JS渲染的页面Google抓不到,先从这几种情况查起

本文目录
- 搜索引擎处理一个JavaScript页面,到底分几步?
- 第一步:抓取拿到的是服务器原始响应
- 第二步:渲染排队,而不是立即渲染
- 第三步:渲染后才做的二次抽取
- 内容明明在页面上,为什么就是搜不到?
- 正文完全靠客户端请求接口才出现
- 关键内容藏在交互之后
- 渲染需要的资源被挡或报错
- 关键信号在渲染前后打架
- 渲染队列和渲染预算,会带来哪些你没料到的连锁反应?
- CSR、SSR、SSG、动态渲染,到底按什么标准选?
- 判断标准其实只有几句话
- hydration这个坑要单独拎出来说
- 客户端路由和深链直达,为什么经常是隐形重灾区?
- JS把状态码玩坏了,会怎样静默掉量?
- 软404:页面说找不到,服务器说一切正常
- JS跳转不等于服务端跳转
- 结构化数据靠JS注入,为什么富媒体结果时有时无?
- JS体积和渲染预算之间,是什么样的拖累关系?
- 第三方异步加载的内容,为什么常常等于没有?
- AI抓取器根本不跑JavaScript,这件事改变了什么?
- 遇到JS内容搜不到,按什么顺序排错?
- 第一刀:看原始HTML里有没有
- 第二刀:看搜索引擎渲染后的样子
- 第三刀:查资源有没有被挡、JS有没有报错
- 第四刀:查信号冲突和交互依赖
- 一个真实的排错过程长什么样?
- 哪些是反直觉、最容易踩的判断错误?
- 从客户端渲染迁到服务端直出,怎么分阶段不掉量?
- 上线前的JavaScript SEO验收,到底该卡哪几项?
- 原始和渲染后的差异,怎么变成持续监控而不是一次性体检?
- JS渲染问题,怎么和其他几种问题区分开,别认错?
- 常见问题解答
- 禁用JavaScript看到页面是空的,是不是SEO就一定完蛋?
- 动态渲染(给爬虫单独输出预渲染版)现在还能用吗?
- 已经上了服务端渲染,为什么还是有页面不收录?
- 单页应用想做好SEO,最优先改哪一件事?
- 怎么快速判断问题是出在渲染,还是出在内容质量?
- AI搜索时代,JS渲染这件事的优先级是升了还是降了?
- 权威参考资料
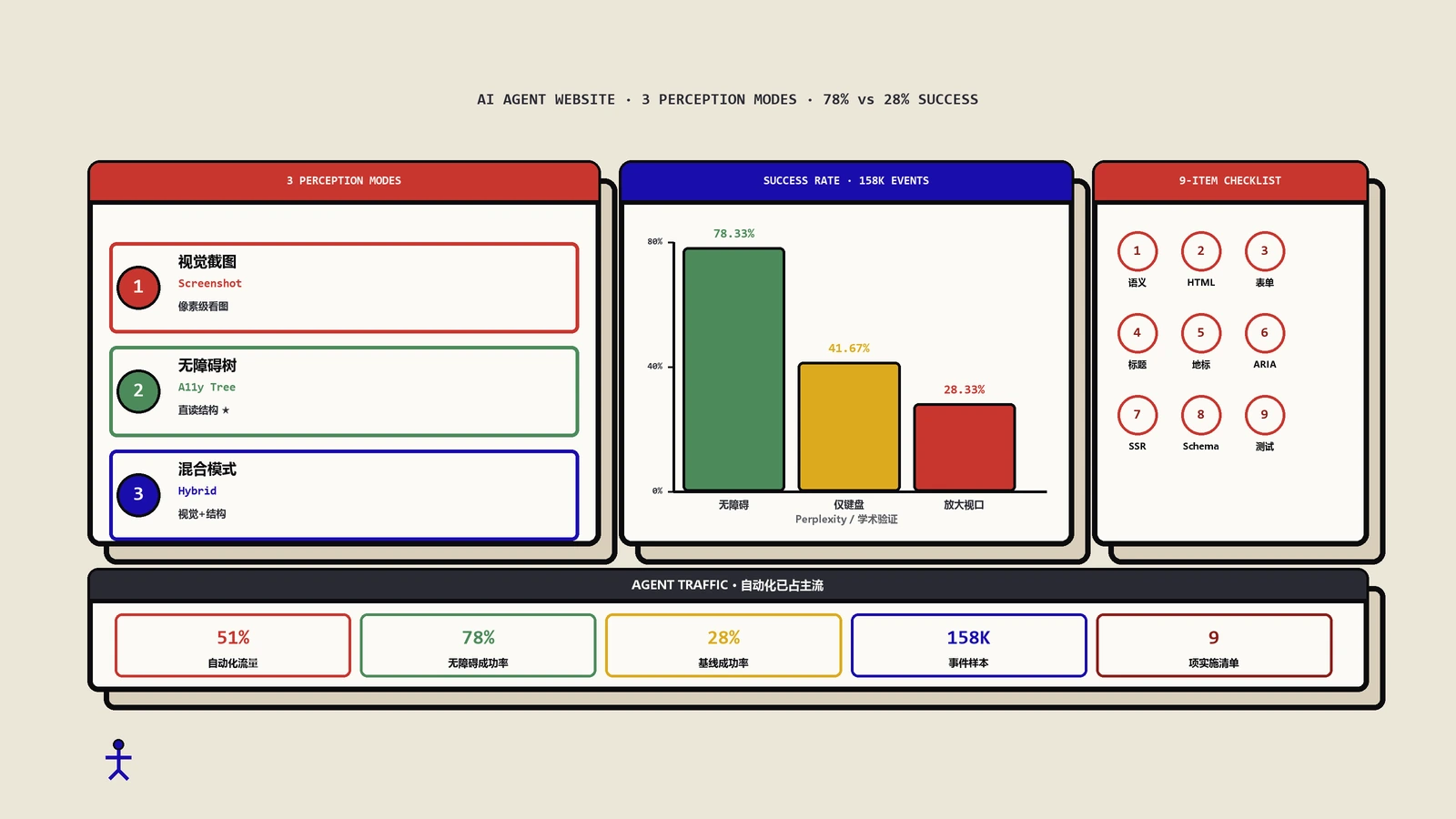
摘要:搜索引擎看你的页面分两眼,第一眼是服务器吐回来的原始HTML,第二眼才是浏览器跑完JavaScript之后的样子,而这两眼之间隔着一条会堵车、有预算、会静默失败的渲染队列。内容确实显示在屏幕上,不代表第一眼能看见它;排名靠的恰恰是第一眼能不能直接拿到正文、关键标签和真实链接。更要命的是,绝大多数AI抓取器只看第一眼,根本不跑第二眼——所以把关键内容压在客户端JavaScript里,等于同时对慢半拍的搜索收录和完全不渲染的AI引用关门。这篇把渲染机制、四种架构怎么选、以及内容明明在页面上却搜不到时按什么顺序排错,一次讲透。
有个现象这些年反复出现:开发把站点用前端框架重写了一版,页面在浏览器里打开漂漂亮亮,产品经理验收也没问题,三个月后流量却一路往下走,长尾词几乎全军覆没。打开站点看,内容明明都在;用搜索引擎搜站内一段独有的句子,却一条不出。问题不在内容质量,而在搜索引擎到底是用哪只眼睛看这个页面。把这件事的机制讲清楚,比给一堆零散的修复技巧有用得多。
搜索引擎处理一个JavaScript页面,到底分几步?
