Linux进程管理怎么玩才不手忙脚乱?ps/top看进程、kill信号与nice优先级实战
本文目录
- Linux里的进程到底是什么?为什么先要搞懂它的状态?
- 怎么看系统里都跑着哪些进程?ps和top各擅长什么?
- ps aux那一堆列都是什么意思?怎么快速找到我要的进程?
- top和htop怎么用才能实时盯住吃资源的进程?
- 想关掉一个进程,kill发的信号到底是什么?
- kill -9是不是万能?为什么不该动不动就用?
- 怎么按名字、按规则批量管理进程?killall和pkill怎么选?
- 进程抢资源拖慢系统,怎么用nice和renice调优先级?
- 前台跑的命令怎么转到后台?关了终端进程还在吗?
- 僵尸进程和孤儿进程是什么?要不要紧、怎么处理?
- 保哥排查一个吃满CPU的失控进程,是怎么一步步收拾的?
- Linux进程管理最容易翻车的几个地方有哪些?
- 常见问题解答
- kill和kill -9到底有什么区别?什么时候该用哪个?
- 为什么有的进程连kill -9都杀不掉?
- nice值范围是多少?为什么普通用户调不了某些优先级?
- nohup和直接加 & 放后台有什么不一样?
- 系统里出现僵尸进程要紧吗?怎么清理?
- 权威参考资料
摘要:服务器突然变慢、某个程序卡死不动、关了SSH窗口跑了一半的任务就断了——这些是运维独立站服务器时几乎天天会遇到的状况,背后考的都是同一项基本功:进程管理。可很多人对它的全部认知就停留在一句kill -9,进程一卡就 -9伺候,结果数据没存盘、文件被写坏,越救越乱。
其实Linux的进程管理是一套挺讲究的体系:怎么看清系统里在跑什么、怎么找到该处理的那个进程、关进程时发的是哪种信号、信号之间有什么区别、怎么调进程的优先级让它别抢资源、怎么把任务丢到后台让它脱离终端继续跑。把这套搞明白,你处理服务器问题就能从瞎试变成有章法。
保哥这篇按真实运维场景把进程管理讲透:进程的状态怎么读、ps和top各擅长什么、ps aux那堆列什么意思、top和htop怎么实时盯资源、kill发的信号到底是什么、为什么不该动不动kill -9、killall和pkill怎么选、nice和renice怎么调优先级、前台任务怎么转后台、僵尸和孤儿进程要不要紧,最后给一个收拾失控进程的真实案例和几个翻车现场。
保哥先讲个真见过的事。一个朋友的独立站服务器半夜负载飙高,网站打不开,他SSH上去一看,有个数据导出脚本卡住了、CPU占满。他二话不说 kill -9 把它干掉,网站是恢复了,可第二天发现那次导出写了一半的文件残留在磁盘上、数据库里还留了几条没提交完的脏记录,清理起来比当初让脚本正常结束麻烦十倍。
问题不在于他不该关那个进程,而在于他对“怎么关”一无所知——上来就用最暴力的SIGKILL,不给进程任何收尾的机会。所以这一篇,保哥按“进程是什么、怎么看、怎么找、怎么关、怎么调度、怎么放后台”这条真实链路,把Linux进程管理讲清楚,让你以后处理服务器问题既快又稳,不再靠kill -9一招走天下。
Linux里的进程到底是什么?为什么先要搞懂它的状态?
