Linux服务器突然变慢、负载飙高怎么排查?CPU、内存、磁盘IO与进程定位实战
本文目录
- 服务器突然变慢、负载飙高,第一步该做什么而不是急着重启?
- load average到底是什么?多少才算高?
- 瓶颈到底在CPU、内存、磁盘还是网络?怎么快速分诊?
- CPU被谁吃光了?怎么定位到具体进程?
- 内存不够用、出现OOM,怎么排查?
- 磁盘IO成了瓶颈,怎么看出来?
- CPU、内存、磁盘都不满,为什么网站还是慢?
- 怎么从一次具体的慢请求,反查到性能根因?
- 排查时手边该常备哪些命令和日志?
- 排查之后,怎么建立日常监控、不再被动救火?
- Linux服务器性能排查的落地顺序,和最容易踩的5个坑是什么?
- 常见问题解答
- 服务器一卡,能不能直接重启了事?
- load average显示8,到底算不算高?
- 怎么快速判断瓶颈到底在CPU、内存还是磁盘?
- 出现OOM(内存被打爆、进程被杀)怎么排查?
- CPU、内存、磁盘看着都不满,网站却很慢,问题可能在哪?
- 排查完一次故障,怎么做才能下次不再被动救火?
- 权威参考资料
摘要:服务器突然变慢、负载飙高,最坏的第一反应就是立刻重启——重启往往把现场和线索一起清空,问题下次照样复发。
正确的姿势是先做分诊:负载到底高在哪,是CPU被算力密集型进程吃满、内存不够触发了OOM和频繁换页、磁盘IO排队,还是看着资源都没满却卡在网络和连接上。保哥这篇把Linux服务器性能排查整理成一条可复用的诊断链:从读懂load average,到用一套固定工具快速分诊四大瓶颈,再到从一次慢请求反查根因、最后建立日常监控不再被动救火,一段段拆开讲,并给一份手边常备的命令清单和最容易踩的坑。
服务器突然变慢、负载飙高,第一步该做什么而不是急着重启?
保哥见过太多人,服务器一卡、负载一高,第一反应就是连上去reboot。业务是暂时恢复了,可问题的现场——是哪个进程在吃资源、内存涨到了多少、有没有触发OOM、磁盘队列排了多长——全被重启清空了。结果就是同样的故障过几天又来一次,你还是两眼一抹黑。
重启是恢复手段,不是排查手段,这两件事千万别混为一谈。除非业务已经彻底瘫痪、必须立刻拉起来,否则上来就重启,等于把破案的所有线索先烧掉。
正确的第一步是抓现场。哪怕情况很急,也尽量先花一两分钟跑几个命令、把关键画面记下来:用top看当前负载和最吃资源的进程、用free看内存和swap、看一眼系统日志末尾有没有OOM或硬件报错。这几屏信息留下来,等重启恢复业务之后还能回头分析根因。
抓现场不需要你当场就分析明白,先存证、后分析。保哥的做法很土但有效:开一个文本文件,把top、free、dmesg末尾几屏直接粘进去存下来,时间戳标好。等业务恢复、人不慌了,再对着这份快照慢慢拆。慌乱中边查边救,最容易把唯一的线索手滑弄没。
有了现场快照,接下来就是这篇文章要讲的事:怎么从负载这个笼统的高,一步步分诊到底是CPU、内存、磁盘还是网络出了问题,再针对性地定位到具体进程、具体根因。保哥把这套排查整理成一条可复用的诊断链,跟着走就不至于慌乱乱试。需要说明的是,本文讲的是操作系统层的通用排查方法,具体到Web服务器、数据库、应用各自的调优是另一层话题,文中会在相应位置给出衔接。
load average到底是什么?多少才算高?
