独立站服务器怎么用cron把运维自动化?备份、sitemap、缓存、SSL、日志一条龙
本文目录
- 独立站为什么必须把运维自动化?手动维护的代价有多大?
- cron到底怎么工作?crontab五个时间字段怎么读不踩坑?
- 自动备份脚本怎么写才靠得住?
- sitemap和缓存怎么定时重生与清理,才不拖累SEO?
- SSL证书怎么自动续期,才不会某天突然过期?
- 服务器日志不轮转会怎样?logrotate怎么配?
- 自动化运维怎么加监控,别让cron任务静默失败?
- 一套独立站自动化运维的crontab长什么样?
- cron自动化运维最容易踩的5个坑是什么?
- 常见问题解答
- 我不是程序员,shell脚本看不懂,也能搞cron自动化运维吗?
- cron任务设好了,怎么知道它到底有没有在跑、有没有跑成功?
- SSL证书不是有自动续期吗,为什么还会有人证书过期全站打不开?
- sitemap用插件自动生成了,还需要专门写cron重生吗?
- 自动备份存在同一台服务器上,算不算做了备份?
- 权威参考资料
摘要:独立站做到后面,真正拖垮人的往往不是流量,是琐碎的服务器运维——备份忘了、证书过期了、磁盘被日志撑满了、sitemap半个月没更新。这些活儿一件都不难,难在天天记着、件件手动做,做着做着必有漏网。保哥这篇讲的就是怎么用Linux自带的cron加上几个几十行的shell脚本,把数据库文件备份、sitemap重生、缓存清理、SSL证书续期、日志轮转、健康巡检这一整套常规运维全部托管给机器,让服务器自己照顾自己。
这不是炫技,是给独立站修地基——服务器稳、响应快、证书不掉链子,本身就是SEO最底层的信号。文末给一份能直接抄的完整crontab。
独立站为什么必须把运维自动化?手动维护的代价有多大?
保哥接触过不少独立站主,技术不差,站也做得有声有色,可一聊到服务器运维,几乎都有过同一种惊魂时刻:某天早上发现网站打不开了,一查是SSL证书过期;或者数据库崩了想恢复,翻遍服务器才发现最近一次备份还停在三周前;又或者站突然变得奇慢,登上去一看磁盘满了,全是没人清理的日志。
这些事故有个共同点——它们都不难防,难的是天天记着去防。备份、续期、清日志、更新sitemap,每一件单独拎出来都是几分钟的小事,但它们是日复一日的常规活儿,靠人脑记、靠手动做,做十次能漏一次,而运维这行,漏一次可能就是一次全站事故。人会忘、会累、会请假、会觉得“今天先不弄了”,机器不会。
把这些常规运维交给机器,本质上是用一次性的脚本投入,换掉长期的心智负担和事故风险。配好之后,服务器自己定时备份、自己续证书、自己清日志、自己更新地图,你只需要偶尔看一眼监控报告确认一切正常。这就是cron自动化运维的全部意义——让服务器学会照顾自己。
对独立站来说,这件事还有一层常被忽略的价值:它直接关系SEO的地基。谷歌的爬虫和排名系统在乎站点的稳定性和响应速度——服务器三天两头宕机、证书过期触发浏览器警告、响应慢得抓取超时,这些都是实打实的负向信号。一个备份齐全、证书常新、日志干净、响应稳定的服务器,本身就是在为SEO攒底层信用。运维自动化不是程序员的炫技,是独立站主给自己生意修地基。
这套方案的工具其实朴素到不能再朴素:一个几乎所有Linux服务器都自带的定时任务工具cron,加上几个你能看懂、能改的shell脚本。不用装重型软件、不用买服务,门槛低到只要你有一台自己的服务器就能上。下面从cron本身讲起。
cron到底怎么工作?crontab五个时间字段怎么读不踩坑?
