Schema官方第一次公开全网使用数据:哪些结构化数据该做,别再凭感觉堆类型

本文目录
- 为什么这份“使用数据”比又一篇schema教程更值得看?
- 这份数据到底长什么样?
- 全网在用的schema,90%集中在哪几个?
- 这份官方数据,和第三方schema统计有什么不一样?
- 头部那12个里,有哪些是你“不写也已经在用”的?
- Product、Review、Article、FAQPage在1M到10M桶,说明了什么?
- 怎么用这份数据给自己的schema排优先级?
- “采用度高”就等于“该做”吗?数据的三个陷阱
- 长尾里50%的类型不到1000个域名用,这意味着什么?
- 属性比类型更值得看:name、description、image、url为什么排最前?
- 这份数据怎么帮你说服开发和老板?
- 桶位每月都在更新,怎么看采用度的趋势?
- 出海独立站该怎么读这份数据?
- 对AI搜索和GEO,这份数据意味着什么?
- 为什么是Google和Schema.org联手出这份数据?
- 一份真实复盘:把“128种全覆盖”砍回头部
- 哪些站可以先不折腾这份数据?
- 一份可落地的schema优先级自查清单
- 常见问题解答
- 这份Schema.org使用统计数据多久更新一次,在哪里能看到?
- 我用的schema类型落在低采用桶里,是不是说明我不该做?
- 使用统计能代替Google的富结果测试吗?
- schema用得越多,排名就越好吗?
- 出海独立站最该优先做哪几个schema?
- 中小站上结构化数据,该从哪几个类型先下手?
- 权威参考资料
摘要:2026年6月4日,Schema.org联合Google第一次把全网结构化数据的使用情况公开成数据集——哪个Type被多少域名用过、哪个属性最普及,全按域名分桶摊在明面上。过去判断“这个schema该不该做”靠经验和猜测,现在第一次有了全网采用度这把尺子。这篇不教你怎么写schema,而是带你读懂这份数据:5545条词汇里头部有多窄、长尾有多长,怎么用采用度反推自己站的schema优先级,以及最容易被误读的三个陷阱。出海独立站尤其要看,因为这份数据的爬虫口径,正好对着你要竞争的那片海。
做SEO这行,关于结构化数据的争论从来没停过。有人把schema当万能钥匙,恨不得128种类型全堆上;有人觉得是玄学,写了也不见排名动。两边吵了这么多年,谁都拿不出全网层面的硬数据,因为这数据本来就没人公开过。
这次不一样了。Schema.org在2026年6月4日发布的这份使用统计数据集,把词汇表里每一个类型、每一个属性在全网到底被多少域名用过,整理成了一份可下载、每月更新的数据。这是十几年来第一次,你能用“全网有多少人在用”这个客观维度,去校准自己对schema的判断。值不值得专门写一篇来讲,看完下面这些数字你就有答案了。
为什么这份“使用数据”比又一篇schema教程更值得看?
站内关于schema怎么写、用哪个工具生成、怎么校验,保哥已经写过不少。但那些都是“怎么做”的问题。这份数据回答的是一个更靠前、也更难的问题:在动手之前,你怎么知道某个schema到底值不值得做?
以前回答这个问题,靠的是三样东西:官方文档里列的支持类型、几个大站的抓包观察、还有同行口口相传的经验。这三样都有局限——文档只说“支持”不说“多少人真在用”,抓包样本太小,口口相传又掺了太多幸存者偏差。结果就是,schema优先级排序基本是凭感觉。
现在Schema.org直接把全网的采用度摊开了。这相当于把一道主观题变成了客观题:你不用再猜“Article这个类型是不是主流”,数据会告诉你它被几百万到上千万个域名用着。把决策从感觉挪到数据上,这件事本身就值得认真对待。
这份数据到底长什么样?
