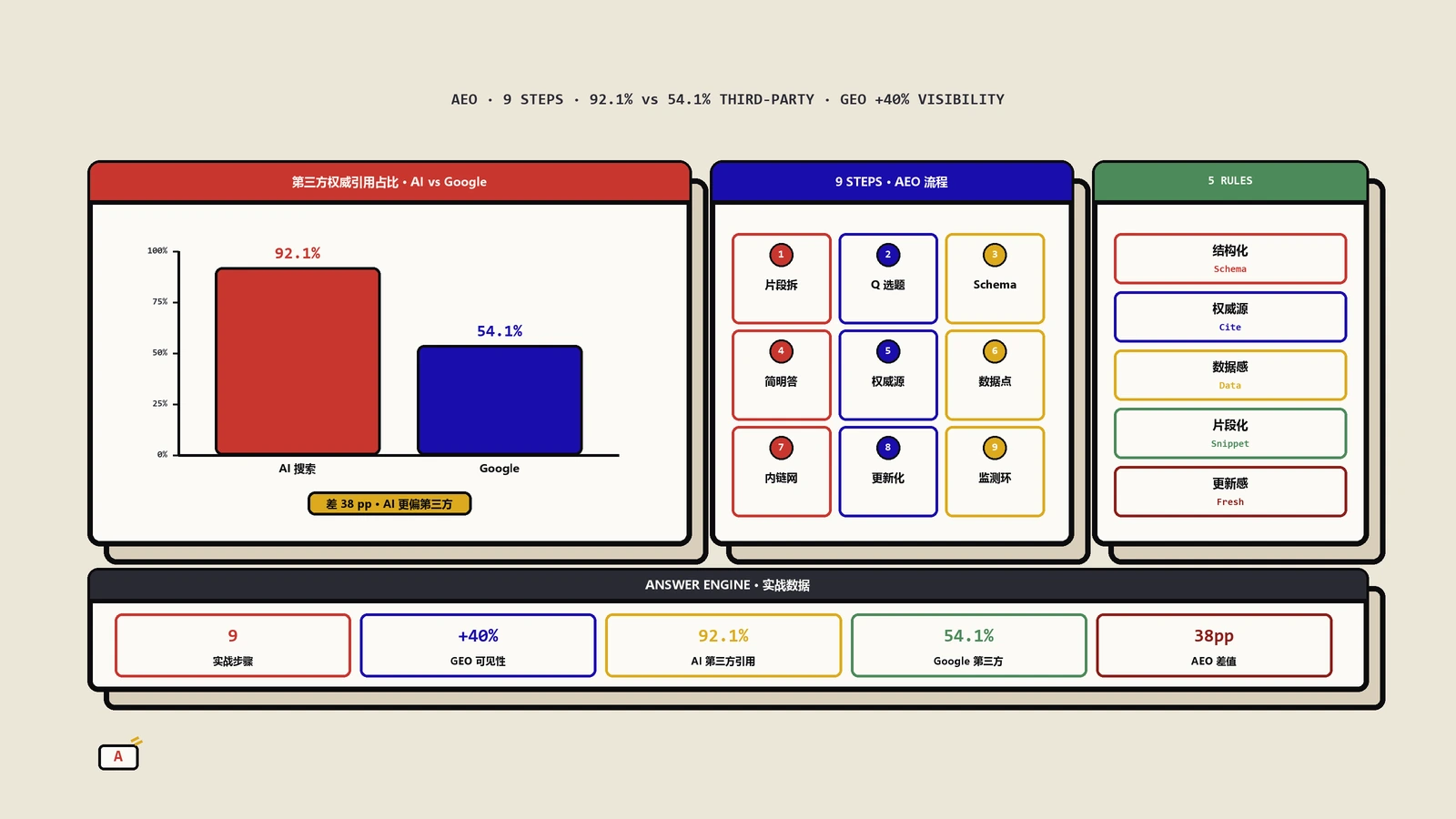
结构化数据Schema怎么配合SEO落地?附常见避坑
本文目录
- 结构化数据(Schema)到底是什么?
- 结构化数据对SEO到底有没有用?
- 除了JSON-LD,还有哪几种结构化数据格式?
- 为什么落地几乎只推荐JSON-LD?
- 结构化数据和Meta元数据有什么区别?
- Google目前支持哪些结构化数据类型?
- 还值得做的常用类型
- 已经被砍掉或缩限的类型,别再白做
- 结构化数据怎么落地实施?
- 先确认这个页面该用哪种类型
- 不会写代码也能加:插件与标记助手
- 需要工程师介入的三种写法
- 结构化数据怎么和内链、面包屑配合成站点级语义?
