Markdown转换器怎么用?HTML与Markdown双向转换全拆解
本文目录
- Markdown转换器到底转什么?双向是哪两个方向?
- 它是用正则一行行解析的吗?
- HTML转Markdown,靠的是什么库?
- Markdown转HTML,又靠什么?
- 它支持哪些标准的Markdown语法?
- 表格能转吗?GFM的表格是怎么处理的?
- 任务列表那种带勾选框的清单,也支持吗?
- 删除线、行内代码、代码块这些呢?
- 代码块的语言标注,是怎么识别出来的?
- 它是完全符合CommonMark规范的吗?
- 标题用的是井号风格还是下划线风格?
- 转换时,表格里的竖线和换行怎么不破坏格式?
- 怎么用它把AI写的Markdown变成能发布的HTML?
- 内容场景一:AI输出的Markdown一键转发布HTML
- 内容场景二:网页或Word富文本迁移到Markdown
- 内容场景三:给大模型喂干净的Markdown内容
- 它转不了什么?这些边界得知道
- 为什么HTML转Markdown再转回HTML,能得到干净代码?
- 双向转换会丢信息吗?
- 实战案例:瑜伽服垫出海站的AI博客发布流
- 内容素材清洗三件套:格式流转是中间一环
- 常见问题解答
- Markdown转换器和直接在编辑器里写HTML有什么区别?
- 从Word复制内容转Markdown,为什么格式有时会乱?
- 代码块的语法高亮,转换后还能保留吗?
- 转出来的HTML可以直接用于SEO吗?语义标签全吗?
- Markdown转换、HTML转纯文本,这两个工具该用哪个?
- 权威参考资料
摘要:AI写的内容是Markdown,发布系统要的是HTML;从网页扒的是HTML,想搬进静态站又得是Markdown——两种格式来回倒腾,是现在做内容绕不开的活儿。这篇用一个Markdown转换器当例子,把它背后的双向转换讲透:HTML转Markdown靠的是Turndown库、Markdown转HTML靠的是marked库,两者都不是简单的正则替换,而是基于文档树的解析。顺带讲清它支持哪些语法、GFM的表格和任务列表怎么处理、代码块的语言标注怎么识别、它是不是完全符合CommonMark规范,以及在内容工作里它怎么帮你把AI的Markdown变成发布HTML、把脏网页洗成干净Markdown,又有哪些东西它转不了。
