Cloudflare按次抓取是什么?独立站要不要向AI爬虫收费
本文目录
- Cloudflare按次抓取到底是什么?一句话能不能说清?
- 为什么Cloudflare非要搞这么个东西?
- 按次抓取在技术上是怎么跑起来的?
- Cloudflare自己当“结算方”是什么意思?
- 现在就能开通吗?AI Crawl Control和按次抓取是一回事吗?
- 有哪些路径是永远免费抓的?会不会误伤搜索引擎?
- Stack Overflow为什么第一个吃螃蟹?
- 那中国出海独立站,到底该不该开收费?
- 内容是“饵”的站,为什么千万别对AI收费?
- 什么样的站,才真正值得对AI收费?
- 拦截、放行、收费,这三元决策到底怎么选?
- 真要动手配置,有个反直觉的坑:先拦了就收不了费
- 开收费之前,你得先知道谁在抓你、抓多狠?
- 中国卖家落地,有哪些现实门槛?
- 收了费,就等于内容值钱了吗?
- 更深一层:robots“全有或全无”的时代正在结束?
- 如果你靠AI可见度获客,现在更该做的是什么?
- 给三类站的落地清单
- 常见问题解答
- Cloudflare按次抓取现在普通独立站能直接开通吗?
- 我的外贸独立站要不要给AI爬虫设收费墙?
- 开了按次抓取会不会影响Google搜索排名?
- 按次抓取用的HTTP 402到底是什么?
- 设了收费价格就一定能收到钱吗?
- 权威参考资料
摘要:Cloudflare的按次抓取(pay per crawl)把网站对AI爬虫的态度从过去“要么放、要么拦”的二选一,变成“放行、收费、拦截”三选一——AI每抓一个页面,先掏钱才给200,否则吃一个402。技术上它用HTTP 402搭一套握手协议,Cloudflare自己当结算方代收代付。但对绝大多数出海独立站来说,真正该想清楚的不是怎么开通,而是要不要开:你的内容是拿来吸引买家的“饵”,还是本身就是商品的“货”?是饵就千万别收费,否则AI抓不到你、你直接从AI答案里消失,等于亲手掐断GEO获客这条线。这篇把机制、谁该收谁不该收的决策框架、以及背后“内容开始被定价”的趋势信号,一次讲透。
2025年年中,Cloudflare抛出一个让整个内容行业都竖起耳朵的功能:让网站可以向AI爬虫收费。它给这件事起了个很有仪式感的名字,叫“内容独立日”(Content Independence Day)。一年过去,这个叫按次抓取的功能仍在私有测试,但它掀起的讨论一点没冷下来,反而随着Stack Overflow这样的大站真刀真枪上线,越来越具体。
很多做独立站、做外贸、做GEO的朋友看到新闻第一反应是:太好了,终于能管管这帮白嫖内容的AI了,我也去开一个。先别急。这个功能确实是网络历史上的一个分水岭,但它服务的对象、它的代价、它适不适合你,需要掰开揉碎看清楚。开错了,轻则白忙活,重则把自己在AI时代好不容易攒下的可见度一把清零。
Cloudflare按次抓取到底是什么?一句话能不能说清?