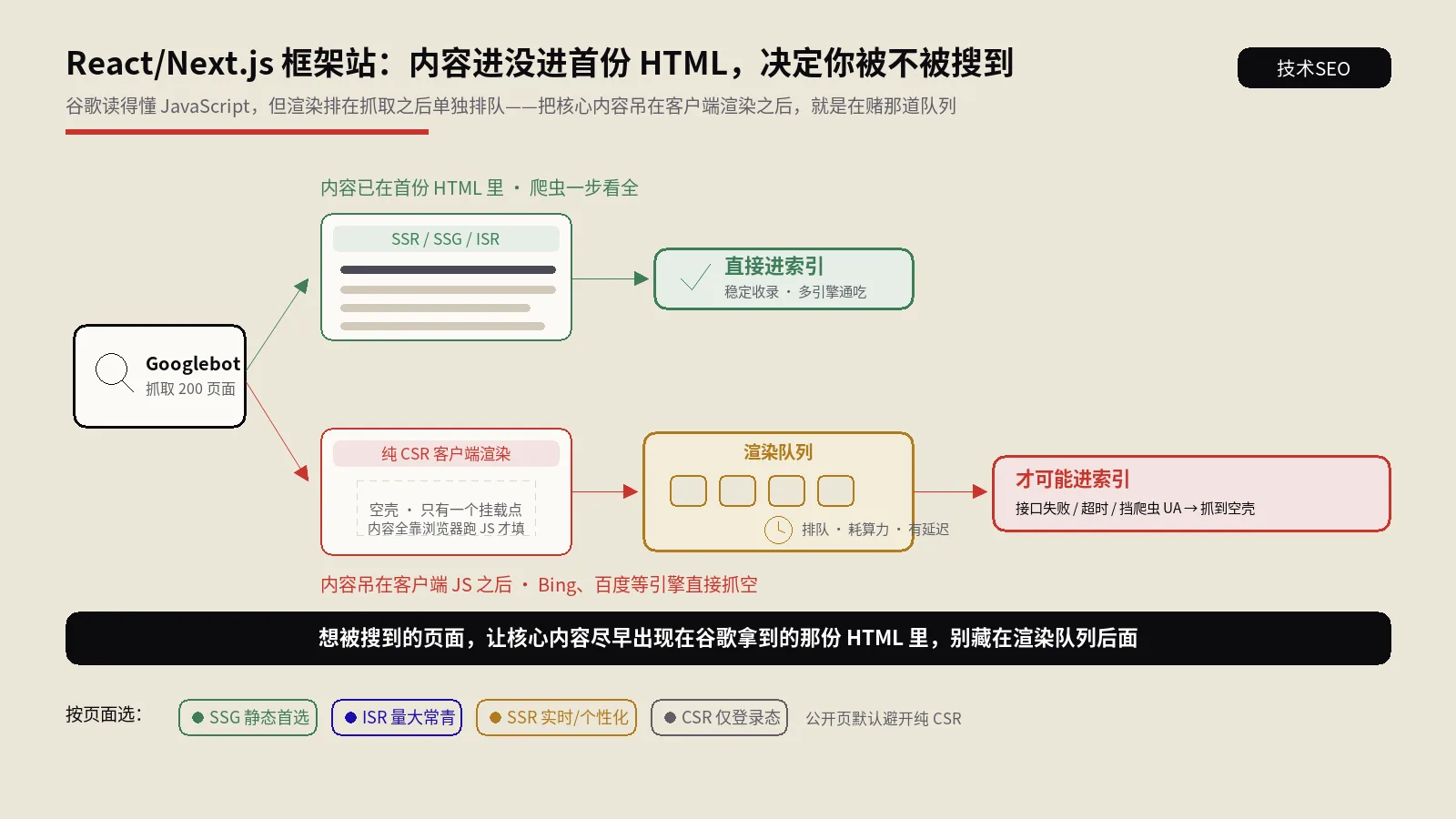
很多人脑子里的模型是错的:以为搜索引擎打开你的URL,就像用户用Chrome打开一样,所见即所得。实际不是。一个现代搜索引擎处理网页,至少拆成抓取、渲染、索引三个解耦的阶段,而且渲染是单独排队、单独算账的。
第一步:抓取拿到的是服务器原始响应
爬虫发起请求,服务器返回什么字节,它就先拿到什么字节。这一步看到的是没有执行任何JavaScript的原始HTML。如果你的页面是个空壳——body里只有一个 <div id="root"></div> 加几个打包后的脚本文件,那么这一眼里,你的正文、标题文案、内部链接统统不存在。爬虫在这一步还会顺手解析原始HTML里的链接,决定接下来去抓哪些URL。注意这个细节:第一步发现的链接,是从原始HTML里来的,不是从渲染后的页面里来的。
第二步:渲染排队,而不是立即渲染
如果原始HTML不完整,搜索引擎会把这个页面丢进一个渲染队列,由一套服务端的无头浏览器(可以理解成一台没有界面的Chrome)择机执行JavaScript,把页面渲染成最终样子。关键词是择机。渲染很贵,搜索引擎不可能对全网每个页面实时跑一遍浏览器,所以它排队、有优先级、有预算。权重高、被抓得勤的站排得靠前;新站、低权重站、海量同质页面的站,可能要等很久,甚至这一轮被跳过。这就是所谓的两波索引:第一波基于原始HTML先把能看的信息编进去,第二波等渲染完了再补。
第三步:渲染后才做的二次抽取
渲染完成后,搜索引擎重新抽取这个页面渲染后的正文、标签和链接,再做一遍索引和链接发现。这里有个被严重低估的连锁反应:渲染后才出现的内部链接,要等到第二波之后才被发现。对一个靠列表页、靠新内容不断冒出来的站(电商、资讯、招聘),这意味着新页面被发现的速度整整慢一个渲染周期。你以为只是首页正文晚点收录,实际是整条新内容的发现链路都被拖慢了。搜索引擎抓取索引这套底层流程,搜索引擎怎么工作的那篇拆解讲得很细,本篇只聚焦渲染这一环卡在哪里。
内容明明在页面上,为什么就是搜不到?