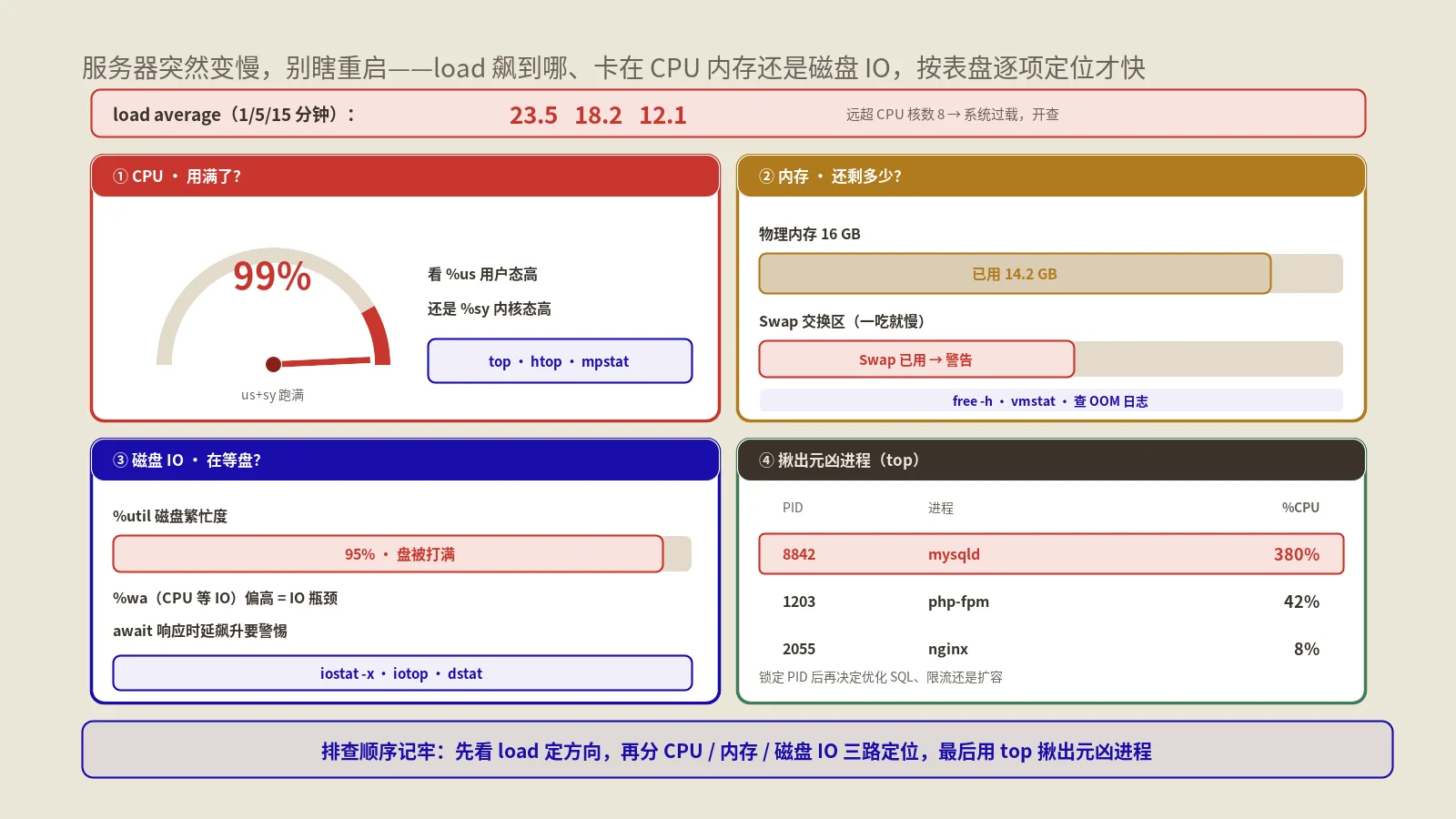
排查高负载,得先搞懂负载这个数到底在说什么。你在top或uptime里看到的load average三个数,分别是过去1分钟、5分钟、15分钟的平均负载。
它大致反映的是处于运行中、或在不可中断等待状态的任务数量的平均值。注意这个不可中断等待——它通常是进程在等磁盘IO,这意味着Linux的load不只反映CPU忙不忙,磁盘拖后腿也会把load顶上去。这一点是很多人误判的根源:看到load高就以为是CPU不够,其实可能是磁盘在排队。
那多少算高?关键是和CPU逻辑核数比着看,光看绝对数字没意义。一个粗略的参照:
| load相对核数 | 含义 |
|---|---|
| 明显低于核数 | CPU有余量,通常不是CPU瓶颈 |
| 接近核数 | CPU基本跑满,开始吃紧 |
| 持续远超核数 | 大量任务排队,系统过载 |
所以同样是load等于8,对一台16核机器是轻松,对一台2核机器就是严重过载。怎么知道自己几核?看 /proc/cpuinfo或用nproc一看便知,这是排查前就该心里有数的基础数字。
还有个常见误会,是把load和CPU使用率画等号。两者相关但不是一回事:CPU使用率说的是当下这一刻CPU忙到几成,load说的是一段时间里有多少任务在抢着用或在等着用。可能出现CPU使用率不到满、load却很高的情况——任务大量卡在磁盘等待上,CPU没活干但任务排成了长队。所以看负载要load和CPU使用率两个一起看,单看一个都容易得出片面结论。
再看三个数的趋势:1分钟远高于15分钟,说明负载正在飙升、可能是突发事件;1分钟低于15分钟,说明高峰在回落。先用load判断大盘紧不紧、是不是在恶化,再往下分诊到底是哪类资源的问题。怎么看load和进程,用top这个最基础的工具就够,它的完整用法在官方手册里写得很清楚Linux man-pages — top(1)(进程与负载实时监控手册)。
瓶颈到底在CPU、内存、磁盘还是网络?怎么快速分诊?
