Linux网络配置和排查怎么做才不瞎猜?ip/ss看网卡端口、ping与traceroute实战

本文目录
- 为什么ifconfig、netstat这些老命令该换成ip和ss了?
- 怎么用ip addr看清服务器有哪些网卡和IP?
- ip link和ip route分别看什么?默认网关怎么查?
- ip命令改的网络配置为什么一重启就没了?怎么持久化?
- ss怎么替代netstat看监听端口和占用进程?
- 网站连不上,怎么用ping判断到底通不通?
- ping通了还是慢,怎么用traceroute、mtr找出是哪一跳的问题?
- 域名解析不对,怎么用dig排查DNS?
- 端口到底有没有通?怎么用curl、telnet验证服务可达性?
- 保哥排查一个“海外访问独立站时好时坏”的网络问题,是怎么一层层来的?
- Linux网络排查最容易踩的坑有哪些?
- 常见问题解答
- ifconfig和netstat还能用吗?为什么很多新系统里没有?
- 我用ip命令配好了网络,为什么服务器一重启就又不通了?
- ss -tulnp这串参数分别是什么意思?
- ping不通是不是就代表服务器挂了或网络断了?
- 本机服务监听正常,但从外部就是连不上,问题出在哪?
- 权威参考资料
摘要:独立站服务器“连不上”“访问慢”“某个端口不通”,是运维里最让人抓狂的一类问题——因为它看不见摸不着,不像磁盘满了、CPU飙高那样有明确指标。很多人遇到网络问题就开始瞎猜:是不是机房挂了?是不是被墙了?是不是DNS坏了?猜来猜去就是定位不到那一层。
其实Linux早就把网络排查的工具备齐了,关键是你得会用、得有章法地一层层往下查。这一篇保哥把现代Linux的网络命令讲透:用ip看网卡和路由、用ss看端口和连接、用ping判断连通性、用traceroute找出是哪一跳出了问题、用dig排查DNS、用curl验证端口和服务可达性。把这套串起来,你排查网络问题就能从“瞎猜”变成“分层定位”。
顺带把一个很多人没注意的事说清楚:ifconfig、netstat这些用了十几年的老命令其实早就被淘汰了,现在的标准是ip和ss。保哥会讲清新旧命令的对应关系,再用一个“海外访问独立站时好时坏”的真实排查案例把所有工具串成一条完整链路,最后列几个最容易踩的坑。
先讲个保哥常遇到的场景。客户急吼吼地说“网站打不开了,服务器是不是挂了”,保哥SSH一连——能连上,说明服务器活得好好的。这时候真正的问题往往在网络的某一层:可能是某个服务没监听端口、可能是防火墙挡了、可能是DNS解析到了错的地方、可能是中间某段网络线路抽风。“网站打不开”是一个笼统的症状,背后可能是完全不同的原因,而网络排查的核心,就是用对工具把问题锁定到具体哪一层。
这跟服务器“变慢、负载高”是两类问题。负载高了你去查CPU、内存、磁盘IO,那是性能排查的范畴;而“连不上、不通、解析错”这类,考的是网络排查的功夫。这一篇专讲后者,按“看配置、看端口、测连通、查路由、排DNS、验可达”这条真实链路一步步来。
为什么ifconfig、netstat这些老命令该换成ip和ss了?
很多教程、很多老运维张口还是ifconfig、netstat、route,但保哥得先把这事说清楚:这些命令属于net-tools工具包,已经被官方淘汰、很多新的Linux发行版默认都不装了。取代它们的是iproute2工具包,核心就是ip和ss两个命令。
为什么要换?一是net-tools已经多年没人好好维护,二是它对现代网络特性(比如某些高级路由、网络命名空间)支持不全,三是ip和ss功能更强、输出更规范、性能也更好。你在新装的Ubuntu、Debian上敲ifconfig,很可能直接报command not found,这时候别急着去装老工具,而是该用新命令。
新旧对应关系记一下就顺了:看网卡和IP,ifconfig换成ip addr;看路由表,route换成ip route;看网络连接和端口,netstat换成ss;看ARP表,arp换成ip neigh。功能一一对得上,只是命令变了。
根据 Linux官方的ip(8) 手册,iproute2把大部分网络操作统一收进了一个ip命令下面,通过“对象”来区分干什么——ip address(地址)、ip link(网卡链路)、ip route(路由)、ip neigh(邻居/ARP)等等,对象名还能简写,ip address可以写成ip addr甚至ip a。理解了这个“一个ip命令、多个对象”的设计,后面就好学了。保哥这篇全部用现代命令讲,你也该把肌肉记忆从ifconfig切换过来。
怎么用ip addr看清服务器有哪些网卡和IP?