- 怎么确认Google识别了你的结构化数据?
- Google富媒体测试工具有哪些用不上的地方?
- 用结构化数据最常踩的两个坑是什么?
- 坑一:标记内容和页面实际内容不符
- 坑二:一个页面堆一堆不相关的标记
- 常见问题解答
- 在富媒体摘要里,用户点评分星级会直接进我网站吗?
- 同一个页面同时加JSON-LD和Microdata会冲突吗?
- 单页应用(SPA)的结构化数据该怎么部署?
- 可以标记用户看不到的内容来优化富媒体吗?
- 结构化数据会拖慢网站加载速度吗?
- 博客文章该用Article、NewsArticle还是BlogPosting?
- 加了结构化数据后,富媒体多久会出现?
- 普通独立站现在还该不该做FAQ标记?
- 权威参考资料
摘要:结构化数据(Schema)是用Schema.org词汇给网页内容打上搜索引擎能读懂的标签,让搜索结果有机会显示成带星级、价格、问答框的富媒体摘要。它不是直接排名因子,但能明显抬高点击率,而且目前大量网站还没用,是少见的低成本竞争差。这篇讲清楚它是什么、四种格式怎么选、Google现在到底支持哪些类型(含已被砍掉的)、从免代码到工程师三种实施路径,以及最常踩的两个坑。适合独立站运营和负责SEO落地的技术。
结构化数据这东西,独立站圈子里长期处在“都听说过、很少做对”的状态。有人压根没加,有人加了一堆却报错,还有人花大力气做了FAQ标记,结果2023年底Google早就把非政府非健康站的FAQ富结果下线了——白忙一场还不知道。把这件事讲透,得从它到底是什么开始,再一路讲到哪些类型现在做了还有用、哪些做了纯属浪费、以及落地时最容易栽的两个坑。
结构化数据(Schema)到底是什么?
用一句话说:结构化数据就是给网站内容穿上一件“搜索引擎能读懂的外衣”。它是一套遵循Schema.org词汇表的标准化代码,按特定格式加进网页,帮搜索引擎精准理解你这页信息的具体含义和上下文关系,而不是靠算法猜。
这里要先把一个术语绕清楚。Schema最早是Google、Bing、Yahoo几家一起制订的统一格式规范,对应的词汇表放在Schema.org这个站上。后来Google发展了自己的一套支持清单和细则,但行业里通常把“结构化数据”和“Schema”当同义词用,本文也不刻意区分。你只要记住一件事:词汇标准来自Schema.org,能不能变成搜索结果里的特殊展示,由各家搜索引擎自己的规则决定,这两件事是分开的——你按标准标了,不等于Google一定给你富媒体。
下面这张表把核心要素先摆出来,后面每一节都是在展开其中一行:
| 核心方面 | 关键说明 |
|---|---|
| 根本目标 | 让搜索引擎更懂你的内容,它本身不是直接排名因子 |
| 直观价值 | 让结果显示成富媒体摘要(星级、价格、问答框等),抬高点击率 |
| 主流格式 | JSON-LD,Google官方推荐,代码与内容分离、好维护 |
| 常见类型 | 文章、产品、本地商家、评论、面包屑等 |
| 关键步骤 | 选类型 → 生成代码 → 加进网页 → 用工具测试验证 |
没有结构化数据时,你的搜索结果就是一条普通蓝色标题加一段摘要。加对之后,差别是肉眼可见的:产品页能直接显示价格、库存状态、评分星级;食谱页能展示烹饪时间和热量;文章页能突出作者和发布日期;本地商家能展示地址、电话、营业时间。这种增强展示的实际意义不是“好看”,是用户在结果页就能判断这页满不满足需求,点进来的更精准,跳出也更低。
结构化数据对SEO到底有没有用?
