Linux网络命名空间怎么用才能给进程隔出独立网络?ip netns、veth与容器网络底层实战

本文目录
- 网络命名空间到底是什么?为什么容器能各有一套网络?
- 怎么用ip netns创建和管理一个网络命名空间?
- 命名空间之间没有网线,veth虚拟网卡怎么把它们连起来?
- 命名空间里的程序怎么才能访问外网?
- 命名空间一多,怎么用虚拟网桥把它们统一连起来?
- 怎么把一个真实进程或物理网卡放进命名空间?
- 网络命名空间和Docker、Kubernetes是什么关系?
- 用netns做网络排查和隔离,有哪些实战姿势?
- 用网络命名空间最容易踩哪些坑?
- 常见问题解答
- 网络命名空间和虚拟机的网络隔离有什么区别?哪个更省资源?
- 我在命名空间里ping不通外网,但ping网关通,问题出在哪?
- ip netns add建的命名空间,重启服务器后还在吗?
- 一个命名空间里能不能监听和宿主机相同的端口,会冲突吗?
- 普通业务运维,有必要专门去手动玩网络命名空间吗?
- 权威参考资料
摘要:很多人是先用上了Docker,才隐约知道有“网络命名空间”这么个东西:每个容器都像有自己独立的一台机器,有自己的网卡、自己的IP、自己的路由表,互不打架。可一旦容器网络出了毛病——容器之间不通、容器连不上外网、端口映射不生效——光在宿主机上敲ip addr、ping,往往看不出名堂,因为你看的根本不是容器那一套网络。
真正的底层主角,就是Linux网络命名空间(network namespace)。它是内核提供的一种隔离机制,能把网络设备、IP地址、路由表、防火墙规则整套切成相互独立的一份份,每个命名空间里就像一台拥有独立网络栈的小机器。Docker、Kubernetes、各种容器和虚拟网络方案,底层都是拿它在搭积木。
保哥这篇不讲容器,专门把网络命名空间这块地基讲透:它到底隔离了什么、怎么用ip netns亲手建一个、命名空间之间没有网线该怎么用veth虚拟网卡连起来、里面的程序怎么访问外网、它和Docker/K8s是什么关系,以及用它做网络排查隔离的实战姿势和最容易踩的坑。看懂了它,容器网络在你眼里就不再是黑盒。
先说个保哥碰到的真实场景。一台出海业务的Linux服务器上跑着好几个Docker容器,某天客户反馈其中一个容器死活连不上外部API,但同一台宿主机上直接curl那个API又通得好好的。运维上去一通ping、看ip addr、查iptables,宿主机这边一切正常,折腾半天没头绪。问题其实出在容器自己的那套网络栈里——它有独立的路由表和DNS配置,而你在宿主机敲的所有命令,看的都是宿主机的网络命名空间,跟容器那一套完全是两个世界。
这件事的关键,是得先明白“一台Linux主机上可以同时存在多套互相隔离的网络栈”,而每一套就是一个网络命名空间。理解了这一层,排查思路立刻就清楚了:要进到容器自己的网络命名空间里去看它的网卡、路由、DNS,而不是在宿主机外面瞎猜。保哥在 Linux网络配置和排查那篇里讲的ip、ss、ping这些命令本身没问题,问题在于你得先确认自己站在哪个命名空间里敲。
网络命名空间到底是什么?为什么容器能各有一套网络?