进程(process)说白了就是一个正在运行的程序的实例。你启动Nginx,就产生了Nginx的进程;跑一个PHP脚本,就产生了一个PHP进程。每个进程都有一个唯一的编号PID(进程ID),系统就靠这个号来识别和操作它。还有个常打交道的PPID,是父进程的PID——进程之间是有父子关系的,一个进程可以派生(fork)出子进程。
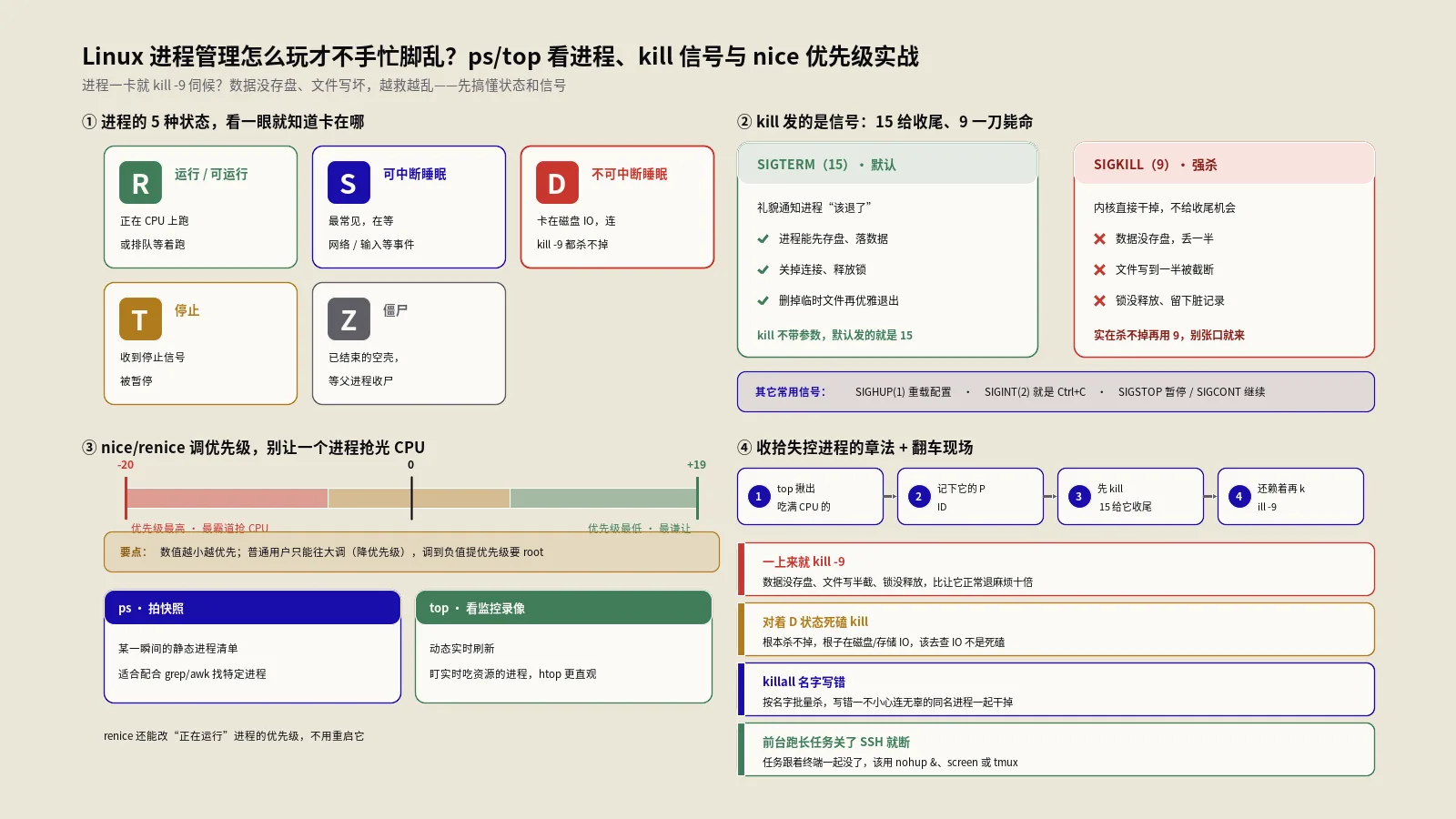
管理进程之前,得先看懂进程的状态,因为很多“卡住”的问题,看一眼状态就明白是怎么回事。Linux进程主要有这几种状态:R(运行或可运行)表示进程正在CPU上跑或排队等着跑;S(可中断睡眠)是最常见的状态,进程在等某个事件(比如等网络数据、等用户输入),大部分时间空闲的进程都是这个状态;D(不可中断睡眠)通常是在等磁盘IO这类没法被打断的操作。
还有两个要特别留意的:T(停止)表示进程被暂停了(比如收到了停止信号);Z(僵尸)表示进程已经运行结束,但它的父进程还没来收尸,残留了一个空壳,这个后面专门讲。
为什么状态这么重要?举个例子,一个进程如果长期处于D状态(不可中断睡眠),你会发现连kill -9都杀不掉它——因为它卡在内核的IO操作里,根本没机会处理任何信号。这时候你再怎么kill都没用,真正的问题在磁盘或存储那一层。如果你不懂状态,只会对着杀不掉的进程干瞪眼;懂了状态,你立刻知道该去查IO而不是死磕kill。所以进程管理的第一步,永远是先看清它现在是什么状态。
怎么看系统里都跑着哪些进程?ps和top各擅长什么?