有用,但要把“有用”说清楚,否则容易优化错方向。它的作用是消除歧义加增强展示,不是直接给你加排名分。
举个最常被用来解释的例子:网页上“苹果”这个词,可以是水果,也可以是那家科技公司。结构化数据的作用,就是明确告诉搜索引擎“这里指的是一个叫Apple Inc.的组织”,歧义没了,引擎对内容的分类和索引就准了。理解准了,这页出现在相关查询里的机会自然变大——这是它间接影响排名的真实路径,不是它直接当排名因子。把这个机制想明白,你就不会再纠结“加了Schema为什么排名没立刻涨”这种问错方向的问题。
| 维度 | 没用结构化数据 | 用了之后 |
|---|---|---|
| 结果展示 | 普通蓝色标题加摘要 | 可能呈现富媒体摘要:星级、价格、问答等 |
| 理解精度 | 靠算法推测,可能歧义 | 给明确上下文,分类索引更准 |
| 点击率 | 主要靠排名位置硬拼 | 视觉更突出,排名稍低也能多拿点击 |
| 用户体验 | 得点进页面才看到关键信息 | 结果页就给核心信息,帮用户快速决策 |
| 特定场景 | 表现普通 | 本地搜索、语音搜索匹配度明显更好 |
这种“精准翻译”带来的价值集中在两块。一块是富媒体摘要,这是最直接最显著的效果:你的结果从单调文本链接,变成带评分、价格、日期、问答的丰富展示,视觉上压过周围普通结果,点击率自然上来。另一块是提升理解从而间接影响排名:内容被更准确地理解后,它出现在相关查询里、被判定为好答案的可能性都更大。
用一个产品页的前后对照感受一下差别。没标Product结构化数据时,这页在搜索结果里就是一行蓝色标题加一段被截断的描述,用户得点进来才知道多少钱、有没有货、评价如何,很多人懒得点就划走了。标对之后,同一个位置可能显示成带价格、库存状态、评分星级和评价条数的富媒体摘要,用户在结果页就完成了“值不值得点”的初筛——愿意点进来的,是已经被价格和评分筛过一轮的高意向用户。注意这里的因果:排名位置没变,但单位展示能换到更多、更精准的点击,这就是为什么说它“排名稍低也能多拿点击”。理解清楚这条因果,你就不会再期待“标了Schema排名立刻往上窜”,而会去正确地衡量它——看的是这页的点击率和点击质量,不是排名数字。
说几个能量化的点。Google官方明确讲过,用了结构化数据的页面点击率会比没用的明显更高,量级在两成以上;第三方大规模实测里,带结构化数据的站点平均排名也更靠前。更值得注意的是另一个数字:到现在为止,相当大比例的网站根本没认真用结构化数据。这意味着它是为数不多的“别人还没做、你先做就能拉开差距”的低成本动作,越往后这个红利越薄。它对AI搜索引擎到底有没有用、官方和实测怎么说,是另一个独立话题,保哥单独写过Schema对AI搜索有没有用的真相,这里只锁定传统搜索这条线。
