网站备份了就安全?灾备恢复演练才是真底气
本文目录
- 为什么说“做了备份”和“能恢复”是两回事?
- 灾备到底要先想清楚哪两个数字?
- 备份该遵守的最低底线是什么?
- 哪些灾难场景最该提前演练?
- 一次完整的恢复演练该怎么跑?
- 恢复演练里最常暴露的坑是什么?
- 不同规模的站点,灾备该做到什么程度?
- 光有备份还不够,平时该盯住哪些信号?
- 保哥踩过的灾备坑
- 坑一:信了服务商的“自动备份”却从没验证
- 坑二:备份和网站在同一台服务器
- 坑三:恢复文档过期没人能用
- 坑四:只测了“恢复成功”没测“数据完整”
- 从0建立灾备恢复能力的落地清单
- 常见问题解答
- 有了自动备份,还需要做恢复演练吗?
- RTO和RPO到底是什么,怎么定?
- 3-2-1备份规则具体指什么?
- 怎么防止备份被勒索软件一起加密?
- 恢复演练多久做一次合适?
- 恢复演练时怎么算“恢复成功”?
- 权威参考资料
摘要:大多数站长以为“我每天都有备份,很安全”——可真到服务器崩了、内容被误删、数据库被勒索软件加密那天,才发现备份文件是坏的、少了数据库、或者恢复一次要折腾两天。保哥这些年处理过不少这类事故,最想敲黑板的一句是:备份不等于灾备,没演练过恢复的备份,约等于没有备份。真正的安全感来自“验证过能在规定时间内、把数据恢复到规定的时间点”这件事,而这恰恰是几乎没人做的恢复演练。这篇讲清楚灾备里最该先定的两个数字RTO和RPO、备份必须守住的3-2-1底线、四类最该提前演练的灾难场景、一次完整恢复演练怎么跑、以及恢复时最常暴露的那些致命缺口。把这套做一遍,你才真正配得上“我有备份”这句话。
为什么说“做了备份”和“能恢复”是两回事?
先戳破一个最普遍的幻觉。很多人把“开了自动备份插件”“服务商每天快照”当成了灾备做完了,心里踏实。可备份只是把数据复制了一份存起来,它回答的是“有没有副本”;灾备要回答的是另一个完全不同的问题——“出事的时候,我能不能、多快、把业务恢复到可用状态”。这两件事中间隔着一道几乎所有人都没跨过的坎:验证。
没验证过的备份,保哥叫它“薛定谔的备份”——在你真正去恢复它之前,你永远不知道它是好的还是坏的。而现实里,备份失效的概率高得吓人。备份任务其实早就报错了没人看、备份文件存了但下载下来是损坏的、备份只含文件没含数据库、数据库导出时编码出问题恢复后全是乱码、备份保留周期太短真要的那个时间点早被覆盖了——这些都是亲眼见过、把人逼到崩溃的真实情况。
最典型的一个场景:网站被黑或误操作后,站长信心满满去恢复最近的备份,结果发现最近三个月的备份任务因为磁盘满了一直在静默失败,能用的最新备份是半年前的。半年的内容、订单、用户数据,就这么没了。备份在那里,却救不了命。一个从没被成功恢复过的备份系统,它的真实可靠性是未知数,而未知数在灾难面前默认等于零。
这里有个心理学层面的陷阱值得点破:备份给人的是“安全的感觉”,而灾备给的才是“真正的安全”,这两者经常背离。配好自动备份后那种踏实感,反而会让人放松警惕、再也不去碰它,直到灾难那天幻觉破灭。越是觉得“我备份做得很好”的人,越要警惕自己是不是只是买了个心安,却从没验证过它在关键时刻顶不顶用。安全感和安全,差的就是“验证”这两个字。
所以灾备这件事的核心动作,不是“配置备份”,而是“定期把备份真的恢复一遍,确认它能用、确认你会用、确认恢复速度能接受”。这就是恢复演练。本站之前那篇WordPress备份方案的多维度选型讲的是“怎么选一个靠谱的备份工具、怎么配异地容灾”,解决的是“有没有备份”;这篇是它的下半场——备份配好之后,怎么验证它在灾难来临时真能把你捞上岸。
灾备到底要先想清楚哪两个数字?