cron是Linux系统里的定时任务调度器,常驻后台,每分钟检查一次有没有到点该执行的任务。你要做的,就是用一张叫crontab的清单告诉它:什么时间、执行什么命令。理解cron,核心就是看懂crontab每一行的格式。
每条cron任务由前面五个时间字段加后面的命令组成,五个字段从左到右分别是:分钟、小时、日、月、星期。看一个最简单的例子:
# 五个字段:分 时 日 月 星期 要执行的命令
# 每天凌晨 3 点 30 分执行备份脚本
30 3 * * * /opt/ops/backup.sh
# 每 6 小时执行一次(在 0、6、12、18 点的 0 分)
0 */6 * * * /opt/ops/regen-sitemap.sh
# 每周一早上 8 点执行
0 8 * * 1 /opt/ops/weekly-report.sh规则不复杂:星号代表“任意值”,所以 30 3 * * * 是“每月每天每星期的3点30分”,也就是天天凌晨三点半。斜杠表示步长,*/6 在小时位就是“每6小时”。逗号可以列多个值,连字符表示区间。crontab五个字段的取值范围和这些写法,Linux官方手册Linux man-pages — crontab(5)(crontab文件格式与五个时间字段的权威定义)里有最权威的定义,记不住语法时查它准没错,也可以用一些在线的cron表达式工具辅助校验。
语法好懂,但保哥要重点提醒三个真正会让新手栽跟头的坑,它们和语法无关,却让无数人的脚本“手动跑没问题、cron一跑就失败”。第一个坑是环境变量。cron执行任务时用的是一个非常精简的环境,PATH和你登录后的shell完全不同。你在命令行能直接敲的命令(比如某个装在非标准路径的工具),cron里可能找不到。
第二个坑是相对路径。cron任务默认的工作目录不一定是你以为的那个,脚本里凡是涉及文件路径,一律用绝对路径,别用相对路径,别假设当前目录。第三个坑是时区。cron按服务器系统时区执行,很多海外服务器默认是UTC,你以为设的是北京时间凌晨三点,实际跑在了别的时间。配cron前先确认服务器时区,或者干脆在脚本里按需处理时区。这三个坑保哥几乎在每个新手身上都见过,记住它们能省下大量“为什么手动行、自动不行”的抓狂。
自动备份脚本怎么写才靠得住?
所有自动化运维任务里,备份是优先级最高的一个,因为它是你最后的救命稻草。一个靠得住的备份脚本,要管三件事:备什么、备到哪、留多久。先看一个数据库加文件的基础备份脚本长什么样:
#!/bin/bash