除了JSON-LD,还有哪几种结构化数据格式?
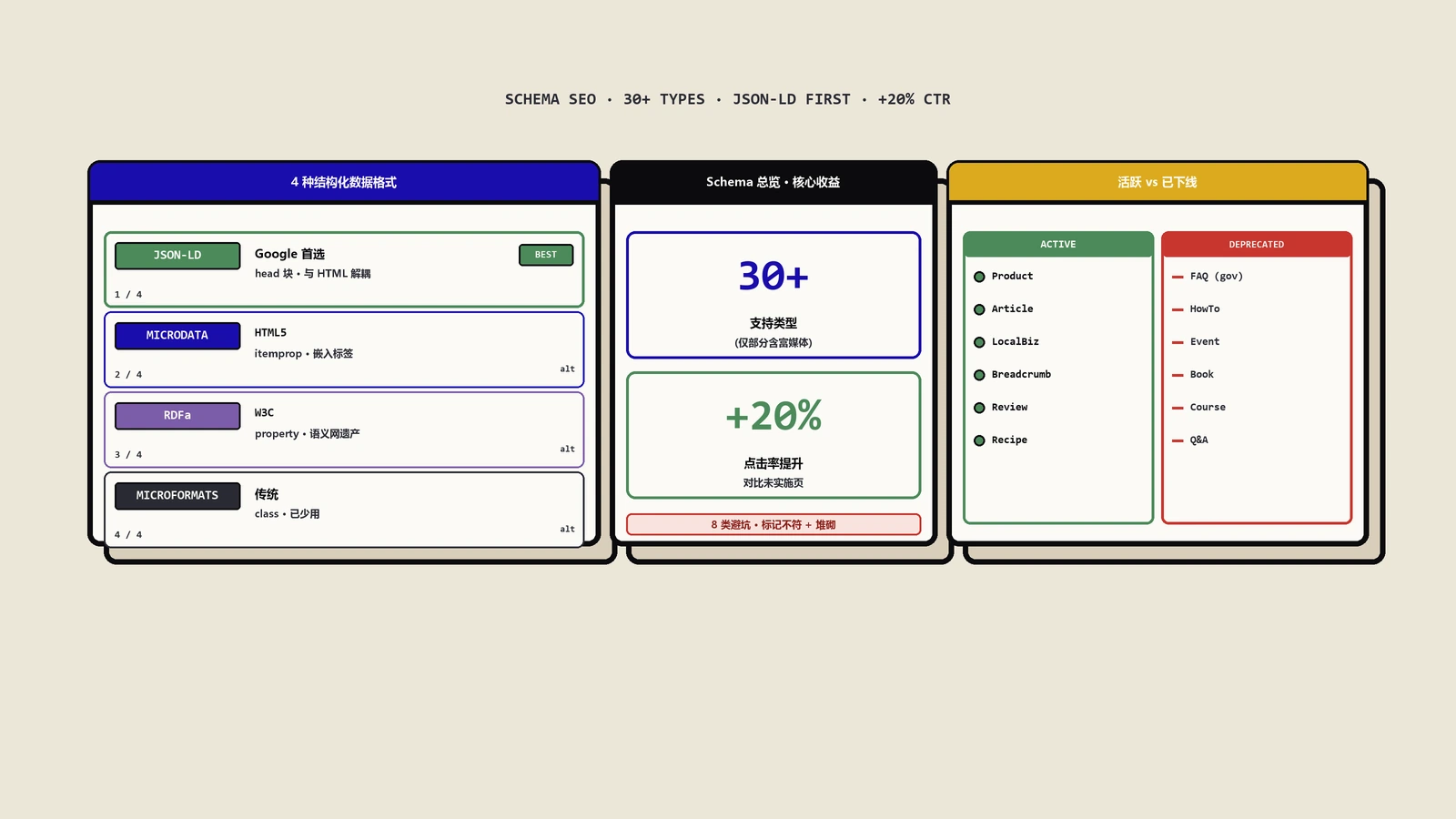
常见的结构化数据格式有四种:JSON-LD、微数据(Microdata)、RDFa,以及相对轻量的微格式(Microformats)。先用一张表看清差异,再讲为什么落地基本只推荐其中一种。
| 特性 | JSON-LD | 微数据Microdata | RDFa | 微格式Microformats |
|---|---|---|---|---|
| 语法形式 | 独立于HTML的JSON脚本块 | 内嵌HTML标签属性(itemscope、itemprop) | 内嵌HTML标签属性(vocab、typeof、property) | 用特定CSS类名(h-card、h-event) |
| 可读维护 | 很好,代码与内容分离 | 一般,与HTML混在一起 | 较差,属性多语法复杂 | 较好,语法简单直观 |
| 灵活性 | 很高,支持复杂嵌套、易动态生成 | 一般,适合简单实体 | 高,语义表达力强 | 低,只适合简单的人事地物 |
| 典型应用 | 各种复杂类型,当前主流选择 | 产品、事件、人物等信息 | 需要表达丰富语义关系的场景 | 博客、联系人、活动等简单社交数据 |
| 搜索引擎推荐 | 首选推荐 | 支持但非首选 | 支持但非首选 | 支持 |
为什么落地几乎只推荐JSON-LD?
有个常被搞错的细节:Google官方明确支持的是三种格式,不是四种——JSON-LD、Microdata、RDFa。其中JSON-LD是它强烈推荐的首选,官方开发者文档的原话大意就是“我们目前更推荐JSON-LD标记”。Microdata和RDFa是支持但非首选,都是通过HTML标签属性把数据嵌进可见内容里。Google偏爱JSON-LD的原因很实在:
- 好实现好维护。它是独立的
<script>块,不和其他HTML元素纠缠,编写、调试、批量管理都简单,改标记不会动到页面结构。 - 灵活性高。可以用JavaScript或CMS工具动态注入,即使不直接改HTML主体也能加上结构化数据。
- 表达力强。复杂的、嵌套的实体关系它能轻松描述,比如一篇文章关联多个作者、一个产品关联多个报价。
还有一个坑要单独点名:有一种叫Data-vocabulary.org的旧格式,Google已经明确不再支持它生成富媒体结果。你要是在老教程或老代码里翻到它,直接弃用,别照抄,否则测试工具会报错且不会有任何富媒体展示。
结构化数据和Meta元数据有什么区别?