动手做灾备之前,有两个数字必须先定下来,它们决定了你整套方案的成本和复杂度。这两个概念来自企业级容灾,但对独立站同样适用,AWS那份被广泛引用的云上灾难恢复策略白皮书把它们讲得很清楚。
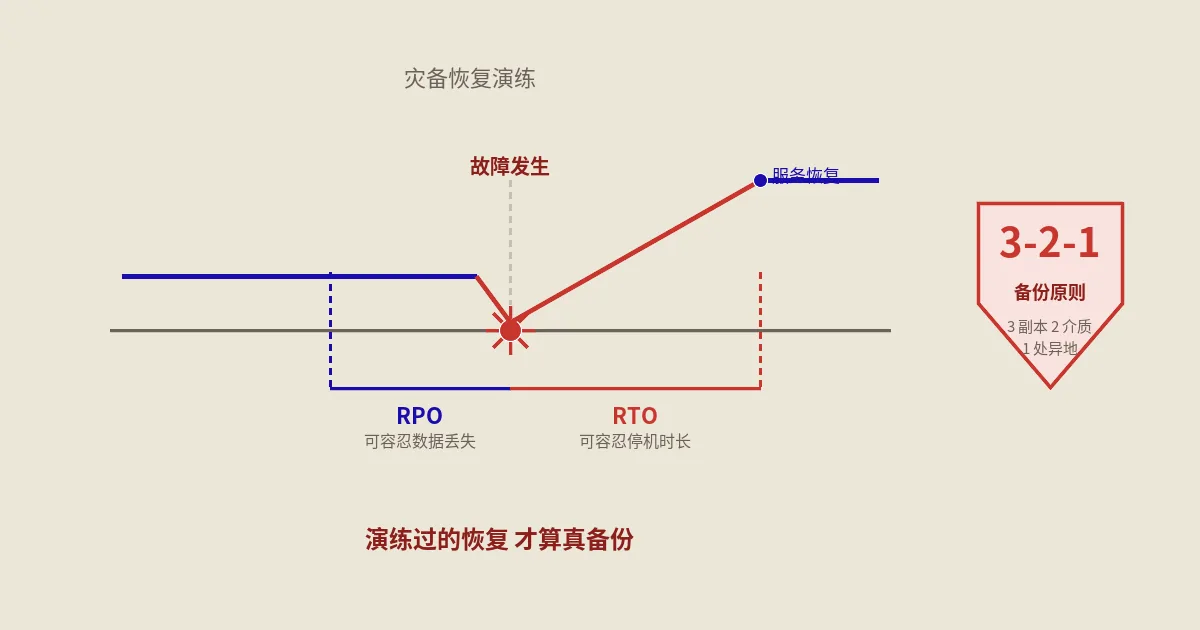
第一个数字是RTO(恢复时间目标),意思是“出事后,你最多能容忍业务中断多久”。是4小时?还是一整天?还是必须15分钟内恢复?RTO越短,方案越贵越复杂——它决定了你需要的是“慢慢从备份重装”还是“随时有个热备站等着切换”。
第二个数字是RPO(恢复点目标),意思是“出事后,你最多能容忍丢多少数据”。如果你每天凌晨备份一次,那最坏情况是丢掉将近一整天的数据(昨晚备份之后产生的全没了),这就是24小时的RPO。能不能接受丢一天的订单?如果不能,就得提高备份频率,甚至上实时复制。
这两个数字不是拍脑袋定的,要按业务损失倒推。一个纯内容博客,丢一天内容、停半天都不致命,RTO一天、RPO一天就够,成本极低;但一个每天成交几十单的独立站,停一天损失实打实,丢一天订单还要面对客诉,那RTO就得压到几小时、RPO压到几小时甚至更短。灾备没有“越强越好”,只有“匹配业务损失”——为一个小博客上多区域热备,是把钱烧在了根本不会发生的损失上。先把这两个数字定出来,后面所有取舍才有标尺。
这两个目标越严,方案就越往“成本和复杂度”那头走,这是个连续的光谱。RTO一天、RPO一天,一套普通的每日自动备份加异地存储就能满足,几乎零成本;RTO几小时、RPO几小时,就要更高频的备份和一套演练过的快速恢复流程;RTO压到一小时内、RPO接近实时,就得上数据库实时复制、甚至随时待命的热备站点,成本和维护精力都成倍上涨。
AWS那份白皮书把这条光谱分成了备份恢复、Pilot Light、Warm Standby、多区域多活几档,独立站虽然用不上那么重,但“目标越严越贵”的逻辑是完全一样的。务实的做法是:先定一个业务能接受的目标,再选满足这个目标的最便宜的方案,而不是反过来被技术方案牵着走。
备份该遵守的最低底线是什么?
