Linux cgroups怎么用才能给进程组套上资源笼子?CPU、内存限制与systemd-run实战
本文目录
- cgroups到底解决什么问题?它和nice、ulimit是一回事吗?
- cgroups v1和v2有什么区别?现在到底该用哪个?
- 怎么用systemd给一个服务限制CPU和内存?
- systemd-run怎么临时给一条命令套上资源笼子?
- cgroup文件系统怎么手动操作?cpu.max、memory.max这些控制器怎么读怎么写?
- 内存超限会怎样?memory.max和memory.high、OOM是什么关系?
- CPU限制是怎么生效的?cpu.max和cpu.weight分别管什么?
- 怎么把多个进程或服务归到一个slice里统一限制?
- cgroups在Docker、Kubernetes里是怎么用的?
- 保哥用cgroups收拾一个吃满内存的导出任务,完整过程是怎样的?
- cgroups最容易翻车的几个地方有哪些?
- 常见问题解答
- cgroups和nice、ulimit到底有什么区别,什么时候该用哪个?
- 我的机器是cgroups v1还是v2,怎么判断?两者必须二选一吗?
- memory.max和memory.high有什么区别,实战中怎么搭配?
- 用systemd-run临时限制一条命令,和写unit文件限制服务有什么不同?
- Docker的 --memory、--cpus和cgroups是什么关系?不用容器也需要懂cgroups吗?
- 权威参考资料
摘要:很多人在一台机器上同时跑网站、数据库、定时导出脚本,平时相安无事,结果某天一个导出任务内存泄漏,几分钟就把整台机器的内存吃光,连带网站、数据库一起被系统的OOM杀手误伤,全站502。事后查日志才发现,罪魁是那个不起眼的脚本,可它把整机都拖下水了。
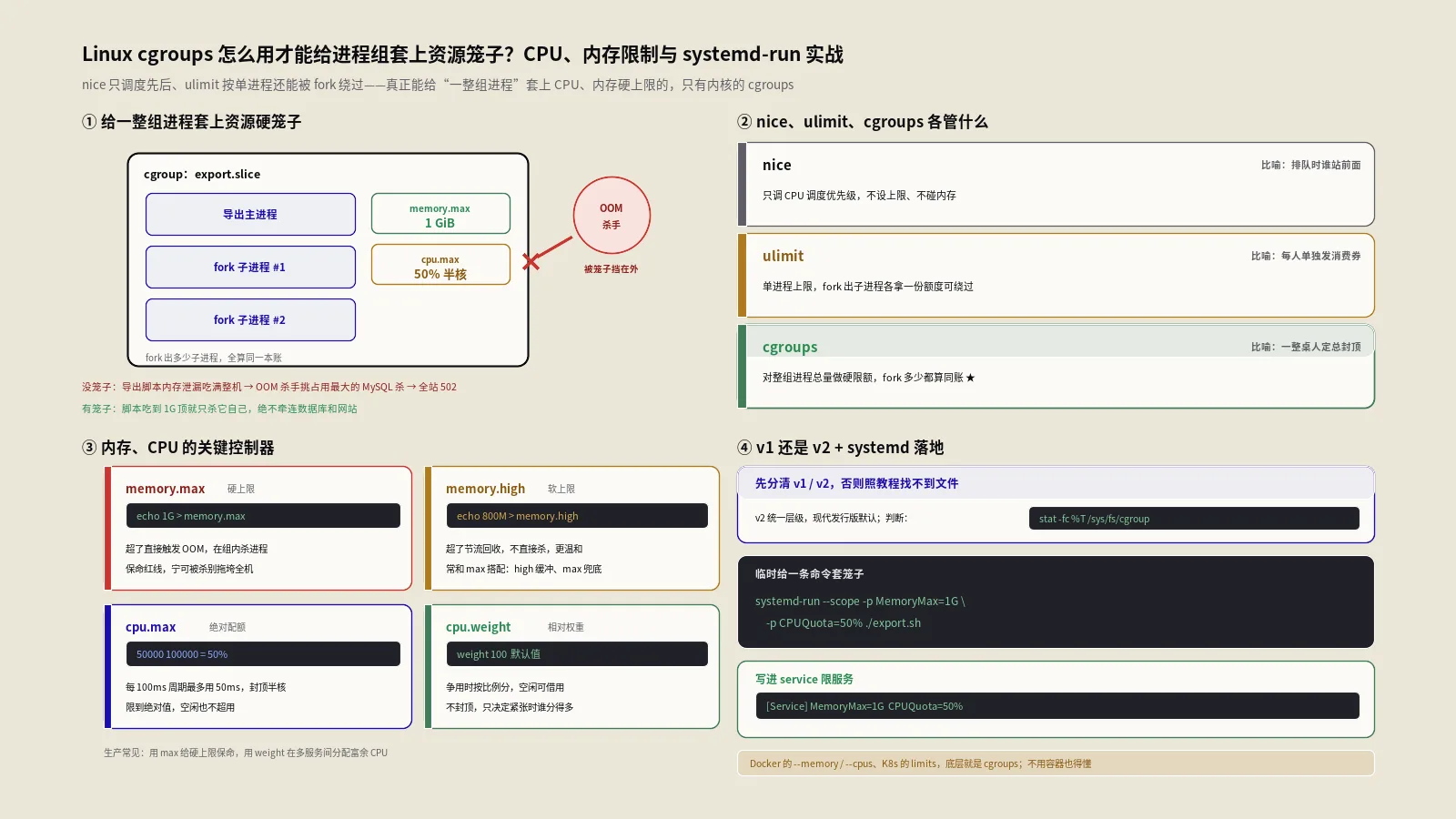