set -e # 任一步出错立即中止
DATE=$(date +%F) # 形如 2026-05-30
BAK=/backup
# 1. 导出数据库
mysqldump -uDBUSER -pDBPASS dbname > $BAK/db-$DATE.sql
# 2. 打包上传目录等关键文件
tar czf $BAK/files-$DATE.tar.gz /var/www/html/wp-content/uploads
# 3. 同步到异地对象存储(按你用的云替换命令)
rclone copy $BAK remote:mysite-backup/$DATE
# 4. 清理 14 天前的本地旧备份
find $BAK -name 'db-*.sql' -mtime +14 -delete
find $BAK -name 'files-*.tar.gz' -mtime +14 -delete逐段拆开看。备什么:动态站的命根子是数据库加用户上传的文件,这两样备齐,站就能重建;纯静态资源、能重新生成的东西可以不备。脚本开头的 set -e 很关键,它让任何一步失败就立即停下,避免数据库没导出成功、却继续打包了个空文件还自以为备份成功。
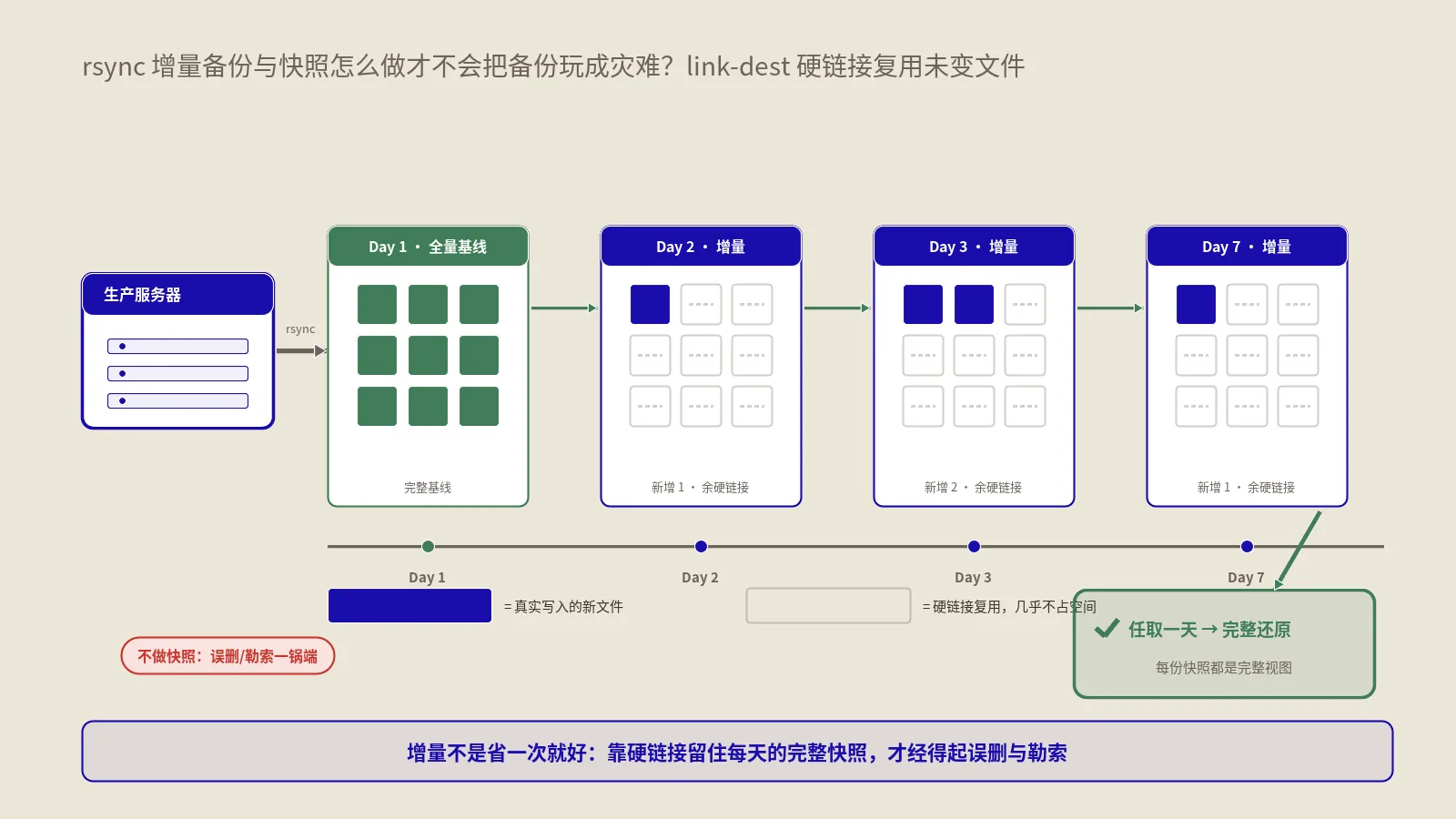
备到哪:这是最容易偷懒、也最致命的一环。备份绝不能只躺在同一台服务器上——硬盘坏了、被勒索加密了、机房出事了,原数据和备份会一起没。脚本第三步的异地同步是底线,把备份推到对象存储、另一台机器或网盘,落实业内的3-2-1原则(至少3份、2种介质、1份异地)。这块的方案怎么选,保哥在WordPress备份方案5维对照那篇里按容灾维度拆得很细。
留多久:备份会越积越多撑爆磁盘,所以要有保留策略。脚本最后用 find 配 -mtime +14 自动删掉14天前的旧备份,天数按你的空间和需求调。讲究一点可以做成“近7天每天留、再往前每周留一份”的阶梯式保留,兼顾恢复粒度和空间。
脚本写好,给它加上执行权限并放进cron即可——这里又会碰到权限问题,备份脚本读数据库、写备份目录、跑系统命令,权限配不对就会静默失败,Linux权限的门道保哥在Linux文件与目录权限完全实战那篇里讲透了。最后必须强调一句:备份脚本跑成功,不等于你能恢复。备份和灾备是两回事,能不能在灾难来时真的把站还原回去,得靠定期演练验证,这点网站备份了就安全?灾备恢复演练才是真底气那篇专门讲过,强烈建议配套读。
sitemap和缓存怎么定时重生与清理,才不拖累SEO?