看进程主要靠两类工具,ps和top,它们的定位完全不同,搞清楚各自擅长什么,你才知道什么时候用哪个。
ps是“拍快照”。它把你执行命令那一瞬间系统里的进程列出来,是一张静态的清单。它适合“我要找某个特定进程”“我要把符合条件的进程筛出来配合别的命令处理”这类场景。因为输出是静态文本,ps特别适合配合管道、grep、awk做过滤和脚本化处理。
top是“看监控录像”。它是一个动态刷新的实时界面,每隔几秒更新一次,按CPU或内存占用把进程排序滚动显示。它适合“系统现在很慢,我要实时盯着看到底是谁在吃资源”这类场景,能动态观察哪个进程在持续飙CPU、哪个在涨内存。
一句话区分:要静态地找、筛、配合脚本处理,用ps;要动态地实时观察资源占用,用top。保哥的实战习惯是,排查“系统正慢着”的现场先开top看实时占用揪出元凶,要对某一类进程做批量精确处理时切回ps配合管道筛选。这套定位思路和保哥讲服务器性能排查那篇里“负载高了先看什么”的诊断链路是配套的,进程管理是性能排查落到具体某个进程时的下一步动作。
ps aux那一堆列都是什么意思?怎么快速找到我要的进程?
ps最常用的写法是 ps aux,它列出系统里所有用户的所有进程。输出的那一堆列,保哥挑实战中最该看懂的几个讲。
ps aux关键的几列:USER 是进程属主;PID 是进程编号,后面kill就用它;%CPU 和 %MEM 是该进程占的CPU和内存百分比,排查吃资源的进程就盯这两列;STAT 是前面讲的进程状态(R/S/D/Z等);COMMAND 是启动这个进程的完整命令,用来确认“这到底是个什么程序”。
实战里你很少傻看全部,更多是配合grep精准筛选。比如想找所有Nginx进程:
ps aux | grep nginx想按CPU占用从高到低排,揪出最吃CPU的几个进程,可以这么写:
ps aux --sort=-%cpu | head这条命令保哥几乎天天用:--sort=-%cpu 按CPU降序排(前面的负号表示降序),head 只看排在最前面的几行,一眼就看到谁最吃CPU。把 %cpu 换成 %mem 就是按内存排。“ps aux加排序加head”这个组合,是定位资源大户最快的一招,比在top里翻找有时还利索。找到了目标进程,记下它的PID,下一步就能对它做操作了。
top和htop怎么用才能实时盯住吃资源的进程?
当系统正在变慢、你要实时观察,top是首选。直接敲 top 回车就进了实时界面。
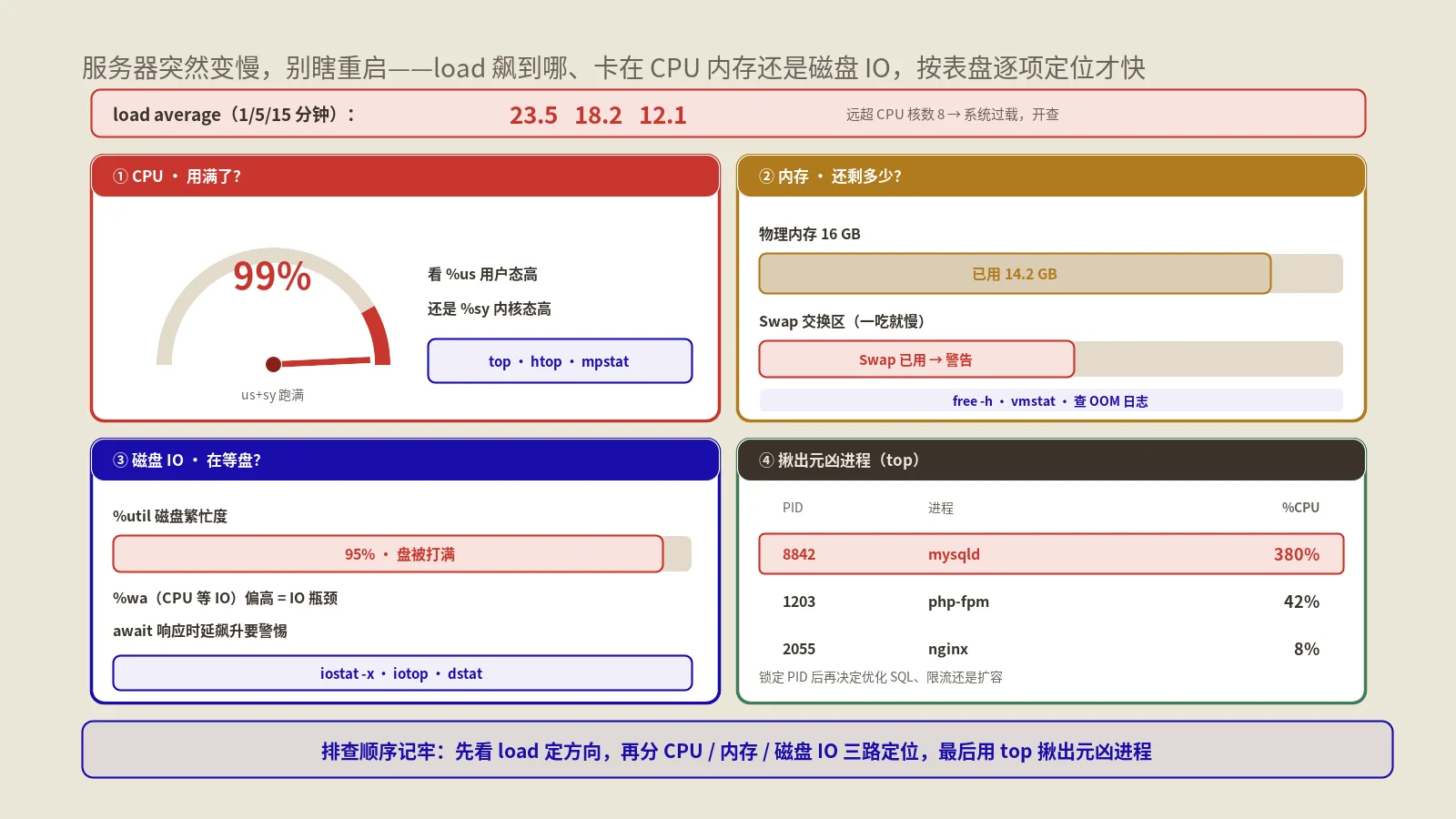
top界面顶部是系统整体概况:load average(负载均值)的三个数字分别是过去1、5、15分钟的平均负载,能看出系统压力是在上升还是缓解;还有CPU各部分占用、内存使用情况。下半部分是进程列表,默认按CPU占用降序排。
