llms.txt到底有没有用?10个站90天实测给的答案
本文目录
- llms.txt到底解决了什么问题?
- llms.txt和llms-full.txt有什么区别?
- llms.txt的标准格式长什么样?
- 不写代码,怎么手动生成一份llms.txt?
- WordPress和Shopify怎么部署llms.txt?
- 其它框架怎么集成,三个文件怎么协同?
- llms.txt到底有没有用?把实测证据摆出来
- 那token效率这个理由,到底站不站得住?
- llms.txt是sitemap,不是增长策略
- Google官方又把llms.txt的口径松了一档,这会不会推翻前面的结论?
- 那llms.txt还要不要做?给你一个决策框架
- 顺手做的话,怎么把它做对?
- 万一以后AI厂商正式采纳了,现在不做会不会踏空?
- 不同类型的网站,侧重点怎么调?
- 怎么自己验证llms.txt到底有没有被AI取过?
- 那几个钟头不投llms.txt,该投到哪几件事上?
- 其它框架和自建站怎么集成llms.txt?
- 给每页配.md版本,到底怎么落地、值不值得?
- 常见问题解答
- 权威参考资料
摘要:llms.txt该不该做,答案是“成本极低,可以顺手做,但别指望它带量”。有人跟踪了一批站点几个月,部署llms.txt后绝大多数毫无变化,少数几个涨了的,真正起作用的是公关背书、能被抽取的对比表和FAQ、可下载资产,跟那个文件没关系;Google那边也明说过,没有哪个AI服务声明在用它,看服务器日志连请求都不去请求。所以这篇既手把手教你写和部署llms.txt与llms-full.txt(含WordPress、Shopify四方案、各类框架),也老实告诉你它的真实天花板在哪、什么场景才真值得投入、以及把那几个钟头花在哪里回报更高。把它当sitemap那样的基础设施看,不要当成增长策略。
2024年9月,Answer.AI创始人Jeremy Howard提了一个看着简单却很有意思的提案:在网站根目录放一个叫llms.txt的Markdown文件,专门写给AI大语言模型看。背景很现实——AI工具正在成为越来越多人获取信息的主入口,但大多数网站是给人看的,导航、广告、JavaScript渲染的动态内容一大堆,AI要从这些噪音里扒出有价值的信息,又费劲又容易出错。
保哥一直盯GEO(生成式搜索优化)这块的动静。llms.txt这个标准从提出到现在,争议一直很大:一边说它是喂给AI的藏宝图,一边说它是浪费时间的自嗨。这篇文章不站队,先把它从概念到部署一次讲透,再用实测证据告诉你它到底值不值得做、值得做到什么程度。
llms.txt到底解决了什么问题?
先搞清一个核心矛盾:AI模型的上下文窗口是有限的。哪怕最新模型能吃十几万token,面对一个动辄几百上千页的网站,全量灌进去既不现实也没必要。
传统的sitemap.xml告诉搜索引擎“我有哪些页面”,robots.txt告诉爬虫“哪些能抓哪些不能抓”,但这两个文件都没回答一个关键问题:如果AI只能看你网站的一小部分,它该看哪些?llms.txt就是来回答这个的——它本质上是一份由网站作者亲手策划的内容导航,用Markdown告诉AI:这些是我这儿最重要、最值得你了解的页面和信息。
打个比方:把网站比作图书馆,sitemap.xml是完整馆藏目录,robots.txt是“禁止入内”的门牌,llms.txt则是管理员给你列的一份推荐书单。
llms.txt和llms-full.txt有什么区别?
实际应用里这俩通常搭配用,各有分工。llms.txt是轻量导航文件,只包含网站结构概览和关键页面链接列表,像一份带注释的目录,AI快速扫一眼就知道你是做什么的、有哪些重要内容,再按需去抓具体页面。llms-full.txt是重量级全量文件,把llms.txt里列出的所有关键页面的完整内容直接整合进一个文件,AI不用再逐个抓链接,一次请求拿到全部核心信息。
关系可以这样理解:llms.txt是菜单,llms-full.txt是把菜全端上来了。建议两个都做——llms.txt满足快速扫描,llms-full.txt满足深度理解。
llms.txt的标准格式长什么样?