备份是防灾,接下来这两项——sitemap重生和缓存管理——则是直接关系SEO表现的日常运维,特别适合交给cron。
先说sitemap。它是给搜索引擎的站点地图,告诉爬虫你有哪些页面、哪些更新了。问题在于很多站的sitemap会“僵”:自研站没有自动更新机制;内容靠外部定时同步入库,SEO插件的钩子捕捉不到;或者站做了重度静态化缓存,连sitemap本身都被缓存住,迟迟不刷新。结果就是你以为地图在更新,爬虫拿到的其实是半个月前的旧版。
解法很简单,加一个低频cron兜底重生并主动通知搜索引擎:
# 每天凌晨 4 点重生 sitemap 并 ping 搜索引擎
0 4 * * * /usr/bin/php /var/www/html/regen-sitemap.php && curl -s "https://www.google.com/ping?sitemap=https://yoursite.com/sitemap.xml" > /dev/null成本极低,却能根治“地图过期、抓取打折”的隐患。这一步本质是保证爬虫每次来都拿到最新地图,抓取效率才不浪费。
再说缓存。独立站为了提速大多上了多层缓存——整页缓存、对象缓存、CDN。缓存提速的同时也带来两个运维需求:一是内容更新后要及时清理对应缓存,别让用户和爬虫看到旧内容(旧价格、旧库存、被缓存住的错误页面对SEO都是伤害);二是清理后最好做缓存预热,主动访问一遍核心页面,把缓存重新焐热,避免爬虫撞上冷缓存、首字节响应时间(TTFB)飙高。用cron可以在低峰期定时清理过期缓存、再预热首页和热门分类页:
# 每天凌晨 4 点半清整页缓存并预热核心页面
30 4 * * * /opt/ops/purge-and-warm.sh缓存这层和抓取预算、Core Web Vitals的关系,保哥在TTFB怎么优化才不白费那篇里专门拆过——服务器响应越快,谷歌愿意分给你的抓取额度越高。把缓存的清理和预热自动化,等于让这份SEO红利长期稳定地拿在手里,而不是清一次热闹几天又打回原形。
SSL证书怎么自动续期,才不会某天突然过期?
SSL证书过期是独立站最经典、也最不该发生的事故之一。免费的Let's Encrypt证书有效期只有90天,靠人记着每三个月手动续一次,纯属给自己埋雷。好在用certbot工具可以彻底自动化,关键是要配对,别留下静默翻车的隐患。
certbot安装后大多会自带一个自动续期任务,但保哥经手的证书过期事故依然不少,原因几乎都逃不出三种:续期任务被误删或服务器迁移后没带过来;续期成功了但Web服务器没重新加载、还在用内存里的旧证书;续期时验证失败又没人发现。针对这三种,正确的cron写法是这样:
# 每天两次尝试续期,临近到期才会真正续;续期成功后自动 reload Nginx
0 3,15 * * * certbot renew --quiet --post-hook "systemctl reload nginx"这行命令里有两个要点。一是 certbot renew 很聪明,它只会续真正临近到期的证书,没到期的跳过,所以一天跑两次完全没问题,反而更保险——万一某次续期遇到网络抖动失败了,下一次还有机会补上。二是 --post-hook 至关重要,它在证书真正续期成功后自动重新加载Nginx,解决了“证书续了但服务没加载、旧证书一过期就崩”这个最隐蔽的坑。
certbot官方文档Certbot官方文档 — User Guide(certbot renew自动续期与cron/systemd配置)对certbot renew的行为、cron与systemd timer两种自动化方式、以及hook的用法讲得很清楚,配置时对照着看最稳。
但光配好续期还不够,前面三种事故里有一种是“续期失败但没人知道”。所以证书续期必须配监控——后面讲监控的那节会说怎么给它加失败告警。证书这东西平时悄无声息,一旦掉链子就是全站打不开、浏览器弹安全警告,用户和搜索引擎双双吓跑,绝对值得用三件套(续期任务在跑、续期后reload、失败有告警)严防死守。
服务器日志不轮转会怎样?logrotate怎么配?