先把数据的基本盘说清楚,不然后面的数字没有坐标。这份数据集覆盖了Schema.org词汇表里的全部内容:958个Itemtype(类型)加上4587个Predicate(属性),总共5545条目。每一条都标注了它在全网的采用规模。
关键在于它怎么计数。这里有几个必须记住的方法论细节,否则极容易误读:
- 按域名聚合,不按页面。同一个term哪怕你在站内100个页面都用了,也只算1个域名。所以这些数字反映的是“多少个站在用”,不是“被用了多少次”。
- 用分桶代替精确值。不会告诉你某个类型刚好被7321456个域名使用,而是落进一个区间桶——比如10K到100K、100K到1M、1M到10M、10M以上。这样既稳定又保护隐私。
- 数据来自Google的公开爬虫。口径等于Google能抓到的那部分web,robots.txt挡掉的站不算在内。这一点对理解出海场景很重要,后面会展开。
- 每月推一次。更新文件会按月推到Schema.org的GitHub仓库,CSV和JSON两种格式,同时也内嵌到了每个term的官方页面上。
换句话说,你现在打开Schema.org上任意一个类型的文档页,就能直接看到它落在哪个采用桶里。不用爬虫,不用第三方工具,官方一手数据。这套计数口径的完整细节,官方写在了About Usage Statistics方法论文档里,想较真的可以去原文核对。
全网在用的schema,90%集中在哪几个?
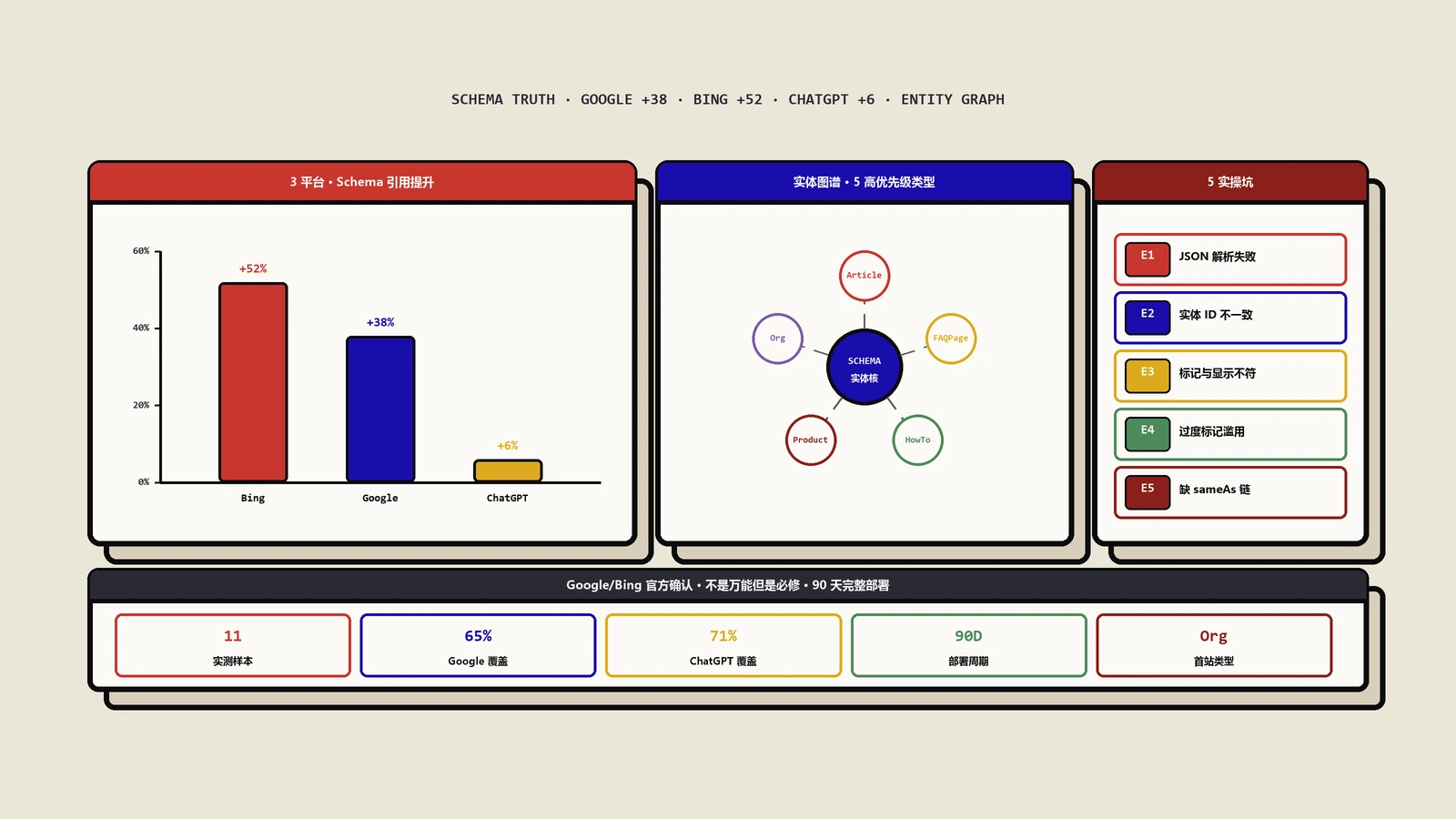
这是整份数据里最反直觉、也最该被记住的一组数字。先看头部。
采用度最高的那一桶——被超过1000万个域名使用的类型,总共只有12个:BreadcrumbList、EntryPoint、ImageObject、ListItem、Organization、Person、PropertyValueSpecification、ReadAction、SearchAction、Thing、WebPage、WebSite。