llms.txt遵循一套明确的Markdown结构,放在根目录,通过域名加斜杠llms.txt访问。按顺序:第一部分是H1标题(必填),网站或项目名称,这是整个文件唯一必填项;第二部分是引用块摘要(建议填),用Markdown的引用语法写一段简短项目概述;第三部分是详细说明(可选),段落或列表,但不能用标题标签;第四部分是分类链接列表(核心内容),用H2分组,每个链接用标准Markdown超链接格式,后面可加冒号和说明;特殊的Optional段落表示上下文受限时这些链接可被跳过。
一个标准文件长这样:
# 你的品牌名
> 一句话概括你的网站做什么,核心价值是什么。
附加说明:技术栈、适用人群、使用注意事项等。
## 核心文档
- [产品介绍](https://example.com/about): 公司和产品的完整介绍
- [使用指南](https://example.com/docs/guide): 从零开始的入门教程
- [API文档](https://example.com/api): 完整的API参考手册
## 常见问题
- [FAQ](https://example.com/faq): 用户最常问的问题和解答
- [定价方案](https://example.com/pricing): 各套餐对比和价格说明
## Optional
- [团队介绍](https://example.com/team): 核心团队成员背景
- [博客](https://example.com/blog): 产品更新和行业分析llms-full.txt保留同样的组织框架,但在每个链接下面直接展开完整页面内容,H2对应大分类,H3对应每个文档标题。编写要点:每个文档内容要干净,去掉导航、页脚、侧边栏这些框架元素只留正文;某些页面特别长可以适当精简保留核心;整个文件体积要控制在合理范围。
不写代码,怎么手动生成一份llms.txt?
页面不多的网站,手动写最直接,按这五步走。第一步,梳理内容优先级:列出所有你认为AI必须了解的页面,通常是关于我们、核心产品或服务页、文档帮助中心、定价页、常见问题页、联系方式。第二步,按逻辑分组:按主题归类,每个分组就是一个H2段落。第三步,为每个链接写一句话描述,言简意赅,帮AI判断要不要进一步访问。第四步,用任意文本编辑器创建文件命名为llms.txt,上传到根目录,确认浏览器能正常打开。第五步,验证状态:HTTP状态码返回200、编码UTF-8、Markdown格式正确渲染。
页面多的网站手动太低效,可以用自动化方案:有在线生成器输入网址爬取后用模型提取关键信息生成两个文件;用Mintlify、GitBook这类文档平台会自动生成并托管,零配置。但自动生成的文件必须人工审核——工具不懂你的业务优先级,会漏掉重要页面或塞进无关内容。正确姿势是先用工具生成骨架,再手动精雕。
WordPress和Shopify怎么部署llms.txt?
WordPress最省事:部分主流SEO插件的较新版本已内置llms.txt自动生成,启用后自动检测最新文章、关键文档和重要页面生成文件,并通过定时任务定期更新,还会自动过滤掉noindex或被robots.txt屏蔽的页面;也有专门的llms.txt插件,控制更精细,能选内容类型、控制每篇字数、手动触发重新生成。已经在用某个SEO插件就直接启用它的功能,需要精细控制或用其它插件就上专用插件。
Shopify麻烦在它的托管架构不允许你直接往根目录扔文件,没有FTP权限。下面按从简单到高级给四个方案:
方案一,应用商店的llms.txt生成应用(最省事)。自动读取店铺产品、集合、博客、页面信息生成文件并通过应用代理路径托管。共同局限是生成的文件URL通常不在根目录,规范要求文件在根路径,所以装完还要在后台的URL重定向里建一条从根路径llms.txt到应用实际路径的重定向,很多应用不会自动帮你做。
方案二,Liquid模板方案(零成本但要动手)。思路是创建一个自定义页面模板输出纯Markdown内容,再用URL重定向把根路径llms.txt指过去。进后台编辑代码新建一个模板,用Liquid动态拉店铺信息——用店铺名作H1、店铺描述生成摘要,遍历产品和博客文章按规范格式输出链接和描述,注意把内容类型设成纯文本而不是HTML。再建一个Handle为llms的页面套这个模板,最后建从根路径llms.txt到该页面的重定向。优点是免费且内容随店铺自动更新,缺点是要点Liquid基础、调试要耐心。
方案三,Cloudflare Workers边缘代理(最规范)。如果你的Shopify已经走Cloudflare做DNS代理,这是最推荐的方案,能让根路径llms.txt真正出现、不用任何重定向。原理是Worker在请求到达Shopify前拦截,访问llms.txt就直接返回你预设内容,其它请求正常转发:
export default {
async fetch(request) {
const url = new URL(request.url);
if (url.pathname === "/llms.txt" || url.pathname === "/llms.txt/") {
const body = "# 你的店铺名称\n> 你的店铺一句话描述\n\n## 产品\n- [产品分类1](https://example.com/collections/xxx): 分类描述\n\n## 资源\n- [博客](https://example.com/blogs/news): 产品指南和行业资讯";
return new Response(body, {
status: 200,
headers: {
"Content-Type": "text/plain; charset=utf-8",
"Cache-Control": "public, max-age=86400"
}
});
}
return fetch(request);
}
};部署后访问根路径llms.txt直接返回纯文本、状态码200,Shopify端完全无感,技术上最干净。方案四,手动上传到Files再重定向(应急):本地写好文件传到后台文件区拿到CDN链接,再把根路径llms.txt重定向过去。能用但有硬伤——CDN域名不是你的、重定向会跳转而非保持原路径、每次更新要重传,只建议临时过渡。
内容上,Shopify的llms.txt第一优先级是核心产品集合页(代表你的商品分类结构),其次是购物指南和产品对比类博客,再是退换货、物流、FAQ这类信任建设页,品牌故事放Optional。别把所有单品页都列出来,用集合页代替单品页,让AI通过集合入口了解产品线效率更高。
其它框架怎么集成,三个文件怎么协同?
