微软Web IQ是什么?给AI代理的Bing接地接口对SEO意味着什么
本文目录
- Web IQ到底是什么?一句话先说清
- 为什么微软挑这个时间点推Web IQ?
- Web IQ和你熟的Bing搜索API有什么不一样?
- 那几个性能数字该怎么读?
- 谁已经在用Web IQ?为什么这才是关键?
- 这对做SEO和GEO的人到底意味着什么?
- 为什么说"别只盯Google,Bing又重要起来了"?
- Web IQ和Google的接地方案比,差在哪?
- AI代理搜索和人搜索,差在哪?
- 段落被抽走却不带点击,是不是又一个"零点击"?
- robots.txt是你唯一的控制开关吗?
- 该不该屏蔽Web IQ和Bingbot?一张决策表
- 怎么让内容更容易被段落抽取?一份可抄的清单
- 一段不好抽的内容,怎么改成好抽的?
- 段落优化和传统排名优化,是一回事吗?
- "结构化证据对象"到底意味着什么?
- 出海做GEO,Web IQ改变了动作清单吗?
- 哪些生意该现在就动,哪些可以再等?
- 怎么知道Bing语料有没有在引用你?
- Web IQ之外,AI抓取的付费和标准化在往哪走?
- 关于Web IQ,最容易踩的三个误判
- 现在就能落地的清单
- 常见问题解答
- 权威参考资料
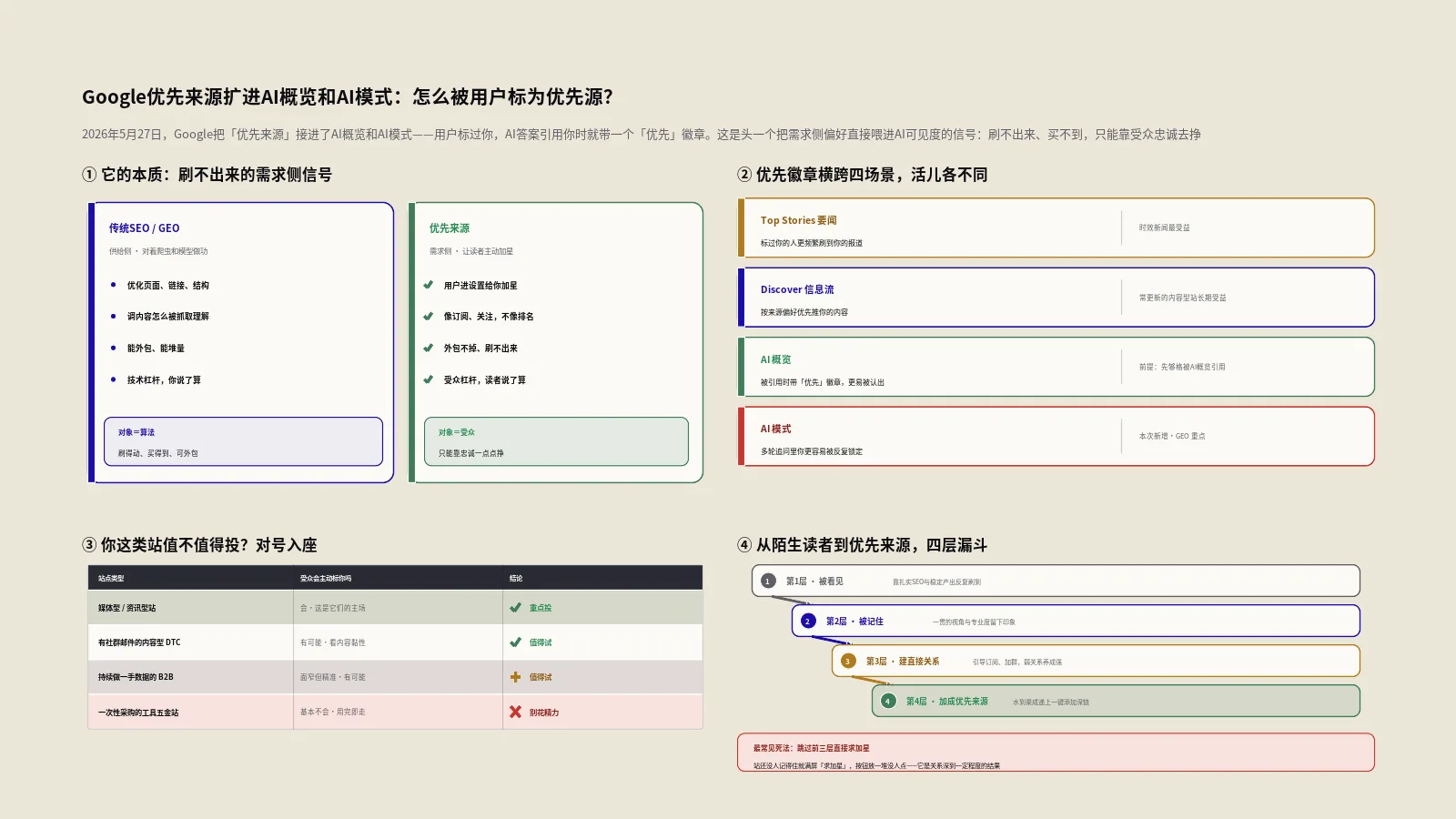
摘要:微软在Build 2026上放出了Web IQ——一套专门喂给AI代理的接地(grounding)接口,背后是Bing的全球索引。它不返回十条蓝色链接,而是直接吐出"段落+结构化证据对象",95%的请求快过165毫秒。关键不在参数,而在Copilot、ChatGPT这些AI已经在用它当事实底座。对做SEO和出海GEO的人来说,这意味着三件事:Bing又重要起来了、内容被抽走却不一定带回点击、robots.txt成了你几乎唯一的开关。本文把Web IQ拆给你看清楚,再给一份能直接抄的段落可抽取性清单、一个改写示范和一张屏蔽决策表。