根子在于:默认情况下,一个进程能用多少CPU、多少内存,几乎是不设防的,谁吃得猛谁占得多,没有一道墙把它圈住。很多人以为nice调一下优先级、ulimit设一下就够了,其实都不对——nice只管调度先后,ulimit按单进程算还能被fork绕过,真正能给一组进程套上资源硬笼子的,是内核的cgroups(control groups)。
保哥这篇按真实运维场景把cgroups讲透:它到底解决什么问题、和nice/ulimit的本质区别、v1与v2怎么选、怎么用systemd和systemd-run给服务和临时任务限CPU限内存、memory.max与memory.high的生死之别、cpu.max配额与cpu.weight权重各管什么、怎么用slice把一批进程归一起统一限制,最后给一套实战心法和几个翻车现场。
先说个保哥真排过的故障。客户一台独立站服务器,Nginx、MySQL、PHP-FPM加一个每晚跑的订单导出脚本全挤在一台机器上。平时内存用得稳稳的,可有天凌晨导出脚本碰上一批异常大的订单,边查边在内存里攒数据,内存噌噌往上涨,十几分钟把可用内存吃干。Linux的OOM杀手一看内存告急,开始挑进程杀,偏偏挑中了占内存最大的MySQL,数据库一挂,整站直接瘫了到早上。
这事的根子,是那个导出脚本完全没被任何东西约束着——它想用多少内存就用多少,没有一道墙把它圈在一个额度里。运维第一反应是给脚本nice一下降低优先级,但nice管的是CPU调度的先后顺序,跟内存用量半毛钱关系没有;又想到ulimit,可ulimit是按单个进程算的,脚本只要fork出子进程,每个子进程又是一份新额度,照样能把内存吃穿。
真正该用的,是cgroups:给这个导出任务划一个内存上限,比如1G,它自己吃到顶就只杀它自己,绝不牵连MySQL和网站。保哥在 Linux进程管理那篇里讲透了ps/top/kill和nice这套面向单个进程的招式,那是基本功;这一篇专门讲压在它之上、面向“一组进程”做资源硬约束的cgroups,这是容器、systemd、现代运维资源治理的底层地基。
cgroups到底解决什么问题?它和nice、ulimit是一回事吗?