load高只是告诉你系统忙,不告诉你忙在哪。接下来要做的是分诊——用一套固定的工具组合,几分钟把瓶颈缩小到某一类资源上,再针对性深挖。一上来就乱翻日志、瞎调参数,是排查效率最低的做法。
保哥用的分诊框架,背后是一个很实用的方法论:对每一类资源,都看它的利用率、饱和度和错误三个维度。利用率是它有多忙,饱和度是有多少请求在排队等它,错误是有没有报错。哪类资源利用率满了、又有排队、或者在报错,瓶颈就锁定在哪。这套思路由性能专家Brendan Gregg总结为USE方法,是系统排查里非常顺手的一把尺子Brendan Gregg — The USE Method(利用率 / 饱和度 / 错误三指标排查法)。
落到命令上,保哥的固定扫描顺序是这样:
top # 看 load、CPU 各项占比、最吃资源的进程
vmstat 1 5 # 看 CPU、内存、换页、IO 的整体节奏
free -h # 看内存与 swap 用量
iostat -x 1 # 看各磁盘利用率与 IO 队列(wa 高时重点看)
ss -s # 看连接数与状态汇总(资源不满却慢时看)其中top里的CPU那几项要会读:us是用户态占用(你的应用在算)、sy是内核态、wa是在等IO(这项高就该转向磁盘)、id是空闲。vmstat能一屏看到CPU、内存、换页、IO的整体节奏,是分诊的利器,它的字段含义官方手册有完整解释Linux man-pages — vmstat(8)(虚拟内存与系统活动统计手册)。下面几节就按CPU、内存、磁盘、网络这四个方向,分别讲深挖的方法。
CPU被谁吃光了?怎么定位到具体进程?
如果分诊指向CPU——top里id很低、us或sy很高、load接近或超过核数——下一步就是揪出到底是谁在吃CPU。
最直接的是在top里按CPU占用排序(默认就是),看排在最前面的进程是什么。这一步往往就能看出端倪:是某个应用进程在跑、是数据库在扛大查询、是某个批处理任务在算、还是有不该出现的进程(比如被植入的挖矿程序)在偷算力。挖矿木马是近年很常见的一种,特征是某个你不认识的进程长期占着接近满的CPU、夜里也不停,发现这种要立刻按安全事件处理。
区分us高和sy高也有意义。us(用户态)高通常是你的应用本身在做大量计算——可能是代码效率问题、可能是某类请求特别耗算力、也可能就是流量大到该扩容了。sy(内核态)高则更多和系统调用、上下文切换、中断有关,比如进程数过多导致频繁切换、或大量小IO触发频繁系统调用。
定位单进程内部还能再细一层。如果某个多线程进程吃满CPU,可以在top里打开线程视图,看是哪个线程在跑;对应用进程,再结合应用自身的日志和性能剖析,往往能定位到具体是哪段逻辑、哪个定时任务、哪类请求在烧CPU。排查的方向始终是从粗到细:先到进程,再到线程或请求类型,最后到代码,一层层逼近,而不是停在某个进程占用高就完事。
定位到具体进程后,还要往里看一层:如果是Web应用吃CPU,到底是哪类请求、哪个接口在耗算力,这就接到应用层排查了。对跑在Apache、PHP-FPM上的站点,工作进程怎么配、并发怎么扛,本身就直接影响CPU表现,Apache性能调优与高并发那篇专门讲了MPM选型、PHP-FPM解耦、worker数怎么按内存算,CPU在应用层吃紧时值得对照着调。如果是数据库或电商应用本身慢,Magento 2性能调优那篇里索引、缓存、慢查询的思路也能借鉴到别的应用上。
内存不够用、出现OOM,怎么排查?
