Linux systemd服务管理:怎么把自己的程序做成开机自启服务?
本文目录
- systemd到底管什么,凭什么是现在Linux的标配?
- 一个service单元文件,该怎么读懂和写对?
- enable和start有什么区别,别再搞混了?
- Type选错,systemd就会误判你的服务死活?
- 怎么把自己的应用做成开机自启的服务?
- 服务崩了能自动拉起来吗,重启策略怎么配?
- 服务为什么一启动就失败?排查从哪下手?
- 用systemd timer取代cron,值不值得?
- 让服务更安全、更省资源,有哪些开箱即用的开关?
- 服务跑起来后,日常怎么盯着它别出事?
- 改单元文件时,哪些坑最容易踩?
- 常见问题解答
- systemctl enable和start到底有什么区别?
- 为什么我的服务在终端能跑,做成systemd服务就启动失败?
- 服务崩溃后怎么让它自动重启,又不会无限重启把机器拖垮?
- 单元文件改了为什么不生效?
- systemd timer能完全替代cron吗?
- 怎么限制一个服务最多用多少内存和CPU?
- 权威参考资料
摘要:在现代Linux上,凡是要常驻后台、要开机自启、崩了要自动拉起来的程序,正确的归宿都是systemd服务,而不是
nohup &加一个脆弱的开机脚本。掌握systemd,核心就三件事:写对单元文件、选对Type、配好重启策略。保哥这些年帮独立站做服务器运维,见过太多人把自研的爬虫、队列、定时任务用
nohup挂在后台,服务器一重启全没了,或者进程崩了无人知晓,直到客户投诉才发现。这篇就把systemd服务管理从头讲透:单元文件三段式怎么读、enable和start的区别、Type选错的后果、怎么把自己的应用做成规范服务、重启策略怎么防风暴、启动失败怎么排查、用timer取代cron值不值、以及安全和资源限制那些开箱即用的开关,最后把改单元文件最容易踩的坑收个尾。
先说清楚为什么要用systemd。一个后台程序,你用nohup ./app &启动,看着是跑起来了,但问题一大堆:服务器重启后它不会自己回来;进程被OOM杀掉或自己崩了,没人重新拉起;日志散落在某个你随手重定向的文件里;想优雅停止还得自己找PID去kill。这些事,systemd全都帮你管了,而且管得比手写脚本规范得多。
systemd是现在绝大多数主流发行版(Ubuntu、Debian、CentOS/RHEL系、Rocky、Alma等)的标准init系统和服务管理器。它是开机后第一个启动的进程,PID永远是1,负责拉起并监管系统里所有其他服务。换句话说,你的服务器从开机到关机,背后那个总调度,就是它。
systemd到底管什么,凭什么是现在Linux的标配?
要理解systemd,先理解它管理的基本单位——单元(Unit)。系统里能被systemd管理的东西,都抽象成各种类型的单元。最常打交道的是这几类:
- .service:服务单元,描述一个后台进程怎么启动、停止、重启。这是运维最常写的。
- .timer:定时器单元,按时间触发某个服务,是cron的现代替代品。
- .socket:套接字单元,实现按需启动(有连接进来才拉起服务)。
- .target:目标单元,一组单元的集合,用来表达系统状态(比如多用户模式、图形模式),相当于过去的运行级别。
- .mount / .path:挂载点和路径监控单元。
这些单元之间还能表达依赖和顺序关系——谁必须在谁之后启动、谁依赖谁。正是这套依赖图,让systemd能并行启动互不依赖的服务,开机速度比老式串行脚本快得多。这也是它取代SysVinit成为标配的核心原因之一:不只是“能跑服务”,而是“能编排服务”。
跟systemd打交道的主命令是systemctl,管日志的是journalctl。这两个命令几乎覆盖了日常运维的全部操作,后面会反复用到。
一个service单元文件,该怎么读懂和写对?