“内容在页面上”这句话本身就是误区——它默认了搜索引擎看到的和你在浏览器里看到的是同一个东西。把根因拆开,常见的是下面这几类,而且经常同时中招。
正文完全靠客户端请求接口才出现
这是最典型的一类。服务器返回的是一个app shell,正文要等浏览器执行JS、再发一个接口请求、拿到JSON、渲染成DOM才出现。搜索引擎第一眼看到空壳,能不能补上全看渲染队列什么时候轮到你、那次渲染有没有成功。结果往往是:标题(如果写死在HTML里)能收,正文进不去,长尾词没有任何着陆点。
关键内容藏在交互之后
爬虫不会帮你点“展开全文”,不会切tab,不会往下滚到懒加载触发,也不会填表单。凡是要用户操作一下才加载的内容,默认就当它对搜索引擎不存在。很多站把核心参数、评价、问答折叠在交互后面,自己以为页面信息很丰富,搜索引擎眼里却是一篇干瘪的页面。
渲染需要的资源被挡或报错
渲染那一步要去加载你的JS包和接口数据。如果robots文件把 /static/ 或接口路径Disallow了,无头浏览器就拿不到脚本和数据,渲染出来还是空的。一个未捕获的JS异常、一个依赖了浏览器没有的接口、一个被跨域策略拦掉的请求,都会让渲染中途断掉,而这种失败是静默的——线上用户没事,因为用户的网络和缓存状态跟那台无头浏览器不一样。
关键信号在渲染前后打架
还有一类很隐蔽:原始HTML里写了noindex或一个canonical,JS渲染后又改成了另一个值。搜索引擎可能在第一波就按原始HTML的noindex把页面丢了,根本等不到你JS把它改回来;或者两个信号冲突,最终行为难以预测。任何决定收录与否、归一到哪个URL的指令,都不要交给客户端JavaScript去注入或修改。
渲染队列和渲染预算,会带来哪些你没料到的连锁反应?
大家容易把问题简化成“渲染了/没渲染”,真实情况是“渲染了,但晚,而且不保证每次都成”。这个时间差和不确定性,才是工程上真正要管理的风险。
第一个连锁反应是新内容发现变慢。前面说过,渲染后才出现的链接要等第二波。一个每天上几百个新商品、新职位、新帖子的站,如果列表和详情页的链接都靠JS注入,等于给整条收录管线套了一个渲染周期的延迟。竞品用服务端直出,当天就被抓被收;你晚三五天,热点早过了。
第二个是渲染失败没有告警。它不像500错误那样在监控里弹红。页面线上访问完全正常,只有搜索引擎那台无头浏览器在它的环境里渲染失败,而你拿不到那份日志。等你发现,通常是流量已经掉了一截、有人去查排名才回溯出来。
第三个是预算向高价值站倾斜。渲染资源有限,分配上天然偏向已经有权重、抓取频率高的站。这对新站特别不友好:你越是新、越没权重,越需要快被收录建立信任,却偏偏在渲染队列里排在最后。这也是为什么新站如果还重度依赖客户端渲染,起步期会格外难熬。新站本身的排名波动机制是另一回事,DOM抓取渲染索引那篇讲过流程层面的拆法,本篇补的是“为什么队列会把你排到后面”这层经济账。
CSR、SSR、SSG、动态渲染,到底按什么标准选?
架构选型不该按“团队喜欢哪个框架”来定,而该按这个页面的内容要不要被搜索和被AI引用、更新有多频繁、个性化程度多高来定。先把四种模式说清楚,再给判断标准。
| 模式 | 原始HTML里有没有正文 | 适合的页面 | 主要代价 |
|---|---|---|---|
| 纯客户端渲染(CSR) | 没有,空壳 | 登录后台、纯工具、不需要SEO的交互应用 | 对搜索和AI几乎不可见,靠渲染补救且不稳定 |
| 服务端渲染(SSR) | 有,每次请求实时生成 | 需要SEO又高度动态、有一定个性化的页面 | 服务器成本与架构复杂度高,hydration处理不好会出问题 |
| 静态生成(SSG / ISR) | 有,构建时或增量生成好 | 内容相对稳定、量大、更新可预期的页面 | 极高频实时更新的内容需要靠增量再生成兜 |
| 动态渲染 | 给用户空壳、给爬虫单独预渲染版本 | 只作为旧站迁移期的过渡手段 | 维护两套输出、容易产生偏差、有被判作弊的边缘风险 |
判断标准其实只有几句话
这个页面要不要被搜索引擎和AI引用?如果要,原始HTML里就必须有完整正文和关键元信息,于是只能在SSR和SSG之间选。内容更新频率可预期、构建能覆盖得过来,优先SSG或增量静态再生成,它最省、最稳、对爬虫最友好。内容高度动态、强个性化、必须请求时实时生成,才上SSR。纯CSR只留给那些本来就不需要被搜索的部分,比如登录后的控制台。动态渲染不要当长久方案——官方早就不推荐它,维护两套输出迟早出现给用户和给爬虫不一致,这本身就踩在作弊判定的边缘。
hydration这个坑要单独拎出来说
很多团队上了SSR就觉得稳了,结果hydration出问题,等于白做。常见的是:服务端吐出的HTML是对的,但前端框架接管页面时,把内容整段替换、闪一下重排、甚至因为服务端和客户端渲染结果对不上而报hydration mismatch,关键内容在接管后才真正稳定。搜索引擎渲染那一刻拿到的可能正是这个中间态。SSR的验收标准不是“服务器返回了HTML”,而是“关键正文在hydration之前就已经在原始HTML里完整存在,且hydration不会把它替换掉”。能用岛屿式、局部hydration把交互范围收窄,就别整页hydration。
客户端路由和深链直达,为什么经常是隐形重灾区?
