网页体积越大排名越差?Google官方揭秘8策略
本文目录
- 你以为的页面大小可能根本不是同一个东西
- Googlebot的15MB抓取上限其实跟你无关
- 压缩让你看到的大小和实际传输大小不一样
- 内容与标记比率:大页面不等于臃肿页面
- 用户看不见的数据并不等于浪费
- 为什么给机器和人类分别提供不同内容行不通
- 网站大小与页面大小是两个层次的问题
- 八条可落地的页面性能优化策略
- AI搜索时代页面体积的新考量
- 这套体积逻辑搬到百度和国内网络环境,要重算哪几笔账
- 为了减体积把内容砍出血:4个"优化过头"的真实翻车
- 常见问题解答
- 页面大小会直接影响Google排名吗
- Googlebot抓取HTML页面有大小限制吗
- Brotli和Gzip压缩有什么区别应该用哪个
- 添加大量结构化数据会不会拖慢页面速度
- 如何判断我的页面是健康地大还是臃肿地大
- 移动端和桌面端的页面大小标准一样吗
- 为什么Google不支持让网站给机器和用户分别提供不同内容
- 页面体积优化应该优先做哪些事
- 权威参考资料
摘要:网页体积大到底会不会拖累排名?本文解析Google官方的最新表态——你以为的页面大小可能不是同一个东西、15MB抓取上限其实跟你无关、压缩后你看到的大小和实际传输不一样、内容与标记比率比绝对体积更重要,再给八条按投入产出比排序的页面性能优化策略和AI搜索时代的新考量。
你有没有这样的经历:用PageSpeed Insights跑完分,看到页面总大小飙到3MB甚至5MB,心里一阵发慌,开始疯狂删图片、砍JS、精简代码。然后排名还是没变化,甚至有些大页面反而排得更好。
这不是错觉。Google内部团队最近在官方播客中系统性地讨论了网页变大这个话题,给出的结论可能会让很多SEO从业者重新审视自己对页面大小的理解——网页变大这件事本身不是问题;问题在于你怎么理解"大",以及那些多出来的字节到底是什么。
保哥把这期播客的核心信息拆解出来,结合多年技术SEO实战经验,帮你彻底搞清楚页面大小与SEO的真实关系,并给出可以直接落地执行的8条优化策略。如果你想配套了解服务器配置层面对SEO的影响,建议先看 常见网站服务器配置对SEO的影响,里面覆盖了HTTP/2、CSP、缓存头等与页面性能直接相关的配置要点。
你以为的页面大小可能根本不是同一个东西
页面大小(Page Weight)是指用户加载某个页面时需要下载的全部数据总量,通常以KB或MB为单位。但这个看似简单的定义,在实际讨论中经常被混淆。Google的技术团队明确指出,讨论页面大小时首先要搞清楚一个前置问题:你测量的到底是什么?
| 测量维度 | 包含内容 | 典型大小范围 | 主要影响对象 |
|---|---|---|---|
| 纯HTML文档 | 仅HTML标记和文本内容 | 50KB-500KB | Googlebot抓取 |
| 传输大小 | 经过Brotli/Gzip压缩后通过网络传输的数据 | 原始大小的30%-60% | 网络带宽、TTFB |
| 完整页面加载 | HTML+CSS+JS+图片+字体+第三方脚本 | 1MB-10MB+ | 用户体验、Core Web Vitals |
| 解压后磁盘占用 | 浏览器解压后在设备上的实际占用 | 传输大小的1.5-3倍 | 设备内存、渲染性能 |
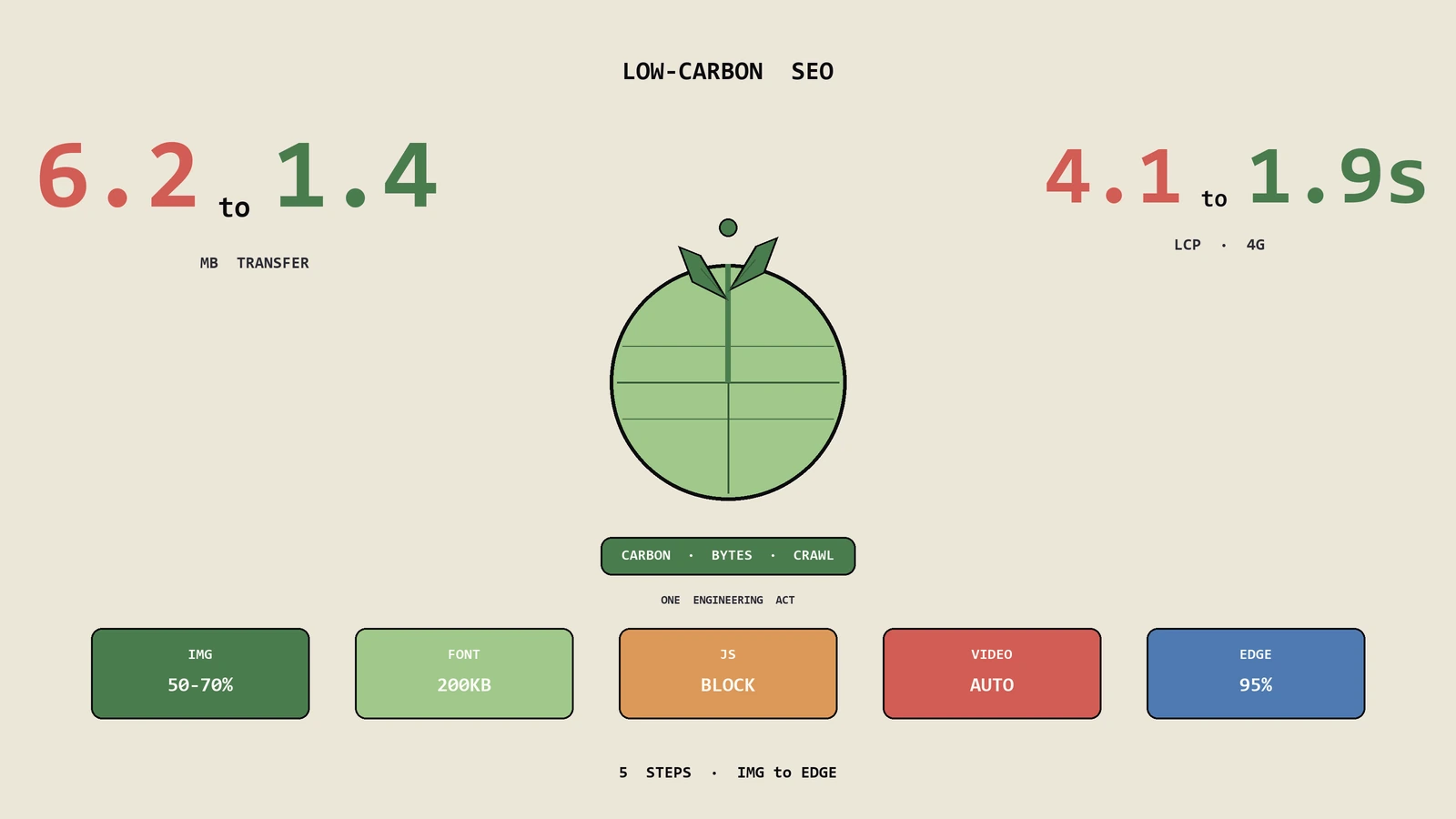
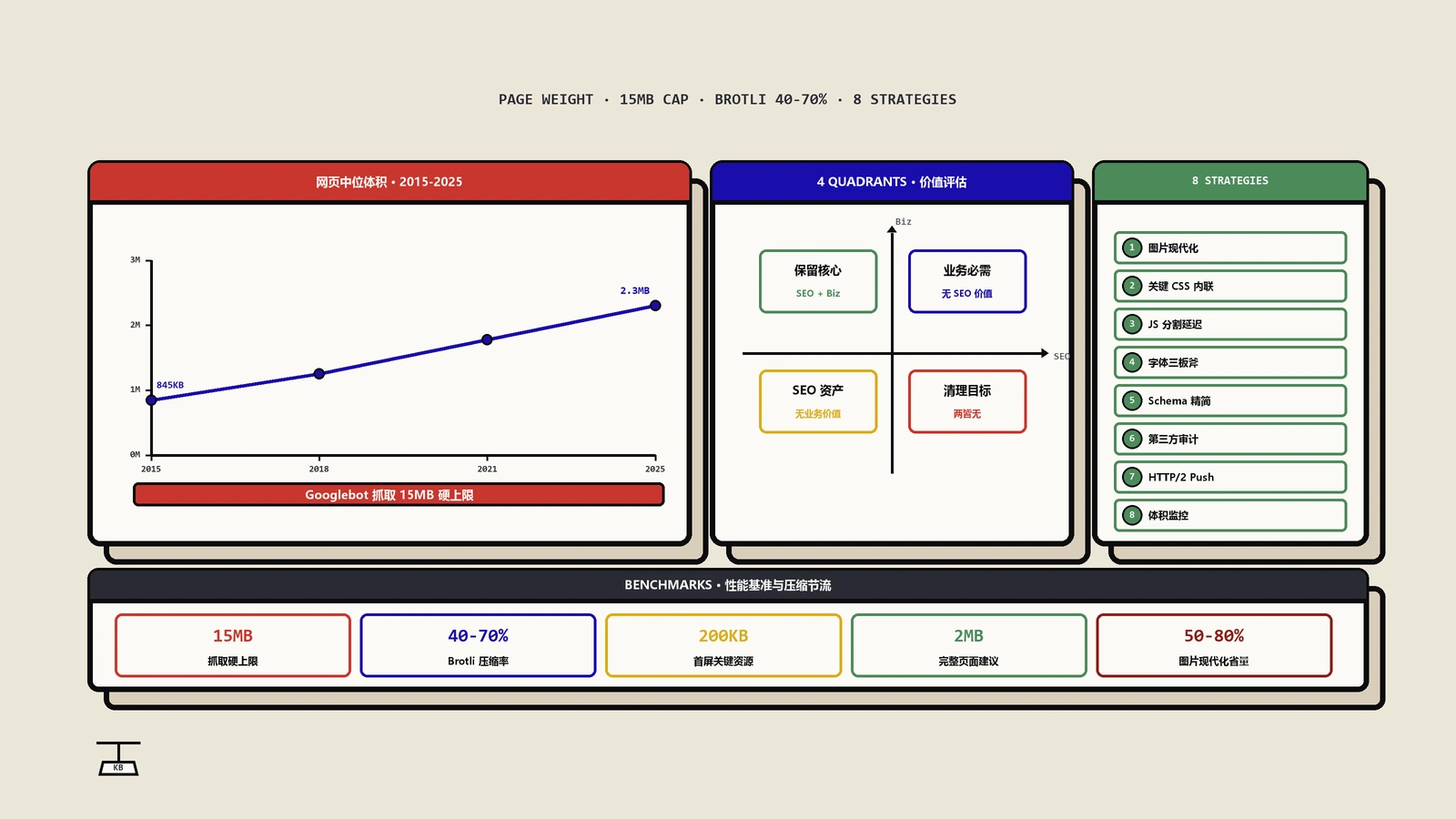