能。按次抓取的核心,是给网站主多了一个选项。
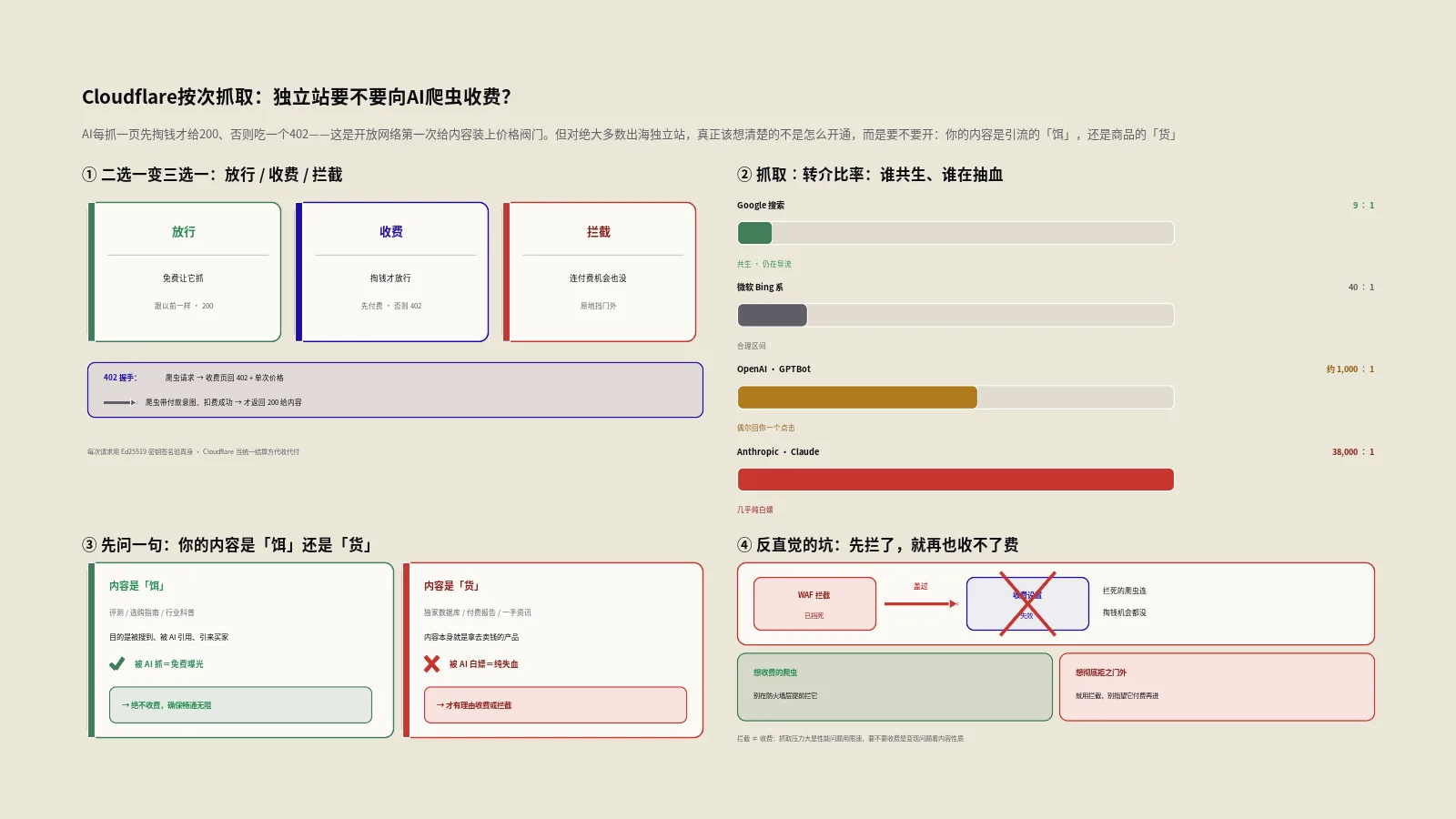
过去你面对一个AI爬虫,只有两种态度:放它进来随便抓,或者用robots.txt、防火墙把它拦在门外。这是个非黑即白的二选一。按次抓取做的事,是在中间塞进第三个选项——收费。现在对每一个AI爬虫,你都可以按官方文档给出的三种态度独立设定其一:
- 放行:免费让它抓,跟以前一样。
- 收费:它每抓一个页面,付一笔钱才放行。
- 拦截:彻底不让它进,连付费的机会都没有。
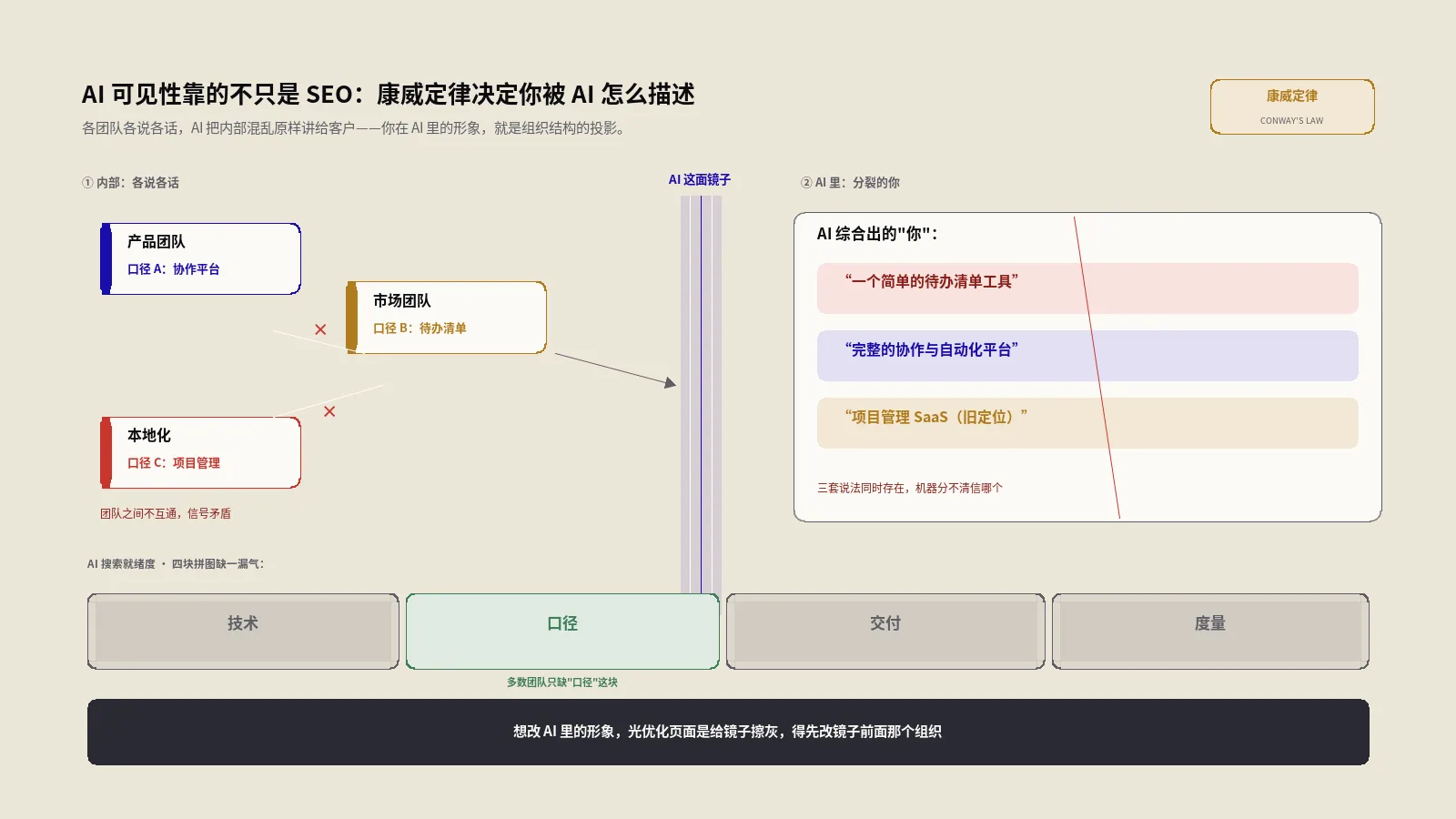
就这么简单。它不是一个让你设计复杂套餐的计费系统,而是给“开放还是封闭”这道老题,补上了一个“有偿开放”的新答案。这一点看似不起眼,却是过去三十年开放网络默认规则的一次松动——这也是为什么站内那篇讲拦AI爬虫该不该、robots加UA加WAF三层选型框架的文章,今天得升级一下:决策从两元变成了三元。
为什么Cloudflare非要搞这么个东西?
因为旧的网络交换规则,被AI爬虫单方面撕毁了。
开放网络几十年来有个心照不宣的默契:你让搜索引擎抓我的内容,搜索引擎在结果页给我导流量回来。我付出内容,换来访客,访客带来广告或成交。这是一桩双赢的买卖,所以大家默认对Googlebot敞开大门。