单页应用最爱用客户端路由:地址栏变了,页面不刷新,靠JavaScript拦截跳转再换内容。问题出在两个地方。第一,用井号做路由(地址里带井号、后面跟一段路径),井号后面的部分对搜索引擎来说不算独立URL,你以为分了几十个页面,它眼里只有一个。第二,也是更隐蔽的——就算用了正规的历史记录接口让地址看起来是条干净路径,用户从外部直接访问那个深层URL时,服务器必须能第一时间返回这个页面的完整内容,而不是只有首页能直出、深层路径一访问就404或回到空壳。
很多团队的服务端渲染只做了首页和少数几个模板,深层详情页、筛选后的列表页、文档子页,从外部直接敲URL进去要么404要么空。搜索引擎和AI抓取器恰恰都是“从外部直接敲一个URL进去”这种访问方式,它们不会先打开首页再在站内一路点过去。验证方法很朴素:把任意一个想被收录的深层URL,复制到一个全新的无痕窗口里直接打开,看服务器第一时间返回的是不是完整内容。做不到,这个URL在搜索和AI眼里就是残的。
JS把状态码玩坏了,会怎样静默掉量?
状态码是搜索引擎判断一个URL该怎么处理的硬信号,而纯前端渲染最容易把它玩坏,且全程静默。
软404:页面说找不到,服务器说一切正常
商品下架、内容删除、筛选无结果,前端JS渲染出一个“没有找到”的提示,但响应状态码还是200。搜索引擎拿到200就认为这是一个正常有效页面,于是把成百上千个其实是空的页面收进索引,稀释整站质量,挤占抓取预算。正确做法是这类情况服务端就返回404或410,而不是让前端演一出找不到、底下却报平安。
JS跳转不等于服务端跳转
用JavaScript把用户弹去另一个地址,和服务端返回一个301永久跳转,对搜索引擎完全是两回事。前者权重传递弱、识别慢、还可能被当成可疑行为。凡是涉及URL永久变更、迁移、归一,一律走服务端301,不要用JS跳。需要把多个地址归一到一个,靠服务端响应里就写死的规范链接,别交给渲染后才注入。
结构化数据靠JS注入,为什么富媒体结果时有时无?
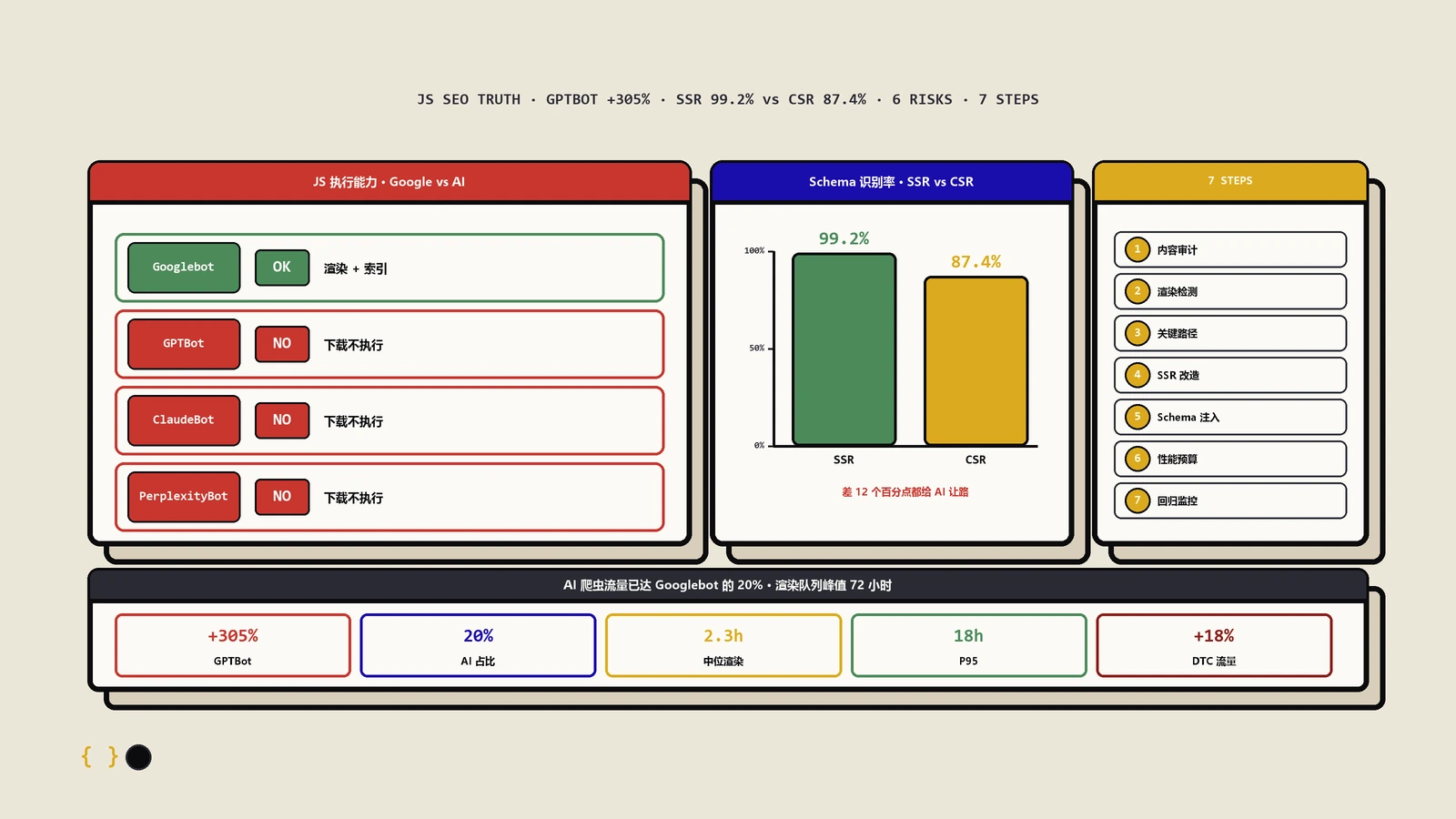
结构化数据决定你能不能拿到富媒体展示——评分星级、问答折叠、面包屑这些。如果结构化数据是JS渲染后才注入的,它就只能等第二波渲染才被看到,而前面讲过,渲染有延迟、有预算、会失败。结果就是富媒体结果时有时无、今天出明天不出,团队还以为是算法在抽风,其实是自己的结构化数据压根没稳定进过第一眼。
更糟的一种是结构化数据描述的内容和页面可见内容对不上——JS注入时拿了一份和正文不同步的数据,这在搜索引擎看来是结构化数据与页面不一致,属于会被取消富媒体资格甚至降权的问题。结构化数据要么服务端直接写进原始HTML,要么就别上,不要交给客户端JavaScript即兴发挥。
JS体积和渲染预算之间,是什么样的拖累关系?
