AI代理如何感知你的网站?2026年网站Agent适配实战指南
本文目录
- AI代理感知网站的三种模式
- 视觉截图模式:像素级"看图说话"
- 无障碍树模式:直读页面结构
- 混合模式:视觉+结构双管齐下
- 无障碍树:你网站的AI代理接口
- 学术数据佐证:无障碍做好了,AI代理成功率翻倍
- Perplexity的内容端验证
- 语义化HTML:AI代理的信任基石
- 使用原生HTML元素
- 正确标注表单字段
- 建立正确的标题层级
- 使用地标区域元素
- ARIA标注:锦上添花,不是雪中送炭
- ARIA误用的风险
- 正确使用ARIA的分层策略
- 页面渲染:AI代理的可见性前提
- JavaScript重度网站对AI代理的额外摩擦
- 渲染优化的四个实操要点
- 你的网站在AI代理眼中长什么样?实测方法
- 屏幕阅读器测试:最佳的代理兼容性替代方案
- Playwright MCP:直接查看代理眼中的世界
- Lynx文本浏览器:低成本的快速检测
- 四步实测工作流
- 给开发团队的9项实施清单
- 高影响力、低成本项
- 高影响力、中等成本项
- 中等影响力、低成本项
- 结构化数据:让AI代理不用猜
- 面向AI代理的Schema最佳实践
- WebMCP与AI代理的未来接口
- 避坑指南:常见的AI代理适配误区
- 误区一:ARIA标签越多越好
- 误区二:只关注视觉美观而忽略代码语义
- 误区三:认为"我的网站不需要被AI代理操作"
- 误区四:把无障碍当成合规成本而非投资
- 核心要点总结
- 常见问题
- AI代理和AI爬虫有什么区别?
- 无障碍优化是否会影响网站设计的自由度?
- 单页应用(SPA)是否无法适配AI代理?
- 给AI代理做的优化会不会与传统SEO冲突?
- 如何判断我的网站对AI代理是否友好?
- ARIA标签中填写关键词能帮助AI搜索排名吗?
- 中小型网站有必要做AI代理适配吗?
- 权威参考资料
摘要:AI代理是通过视觉截图、DOM解析和无障碍树三种方式来感知你的网站的。本文深度解析AI Agent浏览网站的底层逻辑,给语义化HTML、ARIA标注、服务端渲染等九项开发清单,帮你的网站在AI代理时代被准确理解、赢得它的信任,而不是被截图和DOM解析读成一团乱。
你的网站在人类眼里可能漂亮得无可挑剔——精心设计的配色、流畅的动效、考究的排版。但在AI代理的"眼中",这一切可能根本不存在。
2024年,互联网上的自动化流量首次超过人类流量,占到所有网络交互的51%。这个数字来自网络安全公司Imperva发布的2025年坏机器人报告,虽然其中并非全部是AI Agent的智能浏览行为,但趋势已经非常明确:你网站的非人类受众,已经比人类受众更庞大,而且还在持续增长。
ChatGPT的Atlas可以自主填写表单、完成购买;Chrome的自动浏览功能可以滚动页面、点击按钮;Perplexity的Comet能跨标签页进行深度研究。这些AI代理正在以你完全意想不到的方式"阅读"你的网站——它们看不到你精心调整的CSS渐变色,也感受不到你花了三天打磨的微交互动效。
它们看到的是无障碍树(Accessibility Tree)。
这个原本为视障用户的屏幕阅读器而生的技术结构,正在成为AI代理与你的网站之间最核心的交互接口。如果你做过GEO优化策略相关的工作,你一定理解"让AI引擎理解你的内容"的重要性。而本文要讲的,是这个逻辑的更底层——让AI代理不仅能"读懂"你的内容,还能"操作"你的网站。