不管RTO、RPO定多高,备份本身有一条几乎所有专业人士都认的最低底线——3-2-1规则。Backblaze那篇讲得很透的3-2-1备份策略把它总结成一句话:至少3份数据副本、存在2种不同介质上、其中1份在异地。
这三条每一条都有它要防的具体灾难。3份副本,是防单点损坏——一份坏了还有两份。2种介质,是防介质级故障——别把所有副本都放在同一块硬盘、同一个云盘里,那块盘一坏全军覆没。1份异地,是防机房级灾难——服务器所在机房失火、被攻击、整个被封,本地副本一起没了,异地那份才是最后的救命稻草。
这里有个对独立站特别重要的延伸:异地副本最好还是“离线”或“不可变”的。为什么?因为勒索软件最阴险的一招,就是先潜伏、把你的备份也一起加密或删掉,再发作。如果你的备份就挂在同一台服务器上、或者用同一套凭据能直接改写,勒索软件连备份一锅端,你就彻底没了退路。一份攻击者改不动、删不掉的离线或带版本保护的副本,是防勒索的最后一道墙。关于站点怎么防攻击,本站WordPress攻击防御实战那篇可以一起看,灾备是它的兜底。
具体到独立站,3-2-1落地其实不难也不贵。一份在生产服务器本地(恢复最快)、一份同步到对象存储或网盘(不同介质)、一份定期归档到另一个区域或另一个账号下且开启版本控制不可删(异地离线)。三份的角色不同:本地副本管日常小事故的快速恢复,对象存储管服务器级故障,异地不可变副本专门管勒索和机房级灾难这种最坏情况。把这三层叠起来,常见的几类灾难就基本都有对应的退路了。
还有一条容易被忽略:版本保留要够长。只留最近一份备份是危险的,因为很多灾难(比如被植入后门、数据被悄悄篡改)是潜伏一段时间才被发现的,等你发现时,最近几次备份可能都已经是“带病”的了。保留足够多的历史版本,你才有机会回到“出事之前”那个干净的时间点。一个常用的保留策略是“近密远疏”:最近7天每天一份、最近一个月每周一份、最近一年每月一份,既覆盖了近期高频恢复需求,又用较少的存储留住了足够长的时间跨度。
哪些灾难场景最该提前演练?