渲染那台无头浏览器不会无限等你。JS包越大、解析执行越慢、首字节时间越高、依赖的接口越慢,单个页面渲染耗时就越长;渲染耗时越长,单位预算内能渲染的页面就越少,超过某个时间还没渲染完的,这一轮可能直接被放弃。这就是为什么性能不只是用户体验问题,它直接决定了你的页面有多大概率被完整渲染进索引。
几条拖累链路要心里有数:阻塞渲染的大体积脚本会推迟关键内容出现的时间点;一个慢接口会让渲染卡在等待上;一堆第三方脚本(统计、客服、广告)会拖垮整体渲染时间,还经常带进自己的报错;首字节时间高,连进渲染队列都慢一截。把关键内容服务端直出、把非必要脚本延后或异步、把第三方控制住,本质上都是在给渲染争取时间,让它在被放弃之前把你的正文渲染完。性能优化和可被收录,在这里是同一件事的两面。
第三方异步加载的内容,为什么常常等于没有?
有一类内容损失特别可惜:用户评价、问答、评论、嵌入式小部件,这些往往是页面里信息量最大、最有差异化价值的部分,却清一色靠JavaScript异步从第三方或自家接口拉回来。爬虫第一眼看不到,AI抓取器根本不渲染所以永远看不到,连搜索引擎自己的渲染都未必赶得上。你以为详情页内容很丰富,去掉这些异步块之后,搜索引擎实际能抽到的可能只剩干巴巴一段官方描述。
判断方法还是那一条:禁用JavaScript打开页面,看这些高价值内容还在不在。如果一个商品页真正的卖点是几百条真实评价,而这些评价对搜索和AI完全不可见,那等于把自己最强的差异化内容白白扔掉——这一点和后面要讲的内容差异化是一脉相承的,内容再独特,抽不到就不算数。要么把核心的那部分服务端直出,要么接受它对搜索和AI不存在的事实,别自欺欺人。