很多行业报告在谈论网页越来越大时,经常把这几个维度混在一起。比如说2015年网页中位数是845KB,到2025年已经涨到2.3MB——但这个数字到底是压缩前还是压缩后?包不包括图片?包不包括第三方脚本?不同的口径下,结论完全不同。这种混淆直接导致了一个常见的SEO误区:看到页面大就认为有问题。
Googlebot的15MB抓取上限其实跟你无关
一个经常被误解的技术细节:Googlebot对单个HTML文档的抓取上限约为15MB。但15MB的纯HTML意味着大约1500万个字符,相当于两本《哈利·波特》的字数。绝大多数网站的HTML文档远远达不到这个量级。
这个限制针对的是纯HTML内容,不包括CSS、JavaScript和图片。所以当你的PageSpeed Insights显示页面总大小3MB时,其中HTML可能只有200KB,离Googlebot的抓取上限差了几个数量级。真正需要关注的不是Googlebot能不能抓完你的页面,而是用户在实际网络环境下加载这个页面需要多长时间。这才是页面大小与SEO产生实质关联的地方。
压缩让你看到的大小和实际传输大小不一样
Brotli压缩是目前主流的Web内容压缩算法,由Google开发,能将HTML、CSS、JS等文本资源的传输体积缩减40%-70%。理解压缩对于正确评估页面大小至关重要。当你在浏览器开发者工具的Network面板中看到一个JavaScript文件大小为800KB时,它在网络上传输的实际数据量可能只有300KB,因为服务器端已经用Brotli或Gzip做了压缩。浏览器收到后再解压还原成800KB在本地执行。
这引出了一个有趣的模糊地带:你的网页到底是800KB还是300KB?答案取决于你的关注点:网络传输角度是300KB,这决定了下载速度;浏览器解析角度是800KB,这决定了CPU处理时间;用户磁盘角度是800KB,这决定了设备存储占用。
在技术SEO审计中,保哥建议同时关注这两个数字,但权重有所不同:传输大小直接影响First Contentful Paint(FCP),解压大小影响Total Blocking Time(TBT)。两者都是Core Web Vitals的关键因子。
检查你的网站是否开启了Brotli压缩很简单:打开Chrome开发者工具,切换到Network面板;刷新页面,点击任意HTML/CSS/JS资源;查看Response Headers中的Content-Encoding字段;如果显示br则为Brotli,显示gzip则为Gzip,如果没有这个字段则未开启压缩。
Nginx开启Brotli的核心配置:
brotli on;
brotli_comp_level 6;
brotli_types text/plain text/css application/json application/javascript text/xml application/xml text/javascript image/svg+xml;Apache开启Brotli的核心配置:
<IfModule mod_brotli.c>
AddOutputFilterByType BROTLI_COMPRESS text/html text/plain text/css application/javascript application/json
BrotliCompressionQuality 6
</IfModule>压缩级别建议设在4-6之间。级别越高压缩率越好,但CPU消耗也越大。对于动态生成的内容,过高的压缩级别会拖慢TTFB。
