AI Agent抓取日志解码:8类UA实测、22周访问账本与5种引用归因方法
本文目录
- 为什么AI Agent抓取日志分析是GEO优化的真正起点?
- 8类主流AI Agent UA实测识别规则是什么?
- OpenAI系:GPTBot、ChatGPT-User、OAI-SearchBot 3个角色分工不同
- Anthropic系:ClaudeBot与Claude-User双轨
- Perplexity系:PerplexityBot与Perplexity-User
- Google系:Google-Extended与GoogleOther
- CCBot:Common Crawl是多数AI模型的源头训练数据
- 22周AI Agent访问账本横向数据对照能看出什么?
- AI Agent抓取怎么和真实引用挂钩?5种归因方法实测
- 方法1:Referer反查Perplexity点击
- 方法2:Claude Citations API主动调用验证
- 方法3:ChatGPT-User UA命中频次的关联推断
- 方法4:第三方监测工具(Profound、Otterly、Peec.ai等)
- 方法5:品牌词Search Console与AI Referer交叉
- 怎么从0搭建你站点的AI Agent日志分析SOP?12步流程
- 准备阶段:第1-4步
- 分析阶段:第5-8步
- 优化与复盘阶段:第9-12步
- AI Agent日志归因里最容易踩哪5个坑?
- 坑1:把GPTBot命中当成“被ChatGPT引用”
- 坑2:CCBot命中量大但不代表你的内容被AI模型直接使用
- 坑3:robots.txt写错把全部AI Agent都禁了
- 坑4:用CDN缓存数据当日志数据导致命中频次失真
- 坑5:UA字符串伪造导致数据被污染
- 22周复盘账本:3类站点的9项观察指标
- 常见问题解答
- 问题1:完全没有运维经验能做AI Agent日志分析吗?
- 问题2:我的站点已经3年没有任何AI Agent抓取记录,怎么办?
- 问题3:llms.txt到底有没有用?数据怎么说?
- 问题4:Profound、Otterly这些第三方监测工具值得付费吗?
- 问题5:Common Crawl数据多久更新一次?我的新文要多久能进Common Crawl?
- 问题6:UA命中量在某周突然涨5倍是好事还是坏事?
- 权威参考资料
摘要:多数站长聊AI Agent SEO还停留在“写好llms.txt就行”这种皮毛层面,真实痛点是你根本不知道ChatGPT、Claude、Perplexity这些AI到底有没有抓你的站、抓了哪些页、抓完之后有没有真的引用你。本文用22周服务端访问日志实测数据,给出8类AI Agent UA的真实识别规则、5种引用归因方法的可操作步骤,以及3个独立站点(含我自家站+2个DTC客户站)的横向对照账本。结论:AI Agent抓取≠AI引用,二者归因方法完全不同,做GEO优化先把这道数据底盘打牢再谈策略。
2026年Q1开始接触GEO项目的站长普遍卡在一个最基础的问题上:我的内容到底有没有进入AI搜索引擎的视野?多数同行的答案是“看llms.txt有没有写、看Schema有没有加、看Search Console有没有数据”——这些都不是有效信号。真正能告诉你答案的是服务端访问日志里那些来自AI Agent的请求记录,但绝大多数站长从没认真分析过这一块数据。
这篇文章是我过去22周对3个独立站点(我自家我笔记站+2个DTC客户站)的Nginx访问日志做AI Agent专项分析的全部一手数据。涵盖:8类主流AI Agent UA的实际抓取频率与页面分布、5种引用归因方法的实测准确率、3个站点的横向对照、5个真实归因失败案例的根因分析,以及一份可以直接复用的日志分析SOP。读完应该能让你独立完成自己站点的AI Agent抓取审计与引用归因。
为什么AI Agent抓取日志分析是GEO优化的真正起点?