现在做内容,格式来回转换几乎是天天要干的事。你让ChatGPT或者Claude帮你写一篇文章,它吐给你的是Markdown;可你的网站后台、邮件系统、或者某个老CMS,要的是HTML,得转。反过来,你从某个网页上扒了段内容下来,是HTML,但你想把它搬进用Markdown写作的静态博客,又得往回转。一来一回,格式转换成了内容流转里的标准动作。
这种HTML和Markdown之间来回倒腾的活儿,交给一个Markdown转换器最省事。这篇就用一个支持双向转换的Markdown转换器当例子,把它怎么转、背后用了什么、支持哪些语法、又有哪些转不了的边界,掰开揉碎讲清楚——理解了它,你就能在格式转换这件事上少踩很多坑。
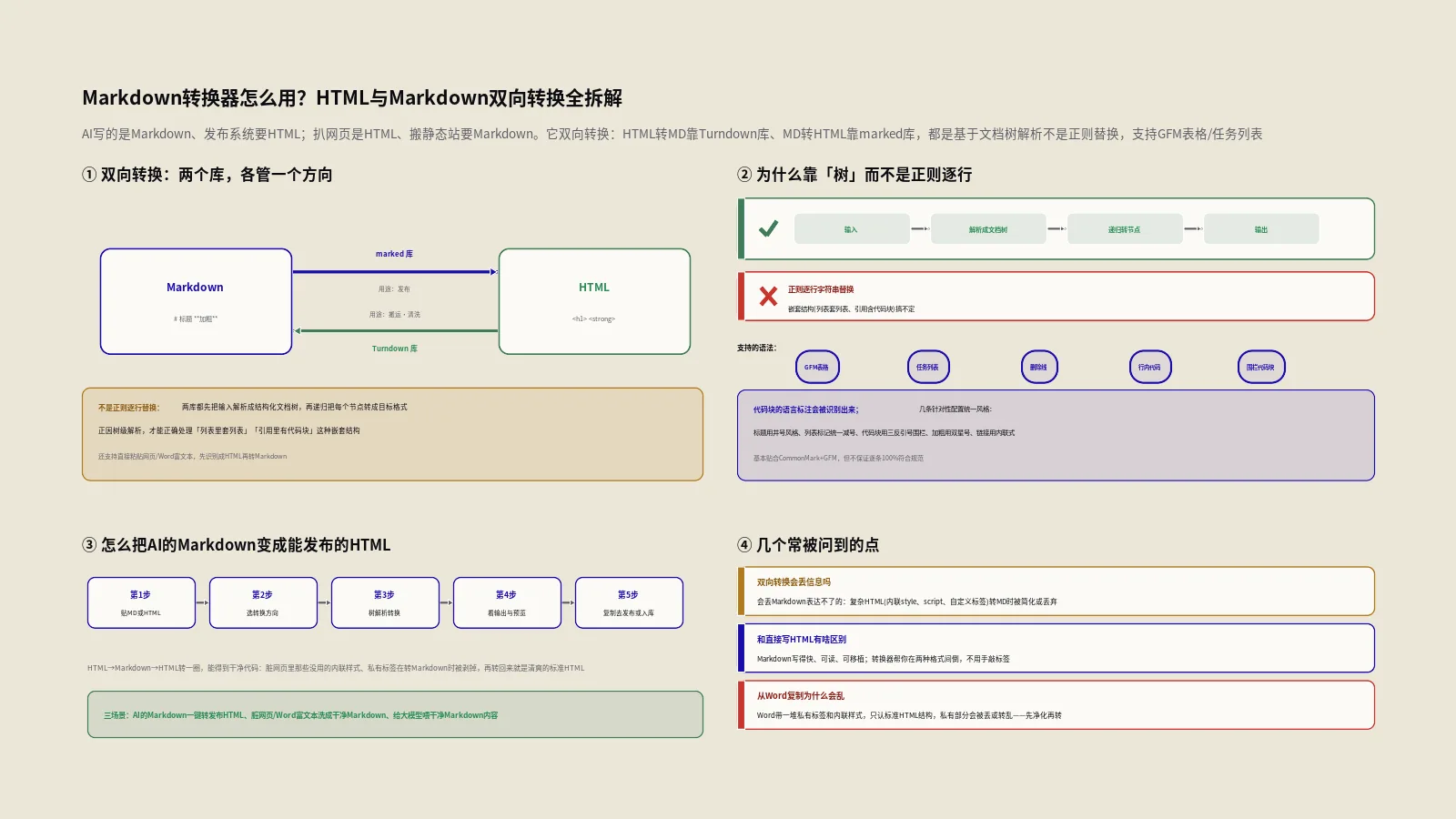
Markdown转换器到底转什么?双向是哪两个方向?
这个工具的核心能力是双向转换,两个方向。一个方向是Markdown转HTML:你写好的Markdown,转成网页能直接用的HTML标签,比如把井号开头的标题转成h标签、把星号包裹的文字转成strong加粗。另一个方向是HTML转Markdown:把网页的HTML源码,反过来转成简洁的Markdown文本。
这两个方向应对的是相反的需求。Markdown转HTML,是为了“发布”——你用Markdown轻松写作,转成HTML发到网站上。HTML转Markdown,是为了“搬运和清洗”——把别处的HTML内容,转成干净、可读、可移植的Markdown。工具还支持一种贴心的输入方式:直接粘贴网页或Word里的富文本,它会先识别成HTML再转Markdown,省去你手动找源码的麻烦。两个方向加起来,基本覆盖了内容格式转换的日常需求。
它是用正则一行行解析的吗?
很多人以为这类转换工具就是一堆正则表达式,逐行匹配替换。这个工具不是——它的两个方向都是基于成熟的开源库,做的是文档树级别的解析,不是简单的字符串替换。这点很重要,因为它决定了工具能不能正确处理嵌套、复杂结构。
具体说,HTML转Markdown这个方向,用的是一个叫Turndown的库;Markdown转HTML这个方向,用的是一个叫marked的库。这两个库都是把输入先解析成一棵结构化的文档树,再递归地把每个节点转成目标格式。正因为是树级解析,它才能正确处理“列表里套列表”“引用里有代码块”这种嵌套结构——这是朴素的正则逐行替换很难搞定的。理解了“它是库驱动的树解析、不是正则替换”,你就理解了它为什么能处理得比想象中复杂的内容。
HTML转Markdown,靠的是什么库?