内容与标记比率:大页面不等于臃肿页面
这是Google此次讨论中最有价值的一个观点:评估页面大小是否合理,关键不在于绝对数值,而在于内容与标记的比率。
举个直观的例子:页面A是15MB,其中14MB是正文内容(长篇深度指南、数据表格、技术文档);页面B是5MB,其中4.5MB是第三方追踪脚本和广告代码,实际内容只有500KB。哪个页面更健康?显然是页面A。尽管它的绝对体积大三倍,但几乎所有数据都在为用户提供价值。
这个思路对SEO实操的指导意义非常大:不要盲目追求更小的页面体积,而是要识别和消除那些不为用户创造价值的体积膨胀源。
| 膨胀源类型 | 典型体积占比 | 排查方法 | 优化建议 |
|---|---|---|---|
| 未压缩图片 | 30%-60% | Lighthouse报告的Properly size images | 使用WebP/AVIF格式,实施响应式图片 |
| 未使用的CSS | 10%-30% | Chrome Coverage工具 | PurgeCSS清理,Critical CSS内联 |
| 未使用的JS | 15%-40% | Chrome Coverage工具 | Tree shaking、代码分割、延迟加载 |
| 第三方脚本 | 10%-25% | Lighthouse第三方脚本审计 | 评估ROI,延迟非关键脚本 |
| 内联SVG/Base64图片 | 5%-15% | HTML源码搜索 | 外部文件加CDN托管 |
| 冗余字体文件 | 5%-10% | Network面板按类型过滤 | 字体子集化,使用font-display:swap |
用户看不见的数据并不等于浪费
Google明确指出,现代网页中有相当一部分内容是给机器看的,不是给用户看的。最典型的例子就是结构化数据。如果你为一个产品页面实施了完整的Schema标记——包括Product、Offer、AggregateRating、FAQ、BreadcrumbList等类型——这些JSON-LD代码可能就有20-50KB。在一个只有100KB HTML的页面上,结构化数据就占了将近一半的页面大小。
但这是有价值的"胖"。结构化数据帮助搜索引擎理解页面内容,触发富媒体搜索结果,在AI搜索时代更是成为让你的内容被AI系统正确理解和引用的基础设施。关于这个话题, Schema聚合实战:WP站5步接入Agentic Web 有更深入的分析。除了结构化数据,页面中还常见这些隐形负载:监管合规标记(GDPR同意管理平台的脚本和配置)、无障碍辅助标记(ARIA属性、跳转导航、屏幕阅读器专用内容)、分析与追踪代码(Google Analytics、热力图工具、A/B测试脚本)、广告管理脚本(Google Ad Manager、头部竞价脚本)、社交分享元数据(Open Graph标签、Twitter Card标签)。
这些数据中,有些是为合规必须存在的,有些是为商业目的存在的,有些是为改善用户体验间接存在的。不能简单地因为用户看不见就认为它们是累赘。
保哥在做技术SEO审计时,会用一个简单的四象限模型来评估每一项隐形负载:
| 对SEO有价值 | 对SEO无价值 | |
|---|---|---|
| 对业务有价值 | 结构化数据、Analytics | 内部管理工具脚本 |
| 对业务无价值 | 无障碍标记(间接有价值) | 已废弃的追踪代码 |