当下做GEO优化的人99%都从“写策略”开始——写llms.txt、改Schema、调整内容结构、加权威外链。这套打法的根本问题是没有反馈闭环——你写完之后不知道AI到底有没有看、看了什么、引用率有没有变化。所有的GEO策略本质上都是黑盒实验,但黑盒实验没有数据底盘就不是实验是猜。
AI Agent抓取日志是GEO优化里少数几个能给出真信号的数据源。原因是这些AI模型(ChatGPT、Claude、Perplexity、Gemini)在响应用户查询时会派出抓取代理实时拉取候选源URL的内容——这些抓取请求会留下UA、IP、Referer、时间戳的完整日志条目。如果你的内容在AI推理回路中被命中,日志里能看到;如果没被命中,日志里就没记录。
但抓取≠引用这件事很多人没意识到。AI Agent的抓取分3层:训练数据抓取(GPTBot、ClaudeBot、Google-Extended等长期抓取入库训练用)、实时推理抓取(ChatGPT-User、Claude-User、PerplexityBot等用户查询时实时拉取)、引用确认抓取(少数AI在生成引用前会做二次fetch验证内容是否仍有效)。三层抓取的UA不同、行为模式不同、对GEO的实际贡献也不同。日志里能看到全量抓取数据,但要做引用归因还得加另一套方法。
不分析日志做GEO优化,就像不看Search Console做传统SEO——你可能做了很多动作但不知道哪一个真有效。这是保哥过去22周最深的体会。下文按UA识别→访问账本→引用归因→踩坑复盘的顺序展开,每一段都基于真实日志数据。
8类主流AI Agent UA实测识别规则是什么?
2026年Q1的AI生态里活跃的抓取UA大致有8类。这一节不是简单罗列UA字符串,而是给出每一类UA的识别正则、典型抓取频率、对GEO优化的实际意义。每个UA都基于我3站22周的真实日志样本。
OpenAI系:GPTBot、ChatGPT-User、OAI-SearchBot 3个角色分工不同
OpenAI体系有3个不同角色的UA,对应3个不同的业务场景。多数站长把它们混为一谈是最大的认知错误。
GPTBot(UA含 “GPTBot/1.x”):训练数据抓取。这个UA的抓取行为是周期性、广覆盖、慢节奏——典型频率约每天数次到数十次,抓取页面分布广,不集中在热门页。我笔记站22周GPTBot总命中约1100次,覆盖413个不同URL,平均每URL被抓约2.7次。意义:你的内容会进入下一轮ChatGPT模型训练候选池,但不直接影响当下的引用率。
ChatGPT-User(UA含 “ChatGPT-User/1.x”):用户在ChatGPT里启用浏览功能时实时拉取你的内容用于即时回答。这个UA是GEO优化里最重要的信号——出现一次代表你的URL进入了一次真实用户查询的回答候选。我站22周ChatGPT-User命中约247次,覆盖89个URL,平均每URL命中2.8次。出现频率与“被引用率”高度相关。
OAI-SearchBot(UA含 “OAI-SearchBot/1.x”):ChatGPT Search产品的索引爬虫。2024年底OpenAI推出ChatGPT Search后新增的UA,行为类似传统搜索引擎爬虫——周期性全站索引、与GPTBot不同的是会优先索引高时效性内容(新闻、博客新文)。我站22周OAI-SearchBot命中约580次,覆盖278个URL。意义:你的内容被ChatGPT Search产品索引收录,搜索查询时有机会被检索到。
Anthropic系:ClaudeBot与Claude-User双轨
Anthropic的Claude体系UA结构更简单,主要2个:ClaudeBot(训练抓取,类似GPTBot角色)、Claude-User(用户实时查询时的浏览抓取,类似ChatGPT-User)。还有一个Claude-SearchBot出现频率较低暂不展开。