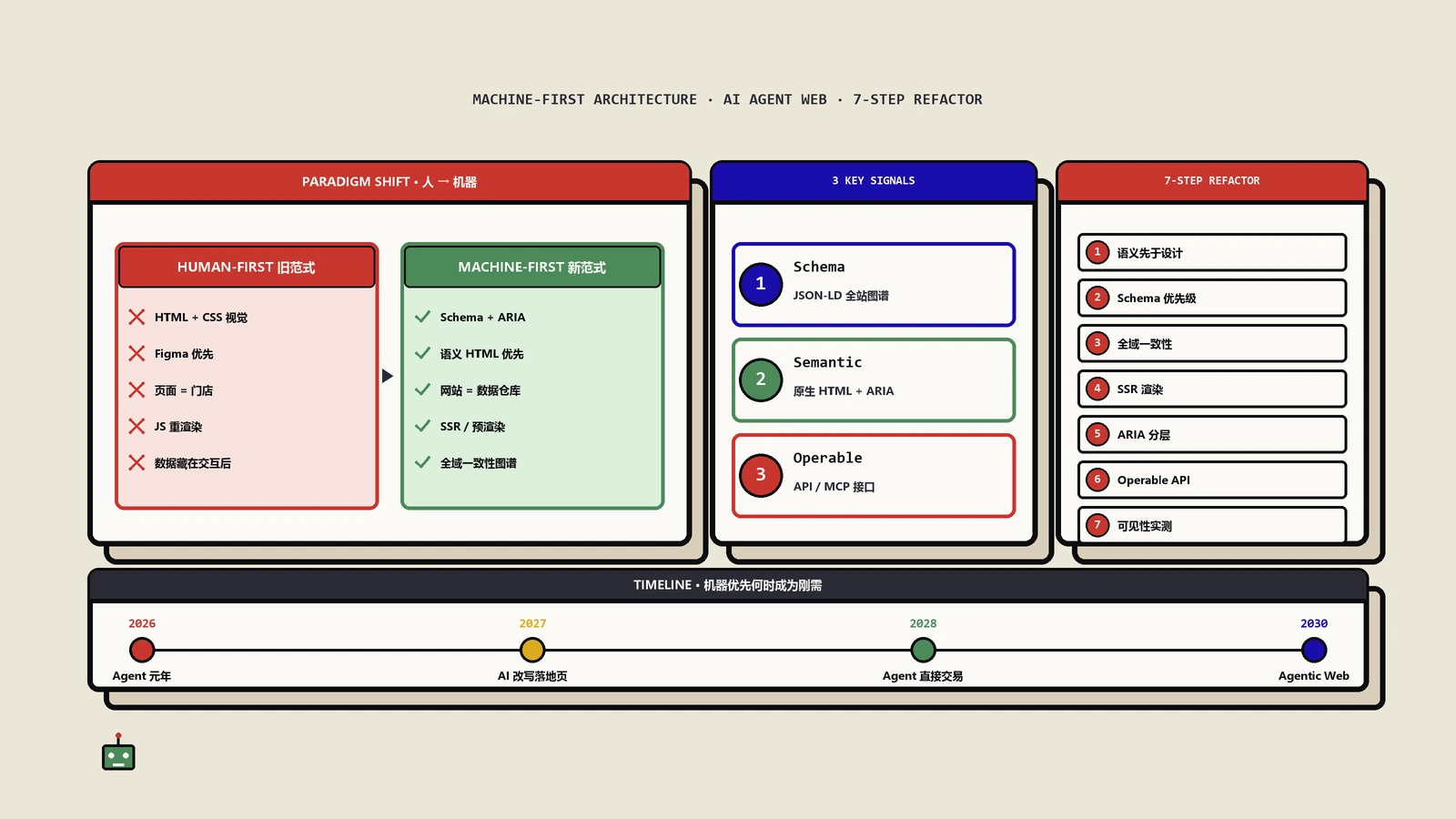
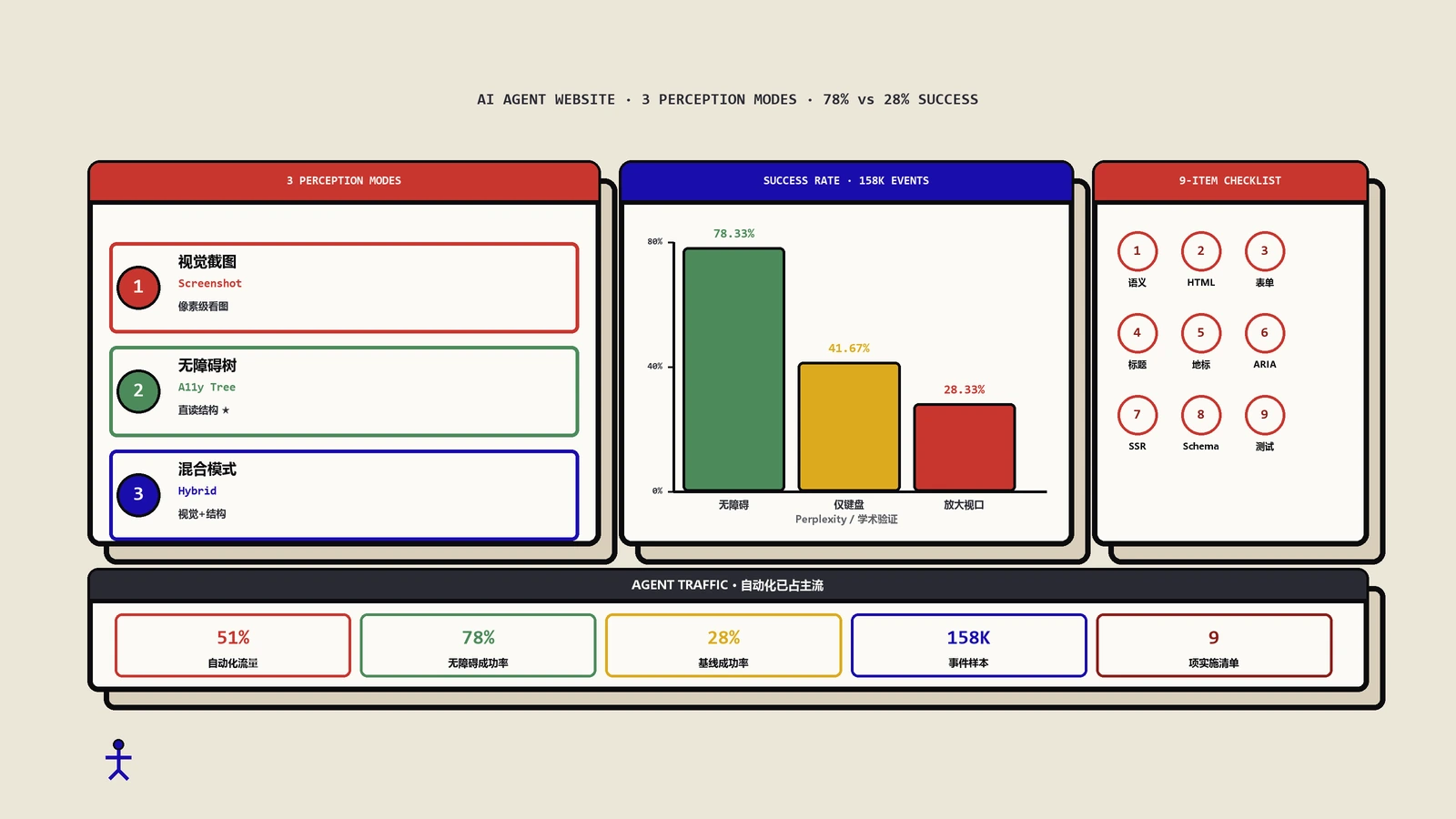
AI代理感知网站的三种模式
AI代理(AI Agent)是指能够自主浏览网页、理解页面内容并执行操作(如点击、填表、购买)的人工智能系统。与传统爬虫不同,AI代理具备多步推理和决策能力。
当人类访问网站时,映入眼帘的是颜色、布局、图片和字体。当AI代理访问同一个页面时,它感知到的是一套完全不同的信息结构。目前主流AI平台采用三种截然不同的感知方式,这些差异直接决定了你应该如何构建网站。
视觉截图模式:像素级"看图说话"
Anthropic的Computer Use是视觉流派的典型代表。Claude通过不断截取浏览器屏幕截图,分析图像中的视觉内容,然后决定在哪里点击、输入什么文字。整个过程是一个持续的反馈循环:截图→推理→操作→再截图。它在像素层面工作,通过按钮的视觉外观来识别按钮,通过渲染后的图像来阅读文字。
Google的Project Mariner采用了类似的"观察-规划-执行"循环:观察阶段捕获视觉元素和底层代码结构,规划阶段制定行动序列,执行阶段模拟用户交互。在WebVoyager基准测试中,Mariner取得了83.5%的成功率。
视觉模式确实能完成任务,但它有三个明显的硬伤:计算开销极大(每一步都需要截图和图像分析)、对布局变化敏感(换个皮肤可能就认不出按钮了)、受限于屏幕可见区域(折叠的内容它看不到)。
无障碍树模式:直读页面结构
OpenAI的ChatGPT Atlas走了一条完全不同的路。根据OpenAI官方发布的开发者FAQ,Atlas明确使用ARIA标签——也就是那些支持屏幕阅读器工作的标签和角色信息——来解析页面结构和交互元素。
Atlas基于Chromium内核构建,但它不去分析渲染出来的像素,而是直接查询无障碍树中具有特定角色(如"button""link")和可访问名称的元素。这与VoiceOver、NVDA等屏幕阅读器帮助视障人士浏览网页时使用的数据结构完全相同。
微软的Playwright MCP——官方的浏览器自动化MCP服务器——也采用了同样的策略。它提供的是无障碍快照(accessibility snapshots)而非屏幕截图,给AI模型一个结构化的页面表示。微软刻意选择了无障碍数据而非视觉渲染作为其浏览器自动化标准,这个决策本身就说明了技术方向。
混合模式:视觉+结构双管齐下
实际上,最强的AI代理会同时使用多种感知方式。OpenAI的CUA(Computer-Using Agent)——也就是驱动Operator和Atlas的底层引擎——将截图分析与DOM处理和无障碍树解析进行了多层叠加。它优先读取ARIA标签和角色信息,当无障碍数据不可用时才回退到文本内容和结构选择器。
Perplexity的BrowseSafe论文也证实了同样的模式。该论文详细描述了Comet浏览器代理背后的安全基础设施,其中提到使用"混合上下文管理,结合无障碍树快照与选择性视觉"。
| 平台 | 主要感知方式 | 技术细节 |
|---|---|---|
| Anthropic Computer Use | 视觉截图 | 截图→推理→操作的持续反馈循环 |
| Google Project Mariner | 视觉+代码结构 | 观察-规划-执行,结合视觉和结构数据 |
| OpenAI Atlas | 无障碍树 | 明确使用ARIA标签和角色信息 |