AI抓取器根本不跑JavaScript,这件事改变了什么?
这是这两年最该重视、却最少被讲透的一点。Googlebot还愿意花成本去渲染,但给大语言模型供数的那批抓取器——无论是训练用的还是答案引擎实时取数用的——绝大多数只取原始HTML,不跑无头浏览器。渲染太贵,它们的工程取舍就是不渲染。
这意味着什么?意味着哪怕Googlebot最终能把你JS注入的内容渲染出来、勉强收录,AI答案引擎大概率从一开始就什么都没看到。在越来越多用户先问AI、AI直接给答案并附引用的格局下,把正文压在客户端JavaScript里,等于主动退出被AI引用的资格。过去“服务端渲染是为了让Google早点看到”,现在要升级成“服务端渲染是被AI引用的入场券”。想知道这些AI抓取器到底取你什么、行为有多保守,可以对照AI爬虫逆向那篇,结论是一致的:原始HTML里没有的东西,对AI基本等于不存在。
所以判断一个页面要不要服务端直出,新的那把尺子是:这块内容你希不希望出现在AI的答案里并被注明来源?只要答案是希望,CSR这条路就直接排除,没有讨论余地。
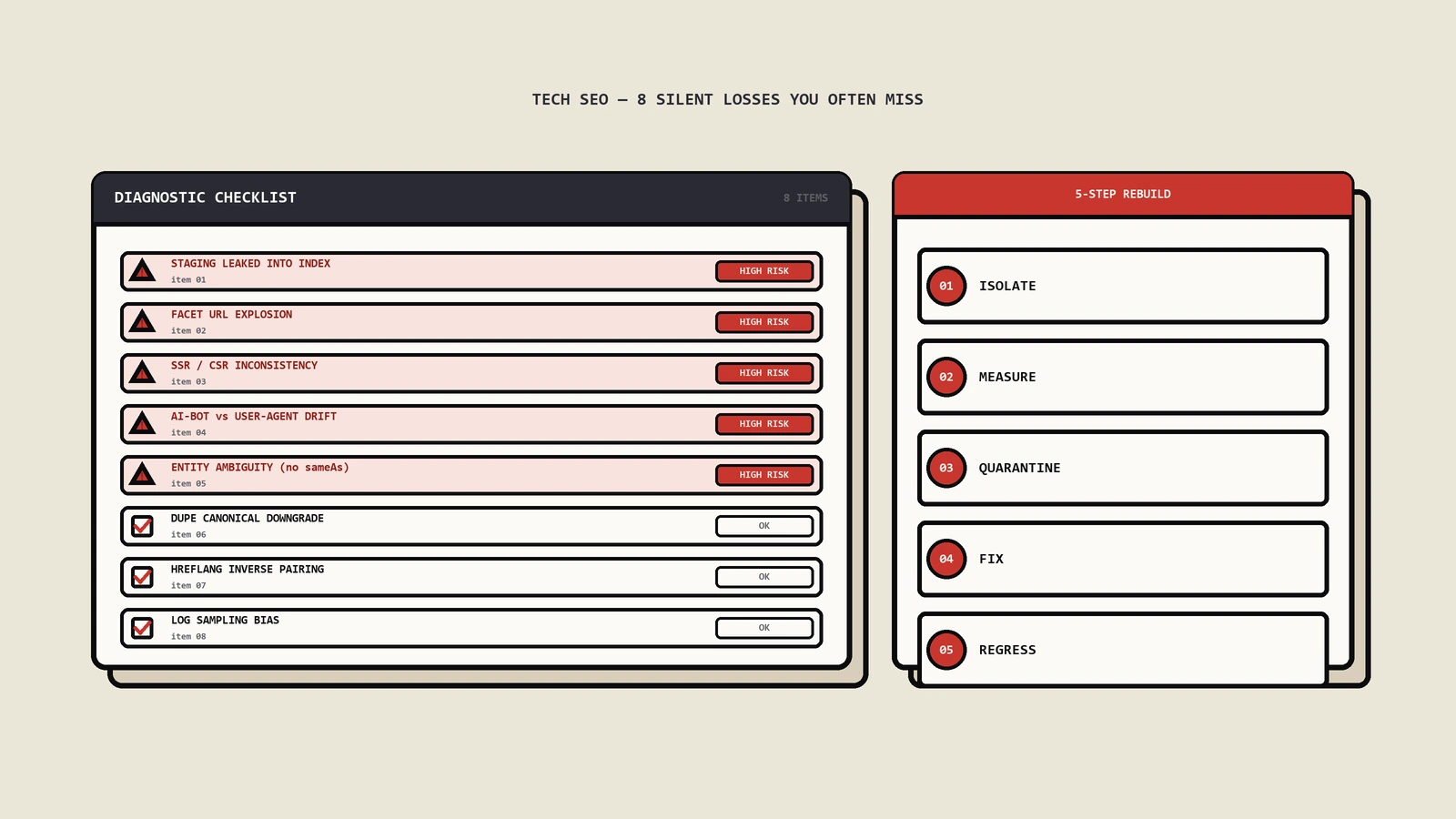
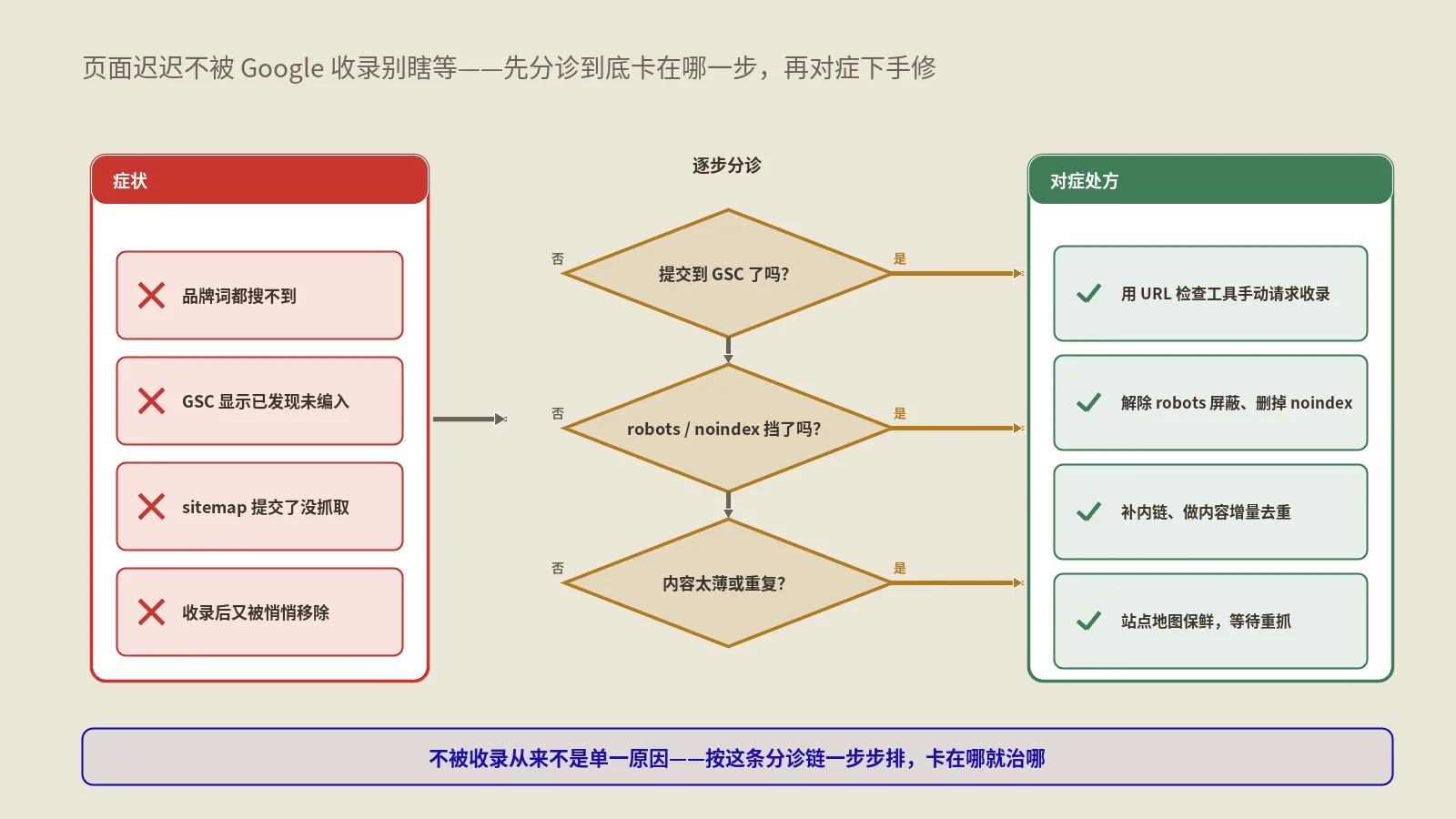
遇到JS内容搜不到,按什么顺序排错?