灾难不是一种,不同灾难的触发方式、恢复动作、能接受的恢复时间都不一样。与其笼统地说“做灾备”,不如把最该提前演练的几类场景拆开,针对性地准备。独立站最常遇到的是这四类。
| 灾难场景 | 典型触发 | 恢复目标 | 核心恢复动作 |
|---|---|---|---|
| 内容/数据误删 | 手滑删文章、插件冲突清数据 | 快速、精准 | 从最近备份恢复单表或单批数据,不必整站回滚 |
| 数据库损坏 | 磁盘故障、非正常关机、表损坏 | RPO尽量短 | 恢复数据库到最近可用时间点,校验数据完整性 |
| 勒索/被黑加密 | 漏洞被利用、凭据泄露 | 回到干净时间点 | 从离线历史版本恢复,全面改密、补漏洞再上线 |
| 迁移/改版上线翻车 | 换服务器、换CMS、大改版出错 | 快速回滚 | 切回上线前的完整快照,排查后再重试 |
这四类里,误删和迁移翻车是最高频的,几乎每个运营久一点的站都会遇到;勒索是最致命的,一旦中招且备份也被端,基本等于重头再来。每一类的恢复策略都该单独想清楚——比如误删追求的是“精准恢复那一部分、别把好的也覆盖了”,而迁移翻车追求的是“一键切回上线前状态”,两者的准备完全不同。
举几个真实的场景感受一下差别。一个做3C配件的独立站,运营手滑批量删错了一个分类下两百多个产品,这种情况最忌讳慌乱地“整站回滚到昨天”——那会把这一天里其他正常的订单和改动全冲掉。正确的做法是从备份里精准地只把那批产品数据捞回来、合并进现状,是个“外科手术”而不是“推倒重来”。
这要求你的备份不只是一个整站压缩包,最好还能支持按表、按数据范围做选择性恢复——能把昨天备份里的某几张数据库表单独导出来,比只能整库覆盖灵活太多。这也是为什么纯靠“整站快照”做备份的站,一遇到误删就很被动:要么整站回滚连累正常数据,要么干瞪眼。备份方案在设计时就该考虑这种“部分恢复”的需求,而不是只准备应对“全站重建”这一种极端。
再看一个做B2B工业品的站,服务器被人钻漏洞植入勒索软件、文件全被加密,更糟的是挂在同一台机器上的备份也一起遭殃。这家最后能救回来,靠的是三个月前那份存在异地、攻击者够不着的离线备份——虽然丢了三个月数据,但至少没全军覆没。如果没那份离线副本,这站基本就没了。这就是3-2-1里“异地离线”那一条的真实价值。
还有一个做服饰的DTC站,换主题大改版上线后发现结算流程坏了、下不了单,每分钟都在流失订单。这种迁移翻车最需要的是“一键切回上线前快照”的能力——先无脑回滚到能正常下单的状态止血,再慢慢在隔离环境里排查新版本的问题,而不是顶着流血在生产环境上现场调试。能不能快速回滚,往往就是损失几百块还是几万块的区别。
迁移和改版翻车这一类,其实在上线前就能大幅降低风险。在正式上线前先在预发布环境完整演练一遍、压测一遍,能提前暴露绝大多数会翻车的问题,本站预发布环境压测防上线翻车那篇专门讲过这套做法。灾备是兜底,上线前的演练是防患于未然,两者要配合用。
一次完整的恢复演练该怎么跑?
说了这么多,恢复演练具体怎么做?它不复杂,但必须真的动手跑一遍,光在脑子里想是没用的。保哥带团队跑恢复演练,一般按这几步走。
第一步,选定场景和目标。这次演练模拟哪类灾难——是整站宕机重建,还是数据库损坏恢复?对应的RTO、RPO目标是多少?把要验证的东西先写下来。
第二步,准备一个隔离的恢复环境。千万不要直接在生产环境上做恢复演练,那是拿真业务冒险。开一台临时服务器、或一个本地环境、或一个隔离的测试站,在那里恢复,避免演练本身变成事故。
第三步,计时恢复。从“宣布灾难发生”那一刻开始掐表,严格按照你的恢复文档一步步操作:下载备份、搭环境、导入数据库、还原文件、配置域名解析。记录每一步花了多久、总共花了多久。这个真实耗时,就是你当前方案的实际RTO——它往往比你以为的长得多。很多人脑子里估的RTO是“两小时吧”,真掐表跑一遍才发现,光下载几十GB的备份就花了一小时、导入数据库又卡了半天,实际六七个小时才弄完。没掐过表的RTO都是幻想,掐过一次才有真实的基线,也才知道该往哪优化——是该把备份放得离恢复环境更近,还是该提前准备好环境镜像。
第四步,校验完整性。恢复完之后,不是“能打开首页”就算成功。要逐项检查:文章数量对不对、最近的订单在不在、图片附件有没有丢、用户能不能登录、支付功能正不正常、结构化数据和SEO配置还在不在。很多人就栽在这一步——站起来了,但数据缺了一大块。最好提前列一张“恢复验收清单”,把每一项要核对的内容写死,演练时逐条打勾,而不是凭感觉扫一眼。验收清单本身也是演练的产物之一,跑几次就会越来越完善。
第五步,记录差距、修补流程。把这次演练暴露的所有问题列出来:哪一步卡住了、哪个文件没在备份里、恢复文档哪里写得不清楚、实际RTO超没超目标。然后逐条修补——补全备份范围、改进文档、优化流程,让下一次更快更顺。
这五步跑完,你才真正知道自己的灾备水平在哪。恢复演练的真正价值,不在于证明你能恢复,而在于在没有真灾难的安全环境里,把所有会失败的地方先失败一遍。演练时发现备份少了数据库,是虚惊一场;真出事时才发现,是灭顶之灾。演练频率不用太高,重大变更后加每季度一次,对多数独立站就够了。第一次跑完你大概率会被结果吓一跳——原以为半小时能搞定的恢复,真跑下来发现要小半天,还漏了好几样东西。这种“安全环境里的惊吓”正是演练最值钱的地方,它把本会在真灾难里发生的崩溃,提前到了一个无关痛痒的下午。
恢复演练里最常暴露的坑是什么?
