网站要不要为AI agent改造?这事Google没说清
本文目录
- AI agent来你网站上,跟用户和搜索爬虫到底有什么不一样?
- Google搜索说不用、Lighthouse却来查,这两边为什么打架?
- discovery和functionality分开看,分歧就不矛盾了?
- 给页面专门做一份Markdown版本,到底值不值得?
- Lighthouse那个Agentic Browsing审计,具体查了哪四项?
- 给agent的可访问性,和给人用的无障碍是一回事吗?
- WebMCP是什么?你的网站现在要不要接?
- llms.txt被Lighthouse查了,那它现在算必做项了吗?
- 除了llms.txt,agent还会认AGENTS.md这类文件吗?
- 怎么判断你的网站,现在到底该不该为agent投入?
- 真要动手,先做哪几件、投多大成本才不亏?
- 为一笔还没来的流量提前改造,会亏在哪?
- 常见问题解答
- 现在到底要不要做llms.txt?
- Lighthouse的Agentic Browsing分数低,会影响Google排名吗?
- 给每个页面做Markdown版本有必要吗?
- WebMCP现在该接吗?
- 那为AI agent改造,到底有没有现在就该做的事?
- Google搜索和Lighthouse对llms.txt口径不一样,该听谁的?
- 权威参考资料
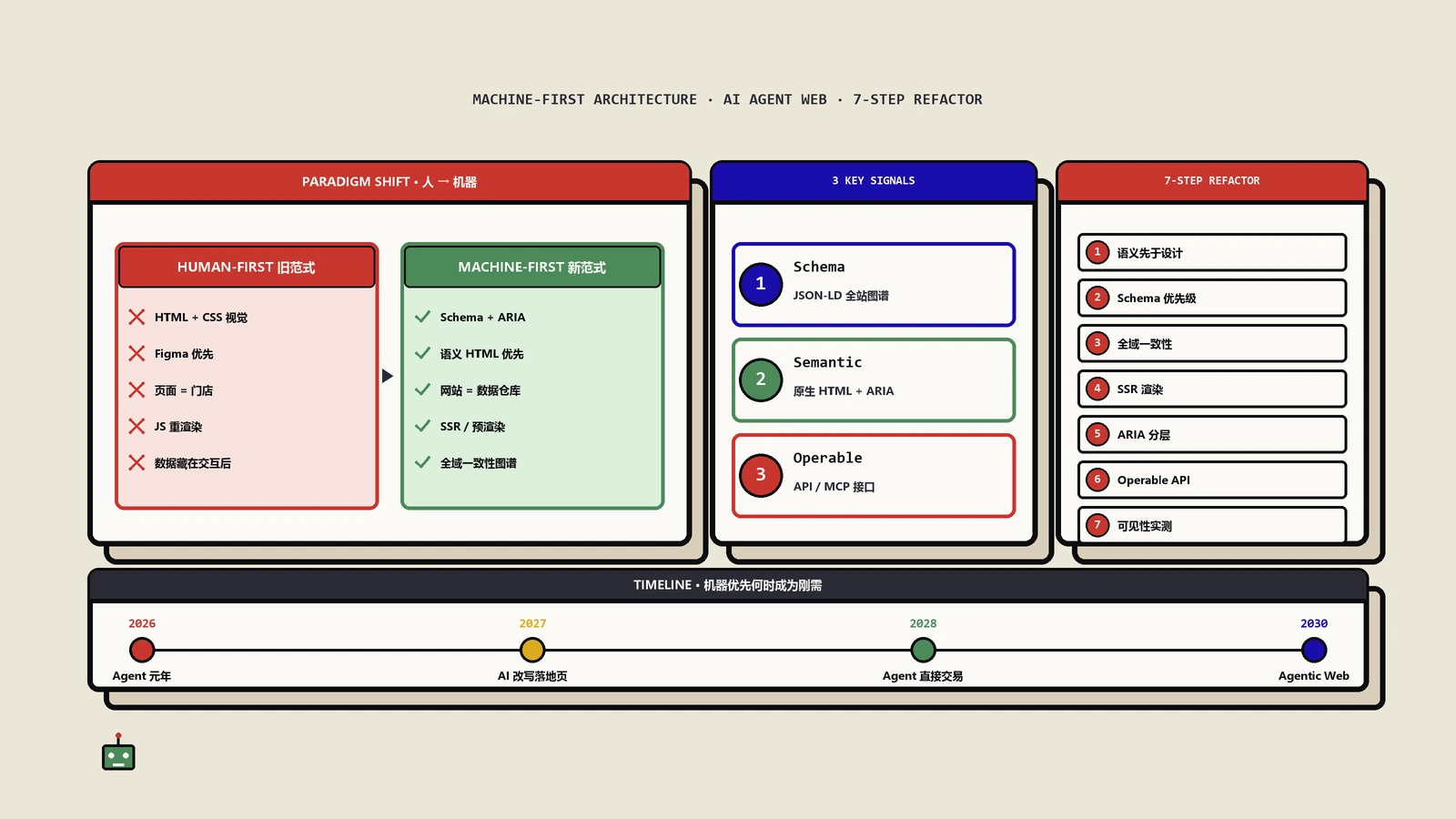
摘要:绝大多数网站,现在不需要为AI agent做任何专门改造。这件事Google自己都没说清楚——搜索团队5月发的官方AI优化指南,明说llms.txt、为机器人单独做Markdown、内容分块这些都不用做;可几乎同一时间,Chrome的Lighthouse又把一个叫Agentic Browsing的审计类别设成默认开启,专门来查你有没有llms.txt、有没有WebMCP、可访问性树健不健全。一边说没用,一边做了个工具来查,看着像打架。其实不矛盾:一个管“被搜索找到”,一个管“被agent操作”,是两个产品团队各说各的。这篇把这层分歧讲透,再给你一张按网站类型分级的优先级表——哪些事现在就该做(因为它同时帮用户、帮搜索、也帮agent,稳赚),哪些是为一笔还没来的流量提前烧钱。Mueller那句“先满足需求,再追梦”,是这件事最好用的一把尺子。
AI agent来你网站上,跟用户和搜索爬虫到底有什么不一样?