不同技术栈各有插件或Recipe:静态文档框架(如VitePress、Docusaurus)有对应插件从文档自动生成;部分文档平台开箱即用并为每页提供Markdown版本;自建站(Next.js、React等)在构建流程里读取页面元数据按规范输出到public目录的llms.txt,部署时自动落到根目录。
llms.txt、robots.txt、sitemap.xml三者各司其职:robots.txt管访问控制(谁能来、哪些不许抓),sitemap.xml管完整索引(所有公开页URL与更新频率),llms.txt管内容策划(从全部页面里精选最值得AI理解的核心)。一个重要逻辑关系:llms.txt里列出的页面,必须在robots.txt里对AI爬虫开放访问,否则自相矛盾,配置时要做一次交叉检查。还可以在robots.txt里加上文件引用方便发现:
User-agent: *
Allow: /
Sitemap: https://example.com/sitemap.xml同时确保llms.txt路径返回200、没被CDN缓存策略意外屏蔽。
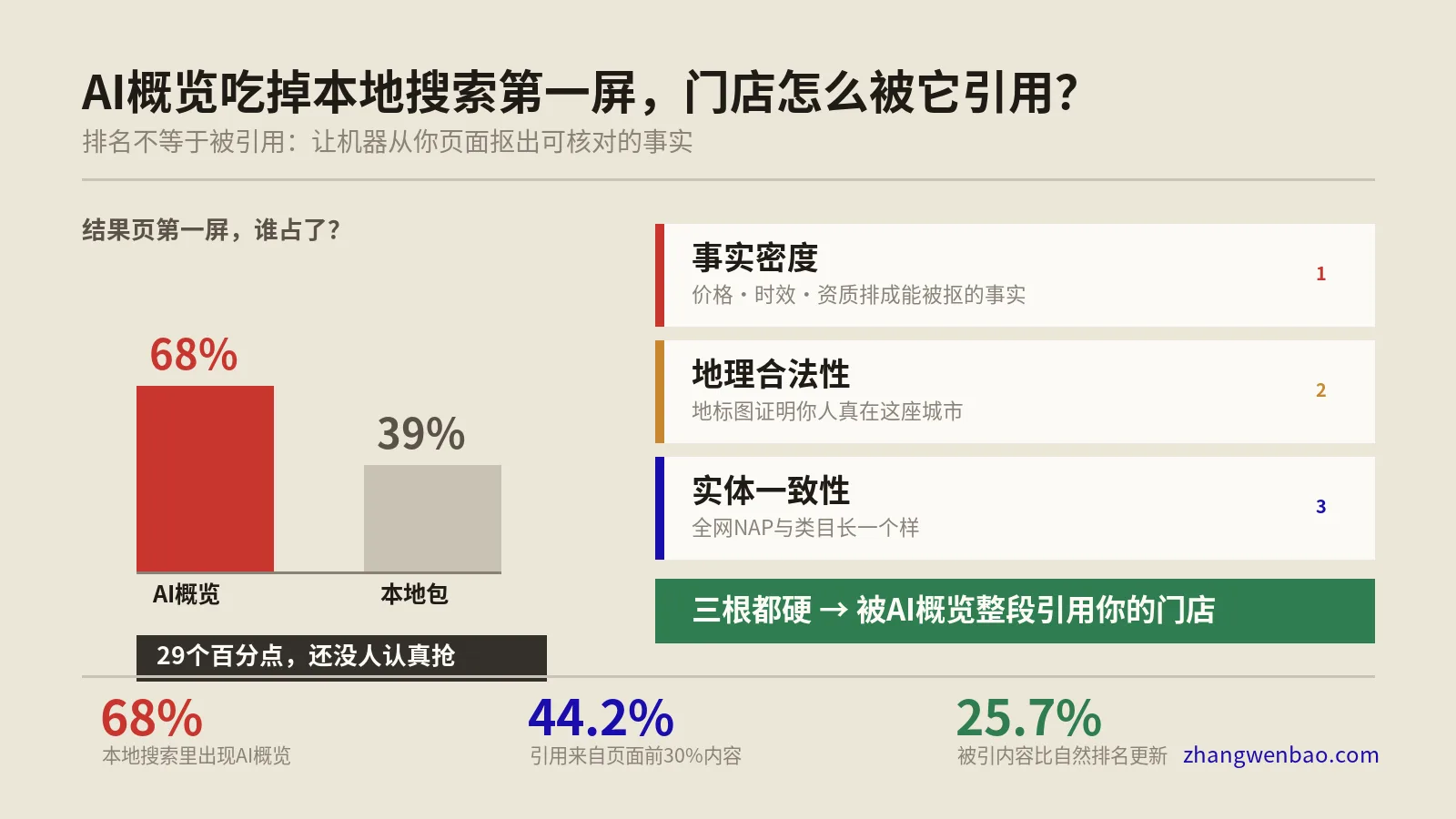
llms.txt到底有没有用?把实测证据摆出来
讲完怎么做,保哥得讲真话——前面教的全部,加起来对你AI可见度的真实贡献,可能比你以为的小得多。这不是泼冷水,是怕你把有限的时间押错地方。
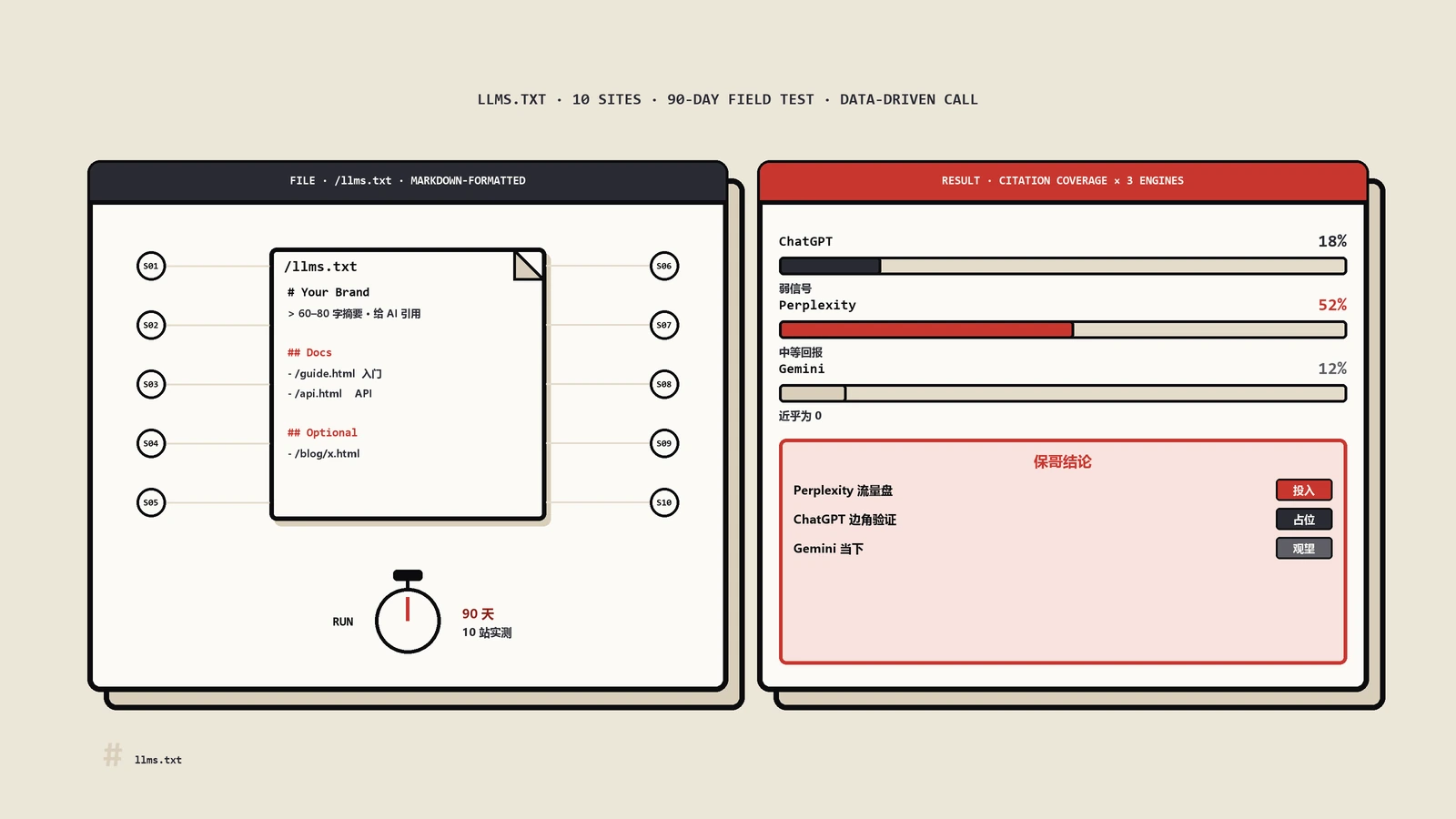
有人做过一个挺扎实的实测:跟踪一批不同类型的站点,连续约三个月,观察部署llms.txt前后AI带来的变化。结果很冷静——绝大多数站点没有任何可测的变化;有少数几个站AI侧确实涨了,但拆开看,真正起作用的根本不是那个文件。