内存问题的典型症状是:free看到可用内存很少、swap在被频繁使用、系统响应变迟钝,严重时进程被莫名其妙杀掉。后者很可能就是OOM。
OOM(Out Of Memory)是内存严重不足时,内核为了不让整台机器崩溃,主动选一些进程杀掉来释放内存。排查它分三步走。
第一步,确认是否真的发生了OOM。查看系统日志(dmesg或 /var/log下的系统日志),找有没有Out of memory、Killed process之类的记录。OOM的日志会写明哪个进程被杀、被杀时的内存状况,这是最直接的证据。
第二步,定位是谁吃光了内存。常见三种:一是某个进程内存泄漏,用量越涨越高停不下来;二是进程数失控——PHP-FPM的子进程、数据库连接、某些worker开得太多,每个吃一块内存,乘起来就撑爆了;三是内存本来就配小了,扛不住正常业务量。用top按内存排序、看进程数和单进程内存,能区分是单点泄漏还是数量失控。
第三步,对症处理。内存泄漏要从应用层查、临时靠重启缓解、根治靠修代码;进程数失控要把各类进程池的上限按可用内存算清楚——别让它无限制地开,这和Web服务器worker数要按内存反推是同一个道理;内存确实不够,就加内存、或把吃内存的服务拆到别的机器。
还有个常被忽略的细节是swap。swap能在内存不足时兜底、避免直接OOM,但一旦系统开始频繁换页(大量数据在内存和磁盘间来回搬),性能会断崖式下跌,表现就是系统卡得要命但还没崩。所以swap是安全垫不是解决方案,看到swap被大量、持续使用,说明内存已经真的不够了,该加内存或减负载,而不是靠swap硬扛。预防上给关键服务设合理的内存上限、给系统留足余量、配上内存告警,比等OOM杀了进程再救火主动得多。
磁盘IO成了瓶颈,怎么看出来?
磁盘IO是最容易被忽略、却又经常是真凶的瓶颈,因为它会伪装成CPU问题——前面说过,等IO的进程会把load顶高。识别它的关键信号是top或vmstat里的 wa(iowait)偏高:CPU大量时间在干等磁盘返回数据。