要回答“要不要为agent改造”,得先搞清楚agent到底是谁。过去二十年,网站只为两种访客设计:人类用户,和搜索引擎爬虫。现在冒出来第三种。
人类用户看的是渲染完的页面,凭眼睛和直觉操作——按钮长什么样、放在哪儿,他扫一眼就知道点哪里。搜索爬虫,比如Googlebot,干的是另一件事:把HTML抓下来、建索引,为“你这页能不能被搜到”服务。它只读,不操作,也不在乎你的“加入购物车”按钮点了会发生什么。
AI agent是第三种,它跟前两种都不一样。它是替用户去“办事”的——比价、下单、填表单、查物流状态。它不只是读你的内容,它要“动手”。问题在于,它动手的方式跟人不一样:它可能没跑完整的浏览器渲染,就算渲染了,它定位一个按钮也不是靠“看”,而是靠可访问性树里的标签、靠元素的坐标位置。你页面上那个设计得很漂亮、但本质是个绑了点击事件的div,人能认出来是按钮,agent经常认不出来。
| 访客类型 | 它要干什么 | 它怎么理解页面 | 网站为它做的事 |
|---|---|---|---|
| 人类用户 | 看内容、做决策、完成操作 | 看渲染后的视觉,凭直觉 | UI设计、可用性、视觉层次 |
| 搜索爬虫 | 抓取、索引,只读不操作 | 解析HTML、看链接结构 | 传统SEO、收录与排名优化 |
| AI agent | 替用户执行任务、动手操作 | 靠可访问性树、元素位置、结构化接口 | 本文要讨论的“agent友好度” |
把这三种访客分清楚,后面所有的纠结都好解了。因为“为agent改造”这件事,本质就是问一句:第三种访客现在来得多不多、值不值得你专门为它动工。而Google自己给的信号,恰恰在这儿绕了个让人犯晕的弯。
Google搜索说不用、Lighthouse却来查,这两边为什么打架?
把时间线摆出来,你就明白为什么这么多人懵了。
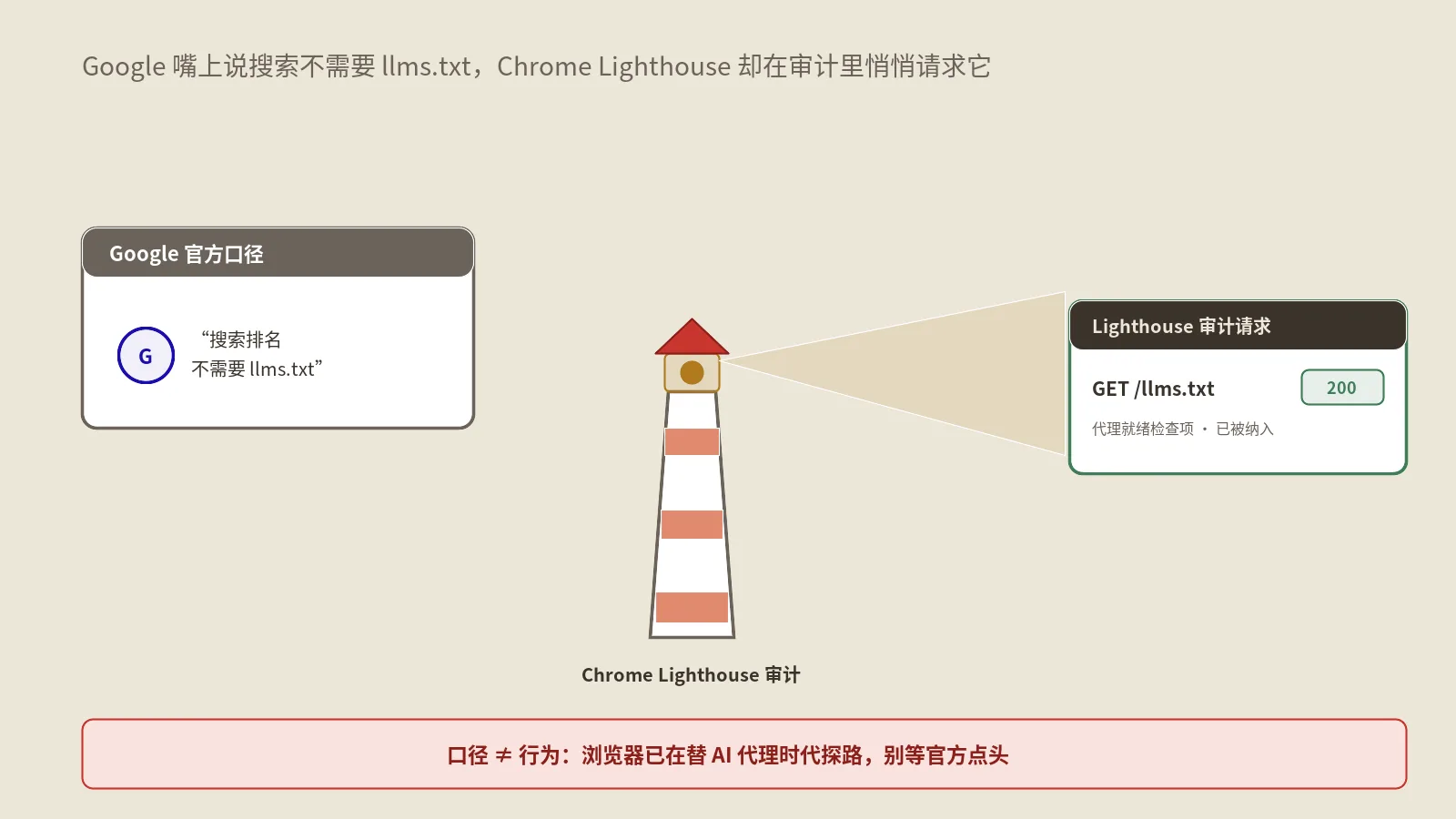
2026年5月15日,Google搜索团队发布了第一份正式的、合并版的生成式AI优化指南。这份指南专门破除了一批“AI搜索玄学”,白纸黑字列出一串你不需要做的事:不用建llms.txt文件、不用做内容分块、不用为AI专门改写一版内容、不用为了AI去堆结构化数据、不用刷不真实的品牌提及。它的核心立场很干脆——为生成式AI搜索做优化,本质还是为搜索体验做优化,那就还是SEO,没有第二套玄学。这份指南到底叫停了哪些动作,站内有一篇专门拆解Google官方AI搜索指南的文章讲得更细。
结果就在差不多同一时间,Chrome团队这边的Lighthouse工具升到了13.3版本(2026年5月7日),新增了一个叫“Agentic Browsing”的审计类别,而且直接从实验性状态转成了默认开启。这个类别里,赫然有一项就是检查你的网站有没有提供llms.txt文件。
你看出那个尴尬了吧:搜索团队说“llms.txt不用做”,Chrome团队却做了个工具默认来查你做没做。一个普通站长打开两份Google官方文档,得到的是两个相反的暗示。这要是不懵才怪。
这种拧巴不是第一次了。2025年12月,有人发现Google的Search Central开发者文档站上,悄悄出现了一个llms.txt文件。Mueller当时只回了句“hmmn :-/”,没多解释。后来Dave Smart发现,developer.chrome.com、web.dev这些Google的开发者站上也都有这个文件——看起来更像是某次内部CMS平台统一升级顺手带出来的,不是搜索团队拍板要做。Search Central那份文件几个钟头内就被撤了,但别的站上的留着没动。一个文件,在Google自家不同的站上,命运都不一样。
所以这不是Google精神分裂,是它内部两个产品团队,管的根本是两件不同的事。把这两件事拆开,分歧立刻就不矛盾了。
discovery和functionality分开看,分歧就不矛盾了?