一个涨得比较明显的金融科技站,同期还干了一堆别的事:拿到牌照后的公关报道、把产品页重构成可被直接抽取的对比表、新增了一批FAQ页、重建资源中心、修了一堆技术SEO问题。另一个B2B SaaS站的增长甚至发生在它上线llms.txt三周之前,真正的推手是它放出去的一批可下载的实用模板,模板页的自然流量在观察期里明显上涨。换句话说,把这两个站的“成功”记到llms.txt头上,是典型的把相关当因果。剩下大部分站上传后毫无动静,还有个别站不升反降。
更上游的信号也对得上:Google那边的John Mueller明确说过,没有哪个AI服务声明自己在用llms.txt,而且你看服务器日志就知道,它们连去请求这个文件都不去请求。平台工具会把“缺llms.txt”标成站点问题,但日志显示AI爬虫极少真的来取它——工具的告警和真实抓取行为是脱节的。这一点你自己也能验证,怎么从日志和爬虫行为反推AI到底在抓你什么,保哥在用代码逆向AI爬虫真实抓取行为那篇里有完整方法,建议拿你自己的日志跑一遍,比信任何工具的告警都实在。
这两年还冒出一份样本大得多的第三方抓取分析,把这个结论钉得更死。有人统计了13.7万个在2026年5月真实有流量的域名,其中约28%配了有效的llms.txt,可这些文件里97%整个月收到的请求是零——传完就躺在根目录,没一个爬虫来取,跟前面那批站三个月的画面如出一辙。
更值得玩味的是来取它的都是谁。抓得最积极的GPTBot占比也才4.5%上下;真正读得最勤的,是那份13.7万域名llms.txt抓取分析点出的Claude-Code这类编程助手,量比所有AI检索bot、AI助手加起来还多。这恰好把llms.txt的真实定位摆明了:它是给已经进了你站、要加载文档的agent一个干净入口,不是帮你在AI搜索结果里被“发现”、被“选中”。那份研究的结论很直白——你要图的是出现在ChatGPT、Perplexity或AI概要的引用里,这文件基本就是个摆设。