网络命名空间是Linux内核提供的一种命名空间(namespace)隔离机制里专门针对“网络”的那一种。普通情况下,一台主机上所有进程共用同一套网络——同一批网卡、同一张路由表、同一套防火墙规则。网络命名空间做的事,就是把这一整套网络资源复制、隔离出独立的一份,让不同进程组各自拥有互不干扰的网络环境。
按 Linux man-pages的network_namespaces(7) 手册,一个网络命名空间隔离的东西相当全:网络设备(网卡)、IPv4和IPv6协议栈、IP路由表、防火墙规则、/proc/net和 /sys/class/net目录、各种 /proc/sys/net下的内核参数、端口号(也就是socket占用)等等。换句话说,每个网络命名空间都拥有一套完整且独立的网络栈,连“80端口被谁占了”这种事,在不同命名空间里答案都可以不一样。
这就解释了容器为什么能各有一套网络:每启动一个容器,容器运行时就为它创建一个独立的网络命名空间,容器里的进程看到的网卡、IP、路由全是这个命名空间私有的。两个容器哪怕都监听8080端口也不冲突,因为它们的8080分属两套互不相干的网络栈。打个比方,一栋楼里本来大家共用一部电话总机,网络命名空间相当于给每户单独装了一条专线,各打各的、号码互不影响。
还有一条手册里写明的重要规则:一块物理网卡在同一时刻只能存在于一个网络命名空间里。当某个命名空间销毁时,它里面的物理网卡会被退还回最初的(默认)命名空间,而不会凭空消失。这条规则在做网络隔离方案时很关键——你不能让一块真网卡同时服务两个命名空间,要连通它们得靠后面讲的虚拟网卡。
怎么用ip netns创建和管理一个网络命名空间?
玩网络命名空间最趁手的命令行工具,是iproute2套件里的ip netns子命令。它把内核那套命名空间操作封装成了几条好记的命令,不用写C代码就能建、删、查、进入命名空间。先建两个命名空间试试:
# 创建两个网络命名空间 ns1 和 ns2
sudo ip netns add ns1
sudo ip netns add ns2
# 列出当前所有命名的网络命名空间
ip netns list按 ip-netns(8) 官方手册,ip netns add用来新建一个命名的网络命名空间,ip netns list(或ip netns)列出所有已命名的命名空间,ip netns delete删除,ip netns exec在指定命名空间里执行命令,还有identify、pids、monitor等子命令分别用于查进程归属、监控变化。命名的网络命名空间在系统里以 /var/run/netns/ 下的对象形式存在,本质是个挂载点,只要那个文件描述符还被持有,命名空间就一直存活。
刚建好的命名空间是个“与世隔绝”的状态——里面只有一块默认的回环网卡lo,而且默认还是DOWN的。你可以用ip netns exec钻进去看一眼:
# 进入 ns1 命名空间执行命令,看看它的网卡
sudo ip netns exec ns1 ip addr
# 此时 ns1 里通常只有一个 lo(回环),而且是 DOWN 状态
# 连 ping 自己的回环地址都不通,得先把 lo 拉起来
sudo ip netns exec ns1 ip link set lo up
sudo ip netns exec ns1 ping -c 2 127.0.0.1ip netns exec NAME command这个组合是日常操作命名空间的核心姿势:它让那些本身并不感知命名空间的普通程序,在指定命名空间的网络环境里运行——手册里写得很清楚,它会把该命名空间专属的网络配置文件挂到 /etc下的惯常位置,所以你在里面跑ip、ping、curl、甚至一个完整的服务进程,看到的全是这个命名空间的网络视图。每次都敲ip netns exec ns1有点长,实战里常把它包成shell函数或别名省事。
命名空间之间没有网线,veth虚拟网卡怎么把它们连起来?
建好命名空间后第一个现实问题是:它们彼此隔离,也连不上外面,等于一座座孤岛。物理网卡又只能待在一个命名空间里,没法拿来连通。这时候就要请出veth——虚拟以太网设备(virtual ethernet)。
按 veth(4) 官方手册,veth设备总是成对创建,且这一对是互联的:从其中一端发进去的数据包,会立刻从另一端冒出来。它的典型用途正是充当网络命名空间之间的隧道,或者把某个命名空间桥接到物理网络上。你完全可以把一对veth想象成一根虚拟网线,两个插头分别插在两个命名空间上,一头进、另一头马上出。
# 创建一对 veth,两端分别叫 veth-a 和 veth-b
sudo ip link add veth-a type veth peer name veth-b
# 把两端分别塞进 ns1 和 ns2
sudo ip link set veth-a netns ns1
sudo ip link set veth-b netns ns2
# 进各自命名空间给两端配 IP、拉起网卡
sudo ip netns exec ns1 ip addr add 10.0.0.1/24 dev veth-a
sudo ip netns exec ns1 ip link set veth-a up
sudo ip netns exec ns2 ip addr add 10.0.0.2/24 dev veth-b
sudo ip netns exec ns2 ip link set veth-b up这套动作做完,ns1和ns2就被一根虚拟网线连起来了。在ns1里ping ns2的地址应该就通了:sudo ip netns exec ns1 ping -c 2 10.0.0.2。如果不通,先别急着怀疑命令写错,多半是两端的veth网卡没拉up,或者IP不在同一网段——这跟物理世界里两台机器直连一根网线、要配同网段IP才通是一个道理。
注意veth一定要成对理解:删掉其中一端,另一端会跟着消失,因为它们本就是一根线的两头。当命名空间数量多起来、要互相连通时,一对对veth直连会变成乱麻,这时通常会引入一个虚拟网桥(bridge)当“交换机”,每个命名空间用一对veth接到网桥上,靠网桥转发——这正是Docker默认网络docker0网桥的基本思路。
命名空间里的程序怎么才能访问外网?