解开这个结的钥匙,是Mueller提出的一个特别朴素的框架:一个网站有两个不同的目标,一个叫discovery(被发现),一个叫functionality(能用)。
discovery就是SEO在干的事——让搜索引擎找到你、让用户通过搜索来到你这儿。functionality是另一回事——让已经来到页面上的访客(包括agent)顺利把事办成。Mueller说得很清楚:这两个目标,你不会“为了SEO”去做functionality,但如果你对整个网站负责,那把高“被发现率”和高“转化率”一起做好,才撑得起你的工作价值。
用这个框架回头看那个“打架”:搜索团队的指南,管的是discovery——它说llms.txt对“被AI搜索找到”没用,这句话在discovery这条线上完全成立。Lighthouse那个Agentic Browsing审计,管的是functionality——它关心的是浏览器里的agent能不能顺利操作你的页面,llms.txt在这条线上被当成一个“可能有点用”的可选项。两边说的是两件事,自然不冲突。
这个框架还能解释Google为什么给自家的开发者文档做Markdown版本。Mueller专门讲过这事:developers.google.com做Markdown版,纯粹是为functionality,跟SEO一点关系没有。原因是AI编程助手现在太火了,这些写代码的系统,如果能轻松读懂、解析参考资料(比如开发者文档),产出的代码就更准、更高效。Markdown帮它们快速抓住文档讲的是什么上下文,等于给了一个简化版的参考页。
但Mueller同时把话点透了:“这些系统当然也读得了HTML,所以Markdown更像一根临时的拐杖,也许就是为了省点token。”他对其他网站的建议特别直接——对非开发者类的网站,就算未来agent流量真的变多,做这个也没什么意义。然后是那句值得贴在工位上的话:“你的网站有更重要的SEO要做,别为一个可能来、也可能永远不来的未来场景做准备。先满足需求,再追梦。”这话还能翻译成更直白的一句:别拿你现在已经吃得到嘴的流量不管,跑去伺候一个假设。
给页面专门做一份Markdown版本,到底值不值得?
既然Google自己给开发者文档做了Markdown版,很多人就开始琢磨:我是不是也该给每个页面配一个.md版本,专门喂给AI?这事得算笔账。
先说Markdown省token这个道理,它确实成立。一份HTML里塞了大量对语言模型毫无意义的东西——导航栏、页脚、广告脚本、内联样式、一层套一层的div。模型读这些要花token,token就是钱、也是有限的上下文窗口。Markdown把这些噪声全剥掉,同样的信息,token数能少一大截。对一个高频调用文档的AI编程助手来说,这笔节省是真金白银。
但账的另一面,是三个常被忽略的成本。第一,主流的大模型和AI爬虫读HTML根本没障碍——一份干净的、语义化的HTML,本身就不难解析,Markdown省下的那点token,对它们不是生死线。第二,维护两份内容是有代价的,HTML改了.md忘了改,时间一长两份对不上,反而误导模型。第三,也是最关键的——真正会高频来取这类.md的,只有AI编程助手在读技术文档、API文档的时候。普通的电商站、内容站、企业官网,压根没有这个调用量。
所以这笔账的结论很清楚:开发者工具站、API文档站,做Markdown版值得认真做,因为“AI编程助手高频取用”是一个确定存在的需求;普通网站做这个,收益约等于零。这里有个省力的中间路径——如果你的站正好托管在Cloudflare上,它能在边缘层零成本地自动生成Markdown版本,关于这种用CDN边缘自动交付Markdown的做法站内有专门一篇。顺手开一下不亏,但别为它单独立一个项目、排一个工程。判断标准浓缩成一句话:会不会有AI编程助手高频来读你的内容——会,就认真做;不会,.md就只是个低成本的占位摆设。
Lighthouse那个Agentic Browsing审计,具体查了哪四项?
