md和一个.claude/skills/deploy/SKILL.md都会生成/deploy命令、行为一致。你原来commands目录里的文件照样能用不必迁移,但Skill多了附属文件、触发控制、自动加载这些能力。新写的话优先用Skill的目录形式。很多老教程还把两者当两回事讲,其实早就是一套了。
怎么让一个内容很多的Skill不浪费token?
用附属文件做渐进式披露。SKILL.md只保留精炼的概览和导航,把详细API参考、示例集、脚本拆到同目录的单独文件里,并在SKILL.md里点明每个文件装了什么、何时该看,Claude用到才加载,平时不占token。官方建议SKILL.md正文控制在500行内。正文本身也要只说做什么、不解释为什么,因为它被调用后一直常驻上下文。
context: fork是干嘛用的?
它让Skill在一个隔离的子代理上下文里跑:Skill正文变成驱动子代理的任务提示,子代理不带你的对话历史、自己开一片干净上下文去执行,干完汇报结果。配合agent字段还能指定用哪种子代理,比如用只读的Explore代理跑研究型任务。价值在于把重型、发散的任务隔离出去,不污染你主对话的上下文。适合研究、批量分析这类活。
什么样的任务才值得做成Skill?
判断标准是看你是不是反复在把同一套指令、清单或多步流程贴进对话。是,就值得固化成Skill,省得每次重打;偶尔用一次、一句话能交代清的事,随手说就好,硬包成Skill反而添维护负担。另一个信号来自CLAUDE.md:当里面某段从一条事实长成了一套流程,就该把它抽出来做成Skill,让它按需加载而非常驻。
本文标题:《Claude Code Skill怎么写才好用?一套经得起用的设计模式与避坑指南》
本文链接:https://zhangwenbao.com/claude-code-skill-patterns.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0