| OpenAI CUA | 混合模式 | 截图+DOM+无障碍树多层叠加 |
| Microsoft Playwright MCP | 无障碍树 | 无障碍快照,不使用截图 |
| Perplexity Comet | 混合模式 | 无障碍树+选择性视觉 |
趋势非常清晰:即便是以视觉优先起步的平台,也在逐步整合无障碍数据。而那些追求可靠性和效率的平台(Atlas、Playwright MCP),则直接以无障碍树为核心。
无障碍树:你网站的AI代理接口
无障碍树(Accessibility Tree)是浏览器根据页面DOM生成的一套简化结构,最初为屏幕阅读器等辅助技术而设计。它过滤掉了DOM中的所有"噪音"——那些div、span、style和script标签——只暴露真正重要的信息:可交互元素、它们的角色、名称和状态。
这正是它对AI代理如此好用的原因。一个普通页面的DOM可能包含数千个节点,而无障碍树会把它们精简到用户(或代理)实际能交互的元素:按钮、链接、表单字段、标题、地标区域。对于在有限上下文窗口内处理网页的AI模型来说,这种精简意义重大。
OpenAI在其开发者FAQ中说得非常明白:遵循WAI-ARIA最佳实践,为按钮、菜单和表单等交互元素添加描述性的角色、标签和状态,这能帮助ChatGPT识别每个元素的功能并更准确地与你的网站交互。同时还指出:让你的网站更加无障碍,有助于ChatGPT Agent更好地理解它。
学术数据佐证:无障碍做好了,AI代理成功率翻倍
加州大学伯克利分校和密歇根大学联合发表的一项研究(收录于CHI 2026会议)提供了目前最严格的数据。研究者使用Claude Sonnet 4.5在60个真实网页任务上进行测试,在不同的无障碍条件下收集了40.4小时的交互数据,涉及158325次事件。结果非常惊人:
| 测试条件 | 任务成功率 | 平均完成时间 |
|---|---|---|
| 标准条件(默认) | 78.33% | 324.87秒 |
| 仅键盘操作 | 41.67% | 650.91秒 |
| 放大视口 | 28.33% | 1072.20秒 |
标准条件下,代理成功率接近80%。限制为仅键盘交互(模拟屏幕阅读器用户的导航方式),成功率降到42%,耗时翻倍。限制视口大小(模拟放大工具),成功率降到28%,耗时超过三倍。
研究识别出三类核心差距:
感知差距(Perception Gaps)——代理无法可靠地获取屏幕阅读器播报或ARIA状态变化,这些信息本该告诉它操作后发生了什么。
认知差距(Cognitive Gaps)——代理在多步骤任务中难以持续追踪任务状态,容易"忘记"自己做到哪一步了。
操作差距(Action Gaps)——代理未能充分利用键盘快捷键,在拖放等复杂交互上表现不佳。
结论很直接:呈现丰富、标注清晰的无障碍树的网站,能给代理提供成功所需的信息。而那些依赖视觉线索、悬停状态或复杂JavaScript交互却没有提供无障碍替代方案的网站,则在制造代理失败的条件。
Perplexity的内容端验证
Perplexity在其2025年9月发布的搜索API架构论文中从内容维度印证了这一点。其索引系统优先处理那些"在内容和形式上都高质量的内容,以保留原始内容结构和布局的方式捕获信息"。包含大量列表或表格形式的结构化数据的网站,能从"更规范化的解析和提取规则"中获益。结构不只是有帮助——它是可靠解析的前提条件。