top运行中有几个实用按键:按 P 按CPU排序、按 M 按内存排序、按 k 可以直接输入PID给进程发信号(在top里就能kill)、按 q 退出。光会这几个键,你就能在top里完成“找到吃资源的进程并处理它”的全过程。
如果服务器上装了 htop,体验会更好。htop是top的增强版,彩色界面、能用方向键上下选中进程、F功能键直接操作,对人更友好,每个CPU核心的负载还单独用进度条显示。它不是系统自带的,需要自己装一下(比如 apt install htop 或 yum install htop)。
htop保哥的习惯是:排查现场如果系统里有htop就优先用htop,看着直观、操作顺手;没有就用自带的top,功能上完全够用。两者的核心价值都是“实时”——把正在持续吃资源的那个进程从一堆进程里盯出来。盯出来之后,要不要关、怎么关,就进入信号的话题了。
想关掉一个进程,kill发的信号到底是什么?
这是进程管理里最该讲透、也最多人误解的部分。很多人以为 kill 就是“杀进程”,其实kill这个命令的本质是“给进程发送一个信号”,杀只是信号的一种效果。
信号(signal)是Linux用来通知进程“发生了某件事”的一种机制。根据Linux官方的signal手册,系统定义了几十种标准信号,每种有自己的编号和默认行为。进程收到信号后,可以选择按默认行为处理、自己写代码捕获处理、或者忽略(少数信号除外)。运维中最常打交道的是这几个:
SIGTERM(编号15)是“礼貌地请你退出”。它是kill命令不指定信号时默认发的信号。进程收到SIGTERM,会得到一个体面收尾的机会——关闭打开的文件、刷新缓冲区、提交未完成的事务、删掉临时锁文件,然后正常退出。所以正确关进程的第一选择永远是SIGTERM,也就是直接 kill PID:
kill 12345SIGKILL(编号9)是“立刻强制处决”。根据signal手册,SIGKILL这个信号进程无法捕获、无法阻塞、也无法忽略——内核收到就直接把进程干掉,不给它任何收尾机会。这就是 kill -9。它的威力最大,但代价也最大,下一节专门讲为什么不该乱用。
SIGHUP(编号1)是“挂断”。本意是终端断开时通知相关进程,但实战中它常被用作“让服务重新加载配置”的信号——很多守护进程(如Nginx)收到SIGHUP会重读配置文件而不中断服务。所以 kill -1 PID 在很多场景下是“平滑重载”而非“杀”。记住这几个信号的区别,你就明白kill不等于杀,它是一套和进程沟通的语言。
kill -9是不是万能?为什么不该动不动就用?