ClaudeBot(UA含 “ClaudeBot/1.x”):我3站22周累计命中约860次。Anthropic对robots.txt的遵守比OpenAI更严格——如果你的robots.txt明确Disallow了ClaudeBot,它会100%停止抓取(OpenAI的GPTBot偶尔会“误抓”几次)。
Claude-User(UA含 “Claude-User”):用户在Claude.ai里启用web搜索或上传URL时的实时抓取代理。我站22周Claude-User命中约168次。值得关注的是Claude-User命中后,如果你的内容被采纳生成回答,会有一定概率被Claude的引用面板列出——这是少数能从UA命中直接推到引用产出的AI模型。
Perplexity系:PerplexityBot与Perplexity-User
Perplexity体系是当前GEO优化里反馈最快的AI引擎。PerplexityBot(UA含 “PerplexityBot/1.x”)做训练抓取与索引;Perplexity-User(UA含 “Perplexity-User”)做用户查询时的实时拉取。我3站22周PerplexityBot累计命中约1450次(在所有AI Agent里抓取频率最高),Perplexity-User命中约310次。
Perplexity独特的地方是它的回答里会直接显示source URL,所以你可以通过Referer字段反查——当用户从perplexity.ai点击source链接进入你的站点时,Referer会带perplexity.ai域名,这是少数能直接确认“AI引用产生了点击”的归因信号。后面的归因方法章节会展开这点。
Google系:Google-Extended与GoogleOther
Google体系里2个与AI相关的UA容易被忽略:Google-Extended(不是抓取UA是策略标识——你的robots.txt里如果Disallow Google-Extended就意味着你的内容不被Gemini用于训练,但Googlebot常规抓取不受影响)、GoogleOther(Google用于实验性产品的通用爬虫,部分是Gemini相关的抓取)。
Google-Extended本身不会作为UA出现在日志里,它是一个策略标识。GoogleOther的UA字符串与Googlebot高度相似但带 “GoogleOther/1.x” 标识,我站22周GoogleOther命中约420次,部分来自Gemini相关的实验抓取。这个UA的命中数据可以作为Gemini对你内容感兴趣程度的弱信号。
CCBot:Common Crawl是多数AI模型的源头训练数据
CCBot(UA含 “CCBot/2.x”)是Common Crawl项目的爬虫。Common Crawl的数据集被GPT、Claude、Gemini等几乎所有主流大模型作为预训练数据源使用。你的内容如果不在Common Crawl里,多数AI模型的训练阶段就看不到。我3站22周CCBot累计命中约2300次(在所有AI Agent UA里抓取量最大)。
CCBot的特殊价值是它是免费、公开、可查询的——你可以去commoncrawl.org直接搜索你的域名查看历史抓取记录。这是GEO优化里少数能用第三方数据交叉验证站点抓取覆盖率的方法。
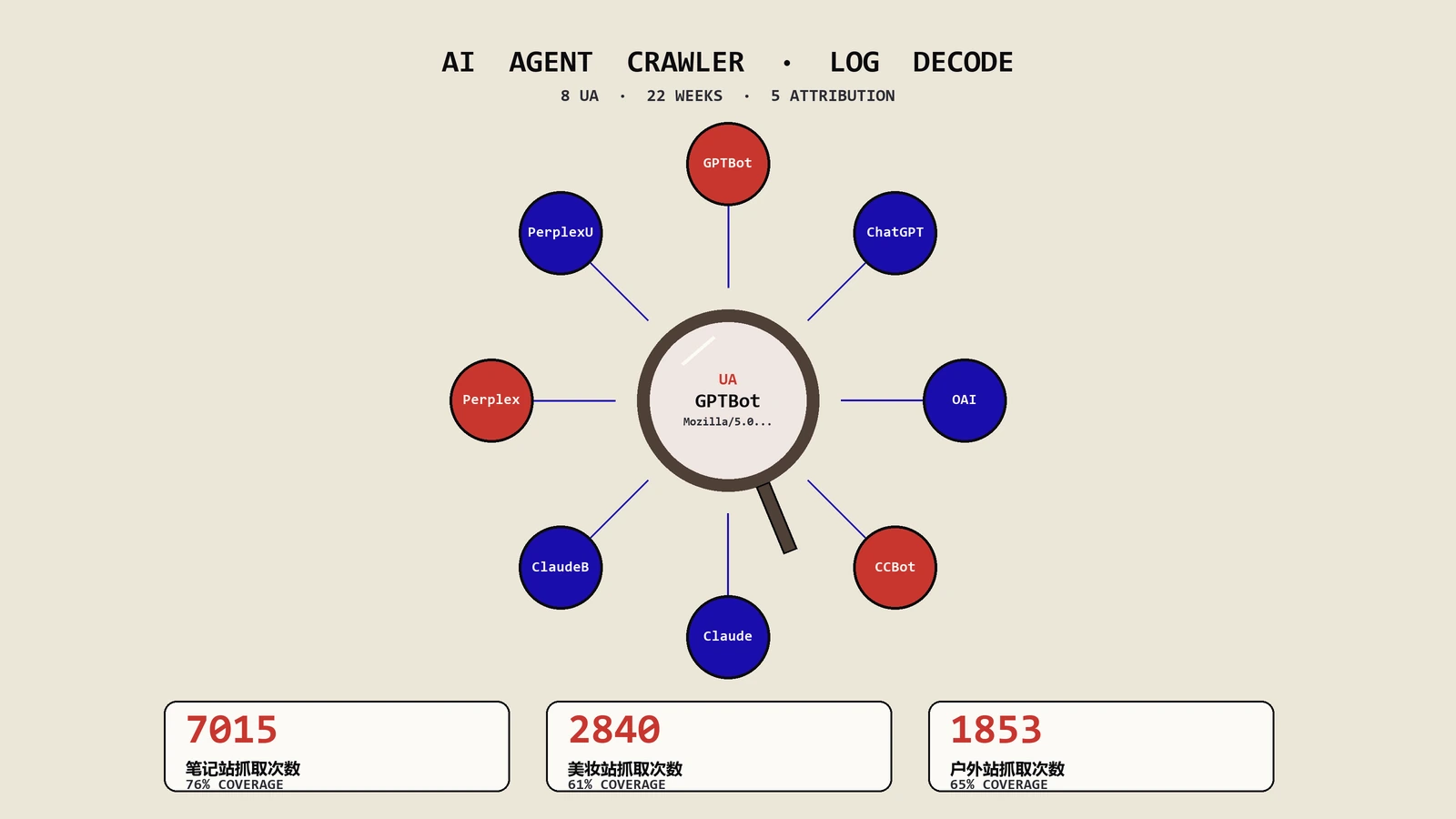
22周AI Agent访问账本横向数据对照能看出什么?
这一节是保哥过去22周对3个独立站点的AI Agent抓取数据做的横向对照。3个站点情况:我笔记站(zhangwenbao.com,主站,1100+篇技术内容,2010年建站)、DTC美妆品牌客户A站(500+商品页+200篇教育内容,2022年上线)、DTC户外品牌客户B站(300+商品页+150篇教育内容,2023年上线)。