这两个常被混为一谈,但角色完全不同:结构化数据是给搜索引擎的“内容说明书”,Meta元数据是网页的“身份证和广告语”。
| 对比维度 | 结构化数据 | Meta元数据 |
|---|---|---|
| 核心功能 | 深度解释内容的具体含义和关系(价格、时间、评分) | 概括描述网页基础信息(标题、描述、关键词) |
| SEO主要价值 | 争取富媒体结果、抬点击率,帮引擎精准理解 | 影响结果里的标题和摘要、吸引点击,辅助基础索引 |
| 对结果的直接影响 | 可能触发额外信息展示(星级、价格、问答框) | 直接影响蓝色标题链接和描述摘要 |
| 代码形式与位置 | 多用JSON-LD,独立脚本块嵌进<head>或<body> | HTML标签(<title>、<meta name="description">),在<head> |
把两者的SEO角色再说深一层。结构化数据要的是“特权展示”:用Schema.org的标准词汇明确告诉引擎“这是一款产品,价格X元,评分Y星”,引擎充分理解后,就可能在常规结果基础上给你生成更丰富的富媒体摘要,让你在一堆普通蓝链里跳出来。Meta元数据则是引擎理解你网页的第一道关口,其中标题标签和描述标签最关键:标题标签是SEO里权重最高的元素之一,直接决定结果里的蓝色标题,要准确含核心词又能吸引点击;描述标签虽然不直接参与排名,但像广告语一样极大影响用户点不点,引擎也常拿它当摘要显示。
实操上两者是配合关系,不是二选一,按这三条协同:
- 先基础后进阶。先把Meta元数据做扎实,标题描述准确吸引人,这是地基;在此之上再为产品、文章、本地商家这类重要类型加结构化数据去争富媒体结果。
- 内容一致是铁律。不管Meta还是结构化数据,描述的内容必须与页面上用户可见的内容完全一致,造假或误导会被处罚。
- 用官方工具各管一段。结构化数据部署后用富媒体结果测试验证,Meta标签的索引和点击效果用Search Console长期盯。
Google目前支持哪些结构化数据类型?
这一节是大多数教程没讲透、却最影响投入产出的部分。Google支持的结构化数据类型有三十多种,但关键不在“有多少”,在于哪些还在大力支持、哪些已经被砍了富媒体展示——后者你做了也不会有任何特殊呈现,纯浪费工时。
还值得做的常用类型
按内容领域分,最常见且效果明显的是这些:
| 内容领域 | 典型类型 | 核心价值 |
|---|---|---|
| 商品与电商 | Product(价格、库存、评分、品牌)、Review | 结果直接显示价格、是否有货、评级,点击率提升明显 |
| 内容与媒体 | Article、Recipe(时间、热量)、Movie(评分、主演) | 以焦点资讯、食谱卡片等富媒体形式突出 |
| 本地与实体 | LocalBusiness(地址、电话、营业时间、坐标) | 方便用户直接联系或导航,对本地排名很关键 |
| 导航与组织 | Breadcrumb、Organization、Logo、Sitelinks Searchbox | 强化站点结构与品牌实体识别 |
| 就业与教育 | JobPosting、Education QA、Practice Problems | 突出职位与学习信息,精准吸引目标人群 |
实施这些类型时有几条核心建议能少走弯路:优先标你最核心的业务内容(内容站先标Article,电商站重点标Product),集中资源标能带来最大商业价值的内容;务必填满所选类型的全部必填属性,并尽量多填推荐属性,属性越全富媒体摘要越丰富、通过率越高;统一用JSON-LD加Schema.org标准词汇,别混用别自造。面包屑这一类容易被忽视,但它对引擎理解站点层级和移动端展示都有实际作用,不同实现方式各有取舍,保哥单独拆过面包屑导航的四种类型与结构化数据实操,需要的话可以单独看那一篇。
已经被砍掉或缩限的类型,别再白做
这是最值钱的一段。Google这几年陆续下线了一批类型的富媒体展示,很多老文章还在教你做,做了却没有任何效果:
- FAQ富结果:2023年10月起,只对政府和健康类网站显示。普通独立站再标FAQ,搜索结果里也不会出现那个问答下拉框了。这一刀砍掉了大量人的既有做法,背景和后续到底还该不该写,保哥专门写过Google下线FAQ富结果后该不该继续写。
- HowTo(作法步骤):2023年9月已淘汰富媒体展示。同样,标了也不再有步骤卡片。
- Event(活动):2023年10月起淘汰了复合式搜索结果展示。
- Book、Car、Course、Occupation、Learning Video、Fact Check等:自2025年6月起陆续停用,做之前先确认当下状态。
- Software App、Speakable、COVID-19公告等:长期处于Beta或公告状态,稳定性和覆盖面有限。
这串清单的意义不是吓你,是提醒一个反直觉的事实:结构化数据不是“做得越多越好”,类型清单一直在变,去年还有效的今年可能就废了。落地前花十分钟去官方文档确认这个类型当前的状态,比闷头标完再发现没用强得多。
结构化数据怎么落地实施?