上一步只是让两个命名空间内部互通了,它们还是上不了外网。一个命名空间要访问外部网络,得满足两件事:一是有一条通往外面的路(默认网关),二是出去的流量能被做地址转换(NAT)变成宿主机的真实地址出网,回程再转回来。
常见做法是建一对veth,一端留在宿主机的默认命名空间、一端放进目标命名空间,给两端配上同网段地址,再在命名空间里设默认网关指向宿主机那一端:
# veth0 留宿主机,veth1 进 ns1
sudo ip link add veth0 type veth peer name veth1
sudo ip link set veth1 netns ns1
# 宿主机端配地址并拉起
sudo ip addr add 192.168.100.1/24 dev veth0
sudo ip link set veth0 up
# 命名空间端配地址、拉起、设默认网关
sudo ip netns exec ns1 ip addr add 192.168.100.2/24 dev veth1
sudo ip netns exec ns1 ip link set veth1 up
sudo ip netns exec ns1 ip route add default via 192.168.100.1光有路还不够,命名空间发出的源地址是192.168.100.2这种私有地址,外网不认识、回不来。所以还要在宿主机上打开IP转发,并配一条NAT(SNAT/MASQUERADE)规则,把从这个网段出去的流量伪装成宿主机的对外地址。
开启转发是sysctl -w net.ipv4.ip_forward=1,NAT规则则用iptables或nftables给192.168.100.0/24这个源网段加MASQUERADE。这一整套“veth连通 + 默认网关 + IP转发 + NAT”,本质上就是容器能上外网背后的原理。
这里有个排查上的提醒:命名空间里ping不通外网时,要分层看是哪一环断的。先在命名空间里ip route看有没有默认网关,再ping一下宿主机那端的veth地址确认本地这段通不通,然后看宿主机ip_forward开没开、NAT规则有没有命中。每个命名空间还有自己独立的DNS配置(resolv.conf),域名ping不通但IP通,那就是DNS没配好,跟外网链路无关。这套分层定位的思路,和排查普通服务器网络是相通的。
命名空间一多,怎么用虚拟网桥把它们统一连起来?
两个命名空间拿一对veth直连还好办,可一旦命名空间有三个、五个、十个,要让它们彼此都能互通,再用一对对veth两两直连就是个噩梦:连通N个节点要拉N×(N-1)/2根线,地址和路由也乱成一锅粥。物理世界里解决“多台机器互通”靠的是交换机,虚拟世界里对应的就是Linux虚拟网桥(bridge)。
思路是建一个虚拟网桥当“软件交换机”,每个命名空间用一对veth接上去:veth的一端进命名空间当它的网卡,另一端留在宿主机挂到网桥上。所有命名空间都接到同一个网桥后,它们之间的流量由网桥负责转发,互通就成了,添新命名空间也只是再接一对veth上桥,不用动别人。
# 建一个虚拟网桥 br0 并拉起
sudo ip link add br0 type bridge
sudo ip link set br0 up
# 给 ns1 建 veth,一端进 ns1,另一端挂上 br0
sudo ip link add veth1 type veth peer name br-veth1
sudo ip link set veth1 netns ns1
sudo ip link set br-veth1 master br0 # 挂到网桥
sudo ip link set br-veth1 up
sudo ip netns exec ns1 ip addr add 10.0.0.11/24 dev veth1
sudo ip netns exec ns1 ip link set veth1 up
# ns2、ns3…如法炮制,都接到 br0,同网段即互通这套“网桥 + 每个命名空间一对veth”的结构,正是Docker默认网络模式的真身:Docker起手就建了个叫docker0的网桥,每个容器接一对veth上去,容器间靠docker0转发、出外网再走宿主机NAT。你把这套手动搭一遍,docker0那张网络拓扑图在脑子里就立起来了,以后看docker network的输出不再是天书。给网桥本身配个IP再当网关,命名空间们还能顺着它统一出外网,比一个个单独配网关清爽得多。
怎么把一个真实进程或物理网卡放进命名空间?