日志是个容易被忽视、却能闷声把服务器搞挂的东西。Nginx的访问日志、错误日志,PHP、数据库的日志,都在不停地往磁盘写,一个流量稍大的站,访问日志一天涨几百兆很正常。不管它,迟早有一天磁盘被塞满,磁盘一满,网站直接瘫痪,数据库可能还会损坏。
管住日志靠的是Linux自带的logrotate工具,它专门负责日志的轮转、压缩和清理。配置也很直白,给Nginx日志写一个配置文件:
# /etc/logrotate.d/nginx
/var/log/nginx/*.log {
daily # 每天轮转一次
rotate 30 # 保留最近 30 份
compress # 旧日志压缩,省空间
delaycompress # 延迟一天压缩,方便排查
missingok # 日志缺失不报错
notifempty # 空文件不轮转
sharedscripts
postrotate
systemctl reload nginx # 轮转后让 Nginx 重开日志文件
endscript
}逐项解释:daily 加 rotate 30 是每天切一份、留最近30天,老的自动删,磁盘占用就稳定可控了;compress 把旧日志压缩,能省下大量空间;postrotate 里的reload很关键,日志被轮转改名后,必须让Nginx重新打开新的日志文件,否则它还会往已经被改名的旧文件里写。logrotate的全部指令和高级用法,官方手册Linux man-pages — logrotate(8)(日志轮转、压缩与清理的官方手册)讲得最全。
多数系统的logrotate本身就由一个每天执行的cron任务驱动,你只要把配置文件放对位置就行,不用再单独加cron。
这里保哥要多说一句和SEO相关的妙用:访问日志在被轮转清理之前,其实是一座金矿。它如实记录了谷歌、必应等搜索引擎爬虫每天来抓了哪些页面、抓了多少次、返回了什么状态码。
在logrotate把日志压缩归档前,用cron定时跑个简单的分析脚本,统计一下爬虫的抓取分布,你就能发现:是不是有大量抓取浪费在了无用的参数页上、是不是重要页面爬虫根本没来、是不是冒出了一堆404或500。这种从真实日志里看爬虫行为的视角,比任何第三方工具都准。把日志管好,不只是为了不爆盘,也是为了留住这座观察抓取的金矿。