不要一上来就猜,按机制顺着查,每一步都对应前面讲过的一个根因。这个顺序保哥带团队排过很多次,照着走基本不会漏。
第一刀:看原始HTML里有没有
这是最便宜也最关键的一刀。把目标页面的原始响应取下来——命令行直接请求、或者在浏览器里看网页源代码、或者干脆禁用JavaScript再打开。重点看:正文核心段落在不在、title和meta描述在不在、决定收录的robots meta是什么值、内部链接是不是真实的 <a href>。如果原始HTML里就有完整正文,问题多半不在渲染,往别处查;如果是空壳,根因基本锁定在客户端渲染。
第二刀:看搜索引擎渲染后的样子
用搜索平台自带的URL检查、富媒体结果测试这类工具,看它渲染后抓到的HTML和截图。把这份渲染后HTML和你期望的对比:正文补上了吗、链接出现了吗、有没有报资源加载失败。这一刀能区分“根本没渲染”和“渲染了但渲染结果不对”。
第三刀:查资源有没有被挡、JS有没有报错
如果渲染后还是空,检查robots文件有没有挡掉JS、CSS、接口路径;检查关键脚本和接口是不是返回了正确状态码;在禁缓存、无登录态的环境下复现一遍,看控制台有没有未捕获异常。渲染那台无头浏览器没有你的登录态、没有你的本地缓存,很多“我这边好好的”都是这个差异造成的。
第四刀:查信号冲突和交互依赖
确认noindex、canonical这类指令在原始HTML里就是最终值,没有被JS改写;确认核心内容不是藏在点击、切tab、滚动、表单之后。把这四刀走完,根因基本就定位了。下面这张对照表把现象和根因对上,方便照着查。
| 观察到的现象 | 最可能的根因 | 验证动作 |
|---|---|---|
| 只收录了标题,正文进不去 | 正文靠客户端接口注入,渲染没补上 | 看原始HTML有没有正文 |
| 新页面迟迟不被发现 | 列表与详情链接靠JS注入,卡在第二波 | 看原始HTML里有没有真实a标签链接 |
| 页面被整体丢出索引 | 原始HTML里有noindex或错误canonical | 直接读原始响应里的robots meta |
| 渲染后仍为空 | 资源被robots挡 或JS渲染报错 | 查robots规则与无登录态控制台报错 |
| 富媒体结果不出现 | 结构化数据靠JS注入或渲染失败 | 对比原始与渲染后HTML里的结构化数据 |
一个真实的排错过程长什么样?
有家做出海效率工具的SaaS,产品是订阅制,官网和帮助文档用同一套前端框架做成了单页应用。早期靠投放和品牌词活得不错,后来想把自然流量做起来,写了几十篇功能讲解和使用场景的文档,半年下来长尾词几乎没有任何排名,团队一度以为是内容写得不够好,又补了一轮。
保哥介入后没看内容,先看原始HTML。结果一目了然:每个文档页服务器返回的都是同一个app shell,title还算正常,正文和文档之间的互链全靠浏览器执行JS之后从接口拉回来再渲染。再用平台工具看渲染后的样子,部分页面渲染后正文是有的,但相当一部分卡在“已抓取、尚未编入索引”,渲染明显没跟上;文档之间靠JS注入的链接也几乎没被发现,整个文档区像一盘散沙,没有内链结构可言。根因清清楚楚——不是内容问题,是这批页面的关键正文和链接从一开始就不在搜索引擎的第一眼里。
处理方式不复杂,但要动架构:把文档区从纯客户端渲染改成构建时静态生成加增量再生成,原始HTML里直接带全文和真实互链,robots不再挡渲染资源,决定收录的指令全部写死在服务端输出里。改完之后,先是“已抓取尚未编入索引”那批陆续转正,文档之间因为有了真实链接开始形成结构,长尾词逐步有了着陆点;额外的一个变化是,团队后来发现AI工具在回答相关问题时开始引用他们的文档——这正是因为原始HTML里终于有内容可抽了。这里不报具体涨幅,因为同期还做了别的事,把单一数字归因到这一项是不诚实的;但机制是确定的:内容回到第一眼里,搜索和AI才谈得上看见你。客户型上,这是个出海B2B工具站,不是常见的电商场景,但机制对任何重前端的站都一样成立。
哪些是反直觉、最容易踩的判断错误?
把这些单独列出来,因为它们听起来都“好像没问题”,恰恰最坑人。
- “Google能渲染,所以无所谓”——能渲染不等于及时渲染,不等于每次都成功,更不等于AI抓取器会渲染。能渲染只是下限,不是可以依赖的工程保证。
- “加了预渲染服务就一劳永逸”——预渲染服务会缓存陈旧内容、会把更新后的页面继续吐旧版、会在自己挂掉时静默返回空页、还可能给一个其实是404的页面回200。它需要被监控,不是装上就不用管。
- “我们上了SSR”——要追问一句:关键正文是在hydration之前就在原始HTML里,还是hydration之后才出现?后者等于没做SSR。
- 用井号路由当多个页面——井号后面的片段不会被当成独立URL,靠它区分的“多个页面”在搜索引擎眼里是同一个。
- 懒加载不留兜底——懒加载正文或图片却没有正确的原生属性、没有可被抓取的兜底标记,等于把这部分内容对爬虫藏起来。
- 把收录指令交给JS——noindex、canonical、跳转,凡是决定页面命运的,全部在服务端就定稿,绝不让客户端去改。
从客户端渲染迁到服务端直出,怎么分阶段不掉量?