前面都是用ip netns exec临时在命名空间里跑命令,但实战里常需要让一个长期运行的服务进程整个待在某个命名空间里,或者把一块真网卡划给它专用。这两件事都做得到。
让进程进命名空间,最直接的就是用ip netns exec NAME把服务的启动命令包起来,这样它fork出来的子进程都继承这个网络命名空间。更现代的方式是用nsenter命令,按目标进程的PID进入它所在的命名空间,比如nsenter --net=/var/run/netns/ns1 bash,常用于钻进一个已经在跑的容器的网络里调试。容器运行时本质上就是先建命名空间、再让容器主进程在里面启动,跟这套手动操作是一个道理。
把物理网卡划进命名空间,用的是ip link set DEV netns NAME。比如服务器上有块专门跑某段业务的网卡eth1,想让它只服务某个命名空间,就sudo ip link set eth1 netns ns1,之后这块网卡在默认命名空间里就“消失”了,只在ns1里可见可用。前面说过,物理网卡同一时刻只能属于一个命名空间,所以这是“独占划拨”。等命名空间销毁,这块物理网卡会自动退还回默认命名空间,不用担心丢卡。
命名空间和进程的生命周期还有个微妙点:一个匿名(没用ip netns命名)的网络命名空间,只要还有进程在用它就存活,最后一个进程退出它就自动销毁;而用ip netns add命名过的,因为在 /var/run/netns下有挂载点占着,哪怕里面没进程也会一直存在,直到你ip netns delete它。理解这点能帮你想明白“为什么容器一停网络就没了”(匿名、随进程销毁)和“为什么手动建的命名空间得手动删”(命名、挂载点占着)。
网络命名空间和Docker、Kubernetes是什么关系?
把网络命名空间搞懂,再看容器网络就豁然开朗了,因为容器网络全是拿它当积木搭的。Docker启动一个容器,默认会为它新建一个独立的网络命名空间,然后建一对veth:一端放进容器的命名空间当容器的eth0,另一端留在宿主机接到docker0这个虚拟网桥上。容器之间通过docker0网桥互相转发,容器出外网则靠宿主机上的NAT规则——是不是和前面手动搭的那一套一模一样?Docker只是把这些步骤自动化、封装好了而已。
容器的资源隔离其实是多种命名空间合力的结果:网络命名空间隔离网络,PID命名空间让容器有自己独立的进程号空间,Mount命名空间隔离文件系统挂载,再配合cgroups限制CPU、内存这些资源用量,才拼出一个完整的“容器”。网络命名空间只负责网络这一摊。保哥在 Linux cgroups资源限制那篇里讲的就是隔离的另一半——命名空间管“看见什么”,cgroups管“能用多少”,两者搭配才是容器的底座。
到了Kubernetes,网络命名空间的角色更精妙。一个Pod里的多个容器之所以能共享同一个IP、彼此用localhost互访,正是因为它们被安排进了同一个网络命名空间——Pod才是网络命名空间的边界,而不是单个容器。各种CNI网络插件(Calico、Flannel等)要解决的核心问题,也就是怎么把成千上万个分布在不同节点上的Pod网络命名空间高效地连通起来。所以说,网络命名空间是理解整个容器网络体系绕不开的地基。
用netns做网络排查和隔离,有哪些实战姿势?