确认方向后,用iostat -x看每块磁盘的细节。重点看几个指标:利用率(这块盘有多大比例的时间在忙,接近100% 说明盘快到极限)、平均队列长度(有多少IO请求在排队,队列长说明饱和)、读写吞吐和每次IO的等待时间。哪块盘利用率满、队列长、等待久,瓶颈就在它。
找到忙的盘后,再看是谁在压它。常见来源:数据库的大量读写、日志疯狂输出(尤其是debug级日志忘了关)、备份或批处理任务在高峰期跑、缓存失效导致大量请求穿透到磁盘。处理思路对应着来:数据库IO高就优化查询和索引、加内存让更多数据缓存在内存里;日志IO高就降日志级别、做日志轮转;备份任务挪到低峰期;缓存层兜住读压力。
另一个容易和IO慢混淆的是磁盘空间满。盘写满了,应用写不进日志、写不进临时文件、数据库无法写入,表现可能是各种诡异报错而不是单纯的慢。所以排查时顺手用df看一眼磁盘使用率、用df -i看一眼inode是否耗尽(小文件太多会先把inode用光),这两个一秒钟的检查能省掉很多绕路。
磁盘问题里还有一类是慢盘或盘有坏块。机械盘老化、云盘的IO配额被限速、或者底层存储异常,都会让IO等待时间异常拉长,而利用率看着却不一定满。这种时候除了iostat,还可以看系统日志里有没有磁盘相关的报错(dmesg里的IO error、超时之类),把硬件层的异常和单纯的负载过高区分开——一个要换盘或扩配额,一个要减压或优化,处理方向完全不同。
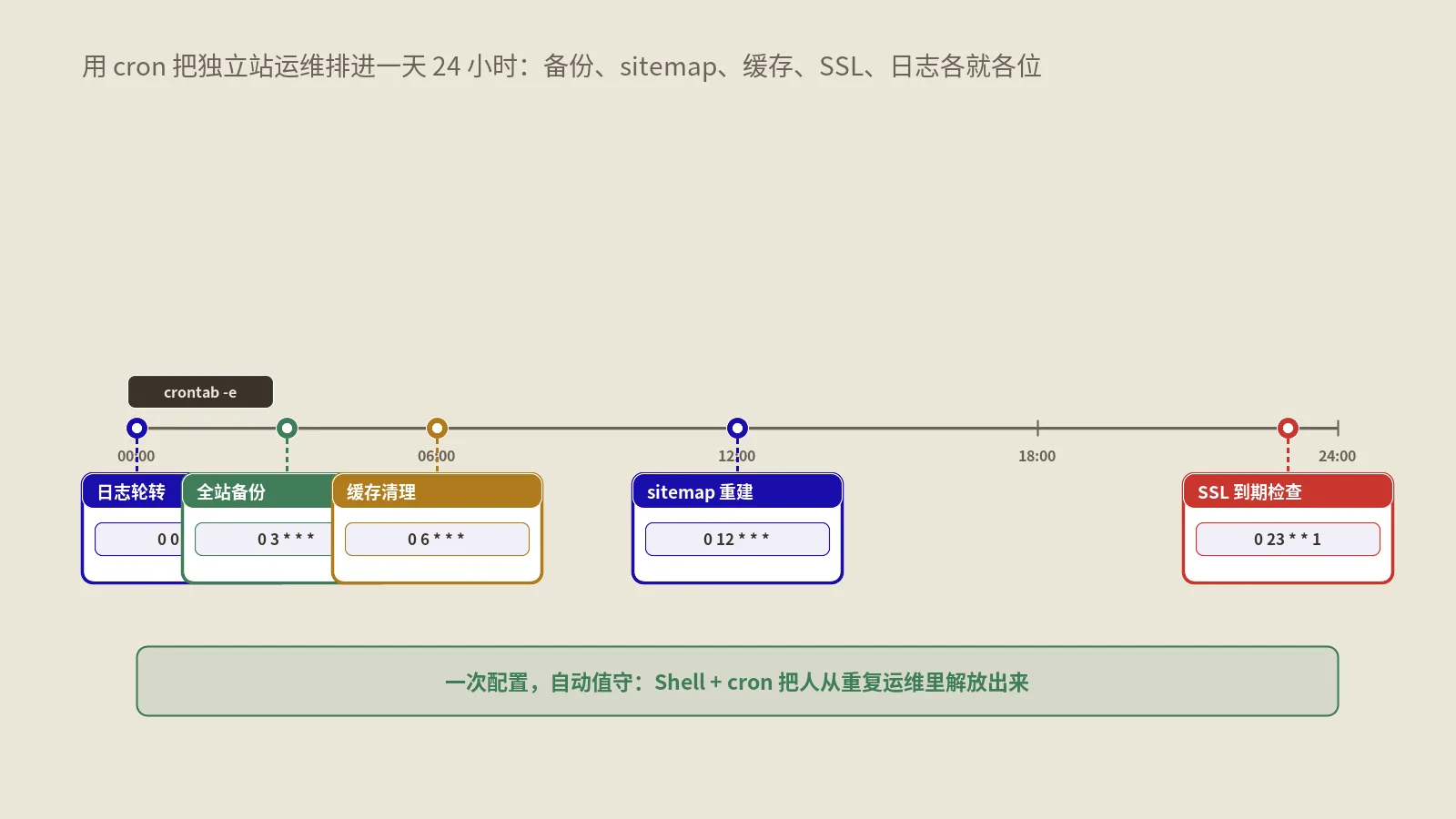
有些重IO的运维动作其实可以错峰自动化——比如备份、日志清理、缓存预热放到夜间定时跑,避开业务高峰。怎么用cron把这些运维任务排好班,用cron把独立站运维自动化那篇讲得很细,把重IO的活挪开高峰,本身就是给磁盘减压。
CPU、内存、磁盘都不满,为什么网站还是慢?