2026年6月2日,微软在Build大会上官宣了一个名字有点拗口的东西:Web IQ。媒体标题大多是"给AI代理的搜索引擎""Bing驱动的接地接口"。听上去像是又一个开发者才关心的API升级,跟天天盯关键词排名的我们没什么关系。
但保哥盯着官方博客和几家外媒来回读了几遍,越读越觉得这事不该被划到"技术新闻"那一栏。它动的是一个很基础的东西:AI到底从哪里、以什么形式,拿到它回答问题时引用的那些事实。而你的内容,正好就是那些事实的来源之一。
这篇不堆参数,只回答一个问题——Web IQ出现之后,做SEO、做GEO、做出海独立站的人,动作清单要不要改,怎么改。
Web IQ到底是什么?一句话先说清
据微软Bing搜索博客的官方公告,Web IQ是一套"接地接口"(grounding API),作用是把AI系统和AI代理连到鲜活的网络信息上——网页、新闻、图片、视频都在内。它的底座是Bing的全球索引和整套生态。
"接地"这个词是AI圈的行话,英文叫grounding。意思是:大模型本身只有训练时那点旧记忆,要回答"今天发生了什么""这家公司最新报价多少",就得临时去外部捞真实信息,把答案"锚"在事实上,免得张口就编。Web IQ干的就是这个捞信息的活。
换个生活里的比方。大模型像一个记性很好但已经闭关三个月的专家,你问他今天的事他答不上来。接地接口就是塞给他的那叠当日报纸摘要——他不用自己跑出去翻遍整个图书馆,有人把相关段落剪好递到手边。Web IQ就是微软做的那个"剪报+递送"系统,而报纸库用的是Bing。
为什么微软挑这个时间点推Web IQ?
因为搜索的"用户"变了。过去搜索框后面坐的是人,人会看排名、会点链接、会在结果页上扫一眼再决定进哪个站。现在越来越多的搜索请求,后面坐的是AI代理——它替人去查、去比、去汇总,自己读完就把结论端给用户。
代理搜索和人搜索的习惯完全不同。人一次搜一个词,代理可能为一个任务连着搜五六次;人要的是一页排好序的结果,代理要的是能直接塞进推理过程的事实碎片;人会被第一名吸引,代理只挑对当前问题最有用的那几段。