HTML转Markdown这个方向,工具用的是Turndown。这是个专门做HTML到Markdown转换的JavaScript库,在前端圈用得很广,很多“把网页转成Markdown”的工具底层都是它。它的工作方式是读入HTML、构建DOM树,然后按一套规则把各类标签翻译成对应的Markdown语法——h标签转井号、strong转双星号、a标签转方括号加圆括号的链接格式,等等。
这个工具在Turndown的基础上还做了几条针对性的配置和扩展:标题用井号风格、列表标记统一用减号、代码块用三个反引号的围栏风格、加粗用双星号、链接用内联风格。这些配置决定了转出来的Markdown长什么样、风格统一不统一。关于Turndown这个库本身的用法和能力,可以查它的Turndown官方仓库,里面把它的规则系统和可扩展性讲得很清楚——工具的HTML转Markdown能力,根子就在这个库上。
Markdown转HTML,又靠什么?
反过来,Markdown转HTML这个方向,用的是marked库。这也是个名气很大的JavaScript库,专门把Markdown解析成HTML,速度快、兼容性好。你写的Markdown丢给它,它逐块逐行解析,生成标准的HTML标签。
marked是以CommonMark这个Markdown标准为基础来实现的。所谓CommonMark,是一份给Markdown立的正式规范——因为早年Markdown的语法在不同工具里行为不一致(同样的写法,这个工具这么渲染、那个工具那么渲染),CommonMark就是来终结这种混乱、给Markdown一个严格、明确定义的标准。
marked大体遵循这个标准,所以它转出来的HTML,行为是可预期的、符合主流认知的。这就是为什么你用这个工具转Markdown,结果不会跟你在GitHub、在其他Markdown编辑器里看到的差太多。
它支持哪些标准的Markdown语法?
常用的Markdown语法,这个工具基本都支持。标题:井号开头,一到六个井号对应一到六级。强调:单星号是斜体、双星号是加粗。链接:方括号包文字、圆括号包网址。图片:链接前面加个感叹号。列表:减号开头是无序列表、数字加点是有序列表,都支持嵌套。
还有引用块:大于号开头。行内代码:单个反引号包起来。代码块:三个反引号围起来。分隔线:三个减号或星号。这些是Markdown的核心语法,覆盖了日常写作的绝大多数需求。无论是Markdown转HTML,还是HTML转回Markdown,这些标准语法都能正确对应转换。换句话说,你日常写文章会用到的格式,它基本都接得住。
表格能转吗?GFM的表格是怎么处理的?
能,但要说清楚:标准的CommonMark其实是不含表格语法的,表格属于一个叫GFM(GitHub风味Markdown)的扩展。这个工具支持GFM的表格,用的是竖线分隔单元格、用一行减号来分隔表头和数据行的那套语法。
HTML转Markdown时,工具会把table标签里的表头和数据行提取出来,还会计算每一列的宽度、用对齐的方式生成那行减号分隔符,让转出来的Markdown表格在源码里看着就是整齐对齐的,可读性好。这个对齐处理是个不起眼但实用的细节,对README这类需要源码也美观的文档很有用。
关于GFM的表格、任务列表这些扩展语法的严格定义,可以参考GitHub风味Markdown官方规范,它把这些在CommonMark之上的扩展讲得很细。要注意,表格转换对规整的二维表管用,遇到合并单元格的复杂表,就力不从心了,这个后面单独讲。
任务列表那种带勾选框的清单,也支持吗?