最让人头疼的是这种:监控面板上CPU、内存、磁盘看着都很从容,网站却实实在在地慢。这说明瓶颈不在本机的硬件资源上,得顺着请求的路径往外找。保哥通常按这几个方向排查。
方向一,网络层。出口带宽被占满、跨境线路抖动丢包、DNS解析慢——这些都会让用户感觉慢,但服务器本身的CPU、内存并不忙。这种就要从网络链路去查,而不是死盯本机资源。海外用户访问慢尤其常见,从DNS到线路到CDN的逐层排障,海外打不开、加载慢的网络层诊断那篇有完整的方法,资源不忙却慢、又涉及跨境访问时,直接对照它查。
方向二,连接与并发瓶颈。Web服务器或PHP-FPM的工作进程数到顶了,新请求只能排队等空闲worker,于是表现为慢,但CPU没跑满——这是典型的慢而不忙。解法是去调进程池和并发上限,让worker数和你的硬件、流量匹配。
方向三,下游依赖慢。应用本身在等别人:数据库慢查询、外部API超时、缓存失效后大量请求穿透到后端。应用线程都在等待,自身CPU当然不高。这要去查数据库慢日志、查外部调用耗时、查缓存命中率。
方向四,锁与等待。数据库行锁、表锁、文件锁导致请求互相阻塞排队。表现也是慢而资源不满。排查的总原则就一句:本机资源不饱和,就顺着请求往外一段段看——网络、连接队列、下游依赖、锁,逐个排除。
判断慢在本机还是慢在外部,有个快又准的土办法:直接在服务器本机上请求一下应用(绕开公网和CDN),如果本机请求很快、公网访问却慢,那慢在网络或前置链路;如果本机请求自己就慢,那慢在应用或下游依赖。一次本机对比公网的请求,往往一秒钟就把问题切成了网络侧和应用侧两半,省掉大量瞎猜。
怎么从一次具体的慢请求,反查到性能根因?
前面是从系统现象往下查,还有一条更精准的路子:从一次具体的慢请求往回查。当你能复现某个慢的页面、慢的接口时,顺着它的处理链路逐段计时,往往能直接戳中根因。
思路是把一次请求拆成几段,看时间花在哪:网络传输(用户到服务器这一段,可借浏览器开发者工具或服务端访问日志里的响应时间字段)、Web服务器到应用(请求有没有在排队等worker)、应用处理(代码本身跑了多久)、应用到数据库和外部依赖(查询、API调用各花了多少)。哪一段时间占比最大,根因就在那一段。
实操里几个好用的抓手:服务器访问日志通常可以配置记录每个请求的处理耗时,把慢请求筛出来按耗时排序,能快速锁定是哪些URL慢;数据库的慢查询日志能抓出超过阈值的查询;应用层的性能剖析工具能看到代码里具体哪个函数、哪次调用最耗时。
反查时要特别留意偶发性的慢:有些请求平时很快、偶尔卡一下,这种最难抓,因为复现不稳定。对付它的办法是把访问日志的耗时记录留长一点、定期捞慢请求样本,积累一段时间后看这些偶发慢是不是集中在某个时间点(比如整点的定时任务)、某类参数、或某个下游依赖抖动的时候。偶发慢往往不是代码恒定的问题,而是某个周期性事件或外部波动在背后捣乱,靠样本累积比靠一次复现更靠谱。
这条从慢请求反查的路,和从系统指标分诊的路是互补的:系统指标告诉你哪类资源饱和了,慢请求反查告诉你具体哪段逻辑慢了。两边对上,根因基本就跑不掉。保哥的习惯是先用系统分诊定大方向,再用慢请求反查钉死具体环节,比单用一种快得多。
排查时手边该常备哪些命令和日志?
