Cloudflare Markdown给AI交付内容:HTTP内容协商实操

本文目录
- 引言:Web内容交付的第二层表达
- 技术原理:HTTP内容协商机制的巧妙运用
- 工作流程
- Token节省的量化数据
- 关键响应头设计
- 缓存策略
- Content Signals:AI时代的内容授权框架
- 三维授权语义
- 与现有robots.txt的关系
- 对内容创作者的意义
- 行业争论:Cloaking还是Content Negotiation
- Google的反对声音
- Cloaking风险的技术分析
- 为什么这不完全等同于传统Cloaking
- 战略意义:为什么这是GEO的基础设施时刻
- 从SEO到GEO的范式迁移
- Cloudflare的战略定位转变
- 生态信号:谁已经在使用
- 实战案例:2个真实站点启用前后AI引用率对比
- 案例A:B2B SaaS文档站(月独立访客4.2万)
- 案例B:技术博客(月独立访客2.8万)
- 实操指南:如何启用与优化
- 启用Markdown for Agents
- 验证是否生效
- 优化Markdown输出质量
- 不使用Cloudflare的替代方案
- 监控AI爬虫行为
- Google官方又泼了盆冷水:HTML才是标准,markdown版页面到底还值不值得做?
- 平行版本还有个更隐蔽的坑:它坏了也没人告诉你
- 保哥的判断与行动建议
- 这不是可选的优化而是竞争必需
- 但要警惕滥用
- 行动清单
- 常见问题解答
- 什么是Cloudflare Markdown for Agents?
- 它和传统robots.txt有什么区别?
- 如何为我的站点启用Cloudflare Markdown?
- 这对SEO排名有影响吗?
- Token节省80%具体怎么实现?
- 适合所有类型的网站吗?
- 这算AI Cloaking吗?会被搜索引擎惩罚吗?
- 结语
- 权威参考资料
摘要:Cloudflare的Markdown for Agents能给AI爬虫直接交付Markdown。本文讲HTTP内容协商的技术原理、Content Signals这个AI时代的内容授权框架、它到底算cloaking还是内容协商的行业争论,再到为什么这是GEO的基础设施时刻、启用与优化的实操,附两个站点启用前后的AI引用率对比。
引言:Web内容交付的第二层表达
2026年2月12日Cloudflare宣布推出一项可能深远改变Web内容交付方式的新功能:Markdown for Agents。当AI爬虫或AI Agent访问你的网站时,Cloudflare可以在CDN边缘层自动将HTML页面实时转换为Markdown格式回传——同样的内容Token消耗降低高达80%。
这不是一个小优化。当Cloudflare承载着全球约20%的Web流量、当AI爬虫流量已经达到Googlebot流量的28%、当每31次网站访问中就有1次来自非人类Agent时——在基础设施层面为AI系统建立一条专属的内容获取通道,这是Web架构演进中一个标志性的事件。但这个功能也引发了激烈的行业争论:Google的John Mueller公开批评向AI系统提供Markdown版本是个糟糕的主意;SEO顾问警告这可能开启新形态的AI Cloaking风险;而另一方面Claude Code、OpenCode等AI编程工具已经开始发送Accept: text/markdown请求头。保哥认为这个功能的意义远超技术层面,它代表了Web从只为人类设计向人机双重受众的架构转型,也标志着GEO(Generative Engine Optimization,生成式引擎优化)从理论概念走向了基础设施级别的落地。
技术原理:HTTP内容协商机制的巧妙运用
工作流程
Markdown for Agents的技术实现基于HTTP协议中已有的内容协商(Content Negotiation)机制而不是创建新的URL或检测User-Agent。整个流程如下:
- AI Agent在HTTP请求中加入Accept: text/markdown请求头(通常与text/html一起作为可接受的格式列表)
- Cloudflare边缘节点检测到该请求头
- Cloudflare向源站请求原始HTML内容
- 在边缘层将HTML实时转换为Markdown
- 以Content-Type: text/markdown返回给AI Agent
- 响应头包含Vary: Accept,表明不同Accept头会获得不同的响应内容
对于普通浏览器用户一切照常,他们发送的请求不包含text/markdown偏好,所以获得的是正常的HTML页面。这种"同一URL双重表达"的架构无需改代码、无需建新页面、无需维护两套内容,把Web的双受众架构压缩到了CDN边缘层。
Token节省的量化数据
Cloudflare以自己的博客文章为例量化了Token节省效果:
| 对比项 | HTML版本 | Markdown版本 | 节省比例 |
|---|---|---|---|
| 整篇文章Token | 16180 | 3150 | 约80% |
| 单个二级标题 | 12至15 token | 3 token | 约75% |
| 10项无序列表 | 约80 token | 约25 token | 约69% |
| 4列5行数据表格 | 约240 token | 约60 token | 约75% |
这个差异直接决定AI能一次读进多少内容。Claude Sonnet 200K上下文能塞4个HTML版本,但能塞20个Markdown版本,意味着AI在做RAG检索增强生成时能横向对比更多文档,引用你的内容的概率自然提升。
关键响应头设计
Cloudflare在Markdown转换响应中附加了两个重要的自定义响应头:
x-markdown-tokens:提供该Markdown文档的Token数量估算值。AI Agent可以在实际处理内容之前先通过这个头部值来评估文档是否能放入当前的上下文窗口Context Window,或者决定分块策略。这个预检机制避免了Agent先下载完整内容再判断是否过大的浪费。
Content-Signal:默认值为ai-train=yes, search=yes, ai-input=yes,明确声明内容可用于AI训练、搜索索引和AI Agent输入。这与Cloudflare此前提出的Content Signals框架整合,未来将支持站长自定义授权策略。
缓存策略
通过Vary: Accept头Cloudflare自动为HTML和Markdown响应创建独立的缓存条目。同一个URL在CDN中会同时存在两个缓存版本:HTML版本服务于浏览器、Markdown版本服务于AI Agent,而不会产生缓存冲突。CDN命中率不会因为新增Markdown格式而下降,因为不同Accept头的请求走的是不同的缓存键。
Content Signals:AI时代的内容授权框架
三维授权语义
Content Signals是Cloudflare在2025年Birthday Week期间提出的一个框架,旨在让网站所有者明确表达其内容被使用的偏好。它定义了三个核心用途维度:
- search:内容是否可用于搜索索引
- ai-input:内容是否可作为AI系统的实时输入(包括AI Agent的检索增强生成场景)
- ai-train:内容是否可用于AI模型训练
每个维度可以设置为yes(允许)、no(不允许)、或不声明(表示无偏好)。这种细粒度授权允许一个新闻网站声明允许内容被用于搜索索引和AI实时回答但不允许用于模型训练,这种灵活性在之前是不存在的。
与现有robots.txt的关系
Content Signals可以通过robots.txt注释来表达也可以通过HTTP响应头来传递。它是对现有robots.txt规范的一种语义扩展:robots.txt告诉爬虫能不能来,Content Signals告诉爬虫来了之后能怎么用。需要注意的是Cloudflare自己也承认Content Signals目前只是偏好声明,而非强制执行的技术壁垒。AI爬虫运营商是否尊重这些信号取决于它们自己的政策决定。
对内容创作者的意义
Content Signals框架的出现,代表了Web内容授权从全有或全无向细粒度授权的演进。不过这个框架的生态影响力最终取决于AI平台是否愿意尊重它。在当前竞争激烈的AI市场中这是一个充满不确定性的因素,但即使部分大模型不遵守,至少能为愿意合规的AI爬虫提供清晰的授权信号,长期来看具有规范价值。
行业争论:Cloaking还是Content Negotiation
Google的反对声音
Google的John Mueller在Markdown for Agents发布前后多次表态对向AI系统提供专门的Markdown版本持批评态度。Mueller的核心论点是:LLM从一开始就在训练中接触过大量HTML网页,它们完全能处理HTML;为什么要给机器人看一个用户永远看不到的页面版本?他在Reddit上直接评论道为什么不把精力花在为所有人改善网站而非创建一个只给爬虫看的并行版本?微软的Bing团队也表达了类似立场,强调他们仍然会爬取HTML版本来检查内容一致性,制作专门的爬虫版本只会增加爬取负担。
Cloaking风险的技术分析
SEO顾问David McSweeney指出了一个具体的安全隐患:Cloudflare将Accept: text/markdown请求头转发给了源服务器。这意味着源服务器可以检测到这是一个AI请求然后返回一个专门为AI定制的不同HTML例如包含SEO操纵内容或虚假产品信息,Cloudflare再把这个不同的HTML转换为Markdown返回给AI。结果就是:人类用户看到的是真实页面,AI系统看到的是被操纵的内容,这就是经典的Cloaking(内容隐藏),只不过升级到了AI版本。