实施路径按团队能力分三条,从完全不写代码到需要工程师介入,挑适合自己的那条就行。
先确认这个页面该用哪种类型
不同业务需要的标记完全不同。一个卖运动鞋的站,产品页要Product和Review,但根本不需要Recipe;一个内容站,文章页用Article,本地门店页才需要LocalBusiness。先把“我这页的核心业务是什么、对应Schema.org哪个最具体的类型”想清楚,再动手,别一上来就套一堆。选最具体的类型很重要:博客文章用BlogPosting比笼统的Article更精准,新闻报道用NewsArticle,引擎对越具体的类型给的富媒体支持越明确。
资源有限时,按这个优先级铺,而不是从首页往下挨个标:
- 先标直接带钱的页面。电商站就是产品页的Product和Offer,本地生意就是LocalBusiness,这些类型的富媒体(价格、评分、营业信息)对点击和转化的拉动最直接,投入产出比最高。
- 再标流量大的内容页。博客和指南类用Article或BlogPosting,量大的话优先标进站流量前列的那批。
- 然后补站点级的基础标记。Organization、Logo、Sitelinks Searchbox这类全站只需配一次,强化品牌实体识别,一劳永逸。
- 最后才考虑边角类型,且先确认它当下还有没有富媒体展示——别把时间花在已被下线的类型上。
不会写代码也能加:插件与标记助手
对WordPress站,最省事的是装一个带Schema功能的SEO插件,在它的结构化数据生成器里选类型、填字段就行,全程不碰代码。Shopify这类平台各有自己的实现方式和限制,平台向的具体做法保哥在Shopify常用结构化数据实施指南里讲过,思路是一样的:用平台或插件能力把字段填对,别手搓。
另一个免写代码的官方途径是Google的结构化数据标记助手,操作大致是:选一种支持的类型,贴上网页地址或要标的代码开始标记,把页面上要标的内容反白选中并指定它是什么(标题、价格、评分等),全部标完点生成,工具会产出对应的JSON-LD代码,你再把这段代码贴进网页HTML里即可。它的限制要知道:支持的类型有限,生成后仍需手动贴入,更适合一次性少量页面,不适合规模化。
需要工程师介入的三种写法
要更精细或要规模化,就得动代码,三种语法各有定位:
- JSON-LD:首选。放在HTML的
<head>区,是独立脚本块,完全不影响前台可见内容,还可以通过代码管理工具(如GTM)统一注入便于批量维护。它逻辑上分两部分:一部分声明用的是Schema以及具体类型,另一部分填该类型要求的具体字段值,类型选错或必填字段缺失都会导致测试不通过。 - Microdata(微数据):把标记用
itemscope、itemtype、itemprop等属性嵌进已有的HTML内容里,改的时候要格外小心别动到读者可见的内容,否则容易标记和显示不一致。 - RDFa:和Microdata思路相似,也是内嵌进现有HTML,用
vocab、typeof、property等属性标示,语义表达力强但语法更繁琐。
给一个最小可用的JSON-LD产品标记长什么样,照着这个结构往里填就行:
{
"@context": "https://schema.org",
"@type": "Product",
"name": "产品名称",
"image": "https://example.com/product.jpg",
"description": "一句话产品描述",
"brand": { "@type": "Brand", "name": "品牌名" },
"offers": {
"@type": "Offer",
"price": "199.00",
"priceCurrency": "USD",
"availability": "https://schema.org/InStock"
}
}这段里每个字段都必须对应页面上用户真能看到的内容:price要和页面标价一致,availability要和实际库存状态一致,image要是页面上真实展示的主图。把它包进一个<script type="application/ld+json">标签放进<head>就完成了。复杂场景(多变体、带评分、带面包屑)在这个骨架上按Schema.org文档往里加属性即可,原则不变:先满足必填,再补推荐属性提升富媒体丰富度。
不管哪种写法,部署完都必须进测试环节,这是下一节的事。
结构化数据怎么和内链、面包屑配合成站点级语义?