12个是什么概念?它只占整个词汇表958个类型的1.3%。也就是说,全网用得最凶的结构化数据,高度集中在不到2%的类型上。
再看尾巴。整份数据里,有485个类型——占全部词汇的50.6%——落在“不到1000个域名使用”的最低桶里。属性那边更夸张:4587个属性中有3779个,也就是82.4%,待在千域名以下的冷区。
把这两头放一起,结论很硬:schema词汇表是一个极度头重脚轻的结构。一小撮类型扛起了全网绝大部分的使用量,而一半以上的类型几乎没人碰。你以为有128种类型可选,真正活跃的就那么十几个加上中间一层。
这份官方数据,和第三方schema统计有什么不一样?
市面上早就有不少第三方报告,号称统计了schema的使用情况。那为什么这份官方数据还值得单独拿出来说?区别在三个地方,每一个都决定了你能不能信。
口径不一样。第三方工具的统计,多数基于自己抓的样本——抓几百万个页面,再往全网外推。Schema.org这份直接建在Google的公开爬虫基础设施上,覆盖的是Google能看到的整片web,量级和代表性完全不是一个级别。样本外推和全量统计,可信度天差地别。
计数单位不一样。很多第三方统计是按页面算的,一个站用一万个页面就计一万次,结果被大站严重带偏。官方这份按域名去重,一个站不管用多少页面都只算一票。这意味着它反映的是“有多少独立站做了这个选择”,而不是“某几个巨头刷了多少量”,对你判断“同行普遍怎么选”更有参考价值。
更新和透明度不一样。第三方报告往往是一次性的,发完就过时;官方这份每月推一次,还把原始CSV和JSON都放在GitHub上,谁都能下载核对。这种持续性和可验证性,是任何商业报告给不了的。
当然,第三方工具也不是没有不可替代的地方——它们在“你这个具体页面写得对不对”这种执行层检查上,依然比这份宏观数据有用。两者是分工,不是替代:官方数据帮你定战略方向,第三方工具帮你查执行质量。
头部那12个里,有哪些是你“不写也已经在用”的?