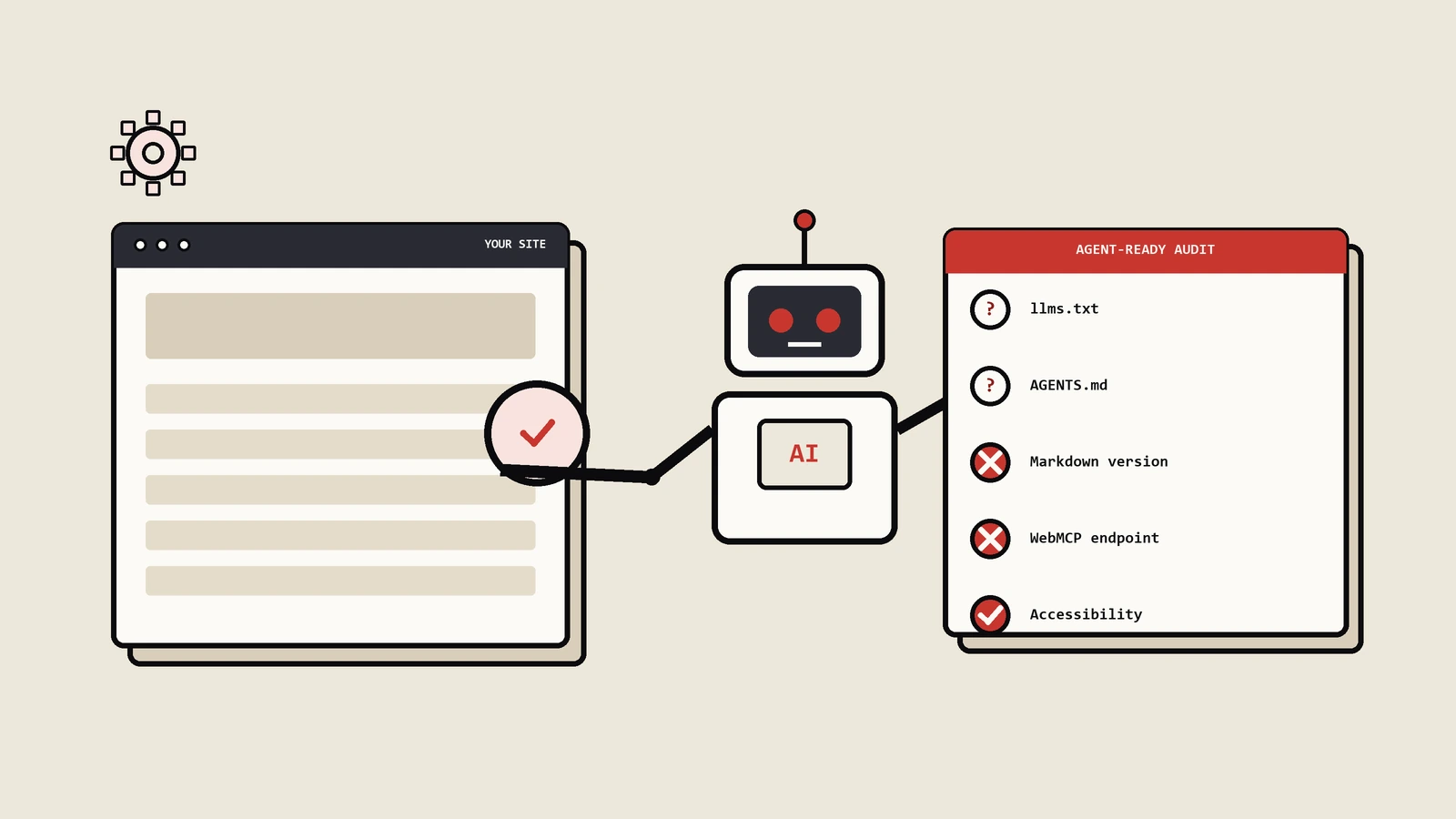
把这个审计类别看明白,比纠结“要不要理它”有用得多。因为它其实是一份现成的、Google视角下的“agent友好度”检查清单。
Lighthouse 13.3里,Agentic Browsing类别一共跑四项审计:
- WebMCP集成:通过Chrome DevTools Protocol里的WebMCP域,监测网站有没有注册“工具”——既看HTML里声明式定义的工具,也看JavaScript命令式注册的工具。说白了,查你有没有用WebMCP把网站功能暴露给agent。
- 可访问性树:它从常规的无障碍审计里,专门筛出跟“机器操作”相关的几项——元素有没有名字和标签、角色和关系组成的树完不完整、可交互的元素在不在可访问性树里露脸。
- 累积布局偏移(CLS):测页面渲染之后内容还动不动。这一项之所以进了agent审计,是因为agent要靠元素的位置去点击,页面渲染完位置还在飘,它就点空、点错。
- llms.txt:查网站根目录有没有这个文件。如果有,再检查它是不是缺了H1标题、是不是太短、是不是一条链接都没有。
这个审计还有个跟别的Lighthouse类别都不一样的地方——它不给那种0到100的加权总分。它给的是一个分数比(四项里通过几项)、每一项单独的通过或未通过、外加一些信息性的计数。Google把话说得很明白:agent这套标准还在萌芽期,现在的重点是收集数据、给出可行动的信号,而不是给你排个名次。这句话本身就是一个重要信号——它在告诉你,别把这个分数太当回事。Lighthouse官方关于Agentic Browsing评分机制的文档里,对这一点讲得很清楚。
还有个实操上要知道的细节:这个审计的结果会跳。同一个站,今天跑和明天跑分数可能不一样。原因有三个——WebMCP靠JavaScript动态注册,有时序问题;可访问性树会随DOM复杂度的变化而构建出不同结果;广告、没设尺寸的图片、后注入的内容,都会让布局偏移忽高忽低。所以别看到一次低分就慌,多跑几次看趋势。
给agent的可访问性,和给人用的无障碍是一回事吗?