AI爬虫把这桩买卖的后半截砍掉了。它来抓你的内容,拿去训练模型、拿去生成答案,然后——没有然后了。用户在AI对话框里得到答案,不再点进你的网站。你付出了内容,什么都没换回来。Cloudflare用一组数据把这种失衡量化得触目惊心,他们管这个指标叫抓取与转介比率(crawl-to-refer ratio),意思是一个平台抓走多少页面,才换来一次回流访客。
这个比率的差距大到离谱。我把2025年的几个代表数字列出来,你感受一下:
| 平台 | 抓取∶转介比率(约) | 这意味着什么 |
|---|---|---|
| Google搜索 | 9∶1 | 抓9次给你1个访客,基本健康,搜索仍在给你导流 |
| 微软(Bing系) | 40∶1 | 稍高,但还在合理区间 |
| OpenAI(GPTBot) | 1,000∶1上下 | 抓上千次,才偶尔回你一个点击 |
| Anthropic(Claude) | 38,000∶1 | 年初峰值一度逼近500,000∶1,几乎是纯白嫖 |
看懂这张表,你就懂了Cloudflare为什么动手。Google抓9次还你1个人,这叫共生;Anthropic抓38,000次才漏给你一个访客,这叫单向抽血。当抽血的规模大到机器人流量开始盖过真人流量,内容方手里又没有任何议价工具时,就得有人发明一个工具出来。按次抓取就是这个工具——既然你不肯用流量回报我,那就用钱。
按次抓取在技术上是怎么跑起来的?