语义化HTML:AI代理的信任基石
无障碍树由你的HTML生成。使用语义化元素,浏览器就能自动生成有用的无障碍树。跳过语义化,无障碍树就会稀疏或具有误导性。
这个建议本身并不新鲜。Web标准的倡导者们已经喊了二十年"请使用语义化HTML"。但不是所有人都听进去了。真正新鲜的是受众扩大了——过去这只关乎屏幕阅读器和相对较小比例的用户,现在它关乎每一个访问你网站的AI代理。
使用原生HTML元素
一个<button>元素会自动出现在无障碍树中,带有"button"角色和其文本内容作为可访问名称。而一个<div onclick="doSomething()">则不会——代理根本不知道它是可点击的。
<!-- AI代理能识别并与之交互 -->
<button type="submit">搜索航班</button>
<!-- AI代理可能根本不认为这是个可交互元素 -->
<div class="btn btn-primary" onclick="searchFlights()">搜索航班</div>保哥在实际项目中见过太多这样的案例:前端开发为了样式灵活性,把所有按钮都用<div>实现,然后用CSS模拟按钮的外观。在人类用户眼里没什么区别,但在AI代理的无障碍树中,这些"按钮"完全不存在。
正确标注表单字段
每个输入框都需要关联的标签。代理读取标签来理解字段期望什么数据。
<!-- AI代理知道这是一个邮箱字段 -->
<label for="email">邮箱地址</label>
<input type="email" id="email" name="email" autocomplete="email">
<!-- AI代理看到的只是一个没有标签的文本输入框 -->
<input type="text" placeholder="请输入邮箱...">这里要特别强调autocomplete属性。它告诉代理(和浏览器)一个字段期望的精确数据类型,使用标准化的值如name、email、tel、street-address、organization等。当代理代替用户填写表单时,autocomplete属性决定了它是精确匹配字段还是在猜测。这是被绝大多数开发者忽略的细节,但对AI代理的表单填写成功率有决定性影响。
建立正确的标题层级
使用h1到h6按逻辑顺序排列。代理利用标题层级来理解页面结构并定位特定的内容区块。跳级使用标题(比如从h1直接跳到h4)会制造内容关系上的混乱。
一个正确的标题层级应该像这样:
h1:页面的唯一主标题h2:主要内容区块的标题h3:每个h2下的子主题标题h4-h6:更细粒度的层级
如果你想快速检查自己网站的标题层级是否合规,可以使用页面结构分析工具对关键页面进行扫描,它能一眼看出标题层级的跳跃和缺失问题。
使用地标区域元素
HTML5的地标元素(<nav>、<main>、<aside>、<footer>、<header>)告诉代理它在页面的哪个位置。一个<nav>元素明确就是导航区域,而一个<div class="nav-wrapper">则需要代理自己去"猜"。
<nav aria-label="主导航">
<ul>
<li><a href="/products">产品</a></li>
<li><a href="/pricing">定价</a></li>
</ul>
</nav>
<main>
<article>
<h1>航班搜索</h1>
<!-- 主体内容 -->
</article>