cgroups的全称是control groups,是Linux内核提供的一套机制,核心就一句话:把若干进程组织成一个个分层的组,然后对“整个组”限制和统计它们能用多少资源——CPU、内存、磁盘IO、进程数都能管。按 Linux man-pages的cgroups(7) 手册的定义,一个cgroup就是“一组被绑定到一套限额或参数上的进程,这些限额通过cgroup文件系统定义”。关键词是“组”和“硬限额”,这正是它和nice、ulimit的分水岭。
nice管的是CPU调度的相对优先级,值从 -20到19,它只决定CPU紧张时谁先被服务、谁让路,但它不设上限——机器空闲时,一个nice值很低的进程照样能吃满CPU,它从不“封顶”,也完全不碰内存。ulimit倒是能设上限,比如限制单进程最大内存、最多打开多少文件,但它有两个致命短板:一是按单个进程算,进程一fork,子进程各自重新拿一份额度,一个脚本拉起十个子进程就等于十倍额度;二是它管不了“一组进程加起来不许超过多少”这种需求。
cgroups恰好补上这两个洞:它是对一整组进程的总量做硬限制,组里不管fork出多少子进程,全部算在这个组的同一本账上,加起来超了就触发限制。打个比方,nice是排队时谁站前面,ulimit是给每个人单独发一张消费券,而cgroups是给一整桌人定一个总消费封顶——这桌人随便点,但总账不许超过这个数。这就是为什么限制“一个服务及其所有子进程”的总资源,只有cgroups干得了,nice和ulimit都使不上劲。
cgroups v1和v2有什么区别?现在到底该用哪个?
cgroups有两个大版本,搞混了会出现“照着教程敲却找不到文件”的怪事,所以先得分清。v1的设计是每个资源控制器(CPU、内存、IO各算一个控制器)各自挂一棵独立的层级树,于是同一个进程在CPU树里属于一个组、在内存树里又可能属于另一个组,层级互相不对齐,管理起来很拧巴,配置也散。
v2把这套推倒重来,改成统一层级(unified hierarchy):所有控制器挂在同一棵树上,一个进程在哪个组就是哪个组,CPU、内存、IO的限制都对着这同一个组生效,清爽得多。现在主流发行版——较新的Ubuntu、Debian、RHEL系——默认都已经切到v2,统一挂在 /sys/fs/cgroup这个目录下,并且由systemd统一接管。所以保哥的建议很直接:新机器、新部署一律按v2来学、来用,别再去碰v1那套割裂的老结构。
怎么确认自己机器跑的是哪个版本?最简单是看 /sys/fs/cgroup目录下的文件:如果直接能看到cgroup.controllers、cgroup.subtree_control这类文件,就是v2的统一层级;如果看到的是cpu、memory、blkio这种一个控制器一个子目录的结构,那还是v1。本文后面讲的cpu.max、memory.max这些接口文件,都是v2的写法,也是当下该掌握的主流。
怎么用systemd给一个服务限制CPU和内存?
虽然cgroups是内核机制,但日常运维里你几乎不需要直接去手搓cgroup文件——因为systemd已经把它包装成了几个一目了然的指令,这才是最该先学的入口。给一个服务限资源,本质就是在它的unit文件 [Service] 段里加几行:
[Service]
# 最多用半个 CPU 核(一个核的 50%)
CPUQuota=50%
# 内存硬上限 512M,超了触发 OOM 只杀这个服务
MemoryMax=512M
# 内存软上限 400M,超了开始节流但不杀
MemoryHigh=400M
# CPU 争用时的相对权重,默认 100
CPUWeight=100按 systemd.resource-control(5) 官方文档,CPUQuota= 接一个百分比,比如CPUQuota=20% 表示这个服务的所有进程加起来最多用一个核的20% CPU时间,它底层映射的就是cgroup v2的cpu.max。
MemoryMax= 是内存硬上限,扛不住就触发OOM杀手,对应memory.max;MemoryHigh= 是节流上限,超了进程被狠狠拖慢做内存回收但不直接杀,对应memory.high。改完unit文件systemctl daemon-reload再restart就生效。
如果不想改unit文件、想给一个正在跑的服务即时调一下,用systemctl set-property:
# 给正在运行的 myapp 服务即时设内存上限
systemctl set-property myapp.service MemoryMax=1G
# 加 --runtime 表示只在本次运行期间生效,重启后失效
systemctl set-property --runtime myapp.service CPUQuota=80%不加 --runtime时,set-property会把这条设置写进一个drop-in配置文件持久保存,重启也还在;加了 --runtime就只是临时调一下。保哥的习惯是:救火现场先用 --runtime临时压住,确认值合适了再写进unit文件固化,这跟改其它系统配置“先临时验证再持久化”的心法一脉相承。关于把自己的程序做成开机自启服务、写unit文件的完整套路,可以配合 Linux systemd服务管理那篇一起看。
systemd-run怎么临时给一条命令套上资源笼子?