四项审计里,可访问性树这一项,是最值得单独说说的——因为它藏着一个对你特别有利的好消息。
给AI agent的可访问性,和给残障用户做的无障碍(accessibility),不是完全一回事,但它俩重叠的面积非常大。重叠的部分是这些:语义化的HTML、正确的ARIA标签、每一个可交互元素都有清清楚楚的名字和角色——屏幕阅读器需要这些来给盲人用户读出页面,agent同样需要这些来“看懂”页面有哪些东西可以操作。Lighthouse官方文档里有个很形象的说法,把语义HTML加ARIA标签叫作“机器视角”。
这个重叠意味着一件好事:你为真实的残障用户做的无障碍工作,agent几乎是白捡的。这是少数几件“一次投入、三方都受益”的事——做好可访问性,用户用得顺、搜索引擎理解得更好、agent也能操作。它不是赌注,是稳赚。
但agent和人也有不一样的地方,主要在两点。一是agent特别在意布局的稳定和可预测。CLS对人来说是个体验问题——页面一抖,你手一滑点错链接,烦一下而已;对agent来说这是个功能问题——它是按坐标去点的,你的页面渲染完布局还在动,它就实实在在地点到了旁边那个广告上,任务直接失败。二是agent不会“将就”。人看到一个伪装成按钮的div,凭经验也能猜出来点它;agent对着可访问性树找“按钮”,找不到就是找不到。
所以落地建议反而简单:把可访问性当回事去做,但别打着“为了agent”的旗号——它本来就该做,是对真实用户的基本尊重;把CLS压到0.1以下;可交互的元素老老实实用真正的button、a标签,别用纯div加JavaScript伪装。这几件做完,你那四项审计里的可访问性树和CLS两项,基本就稳了。
WebMCP是什么?你的网站现在要不要接?
四项审计里最“未来”、也最容易让人焦虑的,是WebMCP。先把它讲清楚,再说要不要碰。
WebMCP是Web Model Context Protocol(网页模型上下文协议)的缩写,由Google和微软联合推出,挂在W3C的Web机器学习社区组下面(协议规范原文公开可查),2026年2月10日正式公布,目前还只在Chrome的早期预览里(Canary版本、要手动开flag)能用。
它解决的问题是这样的:今天的agent操作网页,基本靠“看截图、猜按钮、瞎点”,又慢又不靠谱。WebMCP让网站可以主动发布一份“工具合约”——把网站能干的事,比如搜索商品、加入购物车、查询订单状态,一条条列成结构化的、可以直接调用的工具。agent读到这份清单,就能直接调用对应的功能,不用再靠截图猜。它落地成一个浏览器原生的API,叫navigator.modelContext。这套协议有三个核心部件:发现(agent能标准地问一句“你这页能干什么”)、JSON Schema(每个工具都明确定义了要什么输入、给什么输出)、状态(实时让agent知道当下哪些工具可用)。安全上它走的是权限优先模型——浏览器当安全代理、同源策略管着、敏感操作得用户点头确认。