</main>微软的Playwright测试代理(2025年10月推出)在自动生成测试代码时,默认使用的是可访问选择器——不是CSS选择器,不是XPath,而是可访问角色和名称。微软让AI测试工具以屏幕阅读器相同的方式查找元素,因为这种方式更可靠。
ARIA标注:锦上添花,不是雪中送炭
OpenAI推荐使用ARIA(Accessible Rich Internet Applications),这是W3C制定的让动态Web内容可访问的标准。但ARIA是补充,不是替代。就像蛋白粉——在均衡饮食基础上补充有用,但如果拿它代替正常吃饭就会出问题。
W3C给ARIA定的第一条规则就是:如果你能使用原生HTML元素或属性来实现所需的语义和行为,那就用原生的,不要重新定义一个元素然后给它加上ARIA角色、状态或属性来使它可访问。
W3C不得不把"不要用ARIA"定为ARIA的第一条规则——这个事实本身就说明了ARIA被误用的程度有多严重。
ARIA误用的风险
知名Web无障碍专家Adrian Roselli在2025年10月的分析中提出了一个重要警告。他认为,在没有充分上下文的情况下推荐ARIA,可能会鼓励误用。根据WebAIM对Top百万网站的年度调查,使用ARIA的网站通常反而更不无障碍——因为ARIA经常被错误地当作贴在糟糕HTML结构上的创可贴。Roselli警告说,这种指导可能会激励一些做法,比如在aria-label属性中塞关键词,就像早期SEO中对meta keywords的滥用一样。
正确使用ARIA的分层策略
第一层:语义化HTML打底。 使用<button>、<nav>、<label>、<select>等原生元素,它们默认就能正确工作。
第二层:原生HTML不够用时加ARIA。 没有HTML对应物的自定义组件(标签面板、树视图、折叠面板)需要ARIA角色和状态才能被理解。
第三层:用ARIA状态反映动态内容变化。 当JavaScript改变了页面状态,ARIA属性负责告诉代理发生了什么:
<!-- 告诉代理菜单当前是展开还是收起状态 -->
<button aria-expanded="false" aria-controls="menu-panel">菜单</button>
<div id="menu-panel" aria-hidden="true">
<!-- 菜单内容 -->
</div>第四层:aria-label要描述性、诚实。 用它提供屏幕上不可见的上下文信息,比如在同一页面有多个"删除"按钮时区分它们。不要在里面堆砌关键词。
原则与好的SEO完全一致:先为用户构建,再为系统优化。语义化HTML是为用户构建,ARIA是在HTML力不从心时的精细调优。
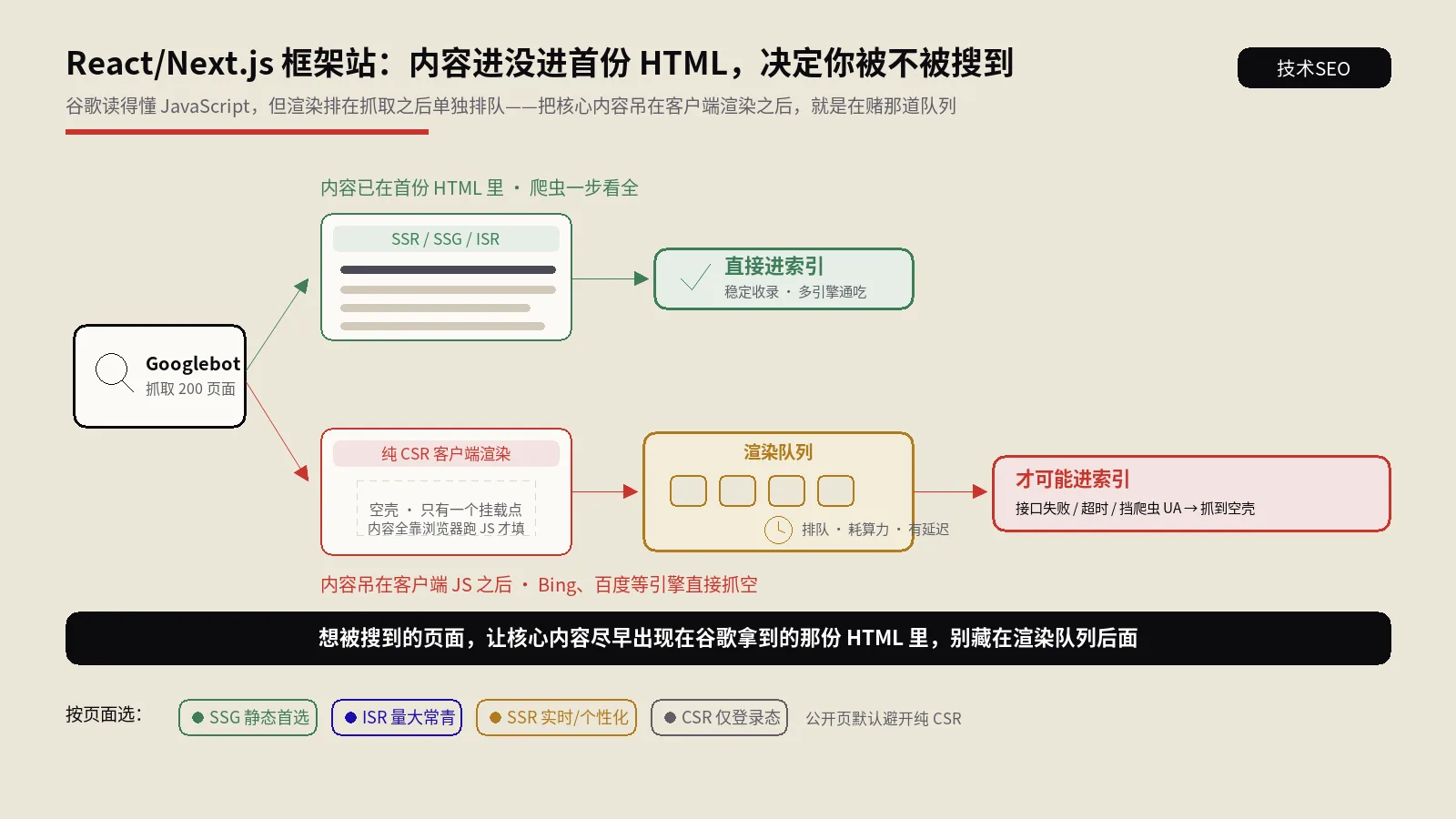
页面渲染:AI代理的可见性前提
基于浏览器的代理——Chrome自动浏览、ChatGPT Atlas、Perplexity Comet——都运行在Chromium上,能执行JavaScript,能渲染你的单页应用。
但并非所有访问你网站的"非人类"都是完整的浏览器代理。
AI爬虫(PerplexityBot、OAI-SearchBot、ClaudeBot)负责索引你的内容以供检索和引用。许多爬虫不执行客户端JavaScript。如果你的页面在React水合之前就是一个空的<div id="root"></div>,这些爬虫看到的就是一个空页面——你的内容对AI搜索生态系统来说是隐形的。