它复用了一个躺在HTTP协议里几十年、几乎没人用过的状态码:402 Payment Required(需要付款)。这个状态码当年就是为“这个资源要花钱”预留的,只是一直没等到合适的场景,现在终于派上用场。
整个握手过程,你可以想象成一家收门票的展馆:
- AI爬虫上门请求一个页面。如果它没带付款意图,而你这个页面设了收费,服务器直接回它一个HTTP 402,附上单次价格,意思是“想看?先买票”。
- 爬虫如果愿意付,会在请求头里带上付款意图。它可以提前用
crawler-max-price声明自己愿意出的价格上限,也可以在收到402之后,用crawler-exact-price回应确认接受这个价。 - 价格谈拢、扣费成功,服务器才返回HTTP 200把内容给它,并用
crawler-charged这个响应头确认这次收了多少钱。
为了防止有爬虫冒名顶替、假装自己是付得起钱的正规军,整套请求还用Ed25519密钥对做了签名校验,靠signature-agent这类请求头验证爬虫的真实身份。换句话说,谁来抓、抓了付没付,都有据可查、赖不掉。
这套机制最聪明的地方,是它把一件原本需要双方签合同、对账、走法务的重活,压缩成了一次HTTP请求里的几个头字段就搞定。不用一对一谈授权,AI公司和发布商各自在Cloudflare设好规则,钱就在抓取的瞬间自动结清了。
Cloudflare自己当“结算方”是什么意思?
这是按次抓取能跑通的关键,也是最容易被忽略的一环。
你想想,全世界几百万个网站,每个都想向几十个AI爬虫收费,如果让网站和AI公司两两去签合同、开发票、对账、催款,这事根本运转不起来,光是法律和财务摩擦就能把所有人拖死。Cloudflare的解法是自己跳进来当那个记录商户(Merchant of Record)——通俗说,就是夹在中间的统一收银台。
AI公司不用跟一百万个网站分别打款,只跟Cloudflare结一次账;网站也不用追着AI公司要钱,钱由Cloudflare代收再分给你。两边都只需要一个Cloudflare账号、配好支付信息,剩下的脏活累活Cloudflare全包了。这种“平台当中间人统一清算”的模式,跟Shopify、Stripe这些做支付的玩法是一个路数,也正因如此,它才有可能从一个点子变成真能跑量的生意。
现在就能开通吗?AI Crawl Control和按次抓取是一回事吗?
这里有个状态差,很多新闻没说清楚,容易让人误以为“现在人人都能开”。实情是两层:
外面那一层叫AI Crawl Control(AI抓取管控,前身是AI Audit审计工具),2025年8月底已经正式商用,所有Cloudflare付费用户都能用。它能让你看到哪些AI爬虫在抓你、抓了多少,也能一键拦截或返回自定义的402响应。光是这一层,Cloudflare的客户们平均每天就已经在对外吐出超过10亿个402响应——这个量级本身就说明,“拒绝免费抓取”已经是个相当普遍的动作了。
里面那一层,也就是真正能自动收钱的按次抓取(Pay Per Crawl),到目前为止仍是私有测试(closed beta),要申请、要排队,企业客户得联系客户经理才能进。也就是说,你今天能做的是“看清楚谁在抓、并选择拦或放”,但“自动向它收费”这一步,对大多数人还没到能一键开通的程度。
这个时间差其实是好事。它给了你一段从容期,先想清楚到底要不要收费这个战略问题,而不是被一个新按钮冲昏头立刻就按下去。
有哪些路径是永远免费抓的?会不会误伤搜索引擎?