大多数人把结构化数据当成一页一页孤立去标,漏掉了它真正的杠杆——站点级的实体网络。单页标记解决“这一页是什么”,站点级标记解决“这个网站、这个品牌是谁,以及它的内容怎么组织”,后者对实体识别和长期权威的作用更大。
站点级有三件事配合起来才完整:
- Organization加sameAs把品牌绑成一个实体。在站点级标一份Organization,name、logo、url齐全,再用sameAs列出你官方的社媒、第三方权威资料页地址。这等于明确告诉引擎“这些分散在全网的资料指的是同一个我”,实体一旦被认清,后续内容的可信度判断都受益。
- Breadcrumb把站点层级显式喂给引擎。面包屑结构化数据不只是搜索结果里那行导航好看,它是在用机器可读的方式声明“这页在站点信息架构的哪一层、它的父级是什么”。引擎据此理解你的内容怎么分类组织,这和内链传递的层级信号是相互印证的。
- 内链和结构化数据要讲同一个故事。如果你的内链结构把一组页面织成了一个主题簇,但结构化数据里类型乱标、面包屑层级和内链层级对不上,引擎收到的是互相矛盾的信号,反而削弱判断。两套结构必须一致:内链怎么组织主题,面包屑和Schema就怎么声明层级。
一个实际的对照:两个内容体量差不多的独立站,A站只在每页单独标了Article,站点级什么都没配,内链也松散;B站标了Organization加sameAs、全站统一面包屑、内链按主题簇组织且和面包屑层级一致。引擎对B站的“这是谁、它擅长什么、内容怎么组织”有清晰得多的判断,同样质量的新内容,B站被正确归类和被当权威来源的速度明显更快。这就是为什么结构化数据不能只停在单页——它和内链、面包屑是同一套站点结构的三种表达,缺一块,引擎拿到的就是半张地图。
怎么确认Google识别了你的结构化数据?
有一套很成熟的官方流程,分即时验证和长期监控两层,组合用。
| 方法 | 主要用途 | 适用场景 |
|---|---|---|
| 富媒体搜索结果测试 | 快速单次验证某URL或代码片段能否生成富媒体结果 | 新加标记后立即检查、调试修复、预览呈现 |
| Google Search Console | 长期批量监控全站结构化数据健康度 | 看全站哪些页被识别、收错误提醒、跟踪展示与点击 |
| Schema.org验证器 | 纯粹校验代码是否符合Schema.org通用规范 | 不针对Google富媒体功能、只验词汇表合规时 |
即时验证用富媒体搜索结果测试最快,流程是:打开工具,要么贴已上线的网址(最常用),要么在开发阶段切到代码标签贴代码,运行测试后它会明确告诉你这页符不符合富媒体条件、是哪种类型,并分别列出所有错误(会直接阻止展示,必须修)和警告(建议修但不阻止)。改到没有错误为止,这是发布前拦住硬伤最有效的一步。
长期监控靠Search Console。先确保站点已验证并提交了站点地图,帮Google发现你的所有页面;然后在“增强功能”或搜索结果呈现报告里,看Google在你站上检测到的各类富媒体类型,每类有多少有效页、多少报错或警告页;再配合网址检查工具,它能显示Google上次抓取该页时看到的实际HTML,确认它看到的和你测试的是不是同一份内容,这对排查“本地测通了线上却没出”特别有用。
还有三条必须记住的认知,少踩很多冤枉坑:
- 识别不等于展示。工具说“符合条件”只代表Google技术上理解了你的数据,会不会真以富媒体形式显示,还取决于查询、用户上下文等一堆因素,没有任何工具能保证一定展示。想明白这点就不会因为“测试通过却没出富媒体”误判成代码有问题。
- 数据必须真实准确。标记内容与页面可见内容完全一致,标不存在的信息可能招致手动处罚。
- 定期检查。网站换模板或内容大改可能意外破坏结构化数据,大改之后务必重新跑一遍测试。
Google富媒体测试工具有哪些用不上的地方?
这个工具很实用,但边界要清楚,否则会过度依赖它做错判断。
| 局限 | 具体说明 |
|---|---|
| 结果非保证 | 测试通过只代表技术合格,不保证一定在搜索里显示成富媒体 |
| 验证范围有限 | 主要查语法和必需属性,对内容质量、相关性等非技术因素几乎不评估 |
| 结果有时效 | 反映的是测试瞬间的页面状态,之后内容变了展示可能就不同 |
| 不模拟排名 | 不评估内容质量、外链、页面体验等影响排名的因素 |
| 动态内容挑战 | 需要用户交互才加载的标记,工具可能识别不到 |
正确的用法是把它当成一个优秀的“代码语法和最小规范校验器”,而不是“搜索结果模拟器”,它的主要作用是部署前发现并修复错误。配套这么用:已上线被索引的站,用Search Console的增强功能报告看全站健康度概览;要确认Google到底看到了什么,用网址检查工具看它抓取时拿到的真实HTML,对比你测试时的内容是否一致;只想纯粹验证是否符合Schema.org通用词汇标准(不特定于Google富媒体功能)时,用独立的Schema.org验证器。三件工具各管一段,别指望一个工具回答所有问题。
用结构化数据最常踩的两个坑是什么?