传统的搜索API是按"给人看"的逻辑设计的——返回标题、摘要、链接,等着人去点。喂给AI时,模型得把整页抓下来、读完、再自己提炼,又慢又费token。微软的判断是:与其让每个AI自己折腾,不如官方做一个专为机器优化的入口。Web IQ就是这个押注。
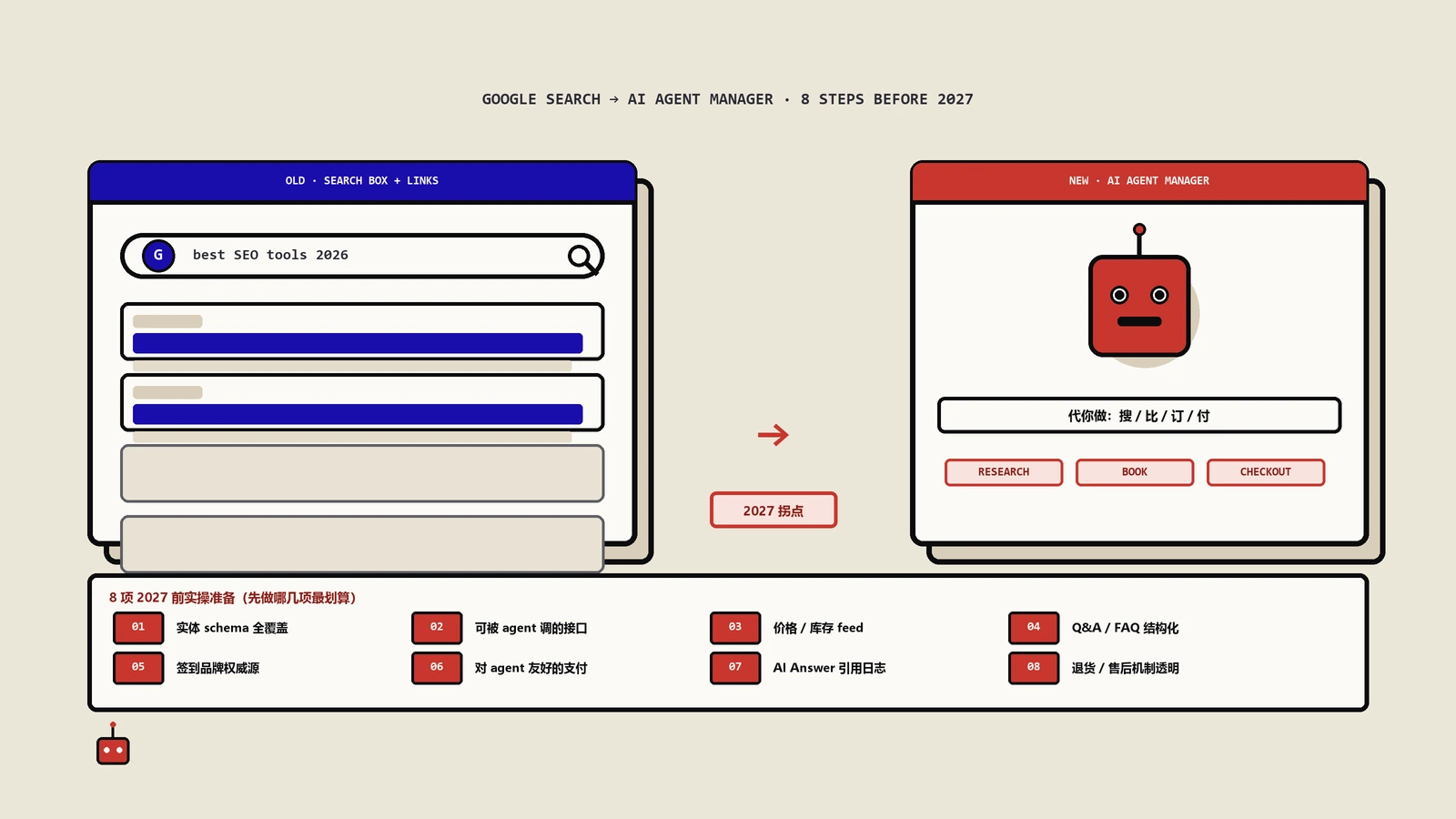
Web IQ和你熟的Bing搜索API有什么不一样?
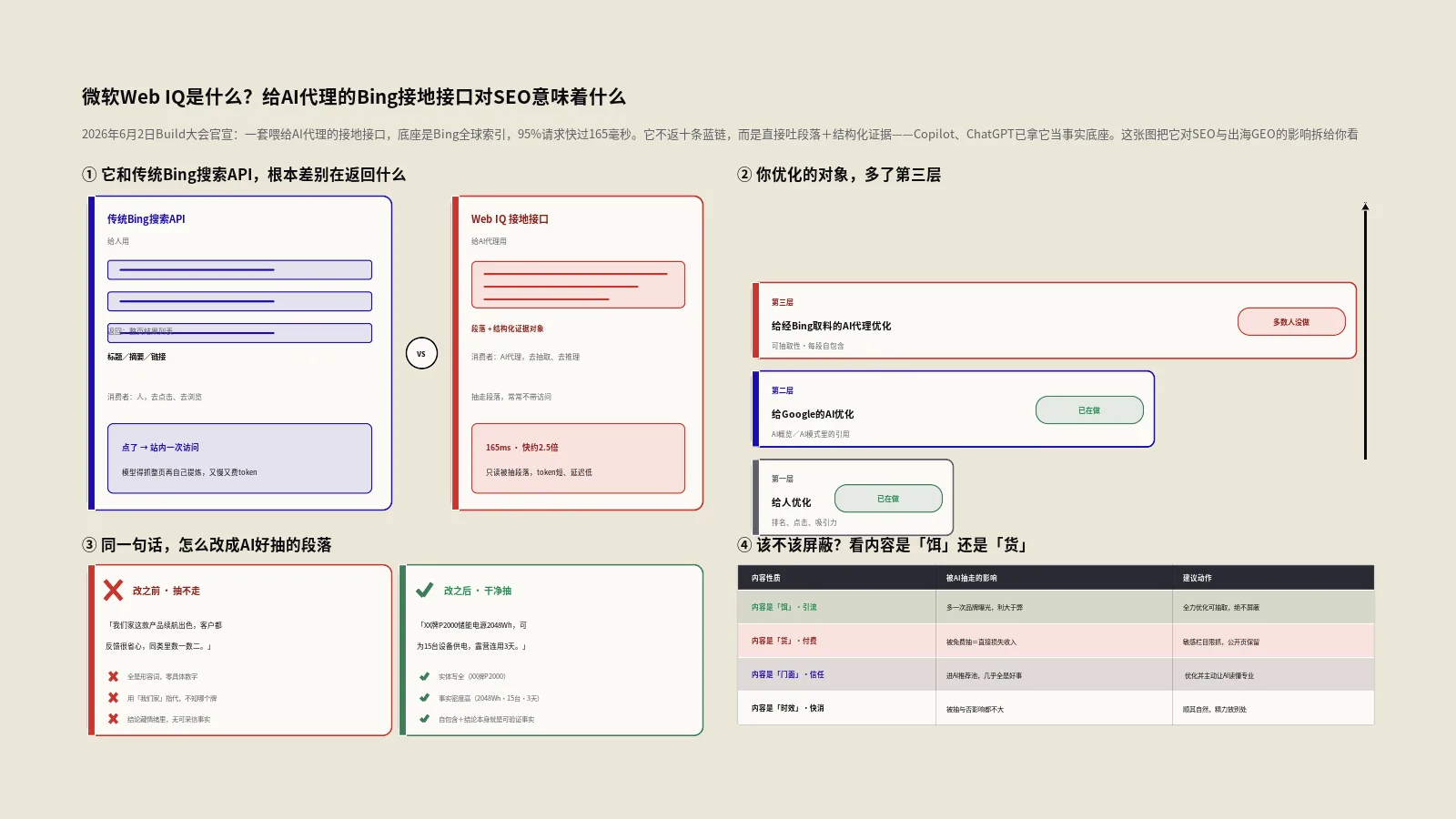
最核心的差别是返回的东西。传统Bing搜索API给你的是一排结果链接,Web IQ给的是"段落+结构化证据对象"——它不让AI去读整篇文章,而是直接把最相关的那几段抽出来,连同结构化的事实一起递过去。
这一下子改了两个成本。一个是token成本:模型不用吞整页,只读被抽出来的段落,输入短了,单次调用便宜了。一个是延迟:少读东西自然快。微软给的数字是95%的请求在165毫秒内返回,比次优的方案快大约2.5倍。
下面这张表把两者摆在一起,差别就清楚了。
| 维度 | 传统Bing搜索API(给人用) | Web IQ接地接口(给AI代理用) |
|---|---|---|
| 返回单位 | 整页结果列表(标题/摘要/链接) | 段落+结构化证据对象 |
| 消费者 | 人,去点击、去浏览 | AI代理,去抽取、去推理 |
| 优化目标 | 排名靠前、吸引点击 | 信息密度高、token成本低 |
| 是否产生访问 | 点了就有一次站内访问 | 抽走段落,常常不带访问 |
| 典型场景 | 搜索结果页、网站内搜 | Copilot、ChatGPT等回答问题时取证 |
看最后两行就够了。这不是一次性能升级,而是把"被搜索"这件事,从"等人来点"悄悄换成了"被机器抽段落"。这个换法,恰恰是后面所有问题的根。
那几个性能数字该怎么读?
官方那串参数很唬人:165毫秒、2.5倍、5个数据中心(West US2、North Central US、East US2、North Europe、South Korea)、用上了DiskANN做大规模向量检索、用GDSAT这个内部指标衡量接地满意度。看着像军备竞赛。