跑过几次恢复演练的人都会发现,问题高度集中在那么几个地方。提前知道,能少走很多弯路。
最常见的第一个坑是备份范围不全。最典型的就是备份了网站文件却没备份数据库,或者反过来——而对动态网站来说,文件和数据库缺一不可,少了任何一个都恢复不出完整的站。还有人忘了备份服务器配置、伪静态规则、定时任务、环境变量里的密钥,恢复后站能起来但各种功能不对劲:邮件发不出、支付回调失败、定时任务全停了。判断备份范围全不全有个笨办法但很有效——假设现在这台服务器彻底没了,只剩这份备份,你能不能从零把站完整重建出来?想一遍就知道还缺什么。
第二个坑是环境不一致。备份是在PHP 8.1、某个WordPress版本、某套插件组合下做的,恢复时环境对不上,轻则报错、重则数据迁移出问题。恢复文档里必须记清楚原始环境的版本信息,恢复时先把环境对齐。
第三个坑是没人会恢复。恢复文档要么不存在,要么是几年前写的、早就和现状对不上,要么只有一个早就离职的同事知道怎么操作。灾难往往在最不方便的时候发生,如果恢复全靠某个特定的人,那个人休假或离职时出事,就是灾难叠加灾难。恢复文档必须是任何一个技术人员照着就能跑通的——判断标准很简单:找一个没参与过的同事,只给他文档和备份,看他能不能独立把站恢复出来。跑不通的地方,就是文档要补的地方。这也是为什么演练最好定期换人来做。
第四个坑是漏了域名和DNS。很多人演练只恢复了网站本身,却忘了真实灾难里,如果是换服务器恢复,还要改DNS解析、等生效、处理HTTPS证书。这些环节在真实切换时会吃掉大量时间,演练里不走一遍,就会严重低估真实RTO。
第五个坑,前面反复强调过——备份和生产放在同一个地方。备份就挂在同一台服务器、同一个账号下,服务器一挂、账号一被黑,备份陪葬。异地、离线、独立凭据,这三个隔离一个都不能省。
不同规模的站点,灾备该做到什么程度?
灾备投入要和站点的业务价值匹配,不能一刀切。下面按规模给个参考档位,你可以对号入座。
| 站点类型 | 合理RTO / RPO | 建议做到 |
|---|---|---|
| 个人博客/小内容站 | RTO一天 / RPO一天 | 每日自动备份+异地一份+每半年演练一次 |
| 成长期独立站 | RTO数小时 / RPO数小时 | 高频备份+离线副本+季度演练+恢复文档 |
| 成交密集的成熟站 | RTO 1小时内 / RPO接近实时 | 实时复制+热备或快速重建+月度演练+自动监控备份健康 |
这里的关键是别两个极端都犯:一个每天几百单的站还在用“每周手动下载一次备份”的草台做法,是把生意架在火药桶上;反过来,一个月访问几百的小博客上多区域实时热备,是无谓地烧钱烧精力。灾备的合理投入,永远是拿“出事的损失”乘以“出事的概率”,去和“灾备的成本”做比较,而不是越多越安心。先估清楚一次典型灾难会让你损失多少,再决定为它花多少钱买保险。
还有一点要随业务成长动态调整。很多站的灾备水平是“创业第一天定的、之后再没动过”——当时是个小博客,配了个最简单的每日备份;几年过去成了每天几百单的生意,灾备却还停在博客时代的水平。业务的价值涨了十倍,灾备没跟上,风险敞口就被悄悄放大了十倍。建议每年至少回看一次:现在这个站如果停一天、丢一天数据,损失到底是多少?这个数字变了,灾备档位就该跟着往上挪。灾备和保险一样,保额要和身价匹配,身价涨了保额没涨,等于裸奔。
光有备份还不够,平时该盯住哪些信号?
