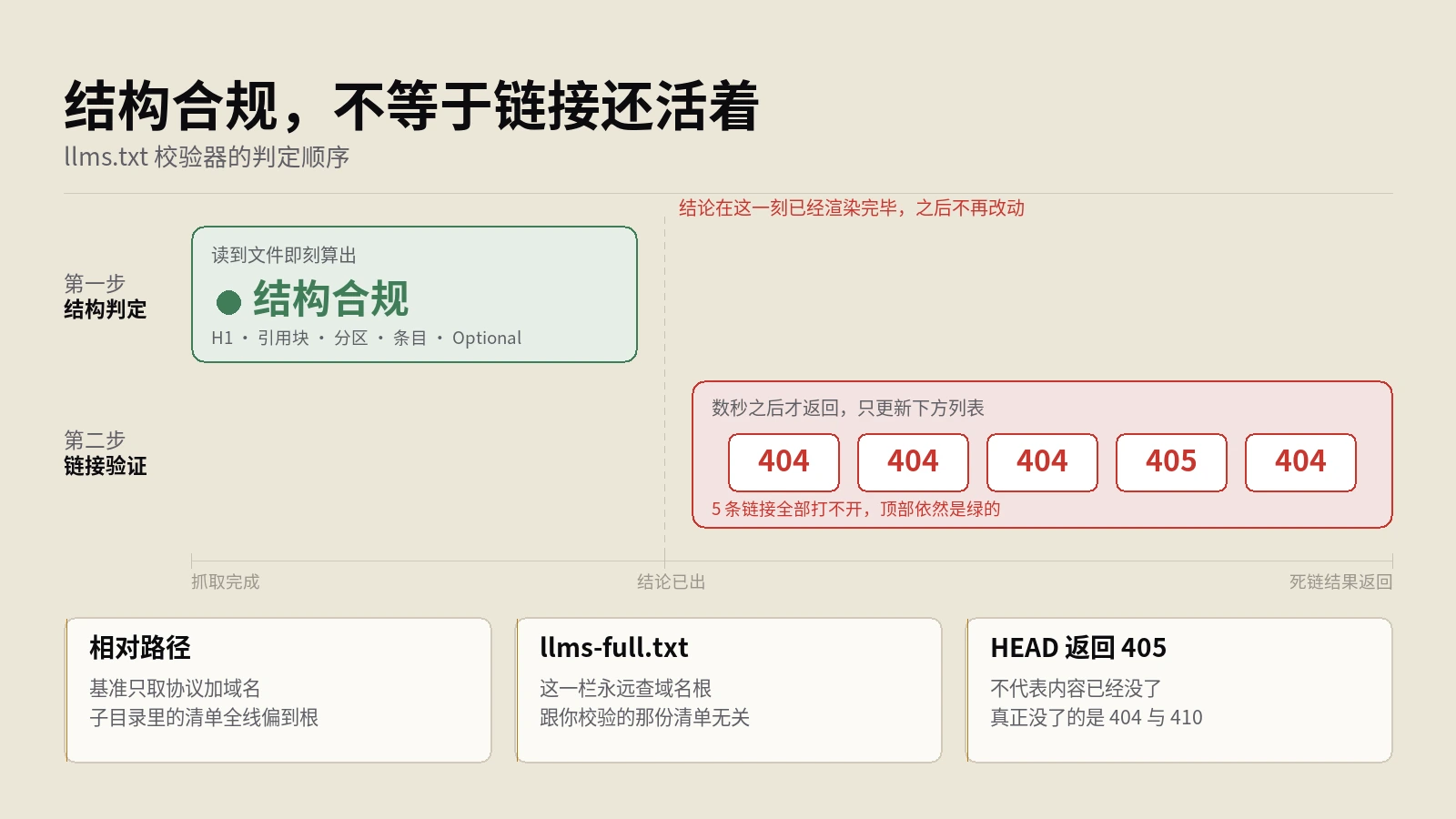
llms.txt校验器亮绿灯时,5条链接可能全是死的
llms.txt校验器的六项结构检查怎么读、哪些黄灯不用理?实测结构合规的绿灯与链接死活无关,相对路径按域名根拼接,llms-full.txt永远查根目录,405也不等于内容不存在。
标签
保哥笔记 llms.txt 标签下共 8 篇文章合集,含《llms.txt校验器亮绿灯时,5条链接可能全是死的》《llms.txt生成器怎么用?逐字段填法、分区设计与》《EntityMap是什么?