右下角那个象限——既对SEO没帮助、对业务也没用的脚本——才是你真正应该清理的目标。常见的例子包括:早已不用的旧版Analytics代码、已经下线的A/B测试残留脚本、失效的社交分享插件等。
为什么给机器和人类分别提供不同内容行不通
这是一个非常有意思的讨论。既然页面里有那么多是给机器看的数据,为什么不干脆把机器需要的内容和用户需要的内容分开?给Googlebot一份精简的机器可读版本,给用户一份完整的展示版本?Google对此的态度非常明确:这是一个乌托邦式的想法,在现实中行不通。原因有三:
- 垃圾信息会爆炸:Google每天要处理数十亿条垃圾URL。如果允许网站提供单独的机器版本,垃圾网站就可以给搜索引擎展示完美优化的内容,给用户展示垃圾内容或者钓鱼页面。这正是Cloaking(内容隐藏)手法的升级版,Google绝不会接受。
- 两套内容必然产生差异:Google在推行移动优先索引时就吃过这个亏。当年很多网站维护桌面版和移动版两套页面,结果两套内容经常不同步——桌面版有的内容移动版没有,用户通过手机搜索找到的结果点进去发现内容根本不存在。Google花了好几年才把整个生态迁移到统一的移动优先索引模式。
- 维护成本不可持续:长期维护两套内容的技术成本和人力成本极高,绝大多数网站根本做不到持续同步更新。
虽然Google没有直接提及,但这个逻辑也解释了Google为什么对llms.txt提案保持谨慎态度。llms.txt的核心理念就是给AI系统提供一个独立于网页内容的机器可读入口,而Google的历史经验告诉它,任何双轨制内容方案最终都会被滥用。因此搜索引擎生态已经稳定在单文档模型上——一个页面就是一个页面,机器和人看到的是同一份内容,即使这意味着页面会更大一些。
网站大小与页面大小是两个层次的问题
Google的讨论中有一个容易被忽略但非常重要的区分:网站层面的大小(页面总数)和单个页面层面的大小(每个页面的体积)是两个完全不同的问题。网站的页面总数增加,对SEO而言几乎没有直接的负面影响,只要每个页面都有独立的价值。一个拥有10万个产品页面的电商站点不会因为网站太大而受到惩罚。
真正需要关注的是单个页面的体积,因为这直接影响用户体验指标。但即便如此,影响的链条也不是"页面大→排名差"这么简单,而是"页面大→加载慢→用户体验差→可能影响排名"。这个因果链中的每一环都有变量:页面大不一定加载慢(如果用了CDN、Brotli压缩、HTTP/2多路复用,大页面也可以加载很快);加载慢不一定用户体验差(如果关键内容先渲染——Critical Rendering Path优化,用户感知的速度可能很快);用户体验差对排名有影响但Core Web Vitals只是众多排名信号之一,内容质量和相关性的权重远远更高。
八条可落地的页面性能优化策略
基于以上分析,保哥总结了8个从投入产出比最高到最低排列的优化策略。
图片格式现代化:这是绝大多数网站投入产出比最高的优化项。将JPEG/PNG全部转换为WebP或AVIF格式,体积通常可以缩减50%-80%。具体操作:使用Screaming Frog爬取全站,导出所有图片URL和格式;按图片大小降序排列,优先处理体积最大的图片;使用picture标签实现格式降级(avif→webp→jpg);在CDN层面配置自动格式转换(Cloudflare Polish、AWS CloudFront等都支持)。
关键CSS内联与非关键CSS延迟加载:首屏渲染所需的CSS直接内联到HTML的head中,其余CSS异步加载。这能显著改善Largest Contentful Paint(LCP)。具体写法是用 link rel="preload" as="style" onload切换为stylesheet 的延迟激活模式。