排查这件事,临场翻手册是来不及的。保哥的建议是把常用的几样工具和日志位置记成肌肉记忆,关键时刻直接上手。下面这张清单按用途分了类,可以贴在手边。
| 用途 | 常用命令 |
|---|---|
| 负载与进程 | top、htop、uptime、ps |
| 内存与换页 | free -h、vmstat |
| 磁盘IO与空间 | iostat -x、df -h、df -i |
| 网络与连接 | ss、ping、mtr |
| 日志与事件 | dmesg、journalctl、tail访问日志 |
日志这块要心里有数几个常看的位置:内核与硬件事件看dmesg;系统服务日志用journalctl(或 /var/log下的系统日志),OOM、服务崩溃重启都在这里;Web服务器的访问日志和错误日志是定位慢请求和报错的主战场;数据库慢查询日志是揪慢查询的关键。
这些命令大多是只读的、安全的,平时没事多跑跑、熟悉自己服务器正常时各项指标长什么样,比临到出事才第一次看要强得多——你得先知道正常是什么样,才认得出异常。保哥强烈建议给自己的服务器建立一份基线印象:正常负载多少、内存用多少、磁盘IO平时什么水平,有了基线,异常一眼就能看出来。
排查之后,怎么建立日常监控、不再被动救火?
救完这次火,更重要的是别再被动等下一次。把这次排查沉淀成两样东西:监控和预案。
监控,是把这次你手动看的那些指标,变成持续采集加阈值告警。至少覆盖这几项:CPU使用率、内存与swap、磁盘空间和IO、load、关键服务的进程数与存活、网站响应时间。指标越线时主动通知你,而不是等用户投诉才发现——很多被动救火,本质上就是缺了这个提前量。磁盘被写满、内存缓慢泄漏这类问题,有告警就能在爆炸前处理。
预案,是把这次排查的过程记下来:症状是什么、怎么一步步定位的、根因是什么、最终怎么解决的。形成一份排查手册,下次遇到类似症状照着走,不用从零摸索。团队里有人能照手册操作,也不至于只有一个人会救火。
再进一步,把高频的巡检和维护动作脚本化、定时化:定时检查磁盘使用率并在超标时告警、定时轮转和清理日志、定时巡检关键服务是否存活。用自动化把人从重复的体力巡检里解放出来,把精力留给真正需要判断的事。监控负责发现、手册负责指导、自动化负责预防,这三样配齐,运维才能从天天救火转成从容值守。
Linux服务器性能排查的落地顺序,和最容易踩的5个坑是什么?
把前面的方法收成一条可执行的主线,遇到服务器变慢就按这个顺序走。
顺序上,先抓现场、再分诊、后深挖、最后沉淀。第一步别急着重启,先top、free、看日志抓现场快照;第二步用top、vmstat、free、iostat、ss这套组合分诊,按利用率、饱和度、错误三维度把瓶颈缩到CPU、内存、磁盘、网络某一类;第三步针对那一类深挖,定位到具体进程、具体盘、具体依赖;第四步若本机资源不满,顺着请求往外查网络、连接、下游、锁,或从慢请求反查;第五步把结果沉淀成监控告警、排查手册和自动化巡检。
再说5个最容易踩的坑:
坑一:一卡就重启,清空现场。问题根因永远查不到、永远复发。重启是恢复手段不是排查手段,先抓现场再说。
坑二:看到load高就当成CPU不够。Linux的load把磁盘IO等待也算进去,load高可能是磁盘在拖后腿,必须分诊别误判。
坑三:脱离核数谈load高低。load 8对16核轻松、对2核过载,不结合核数的数字毫无意义。
坑四:资源没满就以为没问题。慢而不忙往往出在网络、连接队列、下游依赖、锁上,得顺着请求往外查。
坑五:救完火不沉淀。没监控、没手册、没自动化,同样的故障换个时间再来一遍,永远在被动救火。
把这条顺序和这5个坑当成一份排查自查表,贴在手边。Linux的性能排查工具其实就那几样,真正拉开差距的,不是你知道多少命令,而是有没有一套先分诊、再深挖、最后沉淀的章法。有章法,再急的故障也能一步步逼到根因;没章法,工具再多也只是瞎试。
常见问题解答
服务器一卡,能不能直接重启了事?
除非业务已经完全瘫痪、必须立刻恢复,否则别上来就重启。重启的代价是把现场清空——是哪个进程在吃资源、内存涨到哪了、有没有OOM、磁盘队列多长,这些线索重启后全没了,下次同样的问题还会复发,你还是不知道根因。正确的顺序是:先花一两分钟抓现场。哪怕业务很急,也尽量先跑一遍top(看负载和吃资源的进程)、free(看内存)、dmesg末尾(看有没有OOM或硬件报错),把这几屏记下来,再决定要不要重启。有了现场快照,重启恢复业务之后还能回头分析,下次才有机会根治。保哥的原则是:重启是恢复手段,不是排查手段。
load average显示8,到底算不算高?