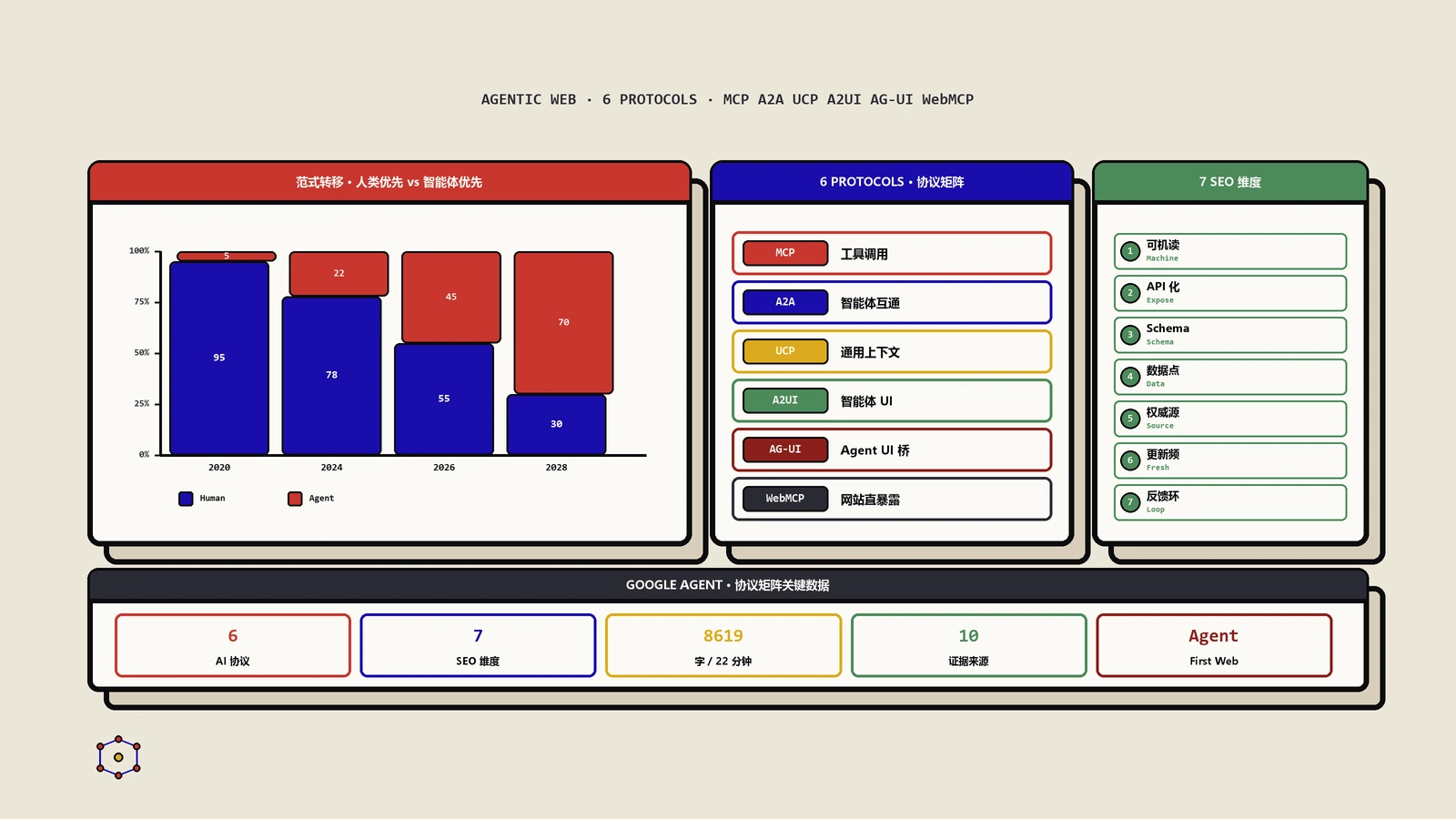
这套设计本身挺漂亮。但回到“你要不要现在接”这个问题,答案对绝大多数网站是:不要。理由很硬——标准2026年2月才公布,浏览器支持还没铺开,连Chrome都还在早期预览。现在投人力去接WebMCP,是教科书级别的“为还没到的梦想提前烧钱”。唯一的例外,是你的核心业务本身就指望agent来完成交易——比如一个已经被ChatGPT购物功能高频调用的电商。那种情况下,可以拿出很小一块资源做试点,但也仅止于试点。想完整了解agent时代有哪几套协议、整个agentic web的协议全景和SEO范式转移,站内有一篇专门梳理。
llms.txt被Lighthouse查了,那它现在算必做项了吗?
回到一开始那个让人懵的点:llms.txt既然被Lighthouse默认审计了,是不是就从“可做可不做”变成“必做”了?答案还是——不是。
先看Lighthouse对待llms.txt有多克制。它的逻辑是:你的站如果根本没有这个文件、返回404,审计直接标成“不适用”,不扣你分。只有当文件存在、但写得有毛病时(缺H1标题、内容太短、一条链接都没有),它才标红。换句话说,Lighthouse从头到尾没强制你必须有这个文件,它只是说“你要做就做对”。Google官方对这个llms.txt审计项的判定规则写得很明确。
再看它所在的位置。这一项归在Agentic Browsing这个“实验性”类别里,是机器交互类的审计,跟SEO审计是明确分开的两套东西。而搜索团队那份正式指南的口径一点没变:AI Overviews、AI Mode这些生成式搜索功能,不需要llms.txt。
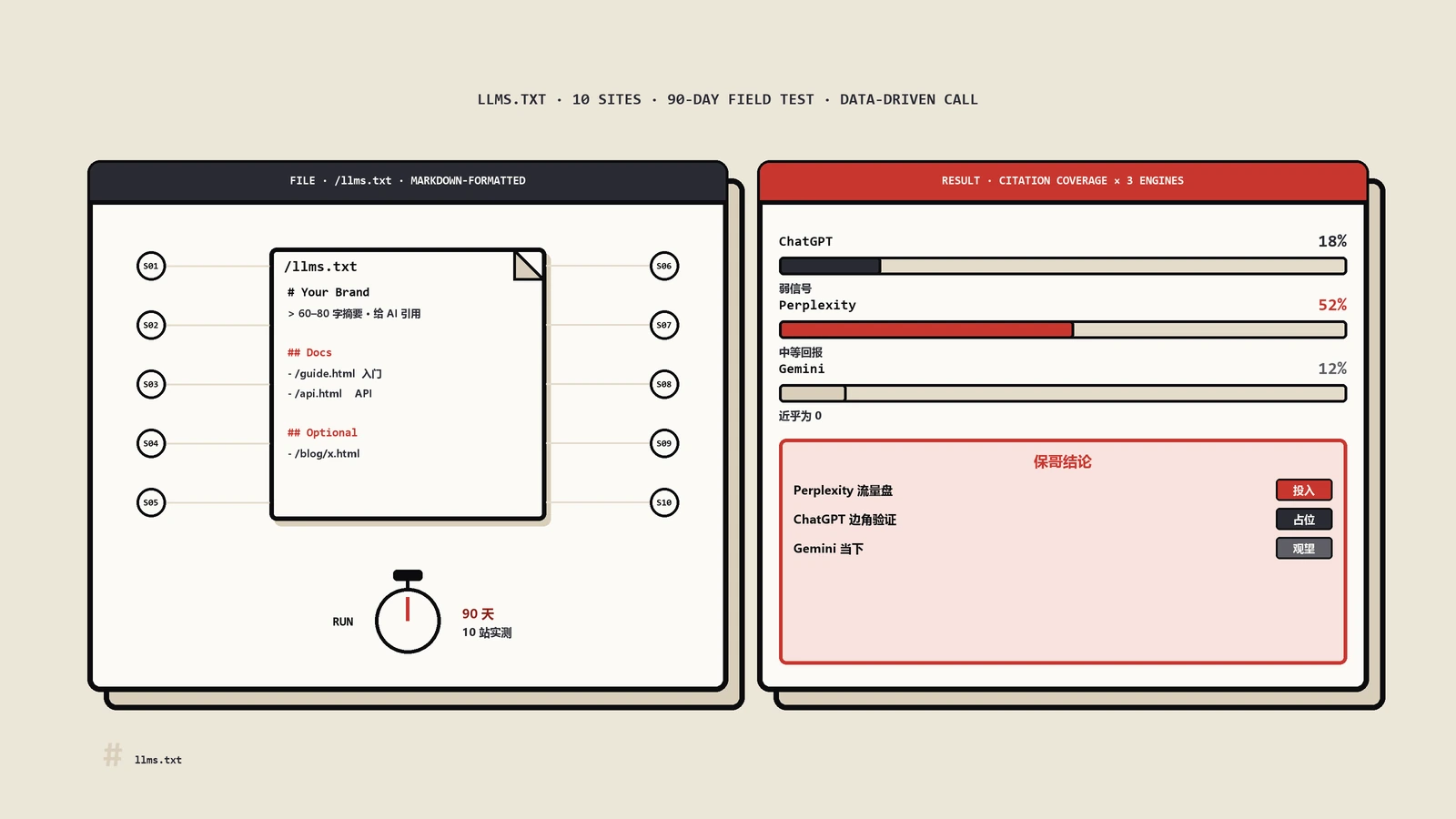
站内有一篇文章,拿10个站做了90天的实测,专门验证llms.txt到底有没有用,结论跟这儿完全对得上:它更像一份sitemap,是基础设施,不是增长开关;部署完绝大多数站没有可测量的流量变化。所以现状一句话说清:Lighthouse查它,不会让llms.txt变成必做项。值得认真做的,还是那两类站——开发者和API文档站、或者你的CMS、CDN能零成本帮你自动生成。剩下的情况,做不做都行,别为它手工精雕。
除了llms.txt,agent还会认AGENTS.md这类文件吗?