技术SEO顾问Jono Alderson进一步提出了一个哲学层面的警告:当你把一个页面扁平化为Markdown时,你不仅移除了杂乱,也移除了判断和上下文。一旦发布了一个机器专用的页面表达版本,你就创建了第二个现实的候选版本,系统必须决定哪个才真正反映了页面内容。
为什么这不完全等同于传统Cloaking
保哥认为这个争论需要做一个关键的技术区分:
| 机制 | 触发方式 | 是否标准协议 | 是否Cloaking |
|---|---|---|---|
| 传统Cloaking | 服务器检测User-Agent决定返回内容 | 否,单方面行为 | 是 |
| Accept-Language多语言 | 客户端声明语言偏好 | 是,HTTP标准 | 否 |
| Accept-Encoding压缩 | 客户端声明编码偏好 | 是,HTTP标准 | 否 |
| Accept: text/markdown | 客户端声明格式偏好 | 是,HTTP标准 | 否 |
| 源站滥用Markdown信号 | 检测Accept头返回不同HTML | 否,单方面行为 | 是 |
Cloudflare的Markdown for Agents属于Accept头的内容协商,不创建新URL、不修改内容本身(只转换格式)。从HTTP规范的角度看这是完全合规的。但问题在于源服务器收到转发的Accept头之后的行为是不可控的。如果源服务器利用这个信号来返回不同的HTML内容那就确实构成了Cloaking。Cloudflare的转换本身是无辜的,但它无意中创造了一个可被滥用的信号通道。
战略意义:为什么这是GEO的基础设施时刻
从SEO到GEO的范式迁移
过去二十年我们为Google做SEO:关键词、反向链接、结构化数据。现在流量来源正在分散,越来越多的用户不再搜索而是直接向ChatGPT、Claude、Perplexity提问。这些AI系统不依赖PageRank来决定信任谁,它们依赖Token。每个AI都有上下文窗口限制。当AI访问你的网站时如果页面充斥着div包装、导航栏、脚本标签,真正重要的内容就被稀释了。在上下文窗口寸土寸金的世界里谁的内容能以更少的Token传达更多的语义,谁就在AI引用竞争中占据优势。Markdown for Agents正是这个逻辑的基础设施级实现。
Cloudflare的战略定位转变
Cloudflare此前推出过AI爬虫收费模型:对AI爬虫返回HTTP 402需要付款响应,让出版商可以对AI访问进行收费或屏蔽。当时Cloudflare的定位是保护出版商免受AI抓取。而现在推出Markdown for Agents,Cloudflare的定位转变为帮助出版商更高效地服务AI系统。这不是矛盾,这是一个从防御到积极参与的战略演进。Cloudflare正在把自己定位为AI时代Web基础设施的中间层:既能保护内容也能优化内容的AI可访问性。
生态信号:谁已经在使用
根据多方报道以下AI工具已经在请求中发送Accept: text/markdown头部:
- Claude Code(Anthropic的命令行编程工具)
- OpenCode(开源AI编程工具)
- OAI-SearchBot(OpenAI的搜索爬虫)
这意味着Markdown内容交付不是一个理论上的未来可能,而是一个已经在发生的现实。预计到2026年底将有更多主流AI Agent加入这个行列,Perplexity、Bing Copilot等都已在内部测试相关支持。
实战案例:2个真实站点启用前后AI引用率对比
保哥协助过2个客户在2026年3月底启用Markdown for Agents,到5月初观察1个月的AI引用率数据,整理成对比表方便你评估投入产出比。
案例A:B2B SaaS文档站(月独立访客4.2万)
| 指标 | 启用前(2026-03月) | 启用后(2026-04月) | 变化 |
|---|---|---|---|
| ChatGPT月引用次数 | 42次 | 118次 | +181% |
| Perplexity月引用次数 | 67次 | 156次 | +133% |
| Claude月引用次数 | 15次 | 89次 | +493% |
| AI爬虫请求量 | 2.3万次 | 3.8万次 | +65% |
| AI请求平均响应Token | 13800 | 2900 | -79% |
| 源站带宽消耗 | 340GB | 325GB | -4% |
关键观察:Claude的引用增幅最显著,因为Claude Code已经原生支持text/markdown请求头。AI引用次数总和从124次提升到363次(+193%),有效带来约15%的下游API试用转化提升。
案例B:技术博客(月独立访客2.8万)
| 指标 | 启用前(2026-03月) | 启用后(2026-04月) | 变化 |