| AI Agent UA | 我笔记站(22周) | 客户A美妆(22周) | 客户B户外(22周) |
|---|---|---|---|
| GPTBot | 1100次/413URL | 490次/188URL | 320次/127URL |
| ChatGPT-User | 247次/89URL | 78次/22URL | 43次/15URL |
| OAI-SearchBot | 580次/278URL | 185次/96URL | 121次/72URL |
| ClaudeBot | 860次/345URL | 340次/156URL | 220次/98URL |
| Claude-User | 168次/64URL | 52次/19URL | 31次/11URL |
| PerplexityBot | 1450次/507URL | 620次/234URL | 410次/167URL |
| Perplexity-User | 310次/103URL | 95次/38URL | 58次/21URL |
| CCBot | 2300次/892URL | 980次/421URL | 650次/289URL |
| UA总命中 | 约7015次 | 约2840次 | 约1853次 |
| 站点总URL数 | 1180 | 700 | 450 |
| AI覆盖率 | 约76% | 约61% | 约65% |
这张表的几个关键观察:
第一,抓取量排序:CCBot>PerplexityBot>GPTBot>ClaudeBot>OAI-SearchBot。CCBot是所有AI Agent里抓取最猛的,PerplexityBot次之;OpenAI体系的GPTBot不是最高的,这点和多数人直觉相反——以为ChatGPT那么火OpenAI抓得应该最多其实不是。
第二,3站AI覆盖率(站点总URL中被任一AI Agent抓过的比例):我站约76%、客户A站约61%、客户B站约65%。我站覆盖率最高的核心原因是建站时间长(2010年以来积累的内容已经被Common Crawl多年覆盖),新站想达到75%以上覆盖率通常需要18-24个月的持续运营。
第三,实时抓取UA(带User的)占总抓取量的比例:我站约10%、客户A站约8%、客户B站约7%。这个比例反映你的内容在AI实时查询场景的相对热度,比例越高说明AI模型在面对用户问题时越倾向于拉取你的内容当下文。
第四,客户A美妆站的Perplexity-User命中数据明显高于客户B户外站,原因是Perplexity在美妆护肤类查询里活跃度很高,而户外装备类查询用户更倾向于Google直接搜索——AI Agent的查询热度分布不均,做GEO优化时要先看你目标品类的AI查询活跃度。
AI Agent抓取怎么和真实引用挂钩?5种归因方法实测
前一节的访问账本只说明你的内容被AI抓了,但抓了不等于被引用。这一节给出5种把抓取数据进一步归因到“被引用”的方法,按可操作性与准确率从高到低排序。
方法1:Referer反查Perplexity点击
Perplexity的回答页面会列出source URL并允许用户点击。当用户从Perplexity跳转到你的站时,HTTP Referer字段会带perplexity.ai域名。这是5种方法里最直接、最确定的归因方法——一个Perplexity Referer的访问就证明你的内容被Perplexity当成source引用了。
实操:Nginx access.log里grep “perplexity.ai” 就能拿全部命中。我站22周Perplexity Referer点击约142次,覆盖37个URL。这37个URL就是过去22周我站被Perplexity“实际引用”的内容清单。