看到头部12个类型的名单,老SEO应该会心一笑。因为这里面大半,根本不是你主动决策的结果。
WebPage、WebSite、Organization、BreadcrumbList、ImageObject、ListItem、SearchAction这些,绝大多数是CMS、主题、SEO插件自动生成的。你装个Yoast或者Rank Math,开箱就给你吐出WebSite加SearchAction;用了带面包屑的主题,BreadcrumbList自动就有了。它们采用度爆表,恰恰是因为它们被“默认”了。
这给我们一个重要的过滤动作:头部高采用,不等于头部高价值决策。把这些“工具替你做掉的”剔除出去,真正需要你拍板该不该写、怎么写的类型,其实没剩几个。你的注意力不该浪费在这些已经自动到位的东西上,而该往下看一层。
Product、Review、Article、FAQPage在1M到10M桶,说明了什么?
往下一层,就是真正的决策区。在1M到10M域名这个桶里,住着35个类型,里面全是熟面孔:Product、Review、AggregateRating、Article、BlogPosting、FAQPage、LocalBusiness、VideoObject、Question等等。
这一层的特征很关键:采用度足够高,说明它们是经过市场检验的主流选择;但又没高到“默认自带”的程度,说明用它们需要你主动配置。换句话说,这35个类型,才是值得你花精力做决策和优化的核心区。
对不同类型的站,重点各有不同:
| 站点类型 | 该重点盯的主流schema | 为什么 |
|---|---|---|
| 电商/独立站 | Product、Review、AggregateRating、Offer | 直接关系到购物类富结果和AI购物的露出 |
| 内容/博客站 | Article、BlogPosting、FAQPage、Question | 影响文章在搜索和AI回答里被解析、被引用 |
| 本地服务 | LocalBusiness、AggregateRating | 本地包和地图露出的结构化基础 |
| 带视频的站 | VideoObject | 视频富结果的入场券 |
这张表不是保哥拍脑袋排的,而是这份采用度数据替你过滤出来的结果——它们之所以在这个桶,正是因为全网同类站都验证过它们值得做。关于这些主流类型具体怎么落地配置,可以接着看结构化数据Schema怎么配合SEO落地那篇里的实操拆解。
怎么用这份数据给自己的schema排优先级?
数据看懂了,落到自己站上怎么用?保哥给一个三步法,简单但管用。
第一步,先确定你这类页面“应该”有哪些schema。这一步靠的是搜索引擎对富结果的支持文档,不是采用度数据。比如商品详情页,候选就是Product加Offer加AggregateRating;文章页就是Article加BlogPosting。先把候选名单列出来。
第二步,拿采用度给候选名单分层。候选里落在头部和1M到10M桶的,是经过全网验证的安全牌,优先补齐;落在低采用桶的,先打个问号。这一步的作用是帮你在有限的开发资源里,先把确定有价值的做掉。
第三步,低采用的冷门类型,单独审视。它采用度低,要么是因为真没什么用,要么是因为太新或太垂直。你得逐个判断它对你的品类到底有没有富结果资格、有没有AI解析价值,而不是因为“能加”就加。
这套流程的核心,是用采用度数据做减法,而不是做加法。它帮你把那些“看起来很全、其实没人用也没用”的类型筛掉,把精力压到真正有回报的地方。如果你之前纠结过Shopify后台那128种类型到底怎么选,Shopify怎么给页面加结构化数据、128种类型怎么选这篇可以和这套数据法配着看。
“采用度高”就等于“该做”吗?数据的三个陷阱
这是全文最该慢下来读的一段。采用度数据很有用,但它也极容易被误读。保哥见过太多人拿着一个数字就冲,最后做了无用功。三个陷阱必须先排掉。
陷阱一:流行不等于有富结果资格。一个类型被很多域名用,不代表它能让你拿到富媒体展示。Google对哪些schema能触发富结果有自己的清单,而且这清单一直在收缩。最典型的就是FAQ富结果——被砍之前FAQPage满网都是,砍完之后采用度还在高位,但富结果早没了。采用度是历史存量,富结果资格是当下规则,两者不能划等号。盯着一个类型的采用桶位欢呼时,先去搜索引擎的富结果支持文档里确认它今天还认不认。
陷阱二:流行不等于对你的品类有用。全网平均采用度高,是因为它对“平均的站”有用,不是对“你的站”有用。一个内容站去对标电商的Product采用度毫无意义。看数据要看你所在垂直里同类站的选择,而不是全网大盘。
陷阱三:域名级计数只算“用没用”,不算“用对没用对”。这是最隐蔽的一个。分桶只统计某个类型在某个域名上出现过,完全不管它写得对不对、字段全不全、有没有报错。所以一个采用度极高的类型,背后可能有大量配置错误的实现。采用度能告诉你“值得做”,但做没做对,还得靠校验工具单独验。一个尾逗号就能让整页结构化数据失效,这种坑数据里完全看不出来,得用结构化数据审计工具把自己页面五种格式的字段缺漏一次扒清楚。
长尾里50%的类型不到1000个域名用,这意味着什么?