开头那个案例的教训就在这里。kill -9(SIGKILL)确实是最强力的关进程手段,几乎没有进程能扛住它,但正因为它太强力,它跳过了进程所有的收尾逻辑,这恰恰是它最危险的地方。
当一个进程被SIGKILL强制干掉,它没有任何机会做这些事:把内存里还没落盘的数据写进文件、提交或回滚正在进行的数据库事务、释放占用的锁、删除临时文件、通知它的子进程。结果就可能是:数据文件写了一半成了损坏文件、数据库留下不一致的脏数据、锁文件残留导致下次启动报“已在运行”、临时文件堆积。开头那位朋友清理脏数据的麻烦,根子就在这。
所以保哥的铁律是:关进程先礼后兵。第一步永远是 kill PID(发SIGTERM),给进程几秒钟体面退出的时间。大多数正常的程序收到SIGTERM都会乖乖清理好自己然后退出。只有当一个进程确实卡死了、对SIGTERM毫无反应、等了一段时间还赖着不走,才升级到 kill -9 强制处决。
kill 12345 # 先礼:发 SIGTERM 请它正常退出
# 等几秒,如果还在……
kill -9 12345 # 后兵:发 SIGKILL 强制干掉还有个前面提过的例外要记住:处于D状态(不可中断睡眠)的进程,连kill -9都杀不掉,因为它卡在内核IO里压根处理不了信号。遇到kill -9都无效的进程,别怀疑命令敲错了,去查它是不是卡在磁盘或存储IO上,那才是真问题。kill -9不是万能钥匙,它是最后手段,能用SIGTERM解决的事就别动用它。
怎么按名字、按规则批量管理进程?killall和pkill怎么选?
知道PID时用kill很方便,但有时你只知道进程的名字、或者想一次处理一批同名进程,这时就轮到killall和pkill上场了。
killall按“精确的进程名”操作。它会把所有名字完全匹配的进程一次性处理掉。比如想关掉所有nginx进程:
killall nginx它同样默认发SIGTERM,也能指定信号,比如 killall -9 nginx 强制干掉所有nginx。注意killall要求进程名精确匹配,名字得对得上。
pkill按“模式匹配”操作,更灵活。它支持按名字的一部分、按用户、按其他条件来筛选进程。比如关掉名字里包含php的进程:
pkill phppkill还能按属主筛选,比如关掉某个用户跑的所有进程:pkill -u username。它和pgrep是一对——pgrep 按同样的规则只“找出并列出”匹配的进程而不处理,你可以先用pgrep确认会匹配到哪些,再用pkill动手,避免误伤。
怎么选?保哥的经验是:名字明确且想精确匹配,用killall;想按名字片段、按用户等更灵活的条件批量处理,用pkill。但无论哪个,批量操作都比单个kill危险——一个不小心模式写宽了,可能误杀一批不该动的进程。所以保哥的习惯是动手前先用 pgrep 或 ps aux | grep 把“将要被处理的进程清单”看一眼,确认无误再执行,尤其是在生产服务器上。
进程抢资源拖慢系统,怎么用nice和renice调优先级?
有时候问题不是某个进程要关掉,而是它太能抢CPU、把别的重要服务挤得没资源。这时候不该杀它,而该给它降优先级,让它给重要任务让路。这就是nice和renice干的事。
Linux用一个叫 niceness(nice值)的数字表示进程的“谦让程度”,根据相关文档,它的范围是从 -20到19,-20是优先级最高(最不谦让、最抢资源),19是优先级最低(最谦让、最容易给别人让路),默认是0。nice值越高,进程越“客气”,CPU紧张时越靠后排队。
nice用于“启动一个程序时就给它设定优先级”。比如跑一个不急的备份脚本,不想让它影响网站,启动时就给它一个高nice值(低优先级):
nice -n 19 ./backup.sh这样这个备份脚本就以最谦让的姿态运行,CPU空闲时它跑得欢,一旦网站需要CPU,它立刻让路,不会拖慢正经业务。
renice用于“调整一个已经在运行的进程的优先级”。比如发现某个正在跑的进程PID 12345太抢CPU,把它的nice值调高到19:
renice -n 19 -p 12345这里有个重要的权限规则要记住:普通用户只能把进程调得更谦让(提高nice值、降低优先级),不能反过来把它调得更霸道(降低nice值、提高优先级),只有root用户才能降低nice值给进程提权。这是出于安全考虑,防止普通用户抢占系统资源。所以你想给某个进程“提速”(降nice值),通常得用root或sudo。nice/renice的价值在于,它让你不用粗暴地杀进程,就能让吃资源的非关键任务给业务让路,这在跑批量任务、数据处理的服务器上特别实用。
前台跑的命令怎么转到后台?关了终端进程还在吗?