llms.txt不是这个赛道上唯一一个“声明文件”。这两年陆陆续续冒出来一批同类的东西,其中讨论度比较高的一个,叫AGENTS.md。
AGENTS.md干的事,跟llms.txt有点像、又不太一样。llms.txt偏向告诉机器“这个站有哪些内容、整体结构大概长什么样”;AGENTS.md更偏“能力声明”——它想告诉agent“这个项目能干什么、该怎么跟它打交道、有哪些约定和规范”。它最早是在代码仓库的语境里火起来的,给AI编程助手读,说明这个代码库怎么构建、怎么测试、有什么编码规矩。
Google Cloud那边负责AI工程的Addy Osmani,2026年4月提过一个叫“Agentic Engine Optimization”(面向agent引擎的优化)的说法,把这一类东西归到一起看。他的观察是:agent的上下文窗口有限,遇到又长又深、信息埋得很里层的页面,要么截断、要么干脆漏看。所以他建议的方向是几样东西凑一块——更干净的语义结构、更省token的内容、Markdown形态的交付、llms.txt这种发现层,再加上AGENTS.md这类能力声明文件。
但回到你最关心的那个问题——要不要现在就给站点加一个AGENTS.md?答案和llms.txt那条线几乎一模一样:判断标准还是那句话,会不会有AI编程助手高频来读你的东西。是代码工具站、API文档站、开源项目,值得认真做,因为它面对的就是agent密集取用的真实场景;是普通电商站、内容站、企业官网,加了基本没人读,它就是个摆设。
把这一整批文件——llms.txt、AGENTS.md、每页的Markdown版本——放在一起看,会发现它们共享同一条判断逻辑,根本不用一个个单独纠结:你的受众里,到底有没有“高频、程序化地来取你内容的机器”。有,这批东西就从摆设变成基建;没有,做多少个文件都改变不了agent不来这个事实。Osmani那套优化思路里,真正普适、对所有网站都成立的,其实只剩“干净的语义结构”这一条——而它,你早就该为用户和搜索引擎做了,根本不算为agent额外掏的钱。
怎么判断你的网站,现在到底该不该为agent投入?
讲了这么多“不用做”,得给一个正面的、能直接用的判断办法。判断的主轴,还是Mueller那句“先满足需求,再追梦”——把每一件事拆成两类:需求,是现在就确定能带来流量和转化的事;梦想,是为还没成气候的agent流量提前改造。需求永远排在梦想前面。
但“需求”和“梦想”的分界,对不同类型的网站不一样。下面这张表,按网站类型把优先级排了出来:
| 网站类型 | 现在就该做(需求) | 可以观望(梦想) |
|---|---|---|
| 开发者工具/API文档站 | Markdown版页面、llms.txt——认真做,因为AI编程助手高频取用是确定需求 | WebMCP可小范围试 |
| SaaS/在线工具 | 语义HTML、可访问性、CLS——本来就该做 | WebMCP(有交易闭环可试点)、Markdown版 |
| 电商独立站 | 语义HTML、可访问性、CLS、修JS渲染 | WebMCP、每页.md——除非已被agent结账高频调用 |
| 内容站/博客 | 语义HTML、可访问性、CLS | llms.txt(CMS能自动生成就顺手开)、其余都不用 |
| B2B企业官网 | 语义HTML、可访问性 | 几乎全部——agent流量在这类站近乎为零 |
这张表横着看是网站类型,但竖着看,你会发现一个更重要的规律:“现在就该做”那一列,反复出现的是同一批词——语义化HTML、可访问性、CLS、干净的结构。这批事有个共同特征:它们同时帮用户、帮搜索引擎、也帮agent。它们根本不是为agent下的赌注,它们是技术SEO的基本功,是无论agent来不来都该做好的事。agent只是顺带也受益而已。
所以真正的决策逻辑,不是“要不要为agent做事”,而是先把“稳赚不亏的基本功”和“为假想流量下的赌注”分开。前者,所有类型的站都该现在做;后者,除非你能指着具体的业务说出agent流量从哪来,否则就让它在“观望”那一列待着。
真要动手,先做哪几件、投多大成本才不亏?