灾备不是“配一次、演练一次”就一劳永逸的,它需要日常的维护和监控,否则会随着站点变化悄悄失效。有几个平时就该盯住的信号。
第一个是备份任务的健康状态。这是最容易出事、也最容易被忽略的——备份任务静默失败是头号杀手。磁盘满了、凭据过期了、目标存储不可写了,备份任务可能已经连续失败了好几周,而没有任何人知道,因为没人会主动去看。解法是给备份加“成功才安静、失败就告警”的监控:每次备份完成自动检查文件大小是否正常、有没有报错,一旦异常立刻推送通知。一个只在出问题时才出声的监控,比一份没人看的日志有用一百倍。
第二个是备份范围有没有跟上站点变化。站点是会长大的——新加了一个数据库、接了一个新的文件存储、上了一套新的定时任务。如果备份配置还停在半年前,这些新增的部分就在保护范围之外。每次站点架构有较大变动,都该回头检查一遍备份范围是不是还覆盖全。
第三个是恢复能力的“人”这一环。别让恢复能力绑死在某一个人身上。如果整个团队只有一个人懂怎么恢复,那这就是个单点故障——他休假、离职、或者恰好在灾难发生时联系不上,恢复就瘫了。恢复文档要写到“换个技术人员也能照着跑通”,并且最好定期换人来跑演练,确保这个能力是团队的、不是个人的。
第四个是定期回看演练记录。把每次演练的真实RTO、暴露的问题、修补情况记成一条时间线,你能清楚看到自己的灾备能力是在变强还是在退化。灾备是个会随时间衰减的能力,不主动维护,它就会悄悄烂掉,等真出事那天才发现早已名存实亡。把监控、范围检查、人员轮换、演练回看这几件事制度化,灾备才是活的,而不是一份配好就再没人管的摆设。
保哥踩过的灾备坑
这些都是真金白银的教训,列出来帮你避雷。
坑一:信了服务商的“自动备份”却从没验证
以为买了主机的自动快照就万事大吉,真要恢复时才发现快照只保留7天、或者恢复要提工单等一天、或者快照根本恢复不出可用的站。服务商的备份能用,但你必须亲自验证它的保留周期、恢复方式和真实耗时,别把命脉全押在一句营销话术上。
坑二:备份和网站在同一台服务器
图省事把备份文件就存在网站根目录下的一个文件夹里,结果服务器磁盘损坏,网站和备份一起没了。备份的物理隔离是底线中的底线,这个坑栽进去一次就再也不敢省。更隐蔽的同款错误是:备份虽然传到了云存储,但用的是和网站同一套凭据、同一个云账号——一旦账号被盗或被勒索,攻击者顺着凭据把云上备份也一并删了。真正的隔离不只是“不在同一台机器”,还包括“不用同一套能互相触及的权限”。给备份存储单独设一套只写不可删的权限,是这个坑的彻底解法。
坑三:恢复文档过期没人能用
有一次客户出事,翻出三年前的恢复文档,发现里面的服务器路径、工具、版本全变了,照着根本跑不通,只能现场摸索,硬生生把本该一小时的恢复拖成了大半天。文档必须跟着环境一起更新,否则就是废纸。
坑四:只测了“恢复成功”没测“数据完整”
恢复后看首页能打开就宣布成功,上线后才陆续发现最近一周的订单、部分用户数据、一批图片都没恢复回来。恢复的验收标准必须是数据逐项核对,而不是“站起来了”。尤其是那些不在首页、不常被点到的功能——退款记录、会员积分、优惠券、第三方对接的回调配置,最容易在恢复后悄无声息地缺失,等用户投诉才暴露。把这些边角功能都写进验收清单逐一核对,才能避免“恢复成功”三天后又冒出一堆问题的尴尬。
从0建立灾备恢复能力的落地清单
把前面的要点收敛成一份可执行清单,按顺序搭:
- 先定RTO和RPO:按一次典型灾难的业务损失倒推,能容忍停多久、丢多少数据。
- 盘点要备份的全部内容:网站文件、数据库、服务器配置、伪静态、定时任务,一个都别漏。
- 落实3-2-1:至少3份副本、2种介质、1份异地,异地副本尽量离线或带版本保护。
- 设定足够长的版本保留周期,留住“出事之前”的干净时间点。
- 为四类灾难场景分别准备恢复策略:误删、数据库损坏、勒索、迁移翻车。
- 写一份任何技术人员照着都能跑通的恢复文档,记清原始环境版本。
- 开一个隔离环境,按文档计时恢复一遍,量出真实RTO。
- 逐项校验数据完整性:文章、订单、附件、用户、支付、SEO配置。
- 记录演练暴露的所有差距,逐条修补备份范围、文档和流程。
- 把域名DNS切换和证书恢复也纳入演练,别低估真实切换耗时。
- 给备份任务加健康监控,备份失败要主动告警,而不是出事才发现。
- 定下演练节奏:重大变更后必演练,常态下每季度或每月一次。
这套东西搭起来不花几个钱,花的主要是“认真做一遍”的耐心。但它换来的,是真出事那天你不至于手忙脚乱、不至于眼睁睁看着数据消失。
说到底,灾备是一件典型的“平时觉得多余、出事才知道救命”的事。它不像做内容、做转化那样能立刻看到回报,所以特别容易被一拖再拖,直到某天服务器崩了、内容没了、站被加密了,才追悔莫及。但概率这东西很公平——做这行久了,几乎没有谁能永远躲开数据事故,区别只在于出事时你是有条不紊地按流程恢复,还是两眼一抹黑地祈祷备份能用。备份给你的是“我有副本”的心理安慰,恢复演练给你的才是“我真能救回来”的底气——而后者,才是灾备这件事的全部意义。别等到灾难那天,才第一次去验证你的备份到底能不能用。
常见问题解答
有了自动备份,还需要做恢复演练吗?
需要,而且这是最关键的一步。没验证过的备份是“薛定谔的备份”,在真正恢复前你不知道它好不好用。备份失效的概率很高,只有定期恢复演练才能确认它真能救命。
RTO和RPO到底是什么,怎么定?
RTO是能容忍业务中断多久,RPO是能容忍丢多少数据。两个都按一次典型灾难的业务损失倒推:小博客可以一天,成交密集的独立站要压到几小时甚至接近实时。
3-2-1备份规则具体指什么?
至少3份数据副本、存在2种不同介质上、其中1份放在异地。三条分别防单点损坏、介质故障和机房级灾难,是备份的最低底线。
怎么防止备份被勒索软件一起加密?
异地副本要尽量离线或不可变,用独立凭据,别和生产环境共用账号。勒索软件常会先加密删除可触及的备份再发作,一份它改不动删不掉的副本是最后的退路。
恢复演练多久做一次合适?
看站点重要性。多数独立站重大变更后必做一次、常态下每季度一次就够;成交密集的成熟站建议每月一次,并给备份任务加自动健康监控。
恢复演练时怎么算“恢复成功”?
不是首页能打开就算成功。要逐项核对数据完整性:文章数量、最近订单、图片附件、用户登录、支付功能、SEO配置都正常,才算真正恢复成功。
权威参考资料
本文标题:《网站备份了就安全?灾备恢复演练才是真底气》
本文链接:https://zhangwenbao.com/disaster-recovery-drill-backup-restore-rto-rpo-rollback.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0