上面说的是给“常驻服务”限资源,但很多时候你要限的是一条临时命令——比如手动跑一次数据导出、压缩一个大文件、执行一个心里没底的脚本,担心它把机器吃垮。这种一次性任务不值得专门写个service,systemd-run就是为这个场景准备的,它能临时拉起一个带资源限制的瞬态单元:
# 把一条导出命令圈进资源笼子:内存最多 1G,CPU 最多半核
systemd-run --scope -p MemoryMax=1G -p CPUQuota=50% \
php /data/scripts/export_orders.php
# 限制一次 tar 打包不要把 IO 和 CPU 占满
systemd-run --scope -p CPUQuota=30% tar czf backup.tar.gz /data/www--scope表示在当前shell的上下文里直接跑这条命令(命令结束这个临时单元就消失),-p后面跟的就是和unit文件里一样的那些资源指令。这招的妙处在于:你不用预先规划、不用改任何配置文件,临时起意就能给任意一条命令套上笼子,跑完即清。保哥排查那种“某个批处理偶尔会吃爆内存”的问题时,第一步就是用systemd-run把它圈住跑——这样哪怕它真泄漏,也只会撑爆自己的1G额度被单独OOM掉,整机其它服务毫发无伤,而不是像开头那个故障里一样连累MySQL陪葬。
cgroup文件系统怎么手动操作?cpu.max、memory.max这些控制器怎么读怎么写?
虽然推荐用systemd,但理解底层手动操作能让你真正看懂限制是怎么落地的——systemd那些指令最终都化成了对这些文件的读写。在v2的统一层级里,建一个组就是建一个目录,把进程放进组就是把PID写进它的cgroup.procs文件:
# 在统一层级下建一个自己的组
mkdir /sys/fs/cgroup/mygroup
# 关键一步:先在父级 enable 要用的控制器,子组才能用
echo "+cpu +memory" > /sys/fs/cgroup/cgroup.subtree_control
# 设内存硬上限 200M、CPU 每 100ms 最多用 50ms(半核)
echo 200M > /sys/fs/cgroup/mygroup/memory.max
echo "50000 100000" > /sys/fs/cgroup/mygroup/cpu.max
# 把某个进程丢进这个组
echo 12345 > /sys/fs/cgroup/mygroup/cgroup.procs
# 随时看这个组当前用了多少内存
cat /sys/fs/cgroup/mygroup/memory.current这里有个v2新手最常踩的坑:建好子组后,必须先在它的父级(这里是根的cgroup.subtree_control)里写上 +cpu +memory把控制器“下放”给子组,子组里才会出现cpu.max、memory.max这些文件,否则你会发现目录是建好了,可里头根本没有想要的接口文件。读memory.current、cpu.stat这些文件可以实时看到这个组的资源消耗,统计能力是cgroups除了限制之外的另一半价值。
但要强调:手动echo进cgroup.procs这种操作是临时的、重启即失效的,只适合验证和应急,正经的持久化配置一定要走systemd的unit文件或slice,别指望手动建的目录能扛过重启。
内存超限会怎样?memory.max和memory.high、OOM是什么关系?