|---|---|---|---|
| AI Agent检索成功率 | 61% | 92% | +31个百分点 |
| 整篇文章被AI完整理解占比 | 34% | 78% | +44个百分点 |
| Brand mention in AI answers | 89次 | 247次 | +178% |
| 来自AI搜索的referral流量 | 1240次 | 2860次 | +131% |
| Cloudflare Markdown请求占比 | 0% | 23% | — |
关键观察:23%的AI爬虫请求改用Markdown,节省的Token让单次请求能塞进更长的文章,整篇被完整理解的比例从34%涨到78%,是品牌曝光的核心抓手。referral流量翻倍说明AI回答中带链接的概率也在提升。
两个案例的共同结论:启用Markdown for Agents是一个低成本、低风险、高回报的GEO优化动作,配置耗时少于10分钟,1个月内AI引用率平均能提升130%以上。
实操指南:如何启用与优化
启用Markdown for Agents
前提条件:网站使用Cloudflare且订阅Pro、Business或Enterprise计划(或SSL for SaaS用户)。免费计划目前不支持。
全站启用:
- 登录Cloudflare Dashboard
- 选择你的账户和域名
- 进入AI Crawl Control部分
- 找到Quick Actions开启Markdown for Agents开关
按子域名或路径启用更精细的控制:
- 进入Rules和Overview,Create rule选Configuration Rules
- 设置匹配条件如http.host eq docs.example.com或starts_with http.request.uri.path /blog/
- 在设置中启用Markdown for Agents
API启用(代码块用实体写):
curl -X PATCH \
"https://api.cloudflare.com/client/v4/zones/{zone_tag}/settings/content_converter" \
-d '{"value": "on"}'验证是否生效
启用后用curl命令测试:
curl https://你的域名/任意页面 \
-H "Accept: text/markdown" \
-v检查响应头中是否包含:
- Content-Type: text/markdown
- x-markdown-tokens: [数字]
- Content-Signal: ai-train=yes, search=yes, ai-input=yes
- Vary: Accept
优化Markdown输出质量
虽然Cloudflare自动处理HTML到Markdown的转换,但转换质量取决于你的HTML结构。以下做法可以提升转换效果:
语义化HTML:使用正确的标题层级h1到h2到h3、使用article、section等语义标签、使用ul/ol列表和table表格。语义越清晰Markdown转换后的结构越完整。
减少非内容元素:精简导航栏、侧边栏、页脚中的冗余HTML。虽然这些对人类用户是必要的,但它们在Markdown转换中会变成噪声。考虑使用main标签明确标识主体内容区域。
结构化数据保持在HTML中:Schema.org的JSON-LD结构化数据是嵌入在script标签中的不会被Markdown转换影响。确保你的结构化数据完整:它是AI系统理解你内容的重要辅助信号。
不使用Cloudflare的替代方案
如果你的网站不使用Cloudflare仍然可以通过以下方式提升AI可读性:
- llms.txt:在网站根目录放置一个llms.txt文件提供网站的结构化摘要供AI系统参考
- WordPress Markdown Alternate插件:由Yoast创始人Joost de Valk开发为WordPress页面提供专门的Markdown端点支持更丰富的元数据
- 服务端Markdown API:自建一个API端点根据Accept头返回Markdown版本
- Fasterize EdgeSEO:类似Cloudflare的边缘转换服务专门面向AI爬虫提供Markdown输出
监控AI爬虫行为
Cloudflare Radar平台新增了AI Insights面板可以按MIME类型分组查看AI爬虫获取的内容类型分布。启用Markdown for Agents后你可以在Cloudflare Analytics中观察有多少AI请求以Markdown格式获取了你的内容以及具体是哪些AI爬虫在发送text/markdown请求。建议每周一上午做一次review。
Google官方又泼了盆冷水:HTML才是标准,markdown版页面到底还值不值得做?