回到那个惊人的长尾:一半以上的类型几乎没人用。这片冷区,藏着两种完全相反的信号,得分开看。
第一种解读,也是大多数情况:这些冷门类型确实没什么实战价值。它们要么太学术、太边缘,要么早就被搜索引擎放弃支持。看到一个类型躺在最低桶,第一反应应该是警惕,而不是兴奋。
第二种解读,少数情况:你恰好领先于市场。如果某个新类型刚被搜索引擎纳入富结果支持,采用度还没起来,那这就是个早期窗口。但这种判断必须有“搜索引擎已支持”这个前提兜底,否则就是自嗨。
这片长尾最大的价值,其实是帮你识破营销话术。很多schema工具、很多插件,主打卖点就是“支持128种类型”“全类型覆盖”。这份数据一摆,你立刻就明白:那128种里有一大半是50.6%的冷门长尾,覆盖它们对绝大多数站毫无意义。真正该追求的,从来不是覆盖多少类型,而是把搜索引擎实际支持、且对你品类有用的那几个做对做全。
属性比类型更值得看:name、description、image、url为什么排最前?
大部分人讨论schema只盯类型,其实属性这一侧的数据,给出的启示更实在。
进入1000万域名以上桶的属性有31个,排在最前面的是这几个:name、description、image、url、headline、datePublished、dateModified、author、publisher、breadcrumb、logo,还有支撑站内搜索框的query-input。
看出门道了吗?这些全是最基础的描述性字段——名字、描述、图、链接、发布时间、作者。它们采用度最高,恰恰因为它们是任何一个类型能被机器正确解析的地基。一个Product对象,哪怕你不写花哨的扩展属性,name和image也必须全;一个Article,缺了author和datePublished,价值就大打折扣。
所以一个很实用的优先级排序浮出水面:与其去纠结要不要上某个冷门类型,不如先把头部这几个基础属性,在你已有的类型里填全填对。地基不稳,盖再多花样都是浮的。这一点,比追逐类型数量重要得多。
这也解释了一个常见的困惑:为什么有些站schema看着配得很简单,效果反而比堆满扩展属性的站更好?因为它们把劲使在了对的地方——基础属性齐全、准确,让机器能稳稳地解析出核心事实,而不是在一堆半残的高级属性里迷路。对绝大多数站来说,把头部那31个属性吃透,远比研究那些采用度极低的边角属性划算。属性这张表给的启示,其实比类型那张更朴素也更值钱:先求全,再求巧。
这份数据怎么帮你说服开发和老板?
schema有个老大难问题:SEO想做,但落地要靠开发排期,而开发凭什么为一个“看不见摸不着”的东西让路?这份数据,正好是你手里的弹药。
这份数据的价值很直白:知道一个schema元素到底流不流行,往往就足以说服开发团队把它做了。道理很简单——当你能甩出“这个类型全网有上千万个域名在用”的客观数字,而不是“我觉得应该做”,说服力完全是两个量级。
具体怎么用?提排期的时候,把候选schema的采用桶位列成一张表,配上对应的富结果或AI露出价值。头部高采用的,定位成“行业标配、不做就是落后”;中间层的,定位成“主流竞品都在做”。这样一来,schema不再是SEO一个人的执念,而是有全网数据背书的工程决策。老板和开发看的是数据,不是你的态度。
桶位每月都在更新,怎么看采用度的趋势?