认识到问题之后,最忌讳的是整站一刀切重构、一次性切上线。正确的做法是按价值和风险分阶段推进。
第一步,排优先级:先动那些既有搜索价值、渲染又受损最严重的模板——通常是详情页和靠它们撑长尾的列表页;登录后的控制台这种本来就不需要被搜索的,最后再说,甚至可以一直留客户端渲染。第二步,灰度而不是全量:先在一个模板、一部分流量上切服务端直出,用原始HTML与渲染后HTML的差异对比、覆盖率报告、关键词着陆情况盯一段时间,确认正文进了第一眼、收录在恢复,再往下一个模板推。第三步,留回滚:每一步都要能快速退回原状,并且在监控里盯住“已抓取尚未编入索引”的占比和核心模板的收录率,异常立刻停下来查。
还要和站点迁移这件事区分清楚:这里改的是同一批URL的渲染方式,URL本身不动,所以不该有大规模跳转,重点是验证内容有没有回到服务器响应里;如果同时还要改URL结构,那是另一件风险更大的事,必须分开做、分开验,别把渲染改造和地址变更搅在一起,否则一旦掉量根本分不清是哪头引起的。
上线前的JavaScript SEO验收,到底该卡哪几项?
把上面所有机制收敛成一份可执行的验收清单,重前端的站每次大改版前都该过一遍。
- 禁用JavaScript打开关键模板页(首页、列表页、详情页、文档页),正文核心段落、标题、描述是否完整存在。
- 原始HTML里的内部链接是不是真实的带href的a标签,而不是靠JS点击事件跳转。
- 决定收录的robots meta、canonical在原始响应里就是最终值,不依赖渲染。
- robots文件没有挡掉渲染必需的脚本、样式、接口路径。
- 用搜索平台工具看渲染后HTML与截图,与预期一致,无资源加载失败。
- 关键内容不依赖任何用户交互(点击、切换、滚动、表单)才出现。
- SSR场景下确认hydration不会替换或抖动关键正文。
- 结构化数据在原始HTML里就完整,不靠JS注入。
- 覆盖率报告里盯“已抓取尚未编入索引”的占比,异常升高就回查渲染。
- 定期抽样对比原始HTML与渲染后HTML的差异,把它做成监控而不是一次性检查。
原始和渲染后的差异,怎么变成持续监控而不是一次性体检?
上面那份验收清单解决的是“这次改版有没有问题”,但JS渲染问题最阴险的地方在于它会悄悄复发:一次没关系的依赖升级、一个改了缓存策略的接口、一段新加的第三方脚本,都可能让原本好好的页面重新退回空壳,而你毫不知情。所以真正稳的做法,是把原始与渲染后的差异检查做成跑在后台的持续监控,而不是上线那天测一次就再也不看。
落地起来并不复杂。挑出几类承担主要搜索价值的关键模板,定期对每类模板抽样几个真实URL,分别取它的原始HTML和渲染后HTML,比这么几个量:原始HTML里的正文字数与渲染后差多少、原始HTML里真实可抓的内部链接有几条、决定收录的robots与规范链接是不是预期值、结构化数据在不在、状态码对不对。给每个量设一个合理阈值,比如原始HTML正文字数低于渲染后某个比例就告警,内部链接数掉到某条线以下就告警。再把这套监控和搜索平台覆盖率报告里“已抓取尚未编入索引”的占比联动起来看,两边一起异常,基本就是渲染又出事了。
关键是这件事得有明确的人负责,而不是挂在某次专项里查完就散。它的成本很低,回报却是把一类会静默掉量、且往往要等流量掉了才被发现的问题,提前到发生当天就报警。对重前端的站来说,这套监控的优先级不该低于业务功能的可用性监控。
JS渲染问题,怎么和其他几种问题区分开,别认错?
排查时最怕把渲染问题误当成别的问题去治,方向一错越治越偏。给一个简单的区分法。
如果原始HTML里有完整正文,页面就是不收或排名差,那大概率不是渲染问题,要往内容质量、意图匹配、站点信任去查。如果原始HTML是空壳、渲染后才有内容,那是典型的JS渲染问题,按前面四刀走。如果是“页面太多、爬虫抓不过来、低质页面挤占资源”,那是抓取预算和索引膨胀的范畴,跟渲染是两件事,别混着治。如果是新站、新页面普遍要等很久才有名次且名次上下浮动,那更多是新站学习期的正常现象,渲染只是其中一个会放大它的因素,不是唯一原因。把这四类分清楚,才不会拿着渲染的锤子到处敲钉子。
常见问题解答
禁用JavaScript看到页面是空的,是不是SEO就一定完蛋?
不一定完蛋,但风险很高。它意味着你完全依赖搜索引擎的渲染队列来补内容,而队列有延迟、有预算、会静默失败,AI抓取器还基本不渲染。结论是:关键内容能在原始HTML里直出就别赌渲染。
动态渲染(给爬虫单独输出预渲染版)现在还能用吗?
能用但只作为旧站迁移期的临时过渡,不要当长久方案。它要维护用户和爬虫两套输出,时间一长几乎必然出现不一致,本身就踩在作弊判定边缘,官方也早不推荐。有条件就直接上服务端渲染或静态生成。
已经上了服务端渲染,为什么还是有页面不收录?
常见原因是hydration把关键正文替换或延后了、收录指令仍被客户端JS改写、或渲染必需资源被robots挡。验收标准要卡在“正文在hydration之前就完整存在于原始HTML”,而不是“服务器返回了HTML”这么宽。
单页应用想做好SEO,最优先改哪一件事?
优先保证每个需要被搜索的URL,其原始HTML里就有完整正文、正确标题描述和真实可抓的内部链接。路由要是真实URL不是井号片段。把这一件做扎实,比纠结具体框架重要得多。
怎么快速判断问题是出在渲染,还是出在内容质量?
看原始HTML:里面有完整正文却排名差,多半是内容、意图或信任问题;里面是空壳、要渲染后才有内容,那就是渲染问题。这一刀几乎能把方向定下来,再按对应路径深挖。
AI搜索时代,JS渲染这件事的优先级是升了还是降了?
明显升了。Googlebot还会渲染,但多数AI抓取器只看原始HTML、不跑浏览器。内容压在客户端JS里,等于同时放弃慢半拍的搜索收录和完全不渲染的AI引用,代价比纯搜索时代更大。
权威参考资料
本文标题:《JS渲染的页面Google抓不到,先从这几种情况查起》
本文链接:https://zhangwenbao.com/javascript-rendering-seo-csr-ssr-debugging.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0