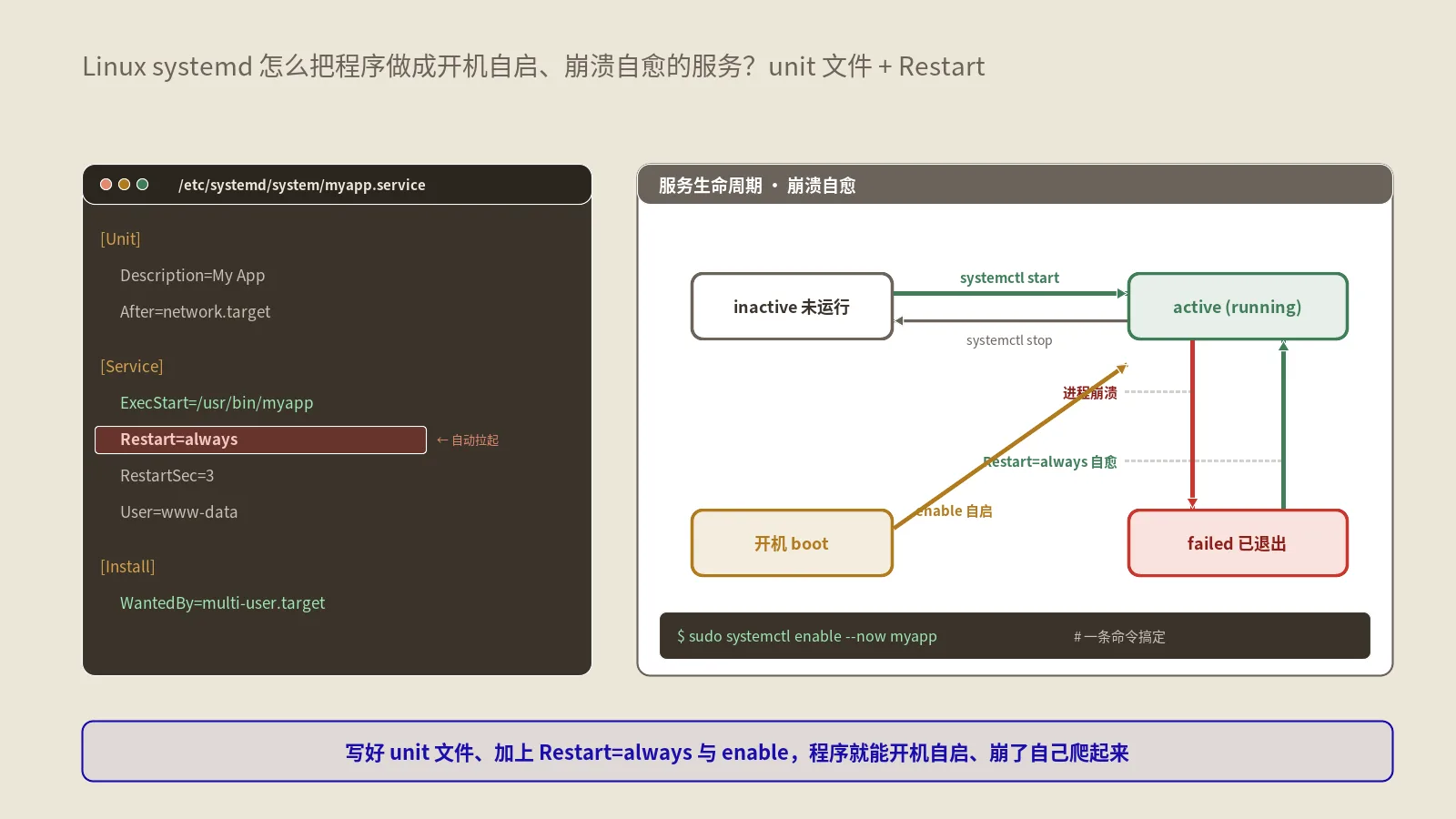
服务单元文件是systemd运维的核心。它本质是一个INI风格的配置文件,通常分三段:[Unit]、[Service]、[Install]。先看一个最小可用的例子:
[Unit]
Description=My Order Sync Worker
After=network-online.target
Wants=network-online.target
[Service]
Type=simple
User=appuser
WorkingDirectory=/opt/order-sync
ExecStart=/usr/bin/node /opt/order-sync/worker.js
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target[Unit]段描述这个单元是什么、和谁有依赖关系。Description是人看的说明;After规定启动顺序(在网络就绪之后再启动);Wants表达弱依赖(希望网络在线,但即使没有也不阻塞)。需要强依赖时用Requires,但保哥提醒慎用——强依赖的服务挂了会连带把你的服务也拖下水。
[Service]段是核心,定义服务怎么跑。Type决定systemd如何判断服务启动成功(这一段后面专门讲);ExecStart是启动命令,必须用绝对路径;User指定以哪个用户身份运行;WorkingDirectory设工作目录;Restart和RestartSec控制崩溃后的重启行为。
[Install]段只在你执行enable时起作用。WantedBy=multi-user.target的意思是:开机进入多用户模式时,把这个服务也拉起来。没有这一段,服务就无法设置开机自启。这是个高频疏漏点,单元文件写得再好,漏了[Install]段,enable就没效果。
enable和start有什么区别,别再搞混了?