但对我们做内容的人,这些数字的真正含义只有一句话:微软把"给AI供料"这件事,当成一门要拼速度和成本的正经生意来做了。速度做到极致、token压到最省,目的就是让各家AI觉得"用Web IQ比自己抓网页划算",从而把它变成默认的取料口。
一旦它成了默认取料口,问题就回到你头上:你的内容在不在这个料库里、被抽出来的是哪几段、抽走之后你拿不拿得到回报。参数是微软的事,这三问才是你的事。所以别被165毫秒晃了眼,往下看。
谁已经在用Web IQ?为什么这才是关键?
据外媒报道,Web IQ目前已经在被微软自家的Copilot、OpenAI的ChatGPT以及其他大模型平台使用。这句话轻飘飘,分量却很重。
它意味着:当用户在ChatGPT里问"哪个品牌的户外储能电源续航最好",ChatGPT去捞事实的那一下,背后很可能就是Web IQ、就是Bing索引。换句话说,你能不能进AI的答案,有一部分由Bing决定,而不全是Google。
这恰好印证了一个老观察。保哥早就在ChatGPT品牌推荐机制的实测里发现,ChatGPT给的品牌推荐和Bing的自然排名高度相关——同一批关键词,Bing前排的品牌更容易被ChatGPT点名。当时还有人觉得是巧合,Web IQ这一官宣,等于把这条暗线摆到了明面:Bing就是相当一批AI的事实底座。
这对做SEO和GEO的人到底意味着什么?
意味着你优化的对象,多了一层。过去是两层:给人优化(排名、点击)、给Google的AI优化(AI概览、AI模式里的引用)。现在要加上第三层——给经由Bing取料的AI代理优化。
这三层不是平行世界,会互相借力,但侧重点不同。给人优化看的是吸引力,给AI代理优化看的是"可抽取性"——你的内容能不能被干净利落地切成一段自包含的事实,递给模型。一篇排名很好、但每段都要联系上下文才看得懂的文章,对人友好,对抽段落的机器却不友好。
残酷的地方在于:这一层你大概率还没专门做过,而它正在被越来越多的AI默默调用。这不是要不要做的问题,是你已经在被打分,只是没看过分数。
为什么说"别只盯Google,Bing又重要起来了"?