很多人盯着这份数据,只看了一眼当下的快照就走了。其实它每月更新这个特性,藏着比快照更有价值的东西——趋势。
单看某个类型今天落在哪个桶,是静态信息;连续几个月看它在桶之间怎么移动,才是动态信号。一个类型如果在持续往上爬,说明市场正在向它聚拢,你早点跟上就是踩在风口;一个类型如果在往下掉,可能预示着搜索引擎对它的支持在弱化,或者有更好的替代方案出现,该考虑撤了。FAQPage就是活教材:它的采用度因为历史惯性还挂在高位,但你若能看到富结果资格被砍后的长期走势,就不会再往这棵树上吊死。
实操上,建议你把自己品类相关的十来个核心类型列个小台账,每个季度去Schema.org的term页面抄一次它们的桶位,记下来。几个季度下来,哪个在涨、哪个在跌一目了然。这点工作量很小,但它把一次性的“查一下”变成了持续的“盯趋势”,价值完全不同。
要提醒的是,分桶本身是个粗粒度的区间,桶内的小波动看不出来,只有跨桶的移动才算真信号。别因为某个类型这个月数字微微变了就过度解读,盯的是方向,不是噪声。
出海独立站该怎么读这份数据?
这一节是给做海外市场的同行划重点。前面提过,这份数据的口径是Google的公开爬虫——而这恰恰是出海站的主场。
国内站和出海站,在这份数据面前要分开看。如果你主要做百度、做国内市场,那这份基于Google爬虫的采用度,参考价值要打折,因为国内搜索引擎对schema的支持和偏好是另一套体系。但如果你做的是Google、做的是海外用户,那这份数据简直是为你量身定制的——它统计的就是你要竞争的那片web。
有个坑要提醒:别拿国内的schema经验直接套海外。国内一些平台对结构化数据的处理方式、对评论星级的展示逻辑,和Google并不一样。出海站应该以这份Google口径的数据为准绳,老老实实把头部和主流类型做扎实,而不是凭国内习惯想当然。
还有一层:robots.txt挡掉的站不进统计。如果你的站把Googlebot拦在外面,那你既不在这份数据里,也大概率不在Google的富结果和AI回答里。数据口径本身,也在提醒你检查抓取这件最基本的事。
对AI搜索和GEO,这份数据意味着什么?
2026年绕不开AI搜索。结构化数据在AI时代的角色,比在传统SEO里还要吃重——它是AI理解你页面的“事实层”,把杂乱的网页内容翻译成机器能直接采信的结构。
那头部那些高采用类型,是不是AI最可能解析、最可能采信的?方向上大概率是的。AI模型见过的训练数据和实时抓取里,这些主流schema出现得最频繁,模型对它们的解析也最成熟。把基础打在采用度高的类型和属性上,等于站在了AI最熟悉的语言上。
但这里要踩一脚刹车,避免over-index:使用统计数据不等于AI引用数据。一个schema被很多站用,不代表AI就会因此更多引用你。AI要不要引你,取决于内容质量、实体一致性、权威信号一大堆因素,schema只是让它“读得懂”,不是让它“非引你不可”。关于schema对AI搜索究竟有没有用、官方怎么说、实测又如何,Schema结构化数据对AI搜索到底有没有用那篇做过专门的拆解,建议和这份采用度数据对照着读,别把“流行”错当成“被引用”。
为什么是Google和Schema.org联手出这份数据?