排查网络第一步,通常是搞清楚“这台机器有哪些网卡、各自是什么IP、状态正不正常”。这就用ip addr,最常简写成ip a。
ip addr输出会列出机器上所有的网络接口。一般你会看到至少两个:lo是回环接口(loopback,IP是127.0.0.1,机器跟自己通信用的,永远在);还有一个或多个真实网卡,名字可能是eth0、ens3、enp1s0之类(现代命名规则下名字花样比较多),这才是连外网的网卡。
每个接口下面,重点看几样:接口状态,括号里的UP表示网卡是启用的,DOWN表示禁用了;inet后面那一串就是这个网卡的IPv4地址,比如inet 192.168.1.10/24,斜杠后面的24是子网掩码位数;inet6 开头的是IPv6地址。如果你发现该有IP的网卡上没有inet地址,那问题可能就出在这——没拿到IP,自然通不了网。
只看某一个网卡可以指定名字:ip addr show eth0。排查时保哥的第一反应就是ip a,先确认“网卡在不在、状态是不是UP、IP有没有正确分配”,这三样有一样不对,后面都白搭,得先解决这层。
ip link和ip route分别看什么?默认网关怎么查?
ip addr偏重看地址,ip link偏重看链路层的网卡状态,ip route则是看路由——数据包该往哪走,这是连通外网的关键。
ip link看网卡的物理/链路状态。敲 ip link 能看到每个网卡是UP还是DOWN、MAC地址是什么。如果要手动启用或禁用一个网卡,用 ip link set eth0 up 或 ip link set eth0 down。网卡是DOWN的,IP配得再对也通不了,所以确认网卡UP是基础。
ip route看路由表,这是排查“能不能出网”的核心。敲 ip route(或ip r)看到的是这台机器的路由规则——按 ip-route(8) 官方手册的说法,它管理的是发往不同目的地的数据包分别从哪个网卡、经哪个网关出去。
ip route这里面最关键的一行是default开头的,那就是默认网关,类似 default via 192.168.1.1 dev eth0,意思是“凡是路由表里没专门指定去向的流量,都交给192.168.1.1这个网关、走eth0出去”。这个默认网关就是你的服务器通向外部世界的大门。如果ip route里压根没有default这一行,那这台机器就出不了网——能ping通同网段的机器,但ping不了外网IP,这是很典型的“没配默认网关”故障。
所以网络不通时,ip route一定要看:有没有默认网关、网关地址对不对、走的网卡对不对。很多“内网通、外网不通”的问题,根子就在这张路由表上。
ip命令改的网络配置为什么一重启就没了?怎么持久化?
这是个特别容易让新手懵的坑。你用ip addr add、ip route add这些命令手动配好了IP和路由,当时一切正常,结果服务器一重启,配置全没了、网又不通了。
原因是:ip命令对网络的修改都是临时的、只存在于内存里,重启就丢。ip命令的定位是“即时生效、临时调整、排查测试”,不负责把配置写进磁盘。要让网络配置开机自动加载、重启也在,得改对应的持久化配置文件,而这部分各发行版不一样。
常见的几种:Ubuntu现在用Netplan,配置在 /etc/netplan/ 下的yaml文件,改完用 netplan apply 生效;用NetworkManager的系统(很多桌面版和部分服务器)可以用nmcli命令或改其配置;较老的Debian 用 /etc/network/interfaces文件;CentOS/RHEL系传统上是 /etc/sysconfig/network-scripts/ 下的ifcfg文件(新版本也转向NetworkManager)。
保哥的实战习惯是:ip命令用来“临时救急和测试”——比如网突然不通了,先用ip命令手动加个IP或路由把网恢复、确认思路对不对,验证通了之后,再去改持久化配置文件把它固化下来,最后可以重启或重载网络服务验证持久化生效。千万别用ip命令临时配好就以为完事了,那只是“这次开机有效”,重启就现原形。这个“先临时验证、再持久固化”的两步法,能避免你在生产服务器上改配置文件改错了直接把网搞断、连SSH都连不上的尴尬。
ss怎么替代netstat看监听端口和占用进程?