光看数字8没法判断,必须结合CPU核数。load average大致反映处于运行或不可中断等待状态的任务数,它要和你的逻辑核数比着看。简单的参照:load持续接近核数,说明CPU基本跑满、比较吃紧;load远超核数(比如4核机器load长期在20以上),说明大量任务在排队、系统过载;load明显低于核数,CPU这块还有余量。所以同样是load 8,对16核机器是轻松,对2核机器就是严重过载。还要看1分钟、5分钟、15分钟三个数的趋势判断是在飙升还是回落。另外注意:Linux的load把不可中断状态(常见于磁盘IO等待)也算进去,所以load高不一定是CPU忙,也可能是磁盘在拖后腿。
怎么快速判断瓶颈到底在CPU、内存还是磁盘?
用一套固定的工具组合扫一遍,几分钟就能定位大方向。保哥的习惯顺序是:先top或htop,看load、看CPU各项占比(us用户态、sy内核态、wa等待IO、id空闲)、看排前面的进程吃多少CPU和内存;如果wa(iowait)很高,重点转向磁盘,用iostat -x看哪块盘利用率和队列高;如果内存吃紧、swap在用,用free和vmstat看换页;如果CPU、内存、磁盘看着都不满却还是慢,把注意力转到网络和连接,用ss看连接数。这套组合背后是一个方法论——对每类资源都看利用率、饱和度、错误三个维度,哪类资源饱和了、报错了,瓶颈就在哪。先分诊定大方向,再针对那一类深挖。
出现OOM(内存被打爆、进程被杀)怎么排查?
OOM是内存严重不足时内核为自保强行杀掉某些进程。排查分三步。第一步确认确实发生了OOM:看dmesg或系统日志里有没有Out of memory和Killed process的记录,它会告诉你哪个进程被杀、当时内存什么情况。第二步定位是谁吃光了内存:是某个应用进程内存泄漏越涨越多,还是进程数失控(PHP-FPM或数据库连接开太多、每个吃一块内存乘起来撑爆),还是本来内存就配小了扛不住正常负载。第三步对症处理:内存泄漏从应用层查、可能要重启或修代码;进程数失控要把进程池上限按内存算清楚;内存确实不够就加内存或拆服务。预防上给关键服务设合理内存上限、留足系统余量、配监控告警,比等OOM杀进程再救火主动得多。
CPU、内存、磁盘看着都不满,网站却很慢,问题可能在哪?
这是最让人挠头的一类,因为资源监控看着正常。常见方向有四个:一是网络层——出口带宽占满、跨境线路抖动丢包、DNS解析慢,用户端慢但服务器资源不忙;二是连接与并发瓶颈——Web服务器或PHP-FPM的工作进程数到顶,新请求排队等空闲worker,CPU却没跑满;三是下游依赖慢——数据库慢查询、外部API超时、缓存失效后请求穿透到后端,应用在等别人;四是锁与等待——数据库行锁、文件锁导致请求互相等。排查思路是:既然本机资源不饱和,就顺着请求的路径往外看,逐段排除是卡在网络、连接队列还是下游依赖。
排查完一次故障,怎么做才能下次不再被动救火?
把这次排查沉淀成两样东西:监控和预案。监控方面,至少把CPU、内存、磁盘空间和IO、负载、关键服务进程数、网站响应时间这几项做成持续采集加告警——在指标越过阈值时主动通知你,而不是等用户投诉才发现。很多被动救火,本质是缺了提前量。预案方面,把这次排查的步骤、定位到的根因、最终的解决动作记下来,形成一份排查手册,下次类似症状照着走。再进一步,把高频检查动作脚本化、定时跑,比如定时检查磁盘使用率、定时清理日志、定时巡检关键服务。监控发现问题、手册指导排查、自动化预防复发,三件事配齐才能从天天救火转成从容运维。
权威参考资料
本文标题:《Linux服务器突然变慢、负载飙高怎么排查?CPU、内存、磁盘IO与进程定位实战》
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0