退一步看,这件事本身就是个值得读的信号。Google为什么要花力气,联合Schema.org把这份过去从不公开的数据摊出来?背后的动机,比数据本身还有意思。
一个朴素的解释是:Google想推动整个web把结构化数据做得更好、更普及。结构化数据是机器理解网页的基础,而到了AI搜索时代,机器“读懂”网页的需求被放大到了前所未有的程度。把采用度公开,等于给所有犹豫要不要做schema的站一个推力——你看,大家都在用,你也该跟上。透明本身就是一种引导。
另一个解释藏在数据的结构里。还记得那个极端的长尾吗?一半以上的类型几乎没人用。这其实暴露了一个问题:Schema.org的词汇表太庞大、太学术,真正被市场接纳的只是很小一部分。把使用数据公开,也是在帮社区识别哪些词汇是有生命力的、哪些可以慢慢淡出,让这套标准朝着实用的方向收敛。
对我们做SEO的人来说,从这个信号里能读出的最实在的一条是:结构化数据在可见的未来只会更重要,不会更不重要。一个平台不会去给一件正在边缘化的事做透明化基建。Google愿意为schema的采用度背书,本身就说明它在Google的技术路线里分量不轻。这给那些还在怀疑“schema是不是玄学”的人,提供了一个来自平台行为的、而非口号的答案。
一份真实复盘:把“128种全覆盖”砍回头部
讲个最近遇到的真实例子,做脱敏处理。一个出海家居收纳的独立站,之前的SEO外包给他们配schema时,主打的就是“全类型覆盖”,后台塞了二十多种结构化数据,从Product一直到一些连名字都没人听过的冷门类型,看着特别唬人。
结果呢?Google的富结果测试天天报警告,校验工具一片红,真正想要的商品富结果反而时有时无。团队一直以为是哪个字段写错了,查了几个月没查出根因。
后来用这份采用度数据一对照,问题一下子清楚了:那二十多种里,有一多半都躺在50.6%的冷门长尾里,根本没有富结果资格,纯属为了“覆盖”而堆。它们不光没价值,还互相打架、拖累了核心类型的解析。处理方式很简单——做减法:砍掉所有低采用、无富结果资格的类型,只留Product、Offer、AggregateRating、Review这几个电商核心,再把name、image、price这些头部属性逐个填全填对。
一个多月后,校验报错清零,商品富结果稳定回来了。整个过程没加任何新东西,全是在砍。这就是采用度数据最朴素的用法:它给你砍掉冗余的底气。
这个案例还有个更深的教训值得说。团队之前之所以敢堆二十多种类型,是因为没有任何客观标准来判断“够了没有”——多一种总比少一种安全,反正看着全。这种“宁滥勿缺”的心态,恰恰是缺数据时的本能反应。一旦有了全网采用度这把尺子,判断逻辑就反过来了:不是“能加的都加上”,而是“没被验证过的先别动”。同样一堆类型,换一个判断框架,结论完全相反。所以这份数据真正改变的,不是某几个具体决策,而是你做schema决策时的默认姿态——从加法思维,切换到减法思维。
哪些站可以先不折腾这份数据?