排查“服务起没起、端口通不通”,最常用的就是看监听端口,这活以前用netstat,现在用ss——它更快、信息更全。根据 ss(8) 官方手册,ss是用来dump套接字统计信息的工具,能显示比老netstat更详细的TCP和连接状态信息。
最经典的一条命令,保哥几乎天天敲:
ss -tulnp这几个参数拆开看:-t 看TCP连接、-u 看UDP、-l 只看处于监听(listening)状态的、-n 不做名字解析直接显示数字端口(更快也更清楚)、-p 显示是哪个进程在占用这个端口。合起来 ss -tulnp 就是“列出所有正在监听的TCP/UDP端口,以及各自是哪个程序在听”。
这条命令排查时的价值太大了。比如你的网站打不开,想确认Nginx到底起没起、有没有在听80和443端口,敲一下ss -tulnp,如果看到80、443端口有nginx进程在LISTEN,说明服务本身没问题,问题在更外层(防火墙、DNS等);如果压根没看到这两个端口,那就是Nginx没起来或配置没监听,问题在服务本身。“服务到底在不在听端口”这个判断,能一刀切开“是服务的问题还是网络的问题”,是排查时极其关键的分水岭。
顺便一个安全用途:ss -tulnp 还能帮你审计服务器对外开了哪些端口,看看有没有不该监听的服务暴露在外。这跟保哥讲SSH登录加固时强调的“减少攻击面”是一个思路——先用ss看清自己开了哪些门,才知道该关哪些、该用防火墙挡哪些。
网站连不上,怎么用ping判断到底通不通?
测连通性,最基础的工具是ping。它通过发送ICMP包看对方回不回应,来判断“能不能到达对方、来回要多久、丢不丢包”。
ping zhangwenbao.comping的输出里看三样:能不能收到回复(有reply就是通的,一直timeout就是不通);time= 后面的延迟(毫秒数,越小越快,几百毫秒以上就明显慢了);丢包率(停掉ping后会统计packet loss,0% 最好,丢包说明线路质量差或不稳)。Linux下ping默认会一直发,按Ctrl+C停止并看统计。
ping的几个实战判断:ping域名不通,先ping IP试试——如果ping域名不通但ping IP通,那问题在DNS解析(域名没正确解析到IP),不是网络不通;如果ping IP也不通,那才是网络层面到不了对方。ping自己的默认网关,能ping通网关说明本地到网关这段没问题,问题在更外面;连网关都ping不通,那是本机网络配置或本地链路的问题。
不过ping有个要注意的:ping不通不一定代表服务不可用。很多服务器出于安全考虑禁用了ICMP回应(防止被扫描),这种情况下ping不通是正常的,得用别的方式(比如curl测端口)来判断服务可达性。所以ping通了能说明网络通,ping不通要结合具体情况判断,不能一口咬定就是网断了。
ping通了还是慢,怎么用traceroute、mtr找出是哪一跳的问题?
有时候ping是通的,但延迟高得离谱、或者时通时断,这时候要知道“数据包从我这到目标,中间经过了哪些节点、是哪一跳出了问题”,就用traceroute(或更强的mtr)。
traceroute把数据包从你这里到目标服务器经过的每一跳路由都列出来,每一跳显示它的IP和往返延迟。
traceroute zhangwenbao.com怎么看?沿着输出一跳跳往下,如果前面几跳延迟都正常,到某一跳突然延迟飙到很高、或者开始大量出现星号(* 表示这一跳超时无响应),那问题大概率就出在那一跳或它之后的线路上。这能帮你判断瓶颈在哪段:是出了你的机房就慢、还是到了某个国际出口才慢、还是快到目标了才慢。对排查跨国访问问题尤其有用。
mtr是traceroute和ping的结合体,更适合排查时通时断的问题。traceroute只跑一次是张快照,而mtr会持续不断地探测每一跳并实时统计每一跳的丢包率和延迟,跑一会儿你就能看出哪一跳在持续丢包。mtr zhangwenbao.com 跑起来,盯着哪一跳的丢包率(Loss%)居高不下,那就是病灶。排查“网络时好时坏、间歇性卡顿”这类玄学问题,mtr比traceroute靠谱得多,因为它能抓住偶发的丢包,而单次traceroute可能恰好那一下没丢就漏过去了。mtr一般要自己装一下。
域名解析不对,怎么用dig排查DNS?