一个给AI的实体声明文件要》等,与 技术SEO、GEO、AI爬虫 主题密切相关,覆盖 SEO/GEO 实战角度的深度解析与可落地方案。
llms.txt校验器的六项结构检查怎么读、哪些黄灯不用理?实测结构合规的绿灯与链接死活无关,相对路径按域名根拼接,llms-full.txt永远查根目录,405也不等于内容不存在。
llms.txt生成器的完整用法:站点名称、描述、分区各填什么,条目描述怎么写才有信息量,选内容的三条标准,以及生成后的部署位置、robots放行与校验闭环。

EntityMap是2026年6月刚进公示期的开放标准,让你用一个文件向AI声明:我是谁、我懂什么、证据在哪。它会不会重蹈llms.txt没人认的覆辙?本文讲清它的结构、怎么配、谁在推,以及哪类站值得做。

Google刚说搜索不需要llms.txt,Chrome的Lighthouse就新增了一项检查它的审计。这篇拆解这个看似打架的信号:代理浏览审计到底查什么、Mueller怎么解释、你的站到底该不该做llms.txt。
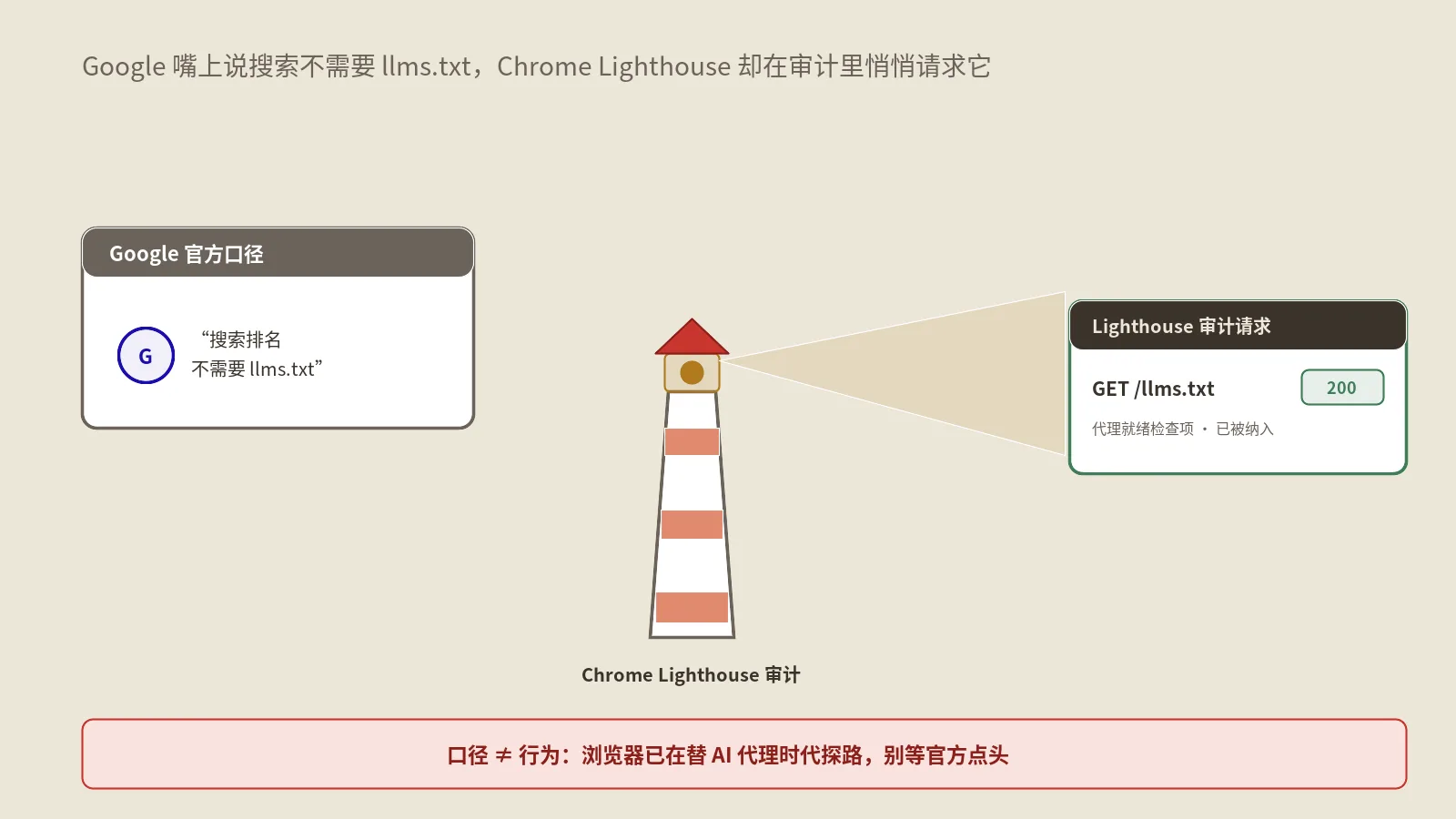
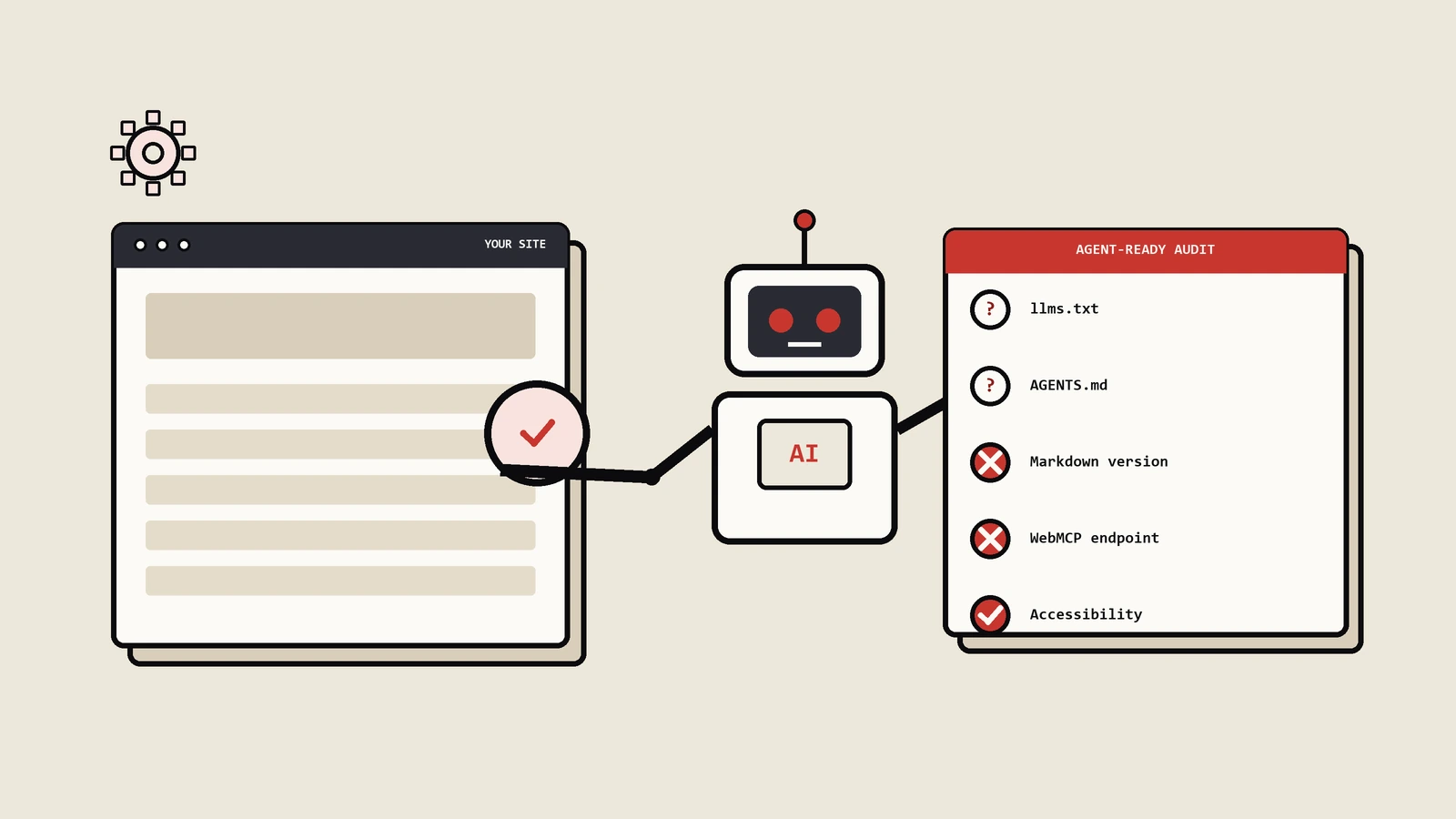