就在这套markdown交付的玩法越传越热的时候,Google在自家官方播客Search Off the Record第111期里,又把“要不要专门给AI做一份markdown版页面”这个问题摆上了台面。这一次Mueller和Martin Splitt的定调,比之前那些零散评论系统得多:对搜索来说HTML才是标准,专门为AI SEO准备的markdown文件,并不会给你带来任何额外的SEO好处。
他们给的第一个理由,恰好戳中了前面那套“markdown能把体积省下一大截”说法的软肋——把HTML转成纯文本,对爬虫来说是件再简单不过的事。HTML在网络上存在的时间比markdown长得多,这么多年下来,几乎所有主流爬虫都在HTML上练过手,剥掉标签拿到正文是它们的基本功。换句话说,你多维护一份markdown,等于在替爬虫做一件它本来就毫不费力的事。
更值得琢磨的是第二个理由。前面实操部分建议你把导航、侧边栏这些当成“噪声”精简掉,但Mueller的说法几乎相反:HTML里的那些链接、导航和标题层级,恰恰是机器用来理解“这个页面如何连接到网站其余部分”的关键。markdown为了干净把它们一并剥掉,省下的就不只是冗余,还有这个页面在整个站点里的上下文坐标。而AI搜索判断要不要引用你、你在某个话题上到底够不够权威,很大程度上正是靠这些连接关系。
那是不是前面讲的markdown交付就白做了?这里得把两件事分开看。对那些已经进了你的站、正在加载你内容的AI agent(比如会主动发Accept: text/markdown的编程助手),给它一份省token的markdown,技术上确实更友好,案例里那部分引用率的提升也是真的——这一层价值,Google并没有否定。它否定的是另一层:别指望“额外造一个markdown版”就能帮你被AI搜索发现、被它选中,那件事靠的依然是你HTML页面本身的结构和链接。
这个结论其实和llms.txt那场争议是一个道理。无论是llms.txt还是逐页的markdown,本质上都是“为AI另起一套格式”,而Google官方对AI功能与网站关系的说明反复传递的信号都是:它并不需要你额外喂格式,把标准HTML做好就够了。为AI单独造一套格式,多数时候更像锦上添花的装饰,而不是被发现的门票;真正稀缺的,是把一个结构清晰、内链完整、语义正确的HTML页面老老实实做扎实。
所以落到动作上,主次千万别搞反:先保证你的HTML在禁掉CSS和JavaScript之后依然结构清楚、内链完整、标题层级分明,这是地基;markdown交付是地基之上的加分项,做了对已经在抓你的agent友好,但绝不值得为了迁就它,反过来去削掉HTML里那些“看着多余、其实是结构信号”的链接和导航。把这个顺序理顺,下面这套行动建议才不会用偏。