自动化运维怎么加监控,别让cron任务静默失败?
讲到这儿,必须停下来强调一个最容易被新手跳过、却决定成败的环节:监控。前面配的所有自动化任务,如果没有监控,都只是“看起来在跑”,一旦某天悄悄断了,你根本不会知道,直到事故爆发。
问题的根源在于 cron默认是沉默的。任务跑成功不会通知你,跑失败也通常不报警——cron只会把脚本的输出发到本机的系统邮件,而绝大多数服务器压根没配邮件,于是所有失败信息都被默默吞掉了。你的备份可能已经断了一个月,证书续期可能已经失败了三次,而你毫不知情。
解决思路是给每个关键任务都装上“信号”,主动告诉你它的死活。最实用的有两种模式。第一种是失败即告警:在脚本里检查每条关键命令的退出码,成功就记一行带时间戳的日志,失败就立刻推一条消息出来。比如:
#!/bin/bash
if /opt/ops/backup.sh; then
echo "$(date +'%F %T') backup OK" >> /var/log/ops.log
else
# 失败时推送告警到钉钉/企业微信/Telegram 的 webhook
curl -s -X POST "你的告警webhook地址" -d 'msg=备份失败,请立即检查'
fi第二种是心跳监控,更适合“怕任务根本没跑”的场景:用一个第三方的心跳监控服务,约定你的脚本每次跑完都去它那儿“报到”一次(访问一个特定URL),如果超过预定时间没收到报到,它就主动给你发通知。这样不光能发现“跑了但失败”,还能发现“压根没跑”——比如cron服务本身挂了、服务器关机了这种连脚本都没机会执行的情况。
保哥的建议是两种结合:关键任务(备份、续期)内部做退出码检查加失败告警,同时挂一个心跳监控兜底。再配一个每周的汇总——把一周的运维日志整理成一封简报,让你扫一眼就知道这周备份成功几次、有没有异常。没有监控的自动化是定时炸弹,加了监控的自动化才是真正的省心。这一步千万别省。
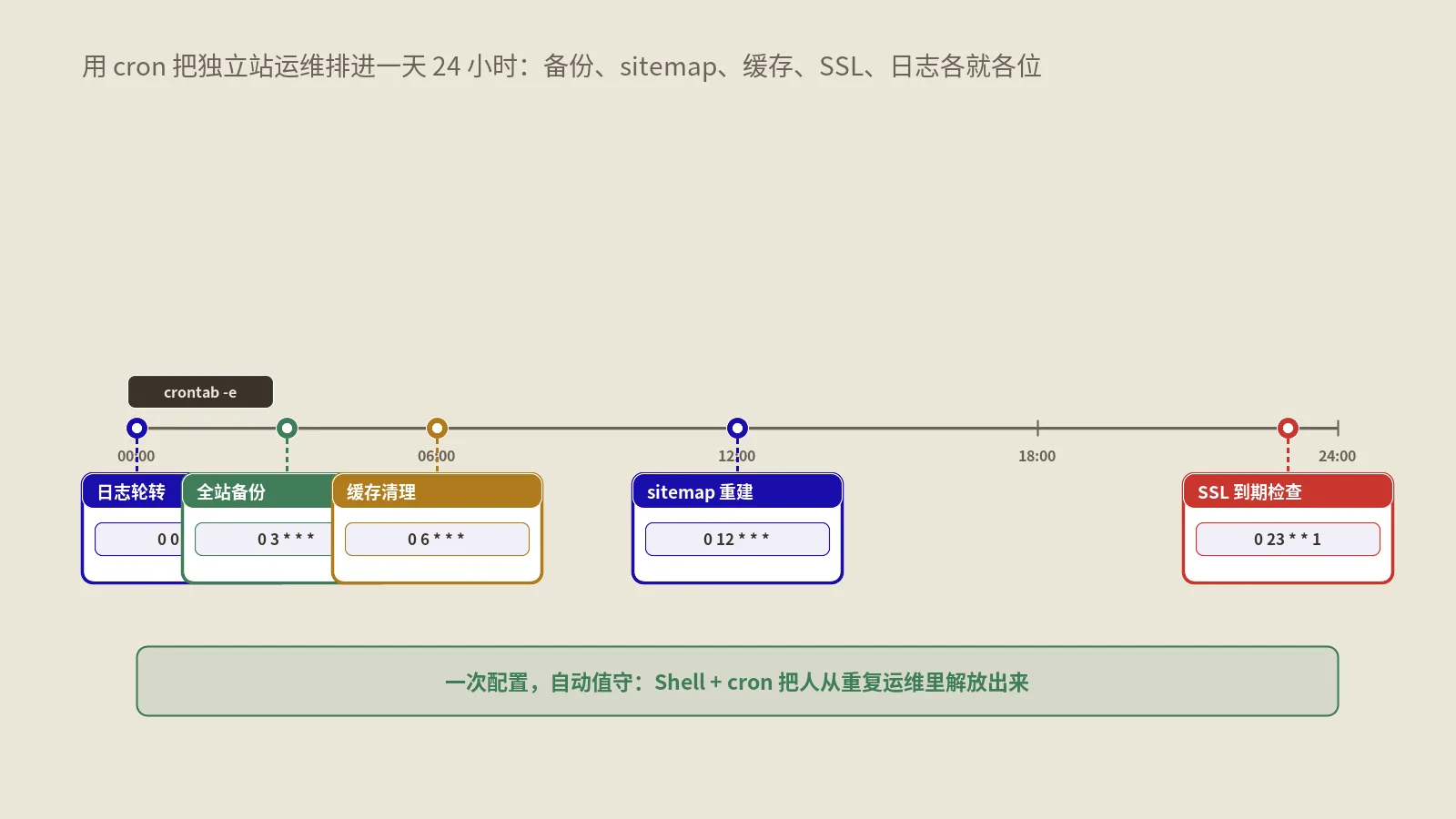
一套独立站自动化运维的crontab长什么样?