很多“网站打不开”其实是DNS的锅——域名没解析到正确的IP。排查DNS,最专业的工具是dig。
dig zhangwenbao.comdig会告诉你这个域名解析出来的结果。重点看 ANSWER SECTION,那里是实际解析到的记录——比如A记录指向的IP地址。你拿这个解析出来的IP,跟你服务器真正的IP对一下,如果对不上,那就是DNS解析错了(可能是解析记录配错了、或者改了之后还没生效、或者命中了旧缓存),网站打不开就顺理成章了。
几个实用技巧:查特定类型的记录,比如查MX(邮件)记录用 dig zhangwenbao.com MX,查CNAME、TXT同理在域名后加类型;指定用某个DNS服务器查,比如用Google的公共DNS查 dig @8.8.8.8 zhangwenbao.com,这招特别有用——如果用公共DNS查到的结果是对的、但用你本地默认DNS查是错的,那说明是你本地的DNS服务器缓存了旧记录或配置有问题,而不是域名本身解析错了。
DNS问题的典型表现,前面ping那节也提到了:ping域名不通、但ping IP通,基本就是DNS的问题。这时候dig一查就清楚——是解析没结果、还是解析到了错的IP。改了DNS记录后没立刻生效也别慌,DNS有缓存和TTL,需要等一段时间传播,dig加 @公共DNS可以查到比较新的结果验证是否已生效。
端口到底有没有通?怎么用curl、telnet验证服务可达性?
前面ss是在服务器本机看“我有没有在听某端口”,但从外部看“这个端口从外面能不能连进来、服务正不正常响应”,是另一回事——中间可能隔着防火墙、安全组。验证端口和服务可达性,用curl、telnet这类工具。
curl测HTTP/HTTPS服务最直接。比如确认网站能不能正常响应:
curl -I https://zhangwenbao.com-I只取响应头,能看到HTTP状态码——返回200说明服务正常响应;连不上、超时说明端口或服务不可达;返回5xx说明服务本身出错了。curl还能加 -v看完整的连接过程(包括DNS解析、TCP握手、TLS握手哪一步出的问题),排查起来信息很全。
测某个端口通不通,可以用telnet或nc。比如测目标的3306(MySQL)端口能不能连:telnet 目标IP 3306,能连上(出现连接成功的提示)说明端口是通的,连不上说明端口不通——可能是服务没起、也可能是防火墙挡了。
这里引出一个高频根因:端口不通,很多时候不是服务的问题,而是防火墙或云安全组把端口挡在外面了。你本机ss看着服务在好好监听80端口,外面就是连不上,十有八九是防火墙没放行。这时候要去查服务器的防火墙规则——保哥讲ufw防火墙配置那篇里专门讲了端口放行,以及云服务器还有一层云平台的安全组也得放行。“本机监听正常但外部连不上”这个症状,第一嫌疑就是防火墙/安全组,别在服务配置上瞎找。
保哥排查一个“海外访问独立站时好时坏”的网络问题,是怎么一层层来的?