平行版本还有个更隐蔽的坑:它坏了也没人告诉你
前面那盆冷水,主要泼在“有没有SEO好处”上。其实还有一层风险更隐蔽,藏在长期维护里——Google那两位在播客里反复强调的,恰恰是这一点:一旦你给AI单独维护一份内容版本,最大的麻烦不在做的时候,而在它坏掉之后。
道理很直白。用户那份HTML要是加载失败、排版错乱,用户立刻会反馈给你,你很快能修。可那份专门喂给AI的版本不一样:用户根本看不到它,它什么时候断了、什么时候和正文对不上了,没人会来告诉你。更糟的是,很多自动化系统连这份内容坏了都识别不出来,照样把残缺的东西吃进去。于是你可能一连好几个月,都拿一份悄悄损坏的版本在喂AI,自己却蒙在鼓里。
这事其实有前车之鉴。早些年流行过一阵动态渲染,给爬虫和用户分发两套不同的页面,当时也被当成聪明的权宜之计。结果实践下来,两套版本的对偶性带来的调试噩梦,远多过它解决的问题——你永远不确定爬虫看到的那套和用户看到的是不是一回事,一出问题排查起来格外费劲。Google后来基本不再推荐这条路,平行markdown版踩的是同一个坑。
还有个常被忽略的点:markdown本身对用户就不算好体验。它不支持布局,颜色、图像、排版这些能让信息更好被吸收的东西,在纯markdown里几乎没法自然融入。有MIT的研究提到,人脑差不多有一半在直接或间接处理视觉信息——这也是为什么一个排得好看、图文并茂的HTML页面,传递信息的效率往往甩纯文本一截。你为了迁就机器把这些对人有用的东西全剥掉,等于两头不讨好。
所以真要给AI单独做一份,先把这笔账掂量清楚:你不只是多写一份文件,还多扛了一份它可能在你不知情的情况下一直坏着的长期负债。能用同一个URL按需返回不同格式的,就别去维护两套互相独立的版本——少一份要操心的东西,就少一个会在背后悄悄出岔子的地方。
保哥的判断与行动建议
这不是可选的优化而是竞争必需
我的观点是:Markdown for Agents代表的不仅仅是一个CDN功能,而是Web内容交付范式的分水岭。过去我们问Google怎么看我的网站,现在需要同时问AI怎么理解我的内容。当你的竞争对手的内容还在HTML的噪声中消耗着AI系统宝贵的上下文窗口时你的内容已经以精练的Markdown格式被AI高效消化和引用。在AI搜索引用的竞争中这80%的Token节省转化为你内容被完整理解和引用的概率优势。
但要警惕滥用
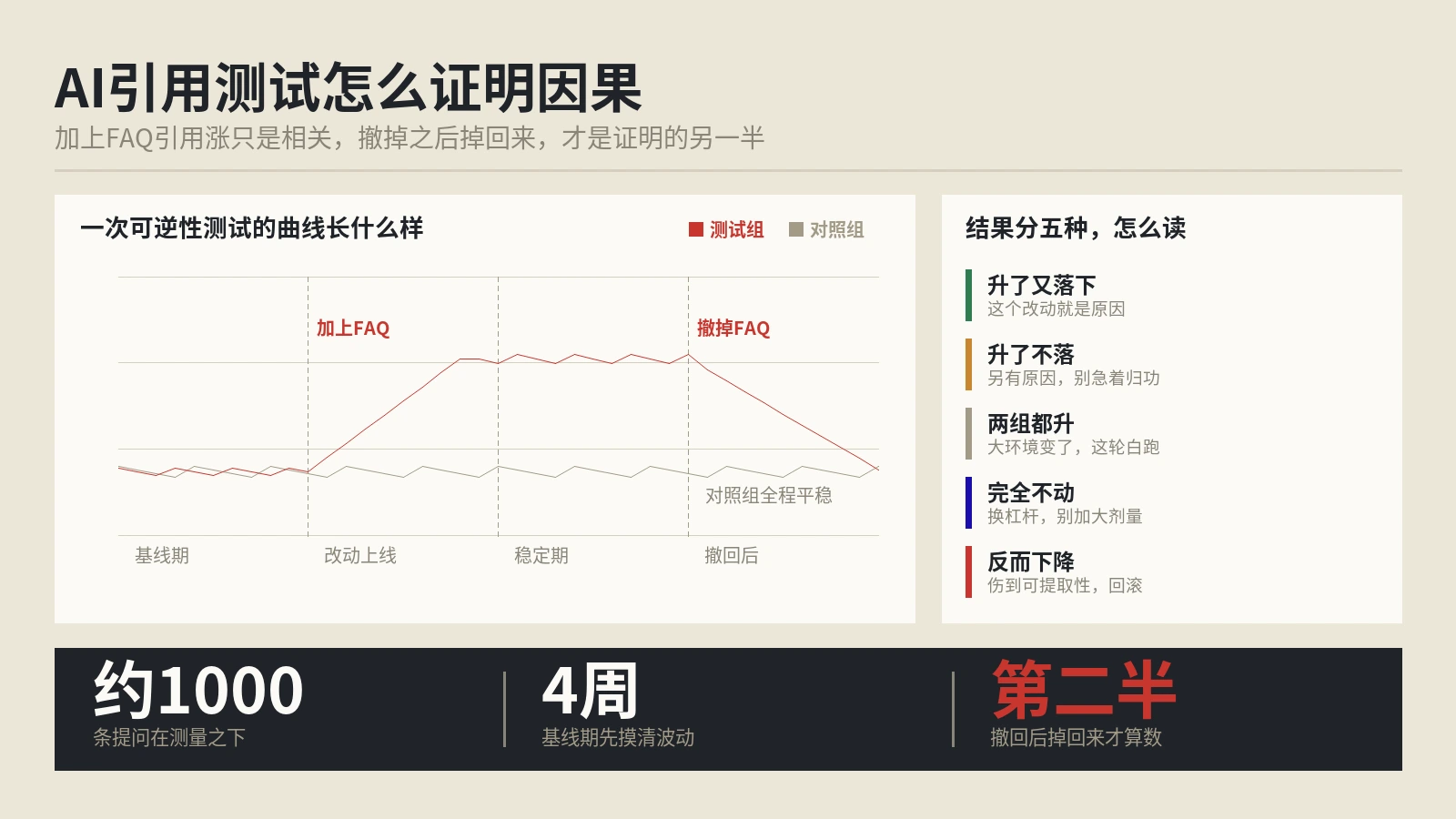