这是开收费之前必须搞清楚的一条安全线,否则很容易把自己的自然搜索一起拦没了。给AI爬虫设收费墙和拦截搜索引擎,是必须分开处理的两件事,一旦搞混,代价不小。
Cloudflare在设计上留了几条“永远免费、谁来都能抓”的白名单路径,包括:
/robots.txt——爬虫读规则的地方,不能收费,否则连规则都读不到。/sitemap.xml——站点地图,搜索引擎的导航图。/security.txt与/.well-known/security.txt——安全联系方式。/crawlers.json——爬虫声明文件。
更重要的一点:按次抓取针对的是AI训练与推理类爬虫,不是搜索引擎的索引爬虫。Googlebot这类为传统搜索服务、并且实打实给你导流量回来的爬虫,逻辑上你不会去收它的费,反而要确保它畅通无阻。Cloudflare的数据也佐证了这个分野——Googlebot一家就占了所有可信机器人流量的四分之一以上,它产生的HTML请求量比所有AI爬虫加起来还多,但它的抓取转介比只有9∶1。对给你流量的爬虫敞开,对只抽血的爬虫收费或拦截,这才是收费功能的正确打开方式。
Stack Overflow为什么第一个吃螃蟹?
大出版商上线,账是算得过来的,这事Stack Overflow讲得很坦白。
他们的产品负责人提到,老的内容交换模式建立在一个假设上:“我开放内容,会有一大堆转介流量回来”,回流之后才有变现机会。AI爬虫把这个假设直接推翻了——内容被大量抓走拿去喂模型,回流却几乎归零,这桩共生关系单方面断了。更刺眼的是,Stack Overflow在它们的官方博客里提到,有些机器人伪装成真实用户、用无头浏览器去触发广告加载,连广告主都被骗了,等于一边白嫖内容一边还污染了广告数据。
他们的站点可靠性工程师描述上线过程时说得很轻巧:“其实挺简单,就是一个UI界面,把现成的防火墙规则包了一层。”开了之后效果也很直接——有些机器人“干脆不再往我们这儿发流量了,像是收到信号了”。对Stack Overflow这种内容本身就是核心资产、还在跟AI公司谈数据授权的大站来说,按次抓取是一张额外的、灵活的、可编程的牌,跟它们已有的大额授权合同互补。
但你要特别注意一件事:Stack Overflow的账,未必是你的账。它的内容是商品,是要拿去卖授权的“货”;而你的独立站内容,多半是另一回事。这就引出了整篇文章最该想清楚的那个问题。
那中国出海独立站,到底该不该开收费?
先别问怎么开,先问自己一句:你的内容,是拿来卖的“货”,还是拿来引流的“饵”?
这是我给所有来问按次抓取的客户的第一个问题,因为它直接决定了答案,而且两类站的答案是相反的。
大多数做独立站、做外贸、做DTC的朋友,内容是“饵”。你写产品评测、写选购指南、写行业科普,目的从来不是靠这些文章本身收钱,而是为了被搜到、被AI引用、被潜在买家看见,最终把人引到你的产品页、引出一笔成交。对这类站,AI爬虫抓走你的内容,在ChatGPT或者Perplexity的答案里带上你的品牌,本质上是在免费帮你做曝光。这是好事,不是坏事。
少数站的内容是“货”。比如卖独家市场数据的行业数据库、卖深度研究报告的付费媒体、做独家一手资讯的垂直站点——内容本身就是你拿去卖钱的产品。AI把它白嫖走,等于直接抢了你的生意。这类站,才真正有理由考虑对AI收费或者干脆拦截。
所以同一个功能,对这两类站的意义完全相反。判断你属于哪一类,比研究怎么配置重要一百倍。
内容是“饵”的站,为什么千万别对AI收费?
因为那等于亲手把自己从AI答案里删号,是一种GEO自杀。
这里藏着一个很多人没绕过来的悖论。按次抓取的逻辑是:你收费,AI不付钱,它就抓不到你的内容。问题是——你那些内容本来就是“饵”,你巴不得AI多抓、抓了之后在答案里多引用你。现在你设了收费墙,AI公司一看要花钱,大概率掉头就走(它们手里有的是免费内容可抓),结果就是你从所有AI生成的答案里消失了。
对一个靠AI可见度获客的独立站来说,这是灾难。你花了大力气做GEO、做内容,想的就是当用户问AI“最好的户外储能电源有哪些”时,你的品牌能被提到。你一收费,AI抓不到,这个位置就拱手让给了那些免费开放的竞争对手。Cloudflare那个抓取转介比率,对“货”站是抽血指标,对“饵”站却恰恰是免费曝光的渠道——你要的就是被抓。
保哥去年接触过一个做高端户外储能电源的DTC客户,技术负责人看了新闻很兴奋,问要不要给AI爬虫上收费墙。我让他先回答那个“货还是饵”的问题。他们的内容是大量的使用场景科普、露营电力方案、参数对比——全是为了把搜电源的人引到独立站来的饵。结论很清楚:不但不能收费,还得反过来确保GPTBot、ClaudeBot这些爬虫畅通无阻,让自己尽可能多地出现在AI推荐里。给“饵”收费,是把获客渠道当成收费站来经营,方向完全反了。
什么样的站,才真正值得对AI收费?