保哥之前在AI会不会让SEO消亡这篇文章里提到过,AI Agent的崛起正在重新定义"搜索"的含义。而服务端渲染(SSR)在这个新时代不仅仅是性能优化——它是可见性的前提条件。如果你的内容不在初始HTML中,它就不在AI的索引里。不在索引里,就不会被引用。
JavaScript重度网站对AI代理的额外摩擦
即便是完整的浏览器代理,JavaScript密集型网站也会制造摩擦。交互后才加载的动态内容、永远不发出结束信号的无限滚动、每次输入后自我重构的表单——这些都给代理创造了丢失状态追踪的机会。
前述伯克利/密歇根大学的研究把部分代理失败归因于"认知差距"——代理在复杂多步交互过程中丢失了对当前状态的追踪。更简单、更可预测的渲染方式能减少这些失败。
微软的官方指导直接适用于此:不要把重要的答案隐藏在标签页或可展开菜单中——AI系统可能不会渲染隐藏内容,导致关键细节被跳过。如果信息重要,把它放在可见的HTML中。不要要求交互才能显示。
渲染优化的四个实操要点
第一,内容页面必须服务端渲染或预渲染。 如果AI爬虫看不到你的内容,在AI生态系统中它就不存在。Next.js、Nuxt、Astro等框架让SSR变得非常简单。
第二,内容页面避免空壳SPA架构。 那种初始HTML只有一个空div、完全依赖客户端JavaScript渲染内容的架构,对AI爬虫来说就等于一张白纸。
第三,关键信息不要藏在交互背后。 价格、规格参数、库存状态——这些核心信息应该直接在初始HTML中呈现,不要放在手风琴折叠面板或标签页切换的后面。
第四,导航使用标准的<a href>链接。 不更新URL的客户端路由,或者用onClick事件处理器替代真实链接,都会破坏代理的导航能力。
你的网站在AI代理眼中长什么样?实测方法
你不会在没有浏览器测试的情况下发布网站。测试AI代理如何感知你的网站,正变得同样重要。
屏幕阅读器测试:最佳的代理兼容性替代方案
如果VoiceOver(macOS)、NVDA(Windows)或TalkBack(Android)能成功地在你的网站上导航——识别按钮、读取表单标签、跟随内容结构——那么代理大概率也能做到。两类"用户"依赖的是同一棵无障碍树。这不是完美的替代方案(代理有屏幕阅读器没有的能力,反之亦然),但它能捕捉到绝大多数问题。
Playwright MCP:直接查看代理眼中的世界
如果你想看到AI代理看到的确切内容,微软的Playwright MCP能生成任意页面的结构化无障碍快照。它发布为npm包@playwright/mcp,是目前最直接的方式来通过代理的"眼睛"查看你的网站。
输出大概长这样(已简化):
[heading level=1] 航班搜索
[navigation "主导航"]
[link] 产品
[link] 定价
[main]
[textbox "出发机场"] value=""
[textbox "到达机场"] value=""
[button] 搜索航班如果你的关键交互元素没有出现在快照中,或者出现了但没有有用的名称,代理在你的网站上就会遇到困难。
Lynx文本浏览器:低成本的快速检测
Lynx是一个纯文本浏览器,它剥离了所有视觉渲染,大致向你展示一个非视觉代理解析到的内容。虽然技术含量不高,但它能快速暴露问题:如果在Lynx里你的页面是一片空白或者内容顺序混乱,代理也会遇到同样的困境。
四步实测工作流
步骤一: 用VoiceOver或NVDA走一遍网站的核心用户流程。不用眼睛能完成核心任务吗?