这是新手最常犯的迷糊。systemctl start是“现在就把服务启动起来”,但它管的只是当下这一次;systemctl enable是“设置开机自启”,它会在[Install]段指定的target里创建一个符号链接,让服务在每次开机时自动被拉起,但它本身不会立刻启动服务。
所以正确的理解是:这两个命令管的是两件不同的事,一个管“现在”,一个管“以后每次开机”。一个常见的翻车场景是:运维只start了服务没enable,当时跑得好好的,结果服务器某次重启后服务没回来,业务中断了才发现。反过来,只enable没start,服务要等到下次重启才生效,当下并没跑起来。
想一步到位,用systemctl enable --now 服务名,等于同时执行enable和start。日常部署一个新服务,保哥的标准动作就是这一条命令,既启动当下、又保证以后开机自启,省得来回切。对应地,disable --now则是同时停止并取消开机自启。
另外几个常用的状态查询命令一并记住:systemctl status 服务名看当前状态和最近几行日志;systemctl is-active 服务名只回答“现在跑没跑”;systemctl is-enabled 服务名只回答“开机自不自启”。脚本里做判断,后两个比解析status输出靠谱得多。
Type选错,systemd就会误判你的服务死活?
[Service]段里的Type,是最容易踩坑、却最少被理解的一项。它告诉systemd“怎么判断你的服务算启动成功了”。选错了,systemd可能误以为服务启动失败、或一直卡在启动中,进而触发错误的重启或依赖处理。
- Type=simple(默认):systemd认为ExecStart一执行,服务就算起来了。适合那些在前台一直运行、不fork的程序,比如大多数Node、Python写的常驻进程。
- Type=forking:适合传统的守护进程——它启动后会fork出子进程、父进程退出。这时要配合
PIDFile告诉systemd去哪找真正的进程。Nginx、传统的MySQL这类就属于这一型。 - Type=oneshot:适合跑一次就结束的脚本(比如初始化任务、备份脚本),配合
RemainAfterExit=yes可以让systemd在脚本跑完后仍视它为active。 - Type=notify:服务自己通过sd_notify机制主动告诉systemd“我准备好了”,最精确,但需要程序支持。
保哥踩过的典型坑:把一个会自我daemon化(fork后父进程退出)的程序配成了默认的Type=simple。结果父进程一退出,systemd就以为服务死了,立刻按重启策略反复重启,陷入死循环。这种程序应该用Type=forking。反过来,把一个前台运行的程序配成forking、又没给对PIDFile,systemd会一直等那个不存在的fork,卡在启动超时。Type这一项,务必和你的程序实际行为对上。
怎么把自己的应用做成开机自启的服务?