内存限制这块最值得讲清楚,因为memory.max和memory.high一字之差,行为却是生死两重天,用错了要么误杀要么失效。按 Linux内核Control Group v2文档的说法,memory.max是硬限:当一个cgroup的内存用量摸到这个上限、且无法再回收下去时,OOM杀手会被唤起,把这个组里的进程杀掉。它是兜底的最后一道墙,撞上去就是“处决”。
memory.high则完全不同,它是节流上限(throttle limit):当用量越过high这条线,组里的进程会被节流、被施加沉重的内存回收压力,逼着系统拼命回收内存把它压回去,但越过high这条线“永远不会触发OOM杀手”。换句话说,high是一道减速带、一个缓冲区,让进程慢下来、把内存吐出来,而不是一刀杀掉。
实战里这两个最好搭配着用:把memory.high设得比memory.max略低,比如high=400M、max=512M。这样进程内存涨到400M就开始被节流、被逼着回收,给了它一个自我修正的缓冲带;只有当它连节流都压不住、一路冲到512M硬顶还下不来,OOM才出手。
这种“先减速、实在不行才处决”的两段式,比只设一个硬max要稳得多——只设硬max的话,进程往往是毫无征兆地一头撞墙被杀,留下损坏的临时文件和半截数据。这也是为什么排查内存问题时,光看进程级别的top不够,得结合组的视角,这和 Linux服务器性能排查里讲的内存、负载诊断是配套的。
CPU限制是怎么生效的?cpu.max和cpu.weight分别管什么?
CPU这边也有两个容易混的概念:cpu.max是配额(绝对封顶),cpu.weight是权重(相对分配),管的是两件事。cpu.max的格式是“配额 周期”两个数,比如“50000 100000”意思是每100000微秒(100毫秒)这个周期里,这个组最多能用50000微秒的CPU时间,算下来就是半个核的能力,它是个绝对天花板,机器再空闲也不许超。systemd的CPUQuota=50% 底层就是写成这个值。
cpu.weight是另一回事,它是相对权重,默认值100,范围1到10000。权重只在CPU真的不够分、多个组在抢的时候才起作用:假设A组权重100、B组权重200,争用时B拿到的CPU大约是A的两倍。但注意,权重不封顶——如果只有A组在跑、没人跟它抢,它照样能吃满所有CPU,权重纯粹是“僧多粥少时按比例分粥”的规则。
这俩怎么选?要给某个任务一个铁打的天花板、不管机器多闲都不许超过,用cpu.max(CPUQuota);要的是“平时随便用,紧张时按重要程度让路”,用cpu.weight(CPUWeight)。保哥的经验是:在线核心服务给高权重保证它紧张时不被饿着,后台批处理给低权重让它平时能跑满但一抢就让路;而对那些容易失控的任务,则直接上cpu.max硬封顶。另外还有个cpuset.cpus,能把一个组死死绑到指定的几颗物理核上,做核隔离,对延迟敏感的服务有用。
怎么把多个进程或服务归到一个slice里统一限制?
前面限的都是单个服务或单条命令,但运维里常有“一类东西加起来不许超过多少”的需求——比如希望所有后台批处理任务加在一起最多用两个核、不许影响在线业务。这种成组治理,systemd用slice来做。slice是systemd里专门表示资源分组层级的一种单元(以 .slice结尾),它本身不跑进程,而是作为一个容器,把归属它的服务们的资源汇总到一起管。
# 定义一个 batch.slice,给这一类任务一个总额度
# /etc/systemd/system/batch.slice
[Slice]
CPUQuota=200%
MemoryMax=2G
# 让某个服务归到这个 slice 下
[Service]
Slice=batch.slice这样一来,所有Slice=batch.slice的服务,它们的CPU总和被压在两个核(200%)、内存总和压在2G以内,不管这底下挂了三个还是三十个服务,加起来都越不过这条总线。
systemd本身就用slice把整个系统分成了system.slice(系统服务)、user.slice(用户会话)等几大块,是层级化的——你完全可以在这个体系下再细分自己的业务slice。这正是slice的价值:从“管单个服务”升级到“管一类服务的总盘子”,按业务把资源切成几个互不挤占的盘子,一个盘子里闹翻天也烫不到别的盘子。这种隔离思路,和按用户、按目录控制磁盘用量的 Linux磁盘配额是同一个精神,只是一个管CPU内存、一个管磁盘空间。
cgroups在Docker、Kubernetes里是怎么用的?