很多做出海的朋友,多年来对Bing的态度是"那个市场份额零头、可以忽略的第二搜索引擎"。流量角度,这个判断没大错。但Web IQ把账重算了一遍——Bing的价值不再只看它自己导来多少流量,而要看有多少AI拿它当料库。
这就是"一处优化、喂多家AI"的杠杆。你把内容在Bing索引里弄干净、弄齐整,受益的不只是Bing搜索那点份额,而是所有经由Bing取料的AI代理。在Bing SEO完整指南里反复讲过"别忽略Bing",过去的理由是Bing用户购买力不差、竞争小,现在多了一条更硬的理由:它是AI的后厨。
最起码的动作:去Bing Webmaster Tools把站验证了、把站点地图提交了、把抓取异常清了。这是地基活,很多人连这步都没做,就别谈被AI引用了。
Web IQ和Google的接地方案比,差在哪?
有人会问:Google不也在做接地吗?没错。Gemini通过Google Search做接地取料,Vertex AI那边也有"用Google搜索接地"的能力。两大阵营其实在干同一件事——把自家的搜索索引,改造成喂给AI的事实库。区别在于你和它们的距离。
| 维度 | Google接地(Gemini/Vertex AI) | 微软Web IQ |
|---|---|---|
| 索引来源 | Google Search索引 | Bing全球索引 |
| 你做了没 | 做传统Google SEO就有机会进 | 多数人连Bing收录都没做全 |
| 竞争程度 | 挤,所有同行都在抢 | 洼地,很多人还没反应过来 |
| 调用方 | Gemini及Google系AI | Copilot、ChatGPT等多家 |
| 你要补的动作 | 维持Google SEO+结构化数据 | 补全Bing收录+段落可抽取性 |
这张表里藏着一个机会。Google那一侧你多半已经在做——只要你认真做Google SEO,进了Google索引,就有机会被Gemini引用,但那条路上挤满了人。Bing这一侧不一样:被ChatGPT、Copilot当料库,门槛却低得多,因为大量同行压根没把Bing当回事,连收录都不全。
洼地的意思是,同样一份力气,在Bing侧的边际回报更高。当所有人都在Google那边卷生卷死时,把Bing索引这块没人抢的地认真种一遍,是性价比最高的动作。两边索引都要进,但现阶段该多分点注意力给被低估的那一侧。
AI代理搜索和人搜索,差在哪?
这个差别值得单独掰开,因为它决定了你内容该长成什么样。这一点其实挺直接:代理和人用的根本不是同一种搜索方式。人搜索是"逛",代理搜索是"取"。
人会逛:搜一个词,扫一眼结果页,点进去读一会,不满意退出来再点下一个,过程里你的导航、你的相关推荐、你的品牌氛围都在悄悄起作用。代理不逛:它带着一个明确的子问题来,捞到能回答它的那一段就走,多余的一概不看,更不会顺手记住你是谁。
这就引出一个让人不太舒服的事实:代理可能反复"路过"你的内容、用你的段落拼出了答案,但从头到尾没在你的服务器上留下一次像样的访问。你被用了,却感觉不到。关于AI代理怎么感知和读取网站,AI代理网站适配实战里有更细的拆解,这里只点出结论:为代理优化,要把每一段都当成可能被单独拎走的零件来写。
段落被抽走却不带点击,是不是又一个"零点击"?
是,而且是更彻底的那种。零点击搜索好歹还在搜索结果页上露个脸,用户扫到你的标题、记住你的品牌。段落被抽进AI答案,连露脸的机会都常常没有——用户看到的是一段流畅的回答,未必知道这句话是从你这儿来的。
这跟上一篇讲的GSC生成式AI性能报告是同一个张力的两面。Google那边给你看曝光、不给点击;微软这边的Web IQ连曝光报告都还没有,你的段落被抽了多少次、喂给了谁,目前基本是黑箱。
所以衡量逻辑得换。还盯着"AI带来多少直接点击",你会得出"白干了"的丧气结论。该盯的是间接信号:品牌词搜索量有没有涨、AI回答里你的品牌被提及的频次、被点名后用户绕回来的转化。这套替身衡量法,是AI时代不被数字吓退的必修课。
robots.txt是你唯一的控制开关吗?