JavaScript代码分割与延迟执行:将非首屏交互所需的JS全部标记为defer或async,并使用动态import()实现按需加载。非关键第三方脚本(如热力图、推荐插件)可以延迟3秒后再触发加载,绝大多数用户在首屏阶段感知不到差别。
字体优化三板斧:字体子集化(如果只用了英文字体的拉丁字符集,用unicode-range限制加载范围);font-display: swap确保字体加载期间用系统字体显示文字,避免FOIT;预加载关键字体使用 link rel="preload" as="font" crossorigin。
结构化数据精简但不删减:不要为了减小页面体积而删除结构化数据。相反应该确保JSON-LD代码经过压缩(去除多余空白和换行)、避免在结构化数据中嵌入大段冗余描述、使用@id引用避免重复声明相同实体、定期用Google Rich Results Test验证有效性。
第三方脚本审计与管控:建立第三方脚本清单,对每个脚本评估它的商业价值是什么、它增加了多少页面体积、它对Core Web Vitals的影响有多大、能否用更轻量的替代方案。特别注意:很多网站的Google Tag Manager容器里积累了大量已经不再使用的标签,这些都是应该定期清理的死代码。
实施HTTP/2 Server Push或103 Early Hints:HTTP/2 Server Push允许服务器在浏览器请求HTML时就主动推送关键的CSS和JS文件,减少往返延迟。更现代的方案是使用103 Early Hints响应头,让CDN在源服务器处理请求的同时就开始向浏览器发送资源提示。
建立页面体积监控体系:用Lighthouse CI(在CI/CD流水线中设置性能预算,页面体积超标自动报警)、Web Vitals Chrome Extension(日常快速检查Core Web Vitals)、Google Search Console的Core Web Vitals报告(监控全站性能趋势)、HTTPArchive/CrUX(对比你的网站与行业基准)。
AI搜索时代页面体积的新考量
随着Google AI Overviews、ChatGPT Search、Perplexity等AI搜索引擎的兴起,页面体积问题有了新的维度。AI爬虫的抓取行为与传统搜索引擎爬虫不同。部分AI爬虫对单页的抓取频率更高、对页面内容的解析深度更大。这意味着:
- 结构化数据的重要性进一步提升。AI系统比传统搜索引擎更依赖结构化数据来理解内容语义,为此增加的页面体积是值得的。
- 内容的信息密度比页面体积更重要。AI系统倾向于引用信息密度高、定义清晰、观点明确的内容,而不是冗长但空洞的文章。
- 爬虫流量对服务器的压力增大。如果你的服务器带宽有限,大页面加高频AI爬虫访问可能导致服务器响应变慢,进而影响所有用户的访问体验。
核心观点一句话总结:页面大小本身不是SEO问题。你需要关注的是每一个字节是否在为用户或为帮助用户找到你的内容创造价值。如果是,那页面大一点完全没问题;如果不是,哪怕只大了1KB,也是浪费。
这套体积逻辑搬到百度和国内网络环境,要重算哪几笔账
前面拆的都是 Google 的口径——15MB 抓取上限、Brotli、Core Web Vitals。可保哥的客户里有一大半主战场在国内,盯的是百度收录和移动端访问速度。同样"页面大小本身不是问题"的结论成立,但有几笔账,到了百度和国内的网络现实里得重新算一遍,照搬海外那套优化优先级,你会把力气使错地方。