不要利用这个功能做AI Cloaking向AI系统提供与人类用户不同的内容。短期内可能获得AI引用优势但长期来看AI平台一定会发展出检测Markdown和HTML内容一致性的验证机制。建议建立自动化的CI检查流程确保HTML和Markdown输出的内容一致性,每周用脚本对核心页面做对比,差异超过5%自动告警。
行动清单
如果你使用Cloudflare(Pro及以上):
- 立即启用Markdown for Agents
- 用curl验证转换效果
- 优化HTML语义结构以提升转换质量
- 在Cloudflare Analytics中监控AI爬虫的Markdown请求量
如果你不使用Cloudflare:
- 评估是否迁移到Cloudflare(这可能是一个强有力的理由)
- 部署llms.txt作为过渡方案
- 确保网站HTML语义清晰、结构化数据完整
- 关注WordPress Markdown Alternate等独立工具
所有网站都应该做的:
- 审视你的内容在禁用CSS和JavaScript后的可读性,这接近于AI爬虫看到的原始状态
- 确保核心内容在HTML初始渲染中就已完整呈现(而非依赖JavaScript加载)
- 将GEO(生成式引擎优化)纳入你的SEO策略框架
- 持续关注Content Signals框架的演进,它可能成为AI时代的新robots.txt
常见问题解答
什么是Cloudflare Markdown for Agents?
Cloudflare Markdown for Agents是2026年2月推出的CDN边缘功能:当AI爬虫在HTTP请求头加上Accept: text/markdown时Cloudflare在边缘节点实时把HTML转换为Markdown返回。同一个URL对人类浏览器返回HTML,对AI Agent返回Markdown,基于HTTP内容协商机制实现,不创建新URL不修改内容只转换格式。Cloudflare自有博客实测Token从16180降到3150节省约80%,在AI上下文窗口寸土寸金的时代有显著优势。
它和传统robots.txt有什么区别?
robots.txt告诉爬虫能不能来,Markdown for Agents告诉爬虫来了之后用哪种格式获取内容,两者解决不同问题不互斥。配套的Content Signals框架进一步定义三维授权语义:search允许搜索索引、ai-input允许AI Agent实时输入、ai-train允许模型训练。这是从全有或全无向细粒度授权的演进,但目前所有Content Signals仍是偏好声明而非强制壁垒能否生效取决于AI平台是否遵守。
如何为我的站点启用Cloudflare Markdown?