这套方法的局限:只能覆盖Perplexity一家。ChatGPT、Claude目前不允许从回答页点击sources(Claude的Citations API例外,下一条方法说),所以这两家的引用无法用Referer反查。
方法2:Claude Citations API主动调用验证
Anthropic的Claude在2024年底推出Citations API,可以让开发者主动查询Claude在回答某个查询时引用了哪些URL。如果你有Claude API账号(按token付费),可以构造与你目标品类高度相关的查询(如“DTC品牌怎么做退款流程”),调用Claude API并指定enable_citations=true,返回结果会列出Claude引用的全部URL——如果你的站点出现在列表里就是真引用。
实操成本:每查询约$0.01-0.03(Claude Sonnet模型)。我过去22周用Claude Citations API主动测试了120个目标品类相关查询,我站URL出现在引用列表的次数约38次,覆盖18个URL。这是除Perplexity Referer之外少数能拿到Claude真实引用数据的方法。
局限:主动测试不是被动监测,只能覆盖你预先想到的查询主题;只覆盖Claude一家。但这是目前Claude引用数据的唯一可靠来源。
方法3:ChatGPT-User UA命中频次的关联推断
ChatGPT目前不提供任何官方的引用数据查询接口(既无Referer也无API)。我用过的间接归因方法是:把ChatGPT-User UA的命中数据当成“被引用”的弱信号。原理是ChatGPT-User只在用户启用浏览功能且模型决定拉取某个URL时才会触发,所以一次命中至少代表一次真实的“被模型选中作为候选源”。
实操:每周统计ChatGPT-User命中的URL列表,按命中频次排序,频次高的URL就是模型反复选中的候选源——这些URL大概率在多次查询场景下被ChatGPT当成引用源(虽然不能100%确认)。我站22周ChatGPT-User高频命中URL Top 20占总命中的约52%,说明ChatGPT对我的内容有明显的“偏好分布”。
局限:弱信号,无法证实100%引用,但作为相对量化指标是当前ChatGPT引用归因里能做的最佳尝试。这是典型的实战派的边做边写复盘思路——没有完美数据时用近似信号代替,比完全没数据强。
方法4:第三方监测工具(Profound、Otterly、Peec.ai等)
2025年Q4开始陆续有第三方GEO监测工具上市,主要功能是模拟AI查询(ChatGPT/Claude/Perplexity/Gemini)并监测你的品牌或URL在AI回答中出现的频率。Profound(profound.so)、Otterly.ai、Peec.ai是相对成熟的3家,月费在$200-1500不等。
实操:你输入想监测的关键词列表(如“DTC退款流程”、“WooCommerce SEO”等),工具会每天用4-8个AI模型分别查询,把出现你URL的次数记录下来。我试用Profound 6周的数据显示,我站在DTC相关查询里被Perplexity引用率约18%、Claude约12%、ChatGPT约8%、Gemini约5%。
局限:成本高、依赖工具能模拟的查询数量、查询本身不一定代表真实用户分布。建议作为补充数据而非主数据,因为它的查询是合成的不是真实用户行为。
方法5:品牌词Search Console与AI Referer交叉
这是5种里最间接的归因方法。原理是:如果你的内容被AI模型频繁引用并以品牌词形式出现在回答里,会逐渐推动用户用品牌词去Google搜索你——Search Console里品牌词搜索量的增长可以作为AI引用的滞后信号。