Google搜索说不用做llms.txt、不用为机器人单独写Markdown,可Chrome的Lighthouse又新增了Agentic Browsing审计来查这些。本文拆解口径分歧背后discovery与functionality的分工,讲清Markdown、llms.txt、WebMCP到底值不值得做,并给出一张按网站类型分级的agent友好度优先级落地表。
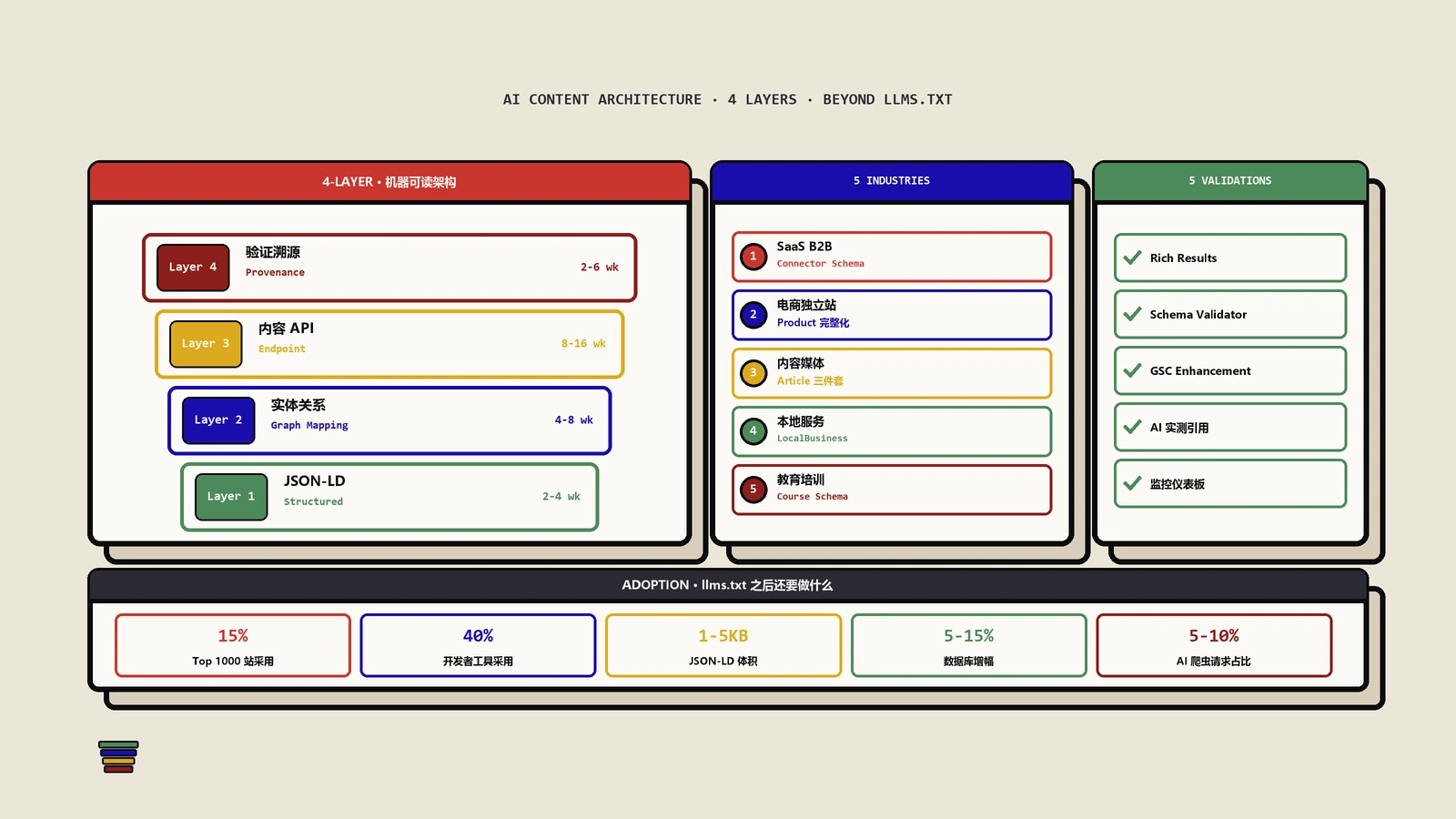
llms.txt只是起点。AI准确引用品牌信息需要JSON-LD事实层、实体关系图谱、内容API端点和溯源元数据4层完整架构。保哥给出本季度可交付的最小可行方案与5个行业实施策略。