差不多是。Web IQ官方明说,它遵守robots.txt的排除规则,以及Bing本来就尊重的发布者偏好。这话听着体面,落到操作上却很骨感——你能做的,基本就是"允许Bingbot抓"或"禁止Bingbot抓"两档,没有"允许抓但不许喂给AI"这种精细档位。
根据Bing官方关于爬虫的说明文档,Bing用同一个Bingbot既做传统搜索抓取、也做AI相关的取料。这就尴尬了:你要是为了不被AI抽段落而封了Bingbot,连Bing的自然搜索可见度也一起没了,杀敌一千自损八百。
有人会想到用nosnippet、max-snippet这类meta标签限制摘要长度。但那是连传统搜索的摘要也一起砍,同样是双输。真正"只屏蔽AI、不伤自然搜索"的干净开关,目前在Bing这边还不存在——这也是微软说在和IETF一起推标准的原因,行业还在补这块。
该不该屏蔽Web IQ和Bingbot?一张决策表
既然只有"全允许"和"全屏蔽"两档,决策就得想清楚:你的内容,是用来当饵的,还是本身就是货?
| 你的内容性质 | 典型站点 | 被AI抽走的影响 | 建议动作 |
|---|---|---|---|
| 内容是"饵",目的是引出后续转化 | 独立站博客、品牌科普、产品故事 | 被引用=多一次品牌曝光,利大于弊 | 全力优化可抽取性,绝不屏蔽 |
| 内容是"货",本身就是付费产品 | 付费报告站、专业数据库、会员课 | 被免费抽走=直接损失收入 | 考虑对敏感栏目限制抓取,公开页保留 |
| 内容是"门面",主要靠它建立信任 | B2B工业品、专业服务 | 被引用=进入AI推荐池,几乎全是好事 | 优化并主动让AI读懂你的专业 |
| 内容是"快消时效",过期就没价值 | 促销页、活动页 | 被抽与否影响都不大 | 顺其自然,把精力放别处 |
保哥手上有两类客户正好是两端。一家做高端户外储能电源的DTC,内容全是使用场景和续航实测——这种内容就是饵,被ChatGPT经Bing引用一次,等于在用户做选型时多一次露脸,求之不得,谈何屏蔽。
另一家做行业付费数据库,核心报告本身就是卖钱的货。这家就得拆开看:公开的方法论介绍、行业科普该敞开让AI抓,当引流的饵;而藏在付费墙后的具体数据,本就不该让任何爬虫碰到。屏蔽的边界,跟着"饵还是货"走,而不是一刀切。
怎么让内容更容易被段落抽取?一份可抄的清单
既然代理是来"取段落"的,你的活就是把段落做得好取。下面这几条是保哥团队内部在用的可抽取性自查表,每条都能直接对着你的文章改。
- 结论前置:每一段第一句就把核心事实说完,别让模型读到第三句才明白你在讲什么。前置结论的段落,被干净抽走的概率高得多。
- 段落自包含:一段话单独拎出来也能看懂,不依赖上一段的"它""这个""上述"。代理不读上下文,指代不清的段落等于废段。
- 事实密度高:一段里塞进具体的数字、名称、条件,而不是一堆形容词。"续航72小时、支持15台设备同时供电"比"续航超强"好抽一百倍。
- 实体写明白:品牌名、产品名、规格型号都写全称,别用"我们的旗舰款"这种只有你懂的代称。模型靠实体把事实挂到你名下。
- 一段一个意思:别把三个论点塞进一个长段。能拆就拆,每段对应一个可能被单独引用的事实点。
- 结构化标注:该用表格的用表格,该用列表的用列表,关键事实配上Schema结构化数据。结构清晰的内容,更容易被解析成"结构化证据对象"。
这份清单的底层逻辑,跟一贯讲的"机器优先架构"是一脉相承的:先让机器读得懂、抽得干净,人读着也不会差。两头讨好,没有取舍。
一段不好抽的内容,怎么改成好抽的?
清单看着简单,落到手上常常不知道怎么动。给你一个真实的改写示范,就拿户外储能电源那条产品介绍开刀。
改之前,很多人会这么写:"我们家的这款产品在续航方面表现非常出色,很多客户都反馈说用起来特别省心,尤其是在户外的时候,完全不用担心电量问题,可以说是同类里数一数二的了。"读着挺顺口,对吧?但对抽段落的机器来说,这是一段废话。
问题出在四处:没有一个具体数字,全是"出色""省心""数一数二"这种形容词;用"我们家的这款产品"指代,模型不知道说的是哪个牌子哪个型号;结论藏在情绪里,没有可被采信的事实;单独拎出来,谁也不知道在讲什么。这样的段落,代理捞一眼就划走了。
改之后,按清单逐条对齐:"XX牌P2000户外储能电源容量2048Wh,满电可为15台设备同时供电,在无市电的露营场景下连续使用3天无需补电,工作温度范围零下20度到40度。"实体写全了(XX牌P2000),事实密度上来了(2048Wh、15台、3天、温度区间),自包含了(不依赖上文也看得懂),结论本身就是可验证的事实。
两段表达的是同一个意思,但后一段被AI干净抽走、原样引用的概率,是前一段的好几倍。改写不是把话说得更花哨,恰恰相反,是把形容词换成事实、把"我们家"换成全称、把结论提到最前面。这活儿不难,难在习惯——大多数产品文案,至今还在写第一种。
段落优化和传统排名优化,是一回事吗?