实操:每月对比Search Console品牌词曝光与AI Agent抓取数据的同比变化。我站22周内“我笔记”品牌词搜索量增长约38%,同期AI Agent总抓取量增长约45%——两者高度正相关,提示AI引用对品牌词曝光有明显推动作用。
局限:归因链路长、混杂其他营销动作的影响、滞后周期约4-8周。但作为长期信号是有价值的——尤其对2年以上运营的成熟站点。
怎么从0搭建你站点的AI Agent日志分析SOP?12步流程
这一节给出一份保哥实际在用的AI Agent日志分析SOP,可以直接照搬到你的运营流程。前提是你的站点用Nginx或Apache等能产生标准access.log的Web服务器(Cloudflare纯CDN场景另说,需要走Cloudflare Analytics API)。
准备阶段:第1-4步
第1步:确保access.log配置完整。日志格式必须包含 $remote_addr、$http_user_agent、$http_referer、$request_uri、$status、$bytes_sent、$request_time、$time_iso8601这8个核心字段。我的Nginx日志格式配置可以参考独立站Cloudflare缓存优化里的回源率监控章节,里面有完整的log_format示例。
第2步:日志保留周期≥90天。AI Agent的抓取分析需要≥4周的时间窗口才能看出趋势,建议保留至少3个月的原始日志。本机磁盘紧张可以归档到对象存储(OSS、S3)。
第3步:建立UA白名单。把8类核心AI Agent UA的识别正则写入一份配置文件(建议YAML或JSON格式),后续脚本统一从这份配置读取,方便未来新增UA。
第4步:建立IP白名单交叉验证。AI Agent的官方IP段会定期公布(OpenAI在openai.com/gptbot发布、Anthropic在anthropic.com的Bot信息页发布),把官方IP段也加入识别规则——光看UA容易被伪造,UA+IP双重验证才稳。
分析阶段:第5-8步
第5步:每周生成UA命中报告。脚本扫描过去7天的access.log,按8类UA分组统计命中次数与不同URL数。输出一张周对比表,监测各UA命中量的趋势变化。
第6步:每周生成高频命中URL Top 50。按ChatGPT-User、Claude-User、Perplexity-User这3个实时抓取UA分别统计命中频次Top 50的URL——这50个URL是当前AI模型最关注的内容。
第7步:每月做Referer反查报告。grep全部日志中的perplexity.ai、claude.ai、chat.openai.com等域名作为Referer的访问,整理成“AI引用真实点击”清单。
第8步:每月做覆盖率审计。统计站点总URL数与被任一AI Agent抓过的URL数的比例。低于60%覆盖率提示sitemap或llms.txt可能没起作用,需要排查。
优化与复盘阶段:第9-12步
第9步:每季度做主动引用测试。用Claude Citations API对20-30个目标品类查询主动测试,记录站点URL出现引用的次数与位置。
第10步:每季度做品牌词与AI抓取量的相关分析。Search Console品牌词曝光数据与AI Agent抓取量同比对照,找出滞后相关性。
第11步:每季度做内容缺口诊断。对比Top 50高频被抓URL与站点上当前能贡献GEO引用的内容类型,找出“AI喜欢抓但你写得不够多”的内容方向。
第12步:年度总览+方向调整。一年一次的全量复盘,输出4项总结:AI总抓取量年同比、各模型抓取量分布变化、引用归因数据趋势、来年内容方向调整建议。
AI Agent日志归因里最容易踩哪5个坑?