支持。任务列表也是GFM的扩展之一,就是那种前面带方括号、可以打勾的清单——`- [ ]`是没勾的、`- [x]`是打了勾的,你在GitHub的issue和待办里常看到。这个工具专门处理了这种结构。
HTML转Markdown时,它会识别列表项里的勾选框,根据勾选框是不是被选中,转成对应的`- [ ]`或`- [x]`语法。反过来Markdown转HTML,也能把这种任务列表语法转成带勾选框的HTML。这意味着你从一个支持任务列表的地方(比如某个项目管理工具)扒下来的待办清单,转成Markdown后,勾选状态能保留,不会变成普通的无序列表。对要搬运带状态的清单的人来说,这个细节省了不少手工补勾的功夫。
删除线、行内代码、代码块这些呢?
都支持。删除线是GFM扩展,用两个波浪号包起来表示,工具能把HTML里的del、s、strike这几种表示删除的标签,转成波浪号的Markdown删除线。行内代码用单个反引号,对应HTML里非代码块的code标签。
代码块是三个反引号围起来的,对应HTML里的pre标签。这里有个值得说的细节:代码块通常会带语言标注(比如指明这是Python代码、那是JavaScript代码),好让渲染时能做语法高亮。这个工具能识别并保留语言标注,下一节专门讲它怎么做到的。总之,写技术文档、教程时常用的删除线、行内代码、代码块,这个工具都能正确双向转换,不会在转换中丢掉。
代码块的语言标注,是怎么识别出来的?
代码块带语言标注,渲染时才能正确高亮,所以转换时能不能保住这个标注很关键。这个工具是这么做的:HTML里的代码块,语言信息通常写在code标签的class属性里,是个固定的格式——“language-”后面跟语言名,比如`language-python`表示Python、`language-javascript`表示JavaScript。
工具用正则去匹配这个`language-`开头的class,把后面的语言名提取出来,转成Markdown代码块围栏后面的语言标注,也就是三个反引号紧跟着语言名那种写法。如果代码块的class里没有这个标注,那转出来就是个不带语言的普通代码块。这个处理保证了你从一个有语法高亮的网页扒代码下来,转成Markdown后语言信息不丢,搬到别处还能继续正确高亮。对搬运技术内容的人,这是个很实在的便利。
它是完全符合CommonMark规范的吗?
这里要诚实说一句:不是严格完全符合。工具的Markdown转HTML用的marked库,是以CommonMark为基础实现的,大体遵循这个标准,但默认配置下并没有开启严格模式。这意味着在一些边边角角的情况下,它的行为可能跟CommonMark规范的字面定义有细微出入。
对日常使用来说,这点出入基本无感——你写的那些标准语法,标题、列表、链接、表格,转出来都是符合主流认知的结果。只有当你去抠一些极端的、有歧义的语法边界时,才可能碰到“这里跟规范说的不太一样”的情况。所以更准确的说法是:它大体遵循CommonMark、加上GFM扩展,而不是百分百严格符合规范。
想了解CommonMark规范本身那些严谨到每个例子的定义,可以看CommonMark官方规范,它用五百多个例子把Markdown的每种边界行为都钉死了。知道这个边界,你就不会拿一些极端case去苛求它跟规范分毫不差。
标题用的是井号风格还是下划线风格?
Markdown的标题其实有两种写法。一种是井号风格(也叫atx风格):标题前面加井号,几个井号就是几级标题,这是最常见的写法。另一种是下划线风格(也叫setext风格):在标题文字下面用等号或减号画一条线来表示标题,但这种只能表示一级和二级,用得少。
这个工具在HTML转Markdown时,配置成了用井号风格。所以你把网页标题转成Markdown,得到的会是井号开头的那种,而不是下划线画线那种。这是个有意的统一——井号风格更通用、更清晰、能表示全部六级,是绝大多数Markdown写作的主流选择。工具固定用井号风格,保证了转出来的Markdown风格一致,不会一会儿井号一会儿画线地混着来。
转换时,表格里的竖线和换行怎么不破坏格式?
表格转换有个很容易翻车的地方:Markdown表格用竖线来分隔单元格,那如果某个单元格的内容里本身就含有竖线字符,岂不是会被误当成列分隔符,把表格搞乱?还有,如果单元格内容里有换行,也会破坏表格的行结构。
这个工具对此做了转义处理。单元格内容里的竖线,会被转义成反斜杠加竖线的形式,这样它就只是个普通字符、不会被当成列分隔符。单元格内的换行,会被替换成空格,避免一个单元格的内容跨了行把表格撑破。这两个处理保证了表格转换的健壮性——哪怕你的表格数据里有竖线、有换行这些“危险字符”,转出来的Markdown表格也不会散架。这种对边界情况的处理,正是成熟转换工具和粗糙工具的区别所在。
怎么用它把AI写的Markdown变成能发布的HTML?