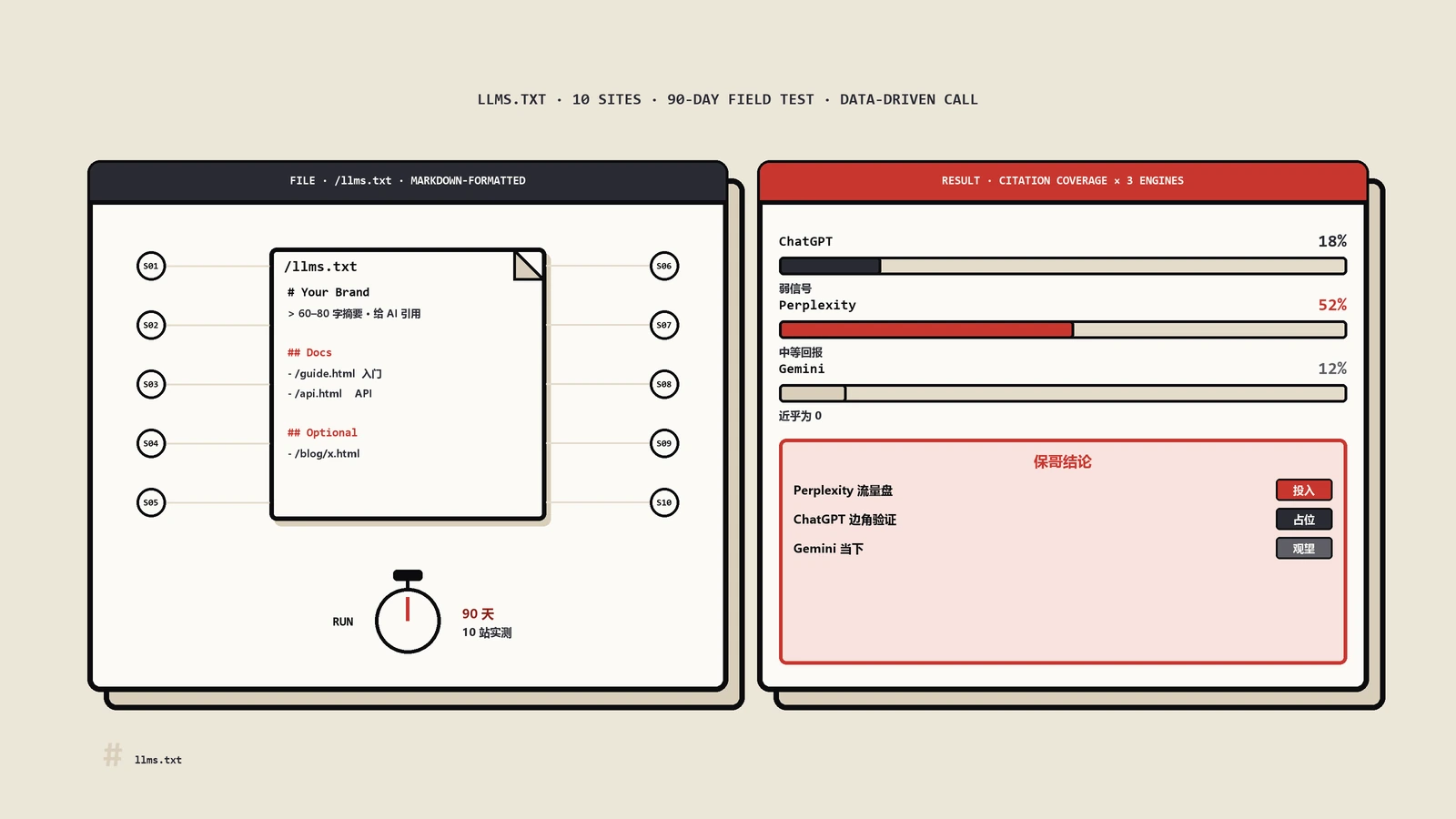
藏宝图,还是浪费时间?这场争论该用证据收尾了。文章一边手把手带你写出并部署到位(含多平台与Shopify的四种落地路径),一边把一组跨站点跟踪实测的结论讲明白:谁真该认真投入、谁顺手占位即可、把省下的工时押到哪里回报才高。
14种AI客户端、3类抓取经济学、5种日志里的病:别再照官方文档和llms.txt模板猜了。这篇用一个能复现请求指纹的模拟器加访问日志反查,把robots、llms.txt、渲染策略从凭感觉改成可验证的工程,再讲清怎么固化成每季度自动复跑的能力