这是最实用的部分。假设你写了一个处理订单同步的后台worker,想让它规范地常驻运行、开机自启、崩溃自愈。步骤是这样的。
第一步,把单元文件放到正确的位置。系统自带服务的单元文件在/usr/lib/systemd/system/(或/lib/systemd/system/),而你自己的、或要覆盖系统的,放在/etc/systemd/system/。后者优先级更高,也是放自定义服务的标准位置。比如建一个/etc/systemd/system/order-sync.service。
第二步,写好单元文件。关键是几个细节别漏:
[Unit]
Description=Order Sync Worker
After=network-online.target
[Service]
Type=simple
User=appuser
Group=appuser
WorkingDirectory=/opt/order-sync
EnvironmentFile=/opt/order-sync/.env
ExecStart=/usr/bin/node /opt/order-sync/worker.js
Restart=on-failure
RestartSec=5
StartLimitIntervalSec=60
StartLimitBurst=5
[Install]
WantedBy=multi-user.target这里有几个保哥反复强调的要点。ExecStart必须用绝对路径,因为systemd不经过登录shell,你的PATH环境变量它一概不认,写node worker.js百分百失败,得写/usr/bin/node /opt/.../worker.js这样的完整路径。
环境变量要用EnvironmentFile或Environment显式注入,systemd不会加载你的.bashrc、.profile,你平时在终端里有的环境变量,服务里一个都没有。务必指定非root的User,别让一个web应用以root裸奔,这是基本的安全底线。
第三步,让systemd重新加载配置,再启用:执行systemctl daemon-reload让它读到新单元文件,然后systemctl enable --now order-sync启动并设为开机自启。最后systemctl status order-sync确认状态是active(running)。
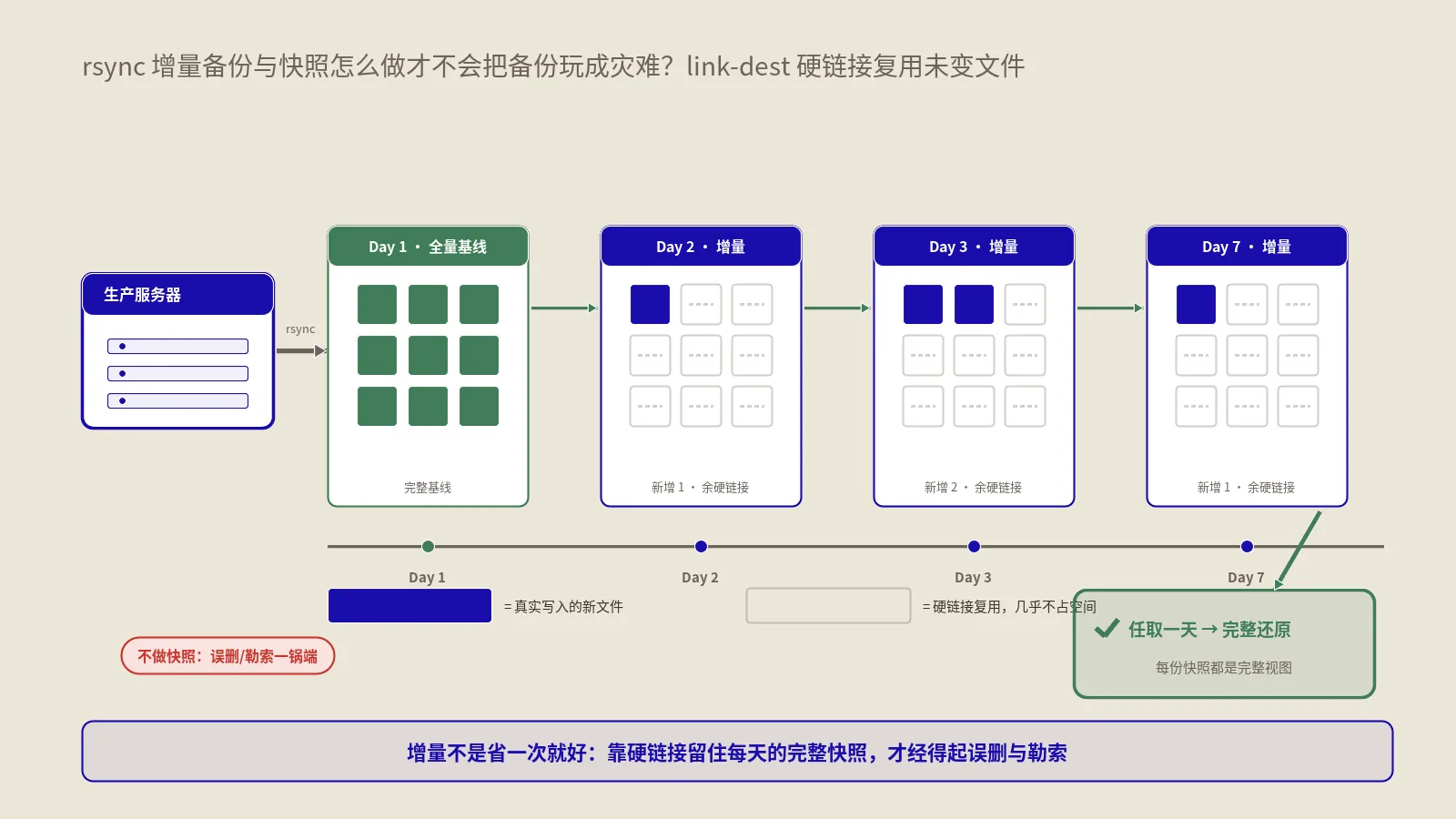
到这一步,你的应用就从一个脆弱的后台进程,升级成了被systemd全程监管的正规服务:开机自启、崩溃自愈、日志归口、优雅启停,一应俱全。同理,像rsync增量备份这类任务,也可以从随手挂的后台脚本,改造成由systemd规范托管的服务或定时器。
服务崩了能自动拉起来吗,重启策略怎么配?