这是现在最高频的用法之一,把它走顺其实就几步,这里给一套可照搬的流程。
- 拿到AI输出的Markdown。从ChatGPT、Claude这类工具复制它生成的内容,这些内容默认就是Markdown格式(带井号标题、减号列表、星号加粗那种)。
- 贴进转换器,选Markdown转HTML方向。把复制的Markdown粘贴到工具的输入框,确认转换方向是“Markdown转HTML”。
- 转换并预览。点转换,工具会输出对应的HTML,同时一般有个预览区让你看渲染效果,确认标题、列表、表格、代码块都转对了。
- 检查语义标签。扫一眼输出的HTML,确认标题是规规矩矩的h标签、列表是ul或ol、加粗是strong——这些语义标签对SEO是有意义的,别转出来一堆没有语义的div。
- 复制HTML去发布。确认无误后,把HTML复制到你的网站后台、CMS或者邮件系统里发布。需要的话,再补上你的样式class。
这套流程的关键,是第四步的语义标签检查——AI生成的Markdown转出来的HTML,标题、列表这些结构标签是否规整,直接关系到这篇内容对搜索引擎友不友好,别图快跳过这一步。
内容场景一:AI输出的Markdown一键转发布HTML
这是Markdown转换器在AI时代最直接的价值。现在大量的内容初稿是AI写的,而AI几乎清一色用Markdown输出。你总不能手工把每个井号标题改成h标签、每个减号列表改成ul吧,那太慢了。
用转换器,把AI的Markdown一贴一转,干净的HTML就出来了,直接进发布系统。这里要强调的还是语义质量:好的转换会把Markdown的结构准确映射成对应的语义HTML标签——标题就是h标签、列表就是ul或ol、引用就是blockquote。这些语义标签不只是好看,它们帮搜索引擎理解你内容的结构层次。AI写得再好,如果转成HTML时结构标签乱了,SEO上是要吃亏的。所以选一个能输出干净语义HTML的转换器,是AI内容工作流里一个容易被忽略、但其实很要紧的环节。
内容场景二:网页或Word富文本迁移到Markdown
另一个高频场景是反方向的:把已有的HTML或者富文本内容,迁移成Markdown。比如你要把一批老文章从某个CMS搬到用Markdown写作的静态博客,或者把Word、Google文档里的内容转成Markdown存档。
这时候HTML转Markdown的能力就派上用场。工具能把常见的标签结构——标题、列表、表格、代码块、链接——比较完整地映射成Markdown。Word复制出来的HTML通常带着一堆冗余的样式标签,Turndown在转换时会把这些噪声清理掉,给你相对干净的Markdown。要诚实说,这种迁移不是百分百无损,主流的格式能保住八成左右,但复杂的排版、合并单元格的表格、嵌套很深的结构,转完往往还要手工调一调。把它当成“帮你完成大部分迁移工作、剩下小部分手工收尾”的工具,预期就对了。
内容场景三:给大模型喂干净的Markdown内容
还有个越来越常见的用法:把内容转成Markdown再喂给大模型。为什么不直接喂HTML?因为HTML里标签噪声多,既干扰模型对内容结构的理解,又白白消耗token。Markdown则简洁得多,用很少的符号就表达了标题、列表、强调这些结构。
所以一个实用的工作流是:先把网页HTML用转换器转成Markdown,再把这份干净的Markdown喂给AI。模型既能从Markdown的井号、减号里读懂内容的层级结构,又不用为一堆标签买单。比起喂纯文本,Markdown还多保留了结构信息(哪是标题、哪是列表),比起喂HTML,又干净得多——它在“保留结构”和“足够干净”之间取了个很好的平衡。这也是为什么Markdown正在成为人和AI之间传递内容的一种通用中间格式。
它转不了什么?这些边界得知道
用好它,得清楚它的边界。第一,合并单元格的复杂表格转不好。Markdown的表格语法本身就不支持单元格横跨多列、纵跨多行,所以HTML里那种有合并单元格的复杂表格,转成Markdown只能被拍平成普通的单元格序列,合并信息丢失。
第二,一些扩展语法不支持,比如脚注、数学公式(LaTeX),工具没有专门的规则处理它们,会被当成普通文本。第三,HTML的自定义属性保不住——Markdown没法表达HTML标签上的class、id、data这些属性,所以HTML转Markdown再转回HTML,这些属性会丢。第四,行内混写的原始HTML、iframe、script这类动态内容,要么处理不了要么出于安全被忽略。把这几条记清楚:它擅长的是标准的、结构化的内容格式互转,不擅长复杂排版、扩展语法和带属性的精细HTML。
为什么HTML转Markdown再转回HTML,能得到干净代码?