网络命名空间不只是容器的底层原理,运维手里它也是个趁手的实操工具。最高频的一招就是进容器的网络命名空间排障。回到开头那个容器连不上外网的例子,正确动作是钻进容器自己的网络命名空间里,用它那套网络视图去看:
# 找到容器主进程 PID(docker inspect 可查),假设是 12345
# 用 nsenter 进入它的网络命名空间排查
sudo nsenter -t 12345 -n ip addr # 看容器的网卡和 IP
sudo nsenter -t 12345 -n ip route # 看容器的路由表和默认网关
sudo nsenter -t 12345 -n cat /etc/resolv.conf # 看容器的 DNS
sudo nsenter -t 12345 -n curl -I https://api.example.com # 在容器视角实测这么一看,问题往往立刻现形:要么容器路由表里没默认网关、要么DNS指向了不通的地址、要么宿主机的转发或NAT没配好。在容器自己的命名空间里做测试,看到的才是容器进程真正经历的网络,比在宿主机外面隔空猜要靠谱一百倍。
另一类实战是用命名空间做干净的网络隔离和测试沙盒。比如你想测一个程序在特定网络条件(限速、丢包、特定路由)下的表现,又不想动宿主机的真实网络,就可以建一个独立命名空间,在里面用tc加丢包延迟、配好隔离的路由,然后把程序丢进去跑,测完ip netns delete一删,宿主机网络毫发无损。再比如想让某个不放心的程序完全没有网络(连环境都隔绝),建一个只有lo的命名空间把它关进去,它就彻底出不了网,比配一堆防火墙规则干净利落。
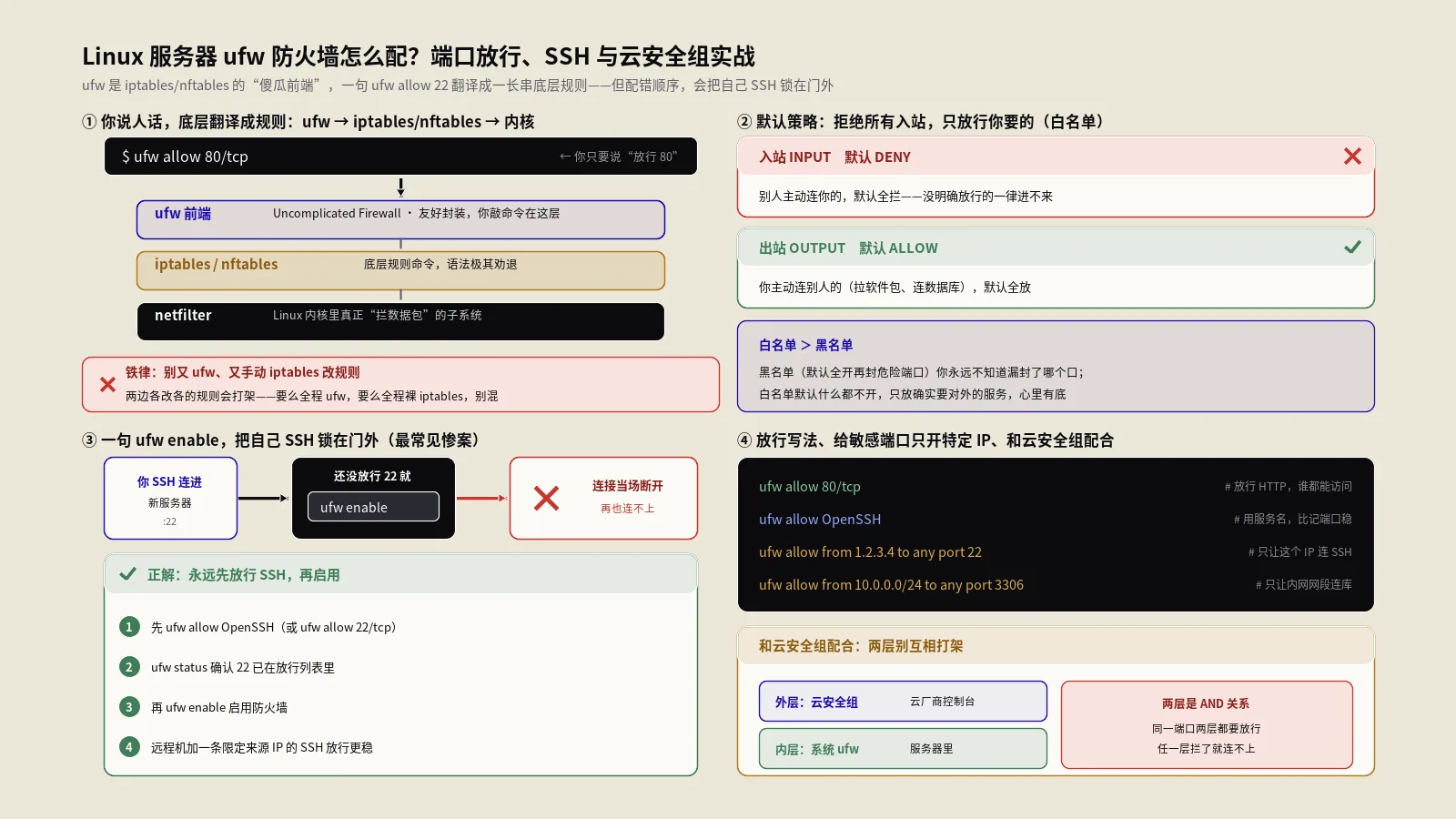
还有个边界要心里有数:命名空间里的防火墙规则也是独立的。每个网络命名空间有自己独立的iptables/nftables规则集,你在宿主机配的放行规则,对命名空间内部不生效,反之亦然。排查“命名空间里端口连不上”时,除了看路由和NAT,也要记得查它自己那套防火墙。保哥在 Linux服务器ufw防火墙那篇里讲的端口放行逻辑没变,只是要落到对应的命名空间里去看去配。
用网络命名空间最容易踩哪些坑?
第一个坑是ip netns exec跑命令时忘了自己在哪个命名空间,看着像没生效。新手常犯的错是在命名空间里配完网络,回头在宿主机敲ip addr发现什么都没有,以为配失败了——其实是配在命名空间里了,得用ip netns exec NAME ip addr才看得到。脑子里要时刻清楚每条命令作用在哪个命名空间,这是用好它的前提。