步骤二: 用Playwright MCP对关键页面生成无障碍快照。交互元素是否被标注、可识别?
步骤三: 查看页面源代码。主要内容是否在HTML中,还是需要JavaScript才能渲染?
步骤四: 禁用CSS或在Lynx中加载页面,检查内容顺序和层级是否仍然合理。代理看不到你的布局。
给开发团队的9项实施清单
如果你是把这篇文章转发给开发团队看的(你应该这样做),下面是按影响力和实施难度排序的优先实施列表。
高影响力、低成本项
1. 使用原生HTML元素。 操作按钮用<button>,链接用<a href>,下拉选择用<select>。全面排查并替换所有<div onclick>模式。这是收益最大、成本最低的单项改进。
2. 标注每一个表单输入框。 用for属性将<label>元素与输入框关联。为所有输入框添加autocomplete属性并使用标准值。这一项对AI代理的表单填写成功率有直接影响。
3. 内容页面实施服务端渲染。 确保主要内容出现在初始HTML响应中。这是AI爬虫索引你内容的前提条件,没有任何替代方案。
高影响力、中等成本项
4. 实施地标区域。 用<nav>、<main>、<aside>、<footer>包裹对应内容。当同一页面有多个同类地标时,用aria-label加以区分。
5. 修复标题层级。 确保页面只有一个h1,h2到h6按逻辑顺序排列,不跳级。使用页面结构分析工具批量扫描全站标题层级问题。
6. 把关键内容从隐藏容器中移出来。 价格、规格参数、核心细节不应该需要点击或交互才能显示。如果实在需要折叠展示,确保至少在HTML源代码中可见。
中等影响力、低成本项
7. 为动态组件添加ARIA状态。 菜单、手风琴面板、开关按钮使用aria-expanded、aria-controls和aria-hidden,让代理知道当前状态。
8. 使用描述性链接文本。 "查看完整报告"而不是"点击这里"。代理依赖链接文本来判断链接指向哪里,而不是像人类那样看链接上下文。
9. 把屏幕阅读器测试纳入QA流程。 不是一次性审计,而是每次发版前的常规检查项。如果你无法给VoiceOver分配专门的测试人员,至少在关键页面改版时跑一次。
结构化数据:让AI代理不用猜
除了无障碍树和语义化HTML,结构化数据(Schema Markup)是帮助AI代理理解页面"是什么"以及"能做什么"的另一个关键层。JSON-LD格式的结构化数据不依赖视觉渲染,直接以机器可读的方式声明页面的核心信息。
对于电商网站来说,Product Schema能让代理精确识别价格、库存、评分;对于文章页面,Article Schema能声明作者、发布时间、内容摘要。想快速为页面生成规范的结构化数据,可以使用Schema结构化数据生成工具。
结构化数据与无障碍树的关系可以这样理解:无障碍树告诉代理"页面上有什么可以操作",结构化数据告诉代理"这些内容的语义是什么"。两者协同工作,才能给AI代理提供完整的理解。
面向AI代理的Schema最佳实践
Product Schema必须完整。 如果你是电商网站,name、price、priceCurrency、availability、image、description这些字段缺一不可。代理在执行购买任务时,依赖这些字段做决策。
FAQ Schema提升AI可引用性。 FAQPage结构化数据不仅有助于传统搜索的富结果展示,更让AI搜索引擎能直接解析问答对,大幅提升内容被引用的效率。
BreadcrumbList Schema帮助代理理解站点结构。 面包屑导航的结构化数据为代理提供了一张网站的"地图",帮助它快速定位目标页面在整个站点层级中的位置。
WebSite SearchAction Schema声明站内搜索能力。 通过这个Schema,你可以告诉代理"我的网站支持搜索,搜索接口是这样的",让代理能直接调用你的站内搜索,而不是自己在页面上四处寻找搜索框。
WebMCP与AI代理的未来接口
当前的无障碍树是AI代理与网站交互的"事实标准",但它毕竟不是为代理设计的。行业正在探索更专门的协议。
WebMCP是一个值得关注的新兴方向。它建立在语义化HTML和结构化数据的基础上,为网站提供声明式的表单方法——网站主动告诉代理"我能做什么""需要什么参数""预期输出是什么"。这本质上是把网站从一个"需要代理自己摸索的界面"变成一个"主动声明能力的服务"。
虽然WebMCP还处于早期阶段,但它的逻辑与本文讨论的所有优化措施完全一致:你今天构建的语义化HTML和无障碍树,就是明天WebMCP声明式接口的基础。任何在当下投入无障碍优化的工作,都不会被浪费。
避坑指南:常见的AI代理适配误区
误区一:ARIA标签越多越好
过度使用ARIA不仅不会帮助代理,反而会制造混乱。一个语义清晰的<button>Search</button>比一个<div role="button" aria-label="Search button for finding products on our website" tabindex="0">好得多。前者简洁明了,后者信息冗余且有关键词堆砌的嫌疑。
误区二:只关注视觉美观而忽略代码语义
网站可以既漂亮又语义清晰。这两件事不矛盾。视觉层由CSS负责,语义层由HTML负责。代理不看CSS,它只看HTML的语义结构。
误区三:认为"我的网站不需要被AI代理操作"