第一笔账是百度对速度的态度,比 Google 直接得多。Google 一直强调速度只是"间接信号",藏在 Core Web Vitals 后面。百度不绕弯子——2017 年就上线了"闪电算法",白纸黑字写明移动端首屏在 2 秒内打开的页面给加权、3 秒以上的降权。这是把首屏速度当成了明面上的排名因子,不像 Google 那样裹着一层。所以在国内站点上,移动端首屏速度的优先级,要比海外文章里给的排序再往前提一格——它直接挂钩百度的移动排名,不是"可能间接影响"。
第二笔账更有意思,是百度自己用一段历史,给文中那个"双轨制内容必出问题"的论断盖了章。百度当年推过 MIP,思路和 AMP 一样,让你给移动端单独做一套精简的机器友好页面。结果跟 Google 移动优先索引时踩的坑一模一样:大量站点的 MIP 版和原版内容不同步,用户搜到的和点进去看到的对不上,维护成本高到没人扛得住,最后百度自己也把 MIP 收缩淡出了。这正好印证了原文的核心观点——任何"给机器一份、给用户一份"的双轨方案,无论 Google 还是百度,最终都会被内容漂移和滥用拖垮。所以别动给百度蜘蛛单独喂精简页的念头,那条路百度自己已经走不通了。
第三笔账是中文站独有的体积大头,海外文章几乎不提——中文字体。一套完整的中文字体动辄就是体积黑洞,思源黑体的 full 版本单个字重就 20MB 上下,哪怕压缩、哪怕拆字重,没做子集化也是好几 MB 砸在那里。英文站点用的拉丁字体本来就小,所以海外谈减体积,第一刀永远砍在图片上。中文站不一样,字体子集化——按页面实际用到的那些字裁出一个最小集——往往是减体积投入产出比最高的一刀,比删图还狠。保哥的经验是,一个中文内容站如果从没做过字体子集化,光这一项就能把字体的传输体积从几 MB 压到几十 KB。这件事在海外的优化清单里排不上号,在国内得排到前列。
第四笔账是国内的网络现实——备案和 CDN。海外站点习惯挂 Cloudflare,免费、免备案、全球节点。可 Cloudflare 的免备案节点在国内访问又慢又不稳,真要让国内用户快,得用国内 CDN,而国内 CDN 要 ICP 备案。这意味着同样一个 3MB 的页面,挂着海外 CDN 给国内用户看,首屏可能要等好几秒;换成国内备案 CDN 就顺畅。所以在国内的带宽和节点现实下,体积优化比海外更刚需——你没有"全球 CDN 兜底"这个奢侈前提。日常看速度也别只盯 Lighthouse,国内多用百度统计里的"页面加载速度"报告,它取的是真实国内用户的访问样本,比模拟环境更贴合你的实际访客。
最后一笔是中文 AI 的抓取。豆包、DeepSeek 这些中文 AI,对结构化数据和信息密度的偏好和 Google 系一致,所以"结构化数据该留就留、别为减体积删掉"这条在中文 AI 时代同样成立。差异在于,国内 AI 爬虫对备案、对国内 CDN 上的站点抓取更顺畅——一个挂在国内节点、备案齐全的站点,被中文 AI 稳定抓取和引用的概率,明显高于一个国内访问就时断时续的海外节点站点。这也是为什么国内站点把"用国内备案 CDN"当成基础设施,不只是给用户快,也是给中文 AI 爬虫留一条顺畅的路。
为了减体积把内容砍出血:4个"优化过头"的真实翻车
页面体积优化是做减法的手术,刀下去之前得先分清哪些是脂肪、哪些是肌肉。保哥做技术审计时见过太多"优化过头"反而把站点搞坏的案例,挑四个最典型、也最容易犯的列出来,对照着避坑。