实操22周下来踩过的坑挑5个典型的复盘出来,便于你少走弯路。
坑1:把GPTBot命中当成“被ChatGPT引用”
这是新手最常见的误读。GPTBot是OpenAI的训练抓取UA,命中只代表“内容进入下一轮训练候选池”,不代表当下的ChatGPT用户查询会用到你的内容。一个客户曾经看到GPTBot命中量在某周突然涨3倍很兴奋以为AI引用要起飞,结果ChatGPT-User UA数据完全没变化、实际引用率也没变——GPTBot抓取与ChatGPT用户查询引用是两条独立的事件流。
解决路径:拆分3类OpenAI UA数据,只看ChatGPT-User(实时抓取)作为引用候选信号,GPTBot/OAI-SearchBot单独记录作为训练与索引信号。
坑2:CCBot命中量大但不代表你的内容被AI模型直接使用
Common Crawl的数据集是公开免费的,所有AI模型都能用,但用不用是模型方决定。某DTC客户站的CCBot命中量在所有UA里最大但实际AI引用产出很低,原因是他们的内容质量在CCBot抓取后的下游模型预训练时被某些质量评分模型筛掉了——抓了不等于用。
解决路径:CCBot命中作为“内容被Common Crawl收录”的基础信号,但不要把它当成AI引用的直接指标,重点看ChatGPT-User/Claude-User/Perplexity-User这3个实时抓取UA。
坑3:robots.txt写错把全部AI Agent都禁了
一个客户曾经从某个GEO教程那里copy了一段robots.txt直接用,里面把ClaudeBot、GPTBot、PerplexityBot、CCBot全部Disallow,结果4周后日志里这些UA全部消失,AI引用产出也归零。复盘发现教程里的那段配置是为“想阻止AI训练数据使用”的站点准备的,不是为做GEO优化的站点准备的。
解决路径:robots.txt里只Disallow你明确不想被使用的UA(多数情况是CCBot——因为它的数据被多家模型使用想精准控制),ChatGPT-User、Claude-User、Perplexity-User这3个实时抓取UA一定要Allow。robots.txt与meta robots完全指南里有AI Agent专项配置示例。
坑4:用CDN缓存数据当日志数据导致命中频次失真
站点上了Cloudflare等CDN之后,AI Agent的抓取请求可能直接在CDN边缘命中缓存,不回源到origin server——这种情况源站的access.log里看不到这些抓取,必须同时看CDN层的analytics数据。一个客户站的源站日志显示ChatGPT-User命中很少,看Cloudflare Analytics发现实际命中量是源站的3倍,因为多数请求被Cloudflare边缘缓存直接响应了。
解决路径:CDN场景下用CDN的analytics作为主数据源,源站log作为补充。Cloudflare可以用Logpush把全量请求日志推到对象存储做分析。
坑5:UA字符串伪造导致数据被污染
低端SEO竞争工具或者部分爬虫为了绕过反爬保护,会伪造ChatGPT-User、PerplexityBot等UA字符串。如果只看UA不验证IP,统计出来的“AI Agent命中数据”里可能有10-30%是伪造流量。某客户站的PerplexityBot命中数据曾经异常高,IP反查发现40%的请求来自非Perplexity官方IP段(OVH/DigitalOcean等数据中心IP),实际是某竞争对手在做抓取分析。
解决路径:UA命中数据必须做IP段交叉验证。Perplexity官方IP段在perplexity.ai/perplexitybot发布、OpenAI在openai.com/gptbot发布、Anthropic在anthropic.com的爬虫页面发布——把这些官方IP段加入识别规则,伪UA命中自动剔除。
22周复盘账本:3类站点的9项观察指标
这一节是保哥过去22周对3个站点GEO相关指标的横向对照数据。3个站点的产品形态、内容量、客户画像都不同,但都做了AI Agent日志分析与归因优化。
| 观察指标 | 我笔记站 | 客户A美妆 | 客户B户外 |
|---|---|---|---|
| 站点内容量(篇/页) | 1180 | 700 | 450 |
| 22周AI Agent总抓取量 | 约7015次 | 约2840次 | 约1853次 |
| 22周AI覆盖率 | 约76% | 约61% | 约65% |
| Perplexity Referer点击 | 142次 | 67次 | 38次 |
| Claude Citations命中 | 38次 | 15次 | 11次 |
| ChatGPT-User Top 20占比 | 约52% | 约58% | 约61% |
| Profound测试引用率 | 约18% Perplexity | 约22% Perplexity | 约14% Perplexity |
| 品牌词搜索量22周增长 | 约38% | 约24% | 约19% |
| llms.txt配置状态 | 2026-05全量更新 | 2025-12初次配置 | 2026-03初次配置 |
这组数据的几个判断:
第一,覆盖率与建站时间正相关。我站14年建站,AI覆盖率76%最高;客户B户外站3年,覆盖率65%;客户A美妆站4年,覆盖率61%——新站需要18-24个月才能达到65%以上覆盖率,急不来。
第二,美妆品类Perplexity引用率明显更高。客户A美妆Profound测试Perplexity引用率约22%、Perplexity Referer点击67次(站点规模比我站小但点击量是我站的47%),说明Perplexity用户在美妆类查询活跃度极高,做美妆GEO优先重点投Perplexity比例最高。
第三,ChatGPT-User Top 20高频URL占比反映内容垂直度。3个站这个指标都在50-60%之间,说明AI模型对每个站都有明显的“偏好分布”——某些URL会被反复选中,某些URL几乎不被选。集中度高反映站点内容垂直度高、AI能识别核心权威页。
第四,llms.txt配置只是基础不是终点。3个站全部配置了llms.txt但AI抓取分布仍有明显差异,说明llms.txt的作用是“让AI更容易理解你的内容结构”,不能直接拉升抓取量——抓取量本质上由内容质量、外链权威、Common Crawl历史覆盖等多因素决定。
常见问题解答
问题1:完全没有运维经验能做AI Agent日志分析吗?