有个挺妙的用法:拿一段又脏又乱的HTML(比如Word导出的、满是冗余样式标签的那种),先用工具转成Markdown,再把这个Markdown转回HTML,你会得到一份干净许多的HTML。这是怎么回事?
原理在于,Markdown这个中间格式本身是“极简”的——它只能表达标题、列表、链接、强调这些核心结构,表达不了那些花里胡哨的内联样式和冗余属性。所以当HTML被转成Markdown时,那些噪声因为“在Markdown里无处安放”就被自然地过滤掉了,只剩核心结构。再从这份纯净的Markdown转回HTML,生成的就是结构清晰、没有冗余的标准HTML。这一来一回,相当于借Markdown当了个“过滤网”,把脏HTML洗成了干净HTML。需要规范化乱HTML时,这是个简单有效的法子。
双向转换会丢信息吗?
会,而且知道丢在哪很重要。最主要的丢失发生在HTML转Markdown这一步,因为Markdown的表达能力比HTML窄。前面说的那些——标签上的class、id、data自定义属性,会丢;HTML注释,转换中保不住;合并单元格的表格结构,会被拍平;复杂的嵌套排版,可能简化。
这意味着,如果你的HTML里承载了重要的样式信息或者自定义属性,转成Markdown再转回来,这些是回不来的。所以用之前要想清楚:你要保的是“内容和基本结构”,还是“连样式带属性的完整呈现”?如果是前者,双向转换没问题,丢的都是你不在乎的;如果是后者,那转换会损失你在乎的东西,得另想办法。这不是工具的bug,而是两种格式表达能力不对等导致的根本限制——Markdown生来就比HTML简单,简单是它的优点,也是它的代价。
实战案例:瑜伽服垫出海站的AI博客发布流
我们团队去年帮一个做瑜伽服、瑜伽垫的出海站搭内容运营流程,Markdown转换器是这条流水线上的一个固定环节。这站走的是内容营销路线,靠大量的瑜伽教程、选购指南、体式科普博客来获取自然流量,更新频率要求不低。
它们的内容初稿很大一部分是借助AI产出的——运营给定选题和要点,让AI写出Markdown初稿,再由编辑润色、补真实经验和案例。问题出在发布环节:站点的CMS要的是HTML,而AI给的、编辑改的都是Markdown,早期是人工一个个标题、列表手动改成HTML标签,又慢又容易出错,有次还把代码示例的格式改乱了。我们引入Markdown转换器后,把这一步标准化了:编辑定稿的Markdown,统一走转换器转成HTML,重点检查转出来的标题是不是规整的h标签、列表是不是ul、有没有把语义结构转丢。
这么一改,发布效率明显提上来,格式出错的情况基本没了,编辑能把精力放回内容本身而不是格式搬运上。更关键的是,转出来的HTML语义结构规整,这批博客在搜索里的表现也比早期手工转的那些稳。这个案例的要点是:在AI写作成为常态的今天,Markdown到HTML的转换不是个可有可无的小工具,而是内容发布流水线上一个该被标准化的关键环节——它处在AI产出和正式发布之间,做好了,整条流水线才顺。
内容素材清洗三件套:格式流转是中间一环
把Markdown转换放进更大的内容处理图景里,它是“内容素材清洗”流水线上承上启下的一环。一份内容从原始素材到能发能用,通常要走采集清洗、格式流转、篇幅质检这几步,转换器管的是中间的格式流转。
它的上游,常常是把脏HTML剥成干净文本或干净结构这一步——比如你从网页扒了内容,可能先要用HTML转纯文本工具剥掉噪声,再决定转成Markdown还是别的格式。
它的下游,往往是对转换好的内容做篇幅和质量的核对——内容到底多少字、读完要多久、够不够发布标准,这要用字数统计工具来量。剥文本、转格式、数字数,这三件套串起来,就是内容素材从杂乱到规整可用的完整清洗流程。这篇讲的格式流转,是中间这道工序——它把内容在不同格式之间安全地搬运,让上下游都好衔接。转换质量好不好,直接影响你最终内容的可读性,想深挖内容可读性这块,也可以看我们讲过的可读性评分工具的方法。
常见问题解答
Markdown转换器和直接在编辑器里写HTML有什么区别?