反过来,如果你符合下面这几类,对AI收费或限制才开始讲得通:
- 内容即商品的站:独家数据库、付费研究报告、行业一手资讯。内容是你直接拿去卖钱的,被白嫖就是真金白银的损失。
- 有授权谈判筹码的大站:内容规模和质量大到AI公司愿意单独跟你谈授权合同的,按次抓取能当成谈判桌上的额外杠杆——“要么按次付,要么签大单”。
- 敏感或高成本内容的特定栏目:哪怕整站是饵,某些花重金做的独家深度内容、付费会员区,也可以单独划出来设防。
保哥手上另一个客户正好是反例的反例:一家做细分工业品行情数据的B2B资讯站,每天更新一手的原材料报价和供需数据,订阅制收费。这种内容就是不折不扣的“货”,被AI抓去免费回答用户,等于砸自己饭碗。对它,限制AI抓取、甚至探索按次收费,逻辑就成立。关键还是那句话:你的内容到底靠什么变现,决定了你该敞开还是设防。
拦截、放行、收费,这三元决策到底怎么选?
把上面的判断收拢成一张可以直接抄走的决策表。过去站内讲AI爬虫,框架是“拦还是放”的二选一;按次抓取出现后,正确的框架是三选一:
| 你的情况 | 对搜索引擎爬虫 | 对AI爬虫 | 理由 |
|---|---|---|---|
| 内容是“饵”、靠GEO获客(绝大多数独立站) | 放行 | 放行 | 被AI引用=免费曝光,收费=从答案里消失 |
| 内容是“货”、靠授权或订阅变现 | 放行 | 收费或拦截 | 白嫖直接损失变现收入 |
| 整站是饵,但有个别独家付费栏目 | 放行 | 整站放行+付费栏目单独收费/拦 | 分栏目区别对待,别一刀切 |
| 被某个AI爬虫抓到服务器扛不住 | 放行 | 限速或拦截那一个 | 这是性能问题,不是变现问题,别跟收费混为一谈 |
这张表里最容易踩的坑,是把“抓取压力大”和“该不该收费”搅在一起。有的站发现某个AI爬虫抓得太凶、把服务器拖垮,第一反应是“那我收它钱”。错。抓取压力是性能和限速问题,该用限速规则解决;要不要收费是变现问题,取决于你内容的性质。两件事的处理逻辑完全不同,别混。
真要动手配置,有个反直觉的坑:先拦了就收不了费
打算亲手配置的人,这里有一条官方文档写明、却极容易踩的规则:如果你已经用Cloudflare的防火墙(WAF)或者机器人管理产品,把某个AI爬虫拦死了,那么这条拦截规则会直接盖过按次抓取的收费设置——爬虫连掏钱的机会都没有,会被原地挡在门外。
换句话说,“拦截”和“收费”是互斥的两手,不能既想拦它、又想收它的钱。逻辑上也说得通:你都把人轰出门了,还谈什么卖票。所以配置的优先级要理清楚——想收费的爬虫,别在防火墙层面提前把它拦了;想彻底拒之门外的,就用拦截,别指望它会乖乖付费再进来。这两层规则谁压谁,是真正落地时第一个容易翻车的地方,配之前一定要把已有的WAF和机器人规则捋一遍,别让它们和收费设置打架。
开收费之前,你得先知道谁在抓你、抓多狠?
不管你最后决定收不收,第一步都一样:先把家底摸清楚。你连谁在抓你、抓得有多狠都不知道,谈何决策。
AI Crawl Control这一层现在就能用,它会告诉你哪些AI爬虫造访过、各自抓了多少、占了多少带宽。这是做任何决定的事实基础。这里要特别提醒一个隐蔽的坑:有些托管主机或CDN会在你不知情的情况下,悄悄替你拦掉AI爬虫,结果你的内容在AI答案里凭空消失,自己还蒙在鼓里。站内AI引用归零监控却没报警、托管主机可能正悄悄拦AI爬虫那篇,讲的就是这种“被默认设置坑了”的情况——在你纠结要不要主动收费之前,先确认自己没在被动地误拦。
顺带说一句大盘趋势:AI爬虫的抓取量这两年涨得极猛,其中由用户实时动作触发的那类AI抓取,一年增长了15倍。站内AI爬虫抓取量已超Googlebot、SEO策略要怎么变那篇有更完整的数据。摸清自己被抓的实况,是这个时代的基本功。
中国卖家落地,有哪些现实门槛?