把前面的工具串成完整链路,保哥分享一个真实案例。一个做出海的独立站,国内访问正常,但海外用户反馈“时好时坏,有时打得开有时转圈打不开”,这种间歇性问题最难搞。
第一步,确认服务器本身没问题。保哥先SSH上去,ip a 看网卡IP正常、ip route 看默认网关在、ss -tulnp 看Nginx在好好监听80/443,curl -I https://localhost 本机请求返回200——服务器这一侧一切正常,问题在更外层的网络链路。
第二步,排除DNS。用 dig @8.8.8.8 域名 和几个不同地区的公共DNS查,解析出来的IP都对、都指向服务器,排除了DNS解析错乱的可能。
第三步,抓间歇性丢包。既然是“时好时坏”,单次ping和traceroute看不出门道,保哥从一台海外的机器对服务器IP跑 mtr,持续探测几分钟。结果很清楚:前面几跳都正常,到某个国际中转节点开始持续丢包,丢包率忽高忽低——这正好对应用户感受到的“时好时坏”。问题锁定在那段国际线路的质量上,不是服务器、不是DNS、不是防火墙。
第四步,对症下药。线路质量问题没法靠改服务器配置解决,得从网络架构层面入手。保哥的处理是给站套上CDN,让海外用户就近访问CDN边缘节点、不再千里迢迢走那段抽风的国际线路回源,间歇性卡顿明显缓解。这类“海外访问慢、时好时坏”的系统排查,保哥在出海店铺访问慢的分层诊断那篇里讲得更全,从DNS、路由到CDN一整套。
这个案例的价值在于排查的顺序和分层思维:从本机服务(ip/ss/curl)、到DNS(dig)、再到中间链路(mtr),一层层往外排除,最后把问题精准锁定在“国际线路丢包”这一层,而不是一上来就瞎猜“是不是被墙了”。有了分层的章法,再玄学的网络问题也能定位。
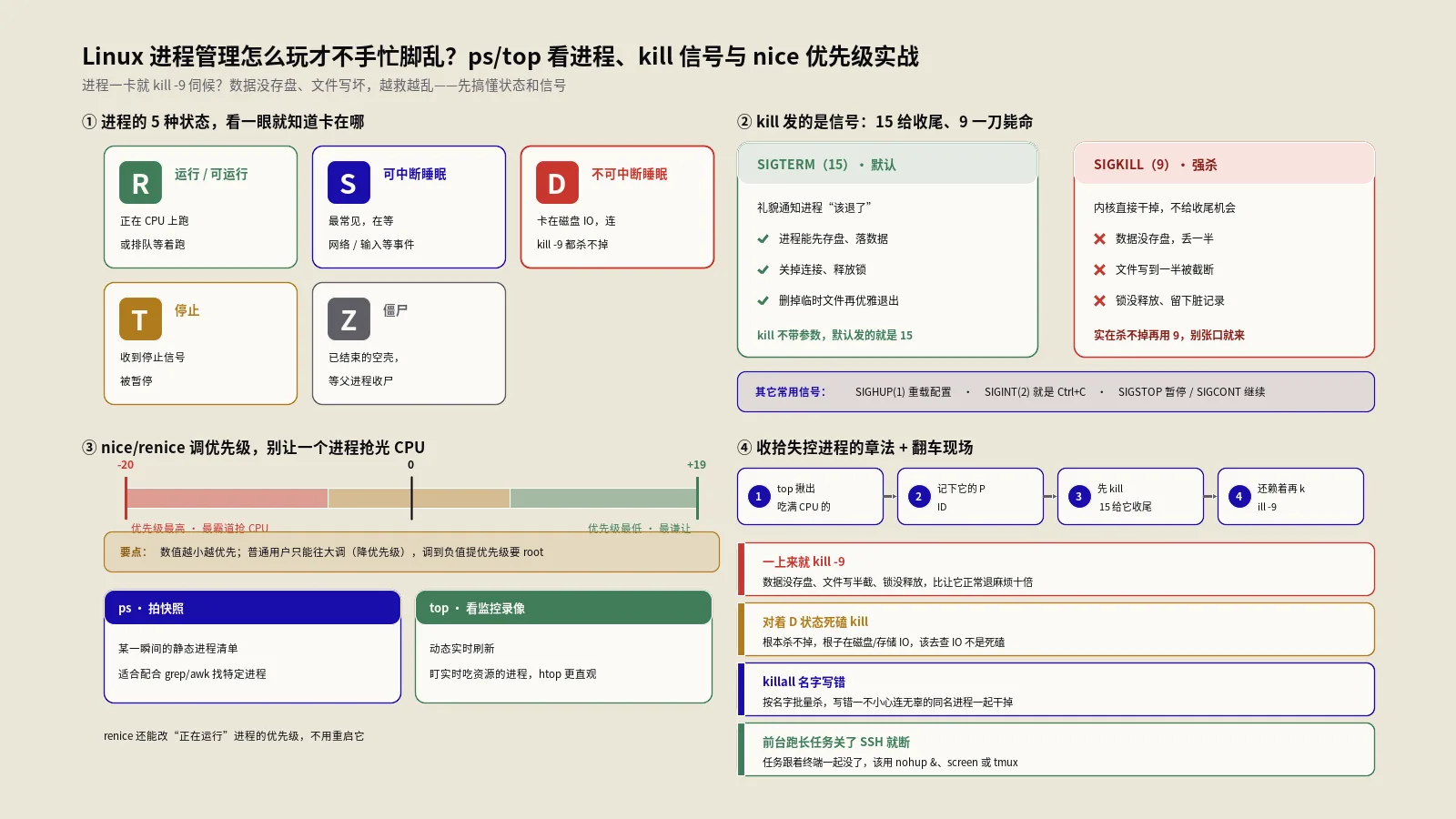
Linux网络排查最容易踩的坑有哪些?