能,而且这正是systemd相比手写脚本最值钱的能力之一。核心是Restart这个指令,它决定服务退出后systemd要不要、以及在什么情况下重新拉起它。
- Restart=no(默认):退出就退出,不管。
- Restart=on-failure:只在异常退出(非零退出码、被信号杀死、超时)时重启。这是保哥最常用的选项,正常停止不重启,异常才自愈。
- Restart=always:无论怎么退出都重启,包括你主动停止后它也会想重启(实际stop命令会先解除)。适合那种“无论如何都得活着”的关键服务。
- Restart=on-abnormal:只在被信号杀死或超时时重启,正常退出码不重启。
配重启,光有Restart还不够,必须配防风暴的闸门。设想一个场景:服务因为配置写错,一启动就崩,Restart=always让它崩了又起、起了又崩,一秒钟重启几十次,CPU和日志瞬间被打爆。这就是“重启风暴”。
防风暴靠StartLimitIntervalSec和StartLimitBurst这一对参数:在前者设定的时间窗口内(比如60秒),如果重启次数超过后者(比如5次),systemd就放弃重启、把服务标记为失败,不再死磕。配合RestartSec(每次重启前等几秒)给系统喘息空间。保哥的默认配置是:RestartSec=5、60秒内最多重启5次,既能应对偶发崩溃,又不会在真出问题时把服务器拖垮。
服务为什么一启动就失败?排查从哪下手?
部署新服务,十次有八次第一遍起不来。别慌,systemd的排查路径很清晰,照着走基本都能定位。
第一步永远是看状态和日志。systemctl status 服务名会显示服务当前状态、主进程退出码,以及最近几行日志;journalctl -u 服务名 -n 50 --no-pager能看到这个服务更完整的日志输出。这套日志机制和journald日志管理是一体的,服务的标准输出和错误输出会自动被journald接管,不用你自己重定向到文件。
定位到日志后,新服务起不来的原因,八成逃不出这几条:
- ExecStart路径不对:命令写成了相对路径,或可执行文件路径写错。改成绝对路径。
- 环境变量缺失:程序依赖的环境变量没注入,导致连不上数据库或读不到配置。用EnvironmentFile补上。
- 权限问题:指定的User对工作目录、文件没有读写权限,或端口需要root权限(1024以下端口普通用户绑不了)。
- Type和实际行为不符:前面讲过的forking/simple选错,systemd误判死活。
- 依赖未就绪:比如服务需要网络或数据库,但启动顺序没配After,起太早了。
保哥的调试技巧:吃不准命令本身能不能跑,先用指定的那个User手动在命令行跑一遍ExecStart的完整命令(sudo -u appuser /usr/bin/node /opt/...),把systemd这层先撇开。如果手动都跑不起来,那是程序或权限问题,跟systemd没关系;手动能跑、服务起不来,那才是单元文件配置的问题,重点查路径、环境变量和Type。
用systemd timer取代cron,值不值得?