第一个翻车,图片懒加载一刀切。团队听说懒加载能省体积、能提速,就给全站所有图片无差别加上 lazy load,包括首屏第一眼就能看到的主图。结果适得其反——首屏那张大图本来该立刻加载,被懒加载推迟到"滚动时再触发",Largest Contentful Paint 不降反升,移动端打分掉了一截。正确做法是首屏可见的关键图必须 eager 加载、甚至 preload 预加载,懒加载只用在折叠线以下、需要滚动才看得到的图片上。懒加载是省流量的好工具,但对着首屏 LCP 元素用,等于自己拖慢自己。
第二个翻车,为了"精简"把结构化数据删了。有个客户嫌 JSON-LD 占了几十 KB,做体积优化时顺手清掉了一批 Schema 标记。几 KB 是省下了,代价是富媒体搜索结果的资格、AI 引用时的语义理解基础,一起没了。这恰恰撞上了原文反复强调的那一点——结构化数据是"有价值的胖",经过压缩后传输体积本来就只剩几 KB,省它纯属捡了芝麻丢了西瓜。体积优化的清单里,结构化数据应该被明确标成"不许动",要动也只是压缩格式、去掉多余空白,绝不是删减条目。
第三个翻车,Brotli 压缩级别拉满。有运维一看 Brotli 最高支持到 11 级,想着"既然要压就压到极致",直接把动态页面的压缩级别设成 11。结果服务器 CPU 被压缩计算打满,首字节时间 TTFB 飙升——浏览器还在干等服务器把页面压缩完。省下的那点传输时间,远远抵不过 TTFB 多出来的延迟,整体反而更慢。原文提的 4 到 6 级才是动态内容的甜区。真正的做法是分开对待:动态生成的 HTML 用 4 到 6 级,平衡 CPU 和压缩率;静态资源像 CSS、JS、字体,可以在构建阶段就预压缩到 11 级存好,反正只压一次、之后直接发,CPU 成本一次性付清。
第四个翻车,JavaScript 全部 defer、async 一刀切。团队为了首屏提速,把页面上所有脚本无差别加上延迟标记。问题来了——脚本之间是有依赖顺序的,无差别延迟会让依赖关系错乱,关键的交互脚本(加入购物车、表单提交、支付校验)在它依赖的库还没就绪时就执行,直接报错。用户点了加购没反应、填了表单提交不了,转化路径当场断掉。体积是优化了,生意没了。延迟加载必须分级:纯展示型、非首屏交互的第三方脚本(热力图、推荐插件、客服弹窗)可以大胆延迟,但承载核心转化动作的交互脚本,要保证它和它的依赖按正确顺序、在用户可能触发交互之前就绪,绝不能盲目甩进延迟队列。
这四个翻车有个共同点:都是把"减体积"当成了目的本身,而忘了体积优化的真正目标是更快、更好的用户体验和搜索表现。脂肪要减,肌肉不能动;该快的地方(首屏图、关键脚本)不能为了省体积去拖慢,该留的东西(结构化数据)不能为了好看的数字去删。下刀之前先问一句:这一刀砍下去,省的是用户根本看不见的浪费,还是用户和搜索引擎都需要的价值?想清楚了再动手。
常见问题解答
页面大小会直接影响Google排名吗
页面大小不是Google的直接排名因素。但页面大小会间接影响排名,因为它通过影响加载速度来影响Core Web Vitals指标(如LCP和FID),而Core Web Vitals是排名信号之一。不过,内容质量和相关性的权重远高于页面速度,所以不必为了缩减几KB而牺牲内容深度。简单说:内容写好、压缩开起来、图片格式现代化,这三件事做完页面大小已经在合理区间,剩下的精力放在内容深度上回报更高。
Googlebot抓取HTML页面有大小限制吗