把前面所有环节串起来,一份完整的独立站运维crontab大致就是下面这个样子。用 crontab -e 编辑,每行一个任务,时间错开排在低峰期,避免几个重任务在同一分钟一起抢资源:
# ===== 独立站自动化运维 crontab =====
# 每天 3:30 备份数据库与文件、异地同步、清理旧备份
30 3 * * * /opt/ops/backup-and-notify.sh
# 每天 3 点、15 点尝试续期 SSL,续期成功自动 reload
0 3,15 * * * certbot renew --quiet --post-hook "systemctl reload nginx"
# 每天 4 点重生 sitemap 并 ping 搜索引擎
0 4 * * * /opt/ops/regen-sitemap.sh
# 每天 4:30 清整页缓存并预热核心页面
30 4 * * * /opt/ops/purge-and-warm.sh
# 每天 5 点分析前一天访问日志里的爬虫抓取分布
0 5 * * * /opt/ops/analyze-crawl-log.sh
# 每 10 分钟做一次站点健康巡检(首页可达性、磁盘占用)
*/10 * * * * /opt/ops/healthcheck.sh
# 每周一 8 点生成上周运维简报
0 8 * * 1 /opt/ops/weekly-report.sh这套东西的部署顺序保哥建议这样走,循序渐进别一口吃成胖子。第一步,先确认基础环境:核对服务器时区、给脚本统一放在一个目录(比如 /opt/ops)、逐个赋予执行权限、确认脚本里用的命令都是绝对路径。
第二步,从备份开始上,因为它最重要也最该先有。脚本写好后先手动跑一遍,确认备份文件正常生成、异地同步成功,并且真的解压恢复一次验证可用,再加进cron。第三步,依次加上证书续期、sitemap、缓存、日志分析、健康巡检,每加一个都先手动验证再托管,别几个一起上、出了问题分不清是谁的锅。
第四步,也是收口的一步——给所有关键任务接上监控告警,并跑一周观察,确认每个任务都按预期执行、汇总简报正常。这四步走完,你的服务器就真正学会了自己照顾自己,你也从天天提心吊胆的手动运维里彻底解放出来。
cron自动化运维最容易踩的5个坑是什么?
最后照例上一份保哥的踩坑清单,都是真实事故换来的,对照自查能避开绝大多数翻车。
坑一:环境与路径问题,手动能跑cron跑不了。这是头号坑。cron的环境极简,PATH和登录shell不同,工作目录也不确定。脚本里一律用绝对路径调命令、引文件,必要时在脚本开头显式声明PATH。别想当然地以为“我命令行能跑,cron就能跑”。
坑二:没有任何监控,任务静默失败。cron默认沉默,失败不报警。备份断了、续期失败了你都不知道,等发现已是事故。任何关键任务必须配退出码检查加失败告警,再加心跳监控兜底。没监控的自动化等于没做。
坑三:备份只存本机,没有异地。备份和原数据同生共死,服务器一出事两者一起没。备份脚本必须有异地同步那一步,落实3-2-1原则。而且要记得,备份能生成不等于能恢复,得定期演练。
坑四:证书续期没配reload,续了等于没续。certbot把新证书签下来了,Web服务器还在用旧的,到期照样崩。续期命令一定要带post-hook自动reload服务,并给续期任务加失败告警。
坑五:忽略日志,磁盘被悄悄塞满。日志不轮转,迟早撑爆磁盘导致全站瘫痪、数据库损坏。用logrotate管住所有日志的轮转、压缩、清理,顺便还能从访问日志里挖爬虫抓取的情报。这五个坑避开了,你这套自动化运维就稳了——它会在你睡觉、出差、忙别的事的时候,默默替你把服务器这块地基守得严严实实。
常见问题解答
我不是程序员,shell脚本看不懂,也能搞cron自动化运维吗?