定时任务,过去都用cron。systemd提供了另一套方案:timer单元。它不是要你立刻抛弃cron,但在某些场景下确实更香。
timer的工作方式是“一个.timer单元触发一个同名的.service单元”。比如backup.timer到点了,就去拉起backup.service。触发时间用OnCalendar表达,语法比cron更易读,比如OnCalendar=*-*-* 03:00:00表示每天凌晨3点。
相比cron,timer的几个实打实的优势:任务的输出自动进journald,排查有日志可循,不像cron还得自己处理邮件或重定向;能表达依赖和启动顺序;Persistent=true能让错过的任务在开机后补跑(机器关机错过了执行点,开机自动补上),这是cron做不到的;还能加随机延迟,避免一堆任务卡同一秒齐发。关于cron本身的玩法和适用场景,保哥在Linux cron与Shell自动化运维里讲过,这里只谈和systemd的取舍。
那还要不要用cron?保哥的实战取舍是:简单的、单机的、跑个脚本的定时任务,cron写一行就完事,够用且人人会改;而那些需要日志可追溯、需要补跑、需要和其他服务有依赖关系、或本来就已经是systemd服务的任务,用timer更顺。两者并存,按任务复杂度选,不必非黑即白。
让服务更安全、更省资源,有哪些开箱即用的开关?
systemd还内置了一批沙箱和资源限制能力,加几行配置就能显著提升服务的安全性和稳定性,很多人却完全没用上,实在可惜。
安全加固方面,几个高性价比的开关:User和Group用专用低权限账户运行(前面强调过,不赘述);NoNewPrivileges=true禁止进程获取新权限,挡住提权;PrivateTmp=true给服务一个独立的临时目录,与其他进程隔离;ProtectSystem=strict把系统目录设为只读,服务只能写你明确允许的路径;ReadWritePaths则精确指定哪些目录可写。这些和服务器整体的登录与权限加固思路一脉相承:最小权限,纵深防御。
资源限制方面,systemd底层用cgroups,你可以给服务设上限:MemoryMax限制最大内存(超了会被OOM处理,但只影响这个服务,不殃及全局);CPUQuota限制CPU占用百分比;TasksMax限制能创建的进程/线程数。给那些可能内存泄漏、或偶尔吃满CPU的服务套上限制,等于给它们划了个笼子,某个服务发疯也不至于把整台机器拖垮。
保哥的建议是,对外网可达、或自研不那么成熟的服务,默认就把NoNewPrivileges、PrivateTmp、ProtectSystem和一个合理的MemoryMax配上。多写四五行,换来的是出问题时炸不大、被攻破时跑不远,这笔账非常划算。
服务跑起来后,日常怎么盯着它别出事?
部署只是开始,服务上线后得有人盯着。systemd提供了不少现成的巡检手段,不用额外装东西。
最该养成的习惯是定期看失败清单:systemctl --failed一条命令列出所有进入失败状态的服务。把它加进你的日常巡检或监控脚本,服务悄悄挂了能第一时间发现,而不是等业务报错才回头查。
实时盯一个服务的日志,用journalctl -u 服务名 -f,像tail -f一样跟踪输出,排查现场问题时特别顺手。想看某段时间的,加--since "10 min ago"这类时间过滤。配合journald的持久化设置,历史日志也能往回翻,不会重启一次就丢光。
但systemd自带的巡检只到“单机状态可见”这一层。真正成熟的运维,要把这些状态接进集中监控和告警:服务进入failed、重启次数异常、内存逼近MemoryMax上限,这些信号都该自动推送到你的告警渠道,而不是靠人工每天手敲systemctl去看。被动查变主动告警,才是从“能用”到“好运维”的关键一跃。保哥的经验是,哪怕只把systemctl --failed的结果接进一个最简单的告警脚本,也比纯靠人盯强得多。
改单元文件时,哪些坑最容易踩?