这种“自报文件没人当真”的逻辑,往上游追一点都不新鲜。Google搜索中心关于AI功能的官方说明把话挑明了:想出现在AI概要和AI模式里,不需要新建任何机器可读文件、AI专用文本或额外标记,常规那套高质量内容加可被抓取就够。Mueller给llms.txt找的类比更直白——它像早年的keywords元标签,你自己填给机器看的“我很重要”,可人人都这么填,机器干脆不当真;搜索引擎二十年前就因为这个把keywords meta扔了,如今对一个同样靠自报的文件,态度不会两样。
那token效率这个理由,到底站不站得住?
支持llms.txt最像样的一个论点是token效率:给AI一份干净的Markdown,比让它去解析一堆HTML省token、也更不容易读错。这个逻辑本身没错,但它的适用面很窄。
它真正有价值的场景,是那种AI编程助手会高频查询你文档的产品——开发者工具、API文档站。有的开发者工具平台报告过相当一部分注册来自AI工具的使用场景,对这类站,把文档做成AI易读的Markdown确实有实打实的回报。但如果你是电商、保险、传统B2B SaaS,AI编程助手根本不会来反复读你的文档,token效率这个收益对你基本不存在。一个只在特定品类成立的理由,不该被当成所有人都该做的理由。
llms.txt是sitemap,不是增长策略
把上面拼起来,结论就清楚了:llms.txt更像基础设施文档,不是增长机制。它和sitemap是一类东西——加上去基本不会伤害你的站,未来某些工具也许能借它更高效地理解你的内容,但它本身不是魔法增长开关,花在精雕它上面的几个钟头,几乎总能用在更有回报的地方。
那更有回报的地方是什么?实测里那几个真涨了的站已经给了答案,全是这些:把内容做成功能性的、可被直接抽取的资产(对比表、FAQ、可下载模板);为抽取而组织结构而不是为人眼排版;修掉真正挡路的技术障碍和抓取错误;靠公关和第三方背书赚外部验证;针对具体用户意图去优化。这些事没有一件靠一个Markdown文件能替代。把内容组织成AI能直接抽取的形态,用结构化内容格式提升AI引用率那篇拆得很细,比花时间雕llms.txt值得多。
Google官方又把llms.txt的口径松了一档,这会不会推翻前面的结论?