这是另一个高频痛点:你在SSH里跑一个耗时命令,它占着终端、你干不了别的,更糟的是SSH一断、终端一关,这个命令可能就跟着没了。怎么让任务脱离终端在后台稳稳地跑?
最简单的,命令后面加 & 直接丢到后台。比如 ./longtask.sh &,命令在后台跑,终端立刻空出来给你用。配套的几个命令:jobs 看当前终端有哪些后台任务、fg 把后台任务调回前台、bg 让一个暂停的任务在后台继续跑。如果一个前台任务跑着跑着你想转后台,先按 Ctrl+Z 把它暂停,再 bg 让它转入后台运行。
但只加 & 有个坑:它没解决“终端关闭”的问题。终端断开时会向它下面的进程发SIGHUP信号,默认行为是进程跟着退出。所以你SSH断了,加了 & 的任务多半也跟着没了。
真正让任务脱离终端、断了SSH也照跑的办法是 nohup。它的作用是让进程忽略SIGHUP信号,这样终端关闭也影响不到它:
nohup ./longtask.sh > task.log 2>&1 &这条命令的意思是:用nohup跑脚本、让它忽略挂断信号,把输出重定向到task.log文件(因为脱离终端后没地方显示输出了),末尾的 & 丢到后台。这样你放心关掉SSH,任务在服务器上稳稳地跑,回头看日志文件就知道结果。如果任务已经在跑了才想起来要防断开,还可以用 disown 把它从当前终端的任务列表里摘出去。
保哥的提醒是:真正长期要常驻运行的服务,别用nohup这种“手动后台”的土办法,那是给临时长任务用的;常驻服务应该做成正规的系统服务。怎么把程序做成开机自启、崩了自动拉起的正规服务,保哥在 systemd服务管理那篇里讲透了,nohup顶多是应急,systemd才是常驻服务的正解。
僵尸进程和孤儿进程是什么?要不要紧、怎么处理?
这两个名字听着吓人的进程,是面试和实战都常碰到的概念,保哥讲清楚它们到底是什么、要不要紧。
僵尸进程(zombie,状态Z),指的是一个子进程已经运行结束了,但它的父进程还没有来“收尸”(读取它的退出状态),于是它在进程表里残留了一个空壳。僵尸进程本身不占CPU、不占内存,它只是占着一个进程表项(一个PID)。少量僵尸进程完全无害,是正常现象。但如果某个父进程写得有bug、一直不回收子进程,僵尸越积越多,可能耗尽系统的PID,那才会出问题。
关键认知是:僵尸进程你杀不掉,因为它已经死了——kill一个已经结束的进程没有意义。真正该处理的是它的父进程:要么通知父进程去回收(很多情况下父进程稍后会处理),要么把有问题的父进程重启或关掉,父进程一没,这些僵尸子进程会被系统的init进程接管并清理掉。所以遇到僵尸进程,别对着僵尸本身使劲,去找它的父进程(PPID)。
孤儿进程(orphan)则相反:父进程先退出了,子进程还在运行,这个子进程就成了孤儿。但孤儿进程不用担心,系统会自动把它过继给init(PID 1)进程收养,由init当它的新父亲负责善后。所以孤儿进程是被妥善照顾的,不像僵尸那样需要你操心。
一句话总结这两者:僵尸是“死了没人收尸”,要去找它父进程;孤儿是“爹没了被系统收养”,不用管。实战中真正偶尔需要处理的是大量堆积的僵尸,而那本质上是某个父程序的bug,治本要去修或重启那个父程序,而不是在僵尸上浪费时间。
保哥排查一个吃满CPU的失控进程,是怎么一步步收拾的?