保哥按踩坑频率,把网络排查里最容易出事或走弯路的点列出来,对照着查能少绕很多路。
第一,还在用ifconfig、netstat这些淘汰命令。新系统默认不装、功能也不全。换成ip addr、ip route、ss,新旧一一对应,把肌肉记忆切过来。
第二,用ip命令临时配好就以为完事,一重启全没。ip命令的修改只在内存里、重启即失效。临时验证通了之后,务必改持久化配置文件(Netplan、NetworkManager等)把它固化下来。
第三,ping不通就断定网络断了。很多服务器禁用了ICMP回应,ping不通是正常的。判断服务可达性要用curl测端口和HTTP,别只信ping一个工具。
第四,本机监听正常但外部连不上,却在服务配置里找问题。这个症状第一嫌疑是防火墙或云安全组没放行端口,先去查ufw规则和云平台安全组,别在Nginx配置里白费功夫。
第五,间歇性问题用单次traceroute排查。单次traceroute是快照,抓不住偶发丢包。时好时坏的问题用mtr持续探测,盯哪一跳丢包率居高不下。
第六,DNS改了立刻测,发现没生效就慌。DNS有缓存和TTL,改完需要时间传播。用dig加 @公共DNS查能看到较新的结果,验证是否已生效,别被本地旧缓存误导。
这几个坑的共同点是:网络排查的核心不是记住一堆命令,而是“分层定位 + 用对工具验证”。从网卡配置、到端口监听、到连通性、到路由、到DNS、到外部可达性,一层层往下查,每一层用对应的工具确认,问题自然就被框到具体某一层。这套章法立住了,你面对再棘手的网络故障,也能从容地一步步逼近真相,而不是对着打不开的网站干着急。
常见问题解答
ifconfig和netstat还能用吗?为什么很多新系统里没有?
它们属于net-tools工具包,已经被官方淘汰,很多新的Linux发行版(比如较新的Ubuntu、Debian)默认不再安装,所以你敲ifconfig可能直接报command not found。这不是系统坏了,而是它换了新工具——iproute2工具包里的ip和ss取代了它们。为什么淘汰?net-tools多年缺乏良好维护,对现代网络特性(如某些高级路由、网络命名空间)支持不全,而iproute2功能更强、输出更规范、性能也更好。新旧对应很好记:看网卡和IP,ifconfig换成ip addr(简写ip a);看路由表,route换成ip route;看网络连接和监听端口,netstat换成ss;看ARP邻居表,arp换成ip neigh。遇到新系统没有ifconfig,别急着去装老的net-tools包,而是该顺势用新命令,它们功能完全覆盖且更好用。把肌肉记忆从ifconfig/netstat切换到ip/ss,是现在做Linux运维该有的基本功。
我用ip命令配好了网络,为什么服务器一重启就又不通了?