区别在效率和专注。直接写HTML,你得一个个敲标签,写个加粗要打strong标签、写个列表要打ul和li,又慢又容易漏闭合标签。用Markdown写作,你只用井号、星号、减号这些极简符号就能表达结构,写得飞快,专注在内容上;写完用转换器一键转成HTML去发布。更现实的是,现在内容初稿大量来自AI,而AI输出的就是Markdown,你几乎必然需要一个Markdown转HTML的环节。所以转换器不是替代手写HTML,而是让你能用更轻松的Markdown来写、用HTML来发,两头的好处都占上。
从Word复制内容转Markdown,为什么格式有时会乱?
因为Word复制出来的HTML特别脏。Word为了精确还原它的排版,会在HTML里塞进大量冗余的样式标签、私有属性和嵌套结构,这些远超标准HTML的范畴。转换器底层的Turndown库会尽力清理这些噪声、提取核心结构,但遇到特别复杂的排版——多级嵌套列表、合并单元格的表格、花式的文本框——就可能转得不理想。应对办法是:转完之后人工过一遍,重点检查表格和深层嵌套的列表,手动调整少数转乱的地方。把它当成“帮你完成大部分、剩小部分收尾”的工具,预期就对了,别指望复杂的Word文档能百分百无损转换。
代码块的语法高亮,转换后还能保留吗?
语言标注能保留,高亮本身要看渲染环境。工具在HTML转Markdown时,会从代码标签的class属性里识别出语言标注(那种language-开头的格式),转成Markdown代码块围栏后面的语言名,所以语言信息不会丢。至于最终有没有语法高亮,取决于你把这份Markdown放到哪渲染:目标平台支持高亮(比如多数静态博客、GitHub),会根据标注自动上色;不支持,就只是个带标注的纯代码块。简言之,转换器负责保住语言信息,高亮效果由渲染端决定。
转出来的HTML可以直接用于SEO吗?语义标签全吗?
基本可以,前提是源Markdown结构清晰。工具会把Markdown的结构准确映射成语义HTML——井号标题转成对应级别的h标签、列表转成ul或ol、引用转成blockquote、加粗转成strong。这些都是对SEO有意义的语义标签,搜索引擎靠它们理解你内容的层次结构。所以只要你的Markdown本身标题层级用对了,转出来的HTML语义结构就是规整的,可以直接用于SEO。要注意工具不会替你补图片alt、不会生成结构化数据,它只负责把结构转成对应标签,内容层面的SEO优化还得你自己做。
Markdown转换、HTML转纯文本,这两个工具该用哪个?
看你要的结果是什么。要的是“完全干净、不带任何格式的纯文字”——比如做文本分析、喂AI做纯内容理解、生成邮件纯文本版,那用HTML转纯文本工具,它把所有标签都剥光、只留文字。要的是“保留结构的轻量格式”——比如在平台间搬运内容、让AI既读懂结构又不被标签干扰,那用Markdown转换器,它把内容转成保留了标题、列表、强调等结构的Markdown。一个剥到只剩文字、一个保留结构,按你下游要拿这份内容干什么来选。很多时候两个会配合用:先剥再转,或者直接HTML转Markdown一步到位。
权威参考资料
本文标题:《Markdown转换器怎么用?HTML与Markdown双向转换全拆解》
本文链接:https://zhangwenbao.com/markdown-converter-html-bidirectional-conversion-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0