这篇写完之后,Google又在它面向生成式AI搜索的优化指南里补了一段话,专门回应社区一直在追问的口径。原话的意思是:如果你想为别的、真在用这些文件的服务或系统去创建和维护llms.txt,完全没问题;这么做既不会损害、也不会帮助你在Google搜索里的可见性和排名,因为Google搜索会直接忽略它们。同一段还顺手把话说全了——想出现在Google搜索(含它的生成式AI能力)里,你并不需要额外去造什么机器可读文件、AI文本文件或标记。
乍一看像是松口、像在给llms.txt背书,其实跟前面实测得出的结论是同一条线,只是把话说得更圆。它把两个一直被搅在一起的问题彻底拆开了:一个是“对Google搜索有没有用”,官方回答明确是没有;另一个是“对Google之外的AI系统有没有用”,这个Google不替你回答,要看下游到底有谁在消费它。这次它还特意承认了一件事——它自己之外,还有别的AI搜索界面存在。
所以别把前面那句“largely decoration”误读成“llms.txt是个骗局,赶紧删掉”。如果你的站点真有某个agent、某个编程助手或某个垂直AI工具在按约定加载这个文件(还记得前面那份数据里,抓得最勤的恰恰是编程类助手吗),那维护好它就是有意义的;反过来,如果压根没有下游在读它,它就还是那份没人翻开的说明书。文件本身的价值,从来不由它存不存在决定,而由有没有人真在用它决定。
这件事保哥的看法没变,只是更有底气了:判断llms.txt值不值得做,永远看“有没有下游真在消费它”,而不是“Google认不认它”。Google不看,不构成删掉它的理由;同样,Google说“完全可以做”,也不构成你必须做的理由。把它当成一个面向特定下游的可选交付物,按你实际接入了哪些AI工具来定取舍,别因为一句官方表态,就在“全站铺开”和“一律删光”这两个极端之间来回横跳。
那llms.txt还要不要做?给你一个决策框架
“别指望它带量”不等于“别做”。它部署成本极低、不会伤站、未来有上行期权,所以判断标准不是“做不做”,而是“值得为它投入多少”。按下面这张表对号入座:
| 你的情况 | 建议投入 | 理由 |
|---|---|---|
| 开发者工具/API文档站,AI编程助手是主要分发渠道 | 认真做,含llms-full.txt和每页.md | token效率收益对这类站真实存在 |
| 普通电商/B2B/内容站 | 用插件顺手生成,别手工精雕 | 低成本占个位,但别挤占内容预算 |
| 团队时间紧、内容和技术债一堆 | 先放着,优先做可抽取资产和修技术债 | 机会成本太高,回报方向明确在别处 |
| 已部署,想再加码优化 | 停,把工时挪到外部背书和结构化 | 边际回报趋近于零 |
常见的失败模式有两个:一是被平台工具的告警牵着走,看到“缺llms.txt”就当成严重问题投入大量精力,而真实日志里AI根本不来取;二是把它当成做完GEO的标志,文件一传就觉得AI优化交差了,结果该做的可抽取内容和外部验证一样没做。这两个坑的共同点都是——把一个低成本基础设施,误当成了高回报策略。
顺手做的话,怎么把它做对?
既然决定顺手做,几条让它别白做的实操。提供页面的.md版本:给每个重要页面提供一个原URL加.md后缀的Markdown版本,AI读Markdown比解析HTML干净得多,也不受JavaScript渲染和广告代码干扰。定期审计:新产品上线、定价调整、重要文档改版时同步更新,至少每月查一次链接是否还都返回200。
用好Optional段落:把次要内容放Optional下,给AI一个上下文不够时可跳过的精简模式。控制llms-full.txt体积:别一味求全,超出的部分回退到llms.txt的链接列表里由AI按需抓。
还要清醒一点:llms.txt不是安全机制,它拦不住AI抓取你不想被抓的内容,它只是建议不是规则。真要做访问控制,得靠认证、付费墙和技术手段,别把内容保护的指望压在它身上。另外要当心一个滥用风险——正因为它是专门写给AI看的,有人会把它当成给大模型投喂夸大信息的理想位置,长期看更稳的做法始终是让页面正文本身经得起读,而不是依赖一个可以单独为AI改写的文件。
万一以后AI厂商正式采纳了,现在不做会不会踏空?