第二个坑是新建命名空间里的lo默认是DOWN的。很多人建好命名空间、配好veth,结果发现连ping 127.0.0.1都不通,一头雾水。原因就是回环网卡lo默认没拉起来,而不少程序依赖回环正常工作。所以建好命名空间的标准动作之一就是ip netns exec NAME ip link set lo up,把回环先拉起来,别等程序报错才想起这茬。
第三个坑是veth配好了却不通,多半栽在三件事上:两端veth网卡没全部set up、两端IP不在同一网段、或者要上外网时宿主机的ip_forward没开/NAT规则没配。排查顺序固定下来:先确认两端都up,再确认IP同网段先打通内部,最后才是网关、转发、NAT这些上外网的环节,一层层往外推,别一上来就怀疑最复杂的NAT。
第四个坑是命名空间和进程绑定关系没理清,导致命名空间“莫名其妙没了”或者“删不掉还占着”。记住那条线:匿名命名空间随最后一个进程退出而销毁,命名空间里的服务进程一挂、命名空间可能就跟着没了;而ip netns add命名过的会因为挂载点常驻,得手动delete。生产里用命名空间承载长期服务时,要么用命名命名空间 + 守护进程托管保证它不随便消失,要么想清楚生命周期,别让关键服务的网络环境意外蒸发。这跟管进程的思路是相通的,保哥在 Linux进程管理那篇里讲的进程生命周期,套到命名空间这儿同样适用。
常见问题解答
网络命名空间和虚拟机的网络隔离有什么区别?哪个更省资源?
两者隔离的层次完全不同,开销也差着量级。虚拟机是连硬件带操作系统整套虚拟出来,每台虚拟机跑一个完整的内核和独立的网络栈,隔离最彻底,但每台都要吃掉可观的内存和CPU,启动也慢。网络命名空间是在同一个宿主机内核之上,只把网络这一摊资源逻辑切开,所有命名空间共用一个内核,几乎不额外占内存、创建销毁是毫秒级的事。所以容器能在一台机器上轻松跑几十上百个、而虚拟机跑不了那么多,根子就在这儿。代价是隔离强度不如虚拟机——大家共用一个内核,内核级的隔离边界终究不如硬件级硬。实战取舍很清楚:要轻量、高密度、快速起停,用命名空间(容器);要强隔离、跑不同操作系统、安全边界要求高,用虚拟机。很多生产环境其实是两者叠用,虚拟机里再跑容器,兼顾隔离和密度。
我在命名空间里ping不通外网,但ping网关通,问题出在哪?