把预期拉回地面:对大多数中国出海卖家,按次抓取短期内更像一个要读懂的“信号”,而不是一个马上要用的“工具”。原因有几个现实门槛:
- 双边都得在Cloudflare体系内。收费要跑通,你的站要挂在Cloudflare、配好收款;AI公司那边也要接入Cloudflare的清算。这条链路目前主要在英文大站和头部AI公司之间打通。
- 它仍是私有测试。能自动收钱的那部分还没全面开放,普通独立站现阶段排不进去。
- 你大概率属于“饵”站。前面说透了,做产品、做外贸的独立站,内容是引流的饵,本来就不该收费。所以对你,这个功能的“收费”部分多半用不上,真正有用的是“看清谁在抓、并确保该抓的能抓到”这部分。
如果你用Shopify或者WordPress建站,且站点挂在Cloudflare后面,那么AI Crawl Control的观测和拦放能力你现在就能用上——但用它的目的,对绝大多数人来说是“确保AI抓得到、别被误拦”,而不是“向AI收费”。把这个主次搞反,是这一波最常见的认知错位。
收了费,就等于内容值钱了吗?
这是要泼的一盆冷水。设置一个收费价格,和这个价格真有AI公司愿意付,是两码事。
按次抓取目前要求发布商设一个全站统一的单次请求价格。你当然可以把价标得很高,但标价不等于成交。AI公司手里有海量免费内容可抓,只有当你的内容独家到、稀缺到它不抓不行时,它才会乖乖付钱。对绝大多数内容并不独家的站,设了收费墙的真实结果不是“躺着收钱”,而是“AI掉头去抓别人,你颗粒无收还丢了曝光”。
换句话说,按次抓取不是一台印钞机,它只是给“本来就值钱的内容”补上了一个收钱的通道。内容值不值钱这件事,在你设价之前就已经定了,收费功能改变不了它,只能反映它。想清楚这一点,能帮你避开“以为开了收费就有被动收入”的幻觉。
更深一层:robots“全有或全无”的时代正在结束?
跳出收费这件具体的事,按次抓取真正值得品味的,是它背后那个更大的信号:网络内容正在从“免费开放”走向“按价计量”。
过去二十多年,网站对爬虫的控制工具粗糙得可怜。robots.txt本质上是个“全有或全无”的开关——要么允许,要么禁止,没有中间地带,而且它还只是一个君子协定,爬虫想无视就能无视。我在写微软Web IQ给AI代理的Bing接地接口那篇时也聊过,这种“全有或全无”的粗糙开关,在AI又抓内容又不给流量的新格局下,已经明显不够用了。
按次抓取代表的方向,是给内容装上一个“价格阀门”——不再是开或关的二元,而是可以定价、可以计量、可以按需谈的连续光谱。配合业界正在推的各种机器对机器支付协议,未来很可能出现这样的局面:你的每一篇内容对每一个AI代理,都带着一个可被机器读取、机器协商、机器结算的价格标签。内容第一次有了在机器世界里被明码标价的可能。
支撑这个方向的,是两块正在成形的底层拼图。一块是爬虫身份的密码学验证——前面提到按次抓取用Ed25519密钥对给每次请求签名,本质上是在给机器人发“可验证的身份证”,让“谁来抓的”从靠不住的UA字符串,变成赖不掉的密码学事实。另一块是HTTP 402这个沉睡多年的状态码被重新激活,一旦它成为内容方和AI代理之间“要付费”的通用暗号,就有可能从Cloudflare一家的玩法,长成跨平台的行业约定。身份能验证、价格能协商、扣费能自动,三块拼到一起,机器之间为内容付费这件事才真正具备了基础设施。
对内容方而言,这是议价权的回归。哪怕你今天用不上收费,理解“内容开始被定价”这个趋势,也会改变你对自己内容资产的看法——它不再只是引流的工具,在某些场景下,它本身就是有市场价格的资产。
如果你靠AI可见度获客,现在更该做的是什么?