这是“别过度投入”最容易招来的反问:要是哪天主流AI厂商集体官宣支持llms.txt,现在没认真做的人岂不是踏空了?这个担心可以理解,但把它拆开看,会发现它恰恰证明了前面的结论而不是推翻它。
关键在于这件事的“补做成本”极低。llms.txt不是那种需要长期积累才有复利的资产(外部背书、内容口碑才是),它本质就是一个可以随时生成、即时生效的Markdown文件。也就是说,假如未来真的官方采纳,你那时候用插件或工具几小时就能补上一份合规的,并不会因为今天没做就永久落后。对“补做成本极低、收益时点不确定”的东西,正确的对冲不是提前重仓,是占个低成本的位、然后把资源压在确定有回报的地方。
具体怎么对冲:用插件顺手生成一份基础版llms.txt挂着,这一步成本接近于零,等于买了个免费的上行期权;同时把真正的精力放在那些“无论llms.txt未来命运如何都一定有用”的事上——可被抽取的内容结构、过硬的外部验证、干净的抓取与渲染。这些事的特点是收益和llms.txt的官方命运完全无关:AI不采纳它,这些照样让你被引用;AI采纳它,这些让你那份llms.txt里指向的页面真的扛得住被读。两头都不亏。
反过来,最差的策略是因为“怕踏空”就现在重仓精雕——花大量工时打磨一个目前没人来取的文件,机会成本实实在在,而所谓的踏空风险,又被“几小时就能补做”这一点几乎抹平。真正会让你踏空的,从来不是少做了一个llms.txt,而是把本该用来做可抽取内容和外部背书的时间,耗在了一个低杠杆的文件上。
不同类型的网站,侧重点怎么调?
电商站:重点放产品分类结构、核心品类页、退换货与物流、品牌故事,热门和促销页放主列表,长尾单品放Optional。SaaS产品站:重点放功能文档、API参考、集成指南、定价、客户案例,开发者文档尤其重要,这正是前面说的token效率真有用的那类。内容型站/博客:重点放核心主题的支柱内容、最受欢迎文章、作者信息、内容分类索引,按主题而非时间组织链接。企业官网:重点放公司介绍、业务范围、核心优势、联系方式,确保成立时间、团队规模、服务区域这些品牌核心事实出现在描述里。
不管哪类站,记住整篇的主线:llms.txt是这套体系里成本最低的一环,它的上限有限,真正决定你被不被AI引用的是内容本身的可抽取性和外部验证。它只是起点,下一步往哪走,llms.txt之后的AI内容架构四层方案那篇接着讲;而如果你的站连AI爬虫都进不来,那是更靠前的问题,托管平台悄悄拦掉AI爬虫导致你在AI答案里消失那篇值得先排查。
怎么自己验证llms.txt到底有没有被AI取过?
别人的实测你可以参考,但最有说服力的证据是你自己站的服务器日志。这件事不用工具,几分钟就能验,而且能让你彻底不再被平台告警牵着走。
思路是去原始访问日志里筛“路径是llms.txt”的请求,然后看两件事:请求总量是多少、发起请求的是哪些客户端。重点关注那几个常见的AI抓取客户端标识——主流模型厂商和AI编程助手各自的爬虫UA。你大概率会看到一个挺扎心的画面:人类浏览器和你自己的监控偶尔点开过,真正的AI爬虫请求次数趴在地板上,甚至是零;与此同时,这些AI爬虫对你正文页面的抓取却一直在发生。
这个对比本身就是结论:它们在抓你的内容,只是没在通过llms.txt这扇门抓。平台工具把“缺llms.txt”标红当成站点问题,但日志说的是另一回事。失败模式是反过来——拿工具的告警当真相,照着它投入大量精力精雕一个没人来取的文件。先看你自己的日志,再决定投不投入,这是整件事里最便宜的一次尽调。怎么系统地从日志和抓取行为反推AI的真实偏好,前面提到的逆向AI爬虫那篇有整套可复用的方法。
那几个钟头不投llms.txt,该投到哪几件事上?