假设你看完决定要动手了,那动手也有个顺序。下面这份清单,是按“确定性”从高到低排的——越靠前的越该先做。
第一档,现在就做,因为它根本不是为agent,是基本功,agent只是顺带受益。具体五件事:把伪装成按钮的div换成真正的button和a标签;把CLS压到0.1以下;给所有图片、视频、广告位、嵌入内容都设好尺寸;补全可访问性树,每个可交互元素都有清楚的ARIA标签和名字;修JavaScript渲染,让关键内容不要完全依赖客户端渲染才出得来。这五件做完,你的Lighthouse Agentic Browsing分数会自然涨上去一大半,而且——这才是重点——你的GSC表现、用户体验、移动端可用性会一起受益。这是一笔怎么算都不亏的投入。
第二档,顺手做不亏。主要是llms.txt和Markdown版——前提是你的CMS、CDN能零成本自动生成。能自动就开一下,要手工精雕就别碰。
第三档,先别做,除非你有明确的agent业务。WebMCP的工具合约、给每一页单独建.md产物的工程、专门的agent结账流程——这些都属于赌注,赌agent流量会规模化到来。没有具体的业务证据撑着,就先别投。
把它装进一个90天的节奏里:前30天,集中修第一档——别把它当“agent改造”,把它当成你早就该还的技术SEO债;中间30天,观察——看GSC数据、看服务器日志里有没有agent类的UA来访、看各渠道的流量构成有没有变化;最后30天,再根据观察到的真实信号,决定要不要碰第二、三档。最关键的一条提醒:千万别把这个顺序倒过来做。先上WebMCP、后修CLS的站,保哥真见过,结果就是下面这个案例。
为一笔还没来的流量提前改造,会亏在哪?
保哥去年接手过一个出海北美的桌面办公好物DTC品牌——卖升降桌配件、显示器支架臂、桌面理线槽、桌垫这类东西,客单价35到180美元。创始人是工程师出身,技术嗅觉很灵,这本来是好事,但这回也恰恰是坑的来源。
2026年初,他读了一大堆关于agentic的文章和分析,做了个判断:agent电商的时代要来了,得抢先发优势。于是他带着团队花了整整6周,干了这么几件事——搭WebMCP的工具合约端点、给每一个产品页生成对应的.md版本、写了llms.txt、还专门研究怎么对接agent的结账流程。听起来挺有前瞻性。
6周之后的结果是:agent给他带来的流量,是0。一个都没有。原因一点不意外——WebMCP标准当时还在Chrome的Canary预览阶段,全网根本没有规模化的agent会来访问一个普通DTC站。他为一群还没出生的访客,装修了一整套房子。
更伤的是这6周里被晾在一边的事。保哥进场后做技术体检,翻出来一堆真问题:移动端首页的CLS高达0.31(图片没设尺寸、网页字体加载得晚,首屏抖得厉害);几百个产品页因为模板的一个bug,H1标题整个缺失;sitemap半年没更新过;还有一批早就下架的SKU,对应的产品页全是404,没人清。这6周里,这个站的自然流量在持续往下掉——掉的恰恰是它当下唯一真实的流量来源。
保哥做的第一件事,是让他把那套agent工程整个停下来。然后用了3周,集中修真问题:CLS从0.31压到0.08、补回所有产品页的H1、重建sitemap、清掉死链。自然流量很快止跌、开始回升。这3周没干任何一件“面向agent”的新鲜事,全是还旧账。
这个案例里有个特别值得回味的细节:他那6周的agent工程,唯一真正产生了价值的部分,是他为了接WebMCP、顺手补的那批语义化HTML和ARIA标签——可那部分本来就该做,它的价值跟agent一点关系都没有,它属于第一档的基本功。换句话说,他6周里做对的那一点点,恰恰是那件“无论agent来不来都该做”的事。
所以这个客户的教训,不是“他做错了事”——WebMCP、llms.txt本身都不是错的东西。他错的是顺序。先满足需求,再追梦——Mueller这句话不是在反对追梦,它反对的是“梦还没醒,就先把需求给饿死了”。一个站当下确定的流量、确定的转化,是需求;一个可能三年后才规模化、也可能永远不规模化的agent访客,是梦。把梦排在需求前面,是这件事上最常见、也最贵的一个错。
常见问题解答
现在到底要不要做llms.txt?
绝大多数站不用。Google搜索官方指南明说生成式AI搜索不需要它。只有开发者、API文档站,或者CMS、CDN能零成本自动生成时,才顺手开一下,别手工精雕。
Lighthouse的Agentic Browsing分数低,会影响Google排名吗?
不会。这个类别是实验性的机器交互审计,跟SEO审计明确分开,不给加权总分,也不进排名计算。它是一个体检信号,不是排名因子,别太当回事。
给每个页面做Markdown版本有必要吗?
普通站没必要。主流大模型读HTML完全没障碍。只有AI编程助手会高频取用的技术文档站才值得做,省token的收益对它们才真正成立。
WebMCP现在该接吗?
绝大多数站不该。标准2026年2月才公布,只在Chrome早期预览里能用。除非你的核心业务就是被agent高频调用来完成交易,否则属于为假想流量提前烧钱。
那为AI agent改造,到底有没有现在就该做的事?
有。语义化HTML、把CLS压到0.1以下、补全可访问性树——这些同时帮用户、搜索和agent,本来就是技术SEO基本功,无论agent来不来都稳赚不亏。
Google搜索和Lighthouse对llms.txt口径不一样,该听谁的?
各管各的,不用二选一。搜索团队管“被搜到”,说不需要;Lighthouse管“被浏览器agent操作”,把它当可选项。你要的是搜索可见性,就按搜索团队的来。
权威参考资料
本文标题:《网站要不要为AI agent改造?这事Google没说清》
本文链接:https://zhangwenbao.com/ai-agent-website-readiness-audit-decision-framework.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0