即便你认为自己的网站不会被AI代理用于自动化购买或表单填写,你的内容仍然需要被AI爬虫正确索引和理解。无障碍优化带来的结构清晰度,同时服务于传统搜索排名、AI搜索引用和代理交互三个目标。
误区四:把无障碍当成合规成本而非投资
2025年6月欧洲无障碍法案生效后,很多人把无障碍当成了一项法规成本。但换个视角看,这是一项一次性投入、持续产出的投资——它同时改善了人类体验、搜索排名、AI引用率和代理兼容性。很少有单项技术工作能同时服务四个目标。
核心要点总结
AI代理通过三种方式感知网站:视觉截图、DOM解析和无障碍树。 行业正在向无障碍树收敛,因为它是最可靠、最高效的方法。
无障碍树不再只是合规产物。 它是AI代理理解你网站的核心接口。伯克利/密歇根大学的研究证明,无障碍特性受限时,代理成功率从78%暴降到28%。
语义化HTML是地基。 <button>、<label>、<nav>、<main>等原生元素自动生成有用的无障碍树。不需要框架,不需要ARIA——基础工作用原生HTML就够了。
ARIA是补充而非替代。 用它处理动态状态和自定义组件,但先把语义化HTML做好。被错误使用的ARIA会让网站变得更不无障碍。
服务端渲染是AI生态系统的可见性前提。 不执行JavaScript的AI爬虫看不到空壳SPA中的内容。内容不在初始HTML中,在AI生态系统中就不存在。
屏幕阅读器测试是代理兼容性的最佳替代方案。 VoiceOver或NVDA能顺畅地导航你的网站,代理大概率也行。Playwright MCP的无障碍快照能让你直接看到代理看到的东西。
好消息是,这些并非独立的工作线。无障碍良好、结构清晰的网站,同时在人类用户体验、搜索引擎排名、AI搜索引用和代理交互四个维度上表现更优。一份工作,四重收益。你今天在语义化HTML和无障碍上的每一分投入,都是在为明天的AI代理网络铺路。
常见问题
AI代理和AI爬虫有什么区别?
AI爬虫(如PerplexityBot、OAI-SearchBot、ClaudeBot)的主要任务是索引网页内容,供AI搜索引擎在回答用户问题时检索和引用。它们通常不执行JavaScript,只读取初始HTML。AI代理(如ChatGPT Atlas、Perplexity Comet)则更进一步,它们能像人类用户一样在浏览器中自主导航、点击按钮、填写表单甚至完成购买。两者对网站优化的要求有交叉但不完全相同:爬虫需要你的内容在初始HTML中可见,代理则需要你的交互元素在无障碍树中清晰可识别。
无障碍优化是否会影响网站设计的自由度?
不会。无障碍优化的核心在HTML语义层,而视觉设计由CSS控制。你可以在保持完全相同视觉效果的前提下,把底层HTML从一堆<div>改为语义化元素。屏幕上的按钮看起来没有任何变化,但在无障碍树中,它从一个未知元素变成了一个明确的"button"角色。代理需要的是语义层面的清晰度,而不是视觉层面的简化。
单页应用(SPA)是否无法适配AI代理?
SPA不是问题,空壳渲染才是。Next.js、Nuxt等现代框架支持SSR或SSG,可以在保留SPA交互体验的同时,确保初始HTML包含完整内容。关键是让AI爬虫在不执行JavaScript的情况下也能读取你的核心内容。如果你使用的是纯客户端渲染的React或Vue应用,需要考虑迁移到支持SSR的框架,或至少对关键内容页面实施预渲染。
给AI代理做的优化会不会与传统SEO冲突?
恰恰相反。AI代理优化和传统SEO的要求高度一致:语义化HTML改善了搜索引擎的页面理解,清晰的标题层级有助于搜索排名,服务端渲染确保内容被正确索引,结构化数据增强搜索结果的展示。做好AI代理适配的网站,传统SEO表现通常也会同步提升。这是为数不多的"一举多得"的技术优化方向。
如何判断我的网站对AI代理是否友好?
最快速的方法是做两个测试:第一,用屏幕阅读器(VoiceOver或NVDA)走一遍网站的核心用户流程,看能否在不用眼睛的情况下完成关键任务;第二,查看页面源代码,确认核心内容(产品信息、文章正文、价格等)是否在初始HTML中可见,而非依赖JavaScript渲染。如果这两个测试都通过,你的网站对AI代理来说至少达到了基本可用的水平。
ARIA标签中填写关键词能帮助AI搜索排名吗?
不能,而且会适得其反。ARIA标签的目的是为辅助技术和AI代理提供准确的元素描述,不是SEO关键词的填充位。在aria-label中堆砌关键词不仅违反WAI-ARIA规范,还会导致屏幕阅读器和AI代理获取到冗余、混乱的信息,反而降低你网站的可访问性和代理交互成功率。保持aria-label简短、准确、描述性。
中小型网站有必要做AI代理适配吗?
有必要,而且中小型网站做起来成本更低。本文提到的大多数优化措施(语义化HTML、表单标注、标题层级修复)都是基础的Web开发规范,不需要额外的技术架构投入。相比大型网站需要梳理成千上万个页面,中小型网站的改造范围更小、见效更快。而且随着AI代理在购物、信息检索等场景中的使用量持续增长,越早适配意味着越早获得这波流量红利。
权威参考资料
本文标题:《AI代理如何感知你的网站?2026年网站Agent适配实战指南》
本文链接:https://zhangwenbao.com/ai-agent-website-optimization-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0