有重叠,但不是一回事,这点必须说清,免得你以为排名做好了就万事大吉。
传统排名优化,优化的是"整页"在某个关键词下的综合得分——标题、外链、整体相关性、用户体验,是一盘整棋。段落抽取优化,优化的是"每一段"作为独立事实单元的质量——能不能被精准定位、干净切出、可靠归因。一篇整体排名第三、但段落写得稀烂的文章,在传统搜索里照样有流量,在代理取料里却可能颗粒无收。
反过来也成立:一篇排名平平、但每段都是结论前置、事实扎实的实操文,可能在AI答案里被反复引用。微软自己也暗示了这点——对AI接地有用的段落,和传统搜索排名靠前的内容,未必是同一批。这就是为什么要把段落优化当成单独一层来做。
"结构化证据对象"到底意味着什么?
Web IQ返回的不只是文字段落,还有"结构化证据对象"。普通人不用纠结这个术语的技术实现,但要懂它背后的信号:微软在鼓励内容把事实结构化地暴露出来。
翻译成动作就是:能用Schema标记的就标记。产品页打上Product结构化数据,把价格、库存、评分写明白;文章里的关键事实,用清晰的表格和列表承载;企业信息、作者信息、组织信息,都用对应的Schema类型标注清楚。
这里还藏着官方那个GDSAT指标的潜台词。它衡量的是接地的"满意度"——说白了,模型更愿意采信哪些事实。含糊其辞、无从核对的内容,满意度低,容易被跳过;写得明确、能交叉验证的内容,满意度高,才会被采纳。
所以让事实"可验证"是一门划算的功夫:给数据标上来源和时间("据某机构2026年报告"),把关键结论挂到具体出处,让模型能交叉印证。一句能被对照核实的事实,比十句漂亮的空话更容易被AI采信。事实密度和可验证性,是接地时代的硬通货。
出海做GEO,Web IQ改变了动作清单吗?
改了几处,但不是推倒重来,更像是在原来的清单上补了几栏。把改动整理成下面这张对照表,左边是过去的做法,右边是Web IQ之后要补的动作。
| 环节 | 过去的做法 | Web IQ之后要补的动作 |
|---|---|---|
| 搜索引擎覆盖 | 主攻Google,Bing顺带 | 认真做Bing索引收录,它是AI后厨 |
| 内容结构 | 面向人写,注重可读性 | 加一层段落可抽取性,每段自包含 |
| 结构化数据 | 有就好,主要给富媒体摘要 | 当成给AI的证据,认真铺全 |
| 效果衡量 | 看排名、看点击、看转化 | 补品牌提及频次、AI引用、间接转化 |
| 抓取控制 | 默认全放开 | 按"饵还是货"重新判断该不该屏蔽 |
注意,这张表里没有一条是"为了Web IQ去搞个什么特殊文件"。这点很重要——Web IQ吃的是正常的网页和正常的Bing收录,不需要你额外伺候一份只给机器看的文件。把基本功做扎实,比追新名词管用。
哪些生意该现在就动,哪些可以再等?
不是每个站都要连夜重做内容。判断该不该现在投入,有一条很简单的标准:你的用户在掏钱之前,会不会先去问AI?
会问的,现在就该动。出海消费品、专业服务、B2B工业品、SaaS工具、知识和咨询类——这些领域用户做决策前习惯先问ChatGPT"哪个好""怎么选",AI答案里有没有你,直接影响进不进候选名单。这类生意,段落可抽取性和Bing收录的回报最高,越早占位越划算。
可以缓一缓的,是另一类:纯交易型、本地刚需、用户直接搜品牌名进站的强品牌直达,以及超低客单的冲动消费。这些场景里,用户要么不问AI,要么问了也不影响成交,把精力先放在转化本身更实在。
但有个趋势得认清:会先问AI的用户只会越来越多,今天还属于"可以缓"的生意,明年可能就被推到"必须动"那一栏。缓,不等于不看;至少先把Bing收录这类地基补上,等风来的时候才不至于手忙脚乱。
怎么知道Bing语料有没有在引用你?
这是最让人抓狂的部分:Web IQ目前没有官方的引用报告,你没法像看GSC那样看到"你被抽了多少次"。但黑箱不等于完全无解,我用的是三个间接办法。
第一,去Bing Webmaster Tools看表现数据。微软已经在Webmaster工具里加了AI维度的数据面板,虽然不如传统报告细,但能看出你的内容在Bing生态里的抓取和活跃情况。先把"页面"和"搜索关键词"两块的趋势盯住,异常掉量往往是被降权或抓取出了问题的信号。
第二,做实测prompt。固定一批和你业务相关的问题,定期去ChatGPT、Copilot里问,看回答里有没有点到你的品牌、有没有引用你的观点或数字。这是最直接的"用户视角"验证,比任何后台数据都真实,建议每两周跑一轮、记成表格看变化。
第三,盯品牌词搜索量。如果你的内容在AI答案里被频繁引用,会有一部分用户记住品牌、绕回来搜你。品牌词搜索量的缓慢上扬,是AI可见度在起作用的滞后信号。三个办法叠起来用,黑箱也能摸出个轮廓。
Web IQ之外,AI抓取的付费和标准化在往哪走?