“别在llms.txt上过度投入”只有配上“那该投哪”才算负责任。实测里真涨了的站,做的全是下面这些——按性价比排好了序,照着往下做:
| 优先级 | 该做的事 | 为什么比精雕llms.txt值 |
|---|---|---|
| 最高 | 把核心信息做成可被直接抽取的对比表、FAQ块 | AI是按段抽取的,能抽走的内容才会被引用 |
| 高 | 修掉真正挡路的抓取与渲染障碍 | 抓不到或渲染不出,后面一切都白搭 |
| 高 | 靠公关和第三方背书赚外部验证 | AI对一致出现的外部信号给权威,文件给不了 |
| 中 | 针对具体用户意图重组页面 | 命中真实问题的页面才会被AI挑去答 |
| 低 | 用插件顺手生成llms.txt占位 | 低成本占个上行期权,但不挤占上面预算 |
这张表的用法是“从上往下做,做不完不往下”。最常见的浪费,是团队把这张表倒着做——先花一周精雕llms.txt,再说“没空做可抽取内容和修技术债”。把内容组织成AI能直接抽走的形态具体怎么落地,前面那篇结构化内容格式的拆解就是这一行的施工图,照着把对比表、FAQ块、可独立成段的结论先做出来,比任何文件级优化都先见效。
其它框架和自建站怎么集成llms.txt?
前面WordPress和Shopify讲得细,其它技术栈也给到可落地的程度,省得你再去翻文档。
静态文档框架(如VitePress、Docusaurus):社区有对应插件,能从你的文档源自动生成符合规范的llms.txt和llms-full.txt,接进构建流程基本零维护。文档托管平台(如部分主流文档SaaS):开箱即用,自动生成并托管两个文件,甚至为每个页面附一个Markdown版本,不用任何配置。内容管理系统(如Drupal较新版本):有现成的配方式方案,装上即提供基础支持。
自建站(Next.js、React等):没有现成插件,思路是在构建脚本里读取所有页面的元数据(标题、URL、摘要),按规范格式拼出字符串,写到构建产物的public目录下命名为llms.txt,部署时它会自动落到根目录;llms-full.txt同理,只是把每页正文也拼进去并控制总体积。
不管哪种栈,集成完都要做同一件收尾事:浏览器访问根路径llms.txt确认返回200、是纯文本、Markdown没被当成HTML渲染掉,并和robots.txt交叉检查没冲突。自动生成最容易翻车的不是生成本身,是没人复核——工具不懂你的业务优先级,骨架生成后必须人工把重要页面补全、把无关页面剔掉。
给每页配.md版本,到底怎么落地、值不值得?
llms.txt官方提案里建议给每个页面提供一个Markdown版本,URL是原地址加.md后缀。原理是AI读干净的Markdown比解析HTML效率高得多,也不受JavaScript渲染、广告代码、弹窗这些干扰。
落地方式取决于你的栈:静态站在构建时为每个页面额外输出一份.md产物;动态站可以加一个路由,识别到.md后缀就返回该页正文的Markdown版本而不是完整HTML页面;走CDN边缘的,可以在边缘层做这层转换。内容上只保留正文,去掉导航、页脚、侧边栏。
值不值得做,回到那张决策表的同一条逻辑:对开发者工具和文档站,AI编程助手会高频取这类.md,值得;对普通电商和内容站,收益和llms.txt本身一样有限,顺手做不亏,但别为它单独排一个大工程。判断标准始终是“AI编程助手会不会高频来读你的文档”——会,就认真做;不会,.md和llms.txt都只是低成本占位。
决定要做之后,具体怎么落笔可以对照这篇操作教程:llms.txt生成器怎么用?逐字段填法、分区设计与部署验证,里面把每个字段填什么、分区怎么排、生成后放哪儿验证都走了一遍。
常见问题解答
llms.txt必须放在网站根目录吗?是的,按规范应放在根目录、通过根路径llms.txt访问,部分平台也支持well-known路径作为备选。如果有子域名或子路径的独立项目,可以在各自根路径下各放一个。
部署llms.txt后AI流量会立刻增加吗?基本不会。实测显示绝大多数站部署后无可测变化,少数上涨的真实推手是公关背书、可抽取内容和可下载资产,不是这个文件。把它当基础设施,别当增长开关。
既然没什么效果,那还有必要做吗?看情况。开发者工具和API文档站值得认真做,token效率收益真实存在;普通站用插件顺手生成即可,别手工精雕;团队时间紧就先放着,优先做可抽取资产和修技术债。
llms.txt和robots.txt的区别是什么?robots.txt管访问控制,告诉爬虫哪些能抓哪些不能;llms.txt管内容策划,告诉AI哪些内容最重要。目标对象和功能完全不同,应同时部署、协同配合。
内容更新后llms.txt需要同步更新吗?需要。尤其新增重要页、删除旧页、改了页面URL时要及时更新。用插件一般会定时自动更新,手动维护建议每月检查一次链接有效性。
不懂技术的人能自己做llms.txt吗?能。它本质就是一个Markdown文本文件,不需要编程,用记事本就能写、用FTP就能传。不熟Markdown就用在线生成器输入网址生成,再按业务需求微调即可。
权威参考资料
本文标题:《llms.txt到底有没有用?10个站90天实测给的答案》
本文链接:https://zhangwenbao.com/llms-txt-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0