这个症状很典型,基本能锁定在“出网那一段”而不是命名空间内部。能ping通网关(也就是宿主机那端的veth地址),说明命名空间到宿主机这一跳是通的、veth和路由没问题。ping不通外网,最常见两个原因:一是宿主机没开IP转发,net.ipv4.ip_forward还是0,宿主机不肯帮命名空间转发流量,包到了宿主机就被丢了,用sysctl net.ipv4.ip_forward查一下,是0就开成1;二是没配NAT,命名空间发出去的是192.168.x.x这种私有源地址,外网收到也无法回包,得在宿主机上给这个源网段加一条MASQUERADE的NAT规则,把私有地址伪装成宿主机的对外地址。另外别忘了区分是IP不通还是域名不通——如果ping IP通、ping域名不通,那是命名空间里的DNS(resolv.conf)没配对,跟外网链路无关,单独配DNS即可。
ip netns add建的命名空间,重启服务器后还在吗?
不在了,会全部消失。ip netns add建的命名空间,其实是靠 /var/run/netns下的挂载点维持的,而这个目录在内存文件系统里,重启后就没了,所以手动建的所有命名空间以及里面配的veth、IP、路由统统不会保留。如果你需要命名空间在重启后自动重建,得把整套创建命令(建命名空间、建veth、配地址、设路由、开转发、配NAT)写成一个脚本,再用systemd做成开机自启的服务,或者放进开机启动流程里跑一遍。这也是为什么容器编排平台都把网络配置写成声明式的——靠平台在每次启动时按声明重建,而不是指望它自己持久存在。手动玩命名空间做实验没问题,但要拿它承载生产网络,持久化和自动重建这步绝不能省。
一个命名空间里能不能监听和宿主机相同的端口,会冲突吗?
不会冲突,这恰恰是网络命名空间最实用的能力之一。端口号是属于某个网络命名空间的socket资源,不同命名空间的端口空间互相独立,所以宿主机的默认命名空间监听80端口、ns1里也监听80端口、ns2里又监听80端口,三者各管各的、毫不打架。这就是为什么一台机器上能跑好几个都监听80或8080的容器还互不影响——它们的端口分属不同命名空间。真正会冲突的,是“同一个命名空间内”两个进程抢同一个端口,那才会报“地址已被占用”。理解这点对排查端口问题很有用:当你在宿主机ss -tlnp看不到某个容器明明监听了的端口时,不是端口没起来,而是它在容器自己的命名空间里,得进到那个命名空间里用ss才看得到。
普通业务运维,有必要专门去手动玩网络命名空间吗?
看你干的活。如果你只是部署部署网站、管管常规服务,平时用Docker、宝塔这类工具,确实不需要天天手动ip netns建命名空间——那些工具已经把命名空间的事全自动化了。但理解网络命名空间的原理,对你排查容器网络问题的帮助是实打实的:知道容器有自己独立的网络栈,你才会想到用nsenter钻进容器命名空间去看它真实的网卡、路由、DNS,而不是在宿主机外面瞎转。手动操作ip netns的价值,更多是在学习和调试阶段——亲手建一遍命名空间、连一对veth、配通外网,把容器网络的黑盒拆开看一遍,之后再遇到容器不通的问题,脑子里就有清晰的模型去定位。所以保哥的建议是:不一定要在生产里手动用它,但一定要花点时间亲手搭一遍弄懂原理,这是从“会用容器”到“能修容器网络”的分水岭。
权威参考资料
本文标题:《Linux网络命名空间怎么用才能给进程隔出独立网络?ip netns、veth与容器网络底层实战》
本文链接:https://zhangwenbao.com/linux-network-namespace-netns-veth-virtual-network-isolation.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0