因为ip命令对网络的所有修改都是临时的、只存在于内存里,重启就会全部丢失。ip命令的定位是即时生效、临时调整、排查测试,它不负责把配置写进磁盘做持久化。要让网络配置开机自动加载、重启后依然在,得去改对应的持久化配置文件,而这部分各发行版不一样:Ubuntu现在用Netplan,配置在 /etc/netplan/ 下的yaml文件,改完用netplan apply生效;用NetworkManager的系统可以用nmcli或改其配置;较老的Debian用 /etc/network/interfaces;CentOS/RHEL传统上用 /etc/sysconfig/network-scripts/ 下的ifcfg文件(新版也转向NetworkManager)。保哥推荐的稳妥做法是两步走:先用ip命令临时把网络配好、验证思路对不对、网能不能通,确认无误后再去改持久化配置文件把它固化下来。这样既能快速救急,又能避免直接改配置文件改错了把网搞断、连SSH都连不上的尴尬。千万别用ip命令临时配好就以为完事,那只是这次开机有效,重启就现原形。
ss -tulnp这串参数分别是什么意思?
这是排查端口监听最常用的一条命令,参数拆开看很好记:-t表示看TCP连接,-u表示看UDP,-l表示只看处于监听(listening)状态的套接字,-n表示不做名字解析直接显示数字端口号(更快也更直观,不会把80显示成http),-p表示显示是哪个进程在占用这个端口。合起来ss -tulnp的意思就是列出所有正在监听的TCP和UDP端口,以及各自对应的进程。它的排查价值非常大:比如网站打不开,你想确认Nginx到底起没起、有没有在听80和443端口,敲一下就清楚——如果看到这两个端口有nginx进程在LISTEN,说明服务本身没问题,问题在更外层(防火墙、DNS);如果压根没看到,那就是服务没起来或没配置监听,问题在服务本身。这个判断能一刀切开是服务的问题还是网络的问题,是排查时的关键分水岭。另外它还能用来做安全审计,看看服务器对外开了哪些端口、有没有不该暴露的服务在监听。
ping不通是不是就代表服务器挂了或网络断了?
不一定,这是个常见误判。ping不通有几种可能:一是网络确实到不了对方;二是对方服务器出于安全考虑禁用了ICMP回应(很多服务器为了防止被扫描会这么做),这种情况下ping不通完全是正常的,服务其实好好的;三是中间某个环节屏蔽了ICMP。所以ping通了能说明网络层是通的,但ping不通不能一口咬定就是网断了或服务器挂了。正确的做法是结合其他工具综合判断:如果ping不通,可以用curl -I测一下HTTP/HTTPS服务能不能正常响应、用telnet或nc测一下具体端口通不通,这些才能真正反映服务可达性。另外有个实用技巧:ping域名不通时先ping一下IP,如果ping IP通但ping域名不通,那问题在DNS解析而不是网络;如果连IP都ping不通,再结合对方是否禁用ICMP来判断。总之别把ping当成唯一的判断依据,它只是连通性排查的第一步,不是终审。
本机服务监听正常,但从外部就是连不上,问题出在哪?
这个症状最大的嫌疑是防火墙或云安全组把端口挡在了外面,而不是服务本身的问题。判断思路是这样:你在服务器本机用ss -tulnp看到服务(比如Nginx)确实在监听对应端口(比如80、443),本机用curl也能正常访问,说明服务跑得好好的;但从外部机器连这个端口就是超时连不上——这种本机正常、外部不通的反差,几乎可以锁定是网络访问控制层面挡住了。要查两个地方:一是服务器自身的防火墙规则,比如Linux上的ufw,看看对应端口有没有放行,没放行的话外部流量进不来;二是如果是云服务器(阿里云、AWS、腾讯云等),云平台还有一层独立的安全组规则,得在云控制台里确认安全组也放行了这个端口——这一层最容易被忽略,因为它不在服务器内部,很多人只查了服务器的ufw却忘了云安全组。把这两层都放行了,外部就能连上了。记住这个口诀:本机监听正常但外部连不上,先查防火墙和安全组,别在服务配置里瞎找。
权威参考资料
本文标题:《Linux网络配置和排查怎么做才不瞎猜?ip/ss看网卡端口、ping与traceroute实战》
本文链接:https://zhangwenbao.com/linux-network-configuration-troubleshooting-ip-ss-ping-traceroute-dns.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0