这里得给源头那股乐观情绪泼点冷水。Web IQ官方的叙事是"尊重发布者偏好、和IETF一起推标准",听上去很美。但现实是,今天你的内容被AI免费抽走、不带回报,这个根本矛盾,Web IQ并没有解决,只是承认了它的存在。
行业正在两个方向上找补。一个是标准化:微软说的IETF标准,就是想给"AI能不能抓、抓了怎么用"立个规矩,让发布者有更精细的控制权,而不是只有robots.txt那一个粗开关。这事在推进,但远没落地。
另一个是付费化:Cloudflare已经在试"按次抓取",让发布者给AI爬虫的每次抓取标个价,最低一美分一次,由Cloudflare当收款方走Stripe结算。思路是把"免费抽走"变成"抽走就付费"。这两条路都还在早期,但方向很明确——白嫖时代不会一直持续。对你的启示是:现在把可抽取性和品牌信号做扎实,等规则成形时你才有筹码,而不是临时抱佛脚。
关于Web IQ,最容易踩的三个误判
跟同行聊下来,发现对Web IQ的误解高度集中在三处,挨个点破。
| 误判 | 实情 |
|---|---|
| "这只是Bing的一次API升级,跟我没关系" | 它是Copilot、ChatGPT的事实取料口,你的内容正经由它被AI引用,是可见度问题不是技术问题 |
| "封了Bingbot就能不被AI抽段落" | 同一个Bingbot既做搜索也做取料,封了它自然搜索一起没,目前没有只屏蔽AI的干净开关 |
| "把关键词排名做好,AI自然就引用我" | 排名优化的是整页,抽取优化的是每段,两者有重叠但不等同,段落写不好排名再高也可能不被抽 |
这三条踩中任何一条,方向就偏了。第一条让你彻底忽视;第二条让你误伤自己;第三条让你以为做完了其实没开始。把它们记反着来,思路就正了。
现在就能落地的清单
说了这么多,落到能动手的,就这几件,按优先级排好了。
- 先把Bing地基补齐:Bing Webmaster Tools验证站点、提交站点地图、清掉抓取异常,这是被AI引用的前提。
- 挑你最重要的5到10篇内容,按可抽取性清单逐段改:结论前置、段落自包含、事实密度拉高、实体写全。
- 给关键页面铺结构化数据:产品页上Product,文章配清晰表格列表,让事实能被解析成证据对象。
- 建一套实测prompt:固定问题定期去ChatGPT、Copilot问,记录品牌被提及和引用的情况。
- 想清楚"饵还是货":对照决策表,定下哪些内容敞开抓、哪些敏感栏目限制,别一刀切。
- 换衡量口径:别只看AI带来的直接点击,把品牌词搜索量、AI引用频次、间接转化纳进来。
Web IQ不是要你推翻重做,而是提醒你:搜索的消费端正在从人变成机器,而你大概率还在只给人优化。补上"给AI代理优化"这一层,趁规则还没定死、趁多数同行还没反应过来,这就是当下最划算的动作。位置是借来的,但先把内容练到能被借去,才谈得上后面的事。
常见问题解答
Web IQ普通站长现在能直接用吗?目前它是面向企业客户的限量访问,定价和正式开放时间都还没公布,普通站长暂时调用不了这个接口。但你不需要调用它——你要做的是让你的内容在Bing索引里足够干净、足够好抽,这样当别的AI通过Web IQ取料时,能取到你。换句话说,你是供给侧,不是调用侧。
我封了Bingbot,是不是就不会被Web IQ抽取了?理论上是,但代价极大。Bing用同一个Bingbot做传统搜索抓取和AI取料,封了它,你在Bing的自然搜索可见度也一起归零。除非你的内容是付费产品、被抽走就直接损失收入,否则不建议封。对绝大多数靠内容引流的独立站来说,被AI引用是好事,封Bingbot是自断后路。
Web IQ会影响我在Google上的排名吗?不会,两者是分开的系统。Web IQ用的是Bing索引,影响的是经由Bing取料的AI代理;Google的排名和AI概览走的是Google自己那套。但有意思的是,为Web IQ做的段落可抽取性优化,对Google的AI引用同样有帮助——结构清晰、事实扎实的内容,在哪家AI那儿都吃香,这层投入是通用的。
我需要专门做个llms.txt之类的文件给Web IQ吗?不需要。Web IQ吃的是正常的网页和正常的Bing收录,不依赖任何只给机器看的特殊文件。与其花时间伺候这类文件,不如把基本的网页质量、结构化数据和Bing收录做扎实,这才是被AI取料的真正前提。把精力放在内容本身,比追文件管用得多。
怎么判断该不该为AI代理优化投入精力?看你的目标用户有没有在用AI找答案。如果你做的是出海消费品、专业服务、B2B这类用户会去ChatGPT、Copilot问意见的领域,那这层投入回报很高。如果你的流量主要来自纯交易型搜索、用户不太会问AI,那可以缓一缓。但趋势上,会问AI的用户只会越来越多,早做早占位。
权威参考资料
本文标题:《微软Web IQ是什么?给AI代理的Bing接地接口对SEO意味着什么》
本文链接:https://zhangwenbao.com/microsoft-web-iq-bing-grounding-api-ai-agents.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0