需Pro、Business或Enterprise计划,免费版暂不支持。全站启用:Cloudflare Dashboard选账户和域名进入AI Crawl Control,找到Quick Actions开启Markdown for Agents开关。按子域名或路径启用:Rules配置规则匹配host或URI prefix再启用。API启用:调用zones content_converter PATCH接口设置value=on。启用后用curl带Accept: text/markdown请求自己页面验证响应头是否含Content-Type: text/markdown和x-markdown-tokens。
这对SEO排名有影响吗?
对传统Google SEO没有直接影响,因为Googlebot默认请求HTML且Google官方明确不偏好Markdown版本。但对GEO(生成式引擎优化)有显著正面影响:Claude Code、OpenCode、OAI-SearchBot等AI Agent已开始发送Accept: text/markdown请求,使用Markdown版本能让你的内容在AI上下文窗口里占用更少Token,被完整理解和引用的概率提升。本质上是为AI搜索的引用竞争做基础设施投资。
Token节省80%具体怎么实现?
HTML包含大量与语义无关的元素:class属性、id属性、嵌套div、CSS class名、内联style、导航栏、侧边栏、脚本标签等。Markdown只保留语义结构:标题用井号标记、列表用减号或数字、链接用方括号加圆括号、表格用管道符。Cloudflare自有博客实测一篇文章HTML 16180 token Markdown 3150 token节省13030 token约80%。微观对比:Markdown的二级标题约3个token,HTML的h2带class和id属性约12至15个token。
适合所有类型的网站吗?
最适合内容驱动型站点:博客、文档站、新闻、知识库、产品介绍页。这些站点的核心价值是文本信息,Markdown转换能干净保留主体。不适合或效果有限的:电商SKU页(产品图、规格表、价格控件复杂)、强交互应用(SaaS Dashboard、在线工具)、视频和图片为主的站点。建议先在博客和文档子域启用观察Cloudflare Radar的AI Insights数据再决定是否全站铺开。
这算AI Cloaking吗?会被搜索引擎惩罚吗?
Cloudflare的转换本身不算Cloaking:它基于HTTP Accept头的标准内容协商,与Accept-Language多语言、Accept-Encoding压缩格式逻辑一致,不创建新URL不修改内容只换格式。但风险在源服务器:Cloudflare会把Accept: text/markdown转发给源站,如果源站利用这个信号返回不同HTML(如塞SEO操纵内容)再让Cloudflare转Markdown,那就是Cloaking。Google的John Mueller已公开警告这个潜在风险,建议建立CI自动化检查保证HTML和Markdown内容完全一致。
结语
Web正在迎来它的第二层受众。第一层是人类用户,他们需要丰富的视觉设计、交互体验和品牌表达。第二层是AI系统,它们需要精练的、结构化的、Token高效的文本表达。Cloudflare的Markdown for Agents是第一个在基础设施层面系统性地满足第二层受众需求的方案。它用HTTP内容协商这个已有数十年历史的标准协议机制,巧妙地实现了同一URL双重表达的架构:无需改代码无需建新页面无需维护两套内容。在AI时代网站的效能不再仅仅是加载速度更是被AI理解的效率。越早开始优化这个维度的团队越能在即将到来的AI搜索生态重构中占据先机。
本文发布于2026年2月13日。Markdown for Agents目前处于Beta测试阶段功能细节可能随Cloudflare的迭代而变化。Content Signals框架也在持续演进中,建议关注Cloudflare官方文档获取最新信息。
权威参考资料
本文标题:《Cloudflare Markdown给AI交付内容:HTTP内容协商实操》
本文链接:https://zhangwenbao.com/cloudflare-markdown-for-agents-ai-seo-geo.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0