对绝大多数读到这里的独立站主,结论可能和你点开标题时的预期正好相反:你现在该操心的不是怎么向AI收费,而是怎么确保AI抓得到你、并且愿意引用你。
方向反过来之后,待办清单也跟着变:
- 先用抓取管控工具盘一遍,确认GPTBot、ClaudeBot、PerplexityBot这些AI爬虫没被你的主机或CDN默默拦掉。
- 检查robots.txt,别在不经意间把AI爬虫一刀切禁了——除非你非常确定自己是“货”站。
- 把精力放在让内容更容易被AI抓取、理解、引用上:结构清晰、事实明确、有独到观点,这些才是AI时代真正给你带来可见度的东西。
- 持续监控你在主流AI答案里的出现频率,把它当成和搜索排名一样重要的指标来盯。
按次抓取是一个为“内容即商品”的少数玩家准备的工具。对靠内容引流、靠AI曝光获客的大多数人,它最大的价值是当一面镜子,照出一个事实:AI正在大规模消费你的内容,而你得想清楚,你是要为这种消费收钱,还是要拥抱它带来的可见度。对前者,收费;对后者——也就是你——拥抱,别设墙。
给三类站的落地清单
最后,把整篇收拢成一份可以直接对号入座的清单:
- 如果你是“饵”站(绝大多数独立站、外贸站、DTC):别碰收费。用AI Crawl Control确认AI爬虫畅通、没被误拦;robots.txt对AI保持开放;把资源投在让内容更易被AI引用上。你要的是曝光,不是抓取费。
- 如果你是“货”站(数据库、付费研究、独家资讯):可以认真评估。先用监控看清谁在抓、抓多狠,再决定对AI爬虫是拦截、还是排队等按次收费的测试资格;同时别忘了大额授权合同可能比按次收费更划算。
- 如果你是“灰色”站(整站引流但有独家栏目):分栏目区别对待。引流内容继续敞开喂给AI,独家付费栏目单独设防,别一刀切。
无论哪一类,第一步都是同一个:先看清谁在抓你。在你对任何AI爬虫做出“拦、放、收”的决定之前,把家底摸清楚,永远不会错。
常见问题解答
Cloudflare按次抓取现在普通独立站能直接开通吗?
不能直接开通收费。外层的AI Crawl Control(观测+拦放)已经正式商用,所有Cloudflare付费用户都能用;但真正能自动向AI收费的按次抓取,目前仍是私有测试,需要申请排队,企业客户得联系客户经理。所以你现在能做的是“看清谁在抓、并选择拦或放”,自动收费这一步对大多数人还没开放。
我的外贸独立站要不要给AI爬虫设收费墙?
绝大多数情况下不要。外贸和DTC独立站的内容是用来引流获客的“饵”,被AI抓走、在答案里引用你的品牌,等于免费曝光。一旦设收费墙,AI大概率掉头去抓免费内容,你就从AI答案里消失了,等于亲手切断GEO获客。只有当内容本身是你拿去卖钱的商品时,收费才讲得通。
开了按次抓取会不会影响Google搜索排名?
逻辑上不会,前提是你配置正确。按次抓取针对的是AI训练和推理类爬虫,不是搜索引擎索引爬虫;robots.txt、sitemap.xml等关键路径被设计成永远免费抓取。Googlebot这类给你导流量的爬虫,你本来就应该放行而不是收费。但配置时务必把搜索爬虫和AI爬虫分开对待,别误把Googlebot也拦了。
按次抓取用的HTTP 402到底是什么?
402是HTTP协议里一个早就预留、却几乎没被用过的状态码,含义是“需要付款”。在按次抓取里,当AI爬虫请求一个收费页面又没带付款意图时,服务器就回它一个402并附上价格;爬虫确认付费后,扣款成功才返回200把内容给它。Cloudflare当中间的统一结算方代收代付,让这套收费在一次HTTP请求里就能自动完成。
设了收费价格就一定能收到钱吗?
不一定。标价不等于成交。AI公司手里有海量免费内容可抓,只有你的内容足够独家、稀缺,它才会愿意付费。对内容并不独家的站,设收费墙的真实结果往往是AI掉头抓别人、你既没收到钱又丢了曝光。收费功能只是给本来就值钱的内容补一个收钱通道,改变不了内容本身值不值钱。
权威参考资料
本文标题:《Cloudflare按次抓取是什么?独立站要不要向AI爬虫收费》
本文链接:https://zhangwenbao.com/cloudflare-pay-per-crawl-charge-ai-bots.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0