有。Googlebot对单个HTML文档的抓取上限约为15MB。但这仅指纯HTML内容,不包括CSS、JavaScript和图片。15MB的HTML约等于1500万个字符,正常网页几乎不可能达到这个上限。如果你的HTML确实接近这个值,通常说明存在代码生成错误或内容管理问题——比如把整篇文章库都内联到了首页、或者后端把日志输出当作了内容。
Brotli和Gzip压缩有什么区别应该用哪个
Brotli是Google开发的更现代的压缩算法,相比Gzip在同等CPU消耗下能提供额外10%-25%的压缩率。目前所有现代浏览器都支持Brotli。建议优先使用Brotli,对于不支持Brotli的旧浏览器自动降级到Gzip。大多数CDN服务商(如Cloudflare、AWS CloudFront)默认已经支持Brotli。源服务器和CDN层最好都开启,避免回源时降级到无压缩。
添加大量结构化数据会不会拖慢页面速度
结构化数据通常以JSON-LD格式放在HTML中,属于文本内容,经过Brotli压缩后体积很小。一个完整的Product+FAQ结构化数据块经过压缩后通常只有5-15KB的传输体积,对加载速度的影响可以忽略不计。相比它带来的搜索可见性提升和AI搜索引用优势,这点体积增加完全值得。注意:JSON-LD要尽量放在head里或body末尾,避免阻塞首屏渲染。
如何判断我的页面是健康地大还是臃肿地大
最直接的方法是使用Chrome DevTools的Coverage工具。它会告诉你CSS和JS文件中有多少代码实际被当前页面使用。如果超过50%的CSS和30%的JS未被使用,说明存在明显的代码冗余。另外,如果页面的纯内容(去掉所有标记和脚本后的可见文字)只占HTML总大小的10%以下,也值得深入排查。
移动端和桌面端的页面大小标准一样吗
Google采用移动优先索引,意味着它抓取和评估的是你的移动版页面。移动设备的网络环境通常不如桌面环境稳定,CPU处理能力也更弱,因此移动端页面对体积更加敏感。建议移动端首屏关键资源控制在200KB以内(压缩后),完整页面加载控制在2MB以内。Lighthouse移动端测试默认模拟4G网络+中端Android设备,这个标准已经足够严苛。
为什么Google不支持让网站给机器和用户分别提供不同内容
因为这会被垃圾网站大规模滥用。Google每天处理数十亿条垃圾URL,如果允许双轨制内容,垃圾网站就可以给搜索引擎展示优化过的虚假内容,给用户展示完全不同的劣质页面。Google在移动端/桌面端分离时代已经吃过类似的亏,所以坚持单文档模型。对站长来说,这意味着不要试图用User-Agent判断来给爬虫和用户返回不同内容——Google会判定为Cloaking并降权。
页面体积优化应该优先做哪些事
按投入产出比排序:第一,将图片转换为WebP/AVIF格式(通常可减少50%以上体积);第二,开启Brotli压缩(如果还没开启的话);第三,清理未使用的CSS和JS代码;第四,延迟加载非关键第三方脚本。这四项做完,大多数网站的页面体积可以减少40%-60%,Core Web Vitals也会有明显改善。再往后追求更细的字体子集化、HTTP/2 Server Push等优化,回报会显著下降。
权威参考资料
本文标题:《网页体积越大排名越差?Google官方揭秘8策略》
本文链接:https://zhangwenbao.com/page-weight-seo-truth.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0