把前面的工具串成一条完整链路,保哥分享一个真实的处理过程。一个独立站服务器告警CPU接近100%、网站响应变慢。
第一步,实时定位元凶。保哥SSH上去先敲 top,按P按CPU排序,一眼看到排第一的是一个PHP进程,CPU占用99%,已经跑了快一个小时——明显是某个脚本陷入了死循环或处理量爆炸。记下它的PID。
第二步,搞清它是什么。保哥没急着杀,先用 ps aux | grep PID 看了它的完整启动命令,确认是一个数据同步脚本,是cron计划任务触发的,不是恶意进程。这一步很重要——动手前先确认对象,别误杀正经服务。
第三步,判断该杀还是该降级。这个同步脚本虽然吃CPU,但它的任务本身是需要完成的,只是不该影响网站。保哥先试着用 renice -n 19 -p PID 把它降到最低优先级,看看能不能让它给网站让路。降级后网站响应确实缓过来一些,但那个脚本因为逻辑确实卡死了,CPU还是占满(只是不再挤占关键服务)。
第四步,先礼后兵地关掉它。确认这次同步已经没救、该终止,保哥先发 kill PID(SIGTERM)给它收尾的机会,等了几秒它正常退出了,CPU立刻降下来,没有像开头那个案例一样留下脏数据。因为走的是SIGTERM,脚本自己把没提交的事务回滚了、临时文件也清了。
第五步,治本。事后保哥去查了那个同步脚本为什么会卡死,发现是某次数据量异常导致死循环,给它加了超时和异常处理,又在 日志管理里加了这个脚本运行时长的监控,超过阈值就告警。从此这类失控进程在拖垮服务器之前就能被提前发现,而不是等CPU打满了才被动救火。整个过程,从top定位到优雅关闭再到治本,前后不到十五分钟,关键是每一步都有依据、没有一上来就kill -9制造新麻烦。
Linux进程管理最容易翻车的几个地方有哪些?
保哥按踩坑频率,把进程管理里最容易出事的几个点列出来,动手前对照检查能少掉很多坑。
第一,进程一卡就kill -9,制造脏数据。SIGKILL跳过所有收尾逻辑,会留下损坏文件、未提交事务、残留锁。关进程先 kill(SIGTERM)给收尾机会,真卡死无反应了再升级到 -9。
第二,对着D状态进程死磕kill。不可中断睡眠的进程卡在内核IO里,连kill -9都没用。遇到杀不掉的进程先看状态,是D就去查磁盘存储IO,别在kill上浪费时间。
第三,杀进程前不确认对象,误伤正经服务。尤其用killall、pkill批量操作时,模式写宽了会连带杀掉不该动的进程。动手前先 pgrep 或 ps aux | grep 看清将被处理的清单。
第四,对着僵尸进程使劲杀。僵尸已经死了,杀它没意义,该处理的是它的父进程(PPID)。少量僵尸无害,大量堆积是父程序bug,去修父程序。
第五,长任务只加 & 不加nohup,SSH一断就没。终端关闭会发SIGHUP让进程退出。要任务脱离终端照跑,用 nohup ... & 并重定向输出,或干脆做成systemd服务。
第六,该降优先级却选择杀进程。有些吃资源的任务是需要完成的,只是不该挤占业务。用nice/renice给它降优先级让路,比直接杀掉更合适,别一看到吃CPU就kill。
这几个坑的共同点是:进程管理的核心不是“怎么把进程弄死”,而是“看清状况、用对手段”。先看状态和占用搞清楚发生了什么,再在“优雅关闭、强制终止、调优先级、放后台”这几种手段里选对的那个,你处理服务器问题就既稳又专业,不会再靠一招kill -9把小问题搞成大麻烦。
常见问题解答
kill和kill -9到底有什么区别?什么时候该用哪个?
区别在于发的信号不同,效果天差地别。直接kill PID默认发的是SIGTERM(15)信号,这是礼貌地请进程退出——进程收到后有机会做收尾工作:把内存数据落盘、提交或回滚数据库事务、释放锁、删临时文件,然后正常退出。而kill -9发的是SIGKILL(9)信号,进程无法捕获、无法阻塞、无法忽略,内核直接把它干掉,不给任何收尾机会。所以正确的做法是先礼后兵:先用kill PID发SIGTERM请进程正常退出,给它几秒钟时间,大多数程序都会乖乖清理好自己退出。只有当进程确实卡死、对SIGTERM毫无反应、等了还赖着不走,才升级用kill -9强制处决。动不动就kill -9是危险习惯,会留下损坏文件、脏数据、残留锁,开头那个清理脏数据清半天的案例就是教训。能用SIGTERM解决的,永远别先动SIGKILL。
为什么有的进程连kill -9都杀不掉?