如果你用过Docker,那你其实早就在用cgroups了,只是没意识到。docker run时那个 --memory=512m限制容器内存、--cpus=1.5限制CPU,底层做的事情,就是Docker替你在cgroups里建了个组、把容器进程塞进去、写上memory.max和cpu.max——跟前面手动操作的本质一模一样,只是Docker把它包装得你看不见了。
Kubernetes里Pod的resources.limits.memory、limits.cpu也是同一个底层,最终都落到节点上的cgroups。
所以理解cgroups的回报很大:它不只是个孤立的运维技巧,而是整个容器资源隔离的地基。你搞懂了memory.max触发OOM、cpu.max是硬配额,就能解释为什么容器里的进程会莫名其妙被OOMKilled(容器内存撞了limit)、为什么给容器的CPU limit设太低应用会变得很卡(被cpu.max节流了)。很多人调容器资源全靠玄学试参数,懂了底层的cgroups就能直接对症下药。反过来,就算你不用容器,在裸机上用systemd的资源指令做的,和容器替你做的也是同一件事。
保哥用cgroups收拾一个吃满内存的导出任务,完整过程是怎样的?
回到开头那个被导出脚本拖垮的故障,保哥后来是这么根治的,整个思路可以照搬。第一步先定位:用top和ps确认就是那个PHP导出脚本在凌晨吃内存,峰值能冲到三四个G,而机器总共才8G,难怪OOM会乱杀。第二步不急着改脚本逻辑(那是另一码事),先给它套上笼子止血——把它从crontab直接调用,改成用systemd-run圈起来跑:
# 原来 crontab 里是裸跑:
# 0 3 * * * php /data/scripts/export_orders.php
# 改成套进资源笼子,内存硬顶 1.5G、CPU 半核
0 3 * * * systemd-run --scope -p MemoryMax=1500M -p MemoryHigh=1200M \
-p CPUQuota=50% php /data/scripts/export_orders.php这么一改,效果立竿见影:那晚脚本又碰上大订单往上涨内存,涨到1200M时memory.high开始节流、逼它回收,涨到1500M硬顶时OOM只把这个脚本自己杀了,MySQL、Nginx安然无恙,第二天网站照常开着,只是那一次导出失败了——但这远比整站瘫一晚上强。
第三步才是治本:根据这次暴露的内存峰值,回去把脚本改成分批查询、流式写文件,不再一次性把所有订单堆内存里,改完内存稳定在两三百M。cgroups在这里扮演的是“安全气囊”——它不修复bug,但能在bug发作时把破坏死死圈在一个进程里,给你留出从容定位和修复的时间,而不是半夜被电话叫醒救火。
cgroups最容易翻车的几个地方有哪些?
保哥踩过和见人踩过的坑,挑高频的几个说一下,能帮你避开大半返工。
第一个,v1和v2搞混,照着v2教程在v1机器上找cpu.max,或者反过来,结果文件死活找不到。动手前先确认机器跑的是哪个版本,新系统基本都是v2。第二个,以为设了ulimit就万事大吉,结果进程一fork子进程就把限制绕过去了,要限一组进程的总量必须用cgroups。第三个,MemoryMax设得太抠,比正常峰值还低,结果服务一启动正常跑就被OOM反复杀,限制值一定要给在真实峰值之上留足余量,先观察实际用量再设。
第四个,v2下建了子组却忘了在父级subtree_control里enable控制器,导致子组里压根没有cpu.max、memory.max文件,限制无从设起。第五个,全靠手动echo进cgroup.procs做限制,重启一次全没了,正经持久化必须走systemd的unit或slice。第六个,把CPUQuota=20% 理解成“占总CPU的20%”,其实它是“一个核的20%”,多核机器上这俩差出好几倍,设之前先想清楚单位。把这几个坑记住,cgroups用起来就稳了。
常见问题解答
cgroups和nice、ulimit到底有什么区别,什么时候该用哪个?
三者管的根本不是一件事。nice(和renice)管的是CPU调度的相对优先级,只决定CPU紧张时谁先谁后,不设任何上限、也完全不碰内存,机器空闲时低优先级进程照样能吃满CPU。ulimit能设上限,但它是按单个进程算的,进程一fork子进程,每个子进程重新拿一份额度,一个脚本拉起多个子进程就等于额度翻倍,而且它没法表达“一组进程加起来不许超过多少”。cgroups才是对一整组进程做总量硬限制:组里fork出多少子进程都算在同一本账上,CPU、内存、IO都能限。选择上:只想调谁先跑用nice;想限单个进程打开文件数这类用ulimit;想给“一个服务及其所有子进程”或“一类任务”设资源总封顶,只能用cgroups。日常里cgroups通过systemd的CPUQuota、MemoryMax这些指令来用,不用直接碰底层文件。
我的机器是cgroups v1还是v2,怎么判断?两者必须二选一吗?