照例说一句反面:不是每个站都得为这份数据大动干戈。
如果你的站还很早期,内容没几篇,那schema优先级排序的边际收益很低,先把内容和基础SEO做起来更重要。如果你用的CMS加SEO插件已经默认覆盖了头部那几个类型,而你又只是个标准的内容站或小电商,那你大概率已经踩在主流上了,不需要为了冷门类型额外开发。如果你是纯本地、纯线下导流的站,结构化数据的盘子本来就小,按LocalBusiness那条主线做扎实即可。
这份数据最大的价值,是给“想做却不知道从哪下手”和“做了一堆却不知道该砍哪些”的站,提供一把客观尺子。如果你既没纠结也没冗余,那就把它当成一年看一两次的体检报告,不用天天盯。
一份可落地的schema优先级自查清单
把全文压成一张能直接照着做的清单:
- 列页面类型。把你站上的页面分类——首页、商品页、文章页、分类页、本地页,分别列出来。
- 查每类页面该有的schema。对照搜索引擎的富结果支持文档,给每类页面列出候选类型,这一步以“有没有富结果资格”为准。
- 用采用度给候选分层。到Schema.org的term页面看每个候选落在哪个桶,头部和1M到10M桶的优先做,低采用的打问号。
- 先填头部属性。name、description、image、url、author、datePublished这些基础字段,在已有类型里全部填全填对,地基优先。
- 冷门类型单独裁决。低采用桶里的类型,逐个判断富结果资格和对你品类的实际价值,没把握就不做。
- 用校验工具验质量。采用度只管“值不值得做”,做没做对要靠校验。每次改完都跑一遍审计,把字段缺漏和语法错误清掉。
- 季度复查数据。这份数据每月更新,搜索引擎的富结果规则也在变,每个季度回头看一次,该补的补、该砍的砍。
照这张清单走一遍,你的schema就从“凭感觉堆”变成了“按数据排”。这正是这份数据集真正的意义所在。
常见问题解答
这份Schema.org使用统计数据多久更新一次,在哪里能看到?
每月更新一次。更新文件会推送到Schema.org的官方GitHub仓库,提供CSV和JSON两种格式;同时,每个类型和属性的采用桶位也直接内嵌显示在Schema.org官网对应的term文档页上。想看某个具体类型有多普及,直接打开它的官方页面就行,不需要任何第三方工具。
我用的schema类型落在低采用桶里,是不是说明我不该做?
不能直接这么下结论。低采用有两种可能:一种是这个类型确实没实战价值,那确实该砍;另一种是它太新或太垂直,但搜索引擎已经支持它的富结果,那它可能是个早期窗口。判断的关键不是采用度本身,而是“搜索引擎当下支不支持它的富结果”加“它对你的品类有没有用”。采用度只是参考维度之一,不是唯一裁判。
使用统计能代替Google的富结果测试吗?
不能,两者管的是完全不同的事。使用统计回答的是“这个类型全网有多少人在用、值不值得做”,是个战略层面的参考。Google富结果测试和校验工具回答的是“我这个页面的schema写得对不对、能不能触发富结果”,是个执行层面的检查。采用度高的类型你照样可能写错,所以做完一定要单独跑校验,两件事不能互相替代。
schema用得越多,排名就越好吗?
不是。这份数据恰好戳破了这个迷信——全网50.6%的类型几乎没人用,因为多数类型对多数站根本没价值。盲目堆类型不仅不涨排名,还可能因为配置出错、类型冲突拖累核心schema的解析。正确的做法是做减法:把搜索引擎支持、对你品类有用的那几个核心类型做对做全,远胜过覆盖一堆冷门类型。
出海独立站最该优先做哪几个schema?
对绝大多数出海电商独立站,优先级是:先确保头部基础类型(Organization、WebSite、BreadcrumbList,这些通常插件已经自动生成)到位;再重点做电商核心的Product、Offer、AggregateRating、Review;有博客内容的补上Article和BlogPosting。把这些落在头部和主流桶位的类型做扎实,再把name、image、price、author这些高采用属性填全,就已经覆盖了绝大部分价值。冷门扩展类型,等核心稳了再单独评估。
中小站上结构化数据,该从哪几个类型先下手?
跟着采用率走。先把Article、BreadcrumbList、Organization、Product、author这些高采用、回报明确的类型填全,就覆盖了绝大部分价值。冷门扩展类型等核心稳了再单独评估,别一上来就贪全。
权威参考资料
- Schema.org官方公告:Announcing the Schema.org Usage Statistics Dataset,数据集发布的一手说明,含发布时间与数据来源。
- Schema.org方法论文档:About Usage Statistics,详解域名级聚合、分桶口径与月度更新机制。
本文标题:《Schema官方第一次公开全网使用数据:哪些结构化数据该做,别再凭感觉堆类型》
本文链接:https://zhangwenbao.com/schema-org-usage-statistics-priority-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0