最常见的原因是这个进程处于D状态,也就是不可中断睡眠。进程会进入D状态,通常是因为它正卡在一个没法被打断的内核操作里,最典型的就是等磁盘IO——比如在读写一块出问题的磁盘、或者等一个挂起的网络存储。处于D状态的进程根本没有机会去处理任何信号,包括SIGKILL,因为它的执行流被卡在内核态出不来,信号要等它从那个操作里返回才能被处理。所以你kill -9发了,信号在排队,但进程一直回不来,就表现为怎么杀都杀不掉。遇到这种情况,别怀疑是命令敲错了,也别反复猛敲kill -9,真正该做的是去排查它在等什么IO——查磁盘健康、查存储挂载、查是不是某块盘或网络存储出了问题。把底层的IO问题解决了(或者那个卡住的操作超时返回了),进程要么自己继续、要么这时候才能被信号干掉。D状态进程是“信号的死角”,治本在IO那一层。
nice值范围是多少?为什么普通用户调不了某些优先级?
nice值的范围是从 -20到19,一共40个档。-20是优先级最高,意味着这个进程最霸道、CPU紧张时最优先得到资源;19是优先级最低,意味着进程最谦让、CPU紧张时最先给别人让路;默认值是0。可以这么记:nice值越大越谦让(nice嘛,越nice越客气),越小越强势。权限规则是:普通用户只能把进程往谦让的方向调,也就是只能提高nice值、降低优先级(比如把自己的备份脚本调到19让它别影响别人),但不能降低nice值、提高优先级。只有root用户才有权降低nice值给进程提权。这个限制是出于系统安全和公平考虑——如果允许任何普通用户随意把自己的进程优先级拉到最高,就会出现互相抢占、有人恶意霸占CPU的情况。所以你想给某个进程提速、降它的nice值,得用root或sudo来执行。日常运维中用得最多的其实是给吃资源的非关键任务调高nice值让路,这个普通用户自己就能做。
nohup和直接加 & 放后台有什么不一样?
核心区别在于能不能扛住终端关闭。直接在命令后加 & 只是把任务丢到当前终端的后台运行,终端空出来能干别的,但这个任务和你的终端还是绑定的——当你关闭终端或SSH断开时,系统会向终端下面的进程发送SIGHUP(挂断)信号,默认行为是进程跟着退出。所以你SSH一断,只加了 & 的后台任务多半也就没了,对跑了一半的长任务是灾难。nohup解决的正是这个问题:它让进程忽略SIGHUP信号,这样终端关闭、SSH断开都影响不到它,任务能在服务器上稳稳地继续跑。配合 & 一起用(nohup命令 & ),再把输出重定向到日志文件(因为脱离终端后输出没地方显示),就是跑长任务的标准姿势。如果任务已经在前台跑了才想起来要防断开,可以用disown把它从终端的任务列表里摘出去达到类似效果。但要强调的是,nohup是给临时长任务的应急办法,真正需要长期常驻、还要开机自启和崩溃自动重启的服务,应该做成systemd服务,那才是常驻进程的正规解法,nohup撑不起生产级的服务管理。
系统里出现僵尸进程要紧吗?怎么清理?
少量僵尸进程完全不用紧张,是正常现象。僵尸进程是子进程已经运行结束、但父进程还没来读取它退出状态时残留的一个空壳,它不占CPU、不占内存,只占着一个进程表项(一个PID)。系统里偶尔有几个一闪而过的僵尸很正常。真正需要关注的是僵尸大量堆积且长期不消失的情况,那通常意味着某个父进程有bug、没有正确回收它的子进程,僵尸越积越多理论上可能耗尽系统的PID资源。清理的关键认知是:僵尸进程你杀不掉,因为它已经死了,对一个已经结束的进程发kill没有任何意义。真正该处理的是它的父进程——找到僵尸进程的PPID(父进程ID),如果父进程能正常回收,稍等它就处理了;如果父进程卡住或有bug一直不回收,就重启或关掉这个父进程,父进程一消失,这些僵尸子进程会被系统的init(PID 1)进程接管并清理掉。所以处理僵尸的口诀是:别对着僵尸本身使劲,去找它的父进程,治本是修复或重启那个不回收子进程的父程序。
权威参考资料
本文标题:《Linux进程管理怎么玩才不手忙脚乱?ps/top看进程、kill信号与nice优先级实战》
本文链接:https://zhangwenbao.com/linux-process-management-ps-top-kill-signals-nice-renice-priority.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0