最后把日常改单元文件最高频的几个坑收个尾,对照着自查,能省下大量“改了没生效”的抓狂时间。
- 改完忘了daemon-reload:这是头号坑。你编辑了单元文件,但systemd内存里还是旧的,直接restart用的还是老配置,改了等于没改。任何单元文件改动后,先
systemctl daemon-reload,再重启服务。 - 直接改系统自带的单元文件:在
/usr/lib/systemd/system/里改厂商提供的单元,下次软件包升级会被覆盖,你的改动全丢。正确做法是用systemctl edit 服务名创建drop-in覆盖文件(放在对应的.d目录里),只覆盖你要改的指令,既保留原文件,又不怕升级冲掉。 - ExecStart用了相对路径:前面反复说的,systemd不认你的PATH,必须绝对路径。
- 以为环境变量会自动带过来:登录shell的环境变量systemd一概不继承,该注入的用Environment或EnvironmentFile显式写。
- Type和程序行为对不上:fork型程序配simple、前台程序配forking,都会让systemd误判,引发反复重启或启动超时。
这五个坑,本质都是一个认知偏差:把systemd服务当成“在终端里敲命令”那一套。但systemd是个独立的、不带你登录环境的执行器,它有自己的一套规则。把这套规则吃透——绝对路径、显式环境、改完reload、用drop-in覆盖、Type对齐行为——你就能让服务器上每一个后台程序都跑得规范、稳当、可控。这也是把服务器从“能用”做到“好运维”的分水岭。
常见问题解答
systemctl enable和start到底有什么区别?
start是“现在立刻启动服务”,只管当下这一次;enable是“设置开机自启”,它在target里创建符号链接让服务每次开机自动拉起,但本身不会立刻启动。只start不enable,服务器重启后服务不会回来;只enable不start,要等下次重启才生效。想一步到位用systemctl enable --now 服务名,同时启动当下并设为开机自启,这是部署新服务的标准动作。
为什么我的服务在终端能跑,做成systemd服务就启动失败?
最常见两个原因。一是路径:systemd不经过登录shell,不认你的PATH,ExecStart必须写绝对路径,node app.js要写成/usr/bin/node /full/path/app.js。二是环境变量:systemd不加载你的.bashrc、.profile,终端里有的环境变量服务里一个都没有,要用Environment或EnvironmentFile显式注入。调试技巧是用指定的User手动跑一遍完整ExecStart命令,先把systemd这层撇开,判断是程序问题还是配置问题。
服务崩溃后怎么让它自动重启,又不会无限重启把机器拖垮?
用Restart=on-failure让异常退出时自动重启(正常停止不重启)。但必须配防风暴参数:StartLimitIntervalSec设时间窗口(如60秒)、StartLimitBurst设窗口内最大重启次数(如5次),超过就放弃重启、标记为失败,不再死磕。再加RestartSec=5让每次重启前等几秒。这套组合既能应对偶发崩溃自愈,又能在服务真有问题(一启动就崩)时及时止损,不会陷入一秒重启几十次的死循环。
单元文件改了为什么不生效?
九成是忘了执行systemctl daemon-reload。你编辑了单元文件,但systemd内存里还是旧配置,直接restart用的还是老的。规矩是:任何单元文件改动后,先daemon-reload让systemd重新读取,再restart服务。另外,如果你改的是系统自带服务,别直接编辑/usr/lib/systemd/system/里的文件(升级会被覆盖),用systemctl edit 服务名创建drop-in覆盖文件,只改你要改的部分。
systemd timer能完全替代cron吗?
能替代,但不必非替代。timer的优势:输出自动进journald便于排查、支持依赖和启动顺序、Persistent=true能补跑错过的任务(关机错过的执行点开机后补上)、可加随机延迟错峰。适合需要日志追溯、补跑、有依赖关系或本就是systemd服务的任务。而简单的单机定时脚本,cron一行搞定、人人会改,继续用cron完全没问题。保哥的取舍是按任务复杂度选,两者并存,不搞一刀切。
怎么限制一个服务最多用多少内存和CPU?
systemd底层用cgroups,在[Service]段加资源限制即可:MemoryMax=512M限制最大内存(超限只影响这个服务,会被OOM处理,不殃及全局);CPUQuota=50%限制CPU占用;TasksMax限制进程/线程数。给可能内存泄漏或偶尔吃满CPU的服务套上限制,相当于划个笼子,即便某个服务发疯也不会把整台机器拖垮。改完记得daemon-reload再重启服务生效。
权威参考资料
本文标题:《Linux systemd服务管理:怎么把自己的程序做成开机自启服务?》
本文链接:https://zhangwenbao.com/linux-systemd-service-management-unit-files-custom-daemon-auto-restart.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0