实施层面真正高频的翻车就两类,其余多是这两类的变体。
坑一:标记内容和页面实际内容不符
Google要的是富媒体结果给用户实用且正确的信息。一旦你标的东西和页面真实可见内容对不上——典型如在FAQ标记里塞一段产品宣传文案、标一个页面上根本没显示的价格或评分——很可能被判定为误导信息,轻则不展示富媒体,重则影响这页甚至站点的排名和权重。这是Google的硬性规定,不是建议:所有标记的内容必须与用户可见内容完全一致。
这里有个跨境独立站的真实场景。一个做出海3C数码配件的客户,产品页用插件批量加了Review评分Schema,但评分数据是从一个第三方聚合接口拉的、页面上压根没展示对应评论。富媒体测试全绿,发上去几周后评分星级却始终不出,再过一阵核心产品词排名还往下掉了。问题就出在“标了用户看不到的数据”这条红线上。处置很直接:要么把真实评论在页面上显示出来让标记与可见内容对齐,要么撤掉这段Schema。对齐之后展示才慢慢恢复。这种坑没有漂亮的数字可以承诺,因为恢复速度取决于抓取频率和站点权重,能确定的只有一点:标记必须对应可见内容,这条没有例外。
坑二:一个页面堆一堆不相关的标记
结构化数据不是越多越好。一个纯产品销售页,没必要硬塞Article、Recipe、Video这些八竿子打不着的Schema。堆无关标记不会让你“多几种富媒体机会”,反而让Google难以判断这页到底是什么、哪段数据才权威,结果可能是该出的富媒体也不出了。原则很简单:只标这页内容真实对应、对你业务最有价值的那一两种类型,集中资源标核心内容,比铺一堆都做不精强。
当测试工具报错时,按这张表排查通常很快能定位:
| 常见问题 | 诊断与修复 |
|---|---|
| 缺必填属性 | 对照Schema.org文档补全所有标了Required的属性 |
| 格式或值错误 | 日期时间用ISO标准格式(如2025-09-27T18:00:00Z),数值字段别带文字单位 |
| 标记内容不可见 | 检查是否标了用户在页面上看不到的内容,全部改成可见 |
| 标记不相关内容 | 去掉与页面主题无关或误导性的标记,避免被当垃圾内容 |
还有一类容易被忽略的维护问题:价格、库存、促销有效期这些会变的字段,要建机制让Schema跟页面同步动态更新,不然展示价和实际价对不上同样算内容不符;网站换模板或大改版后,结构化数据常被意外破坏,大改之后务必重新跑一遍测试。另外要留意搜索引擎对特定类型显示规则的调整(前面那串弃用清单就是例子),算法和规则在变,结构化数据的优化从来不是一劳永逸。
常见问题解答
在富媒体摘要里,用户点评分星级会直接进我网站吗?
通常不会。星级是富媒体摘要的一部分,作用是吸引用户点击整个链接,点星级本身一般不跳转,点标题或描述才会进你的网站。
同一个页面同时加JSON-LD和Microdata会冲突吗?
可能冲突或被误解。Google建议每个实体只用一种格式标记,重复标记会让它难以判断哪份数据权威,可能导致富媒体不准确甚至不显示。
单页应用(SPA)的结构化数据该怎么部署?
推荐JSON-LD动态注入:用JavaScript在页面完全渲染后把JSON-LD注入head或body区,再用网址检查工具确认Googlebot能渲染看到。
可以标记用户看不到的内容来优化富媒体吗?
绝对不可以。这是Google硬性规定,属垃圾行为。所有标记内容必须与页面上用户可见内容完全一致,否则可能触发手动惩罚。
结构化数据会拖慢网站加载速度吗?
影响非常小。JSON-LD是轻量脚本块,执行极快,对整体加载几乎没影响,远不如图片或渲染阻塞脚本那么耗。
博客文章该用Article、NewsArticle还是BlogPosting?
选最具体的:一般博客用BlogPosting,时效性强的新闻报道用NewsArticle,不属新闻也不属博客的综合文章用Article。
加了结构化数据后,富媒体多久会出现?
通常几天到几周。Google需要重新抓取、索引并处理你的数据,具体取决于站点抓取频率、内容重要性和Google的处理负荷,识别了也不保证一定展示。
普通独立站现在还该不该做FAQ标记?
2023年10月起FAQ富结果只对政府和健康类站显示,普通独立站标了搜索结果里也不出问答框。是否保留要看它对AI抽取和内部用途的价值,别再单纯冲富媒体展示去做。
权威参考资料
本文标题:《结构化数据Schema怎么配合SEO落地?附常见避坑》
本文链接:https://zhangwenbao.com/seo-schema-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0