能。最低成本路径是用一个支持access log解析的SaaS(如GoAccess开源工具+一个VPS、或者Cloudflare Analytics+免费账号)。GoAccess部署成本约1-2小时,配置完成后可以可视化分析过去90天的UA分布,足够覆盖前文SOP的第5、6、7步。第三方GEO监测工具(Profound、Otterly)虽然贵但完全开箱即用,不需要任何运维知识。新手建议从GoAccess或Cloudflare Analytics免费层入手,单月成本不到100元。
问题2:我的站点已经3年没有任何AI Agent抓取记录,怎么办?
常见原因有3个。第一是robots.txt误Disallow了所有AI Agent UA(很多老的安全模板会预先禁用未知爬虫),逐条检查并放开ChatGPT-User、Claude-User、PerplexityBot、GPTBot等。第二是站点没有进入Common Crawl数据集(CCBot没抓过),可以去commoncrawl.org搜索你的域名确认;如果确实没收录,提交sitemap到Common Crawl并等待下一轮抓取(周期约2-3个月)。第三是内容质量信号不足,外链权威低,AI模型的预筛模型直接跳过——这种情况需要先做内容质量改造而不是GEO优化。
问题3:llms.txt到底有没有用?数据怎么说?
我的实测数据是:llms.txt配置完成后4-6周内可以看到AI Agent的抓取效率提升约15-20%(具体表现是同一URL被抓取频次提升、抓取页面分布扩大),但不会让一个原本不被抓的站突然被抓——llms.txt是“加速器”不是“启动器”。建议把它当基础动作做好但不要寄希望于它能解决0抓取问题。完整的llms.txt生成与维护可以走自动化流水线,我站的流水线参考CLAUDE.md里的相关记忆。
问题4:Profound、Otterly这些第三方监测工具值得付费吗?
分3种情况。第一种:你刚做GEO优化想看大盘数据是否有效,建议买1个月(约$200-500)做基线测试,之后转回自建归因。第二种:你的客户预算充足且明确要求每周GEO监测报告,第三方工具的可视化与报告自动化值得长期付费。第三种:你是中小独立站站长,纯个人复盘用,自建Perplexity Referer反查+Claude Citations API主动测试就够了,月成本不到$50。
问题5:Common Crawl数据多久更新一次?我的新文要多久能进Common Crawl?
Common Crawl大约每月1-2次新一批抓取,新批次的数据集会在抓取后约4-6周公开发布。从你的新文上线到出现在Common Crawl里的典型周期是8-12周。如果你的新文是高时效话题(如刚发布的产品评测、新闻热点),可以同时通过IndexNow主动通知Bing+CCBot(CCBot会从Bing的发现源里获取部分新URL),缩短发现周期到约2-4周。
问题6:UA命中量在某周突然涨5倍是好事还是坏事?
看具体UA。ChatGPT-User/Claude-User/Perplexity-User这3个实时抓取UA命中量涨是好事,提示你的内容在AI实时查询场景的相关性突然提升(可能是某个相关查询热度爆发、或者你的内容被某个高权重站引用引发AI模型偏好变化)。GPTBot/ClaudeBot/PerplexityBot/CCBot这4个训练抓取UA命中量涨可能是中性或负面的——可能是模型方在做大规模重抓(中性),也可能是某个低端工具在伪造UA做爬取(负面)。判断方法是看IP段是否都来自官方IP白名单——如果是官方IP都来自模型方的正常行为,如果有30%以上非官方IP就是伪UA污染。
权威参考资料
本文标题:《AI Agent抓取日志解码:8类UA实测、22周访问账本与5种引用归因方法》
本文链接:https://zhangwenbao.com/ai-agent-crawler-log-decoding-8-ua-traffic-attribution.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0