最快的判断办法是看 /sys/fs/cgroup目录的结构:如果根目录下直接有cgroup.controllers、cgroup.subtree_control这类文件,就是v2的统一层级;如果看到的是cpu、memory、blkio各占一个子目录的结构,那是v1。也可以用stat -fc %T /sys/fs/cgroup,返回cgroup2fs就是v2、返回tmpfs一般是v1或混合模式。较新的发行版(近几年的Ubuntu、Debian、RHEL系)默认都已经是纯v2。两者确实是系统级二选一的运行模式,不能既是v1又是v2地混着设同一个控制器,发行版会有一个默认模式,能通过内核启动参数切换,但除非有老软件强依赖v1,否则没必要去碰,跟着v2走就对了。本文讲的cpu.max、memory.max、memory.high都是v2的接口。
memory.max和memory.high有什么区别,实战中怎么搭配?
区别是“处决”和“减速”。memory.max是硬上限,组内存撞到它且回收不下来时,内核会唤起OOM杀手把组里的进程杀掉,是最后一道墙。memory.high是节流上限,越过它进程会被狠狠施加内存回收压力、被拖慢,逼着把内存吐出来,但越过high永远不会触发OOM。实战里最稳的是两个搭配用、把high设得比max略低,比如high=1200M、max=1500M:内存涨到1200M就先被节流、被逼回收,给一个缓冲带让它自我修正;只有连节流都压不住、一路冲到1500M硬顶才会被OOM。这比只设一个硬max强很多——只设max的话进程往往毫无征兆地撞墙被杀,留下损坏的临时文件和半截数据。用systemd时对应MemoryHigh= 和MemoryMax= 两个指令,建议两个都设。
用systemd-run临时限制一条命令,和写unit文件限制服务有什么不同?
区别在于“一次性”还是“常驻”。systemd-run --scope -p MemoryMax=1G -p CPUQuota=50% 后面跟一条命令,是临时拉起一个瞬态单元把这条命令圈进资源笼子,命令跑完这个单元就消失,特别适合手动跑导出、压缩大文件、执行心里没底的脚本这类一次性任务,不用预先写任何配置。而写unit文件(在 [Service] 段加CPUQuota、MemoryMax)限制的是常驻服务,配置持久存在、每次服务启动都生效。还有个折中是systemctl set-property,能给正在运行的服务即时调资源,不加 --runtime会写进drop-in文件持久保存、加了 --runtime就只在本次运行期间生效。保哥的习惯:临时任务和救火止血用systemd-run或set-property --runtime,确认参数合适后再写进unit文件固化。
Docker的 --memory、--cpus和cgroups是什么关系?不用容器也需要懂cgroups吗?
Docker的 --memory、--cpus底层就是cgroups,你用Docker时其实一直在间接用cgroups。docker run --memory=512m做的事,就是Docker替你在cgroups里建了个组、把容器进程塞进去、写上memory.max;--cpus=1.5则是写cpu.max。Kubernetes里Pod的resources.limits也是同一个底层,最终都落到节点的cgroups上。所以懂了cgroups,就能解释容器世界里很多“玄学”:进程被OOMKilled是容器内存撞了limit(memory.max),容器CPU limit设太低应用变卡是被cpu.max节流了。至于不用容器要不要懂——非常需要。在裸机或传统虚机上,用systemd的资源指令给服务限资源做的,和容器替你做的是同一件事,开头那个被导出脚本拖垮整机的故障就发生在没有容器的纯物理环境里,正是cgroups(通过systemd-run)把它救了回来。
权威参考资料
本文标题:《Linux cgroups怎么用才能给进程组套上资源笼子?CPU、内存限制与systemd-run实战》
本文链接:https://zhangwenbao.com/linux-cgroups-resource-limits-cpu-memory-control-systemd-run-slice.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0