能,而且这正是cron自动化对独立站主最友好的地方——你不需要会编程,只需要会抄、会改几个变量。保哥这篇给的脚本都是几十行、逻辑直白的,无非是“导出数据库、打包文件、删掉太旧的备份”这种一步步的命令清单,看不懂语法不要紧,看得懂每行注释在干嘛就够了。真正要你动手的,只是把脚本里的数据库名、密码、路径换成你自己服务器的,再把crontab里的时间调成你想要的。哪怕完全不懂Linux,照着把脚本放到对应目录、给上执行权限、填进crontab,这套自动化就能跑起来。当然,第一次配建议在测试环境或低峰期试一遍,确认备份能正常生成、能正常恢复,再正式托管。怕的不是不懂代码,是没验证就上线。
cron任务设好了,怎么知道它到底有没有在跑、有没有跑成功?
这是新手最容易忽略、也最坑的一点——cron默认是“沉默”的,任务跑成功不会通知你,跑失败也常常不报警,它只会把输出发到系统邮件,而大多数服务器根本没配邮件,于是失败就被彻底吞掉了。保哥的铁律是:任何上了cron的关键任务,都必须自带成功或失败的信号。最简单的做法是每个脚本结尾检查上一条命令的退出码,成功就往一个日志文件追加一行带时间戳的“OK”,失败就触发告警——可以是发一条webhook到你的钉钉、企业微信、Telegram,或者调一个第三方的“心跳监控”服务,约定脚本必须定时来报到,超时没报到就给你发通知。这样你不用天天登服务器查,备份断了、续期失败了,第一时间就知道。没有监控的自动化,是定时炸弹,不是省心。
SSL证书不是有自动续期吗,为什么还会有人证书过期全站打不开?
certbot装好后确实大多默认配了自动续期,但保哥经手的事故里,证书过期翻车的依然不少,原因通常有三个。一是续期任务本身被人误删或服务器迁移后没带过来,续期命令压根没在跑。二是续期成功了,但Web服务器没重新加载——certbot把新证书签下来了,Nginx还在用内存里的旧证书,等旧的一过期就崩,所以续期命令一定要配post-hook自动reload服务。三是续期时遇到验证失败(比如80端口被占、防火墙挡了验证请求、DNS变了),但因为没监控,失败被静默吞掉,直到证书真过期才暴露。所以正确姿势是三件套:确认续期任务在跑、续期后自动reload、给续期任务加失败告警。三件缺一,就还是有翻车的可能。
sitemap用插件自动生成了,还需要专门写cron重生吗?
看你的站和插件。如果你用的是WordPress加成熟的SEO插件,多数情况下新发或更新内容时插件会自动更新sitemap,确实不一定要额外的cron。但有几种情况自己定时重生更稳妥:一是你用的是自研站或轻量CMS,没有靠谱的自动机制;二是你的内容来自外部数据同步、定时入库,插件的钩子捕捉不到这种变化;三是你做了静态化或重度缓存,sitemap本身也被缓存住了,需要定时强制重生加清缓存。保哥的经验是,与其纠结插件到底有没有及时更新,不如加一个低频的cron(比如每几小时或每天一次)兜底重生并ping搜索引擎,成本极低,却能避免“以为在更新、其实早就僵了”的尴尬。sitemap是给爬虫的地图,地图过期,抓取效率就打折。
自动备份存在同一台服务器上,算不算做了备份?
算备份,但不算安全,这是保哥反复强调的一条底线。备份和原数据放在同一台机器上,最大的风险一起扛——服务器硬盘坏了、被勒索病毒加密了、机房出事了、或者你手滑把整个目录删了,原数据和备份会一起没。所以自动备份脚本一定要有“异地”这一步:把打包好的备份同步到另一个地方,可以是对象存储(各家云的OSS、S3、B2)、另一台服务器、甚至自动上传到网盘。再讲究一点就是业内常说的3-2-1原则——至少3份副本、2种不同介质、1份异地离线。光在本机cron出一堆备份文件,给你的是一种虚假的安心。备份的意义在于灾难真来时能恢复,而灾难往往就是冲着那台服务器去的。备份和灾备是两件事,备份了不等于能恢复,这一点很多人是出事才想明白的。
权威参考资料
本文标题:《独立站服务器怎么用cron把运维自动化?备份、sitemap、缓存、SSL、日志一条龙》
本文链接:https://zhangwenbao.com/linux-cron-shell-independent-site-automation-ops-backup-sitemap-ssl.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0